
Improving the Accuracy of a Robot by Using Neural Networks (Neural Compensators and Nonlinear Dynamics)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
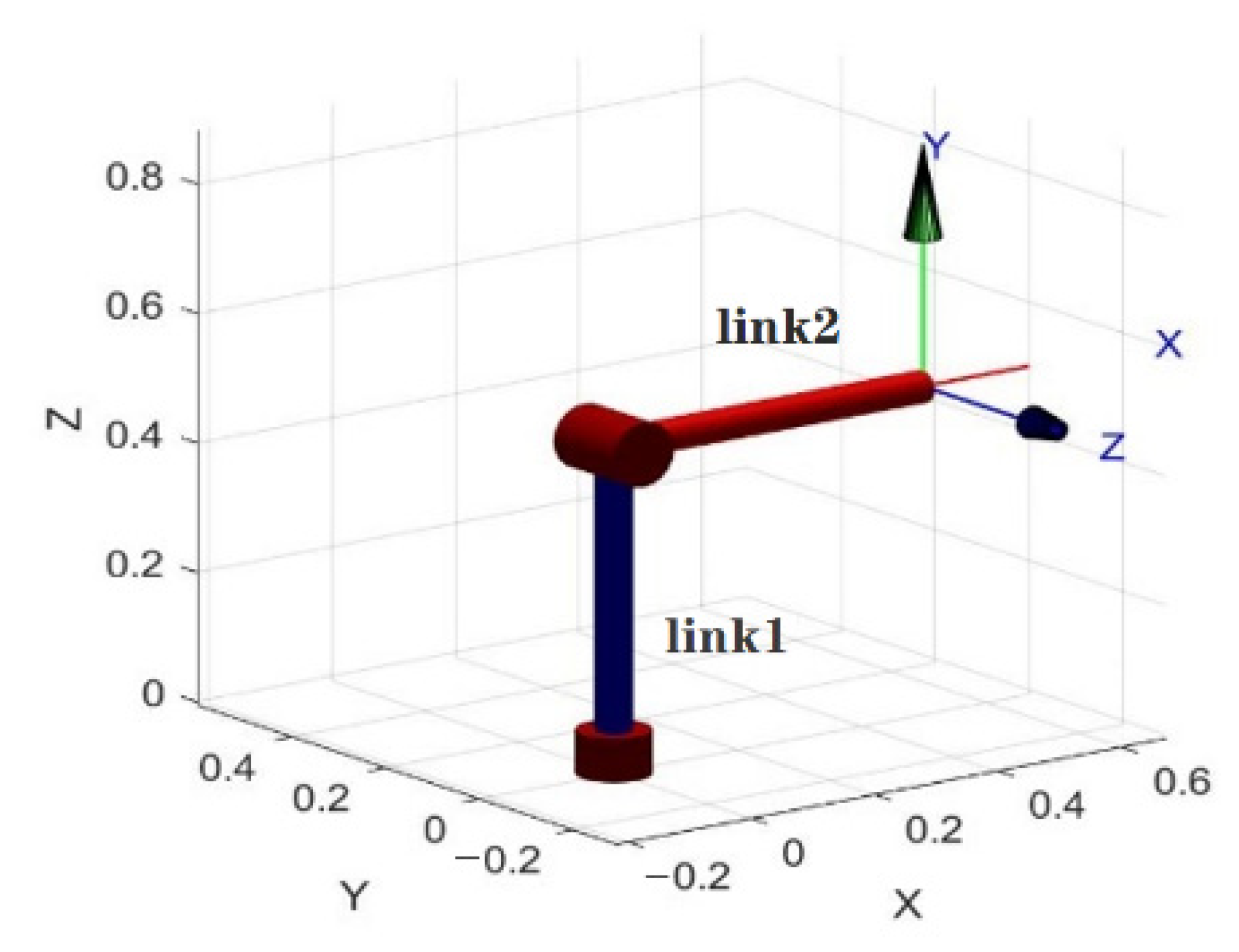
2. Materials and Methods
3. Training of Nonlinear Neural Network Compensators
3.1. Designing Compensators with Elman Neural Networks
- (1)
- oblique symmetry characteristics of the manipulator;
- (2)
- ;
- (3)
- .
- At the initial moment of time t = 0, all neurons of the hidden layer are set to the zero position—the initial value is zero.
- The input value is fed to the network, where it is directly distributed.
- Set t = t + 1 and make the transition to step 2; neural network training is performed until the total root mean-square error of the network takes the smallest value.
3.2. Designing a Compensator with an Adaptive Radial Basis Function Neural Network for Local Model Approximation
- (1)
- From and , from the lemma , e∈L2n, e is continuous; then, when ,
- (2)
- From , we get . Therefore, when , there are,.
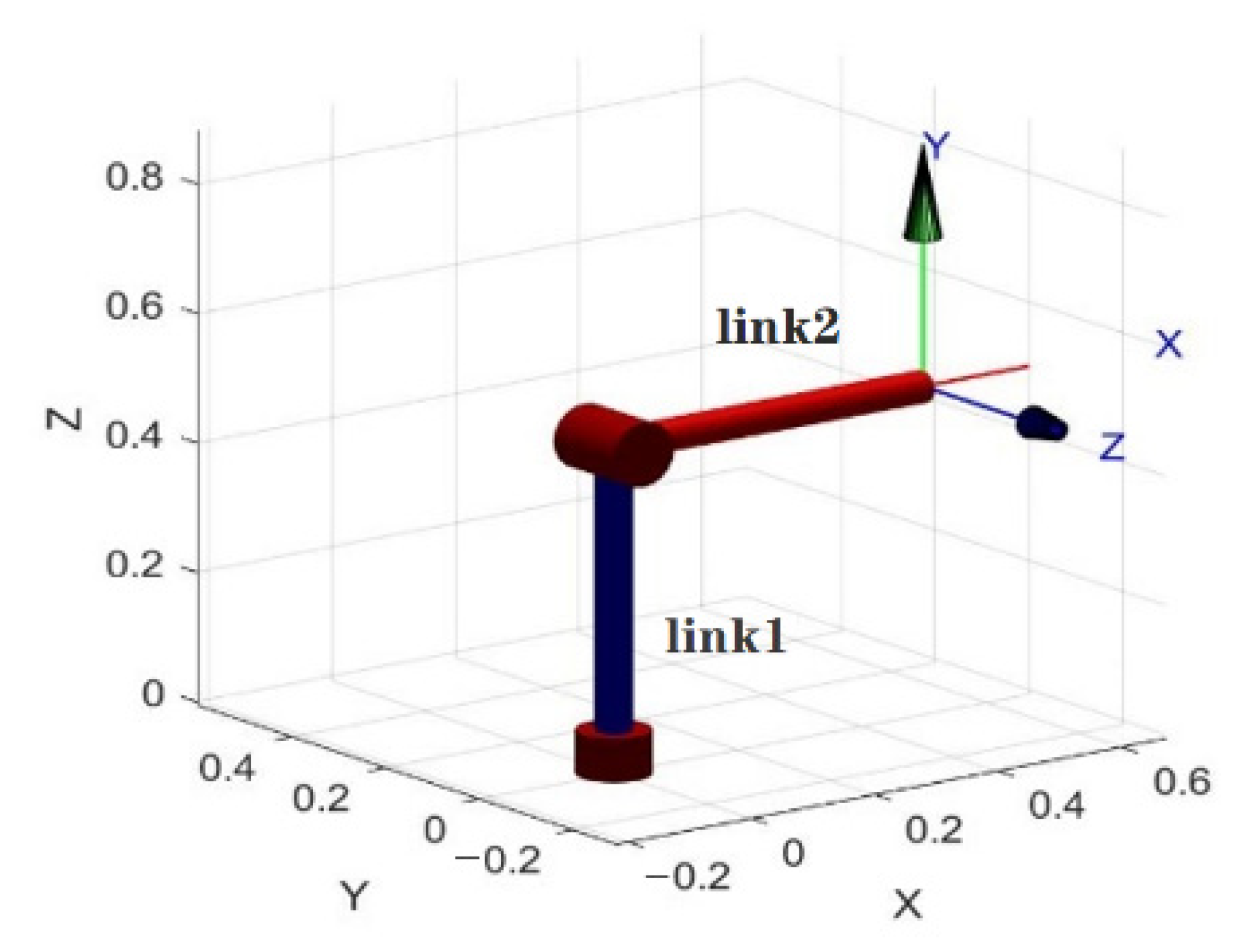
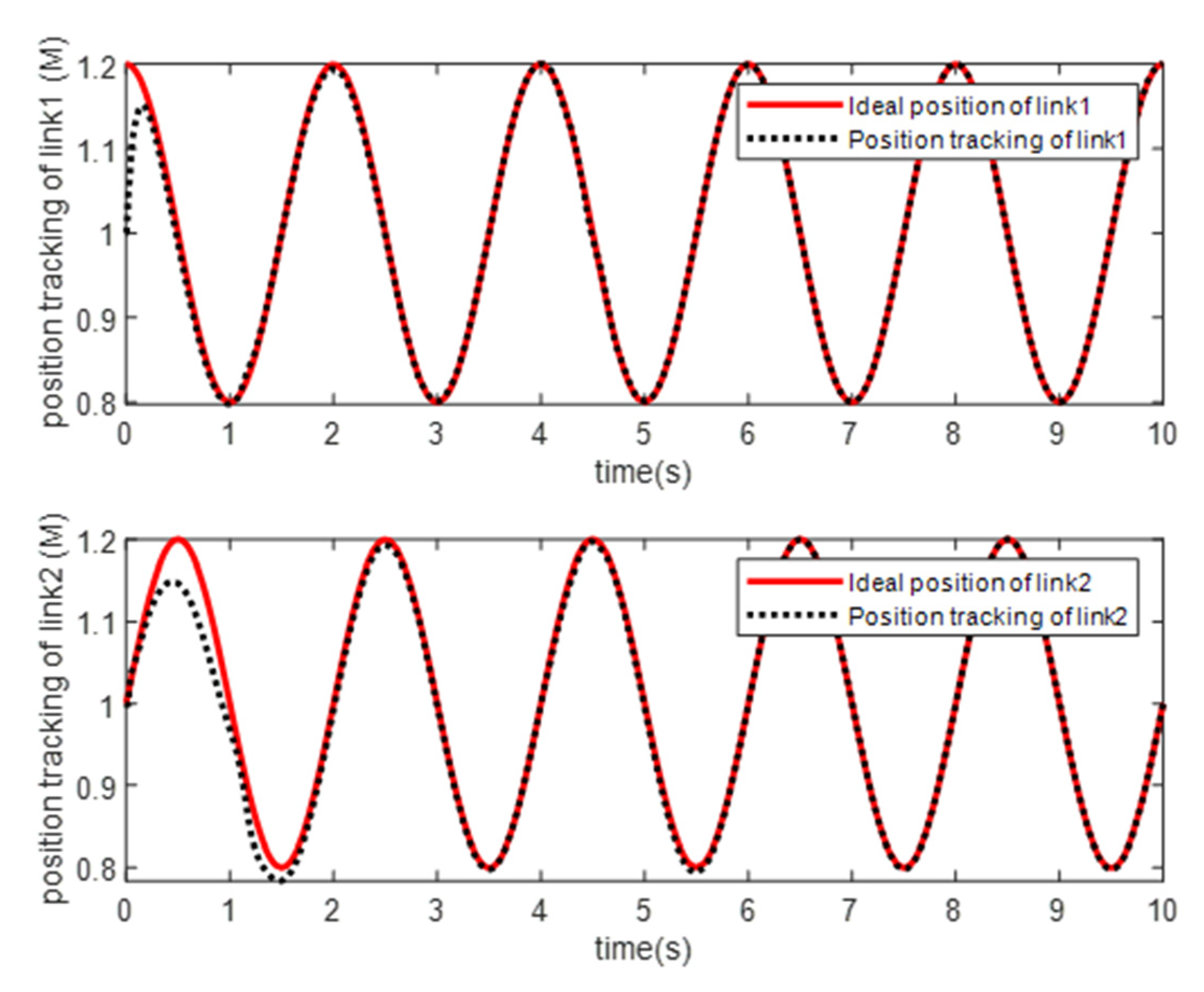
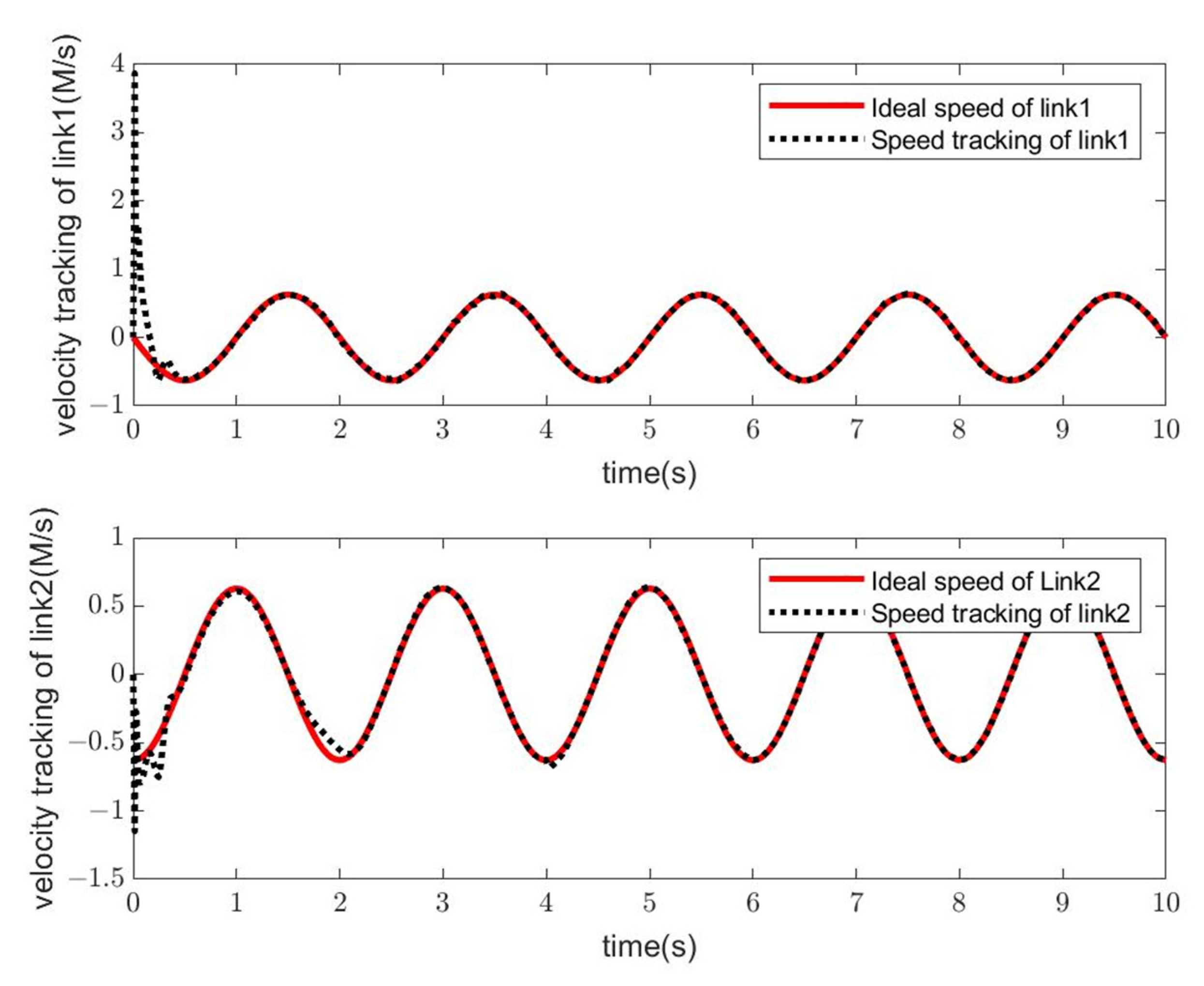
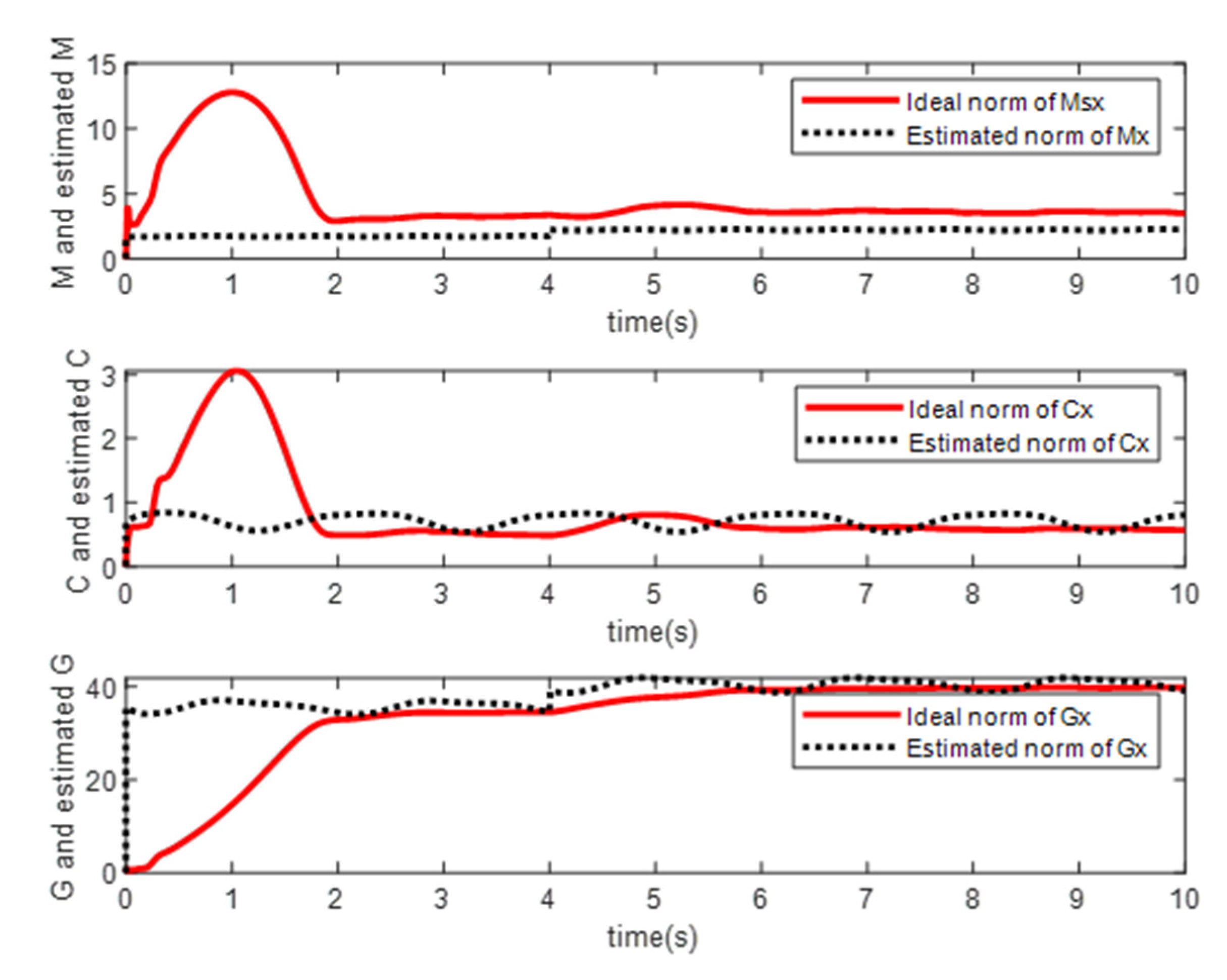
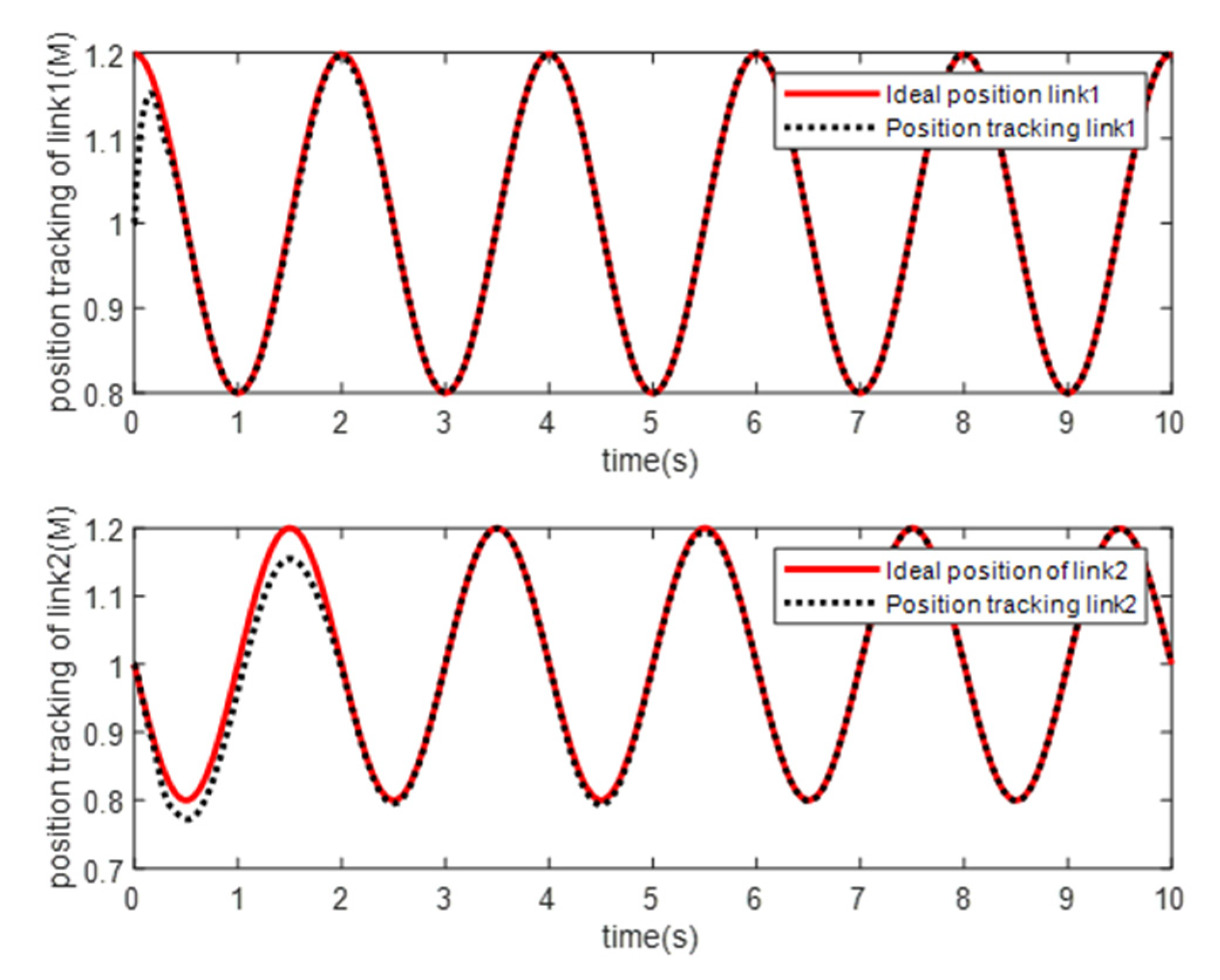
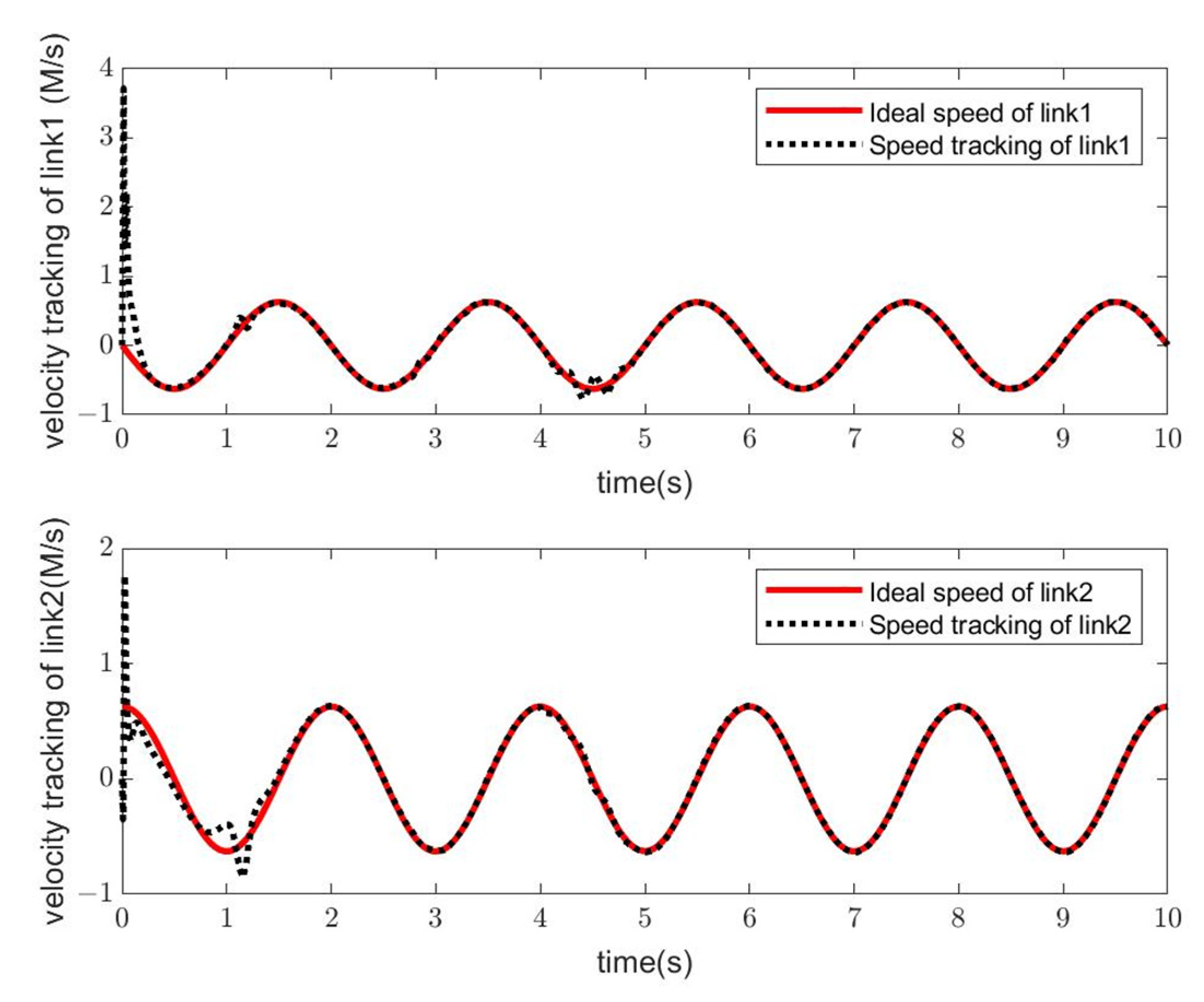
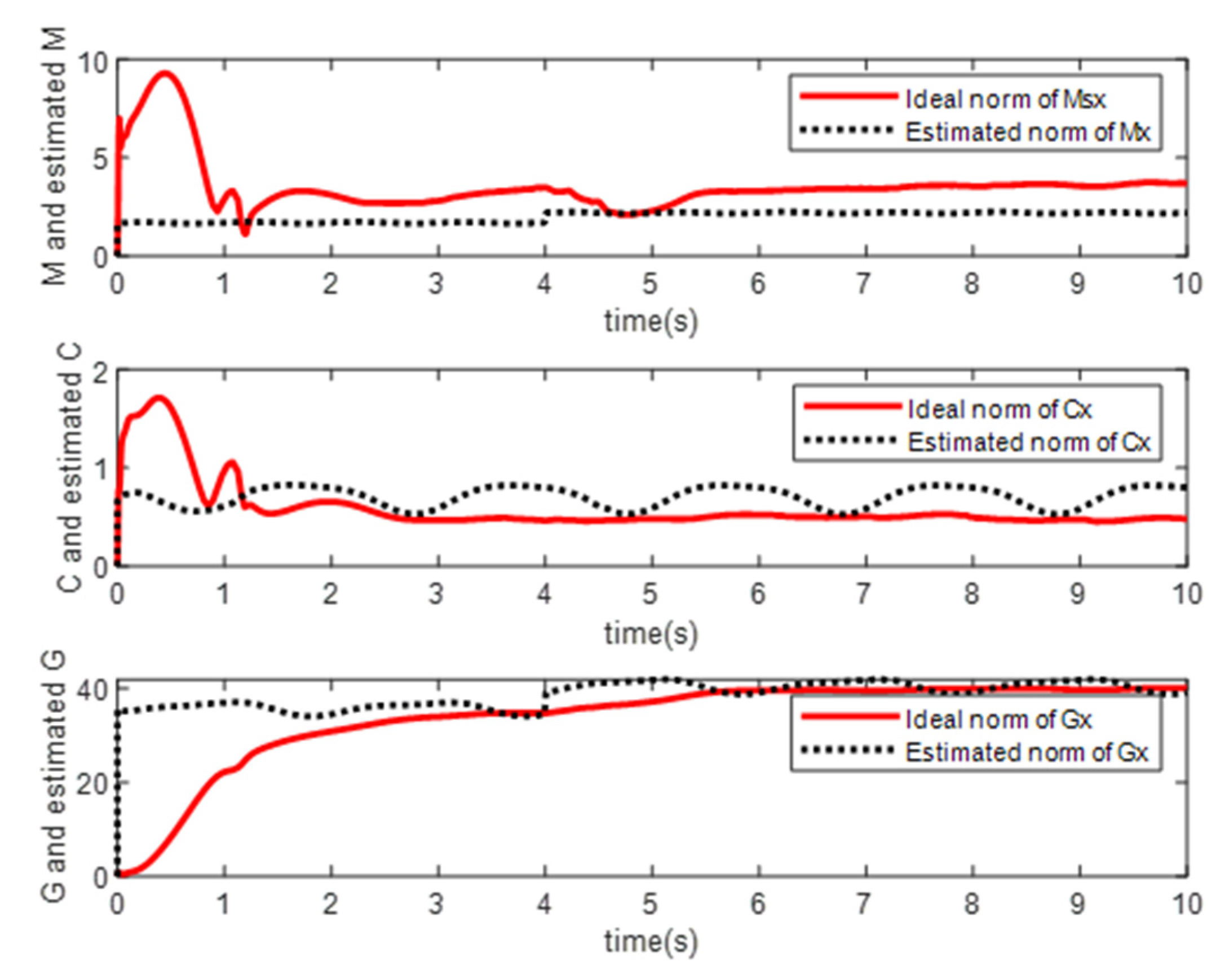
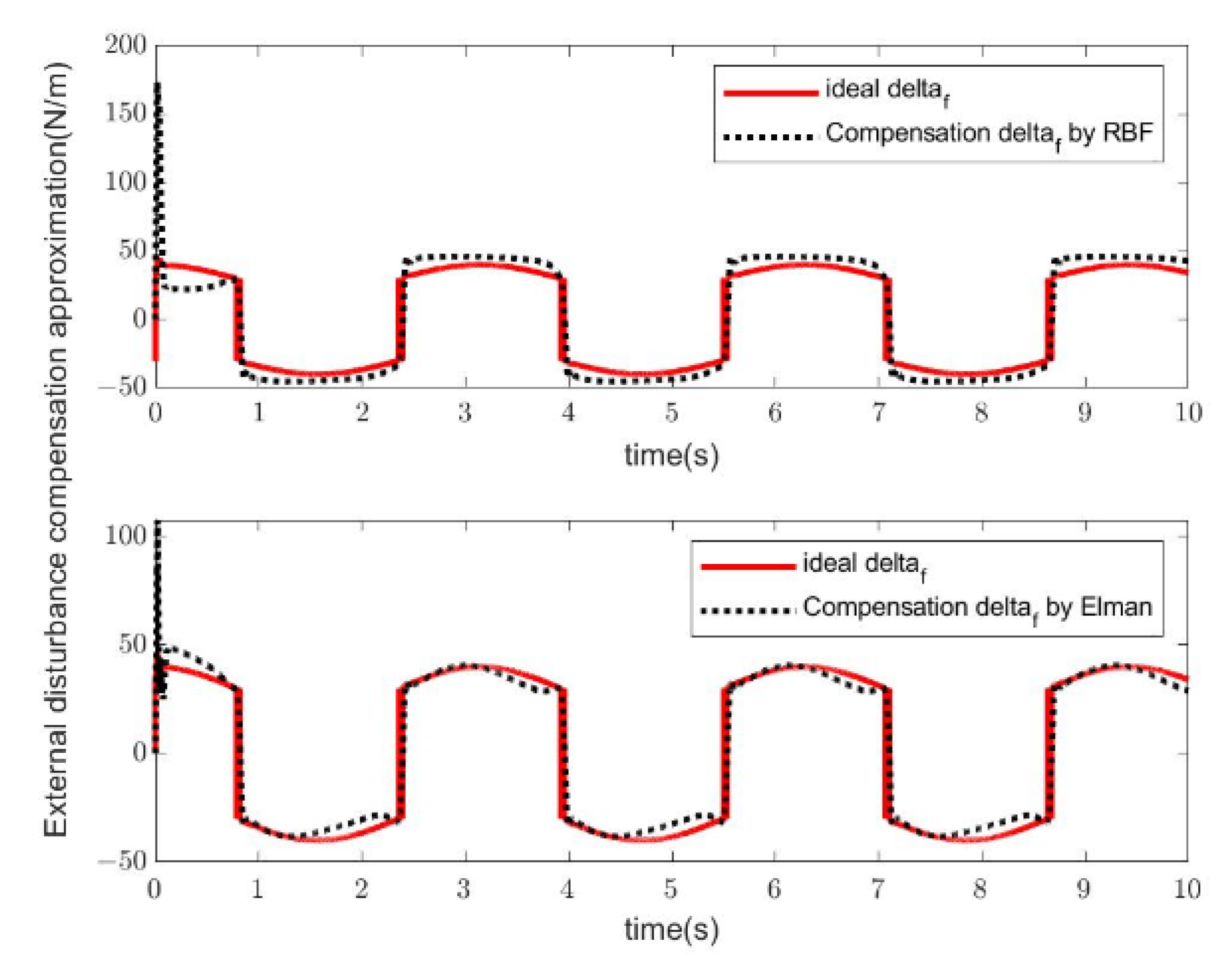
4. Simulation Study
- (1)
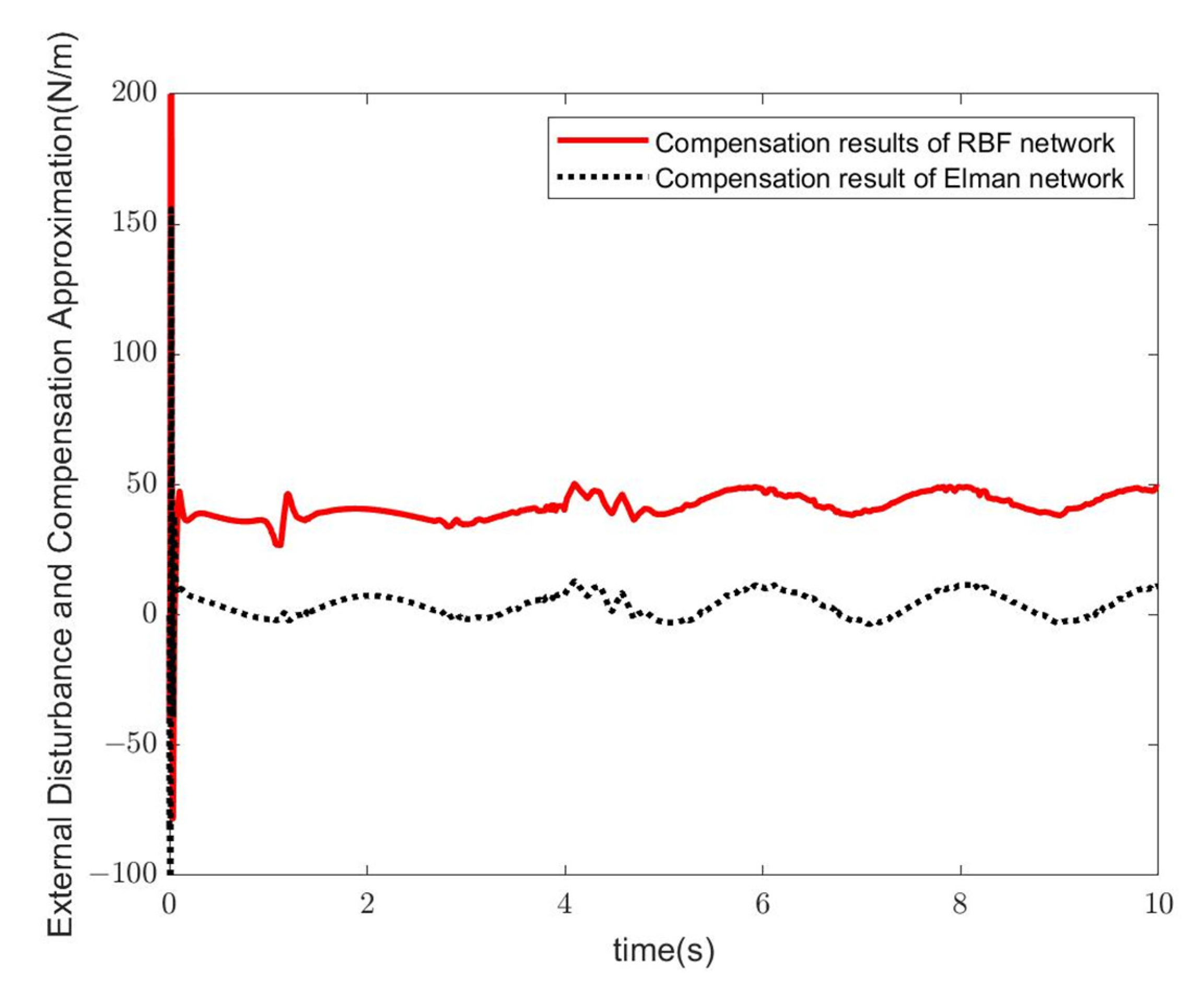
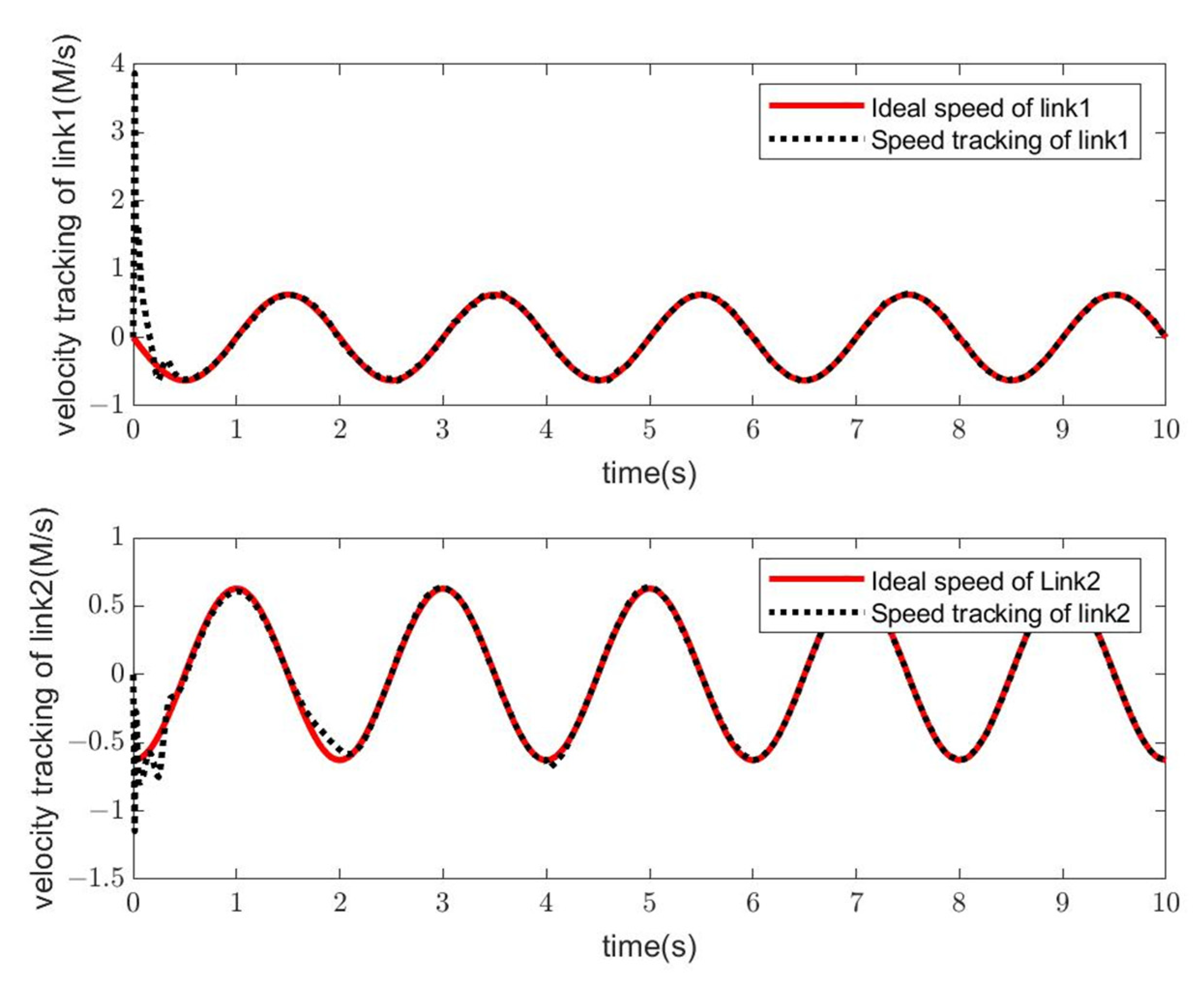
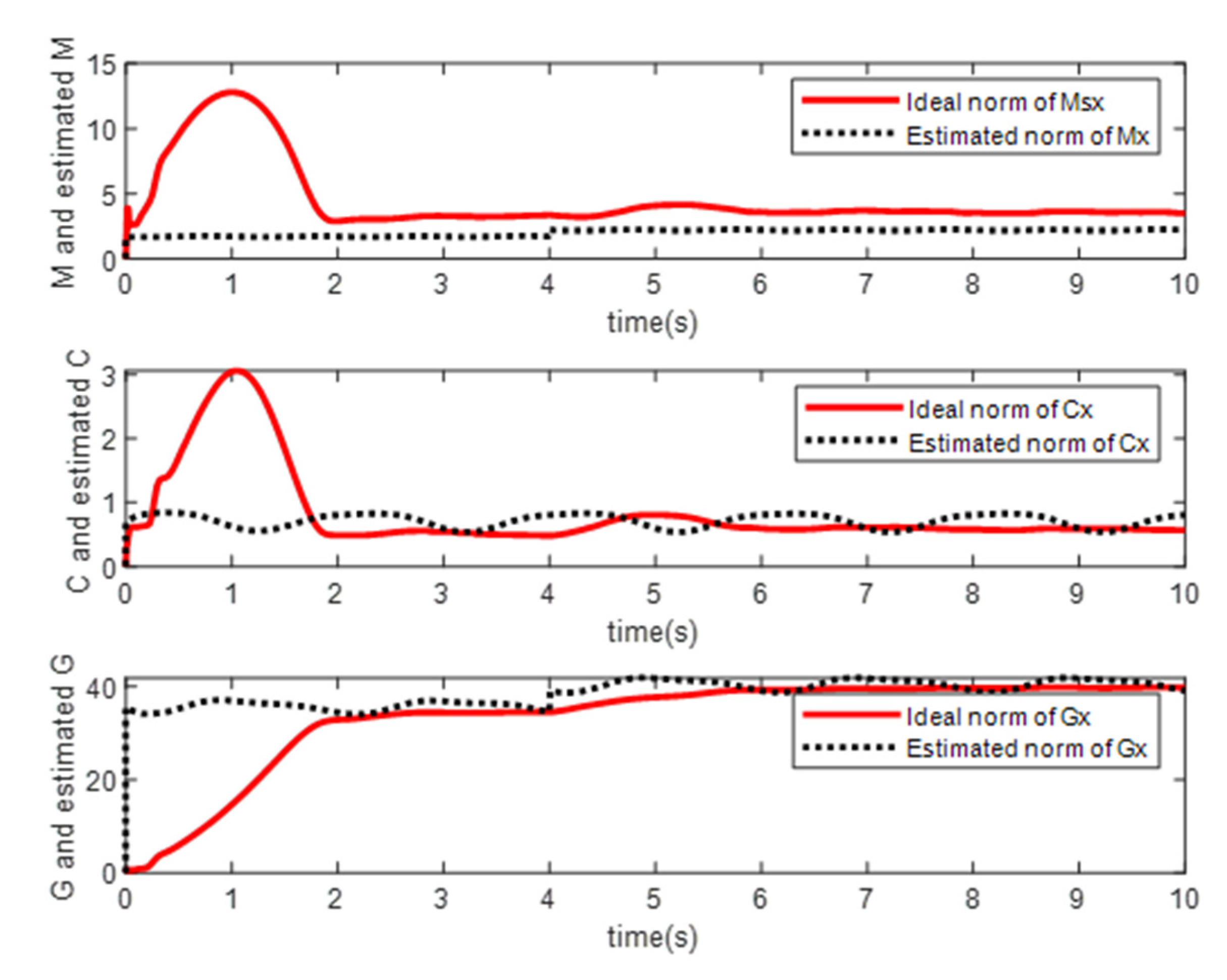
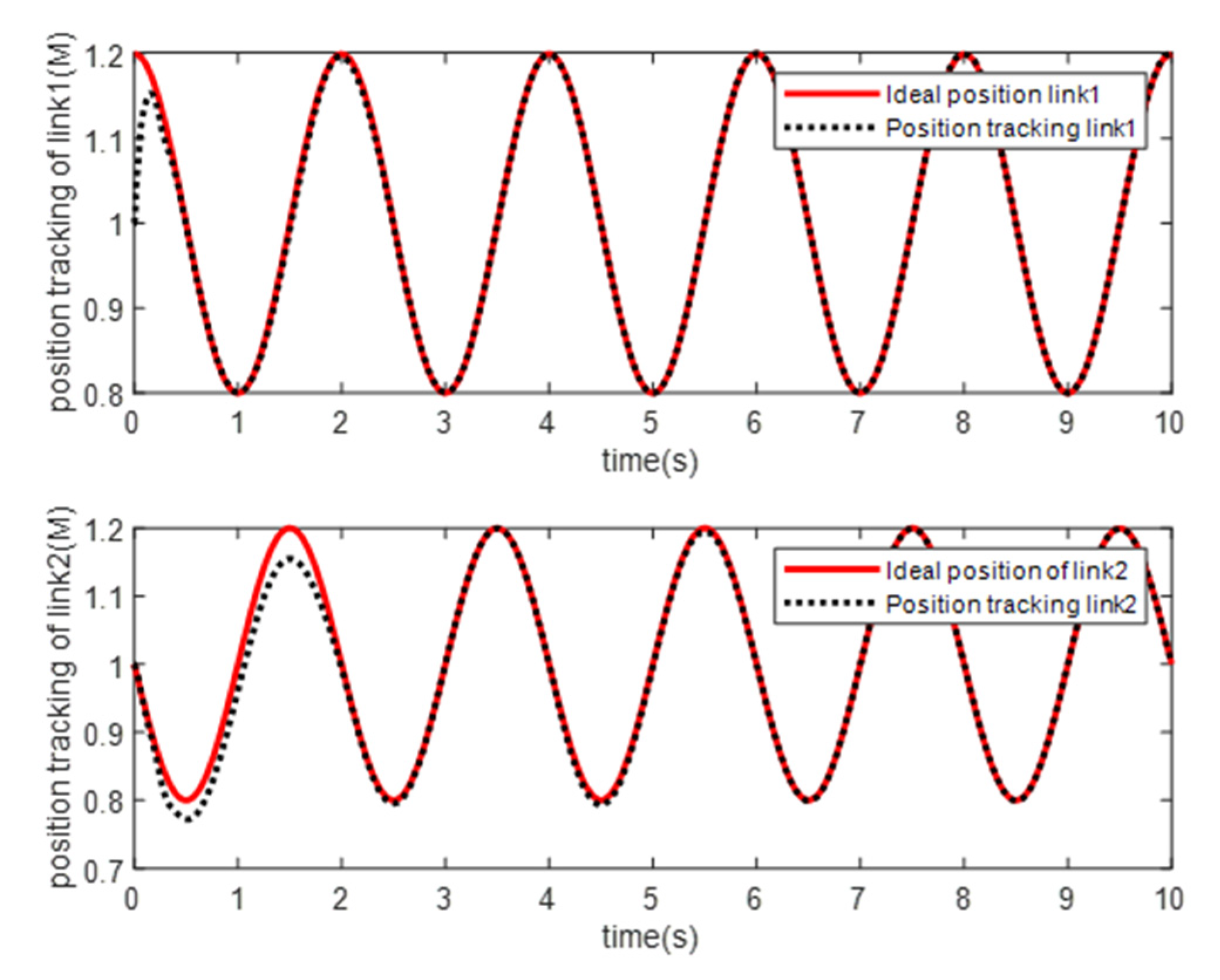
- Simulation Modeling of Elman Neural Networks
- (2)
- Simulation Modeling of RBF Neural Networks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Duka, A.V. Neural Network based Inverse Kinematics Solution for Trajectory Tracking of a Robotic Arm. Procedia Technol. 2014, 12, 20–27. [Google Scholar] [CrossRef]
- Arseniev, D.G.; Overmeyer, L.; Kälviäinen, H.; Katalinić, B. Cyber-Physical Systems and Control; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Islam, S.; Liu, X.P. Robust Sliding Mode Control for Robot Manipulators. IEEE Trans. Ind. Electron. 2011, 58, 2444–2453. [Google Scholar] [CrossRef]
- Yazdanpanah, M.J.; KarimianKhosrowshahi, G. Robust Control of Mobile Robots Using the Computed Torque Plus H∞ Compensation Method. Available online: https://www.sciencegate.app/document/10.1109/cdc.2003.1273069 (accessed on 29 June 2022).
- Rostova, E.N.; Rostov, N.V.; Yan, Y.Z. Neural network compensation of dynamic errors in a position control system of a robot manipulator. Comput. Telecommun. Control. 2020, 64, 53–64. [Google Scholar] [CrossRef]
- Yesildirak, A.; Lewis, F.W.; Yesildirak, S.J. Neural Network Control of Robot Manipulators and Non-Linear Systems; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Kara, K.; Missoum, T.E.; Hemsas, K.E.; Hadjili, M.L. Control of a robotic manipulator using neural network based predictive control. 2010. In Proceedings of the 17th IEEE International Conference on Electronics, Circuits and Systems, Athens, Greece, 12–15 December 2010; pp. 1104–1107. [Google Scholar] [CrossRef]
- Seshagiri, S.; Khalil, H. Output Feedback Control of Nonlinear Systems Using RBF Neural Networks. IEEE Trans. Neural Netw. 2000, 11, 69–79. [Google Scholar] [CrossRef] [PubMed]
- Tetko, V.I.; Kůrková, V.; Karpov, P.; Theis, F. Artificial Neural Networks and Machine Learning–ICANN 2019: Deep Learning: 28th International Conference on Artificial Neural Networks, Munich, Germany, September 17–19, 2019, Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Dou, M.; Qin, C.; Li, G.; Wang, C. Research on Calculation Method of Free flow Discharge Based on Artificial Neural Network and Regression Analysis. Flow Meas. Instrum. 2020, 72, 101707. [Google Scholar] [CrossRef]
- Ren, G.; Cao, Y.; Wen, S.; Huang, T.; Zeng, Z. A Modified Elman Neural Network with a New Learning Rate Scheme. Neurocomputing 2018, 286, 11–18. [Google Scholar] [CrossRef]
- Design and Implementation of a RoBO-2L MATLAB Toolbox for a Motion Control of a Robotic Manipulator. Available online: https://ieeexplore.ieee.org/document/7473678/ (accessed on 30 June 2022).
- Cheng, Y.-C.; Qi, W.-M.; Cai, W.-Y. Dynamic properties of Elman and modified Elman neural network. In Proceedings of the International Conference on Machine Learning and Cybernetics, Beijing, China, 4–5 November 2002; pp. 637–640. [Google Scholar] [CrossRef]
- Beheim, L.; Zitouni, A.; Belloir, F. New RBF neural network classifier with optimized hidden neurons number. WSEAS Trans. Syst. 2004, 2, 467–472. [Google Scholar]
- Song, Q.; Meng, G.J.; Yang, L.; Du, D.Q.; Mao, X.F. Comparison between BP and RBF Neural Network Pattern Recognition Process Applied in the Droplet Analyzer. Appl. Mech. Mater. 2014, 543–547, 2333–2336. [Google Scholar] [CrossRef]
- Luo, B.; Liu, D.; Yang, X.; Ma, H. H ∞ Control Synthesis for Linear Parabolic PDE Systems with Model-Free Policy Iteration. In Advances in Neural Networks—ISNN 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 81–90. [Google Scholar] [CrossRef]
- Ge, S.S.; Hang, C.C.; Woon, L.C. Adaptive neural network control of robot manipulators in task space. IEEE Trans. Ind. Electron. 1997, 44, 746–752. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Z.; Xie, K.; Zhang, Y.; Chen, C.L.P. Adaptive neural control of MIMO stochastic systems with unknown high-frequency gains. Inf. Sci. 2017, 418, 513–530. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, J.; Wang, H.; Pan, Z.; Han, S. Model-free based adaptive RBF neural network control for a rehabilitation exoskeleton. In Proceedings of the 2019 Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 4208–4213. [Google Scholar] [CrossRef]
- Wang, M.; Yang, A. Dynamic Learning from Adaptive Neural Control of Robot Manipulators with Prescribed Performance. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2244–2255. [Google Scholar] [CrossRef]
- Tran, M.-D.; Kang, H.-J. Nonsingular Terminal Sliding Mode Control of Uncertain Second-Order Nonlinear Systems. Math. Probl. Eng. 2015, 2015, e181737. [Google Scholar] [CrossRef]
- Ortega, R.; Spong, M.W. Adaptive motion control of rigid robots: A tutorial. In Proceedings of the 27th IEEE Conference on Decision and Control, Austin, TX, USA, 7–9 December 1988; pp. 1575–1584. [Google Scholar] [CrossRef]
- Zabikhifar, S.; Markasi, A.; Yuschenko, A. Two link manipulator control using fuzzy sliding mode approach. Her. Bauman Mosc. State Tech. Univ. Ser. Instrum. Eng. 2015, 6, 30–45. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Z.; Klochkov, Y.; Xi, L. Improving the Accuracy of a Robot by Using Neural Networks (Neural Compensators and Nonlinear Dynamics). Robotics 2022, 11, 83. https://doi.org/10.3390/robotics11040083
Yan Z, Klochkov Y, Xi L. Improving the Accuracy of a Robot by Using Neural Networks (Neural Compensators and Nonlinear Dynamics). Robotics. 2022; 11(4):83. https://doi.org/10.3390/robotics11040083
Chicago/Turabian StyleYan, Zhengjie, Yury Klochkov, and Lin Xi. 2022. "Improving the Accuracy of a Robot by Using Neural Networks (Neural Compensators and Nonlinear Dynamics)" Robotics 11, no. 4: 83. https://doi.org/10.3390/robotics11040083
APA StyleYan, Z., Klochkov, Y., & Xi, L. (2022). Improving the Accuracy of a Robot by Using Neural Networks (Neural Compensators and Nonlinear Dynamics). Robotics, 11(4), 83. https://doi.org/10.3390/robotics11040083