1. Introduction
With the growth of e-commerce, demand for the automation of bin picking by robots in warehouses has become high [
1], particularly in Japan, since the country is faced with a labor shortage due to its aging society. COVID-19 has made the situation worse since picking tasks in warehouses is not amenable to telework. Most state-of-the-art robotic picking systems focus on single-object grasping. To further improve the efficiency of these systems, simultaneous grasping of multiple objects might reduce the number of pick attempts to improve the picking speed, as shown in
Figure 1A. In addition, a robot can more stably grasp and hold objects that have a large surface using multiple suction cups to grasp the object, as demonstrated in
Figure 1B.
Multiple-object grasp planning for jaw or multi-finger grippers has previously been proposed under various conditions, such as in well-organized scenes [
2,
3], rearranged scenes [
4], and cluttered scenes [
5,
6,
7,
8]. These studies demonstrated that multiple-object grasping could improve picking speed. However, few studies have examined multiple-object grasping using a vacuum gripper with multiple suction cups. Most studies infer the single-object grasp point for a gripper with only a single suction cup using direct or indirect methods. Direct methods [
9,
10,
11] use deep convolutional neural networks to directly infer the grasp point, while indirect methods [
12,
13,
14] first infer the affordance map, which is a pixel-wise map indicating the graspability score for a single-cup vacuum gripper at each pixel, and then find the optimal grasp point in the map. Given that the affordance map contains all possible grasp points for a single suction cup, if all cups in a vacuum gripper have the same geometry (e.g., cup radius) and dynamics (e.g., suction force limit and friction coefficient), then we can search for a gripper pose where the center positions of at least two of the cups are located at non-zero pixels in the affordance map and satisfy the conditions described in
Section 4 for grasping multiple objects or an object with a large surface area.
In this study, we propose an affordance-map-based grasp planner for a multiple-suction-cup vacuum gripper to grasp multiple objects or grasp an object with a large surface area. We propose a 3D convolution-based method, which takes advantage of the suction affordance map inferred by our prior work, suction graspability U-Net++ (SG-U-Net++) [
14], to search for a gripper pose capable of grasping multiple objects or an object with a large surface area. Furthermore, unlike the control of a jaw gripper in which all fingers of the gripper are usually controlled to open or close simultaneously, the suction cups need to be controlled separately. Therefore, we design a kernel that includes an encoded cup ID to determine which suction cup to activate. Furthermore, as there might be many candidates for multiple-suction-cup grasping, we propose an evaluation metric for determining the optimal grasp among candidates. The proposed grasp planner is validated using previous affordance datasets and physical robot experiments.
In short, the contributions of this work include the following:
A 3D-convolution-based grasp planner for a vacuum gripper with multiple cups to grasp multiple objects or an object with a large surface area.
Control of suction cup activation by incorporating a convolution kernel, including the encoded cup ID.
A robotic picking system with a hybrid planner that performs multiple-suction-cup grasp planning preferentially and switches to single-object grasp planning when there are no solutions.
A sorting algorithm for determining the optimal grasp for multiple-cup grasping.
Validation of the grasp planner on previous affordance datasets, including Suction FCN [
12], SuctionNet-1Billion [
13], and SG-U-Net++ [
14].
Experiments for picking boxes, fruits, and daily necessities with a vacuum gripper with two cups and a comparison of multiple- and single-cup grasping results.
5. Multiple-Suction-Cup Grasp Planner
5.1. Overview of Architecture
Figure 4 and Algorithm 1 show the overall architecture and workflow of our multiple-suction-cup grasp planner. Given a depth image of
, our previous work SG-U-Net++ is used to infer the affordance map
for a single cup. The voxel grid generator then extracts the point cloud (
) affiliated with the affordable areas in the map and downsamples them to a voxel grid (
V). The orientation generator uses the point normals
of extracted points to efficiently generate the gripper orientation samples (
). The gripper kernel generator generates 3D encoded gripper kernels (
), including cup ID information. The decoder decodes the result (
) of 3D convolution (3D Conv.) of
V over
and generates the gripper pose candidates (
). The normal direction checker removes candidates where the
and contact point normals are not in the same direction. If
is successfully found,
is evaluated and ranked to obtain the optimal grasp (
). Otherwise, if no
is found, the planner is switched to our previous single-object grasp planner, where the position with the highest affordance score is set as the goal, and the cup that can reach the goal by the shortest trajectory is selected to grasp the object.
| Algorithm 1 Multiple-suction-cup grasp planner |
| Input: Iaff: affordance map |
| Id: depth image |
| Ipcd: point cloud |
| l: voxel size |
| C0: local cup center positions (see the right side of Figure 2) |
| Output: : optimal grasp |
- 1:
- 2:
- 3:
- 4:
- 5:
- 6:
- 7:
- 8:
if
then - 9:
- 10:
else - 11:
- 12:
- 13:
end if - 14:
return
|
5.2. Affordance Map Inference
We use SG-U-Net++ from our prior work to generate the affordance map. SG-U-Net++ has a nested U-Net structure and infers pixel-wise grasp quality and approachability based on a depth image. Refer to [
14] for further details. Pixels with non-zero grasp quality scores are filtered out to generate an affordance map (the green area in the affordance map in
Figure 4).
5.3. Voxel Grid Generation
We use voxel downsampling to generate the binary voxel grid (V) of the point cloud. Points located in the affordable areas are extracted and downsampled to a voxel grid with a defined grid size l. The voxel grid is further binarized such that if a grid in the voxel grid contained more than 10 points, the grid value would be 1 or 0. The voxel grid shape is , where , , and . and are the maximum and minimum bounds of the point cloud.
5.4. Grasp Orientation Candidate Generation
To satisfy Condition 3 in
Section 4, Equation (
2) must be computed for each point normal to sample the gripper orientations. If the size of the input point cloud is large, online sampling will result in high costs in terms of memory usage and computation time. We propose an efficient sampling method for a vacuum gripper by generating an offline normal to gripper orientation map. Since the Cartesian coordinates of a given vector
(
) can be represented by the azimuthal angle
and polar angle
as in Equation (
4), all possible normals of contact points can be sampled by an angle interval
, as in Equation (
5). Meanwhile, as in Equation (
1),
(the last column of
) depends on only
and
and has the same representation as Equation (
4), so
can be sampled by the same angle interval as in Equation (
6).
where
is the normal polar coordinate in the
plane, and
is the angle between the vector and the
z axis. Assuming the normal is always in the up direction,
and
.
where
and
.
For each
, we search for all
satisfying Equation (
2) in order to create a map
, which maps a point normal entry to all
in the same direction as the normal vector. This map could be generated offline, and this only needs to be carried out once, thus reducing the computation cost.
Based on
, given the point normals, the feasible candidate
could be rapidly obtained so that gripper orientation samples (
) could be generated. Given
, normals of points located in affordable areas are extracted and azimuthal and polar angles are computed (lines 1–3 in Algorithm 2). The angles are then used to calculate the entry key
to query
to obtain the feasible
, based on which samples (
and
) of
and
are obtained (lines 4–7 in Algorithm 2). Note that only unique
values with top-10% counts are used as entries. This helps to improve the sampling efficiency when the variation in
is small. For example, if the input point cloud is a set of points in a plane, all
and corresponding
are the same. Hence, using unique values, only one unique
rather than all
are used. As
depends on only
and
,
could be any value if
and
are feasible. Hence,
is sampled by the same interval
in the range
(lines 9–10 in Algorithm 2). The final
is obtained by multiplying the rotation matrix of sampled
,
, and
.
| Algorithm 2 Sample gripper orientation |
| Input: npcd: point normals |
| Iaff: affordance map |
| Δα: sampling interval |
| Output: SO: gripper orientation samples |
- 1:
- 2:
- 3:
- 4:
- 5:
- 6:
- 7:
- 8:
- 9:
- 10:
- 11:
- 12:
- 13:
return
|
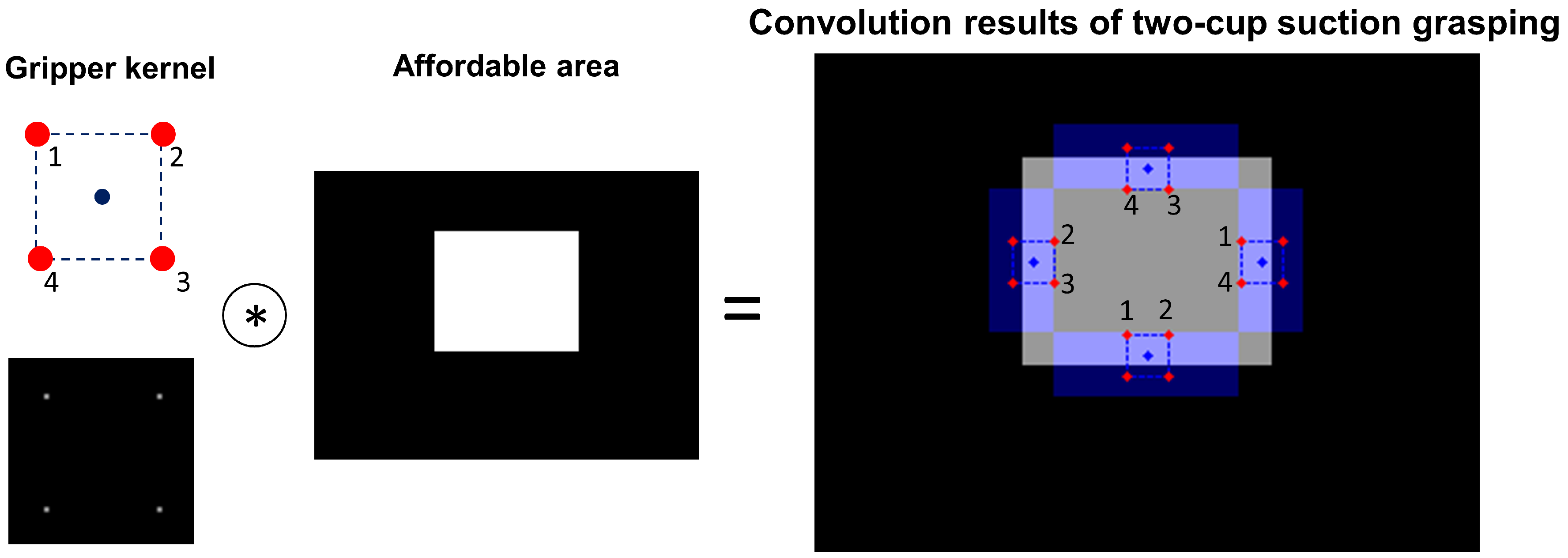
5.5. Gripper Orientation Kernel Generation and Suction Cup ID Encoding
The kernel representing each candidate gripper orientation generated in
Section 5.4 is created using 3D convolution to determine the graspable position for each
, as in Algorithm 3. A binary kernel is used to represent gripper poses in previous studies using 2D convolution [
39]. However, the convolution results can only determine the graspable position of the kernel and cannot directly determine which suction cup to activate. For example, as shown in
Figure 5, although the convolution results for the four cases are the same, the suction cups chosen to be activated are different and cannot be directly determined from the convolution results. Hence, we design a 3D kernel that includes the suction cup ID information. Algorithm 3 is used to generate kernels
of
. The shape of one kernel
is
, where
.
is the maximum distance of the suction cup center to the TCP in local gripper coordinates, and
l is the grid size of the kernel, which is equal to that of the voxel grid. The kernel indices of cup centers are
, where
C is the cup center position of
. The kernel grids at cup center kernel indices are filled with encoded vacuum ID information as in line 9 in Algorithm 3. Here, the
ith suction cup ID information is encoded as
, such that the cup ID is saved in the
ith decimal place, and such encoding helps to directly obtain the target suction cups to activate from the decoding convolution results (see
Section 5.7).
| Algorithm 3 Generated encoded kernels |
| Input: SO: gripper orientation samples |
| C0: local cup center positions |
| (see the right side of Figure 2) |
| l: voxel size |
| Output: : kernels of SO |
- 1:
- 2:
- 3:
for to do - 4:
- 5:
for to do - 6:
- 7:
- 8:
- 9:
- 10:
end for - 11:
- 12:
end for - 13:
return
|
5.6. Three-Dimensional Convolution
We perform 3D convolution to determine the indices in
V, where the gripper can grasp using multiple suction cups. Because the kernel is generated from an oriented
that is located in the same plane as the TCP, the corresponding kernel indices of cup centers and the TCP are in the same plane, which satisfies Condition 2 in
Section 4. Furthermore, as the distances from cup centers to the TCP are represented in a kernel scale that is the same as the voxel grid scale, we can slide the kernel over the voxel grid to determine the voxel grid index where the TCP satisfies Conditions 2 and 4. Specifically, as in Equation (
7), the kernel is set to each grid cell of the voxel grid to calculate the convolution sum. Note that
is the number of kernels, which is equal to
.
5.7. Convolution Results Decoding and Normal Direction Check
Algorithm 4 shows the decode function that decodes the 3D convolution results (
) to generate grasp candidates. As the 3D convolution of the kernel center is set to each grid cell of
V and accumulates the kernel values where the corresponding voxel grid value is non-zero (Equation (
7)), the cup to be activated can be determined by obtaining each digit of
. As in line 7 in Algorithm 4,
is decoded to target
ith suction cup activation
in Equation (
1) by scaling up
by
times and then calculating the value mod 10. If
is 1, a contact point exists for the
ith vacuum cup that should be activated. Otherwise, there is no contact point and the cup should be disabled. For example, for the gripper with two suction cups in
Figure 2, there are four (
) possible values of convolution results: 0.00, 0.10, 0.01, and 0.11, and the decoding results are [0, 0], [1, 0], [0, 1], and [1, 1], indicating non-graspable, graspable for only the first cup, graspable for only the second cup, and graspable for both cups, respectively.
| Algorithm 4 Decode |
| Input: ConvRes: 3D convolution results |
| Output: Gcand: grasp candidates for multiple-cup suction |
- 1:
- 2:
- 3:
for in do - 4:
for to do - 5:
- 6:
- 7:
end for - 8:
end for - 9:
- 10:
- 11:
- 12:
- 13:
- 14:
- 15:
return
|
As A is a one-hot vector, the sum of A is the number of suction cups to be used. Therefore, we determine the indices () of V where the sum of A is greater than or equal to two () in order to find the voxel grid indices where multiple suction cups can be used to grasp multiple objects or an object with a large surface area. is further converted to TCP positions in world coordinates ( in Algorithm 4), and the corresponding orientation , cup center positions , and target activation status can be obtained to generate the grasp candidates (), as in lines 12–15 in Algorithm 4.
The normal directions of all activated cups (
= 1) of
are checked to satisfy Condition 3. Specifically, the closest point to the contact point of each activated cup is searched for in
, and then the normal of that point is checked for whether it is in the same direction as the gripper’s z-axis direction using Equation (
2).
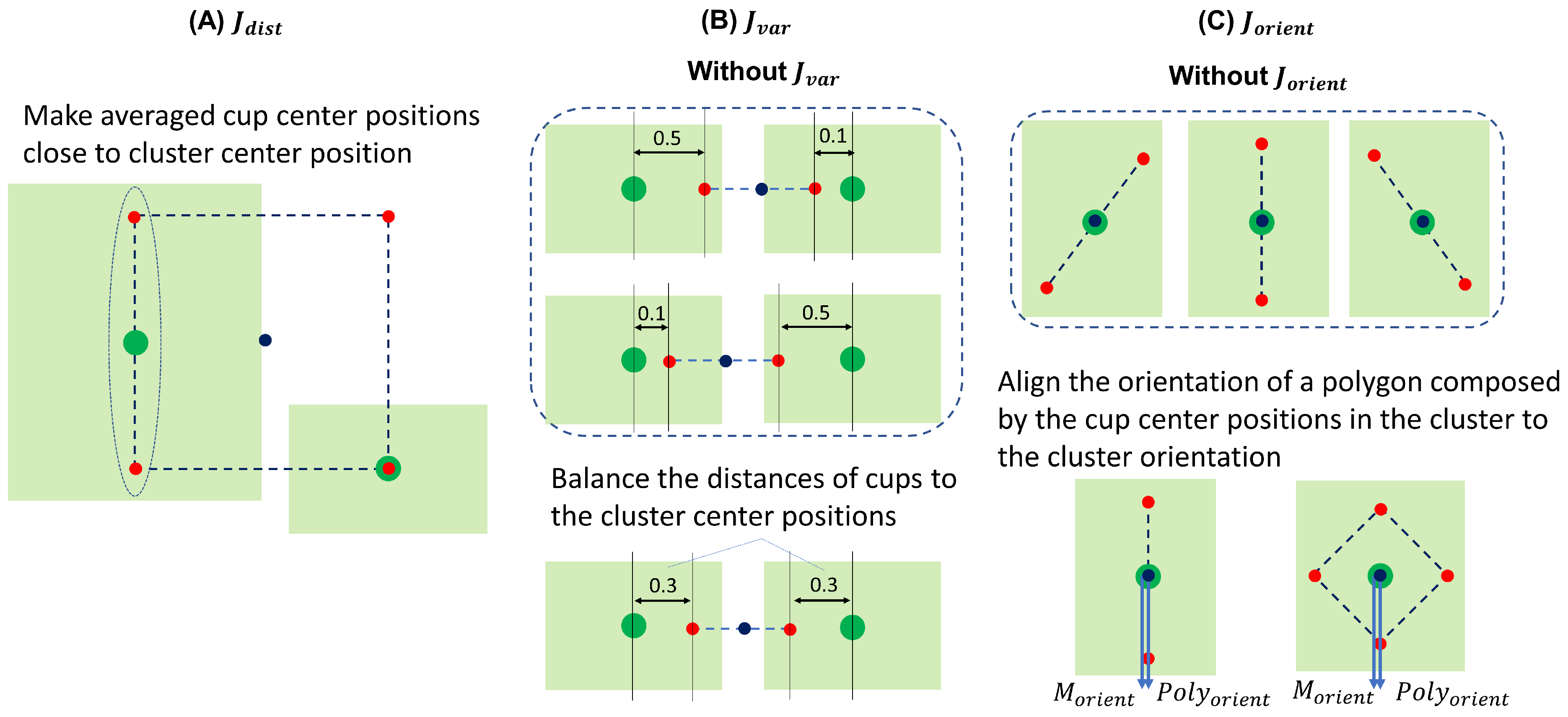
5.8. Ranking
Each
is evaluated and ranked to determine the optimal grasp
. We first perform point clustering on the points with non-zero affordance values, which are extracted from
to generate a label map
, distance map
, and orientation map
, as shown in
Figure 6.
contains the ID label of each cluster and is later used to calculate how many objects can be grasped.
contains the 3D distance from each point in the cluster to the cluster center.
contains the 3D orientation of each cluster.
and
are generated for later evaluation of the score (
J) of
. The height and width of the three maps are the same as those of
.
Lines 3–14 in Algorithm 5 evaluate the maximum number of objects that can be grasped
and the score
J of each
G in
, saving the evaluation results to a dictionary (
). The image coordinates (
) of cup center positions are calculated to obtain the contact point label for each cup in the
. Note that the contact labels might not be unique. If several cups have the same contact point label, it means that these cups can be used to grasp the same object, which has a large surface area. If all cups have different contact point labels, it means that each cup can grasp a unique object. Therefore, the number of unique contact labels is the maximum number of objects that can be grasped by
G.
J is the sum of
,
, and
.
evaluates the distance from the cup center or the average of cup centers to the cluster center because it is assumed to be more stable to hold the object at its center. As in Equation (
8) and
Figure 7A,
is evaluated as the average sum of distances from cups to the cluster center by obtaining the value of
at the position of the average cup center position (
) in each cluster.
has been incorporated because there are cases where one cup is near, but another cup is far from the cluster center, and
cannot evaluate these cases.
is used to balance the distances of cups to cluster center positions. Specifically, as in Equation (
9) and
Figure 7B,
evaluates the variance of the
value at the position of average cup center positions.
| Algorithm 5 Ranking |
| Input: Iaff: affordance map |
| Ipcd: point cloud |
| Gcand: grasp candidates |
| Output: Gopt: optimal grasp |
- 1:
- 2:
- 3:
for in do - 4:
- 5:
- 6:
- 7:
- 8:
- 9:
- 10:
- 11:
- 12:
- 13:
add to - 14:
end for - 15:
- 16:
for in do - 17:
if in in then - 18:
- 19:
else if in in then - 20:
if J in in then - 21:
- 22:
end if - 23:
end if - 24:
end for - 25:
return
|
has been incorporated to align the orientation of a polygon composed of the cup center positions in the cluster to the cluster orientation. Specifically, we calculate the dot product between the cluster orientation (longer or short axis unit vector) and the polygon orientation, as shown in Equation (
10) and
Figure 7C.
The and corresponding and J are added to the dictionary using as a key. Key level (local level) sorting is first performed to sort stored J (line 15 in the algorithm). Next, dictionary-level (global level) sorting is performed to determine with the highest and J (lines 16–24 in the algorithm). Note that both and sorted are returned because, if the motion planner fails to find a trajectory to , it would search for the trajectory to other goals with high and J in .
7. Results and Discussion
To our knowledge, this study is the first to propose a grasp planner for multiple-suction-cup grippers to grasp multiple objects or an object with a large surface area. Most of the previous studies used a deep neural network to infer the affordance map for finding the optimal grasp for single-cup grasping. Our planner took advantage of the affordance map to determine the optimal grasp for multiple-cup grasping. The planner was validated on three previous affordance map datasets, and the results are shown in
Table 1. Our planner successfully found multiple-suction-cup grasps from the affordance map from Suction FCN, SuctionNet-1Billion, and SG-U-Net++, indicating the high generality of the planner. There were no significant differences in position orientation error between the two-cup and four-cup gripper planning results. The error was the smallest when grasping was planned based on the affordance map from SG-U-Net++ because SG-U-Net++ used synthesized data (e.g., depth image and point cloud normals) without noise values.
Figure 9 and
Figure 10 show examples of grasp planning results for the two-cup and four-cup vacuum grippers. The planner successfully determined which of the cups to activate when grasping.
The physical experiment results show that multiple-cup suction grasping could improve the efficiency of picking tasks.
Table 2 shows a comparison of experimental results between single-cup (single-object) and multiple-cup (multiple-object) grasping. For single-object grasping, all three object sets could be cleared by the robot. Daily necessities had the highest success rate (91%) and highest PPH (502) among the three object sets. The success rate of picking fruits was the lowest because the objects had a ball-like shape and rolled and slipped when the gripper pushed them along the normal direction during grasping despite having the correct grasp pose. The success rate of picking boxes was lower than that of daily necessities because when two boxes were very close together, the planner treated them as a single box and grasped the center, which was actually the edge between two boxes. This problem did not occur in the case of multiple-suction-cup grasping because even when two boxes were treated as a single big box, the planner set the averaged cup center positions to the center of the affordable area, as shown in
Figure 7, so that the cups did not suck the edge between boxes. For multiple-object grasping, all three object sets could also be cleared by the robot. The success rate for grasping boxes (100%) was the highest among the object sets. The robot picked fruits with the highest speed (PPH = 779). Multiple-object grasping improved the picking speed by
for boxes (PPH: 467 vs. 677),
for fruits (PPH: 472 vs. 779), and
for daily necessities (PPH: 502 vs. 583). These results indicate that multiple-suction-cup grasping can improve picking speed. The improvement in picking daily necessities was minor because it was difficult to find multiple-cup graspable poses due to the complicated shapes of the items.
Figure 11 shows one picking trial for multiple-suction-cup grasping of boxes, fruits, and daily necessities. More trials are shown in the
Supplementary Materials Video S1 file.
In this study, the object sets are lightweight items. For the fruit object set, we used lightweight plastic fruit samples instead of real fruit to avoid crushing them. We mainly focused on the correct suction poses and assumed that the suction cup can generate enough force to hold the object if the MSC grasp pose is correct. Although we believe that the maximum load capacity of the selected suction cup is 500 g and that the cup can hold most of the common daily necessities, the influence of object weight on the planner result will be validated using objects with various weights (e.g., using real fruit with different weight) in the future. In addition, the objects in the experiments had rather large and flat surfaces, such that the formulated seals were circular shapes and all contact points between the cup and the surface were in the same plane. In this case, cups are assumed to be capable of fully generating the suction force. However, for a complicated object shape, the seal of a cup might be a polygon (see
Figure 1 in [
18]). In this case, a more precise contact force model should be used to evaluate the grasp quality (grasp success probability) of the cups, but this will also lead to an increase in planning time. Finding an efficient method to evaluate the contact force for MSC grasp candidates is one of our future works to improve the planner so it is applicable for grasping more complex shape objects in dense scenes.
The gripper dimensions will affect the planner in two ways. Firstly, the increase in dimensions will lead to an increase in the volume of the gripper kernels in
Figure 4, which will further result in an increase in planning time. Therefore, proper kernel interval size should be determined based on gripper dimension. In this study, the gripper kernel interval size was determined empirically. Automatic determination of the size based on gripper dimension will be considered to make the planner applicable to grippers with different dimensions. Secondly, if the gripper is too large, it will easily collide with the neighboring objects or bins so it will be difficult for the planner to find solutions for MSC grasping.
The picking system is expected to be improved in future work aimed at further increasing the picking speed. Our current layout of cups is fixed, and the positions and orientations of cups are fixed in the gripper. However, the real-world scenario is complex in that the items may have complex shapes, and the poses of items are disorganized. Hence, a fixed cup configuration may lead to a low probability of finding MSC grasp poses in a very complex environment (e.g., a dense scene) because there are few candidates who satisfy the MSC grasp condition. Making the positions and poses of cups adjustable by a proper gripper mechanical design may increase the probability of finding MSC grasp poses, which could be one of the directions in our future work to further improve the picking efficiency. In addition, as described above, one common failure is that objects can move (e.g., roll) after being grasped. We intend to analyze the dynamics (e.g., object shape, friction, and contact force between items) after grasping to find a grasp that moves the object and neighboring objects such that grasp success is improved. Another area for improvement is depth filling because incomplete depth results in low accuracy in estimating the affordance map and normals and thus leads to low grasp success. Furthermore, we will consider the picking sequence to improve the possibility of picking multiple objects. Picking experiments using a gripper with more suction cups will be conducted to further validate the performance and application of the planner for MSC grasp in the future. Our system cannot detect whether or not the gripper has successfully grasped the object. There are no sensors to detect whether or not the seal has been successfully formulated. Using a force sensor to detect the grasp success will be conducted in the future. If the force load of the end-effector increases after grasping, the object will be considered to be successfully grasped by the gripper. Based on the success detection result, the robot will be required to re-grasp a certain object if grasp failure occurs without returning to its home position to improve the picking efficiency.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}