
An Innovative Inducer of Platelet Production, Isochlorogenic Acid A, Is Uncovered through the Application of Deep Neural Networks

 , , and
, , and
Abstract

1. Introduction
2. Materials and Methods
2.1. Dataset Collection and Processing
2.2. Construction, Training, and Evaluation of Models
2.3. Chemicals
2.4. Cell Culture
2.5. LDH Assay
2.6. Morphological Analysis
2.7. Giemsa Staining
2.8. Phalloidin Staining
2.9. Analysis of MK Differentiation
2.10. Animals
2.11. Construction of the RIT Model and ICGA-A Treatment
2.12. Measurement of Hematologic Parameters
2.13. Measurement of Body Weight and Visceral Index
2.14. Histology Analysis
2.15. Flow Cytometry Analysis of PB Cells
2.16. Flow Cytometry Analysis of BM and Spleen Cells
2.17. Polyploidy Analysis of BM and Spleen Cells
2.18. Statistical Analysis
3. Results
3.1. Data Collection and Processing
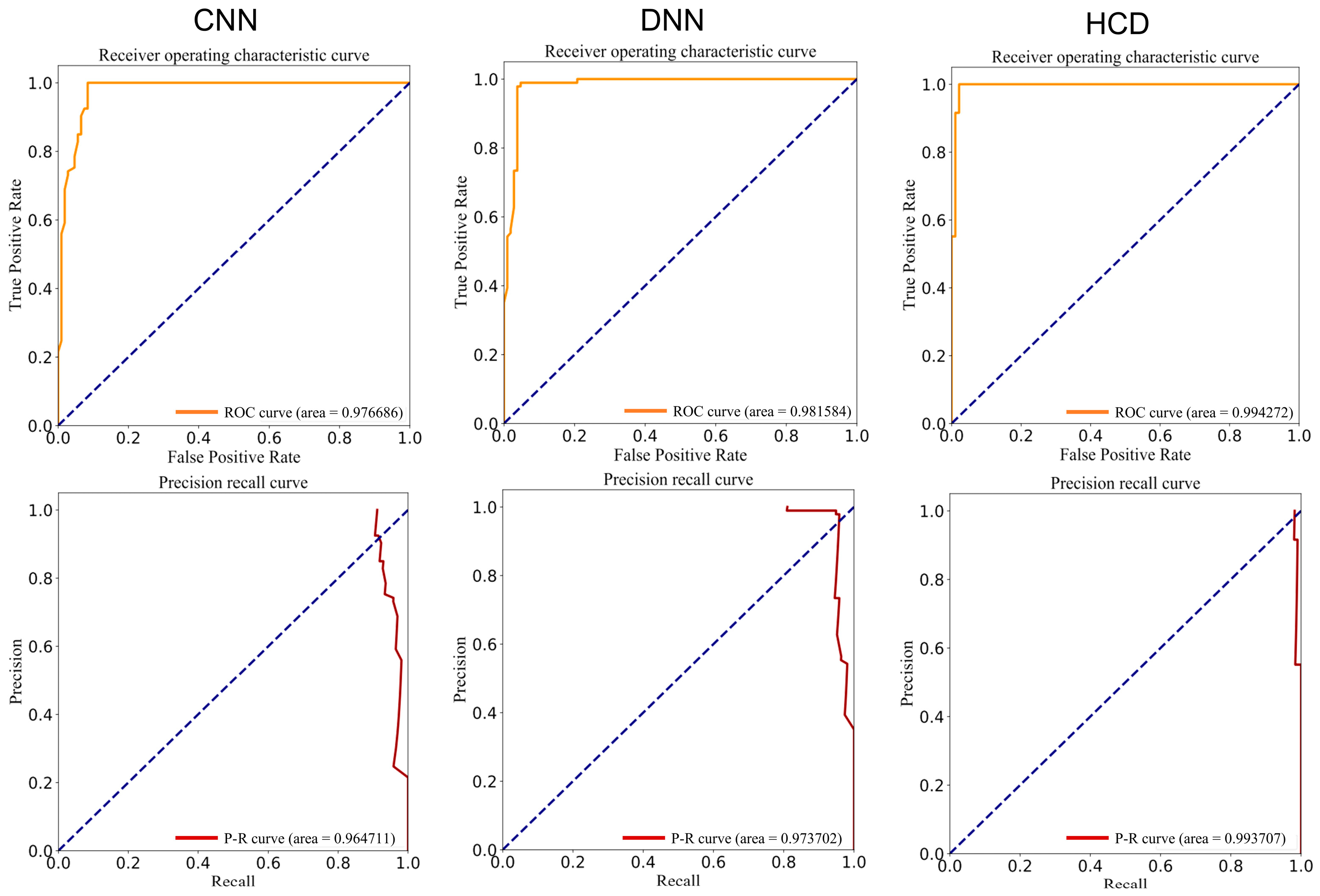
3.2. Development of Deep Learning Models for Drug Screening for the Treatment of RIT Using autoBioSeqpy
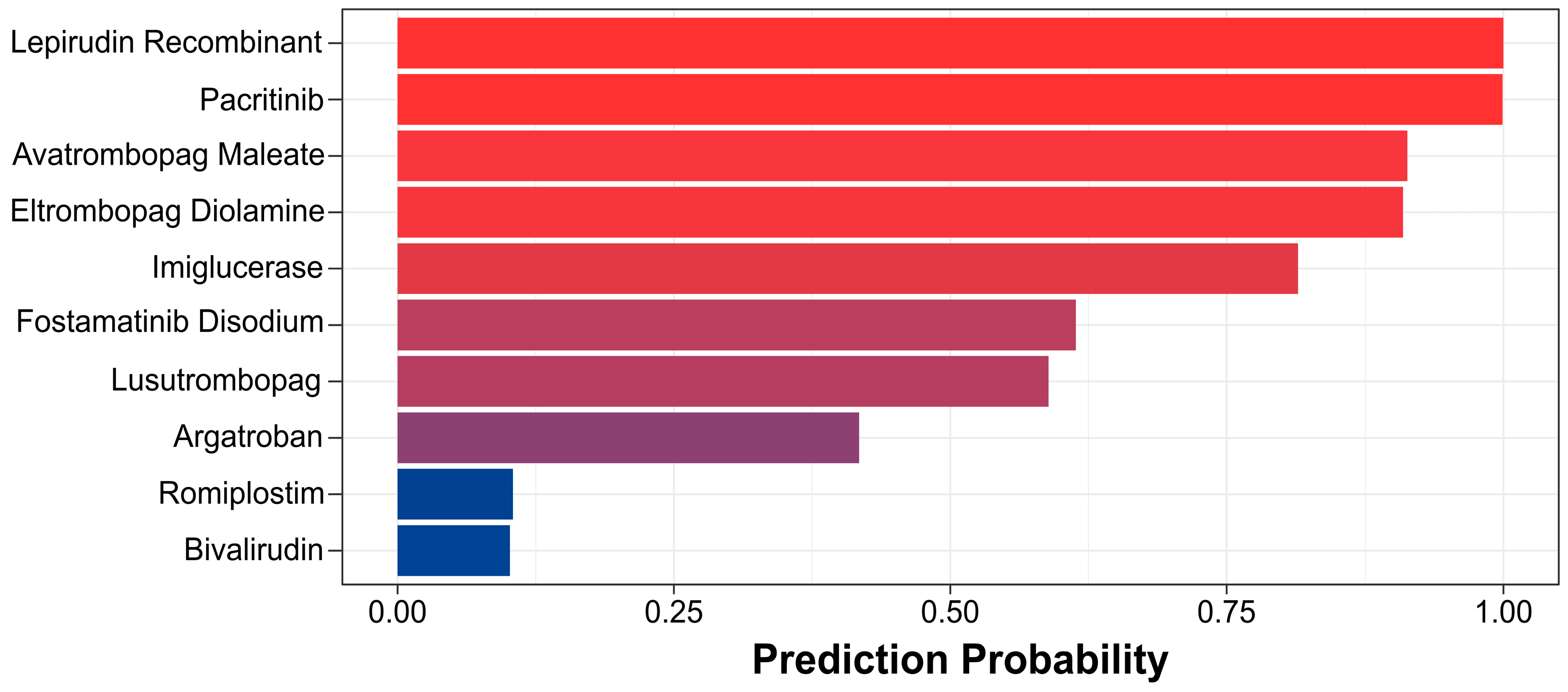
3.3. Verification of the Feasibility of the HCD Model for Virtual Screening to Promote Platelet Production Drugs
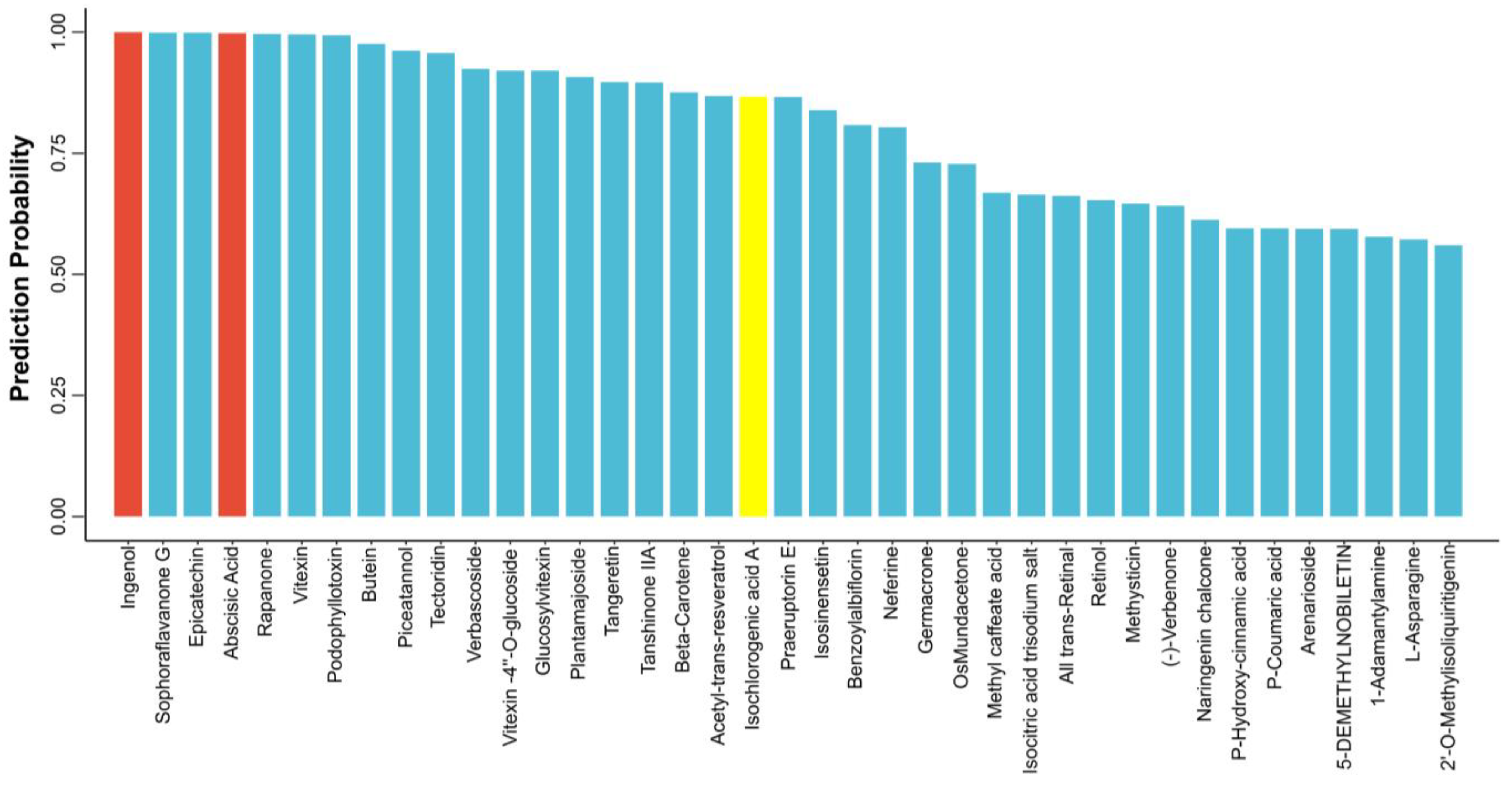
3.4. Virtual Screening for Potentially Promoted Platelet Production Drugs Using the HCD Model
3.5. Verification of the Activity of Compounds Promoting MK Differentiation
3.6. ICGA-A Induces MK Differentiation and Maturation of K562 and Meg-01 Cells
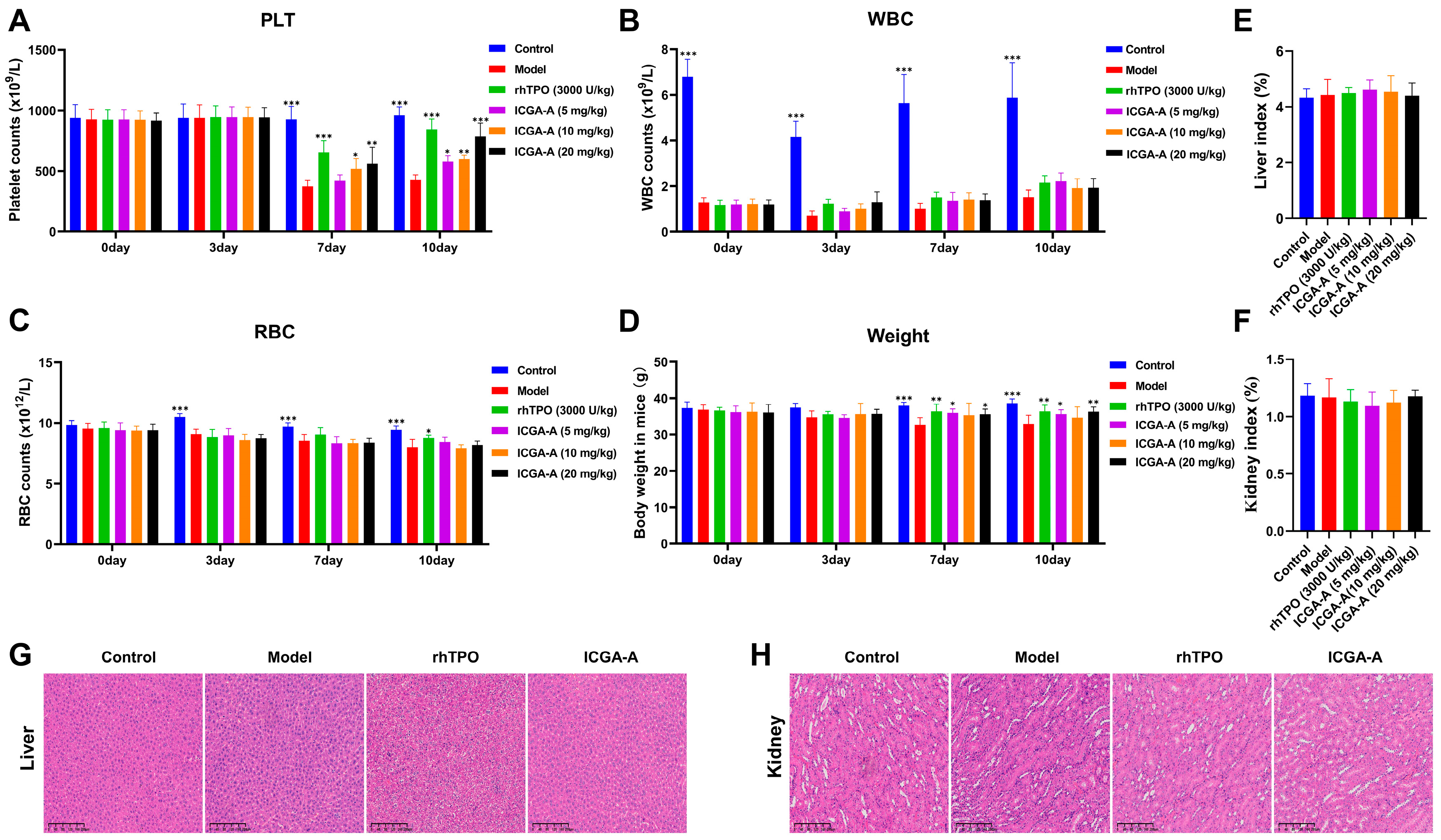
3.7. ICGA-A Promoted Platelet Production and Increased the Number of MKs in RIT Mice
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jameus, A.; Kennedy, A.E.; Thome, C. Hematological Changes Following Low Dose Radiation Therapy and Comparison to Current Standard of Care Cancer Treatments. Dose Response 2021, 19, 15593258211056196. [Google Scholar] [CrossRef]
- Debela, D.T.; Muzazu, S.G.; Heraro, K.D.; Ndalama, M.T.; Mesele, B.W.; Haile, D.C.; Kitui, S.K.; Manyazewal, T. New approaches and procedures for cancer treatment: Current perspectives. SAGE Open Med. 2021, 9, 20503121211034366. [Google Scholar] [CrossRef]
- Thompson, M.K.; Poortmans, P.; Chalmers, A.J.; Faivre-Finn, C.; Hall, E.; Huddart, R.A.; Lievens, Y.; Sebag-Montefiore, D.; Coles, C.E. Practice-changing radiation therapy trials for the treatment of cancer: Where are we 150 years after the birth of Marie Curie? Br. J. Cancer 2018, 119, 389–407. [Google Scholar] [CrossRef]
- Mac Manus, M.; Lamborn, K.; Khan, W.; Varghese, A.; Graef, L.; Knox, S. Radiotherapy-Associated Neutropenia and Thrombocytopenia: Analysis of Risk Factors and Development of a Predictive Model. Blood 1997, 89, 2303–2310. [Google Scholar] [CrossRef]
- Wang, Y.; Probin, V.; Zhou, D. Cancer therapy-induced residual bone marrow injury-Mechanisms of induction and implication for therapy. Curr. Cancer Ther. Rev. 2006, 2, 271–279. [Google Scholar] [CrossRef]
- Kuter, D.J. Treatment of chemotherapy-induced thrombocytopenia in patients with non-hematologic malignancies. Haematologica 2022, 107, 1243–1263. [Google Scholar] [CrossRef]
- Nambiar, A.; Duquesnoy, R.J.; Adams, S.; Zhao, Y.; Oblitas, J.; Leitman, S.; Stroncek, D.; Marincola, F. HLAMatchmaker-driven analysis of responses to HLA-typed platelet transfusions in alloimmunized thrombocytopenic patients. Blood 2006, 107, 1680–1687. [Google Scholar] [CrossRef]
- Cheng, M.; Qian, C.S.; Zhou, H.X.; Xu, M.; Gong, W.J.; Sun, A.; Wu, D.P.; Xue, S.L. Recombinant Human Thrombopoietin Combined with Thrombopoietin Receptor Agonists Can Facilitate the Recovery of Platelet after Allogeneic HSCT. Blood 2023, 142, 5451. [Google Scholar] [CrossRef]
- Ghanima, W.; Cooper, N.; Rodeghiero, F.; Godeau, B.; Bussel, J.B. Thrombopoietin receptor agonists: Ten years later. Haematologica 2019, 104, 1112–1123. [Google Scholar] [CrossRef]
- Reymond, J.L. The Chemical Space Project. Acc. Chem. Res. 2015, 48, 722–730. [Google Scholar] [CrossRef]
- Kayki-Mutlu, G.; Aksoyalp, Z.S.; Wojnowski, L.; Michel, M.C. A year in pharmacology: New drugs approved by the US Food and Drug Administration in 2021. Naunyn-Schmiedeberg’s Arch. Pharmacol. 2022, 395, 867–885. [Google Scholar] [CrossRef]
- Chan, H.C.S.; Shan, H.; Dahoun, T.; Vogel, H.; Yuan, S. Advancing Drug Discovery via Artificial Intelligence. Trends Pharmacol. Sci. 2019, 40, 592–604. [Google Scholar] [CrossRef]
- Sadybekov, A.V.; Katritch, V. Computational approaches streamlining drug discovery. Nature 2023, 616, 673–685. [Google Scholar] [CrossRef]
- Wang, R.; Xu, J.; Yan, R.; Liu, H.; Zhao, J.; Xie, Y.; Deng, W.; Liao, W.; Nie, Y. Virtual screening and activity evaluation of multitargeting inhibitors for idiopathic pulmonary fibrosis. Front. Pharmacol. 2022, 13, 998245. [Google Scholar] [CrossRef]
- Yang, B.; Bao, W.; Wang, J. Hypertension-Related Drug Activity Identification Based on Novel Ensemble Method. Front. Genet. 2021, 12, 768747. [Google Scholar] [CrossRef]
- Sun, Y.Y.; Lin, T.T.; Cheng, W.C.; Lu, I.H.; Lin, C.Y.; Chen, S.H. Peptide-Based Drug Predictions for Cancer Therapy Using Deep Learning. Pharmaceuticals 2022, 15, 422. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Mo, Q.; Jiang, N.; Wu, Y.; Yang, X.; Chen, W.; Li, Q.; Yang, S.; Yang, J.; Zeng, J.; et al. The combination of machine learning and transcriptomics reveals a novel megakaryopoiesis inducer, MO-A, that promotes thrombopoiesis by activating FGF1/FGFR1/PI3K/Akt/NF-κB signaling. Eur. J. Pharmacol. 2023, 944, 175604. [Google Scholar] [CrossRef] [PubMed]
- Mo, Q.; Zhang, T.; Wu, J.; Wang, L.; Luo, J. Identification of thrombopoiesis inducer based on a hybrid deep neural network model. Thromb. Res. 2023, 226, 36–50. [Google Scholar] [CrossRef] [PubMed]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef]
- Jing, R.; Li, Y.; Xue, L.; Liu, F.; Li, M.L.; Luo, J. autoBioSeqpy: A Deep Learning Tool for the Classification of Biological Sequences. J. Chem. Inf. Model. 2020, 60, 3755–3764. [Google Scholar] [CrossRef]
- Wu, C.K.; Zhang, X.C.; Yang, Z.J.; Lu, A.P.; Hou, T.J.; Cao, D.S. Learning to SMILES: BAN-based strategies to improve latent representation learning from molecules. Briefings Bioinform. 2021, 22, bbab327. [Google Scholar] [CrossRef]
- Vogt, M.; Bajorath, J. Modeling Tanimoto Similarity Value Distributions and Predicting Search Results. Mol. Informatics 2017, 36, 1600131. [Google Scholar] [CrossRef] [PubMed]
- Ashton, M.; Barnard, J.; Casset, F.; Charlton, M.; Downs, G.; Gorse, D.; Holliday, J.; Lahana, R.; Willett, P. Identification of Diverse Database Subsets using Property-Based and Fragment-Based Molecular Descriptions. Int. J. Quant. Struct. Prop. Relatsh. 2002, 21, 598–604. [Google Scholar] [CrossRef]
- Durant, J.L.; Leland, B.A.; Henry, D.R.; Nourse, J.G. Reoptimization of MDL Keys for Use in Drug Discovery. J. Chem. Inf. Comput. Sci. 2002, 42, 1273–1280. [Google Scholar] [CrossRef] [PubMed]
- Rogers, D.; Hahn, M. Extended-Connectivity Fingerprints. J. Chem. Inf. Model. 2010, 50, 742–754. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Feng, J.; Liu, S.; Yao, J. A Novel Molecular Representation Learning for Molecular Property Prediction with a Multiple SMILES-Based Augmentation. Comput. Intell. Neurosci. 2022, 2022, 8464452. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Zhang, T.; Liu, S.; Mo, Q.; Jiang, N.; Chen, Q.; Yang, J.; Han, Y.W.; Chen, J.P.; Huang, F.H.; et al. Discovery of a novel megakaryopoiesis enhancer, ingenol, promoting thrombopoiesis through PI3K-Akt signaling independent of thrombopoietin. Pharmacol. Res. 2022, 177, 106096. [Google Scholar] [CrossRef] [PubMed]
- Malara, A.; Fresia, C.; Di Buduo, C.A.; Soprano, P.M.; Moccia, F.; Balduini, C.; Zocchi, E.; De Flora, A.; Balduini, A. The Plant Hormone Abscisic Acid Is a Prosurvival Factor in Human and Murine Megakaryocytes. J. Biol. Chem. 2017, 292, 3239–3251. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Hwang, W.Y.K.; Aw, S.E. Biological characteristics of megakaryocytes: Specific lineage commitment and associated disorders. Int. J. Biochem. Cell Biol. 2006, 38, 1821–1826. [Google Scholar] [CrossRef]
- Schulze, H.; A Shivdasani, R. Molecular mechanisms of megakaryocyte differentiation. Semin. Thromb. Hemost. 2004, 30, 389–398. [Google Scholar] [CrossRef]
- Noh, J.Y. Megakaryopoiesis and Platelet Biology: Roles of Transcription Factors and Emerging Clinical Implications. Int. J. Mol. Sci. 2021, 22, 9615. [Google Scholar] [CrossRef]
- DiCarlo, A.L.; Kaminski, J.M.; Hatchett, R.J.; Maidment, B.W. Role of thrombocytopenia in radiation-induced mortality and review of therapeutic approaches targeting platelet regeneration after radiation exposure. J. Radiat. Oncol. 2016, 5, 19–32. [Google Scholar] [CrossRef]
- Hu, J.; Tang, L.; Cheng, Y.; Liu, A.; Huang, L. Risk Analysis of Severe Thrombocytopenia in Nasopharyngeal Carcinoma During Concurrent Radio-Chemotherapy. Front. Oncol. 2021, 11, 754624. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, P.; Han, Y.; Zhang, H. Platelet transfusion for cancer secondary thrombocytopenia: Platelet and cancer cell interaction. Transl. Oncol. 2021, 14, 101022. [Google Scholar] [CrossRef]
- Yazdanbakhsh, K. TPO-RAs multitask in ITP. Blood 2016, 128, 750–751. [Google Scholar] [CrossRef]
- Agarwal, N.; Mangla, A. Thrombopoietin receptor agonist for treatment of immune thrombocytopenia in pregnancy: A narrative review. Ther. Adv. Hematol. 2021, 12, 20406207211001139. [Google Scholar] [CrossRef] [PubMed]
- Sun, D.; Gao, W.; Hu, H.; Zhou, S. Why 90% of clinical drug development fails and how to improve it? Acta Pharm. Sin. B 2022, 12, 3049–3062. [Google Scholar] [CrossRef] [PubMed]
- Polishchuk, P.G.; Madzhidov, T.I.; Varnek, A. Estimation of the size of drug-like chemical space based on GDB-17 data. J. Comput. Aided Mol. Des. 2013, 27, 675–679. [Google Scholar] [CrossRef]
- Wang, J.; Mao, J.; Wang, M.; Le, X.; Wang, Y. Explore drug-like space with deep generative models. Methods 2023, 210, 52–59. [Google Scholar] [CrossRef] [PubMed]
- Macarrón, R.; Hertzberg, R.P. Design and implementation of high-throughput screening assays. In High Throughput Screening. Methods in Molecular Biology; Humana Press: Totowa, NJ, USA, 2009; Volume 565, pp. 1–32. [Google Scholar] [CrossRef]
- Paul, D.; Sanap, G.; Shenoy, S.; Kalyane, D.; Kalia, K.; Tekade, R.K. Artificial intelligence in drug discovery and development. Drug Discov. Today 2021, 26, 80–93. [Google Scholar] [CrossRef] [PubMed]
- Dara, S.; Dhamercherla, S.; Jadav, S.S.; Babu, C.M.; Ahsan, M.J. Machine Learning in Drug Discovery: A Review. Artif. Intell. Rev. 2022, 55, 1947–1999. [Google Scholar] [CrossRef] [PubMed]
- Choudhary, K.; DeCost, B.; Chen, C.; Jain, A.; Tavazza, F.; Cohn, R.; Park, C.W.; Choudhary, A.; Agrawal, A.; Billinge, S.J.L.; et al. Recent advances and applications of deep learning methods in materials science. NPJ Comput. Mater. 2022, 8, 59. [Google Scholar] [CrossRef]
- Li, Y.; Huang, C.; Ding, L.; Li, Z.; Pan, Y.; Gao, X. Deep learning in bioinformatics: Introduction, application, and perspective in the big data era. Methods 2019, 166, 4–21. [Google Scholar] [CrossRef] [PubMed]
- Vaz, J.M.; Balaji, S. Convolutional neural networks (CNNs): Concepts and applications in pharmacogenomics. Mol. Divers. 2021, 25, 1569–1584. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Bai, J.; Al-Sabaawi, A.; Santamaría, J.; Albahri, A.S.; Al-Dabbagh, B.S.N.; Fadhel, M.A.; Manoufali, M.; Zhang, J.; Al-Timemy, A.H.; et al. A survey on deep learning tools dealing with data scarcity: Definitions, challenges, solutions, tips, and applications. J. Big Data 2023, 10, 46. [Google Scholar] [CrossRef]
- Hao, B.J.; Wu, Y.H.; Wang, J.G.; Hu, S.Q.; Keil, D.J.; Hu, H.J.; Lou, J.D.; Zhao, Y. Hepatoprotective and antiviral properties of isochlorogenic acid A from Laggera alata against hepatitis B virus infection. J. Ethnopharmacol. 2012, 144, 190–194. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Zhu, S.; Liu, Q.; Zhang, Y. Spectrum-effect relationship study between HPLC fingerprints and antioxidant of honeysuckle extract. Biomed. Chromatogr. 2019, 33, e4583. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.N.; Shen, Z.; Liu, Q.; Hou, X.Y.; Cao, Y.; Liu, D.H.; Jiang, H.; Du, H.Z. Isochlorogenic acid (ICGA): Natural medicine with potentials in pharmaceutical developments. Chin. J. Nat. Med. 2020, 18, 860–871. [Google Scholar] [CrossRef]
- Tang, S.; Zhong, W.; Li, T.; Li, Y.; Song, G. Isochlorogenic acid A alleviates dextran sulfate sodium-induced ulcerative colitis in mice through STAT3/NF-кB pathway. Int. Immunopharmacol. 2023, 118, 109989. [Google Scholar] [CrossRef]
- Ru, Y.X.; Dong, S.X.; Liang, H.Y.; Zhao, S.X. Platelet production of megakaryocyte: A review with original observations on human in vivo cells and bone marrow. Ultrastruct. Pathol. 2016, 40, 163–170. [Google Scholar] [CrossRef]
- Patel, S.R.; Hartwig, J.H.; Italiano, J.E., Jr. The biogenesis of platelets from megakaryocyte proplatelets. J. Clin. Investig. 2005, 115, 3348–3354. [Google Scholar] [CrossRef] [PubMed]
- Travlos, G.S. Normal structure, function, and histology of the bone marrow. Toxicol. Pathol. 2006, 34, 548–565. [Google Scholar] [CrossRef] [PubMed]
- Noetzli, L.J.; French, S.L.; Machlus, K.R. New Insights Into the Differentiation of Megakaryocytes From Hematopoietic Progenitors. Arter. Thromb. Vasc. Biol. 2019, 39, 1288–1300. [Google Scholar] [CrossRef] [PubMed]
- Chamberlain, K.G.; Tong, M.; Penington, D.G. Properties of the exchangeable splenic platelets released into the circulation during exercise-induced thrombocytosis. Am. J. Hematol. 1990, 34, 161–168. [Google Scholar] [CrossRef]
- Luu, S.; Woolley, I.J.; Andrews, R.K. Platelet phenotype and function in the absence of splenic sequestration (Review). Platelets 2021, 32, 47–52. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Yan, C.; Liu, X.; Yang, P.; Wang, J.; Chen, Y.; Liu, W.; Li, S.; Zhang, X.; Dong, G.; et al. Global characterization of megakaryocytes in bone marrow, peripheral blood, and cord blood by single-cell RNA sequencing. Cancer Gene Ther. 2022, 29, 1636–1647. [Google Scholar] [CrossRef]
- Short, C.; Lim, H.K.; Tan, J.; O’Neill, H.C. Targeting the Spleen as an Alternative Site for Hematopoiesis. BioEssays 2019, 41, e1800234. [Google Scholar] [CrossRef]
- Stone, A.P.; Nascimento, T.F.; Barrachina, M.N. The bone marrow niche from the inside out: How megakaryocytes are shaped by and shape hematopoiesis. Blood 2022, 139, 483–491. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | ACC (%) | PRE (%) | Recall (%) | F-Value (%) | MCC | AUROC | AUPRC |
|---|---|---|---|---|---|---|---|
| CNN | 94.0 | 90.1 | 99.2 | 94.4 | 0.884 | 0.975 | 0.965 |
| DNN | 96.5 | 95.2 | 97.7 | 96.4 | 0.930 | 0.979 | 0.973 |
| HCD | 98.3 | 97.0 | 99.8 | 98.3 | 0.967 | 0.994 | 0.992 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, T.; Luo, J.; Liao, R.; Wang, L.; Wu, A.; Li, Y.; Zhou, L.; Ni, C.; Wang, K.; Tang, X.; et al. An Innovative Inducer of Platelet Production, Isochlorogenic Acid A, Is Uncovered through the Application of Deep Neural Networks. Biomolecules 2024, 14, 267. https://doi.org/10.3390/biom14030267
Yi T, Luo J, Liao R, Wang L, Wu A, Li Y, Zhou L, Ni C, Wang K, Tang X, et al. An Innovative Inducer of Platelet Production, Isochlorogenic Acid A, Is Uncovered through the Application of Deep Neural Networks. Biomolecules. 2024; 14(3):267. https://doi.org/10.3390/biom14030267
Chicago/Turabian StyleYi, Taian, Jiesi Luo, Ruixue Liao, Long Wang, Anguo Wu, Yueyue Li, Ling Zhou, Chengyang Ni, Kai Wang, Xiaoqin Tang, and et al. 2024. "An Innovative Inducer of Platelet Production, Isochlorogenic Acid A, Is Uncovered through the Application of Deep Neural Networks" Biomolecules 14, no. 3: 267. https://doi.org/10.3390/biom14030267
APA StyleYi, T., Luo, J., Liao, R., Wang, L., Wu, A., Li, Y., Zhou, L., Ni, C., Wang, K., Tang, X., Zou, W., & Wu, J. (2024). An Innovative Inducer of Platelet Production, Isochlorogenic Acid A, Is Uncovered through the Application of Deep Neural Networks. Biomolecules, 14(3), 267. https://doi.org/10.3390/biom14030267