
Robotic Motion Intelligence Using Vector Symbolic Architectures and Blockchain-Based Smart Contracts

 , , , and
, , , and
Abstract
1. Introduction
2. Related Work
2.1. Robotic Learning
2.2. Vector Symbolic Architectures
- Similarity ⨀ is the operation to measure how close two hypervectors are in the vector space they occupy. If you consider two vectors with positive and negative components that are selected randomly, their similarity is expected to be close to zero: .
- Binding ⊗ operates on two (or more) vectors and associates them together: . The idea of binding is commonly used to associate concepts such as role-filler pairs. Bound vectors can later be retrieved using an unbinding operation.
- Unbinding ⊘ reverses the binding operation, i.e., if , then .
- Superposition ⊕ operates on two hypervectors and combines them: . The purpose of superposition is to accumulate concepts of a certain entity to generate a holistic representational hypervector.
2.3. Blockchain-Based Smart Contracts
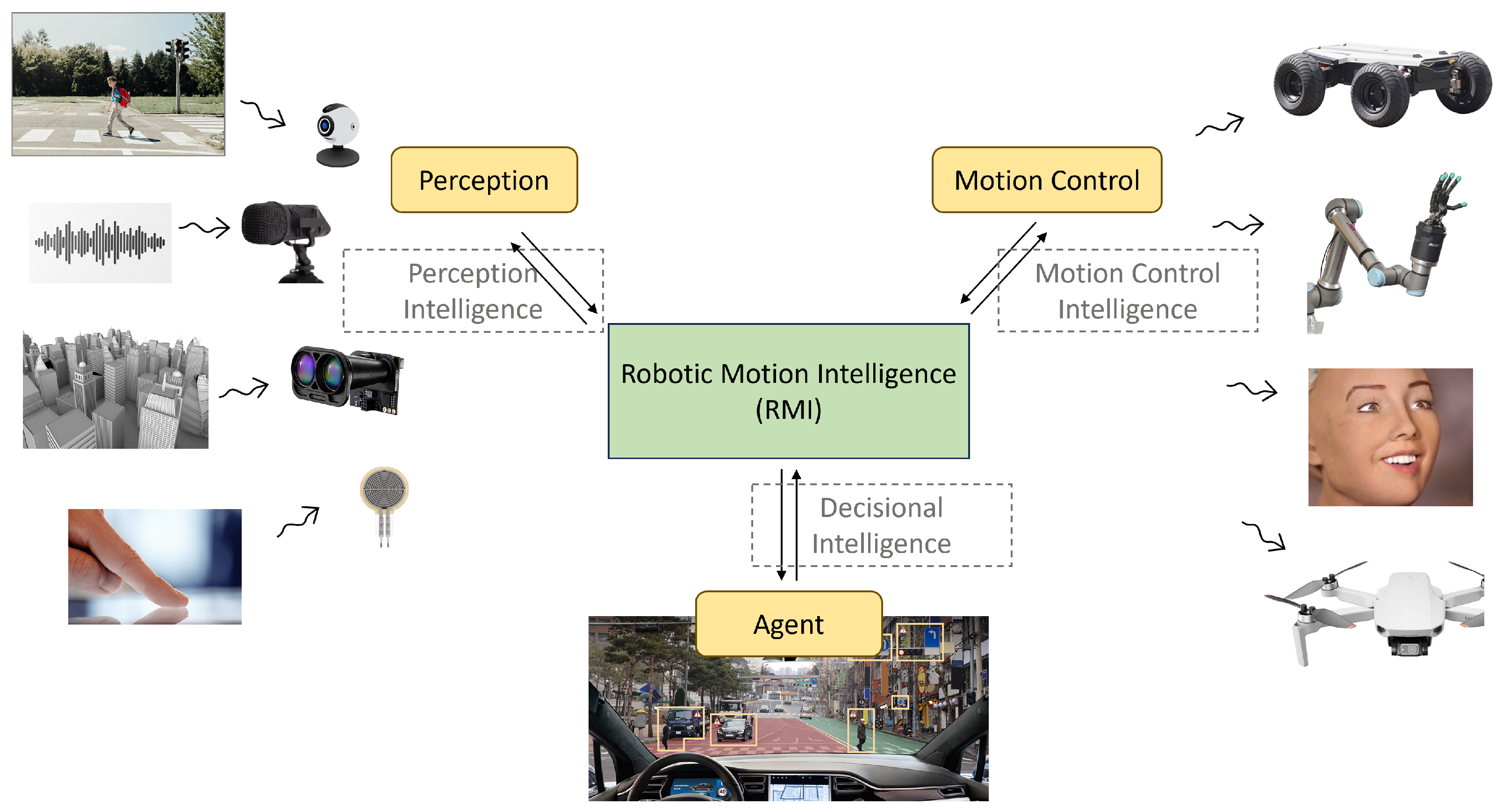
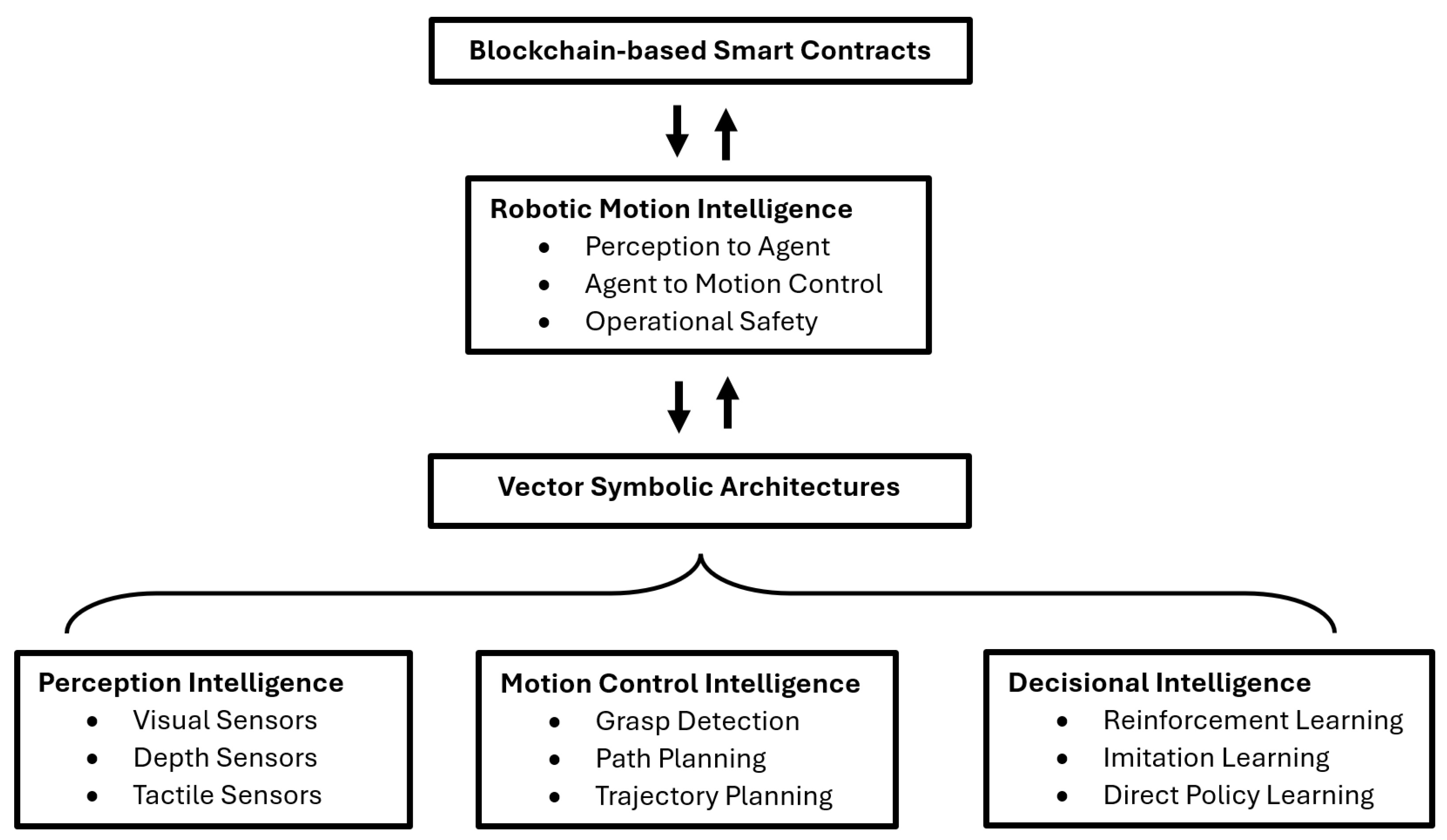
3. The Proposed RMI Framework
- Visual sensors for still images and video footage, facilitating dynamic vision capabilities. Through these sensors, robots can discern and interpret their surroundings, recognizing patterns, obstacles, and entities.
- Depth sensors for spatial understanding. These sensors aid in tasks like simultaneous localization and mapping (SLAM) and 3D mapping. By gauging depth, robots can navigate complex terrains and avoid potential obstructions.
- Audio sensors—besides sound detection, these sensors are equipped for voice and speech recognition, natural language processing (NLP), and noise suppression. This not only enables robots to understand human commands but also to interact in noisy environments.
- Touch sensors to detect tactile feedback, such as pressure variations and collisions. By sensing touch, robots can navigate safely, avoiding undue pressure on objects and preventing potential damage during interactions.
- Grasp Detection: The robot’s ability to hold an object using optimal force and positioning. This involves identifying and reaching the proposed pose of the final actuator with the highest likelihood of achieving a successful grasp. This ensures that the robot can interact with various objects securely and effectively.
- Path Planning: This involves determining a route through path planning as a dynamic and responsive task. It requires the robot to continuously adapt its path based on real-time changes in the environment, ensuring safe and efficient navigation in unpredictable settings.
- Trajectory Planning: Path planning determines the route and trajectory planning is about how the robot will traverse that path. It determines the sequence of movements, speeds, and orientations the robot should adopt to reach its destination.
- Reinforcement Learning (RL): A robotic learning technique for learning by interacting with the environment. Through a system of rewards and penalties, the agent learns to make decisions that maximize a certain objective over time. It is akin to teaching a robot through trial and error, allowing it to understand the consequences of its actions and refine its decision-making process accordingly.
- Imitation Learning: A robotic learning technique where robots learn from demonstrations, often by humans or other trained agents. Instead of learning from scratch, they leverage existing knowledge, adapting and refining it based on their own experiences.
3.1. Perception Intelligence
3.2. Motion Control Intelligence
3.3. RMI Agent and Decisional Intelligence
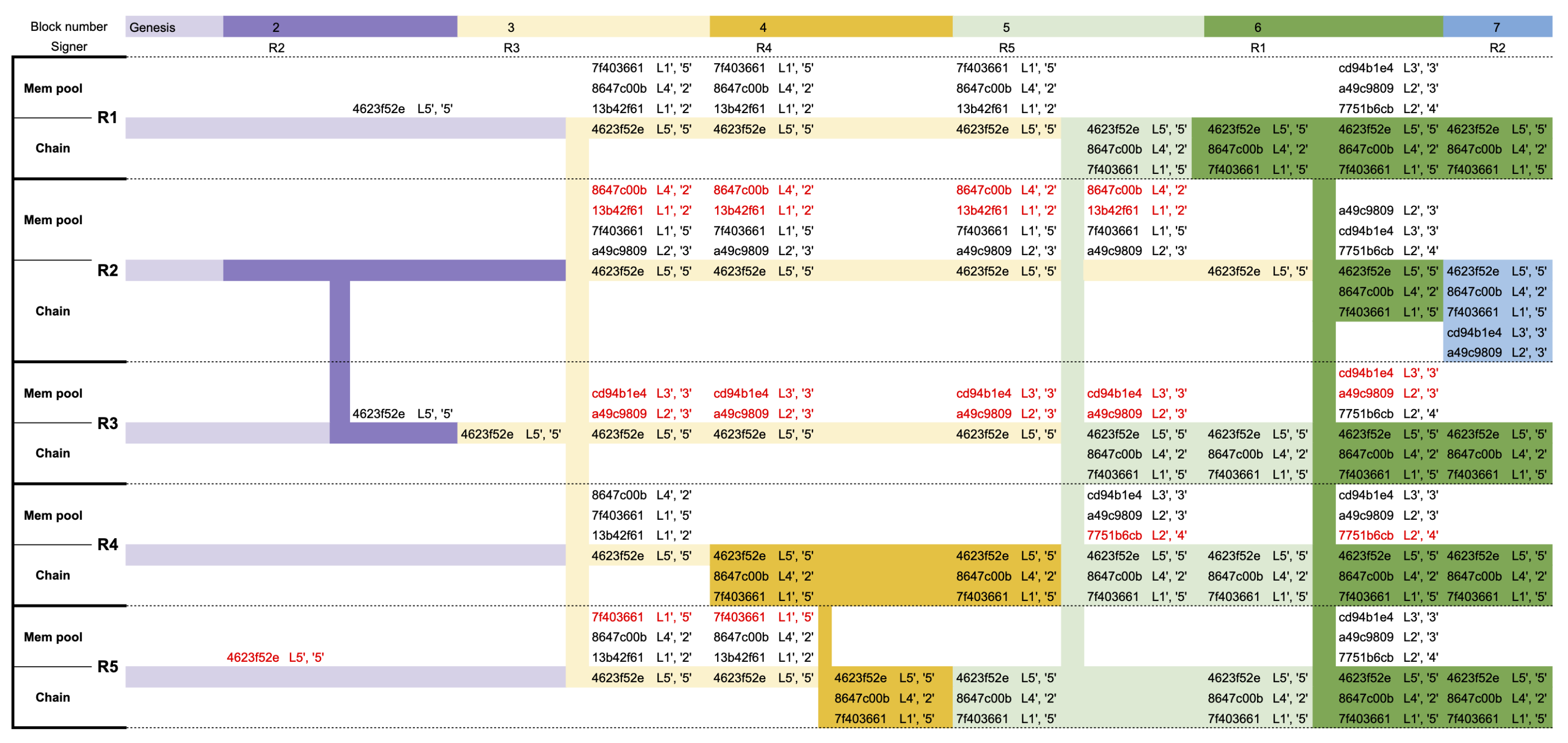
3.4. Blockchain-Based Smart Contracts
4. Empirical Evaluation of the RMI Framework
4.1. Experiment 1—Single Navigational Robot for Visual Place Recognition
Parameter Selection
4.2. Experiment 2—Multiple Navigational Robots for Landmark Discovery
4.3. Scalability Analysis
4.4. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cleary, K.; Nguyen, C. State of the art in surgical robotics: Clinical applications and technology challenges. Comput. Aided Surg. 2001, 6, 312–328. [Google Scholar] [PubMed]
- Manti, M.; Cacucciolo, V.; Cianchetti, M. Stiffening in soft robotics: A review of the state of the art. IEEE Robot. Autom. Mag. 2016, 23, 93–106. [Google Scholar]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Chen, X.; Choromanski, K.; Ding, T.; Driess, D.; Dubey, A.; Finn, C.; et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv 2023, arXiv:2307.15818. [Google Scholar]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Dabis, J.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; Hsu, J.; et al. Rt-1: Robotics transformer for real-world control at scale. arXiv 2022, arXiv:2212.06817. [Google Scholar]
- Reed, S.; Zolna, K.; Parisotto, E.; Colmenarejo, S.G.; Novikov, A.; Barth-Maron, G.; Gimenez, M.; Sulsky, Y.; Kay, J.; Springenberg, J.T.; et al. A generalist agent. arXiv 2022, arXiv:2205.06175. [Google Scholar]
- O’Neill, A.; Rehman, A.; Gupta, A.; Maddukuri, A.; Gupta, A.; Padalkar, A.; Lee, A.; Pooley, A.; Gupta, A.; Mandlekar, A.; et al. Open x-embodiment: Robotic learning datasets and rt-x models. arXiv 2023, arXiv:2310.08864. [Google Scholar]
- Pomerleau, D.A. Alvinn: An autonomous land vehicle in a neural network. Adv. Neural Inf. Process. Syst. 1988, 1. [Google Scholar]
- Pomerleau, D.A. Neural Network Perception for Mobile Robot Guidance; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 239. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Cultrera, L.; Seidenari, L.; Becattini, F.; Pala, P.; Del Bimbo, A. Explaining autonomous driving by learning end-to-end visual attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 340–341. [Google Scholar]
- Schmidgall, S.; Kim, J.W.; Kuntz, A.; Ghazi, A.E.; Krieger, A. General-purpose foundation models for increased autonomy in robot-assisted surgery. Nat. Mach. Intell. 2024, 6, 1275–1283. [Google Scholar]
- Wang, A.; Islam, M.; Xu, M.; Zhang, Y.; Ren, H. Sam meets robotic surgery: An empirical study on generalization, robustness and adaptation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer: Cham, Switzerland, 2023; pp. 234–244. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Adikari, A.; De Silva, D.; Ranasinghe, W.K.; Bandaragoda, T.; Alahakoon, O.; Persad, R.; Lawrentschuk, N.; Alahakoon, D.; Bolton, D. Can online support groups address psychological morbidity of cancer patients? An artificial intelligence based investigation of prostate cancer trajectories. PLoS ONE 2020, 15, e0229361. [Google Scholar]
- Yang, G.; Pang, Z.; Deen, M.J.; Dong, M.; Zhang, Y.T.; Lovell, N.; Rahmani, A.M. Homecare robotic systems for healthcare 4.0: Visions and enabling technologies. IEEE J. Biomed. Health Inform. 2020, 24, 2535–2549. [Google Scholar] [PubMed]
- De Silva, D.; Burstein, F.; Jelinek, H.F.; Stranieri, A. Addressing the complexities of big data analytics in healthcare: The diabetes screening case. Australas. J. Inf. Syst. 2015, 19. Available online: https://proceedings.neurips.cc/paper/1988/hash/812b4ba287f5ee0bc9d43bbf5bbe87fb-Abstract.html (accessed on 31 December 2024).
- Rao, Q.; Frtunikj, J. Deep learning for self-driving cars: Chances and challenges. In Proceedings of the 1st International Workshop on Software Engineering for AI in Autonomous Systems, Gothenburg Sweden, 28 May 2018; pp. 35–38. [Google Scholar]
- Nallaperuma, D.; De Silva, D.; Alahakoon, D.; Yu, X. Intelligent detection of driver behavior changes for effective coordination between autonomous and human driven vehicles. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3120–3125. [Google Scholar]
- Chehri, A.; Jeon, G.; Fofana, I.; Imran, A.; Saadane, R. Accelerating power grid monitoring with flying robots and artificial intelligence. IEEE Commun. Stand. Mag. 2021, 5, 48–54. [Google Scholar]
- De Silva, D.; Yu, X.; Alahakoon, D.; Holmes, G. Semi-supervised classification of characterized patterns for demand forecasting using smart electricity meters. In Proceedings of the 2011 International Conference on Electrical Machines and Systems, Beijing, China, 20–23 August 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–6. [Google Scholar]
- Taheri, H.; Hosseini, S.R.; Nekoui, M.A. Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation. arXiv 2024, arXiv:2405.16266. [Google Scholar] [CrossRef]
- de Moraes, L.D.; Kich, V.A.; Kolling, A.H.; Bottega, J.A.; Grando, R.B.; Cukla, A.R.; Gamarra, D.F.T. Enhanced Low-Dimensional Sensing Mapless Navigation of Terrestrial Mobile Robots Using Double Deep Reinforcement Learning Techniques. arXiv 2023, arXiv:2310.13809. [Google Scholar] [CrossRef]
- Huang, Z.; Lv, C.; Xing, Y.; Wu, J. Multi-Modal Sensor Fusion-Based Deep Neural Network for End-to-End Autonomous Driving with Scene Understanding. IEEE Sensors J. 2021, 21, 11781–11790. [Google Scholar] [CrossRef]
- Kober, J.; Peters, J. Imitation and reinforcement learning. IEEE Robot. Autom. Mag. 2010, 17, 55–62. [Google Scholar]
- Rothmann, M.; Porrmann, M. A survey of domain-specific architectures for reinforcement learning. IEEE Access 2022, 10, 13753–13767. [Google Scholar]
- Nguyen, N.D.; Nguyen, T.; Nahavandi, S. System design perspective for human-level agents using deep reinforcement learning: A survey. IEEE Access 2017, 5, 27091–27102. [Google Scholar]
- Le Mero, L.; Yi, D.; Dianati, M.; Mouzakitis, A. A survey on imitation learning techniques for end-to-end autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14128–14147. [Google Scholar]
- Haavaldsen, H.; Aasboe, M.; Lindseth, F. Autonomous vehicle control: End-to-end learning in simulated urban environments. In Proceedings of the Nordic Artificial Intelligence Research and Development: Third Symposium of the Norwegian AI Society, NAIS 2019, Trondheim, Norway, 27–28 May 2019; Proceedings 3. Springer: Cham, Switzerland, 2019; pp. 40–51. [Google Scholar]
- Codevilla, F.; Santana, E.; López, A.M.; Gaidon, A. Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9329–9338. [Google Scholar]
- Russell, S. Learning agents for uncertain environments. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 101–103. [Google Scholar]
- Ng, A.Y.; Russell, S. Algorithms for inverse reinforcement learning. In Proceedings of the Icml, Stanford, CA, USA, 29 June–2 July 2000; Volume 1, p. 2. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 1. [Google Scholar]
- Sadigh, D.; Sastry, S.; Seshia, S.A.; Dragan, A.D. Planning for autonomous cars that leverage effects on human actions. In Proceedings of the Robotics: Science and Systems, Ann Arbor, MI, USA, 18–22 June 2016; Volume 2, pp. 1–9. [Google Scholar]
- Ziebart, B.D.; Maas, A.; Bagnell, J.A.; Dey, A.K. Maximum Entropy Inverse Reinforcement Learning. In Proceedings of the Proc. AAAI, Chicago, IL, USA, 13–17 July 2008; pp. 1433–1438. [Google Scholar]
- Wulfmeier, M.; Ondruska, P.; Posner, I. Maximum entropy deep inverse reinforcement learning. arXiv 2015, arXiv:1507.04888. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Yang, C.; Liang, P.; Ajoudani, A.; Li, Z.; Bicchi, A. Development of a robotic teaching interface for human to human skill transfer. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 710–716. [Google Scholar] [CrossRef]
- Luo, J.; Dong, X.; Yang, H. Session search by direct policy learning. In Proceedings of the 2015 International Conference on the Theory of Information Retrieval, Northampton, MA, USA, 27–30 September 2015; pp. 261–270. [Google Scholar]
- Ross, S.; Gordon, G.; Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Zhang, J.; Cho, K. Query-efficient imitation learning for end-to-end autonomous driving. arXiv 2016, arXiv:1605.06450. [Google Scholar]
- Li, G.; Mueller, M.; Casser, V.; Smith, N.; Michels, D.L.; Ghanem, B. Oil: Observational imitation learning. arXiv 2018, arXiv:1803.01129. [Google Scholar]
- Müller, M.; Casser, V.; Lahoud, J.; Smith, N.; Ghanem, B. Sim4cv: A photo-realistic simulator for computer vision applications. Int. J. Comput. Vis. 2018, 126, 902–919. [Google Scholar] [CrossRef]
- Ruiz-del Solar, J.; Loncomilla, P.; Soto, N. A survey on deep learning methods for robot vision. arXiv 2018, arXiv:1803.10862. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Gomez-Ojeda, R.; Lopez-Antequera, M.; Petkov, N.; Gonzalez-Jimenez, J. Training a convolutional neural network for appearance-invariant place recognition. arXiv 2015, arXiv:1505.07428. [Google Scholar]
- Sünderhauf, N.; Dayoub, F.; McMahon, S.; Talbot, B.; Schulz, R.; Corke, P.; Wyeth, G.; Upcroft, B.; Milford, M. Place categorization and semantic mapping on a mobile robot. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 5729–5736. [Google Scholar]
- Liao, Y.; Kodagoda, S.; Wang, Y.; Shi, L.; Liu, Y. Understand scene categories by objects: A semantic regularized scene classifier using convolutional neural networks. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2318–2325. [Google Scholar]
- Madhavi, I.; Chamishka, S.; Nawaratne, R.; Nanayakkara, V.; Alahakoon, D.; De Silva, D. A deep learning approach for work related stress detection from audio streams in cyber physical environments. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; IEEE: Piscataway, NJ, USA, 2020; Volume 1, pp. 929–936. [Google Scholar]
- Tian, G.; Zhang, C.; Zhang, X.; Feng, Y.; Yuan, G.; Peng, T.; Pham, D.T. Multi-objective evolutionary algorithm with machine learning and local search for an energy-efficient disassembly line balancing problem in remanufacturing. J. Manuf. Sci. Eng. 2023, 145, 051002. [Google Scholar]
- Zhang, X.; Tian, G.; Fathollahi-Fard, A.M.; Pham, D.T.; Li, Z.; Pu, Y.; Zhang, T. A chance-constraint programming approach for a disassembly line balancing problem under uncertainty. J. Manuf. Syst. 2024, 74, 346–366. [Google Scholar]
- Chitta, K.; Prakash, A.; Geiger, A. NEAT: Neural Attention Fields for End-to-End Autonomous Driving. arXiv 2021, arXiv:2109.04456. [Google Scholar] [CrossRef]
- Chen, D.; Krähenbühl, P. Learning from All Vehicles. arXiv 2022, arXiv:2203.11934. [Google Scholar] [CrossRef]
- Hu, Y.; Yang, J.; Chen, L.; Li, K.; Sima, C.; Zhu, X.; Chai, S.; Du, S.; Lin, T.; Wang, W.; et al. Planning-oriented Autonomous Driving. arXiv 2023, arXiv:2212.10156. [Google Scholar] [CrossRef]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Yu, Q.; Dai, J. BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. arXiv 2022, arXiv:2203.17270. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, X.; Wang, Y.; Wang, Y.; Zhao, H. MUTR3D: A Multi-camera Tracking Framework via 3D-to-2D Queries. arXiv 2022, arXiv:2205.00613. [Google Scholar] [CrossRef]
- Gayler, R.W. Vector symbolic architectures answer Jackendoff’s challenges for cognitive neuroscience. arXiv 2004, arXiv:cs/0412059. [Google Scholar]
- Schlegel, K.; Neubert, P.; Protzel, P. A comparison of vector symbolic architectures. Artif. Intell. Rev. 2022, 55, 4523–4555. [Google Scholar] [CrossRef]
- Kanerva, P. Hyperdimensional computing: An introduction to computing in distributed representation with high-dimensional random vectors. Cogn. Comput. 2009, 1, 139–159. [Google Scholar]
- Karunaratne, G.; Le Gallo, M.; Cherubini, G.; Benini, L.; Rahimi, A.; Sebastian, A. In-memory hyperdimensional computing. Nat. Electron. 2020, 3, 327–337. [Google Scholar] [CrossRef]
- Moin, A.; Zhou, A.; Rahimi, A.; Menon, A.; Benatti, S.; Alexandrov, G.; Tamakloe, S.; Ting, J.; Yamamoto, N.; Khan, Y.; et al. A wearable biosensing system with in-sensor adaptive machine learning for hand gesture recognition. Nat. Electron. 2021, 4, 54–63. [Google Scholar]
- Schlegel, K.; Rachkovskij, D.A.; Osipov, E.; Protzel, P.; Neubert, P. Learnable Weighted Superposition in HDC and its Application to Multi-channel Time Series Classification. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- Osipov, E.; Kahawala, S.; Haputhanthri, D.; Kempitiya, T.; De Silva, D.; Alahakoon, D.; Kleyko, D. Hyperseed: Unsupervised learning with vector symbolic architectures. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 6583–6597. [Google Scholar]
- Kleyko, D.; Osipov, E.; De Silva, D.; Wiklund, U.; Alahakoon, D. Integer self-organizing maps for digital hardware. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Hersche, M.; Karunaratne, G.; Cherubini, G.; Benini, L.; Sebastian, A.; Rahimi, A. Constrained few-shot class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9057–9067. [Google Scholar]
- Bent, G.; Davies, C.; Vilamala, M.R.; Li, Y.; Preece, A.; Sola, A.V.; Di Caterina, G.; Kirkland, P.; Tutcher, B.; Pearson, G. The transformative potential of vector symbolic architecture for cognitive processing at the network edge. In Proceedings of the Artificial Intelligence for Security and Defence Applications II, Edinburgh, UK, 16–20 September 2024; SPIE: Bellingham, WA, USA, 2024; Volume 13206, pp. 404–420. [Google Scholar]
- Fung, M.L.; Chen, M.Z.; Chen, Y.H. Sensor fusion: A review of methods and applications. In Proceedings of the 2017 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3853–3860. [Google Scholar]
- Chandrasekaran, B.; Gangadhar, S.; Conrad, J.M. A survey of multisensor fusion techniques, architectures and methodologies. In Proceedings of the SoutheastCon 2017, Concord, NC, USA, 30 March–2 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–8. [Google Scholar]
- Zheng, Z.; Xie, S.; Dai, H.; Chen, X.; Wang, H. An Overview of Blockchain Technology: Architecture, Consensus, and Future Trends. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; pp. 557–564. [Google Scholar] [CrossRef]
- Szabo, N. Smart Contracts. 1994. Available online: https://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/smart.contracts.html (accessed on 31 December 2024).
- Novak, I. A Systematic Analysis of Cryptocurrencies. Ph.D. Thesis, Faculty of Economics and Business, University of Zagreb, Zagreb, Croatia, 2023. [Google Scholar]
- Strobel, V.; Pacheco, A.; Dorigo, M. Robot Swarms Neutralize Harmful Byzantine Robots Using a Blockchain-Based Token Economy. Sci. Robot. 2023, 8, eabm4636. [Google Scholar] [CrossRef] [PubMed]
- Ferrer, E.C.; Jiménez, E.; López-Presa, J.L.; Martín-Rueda, J. Following Leaders in Byzantine Multirobot Systems by Using Blockchain Technology. IEEE Trans. Robot. 2022, 38, 1101–1117. [Google Scholar] [CrossRef]
- Wang, T. PrivShieldROS: An Extended Robot Operating System Integrating Ethereum and Interplanetary File System for Enhanced Sensor Data Privacy. Sensors 2024, 24, 3241. [Google Scholar] [CrossRef]
- Salimi, S.; Morón, P.T.; Queralta, J.P.; Westerlund, T. Secure Heterogeneous Multi-Robot Collaboration and Docking with Hyperledger Fabric Blockchain. In Proceedings of the 2022 IEEE 8th World Forum on Internet of Things (WF-IoT), Yokohama, Japan, 26 October–11 November 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Xiong, Z.; Zhang, Y.; Niyato, D.; Wang, P.; Han, Z. When Mobile Blockchain Meets Edge Computing. IEEE Commun. Mag. 2018, 56, 33–39. [Google Scholar] [CrossRef]
- Ge, X. Smart Payment Contract Mechanism Based on Blockchain Smart Contract Mechanism. Sci. Program. 2021, 2021, 3988070. [Google Scholar] [CrossRef]
- Ullman, S. Against direct perception. Behav. Brain Sci. 1980, 3, 373–381. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar]
- Ölsner, F.; Milz, S. Catch me, if you can! a mediated perception approach towards fully autonomous drone racing. In Proceedings of the NeurIPS 2019 Competition and Demonstration Track, PMLR, Vancouver, BC, Canada, 8–14 December 2019; pp. 90–99. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar] [CrossRef]
- Yuan, D.; Fermüller, C.; Rabbani, T.; Huang, F.; Aloimonos, Y. A Linear Time and Space Local Point Cloud Geometry Encoder via Vectorized Kernel Mixture (VecKM). arXiv 2024, arXiv:2404.01568. [Google Scholar]
- Neubert, P.; Schubert, S. Hyperdimensional computing as a framework for systematic aggregation of image descriptors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16938–16947. [Google Scholar]
- Imani, M.; Kong, D.; Rahimi, A.; Rosing, T. Voicehd: Hyperdimensional computing for efficient speech recognition. In Proceedings of the 2017 IEEE International Conference on Rebooting Computing (ICRC), Washington, DC, USA, 8–9 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–8. [Google Scholar]
- Neubert, P.; Schubert, S.; Protzel, P. Learning Vector Symbolic Architectures for Reactive Robot Behaviours. 2017. Available online: https://d-nb.info/1214377416/34 (accessed on 31 December 2024).
- Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Large-scale image retrieval with attentive deep local features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3456–3465. [Google Scholar]
- Plate, T.A. Holographic reduced representations. IEEE Trans. Neural Netw. 1995, 6, 623–641. [Google Scholar]
- Wu, P.; Jia, X.; Chen, L.; Yan, J.; Li, H.; Qiao, Y. Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline. arXiv 2022, arXiv:2206.08129. [Google Scholar] [CrossRef]
- Hu, S.; Chen, L.; Wu, P.; Li, H.; Yan, J.; Tao, D. ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning. arXiv 2022, arXiv:2207.07601. [Google Scholar] [CrossRef]
- Pinciroli, C.; Trianni, V.; O’Grady, R.; Pini, G.; Brutschy, A.; Brambilla, M.; Mathews, N.; Ferrante, E.; Di Caro, G.; Ducatelle, F.; et al. ARGoS: A Modular, Parallel, Multi-Engine Simulator for Multi-Robot Systems. Swarm Intell. 2012, 6, 271–295. [Google Scholar] [CrossRef]
- Pacheco, A.; Denis, U.; Zakir, R.; Strobel, V.; Reina, A.; Dorigo, M. Toychain: A Simple Blockchain for Research in Swarm Robotics. arXiv 2024, arXiv:2407.06630. [Google Scholar] [CrossRef]
- Lopes, V.; Alexandre, L.A. An overview of blockchain integration with robotics and artificial intelligence. arXiv 2018, arXiv:1810.00329. [Google Scholar] [CrossRef]
- Aditya, U.S.; Singh, R.; Singh, P.K.; Kalla, A. A survey on blockchain in robotics: Issues, opportunities, challenges and future directions. J. Netw. Comput. Appl. 2021, 196, 103245. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Label Hypervector | Raw Reading | Example Reading |
|---|---|---|---|
| RGB Camera | Channel-R: | ||
| Channel-G: | |||
| Channel-B: | |||
| LiDAR | Channel-X: | ||
| Channel-Y: | |||
| Channel-Z: | |||
| Sonar | d (scaler) | ||
| Accelerometer | Channel-X: | ||
| Channel-Y: | |||
| Channel-Z: |
| Method | Navigational Method | Parameter Count | Dataset |
|---|---|---|---|
| UniAD [53] | MotionFormer | 2,628,352 | The nuScenes dataset is used which has a training set with 28,130 labeled keyframes which have 1.4 million bounding boxes |
| TCP [87] | Trajectory + Multi-step Control | 3,422,127 | 420 k data points are generated using CARLA simulator |
| LAV [52] | Motion Planner | 4,884,864 | 400 k data points are generated using CARLA simulator. |
| NEAT [51] | Neural Attention Field + Decoder | 492,359 | 130 k data points are generated using CARLA simulator |
| ST-P3 [88] | High Level planner | 269,438 | The nuScenes dataset |
| VSA-RMI (ours) | VSA operations | 30,000 (10,000 × 3) | 200 data-points from GardernsPointWalking |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Silva, D.; Withanage, S.; Sumanasena, V.; Gunasekara, L.; Moraliyage, H.; Mills, N.; Manic, M. Robotic Motion Intelligence Using Vector Symbolic Architectures and Blockchain-Based Smart Contracts. Robotics 2025, 14, 38. https://doi.org/10.3390/robotics14040038
De Silva D, Withanage S, Sumanasena V, Gunasekara L, Moraliyage H, Mills N, Manic M. Robotic Motion Intelligence Using Vector Symbolic Architectures and Blockchain-Based Smart Contracts. Robotics. 2025; 14(4):38. https://doi.org/10.3390/robotics14040038
Chicago/Turabian StyleDe Silva, Daswin, Sudheera Withanage, Vidura Sumanasena, Lakshitha Gunasekara, Harsha Moraliyage, Nishan Mills, and Milos Manic. 2025. "Robotic Motion Intelligence Using Vector Symbolic Architectures and Blockchain-Based Smart Contracts" Robotics 14, no. 4: 38. https://doi.org/10.3390/robotics14040038
APA StyleDe Silva, D., Withanage, S., Sumanasena, V., Gunasekara, L., Moraliyage, H., Mills, N., & Manic, M. (2025). Robotic Motion Intelligence Using Vector Symbolic Architectures and Blockchain-Based Smart Contracts. Robotics, 14(4), 38. https://doi.org/10.3390/robotics14040038