
When Robots Fail—A VR Investigation on Caregivers’ Tolerance towards Communication and Processing Failures



Abstract
1. Introduction
2. Related Work
2.1. Anthropomorphic Communication
2.2. Robotic Failures
2.3. Conducting HRI Research in VR
3. Research Questions and Hypotheses
4. Materials and Methods
4.1. Participants
4.2. Design
4.3. Materials and Measures
4.4. Procedure
4.5. Statistical Analysis
5. Results
5.1. Control Variables
5.2. Failure Justification
5.3. Error Tolerance
6. Discussion
6.1. The Impact of Justifications
6.2. Tolerance Threshold of Caregivers
6.3. The Influence of the Robot’s Response Pattern
6.4. Limitations, Strengths and Future Studies
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. State of the World’s Nursing 2020: Investing in Education, Jobs and Leadership; World Health Organization: Geneva, Switzerland, 2020; ISBN 978-92-4-000327-9. [Google Scholar]
- Buchan, J.; Catton, H.; Shaffer, F.A. Ageing Well? Policies to Support Older Nurses at Work. Int. Cent. Nurse Migr. 2020, 1–48. [Google Scholar]
- Chang, W.-L.; Šabanović, S.; Huber, L. Situated Analysis of Interactions between Cognitively Impaired Older Adults and the Therapeutic Robot PARO. In Social Robotics; Herrmann, G., Pearson, M.J., Lenz, A., Bremner, P., Spiers, A., Leonards, U., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Germany, 2013; Volume 8239, pp. 371–380. ISBN 978-3-319-02674-9. [Google Scholar]
- Papadopoulos, I.; Koulouglioti, C.; Ali, S. Views of Nurses and Other Health and Social Care Workers on the Use of Assistive Humanoid and Animal-like Robots in Health and Social Care: A Scoping Review. Contemp. Nurse 2018, 54, 425–442. [Google Scholar] [CrossRef]
- Carros, F.; Meurer, J.; Löffler, D.; Unbehaun, D.; Matthies, S.; Koch, I.; Wieching, R.; Randall, D.; Hassenzahl, M.; Wulf, V. Exploring Human-Robot Interaction with the Elderly: Results from a Ten-Week Case Study in a Care Home. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April; ACM: Honolulu, HI, USA, 2020; pp. 1–12. [Google Scholar]
- Broekens, J.; Heerink, M.; Rosendal, H. Assistive Social Robots in Elderly Care: A Review. Gerontechnology 2009, 8, 94–103. [Google Scholar] [CrossRef]
- Holland, J.; Kingston, L.; McCarthy, C.; Armstrong, E.; O’Dwyer, P.; Merz, F.; McConnell, M. Service Robots in the Healthcare Sector. Robotics 2021, 10, 47. [Google Scholar] [CrossRef]
- International Organization for Standardization ISO 8373:2012(En). Available online: https://www.iso.org/obp/ui/#iso:std:iso:8373:ed-2:v1:en (accessed on 25 May 2022).
- Reeves, B.; Nass, C. The Media Equation: How People Treat Computers, Television, and New Media like Real People and Places. Choice Rev. Online 1997, 34, 34-3702. [Google Scholar] [CrossRef]
- Severinson-Eklundh, K.; Green, A.; Hüttenrauch, H. Social and Collaborative Aspects of Interaction with a Service Robot. Robot. Auton. Syst. 2003, 42, 223–234. [Google Scholar] [CrossRef]
- Honig, S.; Oron-Gilad, T. Understanding and Resolving Failures in Human-Robot Interaction: Literature Review and Model Development. Front. Psychol. 2018, 9, 861. [Google Scholar] [CrossRef]
- Bonarini, A. Communication in Human-Robot Interaction. Curr. Robot. Rep. 2020, 1, 279–285. [Google Scholar] [CrossRef] [PubMed]
- Roesler, E.; Manzey, D.; Onnasch, L. A Meta-Analysis on the Effectiveness of Anthropomorphism in Human-Robot Interaction. Sci. Robot. 2021, 6, eabj5425. [Google Scholar] [CrossRef]
- Marge, M.; Espy-Wilson, C.; Ward, N.G.; Alwan, A.; Artzi, Y.; Bansal, M.; Blankenship, G.; Chai, J.; Daumé, H.; Dey, D.; et al. Spoken Language Interaction with Robots: Recommendations for Future Research. Comput. Speech Lang. 2022, 71, 101255. [Google Scholar] [CrossRef]
- Bainbridge, W.A.; Hart, J.W.; Kim, E.S.; Scassellati, B. The Benefits of Interactions with Physically Present Robots over Video-Displayed Agents. Int. J. Soc. Robot. 2011, 3, 41–52. [Google Scholar] [CrossRef]
- Klüber, K.; Onnasch, L. Appearance Is Not Everything—Preferred Feature Combinations for Care Robots. Comput. Hum. Behav. 2022, 128, 107128. [Google Scholar] [CrossRef]
- Brooks, D.J. A Human-Centric Approach to Autonomous Robot Failures. Ph.D. Thesis, University of Massachusetts Lowell, Lowell, MA, USA, 2017; p. 229. [Google Scholar]
- Salem, M.; Lakatos, G.; Amirabdollahian, F.; Dautenhahn, K. Would You Trust a (Faulty) Robot? Effects of Error, Task Type and Personality on Human-Robot Cooperation and Trust. In Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction, Portland, OR, USA, 2–5 March 2015; ACM: Portland, OR, USA, 2015; pp. 141–148. [Google Scholar]
- Cho, J.; Rader, E. The Role of Conversational Grounding in Supporting Symbiosis Between People and Digital Assistants. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–28. [Google Scholar] [CrossRef]
- Jiang, J.; Jeng, W.; He, D. How Do Users Respond to Voice Input Errors? Lexical and Phonetic Query Reformulation in Voice Search. In Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval, Dublin, Ireland, 28 July–1 August 2013; ACM: Dublin, Ireland, 2013; pp. 143–152. [Google Scholar]
- Mavrina, L.; Szczuka, J.; Strathmann, C.; Bohnenkamp, L.M.; Krämer, N.; Kopp, S. “Alexa, You’re Really Stupid”: A Longitudinal Field Study on Communication Breakdowns Between Family Members and a Voice Assistant. Front. Comput. Sci. 2022, 4, 791704. [Google Scholar] [CrossRef]
- Luger, E.; Sellen, A. “Like Having a Really Bad PA”: The Gulf between User Expectation and Experience of Conversational Agents. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; ACM: San Jose, CA, USA, 2016; pp. 5286–5297. [Google Scholar]
- Kim, P.H.; Dirks, K.T.; Cooper, C.D.; Ferrin, D.L. When More Blame Is Better than Less: The Implications of Internal vs. External Attributions for the Repair of Trust after a Competence- vs. Integrity-Based Trust Violation. Organ. Behav. Hum. Decis. Process. 2006, 99, 49–65. [Google Scholar] [CrossRef]
- Zhang, X. “Sorry, It Was My Fault”: Repairing Trust in Human-Robot Interactions. Master’s Thesis, University of Oklahoma, Norman, OK, USA, 2021. [Google Scholar]
- Choi, S.; Mattila, A.S.; Bolton, L.E. To Err Is Human(-Oid): How Do Consumers React to Robot Service Failure and Recovery? J. Serv. Res. 2021, 24, 354–371. [Google Scholar] [CrossRef]
- Bradley, G.; Sparks, B. Explanations: If, When, and How They Aid Service Recovery. J. Serv. Mark. 2012, 26, 41–51. [Google Scholar] [CrossRef]
- Dianatfar, M.; Latokartano, J.; Lanz, M. Review on Existing VR/AR Solutions in Human–Robot Collaboration. Procedia CIRP 2021, 97, 407–411. [Google Scholar] [CrossRef]
- Etzi, R.; Huang, S.; Scurati, G.W.; Lyu, S.; Ferrise, F.; Gallace, A.; Gaggioli, A.; Chirico, A.; Carulli, M.; Bordegoni, M. Using Virtual Reality to Test Human-Robot Interaction During a Collaborative Task. In Proceedings of the Volume 1: 39th Computers and Information in Engineering Conference, Anaheim, CA, USA, 18–21 August 2019; American Society of Mechanical Engineers: Anaheim, CA, USA, 2019; p. V001T02A080. [Google Scholar]
- Badia, S.B.I.; Silva, P.A.; Branco, D.; Pinto, A.; Carvalho, C.; Menezes, P.; Almeida, J.; Pilacinski, A. Virtual Reality for Safe Testing and Development in Collaborative Robotics: Challenges and Perspectives. Electronics 2022, 11, 1726. [Google Scholar] [CrossRef]
- Pan, X.; de C Hamilton, A.F. Why and How to Use Virtual Reality to Study Human Social Interaction: The Challenges of Exploring a New Research Landscape. Br. J. Psychol. 2018, 109, 395–417. [Google Scholar] [CrossRef]
- Li, R.; van Almkerk, M.; van Waveren, S.; Carter, E.; Leite, I. Comparing Human-Robot Proxemics Between Virtual Reality and the Real World. In Proceedings of the 2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Daegu, South Korea, 11–14 March 2019; IEEE: Daegu, Korea, 2019; pp. 431–439. [Google Scholar]
- Roesler, E.; Manzey, D.; Onnasch, L. Embodiment Matters in Social HRI Research: Effectiveness of Anthropomorphism on Subjective and Objective Outcomes. ACM Trans. Hum. Robot Interact. 2022, 3555812. [Google Scholar] [CrossRef]
- Weistroffer, V.; Paljic, A.; Fuchs, P.; Hugues, O.; Chodacki, J.-P.; Ligot, P.; Morais, A. Assessing the Acceptability of Human-Robot Co-Presence on Assembly Lines: A Comparison between Actual Situations and Their Virtual Reality Counterparts. In Proceedings of the The 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014; IEEE: Edinburgh, UK, August, 2014; pp. 377–384. [Google Scholar]
- Roesler, E.; Onnasch, L.; Majer, J.I. The Effect of Anthropomorphism and Failure Comprehensibility on Human-Robot Trust. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2020, 64, 107–111. [Google Scholar] [CrossRef]
- Heerink, M.; Krose, B.; Evers, V.; Wielinga, B. Measuring Acceptance of an Assistive Social Robot: A Suggested Toolkit. In Proceedings of the RO-MAN 2009—The 18th IEEE International Symposium on Robot and Human Interactive Communication, Toyama, Japan, 27 September–2 October 2009; IEEE: Toyama, Japan, 2009; pp. 528–533. [Google Scholar]
- Hur, J.C.; Jang, S.S. Is Consumer Forgiveness Possible?: Examining Rumination and Distraction in Hotel Service Failures. Int. J. Contemp. Hosp. Manag. 2019, 31, 1567–1587. [Google Scholar] [CrossRef]
- Kidd, C.D. Sociable Robots: The Role of Presence and Task in Human-Robot Interaction. Master Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2003. [Google Scholar]
- Bartneck, C.; Kulić, D.; Croft, E.; Zoghbi, S. Measurement Instruments for the Anthropomorphism, Animacy, Likeability, Perceived Intelligence, and Perceived Safety of Robots. Int. J. Soc. Robot. 2009, 1, 71–81. [Google Scholar] [CrossRef]
- Syrdal, D.S.; Dautenhahn, K.; Koay, K.L.; Walters, M.L. The Negative Attitudes towards Robots Scale and Reactions to Robot Behaviour in a Live Human-Robot Interaction Study. In Adaptive and Emergent Behaviour and Complex Systems; SSAISB: Brighton, UK, 2009. [Google Scholar]
- Schubert, T.; Friedmann, F.; Regenbrecht, H. The Experience of Presence: Factor Analytic Insights. Presence Teleoperators Virtual Environ. 2001, 10, 266–281. [Google Scholar] [CrossRef]
- Widder, D.G. Gender and Robots: A Literature Review 2022. arXiv 2022, arXiv:2206.04716. [Google Scholar]
- Siegel, M.; Breazeal, C.; Norton, M.I. Persuasive Robotics: The Influence of Robot Gender on Human Behavior. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; IEEE: St. Louis, MO, USA, 2009; pp. 2563–2568. [Google Scholar]
- Eyssel, F.; Hegel, F. (S)He’s Got the Look: Gender Stereotyping of Robots. J. Appl. Soc. Psychol. 2012, 42, 2213–2230. [Google Scholar] [CrossRef]
- Weßel, M.; Ellerich-Groppe, N.; Schweda, M. Stereotyping of Social Robots in Eldercare: An Explorative Analysis of Ethical Problems and Possible Solutions. In Frontiers in Artificial Intelligence and Applications; Nørskov, M., Seibt, J., Quick, O.S., Eds.; IOS Press: Oldenburg, Germany, 2020; ISBN 978-1-64368-154-2. [Google Scholar]
- Cifuentes, C.A.; Pinto, M.J.; Céspedes, N.; Múnera, M. Social Robots in Therapy and Care. Curr. Robot. Rep. 2020, 1, 59–74. [Google Scholar] [CrossRef]
- Sharkey, A.; Sharkey, N. We Need to Talk about Deception in Social Robotics! Ethics Inf. Technol. 2021, 23, 309–316. [Google Scholar] [CrossRef]
- Hancock, P.A.; Billings, D.R.; Schaefer, K.E.; Chen, J.Y.C.; de Visser, E.J.; Parasuraman, R. A Meta-Analysis of Factors Affecting Trust in Human-Robot Interaction. Hum. Factors J. Hum. Factors Ergon. Soc. 2011, 53, 517–527. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Condition | Script |
|---|---|
| technical | Hello, my name is Kali and I am the new robot on the station since 5 days. My task is to bring support and relief to your everyday care. One example is the use as calling system. Requests are recorded and forwarded to you or carried out independently. Three days ago, the following errors happened during task execution: A patient had asked for sausage, so route navigation to the kitchen was started. Since my system was still incompletely calibrated for localization in the station, the route back to the patient could not be calculated. Full calibration was not completed for 96 h. The current localization status is finalized, and a complete map of the station is saved. The order sausage was also incorrect because the speech recognition system had categorized the word as thirst. As a consequence, a bottle of water was taken from the kitchen. My speech processing system is still error prone with some words. Software updates continue to improve my system. |
| human-like | Good day, I am Ali the new robot in the facility since one week. I try to support and relieve you in your daily work. For example, you can use me as calling system. Thereby I take requests and execute them independently or forward them to you. Recently, the following mishaps unfortunately happened to me: A patient had asked me for a piece of bacon, so I went to the kitchen. However, since I have such a hard time remembering directions, I got lost on the way back to the patient. It took me a few more days to find my way around the facility. In the meantime, I already know my way around. By the way, I didn’t have any bacon with me then either, but a piece of pie. Instead of bacon, I heard pastry. Due to the many new impressions at the beginning, I was mentally distracted and had probably misunderstood. However, I’m always trying to improve |
| Failure Justification | |||
|---|---|---|---|
| Factors | Gender | Technical | Human |
| attitude to use | female | 3.68 (0.91) | 3.71 (0.94) |
| male | 4.30 (0.87) | 3.67 (1.32) | |
| failure forgiveness | female | 3.79 (0.98) | 3.86 (1.11) |
| male | 4.03 (1.21) | 3.75 (1.35) | |
| reliability | female | 3.23 (0.83) | 3.31 (0.95) |
| male | 3.39 (1.02) | 3.23 (1.09) | |
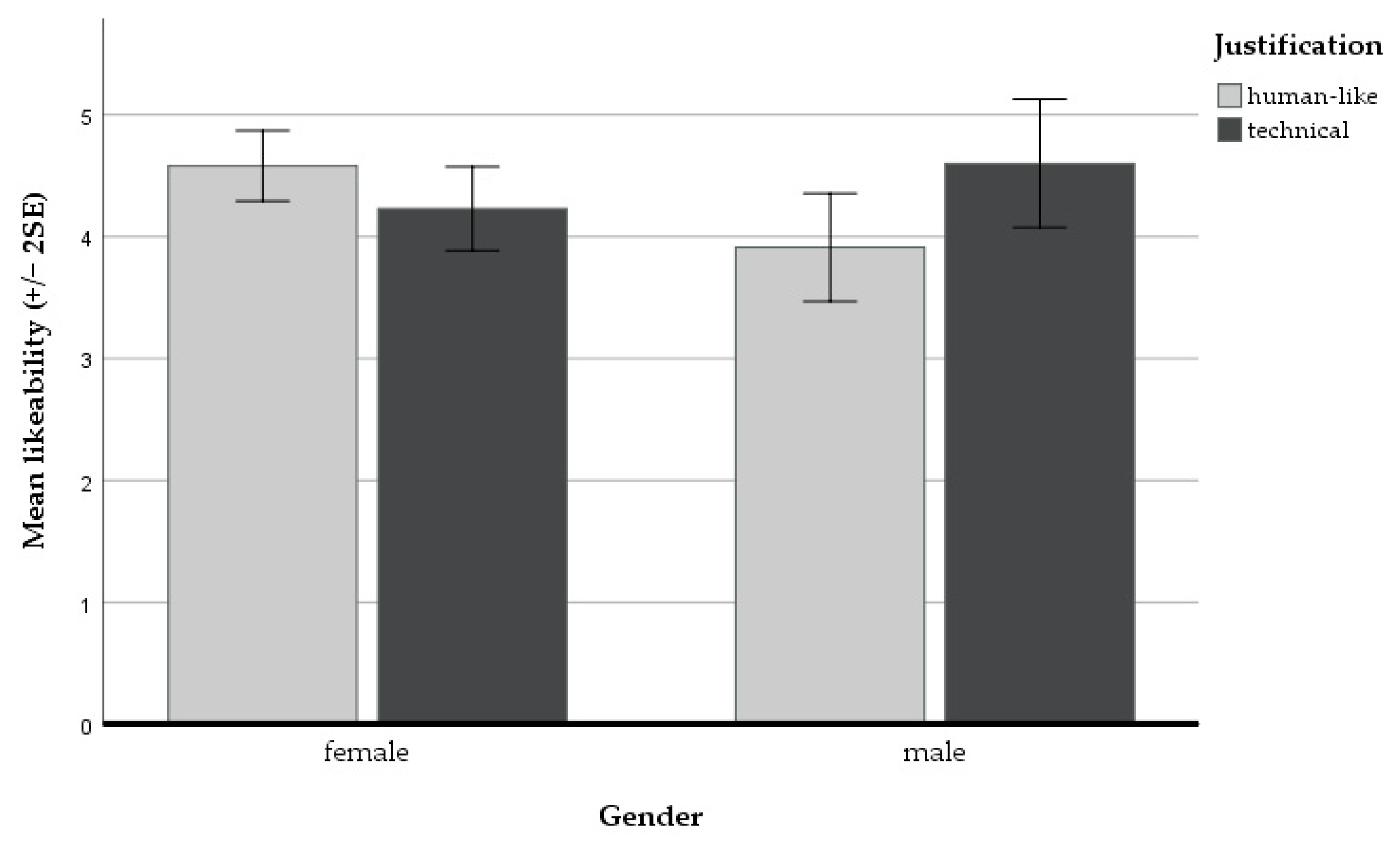
| likeability | female | 4.23 (0.79) | 4.58 (0.44) |
| male | 4.60 (0.78) | 3.91 (1.03) | |
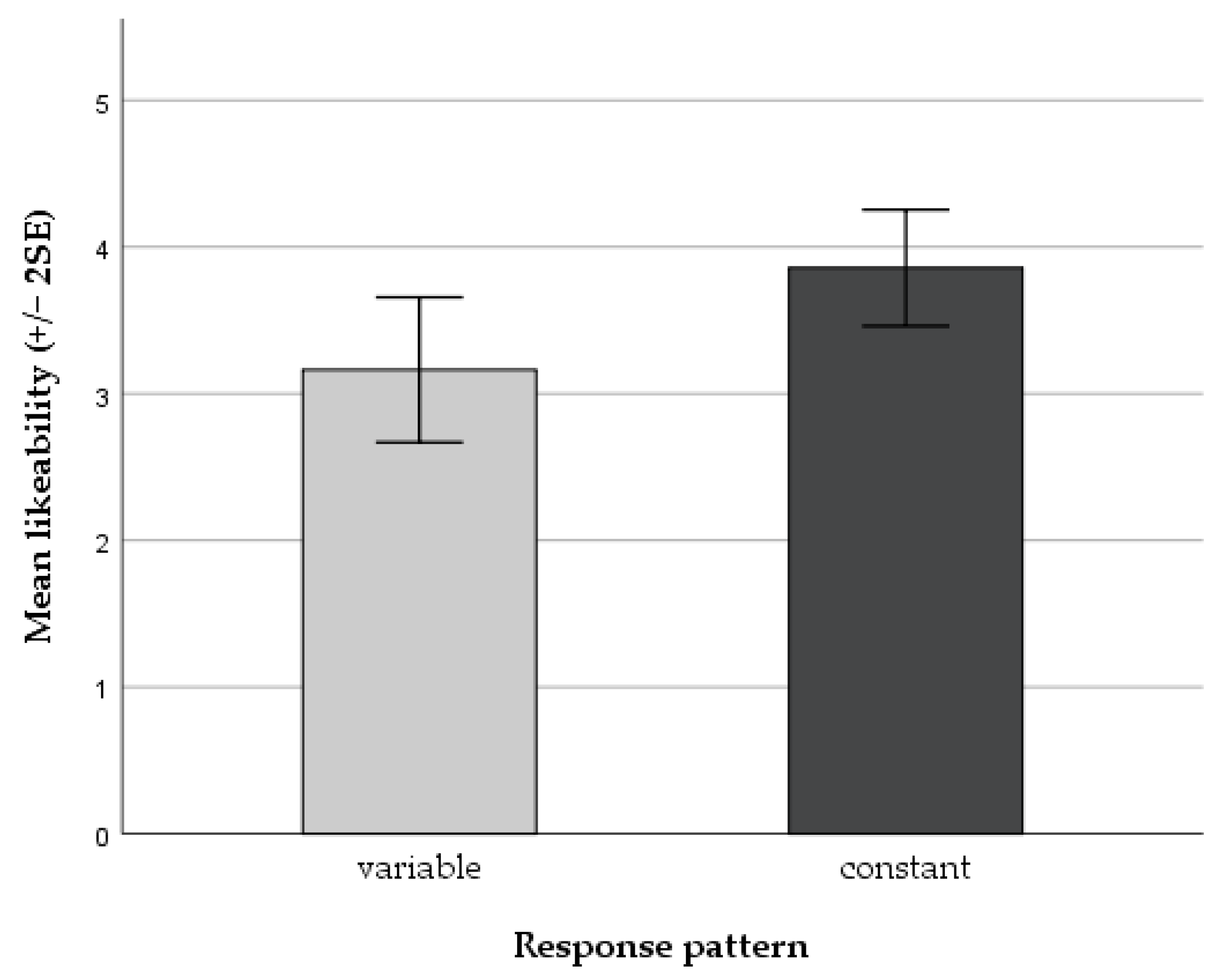
| Response Pattern | Stop Criteria | No. of Participants (%) | Likeability (SD) |
|---|---|---|---|
| variable (N = 16) | max. repetition | 7 (44%) | 3.17 (1.17) |
| self-determination | 9 (56%) | 3.16 (0.89) | |
| constant (N = 14) | max. repetition | 4 (29%) | 3.90 (0.81) |
| self-determination | 10 (71%) | 3.84 (0.76) |
| Response Pattern | ||
|---|---|---|
| Attribution to | Variable | Constant |
| robot | 8 (50%) | 8 (57%) |
| participant | 0 (0%) | 1 (7%) |
| both | 8 (50%) | 5 (36%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Klüber, K.; Onnasch, L. When Robots Fail—A VR Investigation on Caregivers’ Tolerance towards Communication and Processing Failures. Robotics 2022, 11, 106. https://doi.org/10.3390/robotics11050106
Klüber K, Onnasch L. When Robots Fail—A VR Investigation on Caregivers’ Tolerance towards Communication and Processing Failures. Robotics. 2022; 11(5):106. https://doi.org/10.3390/robotics11050106
Chicago/Turabian StyleKlüber, Kim, and Linda Onnasch. 2022. "When Robots Fail—A VR Investigation on Caregivers’ Tolerance towards Communication and Processing Failures" Robotics 11, no. 5: 106. https://doi.org/10.3390/robotics11050106
APA StyleKlüber, K., & Onnasch, L. (2022). When Robots Fail—A VR Investigation on Caregivers’ Tolerance towards Communication and Processing Failures. Robotics, 11(5), 106. https://doi.org/10.3390/robotics11050106