
Combining Low-Dose Computer-Tomography-Based Radiomics and Serum Metabolomics for Diagnosis of Malignant Nodules in Participants of Lung Cancer Screening Studies

 ,
,  ,
, 
 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Subject
2.2. Metabolomic Data
2.3. Radiomic Data
2.4. Univariate Analysis
2.5. Machine Learning Sets
2.6. Logistic Regression Models
2.7. Random Forest Models
2.8. Machine Learning Result Integration
3. Results
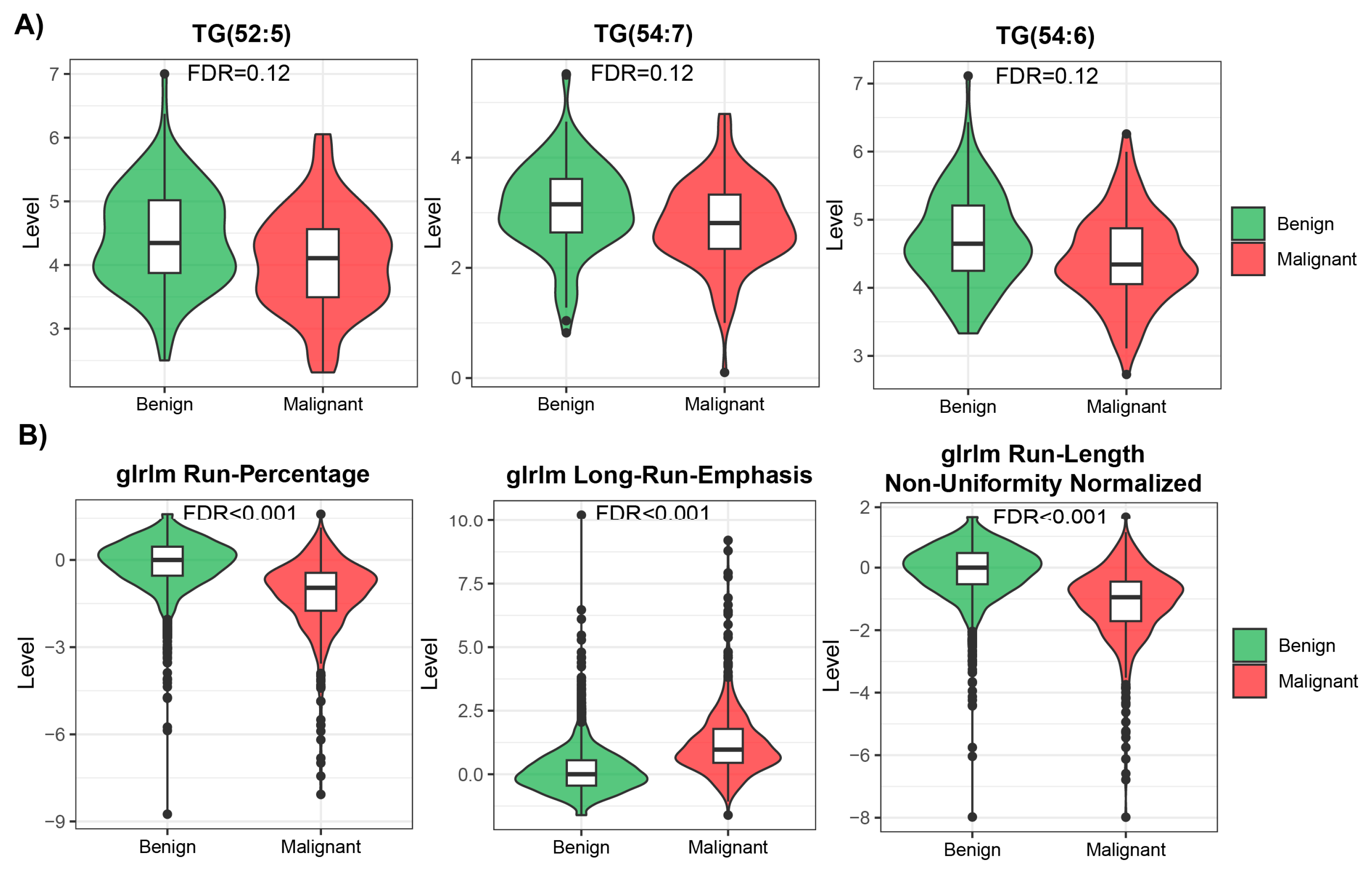
3.1. Univariate Analysis of Metabolomic and Radiomic Studies
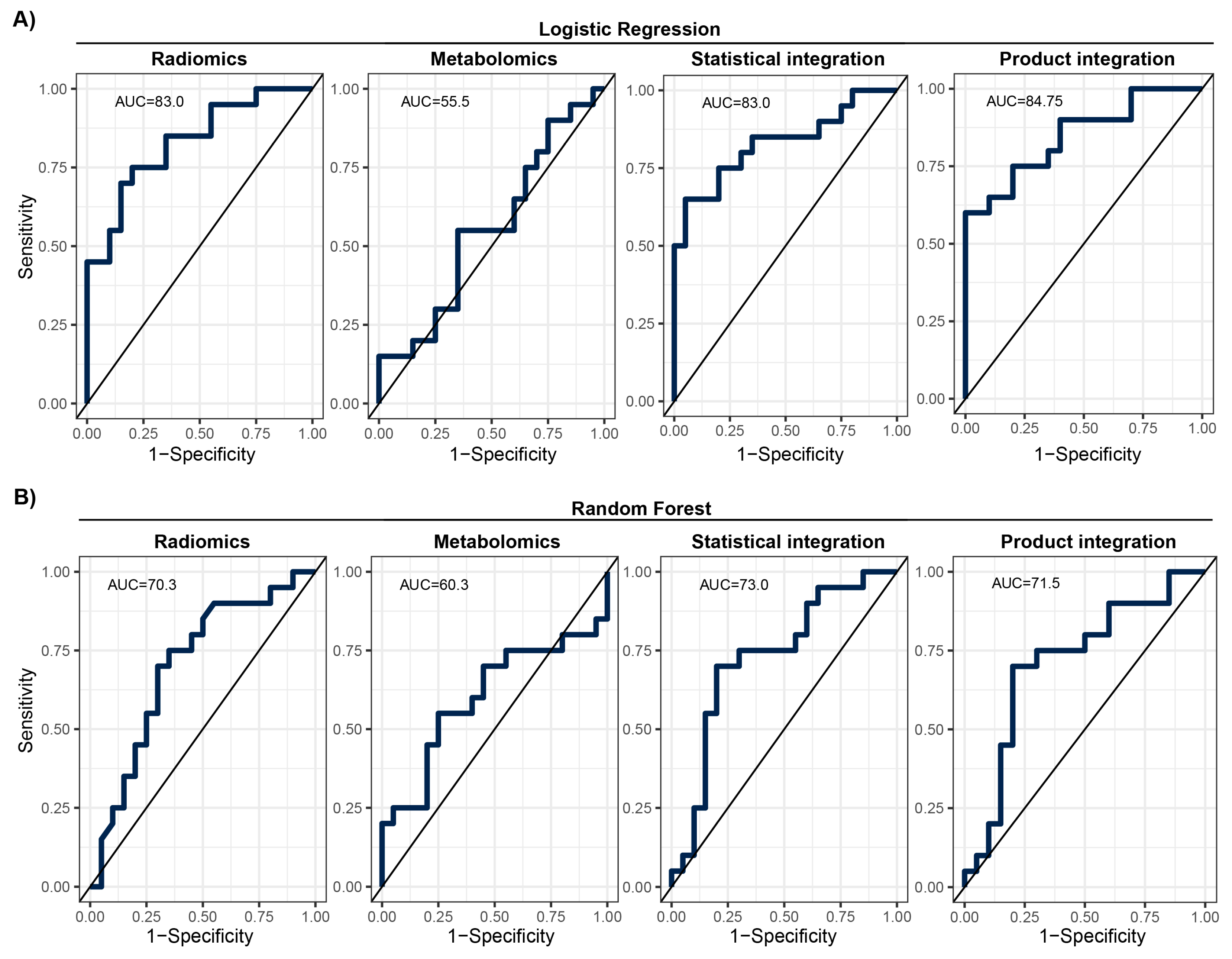
3.2. Development of Machine Learning Models
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schabath, M.B.; Cote, M.L. Cancer Progress and Priorities: Lung Cancer. Cancer Epidemiol. Biomark. Prev. 2019, 28, 1563–1579. [Google Scholar] [CrossRef] [PubMed]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA A Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Ostrowski, M.; Marjański, T.; Dziedzic, R.; Jelitto-Górska, M.; Dziadziuszko, K.; Szurowska, E.; Dziadziuszko, R.; Rzyman, W. Ten years of experience in lung cancer screening in Gdańsk, Poland: A comparative study of the evaluation and surgical treatment of 14200 participants of 2 lung cancer screening programmes. Interact. CardioVascular Thorac. Surg. 2019, 29, 266–274. [Google Scholar] [CrossRef] [PubMed]
- The National Lung Skrining Trial Research Team. Reduced Lung-Cancer Mortality with Low-Dose Computed Tomographic Skrining. N. Engl. J. Med. 2011, 365, 395–409. [Google Scholar] [CrossRef]
- de Koning, H.J.; van der Aalst, C.M.; de Jong, P.A.; Scholten, E.T.; Nackaerts, K.; Heuvelmans, M.A.; Lammers, J.W.J.; Weenink, C.; Yousaf-Khan, U.; Horeweg, N.; et al. Reduced Lung-Cancer Mortality with Volume CT Screening in a Randomized Trial. N. Engl. J. Med. 2020, 82, 503–513. [Google Scholar] [CrossRef]
- Priola, A.M.; Priola, S.M.; Giaj-Levra, M.; Basso, E.; Veltri, A.; Fava, C.; Cardinale, L. Clinical implications and added costs of incidental findings in an early detection study of lung cancer by using low-dose spiral computed tomography. Clin. Lung Cancer 2013, 14, 139–148. [Google Scholar] [CrossRef]
- Atwater, T.; Massion, P.P. Biomarkers of risk to develop lung cancer in the new screening era. Ann. Transl. Med. 2016, 4, 158. [Google Scholar] [CrossRef]
- Hassanein, M.; Callison, J.C.; Callaway-Lane, C.; Aldrich, M.C.; Grogan, E.L.; Massion, P.P. The state of molecular biomarkers for the early detection of lung cancer. Cancer Prev. Res. 2012, 5, 992–1006. [Google Scholar] [CrossRef]
- Sozzi, G.; Boeri, M. Potential biomarkers for lung cancer screening. Transl. Lung Cancer Res. 2014, 3, 139–148. [Google Scholar]
- Chu, G.C.W.; Lazare, K.; Sullivan, F. Serum and blood based biomarkers for lung cancer screening: A systematic review. BMC Cancer 2018, 18, 181. [Google Scholar] [CrossRef]
- Ostrin, E.J.; Sidransky, D.; Spira, A.; Hanash, S.M. Biomarkers for lung cancer screening and detection. Cancer Epidemiol. Biomark. Prev. 2020, 29, 2411–2415. [Google Scholar] [CrossRef] [PubMed]
- Spratlin, J.L.; Serkova, N.J.; Eckhardt, S.G. Clinical applications of metabolomics in oncology: A review. Clin. Cancer Res. 2009, 15, 431–440. [Google Scholar] [CrossRef] [PubMed]
- Rocha, C.M.; Carrola, J.; Barros, A.S.; Gil, A.M.; Goodfellow, B.; Carreira, I.M.; Bernardo, J.; Gomes, A.; de Sousa, V.M.L.; Carvalho, L.; et al. Metabolic signatures of lung cancer in biofluids: NMR-based metabonomics of blood plasma. J. Proteome Res. 2011, 10, 4314–4324. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Wang, X.; Qiu, L.; Qin, X.; Liu, H.; Wang, Y.; Li, F.; Wang, X.; Chen, G.; Song, G.; et al. Probing gender-specific lipid metabolites and diagnostic biomarkers for lung cancer using Fourier transform ion cyclotron resonance mass spectrometry. Clin. Chim. Acta 2012, 414, 135–141. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Ma, Z.; Min, L.; Li, H.; Wang, B.; Zhong, J.; Dai, L. Biomarker identification and pathway analysis by serum metabolomics of lung cancer. BioMed Res. Int. 2015, 2015, 183624. [Google Scholar] [CrossRef] [PubMed]
- Widłak, P.; Jelonek, K.; Kurczyk, A.; Żyła, J.; Sitkiewicz, M.; Bottoni, E.; Veronesi, G.; Polańska, J.; Rzyman, W. Serum Metabolite Profiles in Participants of Lung Cancer Screening Study; Comparison of Two Independent Cohorts. Cancers 2021, 13, 2714. [Google Scholar] [CrossRef] [PubMed]
- Binczyk, F.; Prazuch, W.; Bozek, P.; Polanska, J. Radiomics and artificial intelligence in lung cancer screening. Transl. Lung Cancer Res. 2021, 10, 1186–1199. [Google Scholar] [CrossRef]
- Prazuch, W.; Jelitto-Gorska, M.; Durawa, A.; Dziadziuszko, K.; Polanska, J. Radiomic-Based Lung Nodule Classification in Low-Dose Computed Tomography. In International Work-Conference on Bioinformatics and Biomedical Engineering; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Van Griethuysen, J.J.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.; Fillion-Robin, J.C.; Pieper, S.; Aerts, H.J. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B (Methodol.) 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Stouffer, S.A.; Suchman, E.A.; DeVinney, L.C.; Star, S.A.; Williams, R.M., Jr. The American Soldier: Adjustment during Army Life. (Studies in Social Psychology in World War II); Princeton University Press: Princeton, NJ, USA, 1949; Volume 1, pp. 87–90. [Google Scholar]
- Mohandes, M.; Deriche, M.; Saliyu, O.A. Classifiers combination techniques: A comprehensive review. IEEE Access 2018, 6, 19626–19639. [Google Scholar] [CrossRef]
- Klupczynska, A.; Dereziński, P.; Garrett, T.J.; Rubio, V.Y.; Dyszkiewicz, W.; Kasprzyk, M.; Kokot, Z.J. Study of early stage non-small-cell lung cancer using Orbitrap-based global serum metabolomics. J. Cancer Res. Clin. Oncol. 2017, 143, 649–659. [Google Scholar] [CrossRef] [PubMed]
- Tse, R.T.H.; Wong, C.Y.P.; Chiu, P.K.F.; Ng, C.F. The Potential Role of Spermine and Its Acetylated Derivative in Human Malignancies. Int. J. Mol. Sci. 2022, 23, 1258. [Google Scholar] [CrossRef] [PubMed]
- Thattaamuriyil Padmakumari, L.; Guido, G.; Caruso, D.; Nacci, I.; Del Gaudio, A.; Zerunian, M.; Polici, M.; Gopalakrishnan, R.; Sayed Mohamed, A.K.; De Santis, D.; et al. The role of chest CT radiomics in diagnosis of lung cancer or tuberculosis: A pilot study. Diagnostics 2022, 12, 739. [Google Scholar] [CrossRef] [PubMed]
- Barabino, E.; Rossi, G.; Pamparino, S.; Fiannacca, M.; Caprioli, S.; Fedeli, A.; Zullo, L.; Vagge, S.; Cittadini, G.; Genova, C. Exploring response to immunotherapy in non-small cell lung cancer using delta-radiomics. Cancers 2022, 14, 350. [Google Scholar] [CrossRef]
- Permuth, J.B.; Choi, J.; Balarunathan, Y.; Kim, J.; Chen, D.T.; Chen, L.; Orcutt, S.; Doepker, M.P.; Gage, K.; Zhang, G.; et al. Combining radiomic features with a miRNA classifier may improve prediction of malignant pathology for pancreatic intraductal papillary mucinous neoplasms. Oncotarget 2016, 7, 85785. [Google Scholar] [CrossRef]
- Gong, J.W.; Zhang, Z.; Luo, T.Y.; Huang, X.T.; Zhu, C.N.; Lv, J.W.; Li, Q. Combined model of radiomics, clinical, and imaging features for differentiating focal pneumonia-like lung cancer from pulmonary inflammatory lesions: An exploratory study. BMC Med. Imaging 2022, 22, 98. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Radiomics | Metabolomics | |
|---|---|---|
| Benign nodules | ||
| n | 994 (75%) | 123 (50%) |
| Screening program | ||
| PPPBWWRP | 906 (91%) | 0 (0%) |
| MOLTEST BIS | 88 (9%) | 123 (100%) |
| Sex: male/female | 445/549 (45%/55%) | 66/57 (54%/46%) |
| Age years: (median) | NA | 51–79 (67) |
| Smoking pack-year: range (median) | NA | 26–133 (43) |
| Malignant nodules (lung cancer) | ||
| n | 331 (25%) | 123 (50%) |
| Screening program | ||
| PPPBWWRP | 258 (78%) | 0 (0%) |
| MOLTEST BIS | 73 (22%) | 123 (100%) |
| Sex: male/female | 136/195 (41%/59%) | 67/56 (54%/46%) |
| Age years: range (median) | NA | 53–79 (67) |
| Smoking pack-year: range (median) | NA | 24–138 (48) |
| Clinical stage: | ||
| IA | NA | 49 |
| IB | NA | 10 |
| IIA | NA | 9 |
| IIB | NA | 10 |
| IIIA | NA | 17 |
| IIIB | NA | 7 |
| IVA | NA | 16 |
| IVB | NA | 5 |
| Radiomics | Metabolomics | Common | |
|---|---|---|---|
| Train | |||
| Benign | 4569 | 103 | 68 |
| Malignant | 440 | 103 | 53 |
| N | 5009 | 206 | 121 |
| Test | |||
| Benign | 122 | 20 | 20 |
| Malignant | 49 | 20 | 20 |
| N | 171 | 40 | 40 |
| Metric | Radiomics | Metabolomics | Statistical Integration | Product Integration | ||||
|---|---|---|---|---|---|---|---|---|
| LR | RF | LR | RF | LR | RF | LR | RF | |
| Sensitivity | 0.60 | 0.70 | 0.55 | 0.70 | 0.70 | 0.75 | 0.78 | 0.63 |
| Specificity | 0.85 | 0.70 | 0.55 | 0.55 | 0.80 | 0.60 | 0.73 | 0.69 |
| PPV | 0.80 | 0.70 | 0.55 | 0.61 | 0.78 | 0.65 | 0.70 | 0.75 |
| NPV | 0.68 | 0.70 | 0.55 | 0.65 | 0.73 | 0.71 | 0.80 | 0.55 |
| F1 | 0.69 | 0.70 | 0.55 | 0.65 | 0.74 | 0.70 | 0.74 | 0.68 |
| Balanced accuracy | 0.73 | 0.70 | 0.55 | 0.63 | 0.75 | 0.68 | 0.75 | 0.66 |
| AUC (%) | 83.0 | 70.3 | 55.5 | 60.3 | 83.0 | 73.0 | 84.8 | 71.5 |
| AUC 95% CI | 70–96 | 53–87 | 38–74 | 42–79 | 70–96 | 56–89 | 73–97 | 55–88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zyla, J.; Marczyk, M.; Prazuch, W.; Sitkiewicz, M.; Durawa, A.; Jelitto, M.; Dziadziuszko, K.; Jelonek, K.; Kurczyk, A.; Szurowska, E.; et al. Combining Low-Dose Computer-Tomography-Based Radiomics and Serum Metabolomics for Diagnosis of Malignant Nodules in Participants of Lung Cancer Screening Studies. Biomolecules 2024, 14, 44. https://doi.org/10.3390/biom14010044
Zyla J, Marczyk M, Prazuch W, Sitkiewicz M, Durawa A, Jelitto M, Dziadziuszko K, Jelonek K, Kurczyk A, Szurowska E, et al. Combining Low-Dose Computer-Tomography-Based Radiomics and Serum Metabolomics for Diagnosis of Malignant Nodules in Participants of Lung Cancer Screening Studies. Biomolecules. 2024; 14(1):44. https://doi.org/10.3390/biom14010044
Chicago/Turabian StyleZyla, Joanna, Michal Marczyk, Wojciech Prazuch, Magdalena Sitkiewicz, Agata Durawa, Malgorzata Jelitto, Katarzyna Dziadziuszko, Karol Jelonek, Agata Kurczyk, Edyta Szurowska, and et al. 2024. "Combining Low-Dose Computer-Tomography-Based Radiomics and Serum Metabolomics for Diagnosis of Malignant Nodules in Participants of Lung Cancer Screening Studies" Biomolecules 14, no. 1: 44. https://doi.org/10.3390/biom14010044
APA StyleZyla, J., Marczyk, M., Prazuch, W., Sitkiewicz, M., Durawa, A., Jelitto, M., Dziadziuszko, K., Jelonek, K., Kurczyk, A., Szurowska, E., Rzyman, W., Widłak, P., & Polanska, J. (2024). Combining Low-Dose Computer-Tomography-Based Radiomics and Serum Metabolomics for Diagnosis of Malignant Nodules in Participants of Lung Cancer Screening Studies. Biomolecules, 14(1), 44. https://doi.org/10.3390/biom14010044