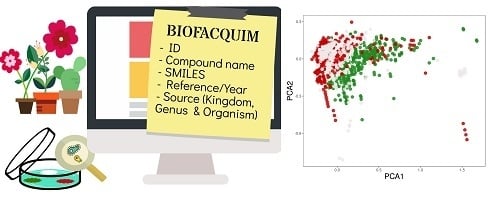
BIOFACQUIM: A Mexican Compound Database of Natural Products

 , and
, and 
Abstract
:
1. Introduction
2. Materials and Methods
2.1. BIOFACQUIM Database
2.2. Reference Data Sets
2.3. Molecular Properties of Pharmaceutical Relevance
2.4. Scaffold Content
2.5. Visual Representation of Chemical Space
2.6. Global Diversity: Consensus Diversity Analysis
3. Results and Discussion
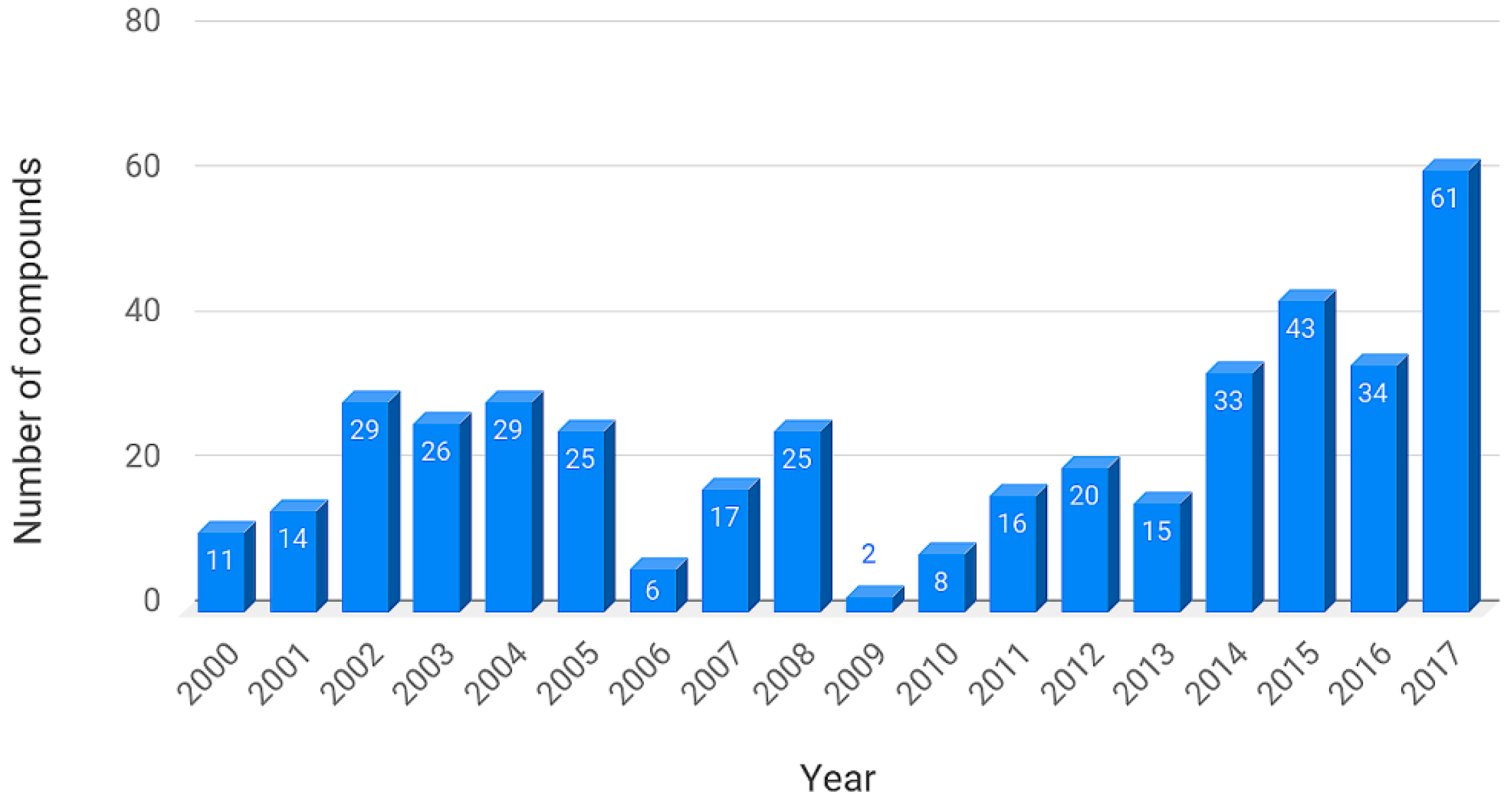
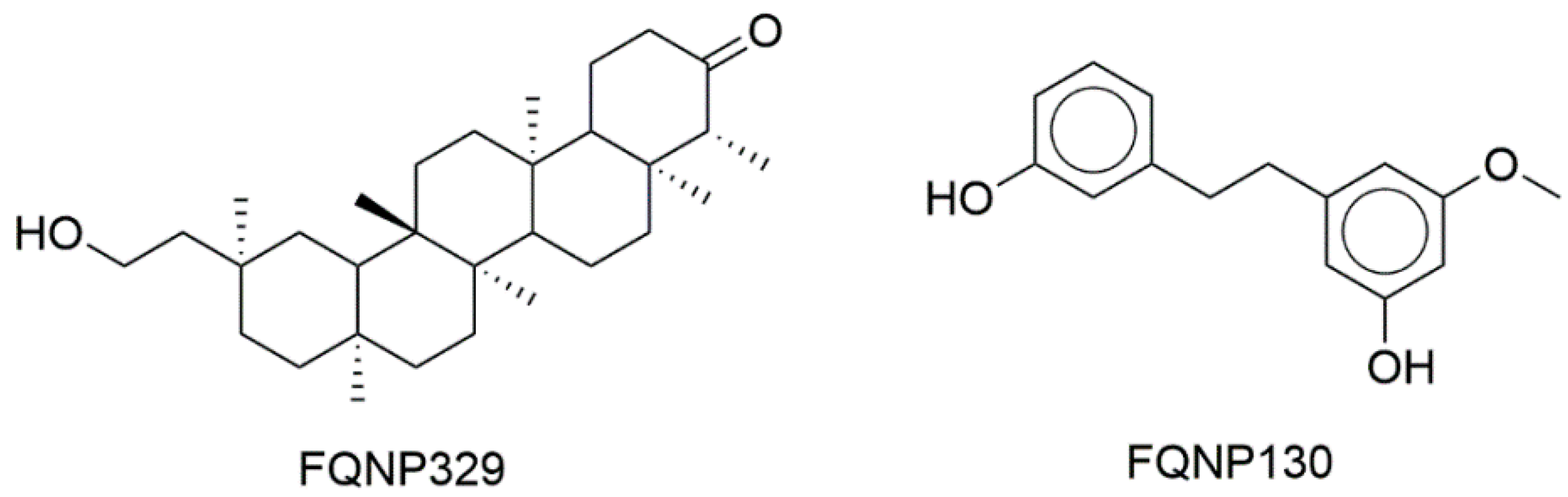
3.1. BIOFACQUIM Database
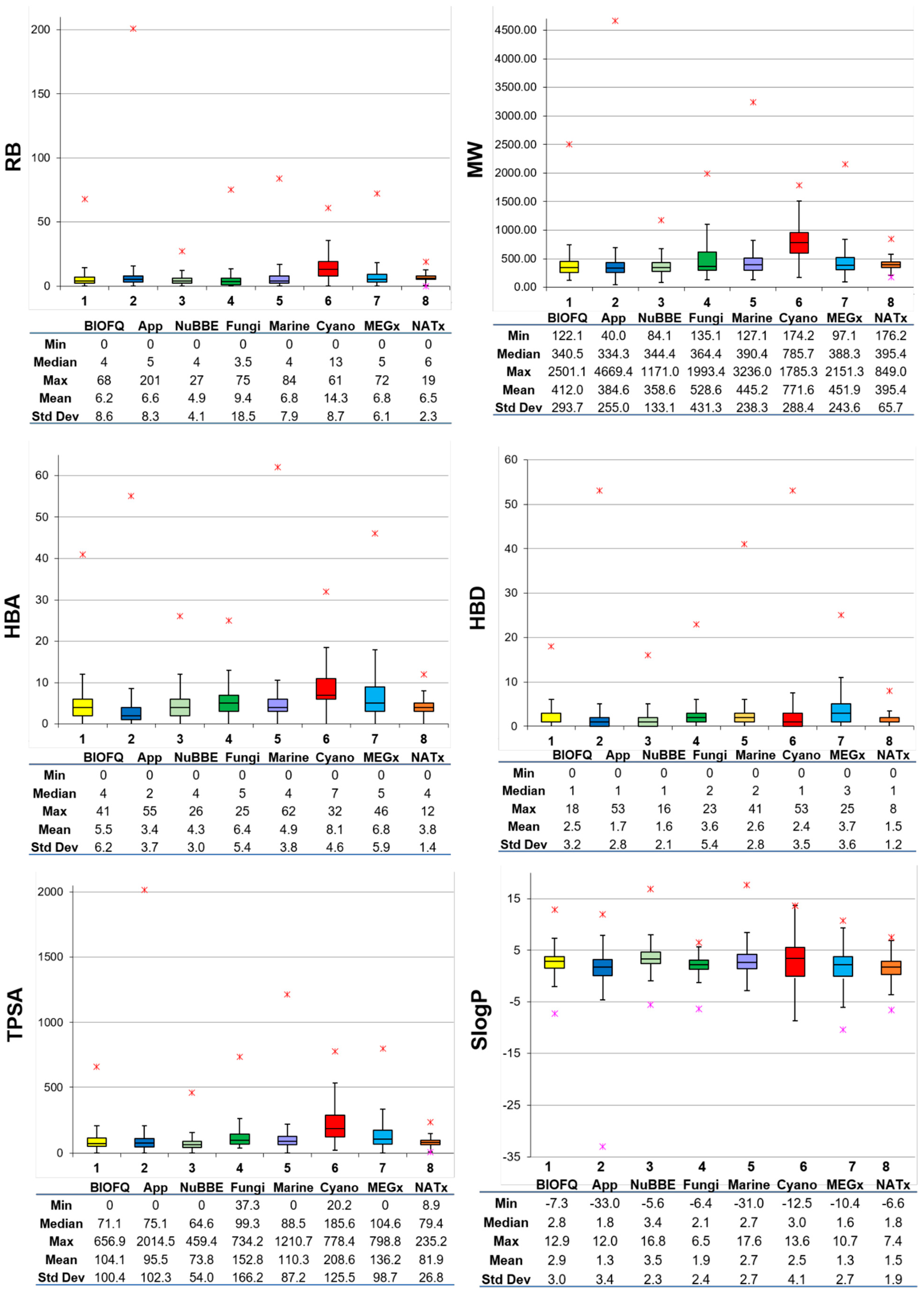
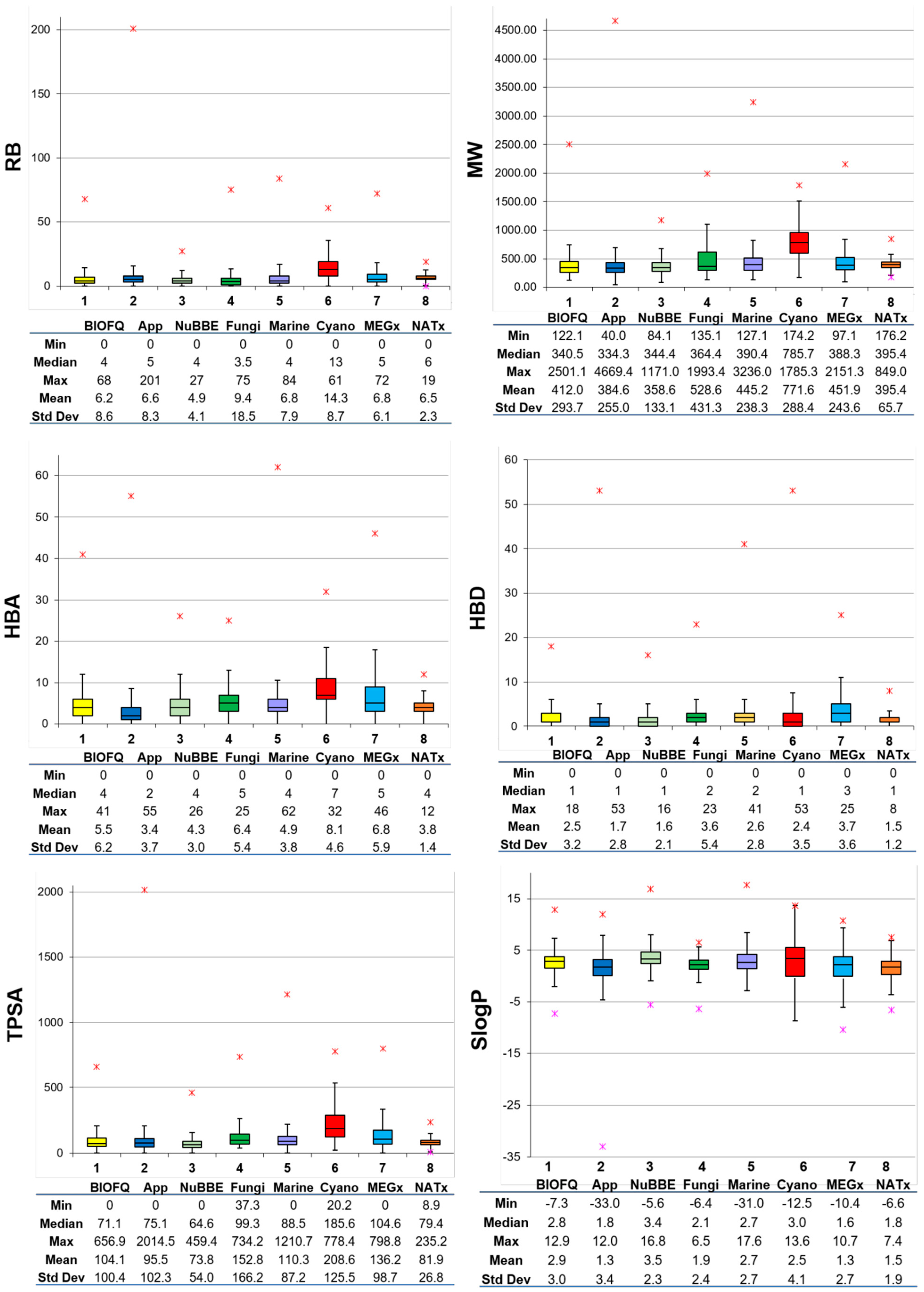
3.2. Molecular Properties
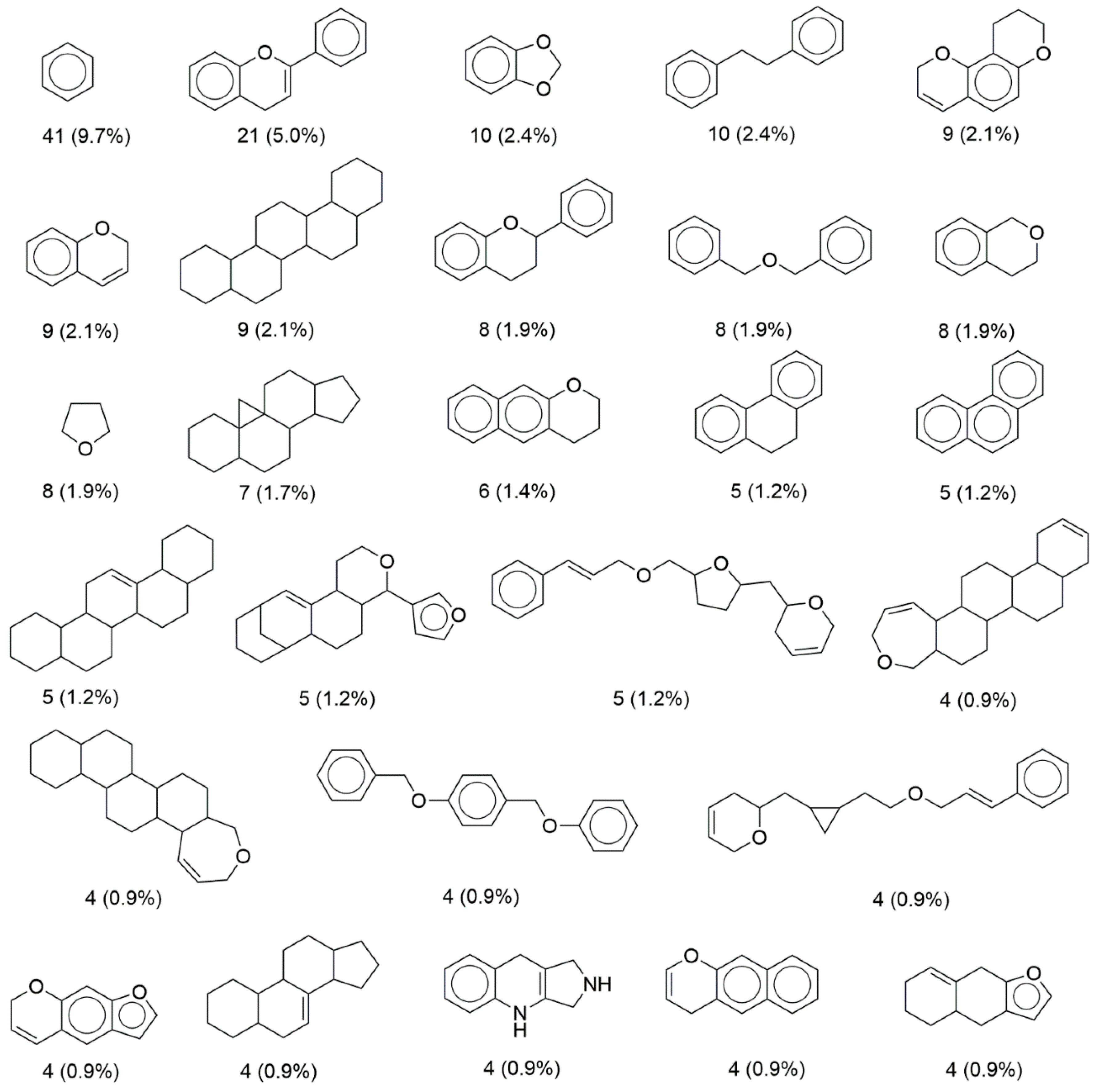
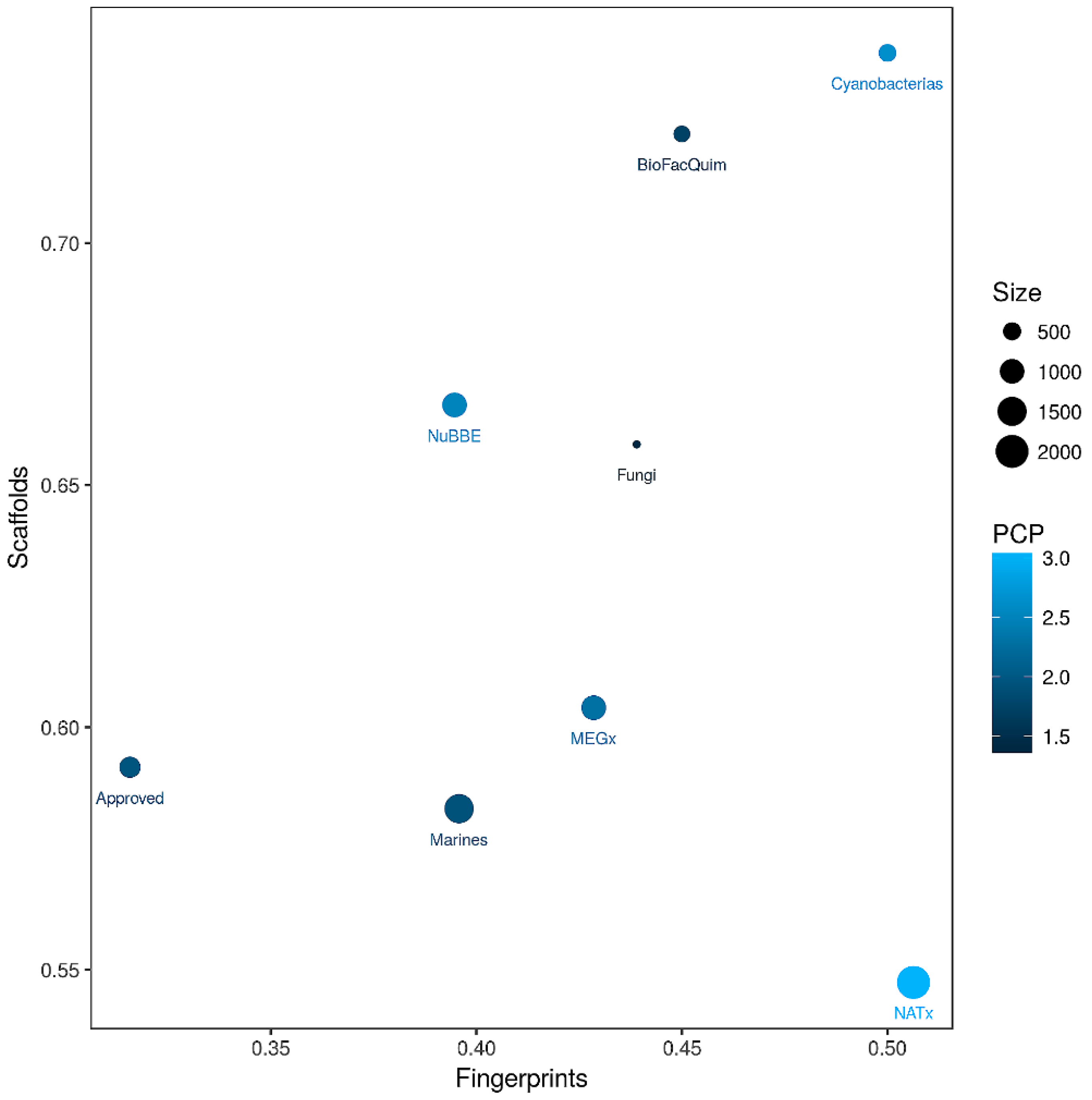
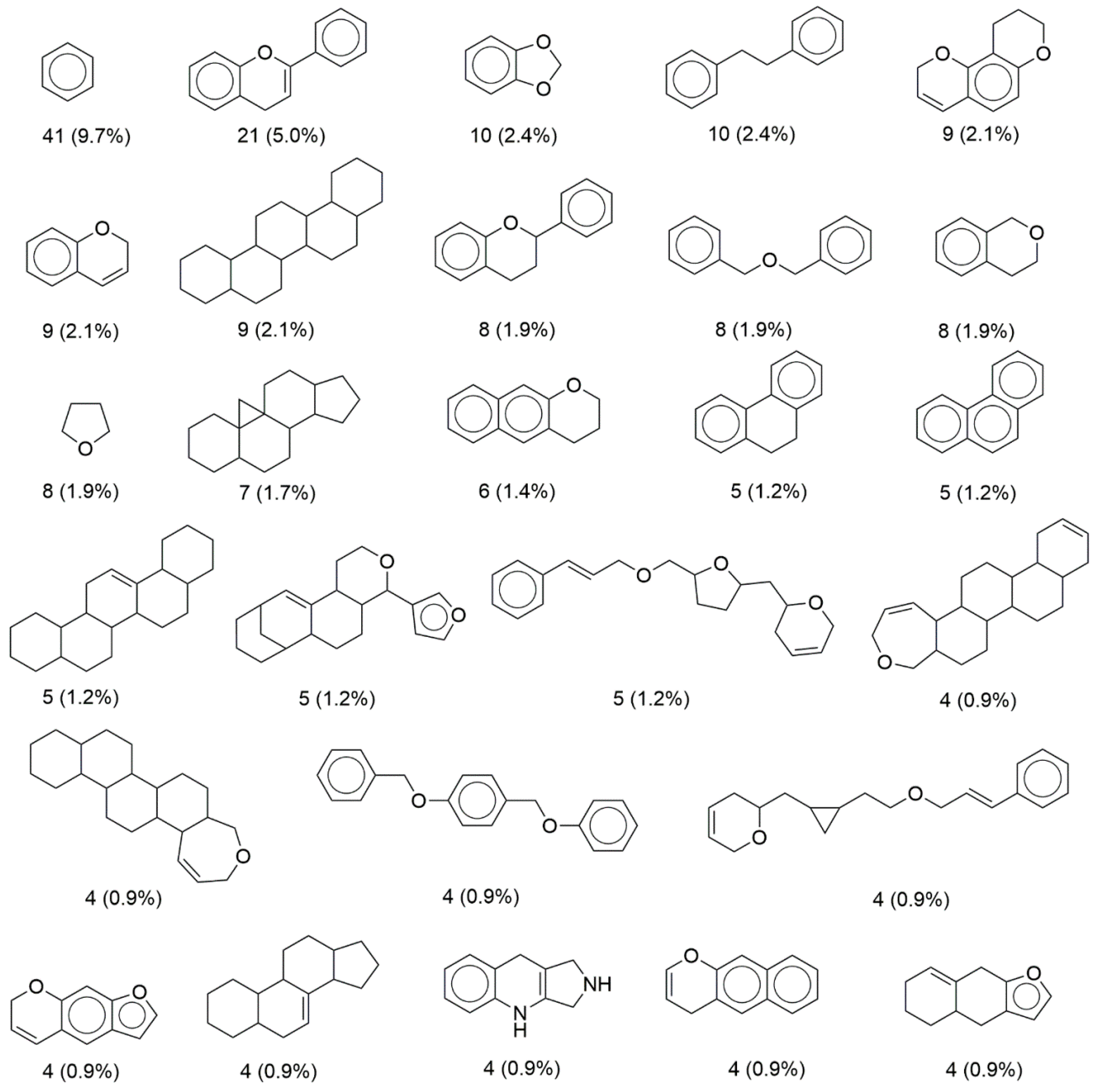
3.3. Scaffold Content
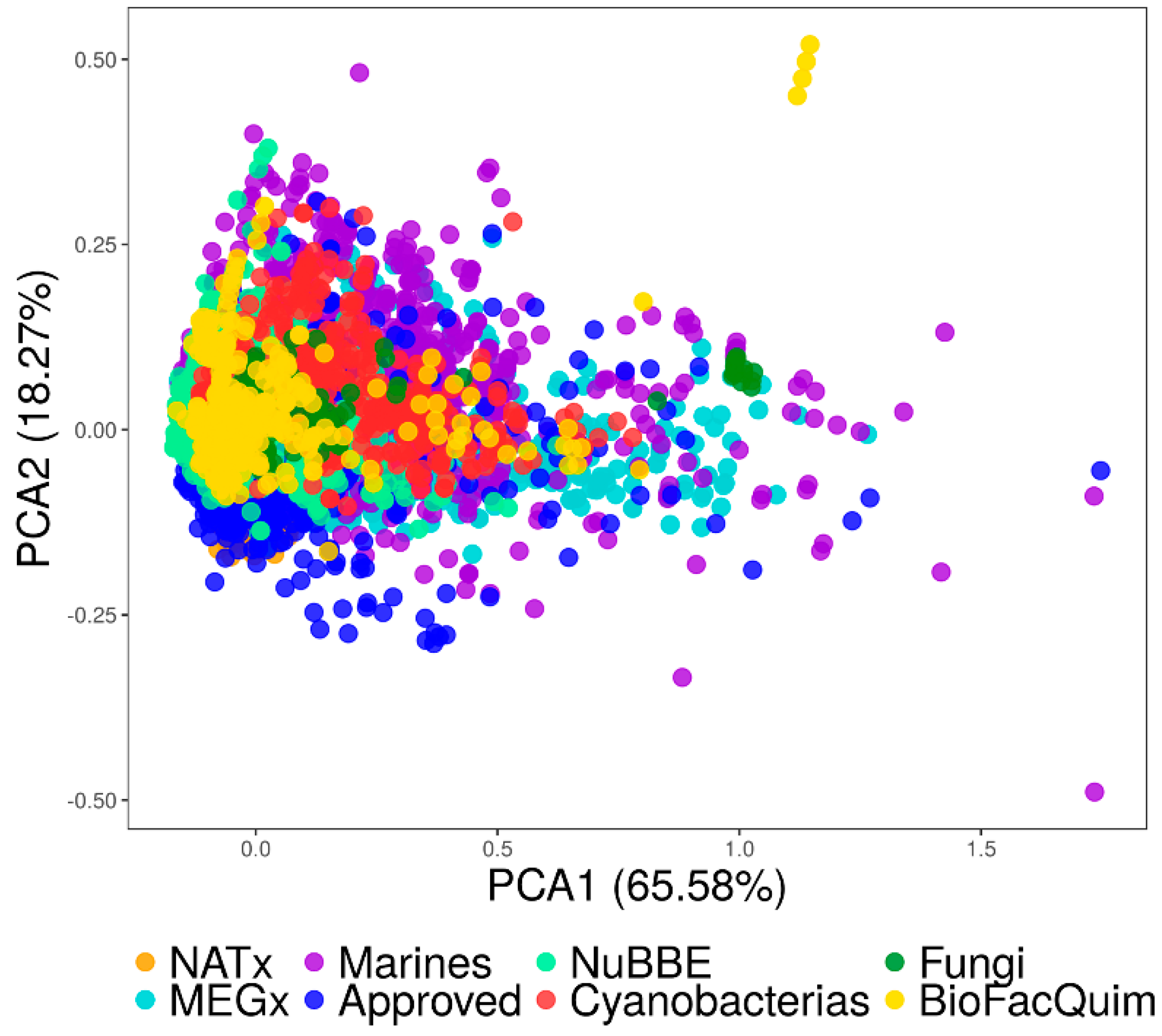
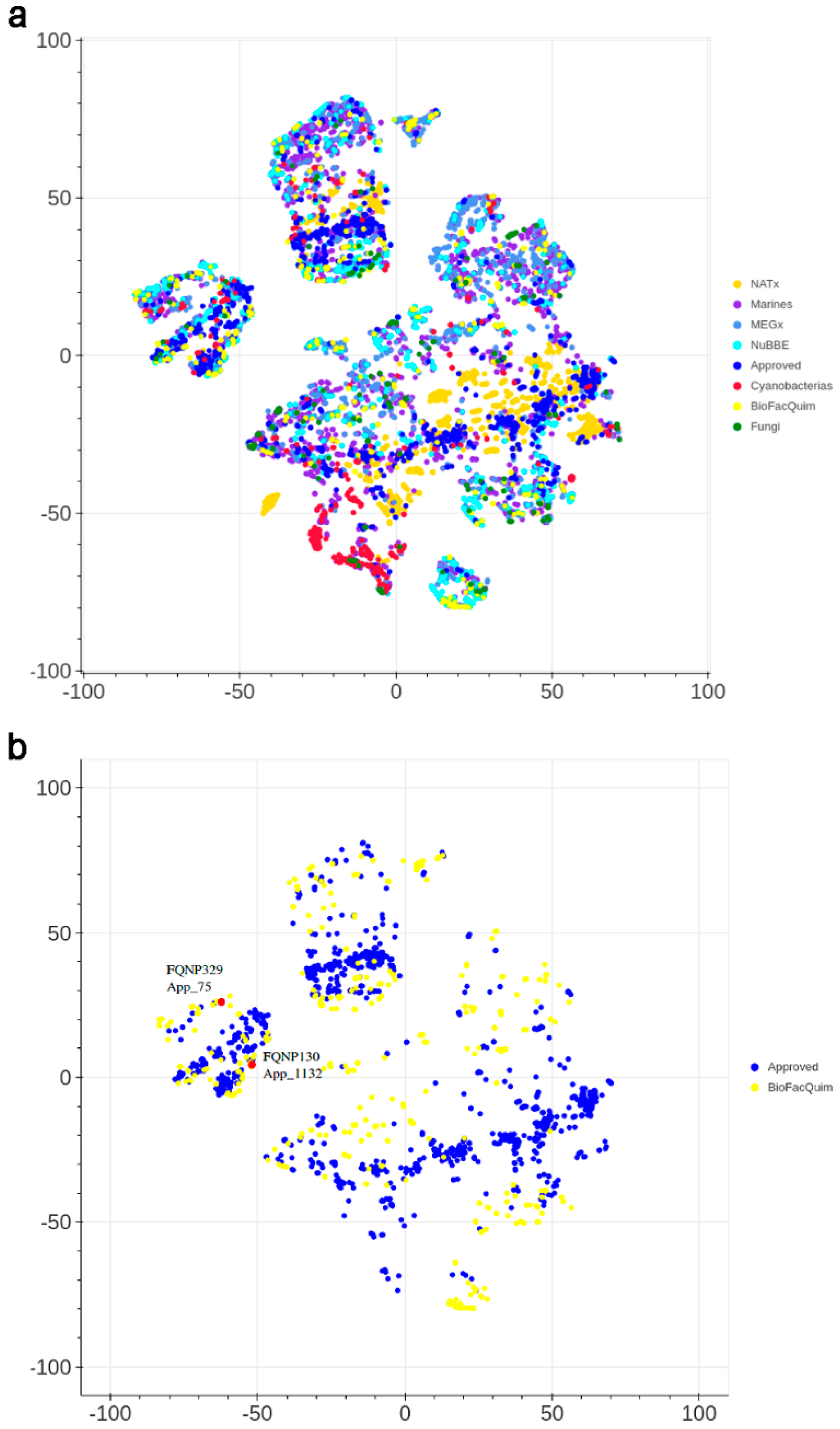
3.4. Chemical Space
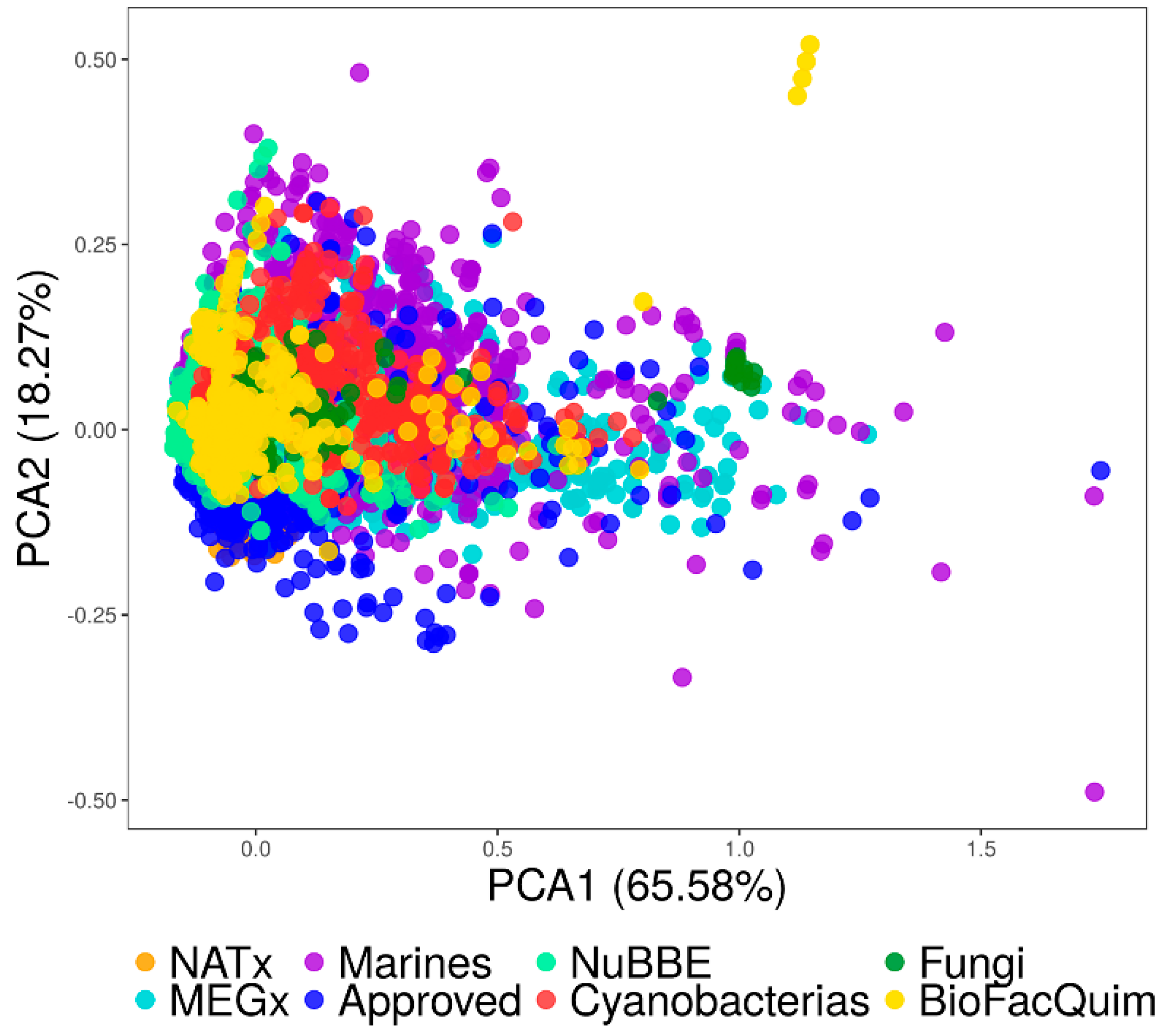
3.4.1. Visual Representation Based on Properties
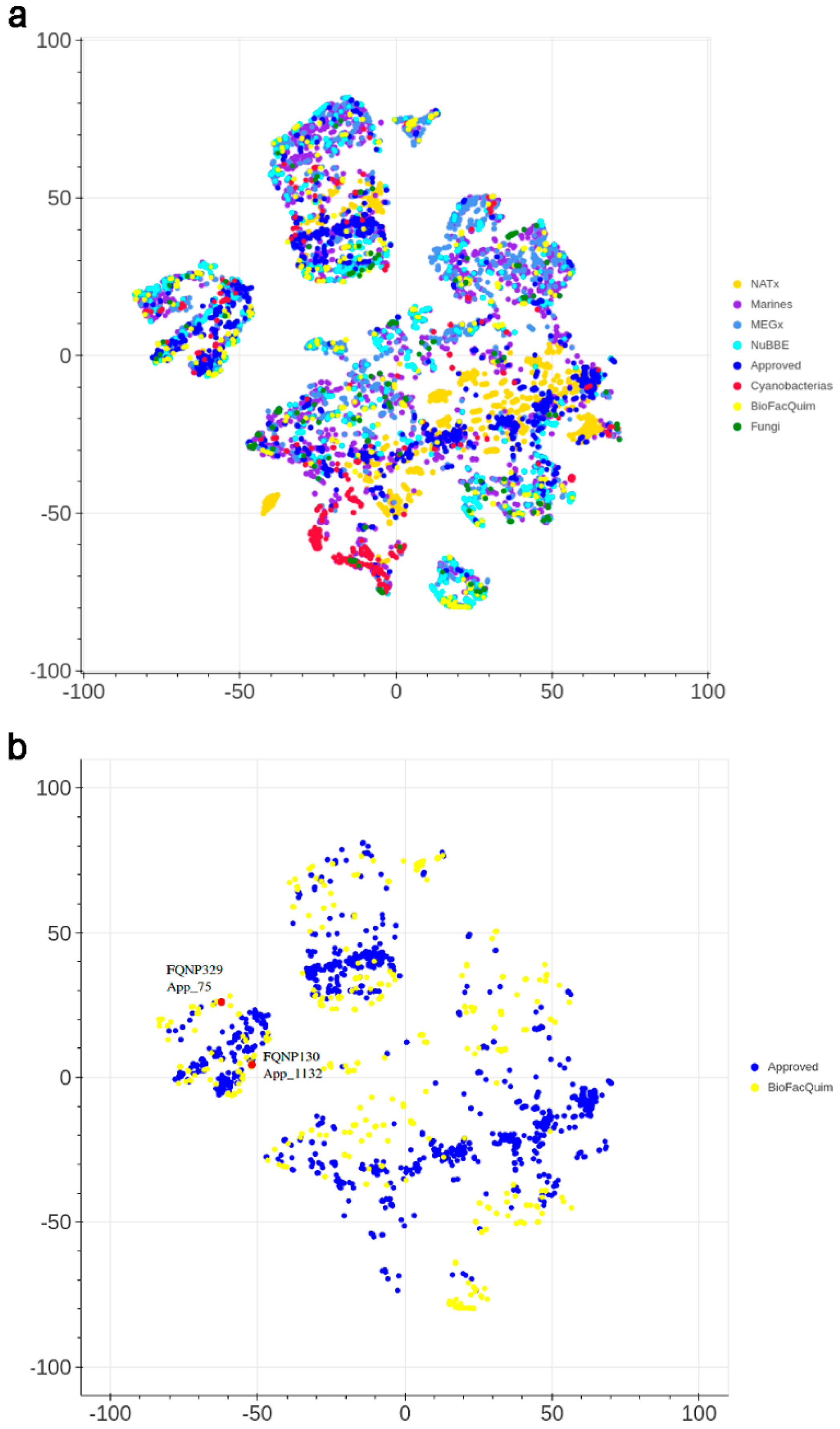
3.4.2. Visual Representation Based on Molecular Fingerprints
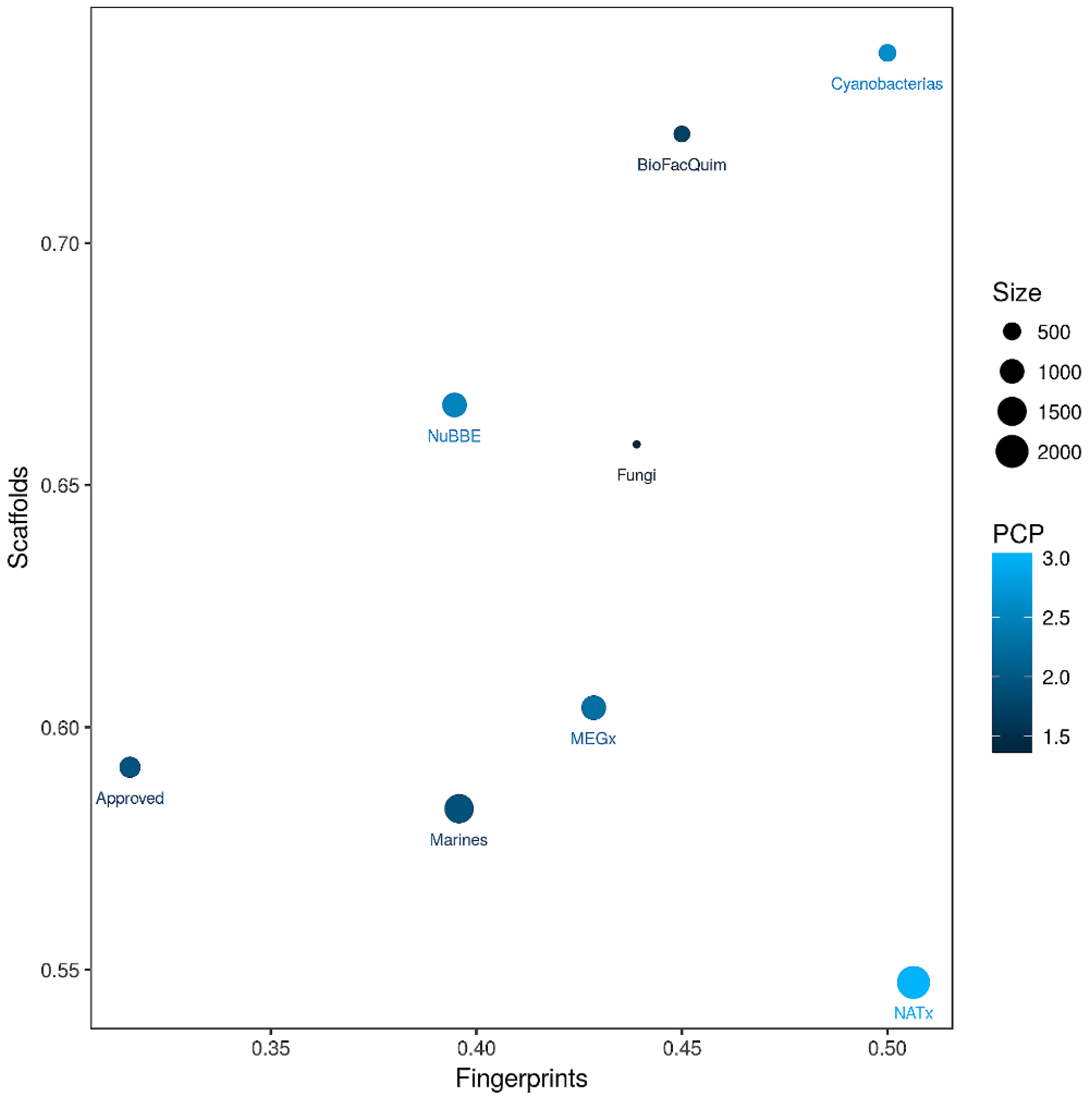
3.5. Global Diversity: Consensus Diversity Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Miller, M.A. Chemical database techniques in drug discovery. Nat. Rev. Drug Discov. 2002, 1, 220–227. [Google Scholar] [CrossRef] [PubMed]
- Newman, D.J. From natural products to drugs. Phys. Sci. Rev. 2018. [Google Scholar] [CrossRef]
- Newman, D.J.; Cragg, G.M. Natural products as sources of new drugs from 1981 to 2014. J. Nat. Prod. 2016, 79, 629–661. [Google Scholar] [CrossRef] [PubMed]
- Saldívar-González, F.I.; Pilón-Jiménez, B.A.; Medina-Franco, J.L. Chemical space of naturally occurring compounds. Phys. Sci. Rev. 2018. [Google Scholar] [CrossRef]
- Saldívar-González, F.I.; Gómez-García, A.; Chávez-Ponce de León, D.E.; Sánchez-Cruz, N.; Ruiz-Rios, J.; Pilón-Jiménez, B.A.; Medina-Franco, J.L. Inhibitors of DNA methyltransferases from natural sources: A computational perspective. Front. Pharmacol. 2018, 9, 1144. [Google Scholar] [CrossRef] [PubMed]
- Thomford, N.; Senthebane, D.; Rowe, A.; Munro, D.; Seele, P.; Maroyi, A.; Dzobo, K. Natural products for drug discovery in the 21st century: Innovations for novel drug discovery. Int. J. Mol. Sci. 2018, 19, 1578. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Gui, Y.; Chen, L.; Yuan, G.; Lu, H.-Z.; Xu, X. Use of natural products as chemical library for drug discovery and network pharmacology. PLoS ONE 2013, 8, e62839. [Google Scholar] [CrossRef]
- Chen, C.Y.-C. TCM database@Taiwan: The world’s largest traditional chinese medicine database for drug screening in silico. PLoS ONE 2011, 6, e15939. [Google Scholar] [CrossRef]
- Pilon, A.C.; Valli, M.; Dametto, A.C.; Pinto, M.E.F.; Freire, R.T.; Castro-Gamboa, I.; Andricopulo, A.D.; Bolzani, V.S. NuBBEDB: An updated database to uncover chemical and biological information from brazilian biodiversity. Sci Rep 2017, 7, 7215. [Google Scholar] [CrossRef]
- Nguyen-Vo, T.-H.; Le, T.Q.M.; Pham, D.T.; Nguyen, T.D.; Le, P.H.; Nguyen, A.D.T.; Nguyen, T.D.; Nguyen, T.-N.N.; Nguyen, V.A.; Do, H.T.; et al. VIETHERB: A database for vietnamese herbal species. J. Chem. Inf. Model. 2018. [Google Scholar] [CrossRef]
- Medina-Franco, J.L. Discovery and development of lead compounds from natural sources using computational approaches. In Evidence-Based Validation of Herbal Medicine; Mukherjee, P., Ed.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 455–475. [Google Scholar]
- Tung, C.-W. Public databases of plant natural products for computational drug discovery. Curr. Comput. Aided Drug Des. 2014, 10, 191–196. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Garcia de Lomana, M.; Friedrich, N.-O.; Kirchmair, J. Characterization of the chemical space of known and readily obtainable natural products. J. Chem. Inf. Model. 2018, 58, 1518–1532. [Google Scholar] [CrossRef] [PubMed]
- Molecular Operating Environment (MOE), version 2018.08; Chemical Computing Group Inc.: Montreal, QC, Canada, 2018; Available online: http://www.chemcomp.com (accessed on 28 November 2018).
- Saldívar-González, F.I.; Valli, M.; Andricopulo, A.D.; da Silva Bolzani, V.; Medina-Franco, J.L. Chemical diversity of NuBBE database: A chemoinformatic characterization. J. Chem. Inf. Model. 2019. [Google Scholar] [CrossRef]
- Sander, T.; Freyss, J.; von Korff, M.; Rufener, C. Datawarrior: An open-source program for chemistry aware data visualization and analysis. J. Chem. Inf. Model. 2015, 55, 460–473. [Google Scholar] [CrossRef] [PubMed]
- Bemis, G.W.; Murcko, M.A. The properties of known drugs. 1. Molecular frameworks. J. Med. Chem. 1996, 39, 2887–2893. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn Res. 2008, 9, 2579–2605. [Google Scholar]
- Osolodkin, D.I.; Radchenko, E.V.; Orlov, A.A.; Voronkov, A.E.; Palyulin, V.A.; Zefirov, N.S. Progress in visual representations of chemical space. Exp. Opin. Drug Discov. 2015, 10, 959–973. [Google Scholar] [CrossRef] [PubMed]
- González-Medina, M.; Prieto-Martínez, F.D.; Medina-Franco, J.L. Consensus diversity plots: A global diversity analysis of chemical libraries. J. Cheminf. 2016, 8, 63. [Google Scholar] [CrossRef]
- Naveja, J.; Rico-Hidalgo, M.; Medina-Franco, J. Analysis of a large food chemical database: Chemical space, diversity, and complexity. F1000Research 2018, 7, 993. [Google Scholar] [CrossRef]
- Medina-Franco, J.L.; Martínez-Mayorga, K.; Bender, A.; Scior, T. Scaffold diversity analysis of compound data sets using an entropy-based measure. QSAR Comb. Sci. 2009, 28, 1551–1560. [Google Scholar] [CrossRef]
- Berthold, M.R.; Cebron, N.; Dill, F.; Gabriel, T.R.; Kötter, T.; Meinl, T.; Ohl, P.; Sieb, C.; Thiel, K.; Wiswedel, B. Knime: The konstanz information miner. In Data analysis, machine learning and applications: Proceedings of the 31st Annual Conference of the Gesellschaft für Klassifikation e.V., Albert-Ludwigs-Universität Freiburg, Freiburg im Breisgau, Germany, 7–9 March 2007; Preisach, C., Burkhardt, H., Schmidt-Thieme, L., Decker, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 319–326. [Google Scholar]
- Naveja, J.J.; Oviedo-Osornio, C.I.; Trujillo-Minero, N.N.; Medina-Franco, J.L. Chemoinformatics: A perspective from an academic setting in Latin America. Mol. Divers. 2018, 22, 247–258. [Google Scholar] [CrossRef] [PubMed]
- Helmy, M.; Crits-Christoph, A.; Bader, G.D. Ten simple rules for developing public biological databases. PLoS Comput. Biol. 2016, 12, e1005128. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Size a |
|---|---|
| Approved drugs | 1806 |
| Cyanobacteria metabolites | 473 |
| Fungi metabolites | 206 |
| Marine | 6253 |
| MEGx | 4103 |
| Semi-synthetics (NATx) | 26,318 |
| NuBBEDB | 2214 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pilón-Jiménez, B.A.; Saldívar-González, F.I.; Díaz-Eufracio, B.I.; Medina-Franco, J.L. BIOFACQUIM: A Mexican Compound Database of Natural Products. Biomolecules 2019, 9, 31. https://doi.org/10.3390/biom9010031
Pilón-Jiménez BA, Saldívar-González FI, Díaz-Eufracio BI, Medina-Franco JL. BIOFACQUIM: A Mexican Compound Database of Natural Products. Biomolecules. 2019; 9(1):31. https://doi.org/10.3390/biom9010031
Chicago/Turabian StylePilón-Jiménez, B. Angélica, Fernanda I. Saldívar-González, Bárbara I. Díaz-Eufracio, and José L. Medina-Franco. 2019. "BIOFACQUIM: A Mexican Compound Database of Natural Products" Biomolecules 9, no. 1: 31. https://doi.org/10.3390/biom9010031
APA StylePilón-Jiménez, B. A., Saldívar-González, F. I., Díaz-Eufracio, B. I., & Medina-Franco, J. L. (2019). BIOFACQUIM: A Mexican Compound Database of Natural Products. Biomolecules, 9(1), 31. https://doi.org/10.3390/biom9010031