



Identification of the Subtypes of Renal Ischemia-Reperfusion Injury Based on Pyroptosis-Related Genes

Abstract
:1. Introduction
2. Methods
2.1. Nonnegative Matrix Factorization (NMF)
2.2. GraphNet Regularizer
2.3. Orthogonal Non-Negative Matrix Factorization Algorithm Based on Dual Laplace Regularization Constraint (DL-ONMF)
2.4. Definition of Reconstruction Performance of the NMF Algorithm
2.5. Silhouette Coefficient
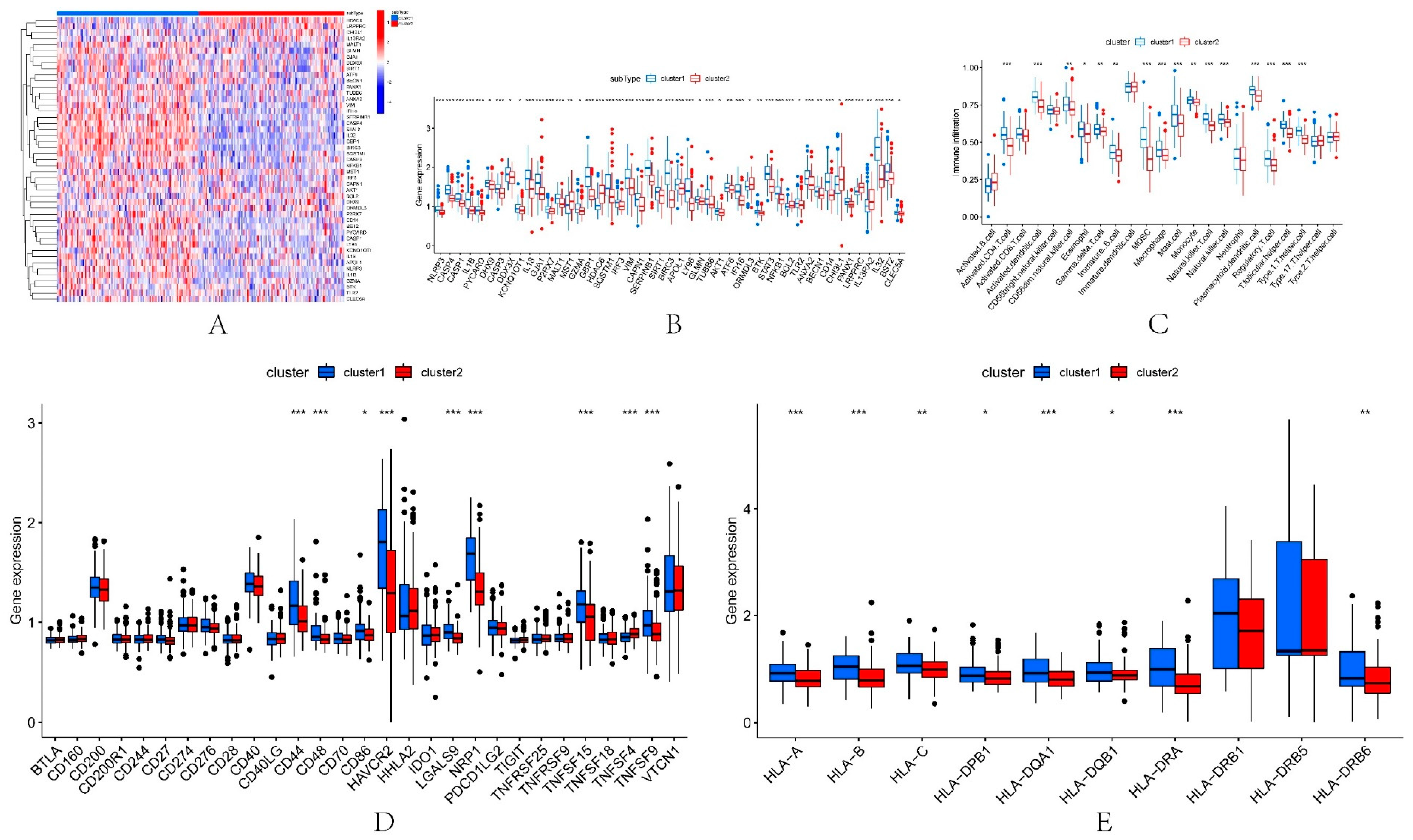
2.6. PRGs Expression before and after Renal Ischemia-Reperfusion
2.7. Enrichment Analysis and Immune Analysis of Different Clusters
2.8. Construction and Validation of Renal Transplantation Related Diagnostic Model
2.9. Construction of Nomogram
3. Results
3.1. Data Preprocess
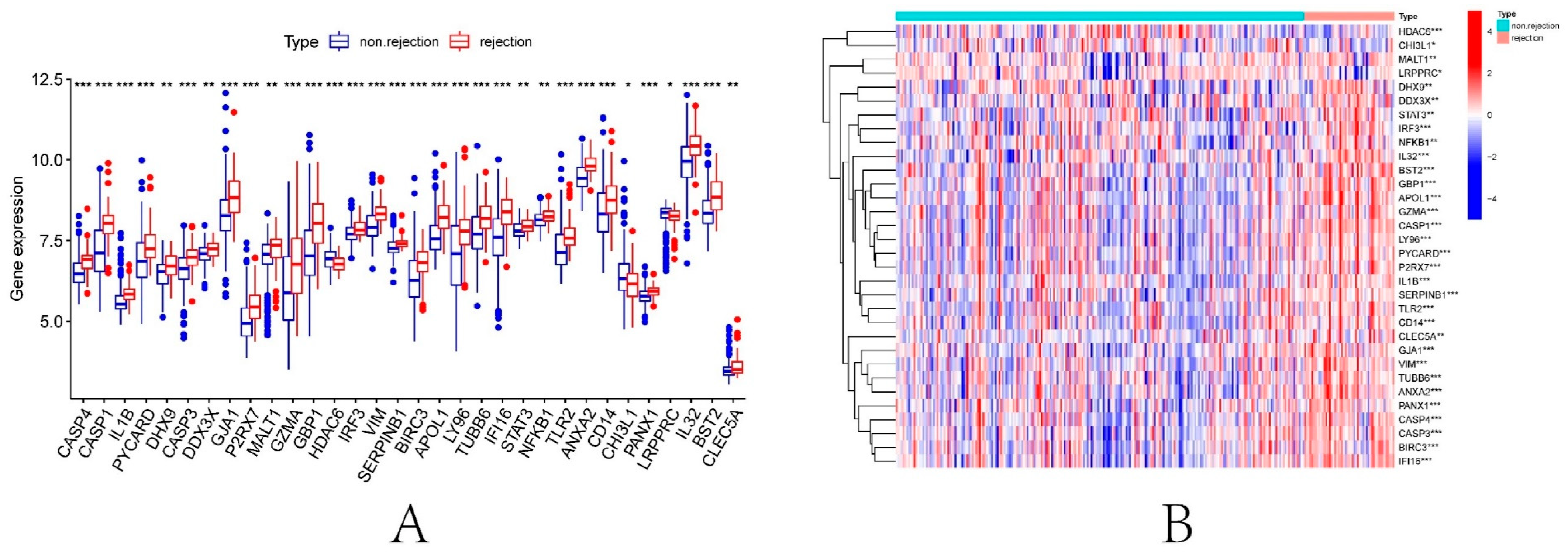
3.2. Identification of DEPRGs in Renal Ischemia-Reperfusion Injury
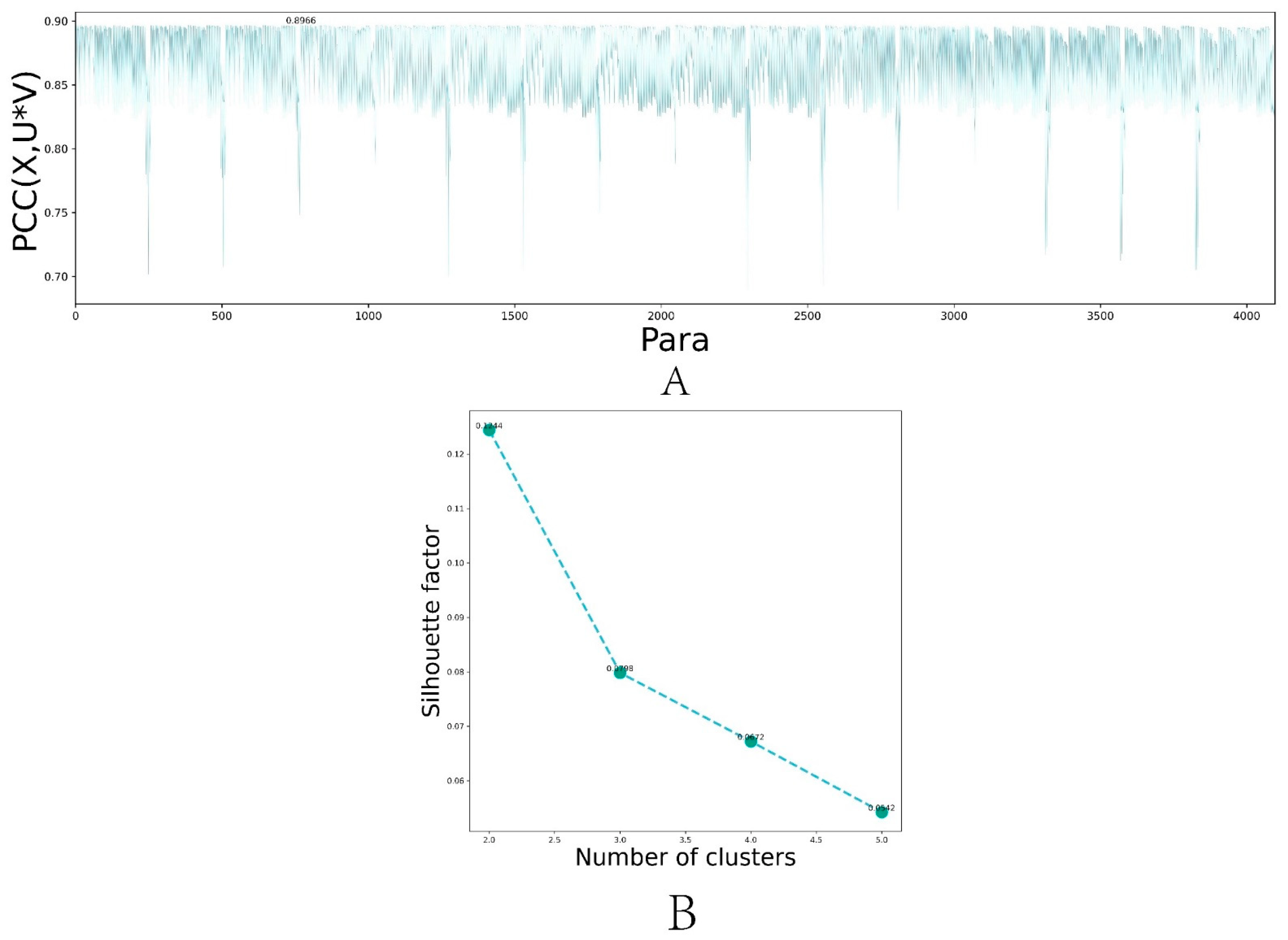
3.3. Selection of Hyperparameters for DL-ONMF Algorithm
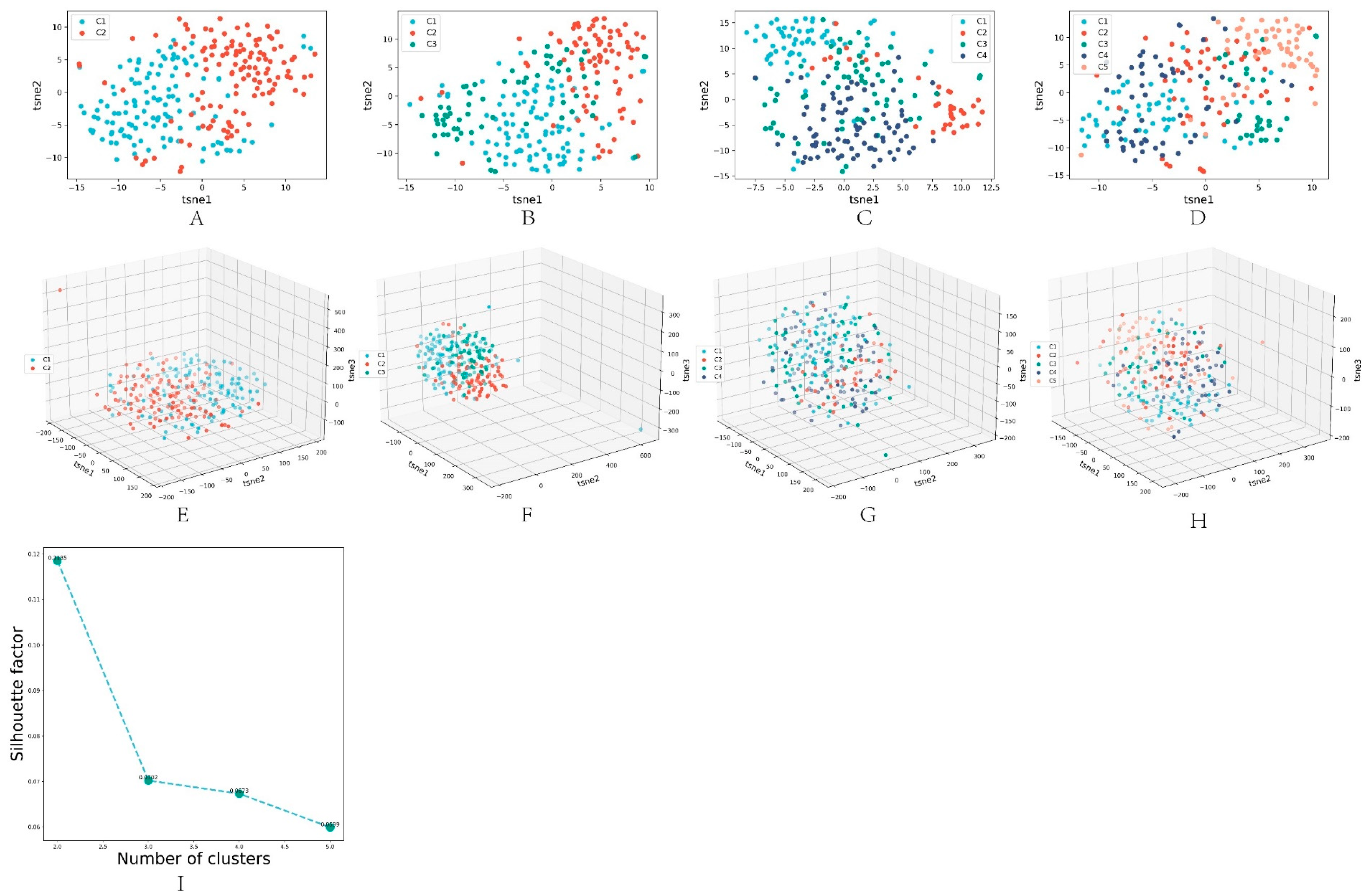
3.4. Algorithm Clustering Results
3.5. Comparison of Algorithm Performance
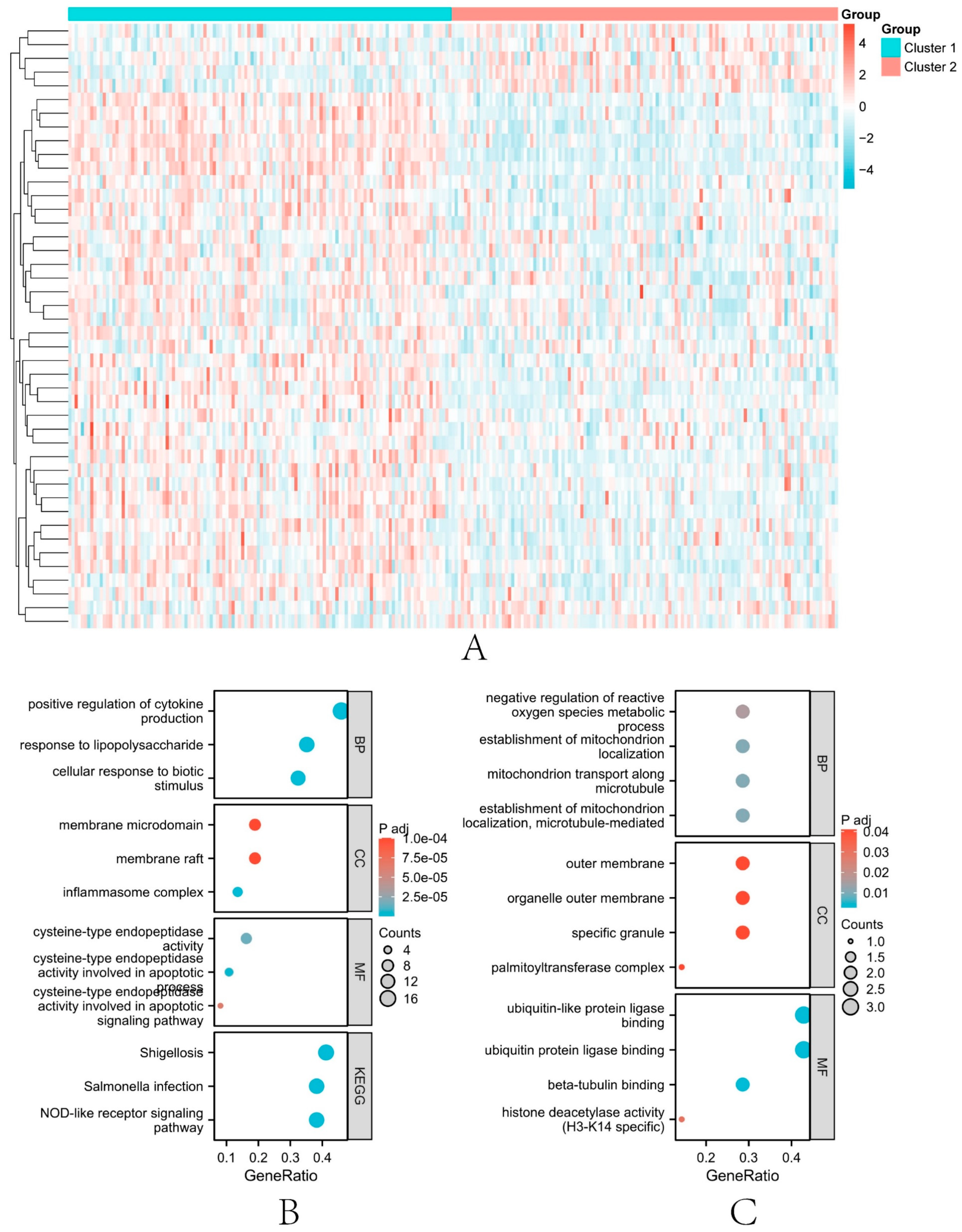
3.6. Subtype Analysis
3.7. Different Immune Characteristics among IRI Subtypes
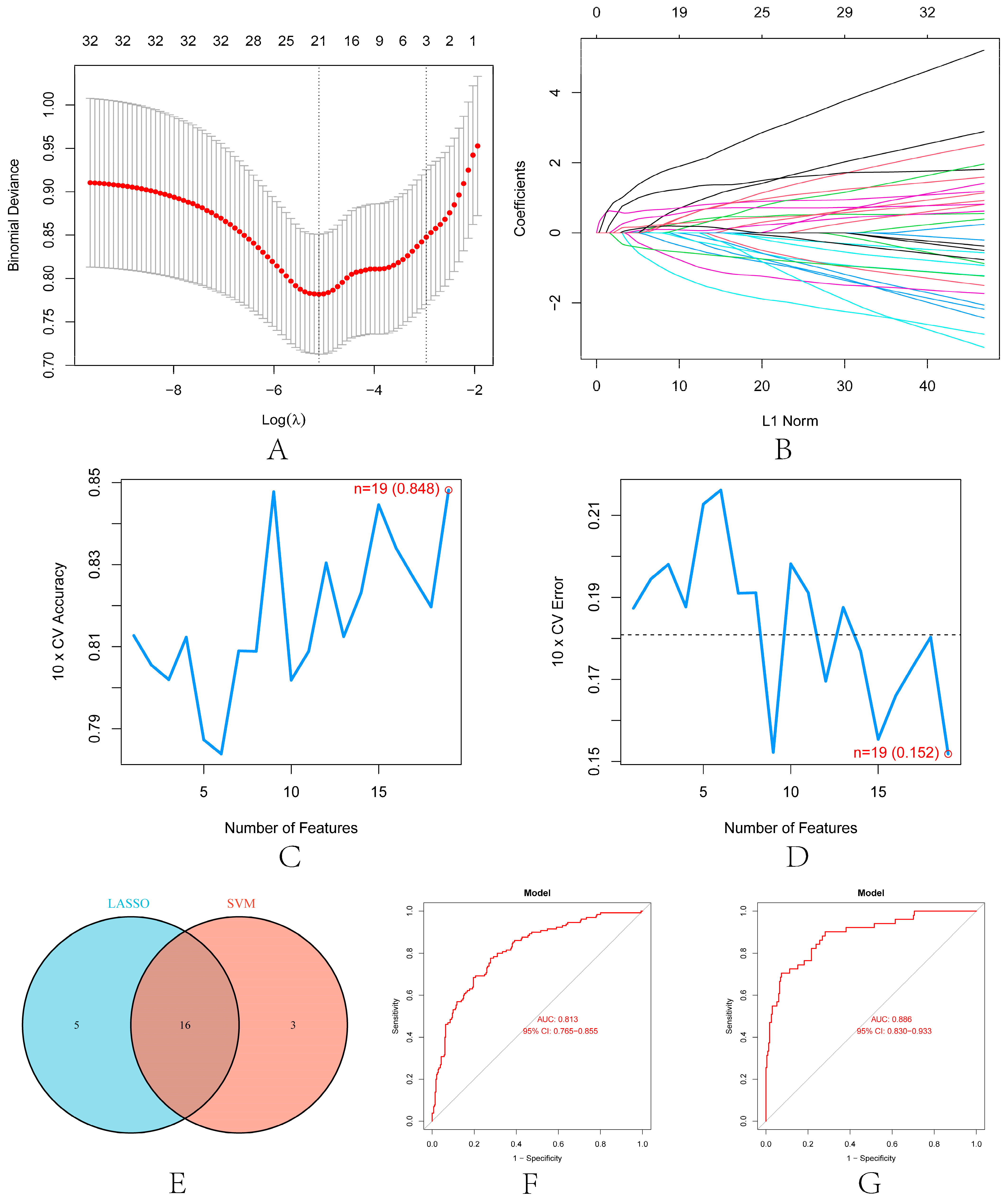
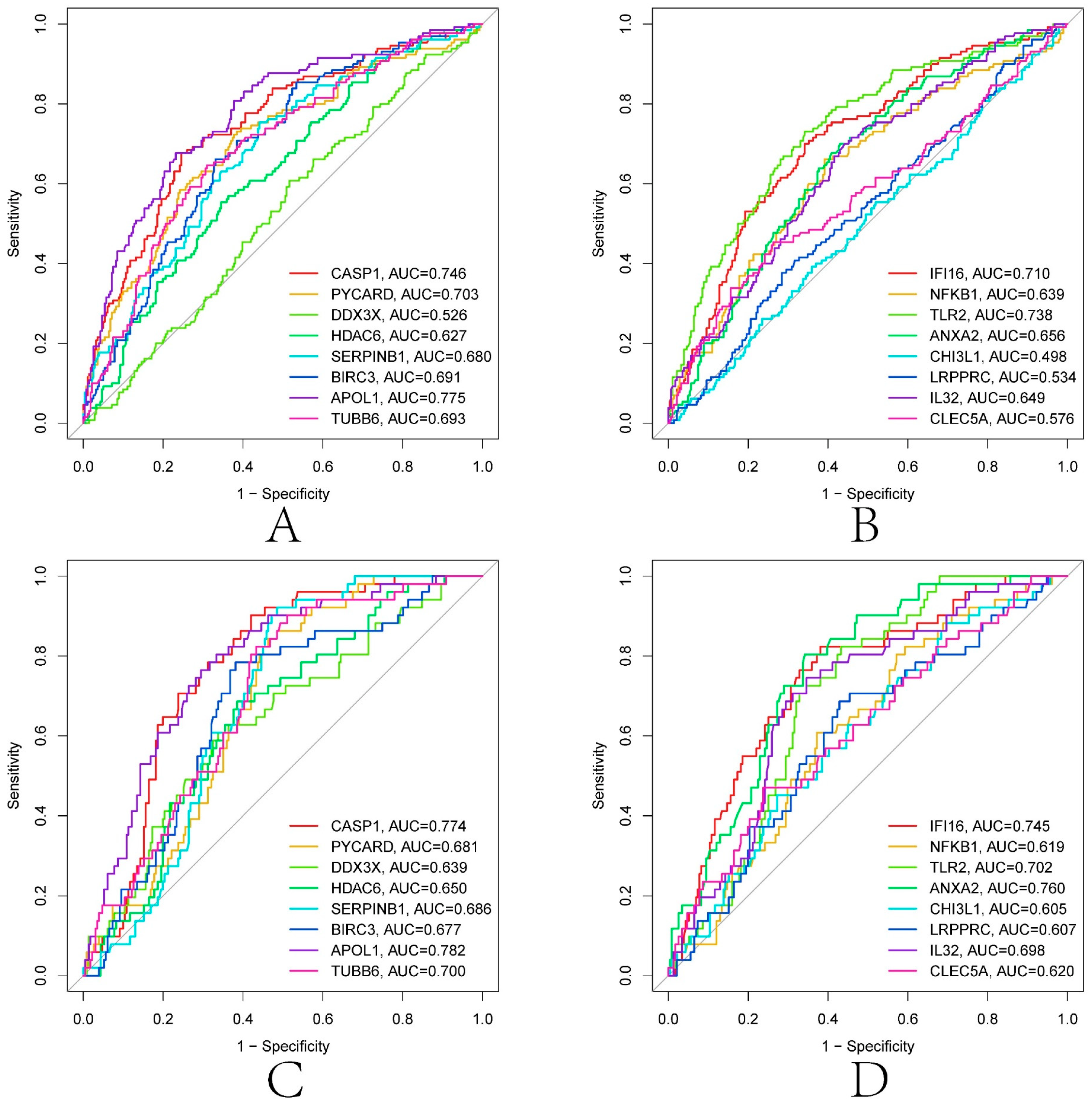
3.8. Construction of Renal Transplantation Related Diagnostic Model
3.9. Construction of Nomogram
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, M.-Y.; Yiang, G.-T.; Liao, W.-T.; Tsai, A.P.Y.; Cheng, Y.-L.; Cheng, P.-W.; Li, C.-Y.; Li, C.J. Current Mechanistic Concepts in Ischemia and Reperfusion Injury. Cell. Physiol. Biochem. 2018, 46, 1650–1667. [Google Scholar] [CrossRef]
- Hosszu, A.; Fekete, A.; Szabo, A.J. Sex differences in renal ischemia-reperfusion injury. Am. J. Physiol. Physiol. 2020, 319, F149–F154. [Google Scholar] [CrossRef]
- Wei, X.; Deng, W.; Dong, Z.; Xie, Z.; Zhang, J.; Wang, R.; Zhang, R.; Na, N.; Zhou, Y. Identification of Subtypes and a Delayed Graft Function Predictive Signature Based on Ferroptosis in Renal Ischemia-Reperfusion Injury. Front. Cell Dev. Biol. 2022, 10, 800650. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wei, X.; Tang, Z.; Miao, B.; Luo, Y.; Hu, X.; Luo, Y.; Zhou, Y.; Na, N. Elucidating the molecular pathways and immune system transcriptome during ischemia-reperfusion injury in renal transplantation. Int. Immunopharmacol. 2020, 81, 106246. [Google Scholar] [CrossRef] [PubMed]
- Dou, M.; Ding, C.; Zheng, B.; Deng, G.; Zhu, K.; Xu, C.; Xue, W.; Ding, X.; Zheng, J.; Tian, P. Immune-Related Genes for Predicting Future Kidney Graft Loss: A Study Based on GEO Database. Front. Immunol. 2022, 13, 859693. [Google Scholar] [CrossRef] [PubMed]
- Eltzschig, H.K.; Eckle, T. Ischemia and reperfusion—From mechanism to translation. Nat. Med. 2011, 17, 1391–1401. [Google Scholar] [CrossRef] [PubMed]
- Ali, T.; Khan, I.; Simpson, W.; Prescott, G.; Townend, J.; Smith, W.; MacLeod, A. Incidence and Outcomes in Acute Kidney Injury: A Comprehensive Population-Based Study. J. Am. Soc. Nephrol. 2007, 18, 1292–1298. [Google Scholar] [CrossRef]
- Gong, J.; Li, R.; Chen, Y.; Zhuo, Z.; Chen, S.; Cao, J.; Zhang, Q.; Chong, Y.; Hu, B. HCC subtypes based on the activity changes of immunologic and hallmark gene sets in tumor and nontumor tissues. Brief. Bioinform. 2021, 22, bbaa427. [Google Scholar] [CrossRef]
- Winterhoff, B.; Hamidi, H.; Wang, C.; Kalli, K.R.; Fridley, B.L.; Dering, J.; Chen, H.-W.; Cliby, W.A.; Wang, H.-J.; Dowdy, S.; et al. Molecular classification of high grade endometrioid and clear cell ovarian cancer using TCGA gene expression signatures. Gynecol. Oncol. 2016, 141, 95–100. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.; Xu, N.; Yang, J.; Li, B.; Shi, J.; Zheng, Y.; Xu, L. Identification of an immune subtype predicting survival risk and immune activity in hepatocellular carcinoma. Aging 2021, 13, 202953. [Google Scholar] [CrossRef]
- Zheng, C.; Xu, R. Molecular subtyping of Alzheimer’s disease with consensus non-negative matrix factorization. PLoS ONE 2021, 16, e0250278. [Google Scholar] [CrossRef] [PubMed]
- Lin, X.; Zhou, T.; Hu, S.; Yang, L.; Yang, Z.; Pang, H.; Zhou, X.; Zhong, R.; Fang, X.; Yu, Z.; et al. Prognostic significance of pyroptosis-related factors in lung adenocarcinoma. J. Thorac. Dis. 2022, 14, 654–667. [Google Scholar] [CrossRef]
- Luxburg, U.V. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Jang, H.R.; Ko, G.J.; Wasowska, B.A.; Rabb, H. The interaction between ischemia–reperfusion and immune responses in the kidney. J. Mol. Med. 2009, 87, 859–864. [Google Scholar] [CrossRef] [PubMed]
- Ismail, O.Z.; Zhang, X.; Bonventre, J.V.; Gunaratnam, L. G protein α12(Gα12) is a negative regulator of kidney injury molecule-1-mediated efferocytosis. Am. J. Physiol. Physiol. 2016, 310, F607–F620. [Google Scholar] [CrossRef]
- Wyant, G.A.; Yu, W.; Doulamis, I.P.; Nomoto, R.S.; Saeed, M.Y.; Duignan, T.; McCully, J.D.; Kaelin, W.G. Mitochondrial remodeling and ischemic protection by G protein–coupled receptor 35 agonists. Science 2022, 377, 621–629. [Google Scholar] [CrossRef]
- Rae, F.K.; Suhaimi, N.; Li, J.; Nastasi, T.; Slonimsky, E.; Rosenthal, N.; Little, M.H. Proximal tubule overexpression of a locally acting IGF isoform, Igf-1Ea, increases inflammation after ischemic injury. Growth Horm. IGF Res. 2012, 22, 6–16. [Google Scholar] [CrossRef]
- Turner, C.M.; Arulkumaran, N.; Singer, M.; Unwin, R.J.; Tam, F.W. Is the inflammasome a potential therapeutic target in renal disease? BMC Nephrol. 2014, 15, 21. [Google Scholar] [CrossRef]
- Kolachala, V.L.; Lopez, C.; Shen, M.; Shayakhmetov, D.; Gupta, N.A. Ischemia reperfusion injury induces pyroptosis and mediates injury in steatotic liver thorough Caspase 1 activation. Apoptosis 2021, 26, 361–370. [Google Scholar] [CrossRef]
- Yuan, H.; Li, H.; Yu, P.; Fan, Q.; Zhang, X.; Huang, W.; Shen, J.; Cui, Y.; Zhou, W. Involvement of HDAC6 in ischaemia and reperfusion-induced rat retinal injury. BMC Ophthalmol. 2018, 18, 300. [Google Scholar] [CrossRef]
- Arslan, F.; Keogh, B.; McGuirk, P.; Parker, A.E. TLR2 and TLR4 in Ischemia Reperfusion Injury. Mediat. Inflamm. 2010, 2010, 704202. [Google Scholar] [CrossRef] [PubMed]
- Grigoryev, D.N.; Cheranova, D.I.; Heruth, D.P.; Huang, P.; Zhang, L.Q.; Rabb, H.; Ye, S.Q. Meta-analysis of molecular response of kidney to ischemia reperfusion injury for the identification of new candidate genes. BMC Nephrol. 2013, 14, 231. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.; Cai, L.; Wang, F.; Huang, J.; Wang, H.; Li, L.; Lv, H. RETRACTED: Upregulated microRNA-381-5p strengthens the effect of dexmedetomidine preconditioning to protect against myocardial ischemia–reperfusion injury in mouse models by inhibiting CHI3L1. Int. Immunopharmacol. 2021, 92, 107326. [Google Scholar] [CrossRef]
- Zhou, R.; Guo, F.; Xiang, C.; Zhang, Y.; Yang, H.; Zhang, J. Systematic Study of Crucial Transcription Factors of Coptidis rhizoma Alkaloids against Cerebral Ischemia-Reperfusion Injury. ACS Chem. Neurosci. 2021, 12, 2308–2319. [Google Scholar] [CrossRef] [PubMed]
- Asmussen, A.; Fink, K.; Busch, H.-J.; Helbing, T.; Bourgeois, N.; Bode, C.; Grundmann, S. Inflammasome and toll-like receptor signaling in human monocytes after successful cardiopulmonary resuscitation. Crit. Care 2016, 20, 170. [Google Scholar] [CrossRef]
- Kireev, R.A.; Cuesta, S.; Ibarrola, C.; Bela, T.; Gonzalez, E.M.; Vara, E.; Tresguerres, J.A. Age-related differences in hepatic ischemia/reperfusion: Gene activation, liver injury, and protective effect of melatonin. J. Surg. Res. 2012, 178, 922–934. [Google Scholar] [CrossRef]
- Ramirez-Carracedo, R.; Tesoro, L.; Hernandez, I.; Diez-Mata, J.; Piñeiro, D.; Hernandez-Jimenez, M.; Zamorano, J.L.; Zaragoza, C. Targeting TLR4 with ApTOLL Improves Heart Function in Response to Coronary Ischemia Reperfusion in Pigs Undergoing Acute Myocardial Infarction. Biomolecules 2020, 10, 1167. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Reconstruction Performance | Reconstruction Error |
|---|---|---|
| NMF | 0.8955 | 8.2945 |
| DL-ONMF | 0.8964 | 8.2773 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, X.; Cheuk, Y.C.; Li, X.; Rong, R.; Xu, X.; Xu, C.; Luo, Y.; Zhang, P.; Guo, J. Identification of the Subtypes of Renal Ischemia-Reperfusion Injury Based on Pyroptosis-Related Genes. Biomolecules 2023, 13, 275. https://doi.org/10.3390/biom13020275
Niu X, Cheuk YC, Li X, Rong R, Xu X, Xu C, Luo Y, Zhang P, Guo J. Identification of the Subtypes of Renal Ischemia-Reperfusion Injury Based on Pyroptosis-Related Genes. Biomolecules. 2023; 13(2):275. https://doi.org/10.3390/biom13020275
Chicago/Turabian StyleNiu, Xinhao, Yin Celeste Cheuk, Xiao Li, Ruiming Rong, Xiaoqing Xu, Cuidi Xu, Yongsheng Luo, Pingbao Zhang, and Jingjing Guo. 2023. "Identification of the Subtypes of Renal Ischemia-Reperfusion Injury Based on Pyroptosis-Related Genes" Biomolecules 13, no. 2: 275. https://doi.org/10.3390/biom13020275
APA StyleNiu, X., Cheuk, Y. C., Li, X., Rong, R., Xu, X., Xu, C., Luo, Y., Zhang, P., & Guo, J. (2023). Identification of the Subtypes of Renal Ischemia-Reperfusion Injury Based on Pyroptosis-Related Genes. Biomolecules, 13(2), 275. https://doi.org/10.3390/biom13020275