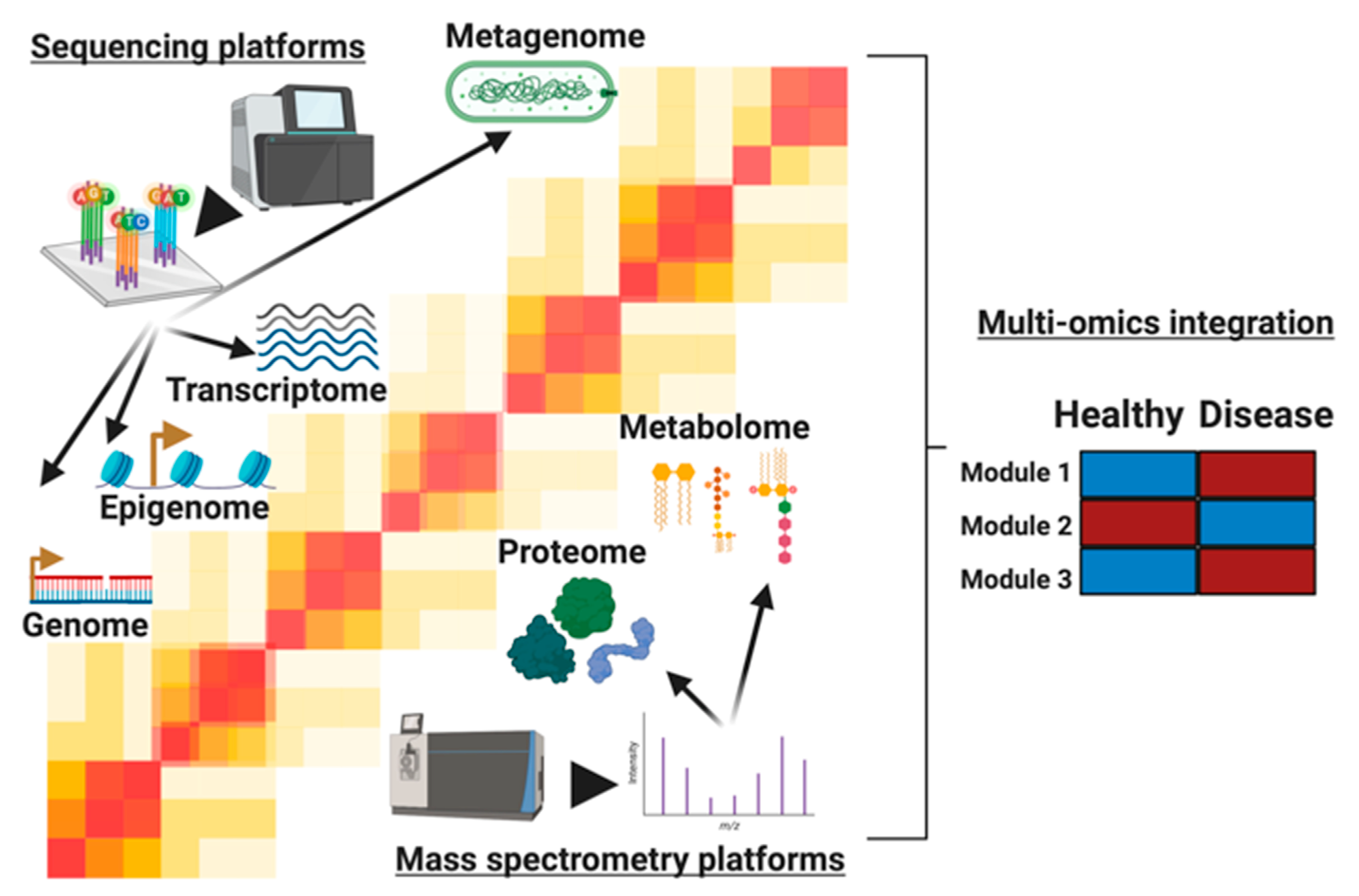
A Customizable Analysis Flow in Integrative Multi-Omics

{kind=link}
{kind=link}
Abstract
1. Introduction
2. Analysis of Single Omics Prior to Integration
2.1. Genome Analysis
2.2. Epigenomic Analysis
2.3. Transcriptome Analysis
2.4. Metagenomic Analysis
2.5. Mass Spectrometry for Biomolecules
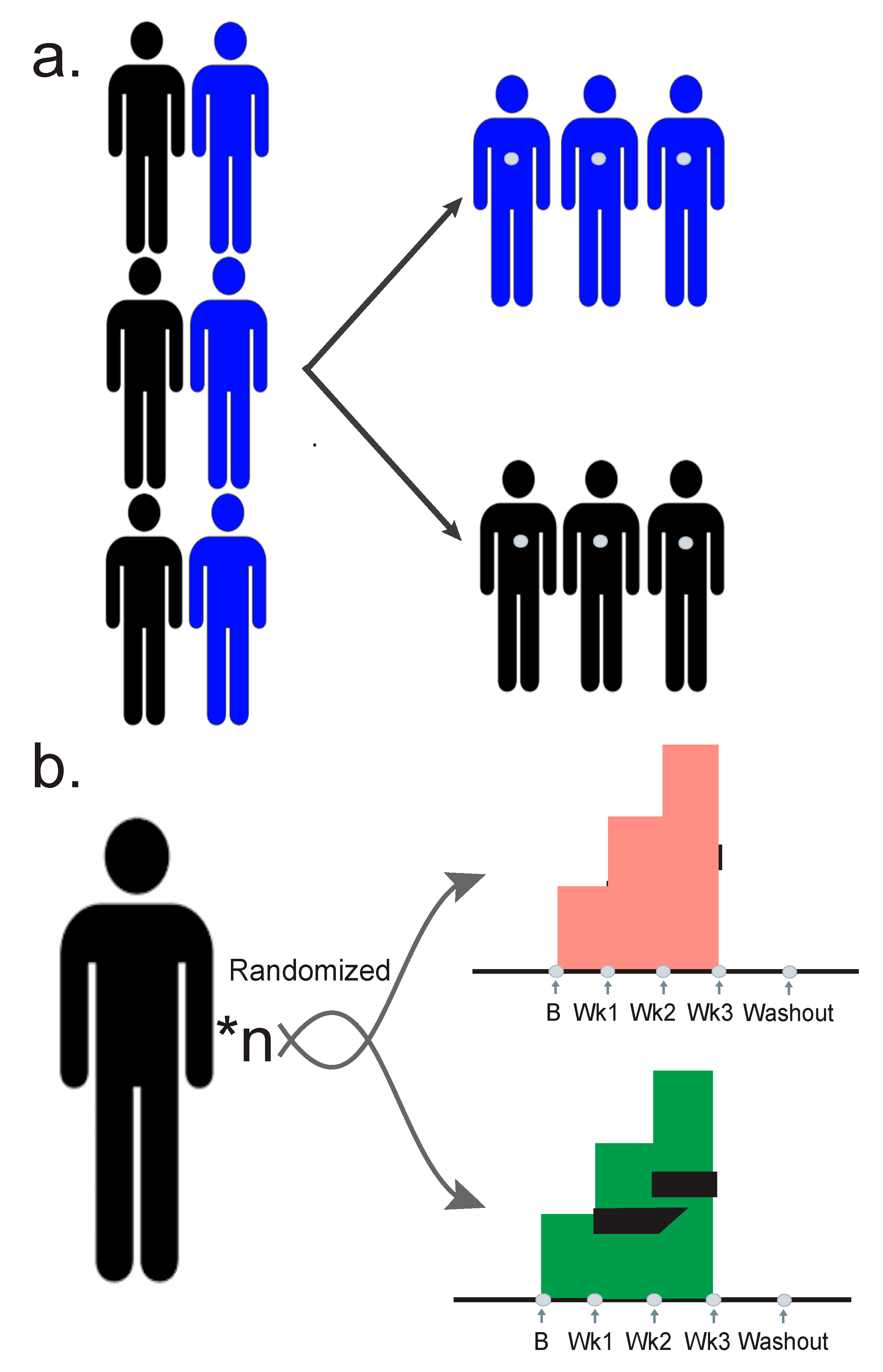
3. Designing a Quality Study
4. Analysis Methods for Multi-Omic Integration
4.1. Dimensionality Reduction
4.2. Normalizing the Data
4.3. Correlation Networks Analyses
4.4. Cross-Sectional Analyses and Testing Categorical Variables
4.5. Testing along Continuous Variables
4.6. Clustering Algorithms
4.7. Feature Selection for Covarying Analytes
4.8. Machine Learning
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Venter, J.C.; Adams, M.D.; Myers, E.W.; Li, P.W.; Mural, R.J.; Sutton, G.G.; Smith, H.O.; Yandell, M.; Evans, C.A.; Holt, R.A.; et al. The sequence of the human genome. Science 2001, 291, 1304–1351. [Google Scholar] [CrossRef]
- Hatfull, G.F. Bacteriophage genomics. Curr. Opin. Microbiol. 2008, 11, 447–453. [Google Scholar] [CrossRef]
- Anders, S.; Huber, W. Differential expression analysis for sequence count data. Genome Biol. 2010, 11, R106. [Google Scholar] [CrossRef]
- Segata, N.; Waldron, L.; Ballarini, A.; Narasimhan, V.; Jousson, O.; Huttenhower, C. Metagenomic microbial community profiling using unique clade-specific marker genes. Nat. Methods 2012, 9, 811–814. [Google Scholar] [CrossRef]
- Ewing, B.; Hillier, L.; Wendl, M.C.; Green, P. Base-calling of automated sequencer traces using phred. I. Accuracy assessment. Genome Res 1998, 8, 175–185. [Google Scholar] [CrossRef]
- Khan, A.R.; Pervez, M.T.; Babar, M.E.; Naveed, N.; Shoaib, M. A Comprehensive Study of De Novo Genome Assemblers: Current Challenges and Future Prospective. Evol. Bioinform Online 2018, 14, 1176934318758650. [Google Scholar] [CrossRef]
- Li, H.; Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 2009, 25, 1754–1760. [Google Scholar] [CrossRef]
- Langmead, B.; Salzberg, S.L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 2012, 9, 357–359. [Google Scholar] [CrossRef]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R.; Genome Project Data Processing Subgroup. The Sequence Alignment/Map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [PubMed]
- Danecek, P.; Auton, A.; Abecasis, G.; Albers, C.A.; Banks, E.; DePristo, M.A.; Handsaker, R.E.; Lunter, G.; Marth, G.T.; Sherry, S.T.; et al. The variant call format and VCFtools. Bioinformatics 2011, 27, 2156–2158. [Google Scholar] [CrossRef]
- Roadmap Epigenomics Consortium; Kundaje, A.; Meuleman, W.; Ernst, J.; Bilenky, M.; Yen, A.; Heravi-Moussavi, A.; Kheradpour, P.; Zhang, Z.; Wang, J.; et al. Integrative analysis of 111 reference human epigenomes. Nature 2015, 518, 317–330. [Google Scholar] [CrossRef]
- Mouse, E.C.; Stamatoyannopoulos, J.A.; Snyder, M.; Hardison, R.; Ren, B.; Gingeras, T.; Gilbert, D.M.; Groudine, M.; Bender, M.; Kaul, R.; et al. An encyclopedia of mouse DNA elements (Mouse ENCODE). Genome Biol. 2012, 13, 418. [Google Scholar] [CrossRef] [PubMed]
- Buenrostro, J.D.; Giresi, P.G.; Zaba, L.C.; Chang, H.Y.; Greenleaf, W.J. Transposition of native chromatin for fast and sensitive epigenomic profiling of open chromatin, DNA-binding proteins and nucleosome position. Nat. Methods 2013, 10, 1213–1218. [Google Scholar] [CrossRef] [PubMed]
- Corces, M.R.; Trevino, A.E.; Hamilton, E.G.; Greenside, P.G.; Sinnott-Armstrong, N.A.; Vesuna, S.; Satpathy, A.T.; Rubin, A.J.; Montine, K.S.; Wu, B.; et al. An improved ATAC-seq protocol reduces background and enables interrogation of frozen tissues. Nat. Methods 2017, 14, 959–962. [Google Scholar] [CrossRef] [PubMed]
- Feng, J.; Liu, T.; Qin, B.; Zhang, Y.; Liu, X.S. Identifying ChIP-seq enrichment using MACS. Nat. Protoc. 2012, 7, 1728–1740. [Google Scholar] [CrossRef] [PubMed]
- Yan, F.; Powell, D.R.; Curtis, D.J.; Wong, N.C. From reads to insight: A hitchhiker’s guide to ATAC-seq data analysis. Genome Biol. 2020, 21, 22. [Google Scholar] [CrossRef] [PubMed]
- Dobin, A.; Davis, C.A.; Schlesinger, F.; Drenkow, J.; Zaleski, C.; Jha, S.; Batut, P.; Chaisson, M.; Gingeras, T.R. STAR: Ultrafast universal RNA-seq aligner. Bioinformatics 2013, 29, 15–21. [Google Scholar] [CrossRef]
- Consortium, E.P. An integrated encyclopedia of DNA elements in the human genome. Nature 2012, 489, 57–74. [Google Scholar] [CrossRef]
- Bray, N.L.; Pimentel, H.; Melsted, P.; Pachter, L. Near-optimal probabilistic RNA-seq quantification. Nat. Biotechnol. 2016, 34, 525–527. [Google Scholar] [CrossRef]
- Patro, R.; Duggal, G.; Love, M.I.; Irizarry, R.A.; Kingsford, C. Salmon provides fast and bias-aware quantification of transcript expression. Nat. Methods 2017, 14, 417–419. [Google Scholar] [CrossRef]
- Robinson, M.D.; McCarthy, D.J.; Smyth, G.K. edgeR: A Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics 2010, 26, 139–140. [Google Scholar] [CrossRef]
- Ritchie, M.E.; Phipson, B.; Wu, D.; Hu, Y.; Law, C.W.; Shi, W.; Smyth, G.K. Limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015, 43, e47. [Google Scholar] [CrossRef]
- Soneson, C.; Love, M.I.; Robinson, M.D. Differential analyses for RNA-seq: Transcript-level estimates improve gene-level inferences. F1000Research 2015, 4, 1521. [Google Scholar] [CrossRef] [PubMed]
- Johnson, W.E.; Li, C.; Rabinovic, A. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics 2007, 8, 118–127. [Google Scholar] [CrossRef] [PubMed]
- Robinson, M.D.; Oshlack, A. A scaling normalization method for differential expression analysis of RNA-seq data. Genome Biol. 2010, 11, R25. [Google Scholar] [CrossRef] [PubMed]
- da Huang, W.; Sherman, B.T.; Lempicki, R.A. Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nat. Protoc. 2009, 4, 44–57. [Google Scholar] [CrossRef] [PubMed]
- Eden, E.; Navon, R.; Steinfeld, I.; Lipson, D.; Yakhini, Z. GOrilla: A tool for discovery and visualization of enriched GO terms in ranked gene lists. BMC Bioinform. 2009, 10, 48. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.M.; Shafi, A.; Nguyen, T.; Draghici, S. Identifying significantly impacted pathways: A comprehensive review and assessment. Genome Biol. 2019, 20, 203. [Google Scholar] [CrossRef] [PubMed]
- Vallania, F.; Tam, A.; Lofgren, S.; Schaffert, S.; Azad, T.D.; Bongen, E.; Haynes, W.; Alsup, M.; Alonso, M.; Davis, M.; et al. Leveraging heterogeneity across multiple datasets increases cell-mixture deconvolution accuracy and reduces biological and technical biases. Nat. Commun. 2018, 9, 4735. [Google Scholar] [CrossRef]
- Chen, B.; Khodadoust, M.S.; Liu, C.L.; Newman, A.M.; Alizadeh, A.A. Profiling Tumor Infiltrating Immune Cells with CIBERSORT. Methods Mol. Biol. 2018, 1711, 243–259. [Google Scholar] [CrossRef]
- Franzosa, E.A.; McIver, L.J.; Rahnavard, G.; Thompson, L.R.; Schirmer, M.; Weingart, G.; Lipson, K.S.; Knight, R.; Caporaso, J.G.; Segata, N.; et al. Species-level functional profiling of metagenomes and metatranscriptomes. Nat. Methods 2018, 15, 962–968. [Google Scholar] [CrossRef] [PubMed]
- Wood, D.E.; Salzberg, S.L. Kraken: Ultrafast metagenomic sequence classification using exact alignments. Genome Biol. 2014, 15, R46. [Google Scholar] [CrossRef] [PubMed]
- Clarridge, J.E., 3rd. Impact of 16S rRNA gene sequence analysis for identification of bacteria on clinical microbiology and infectious diseases. Clin. Microbiol. Rev. 2004, 17, 840–862, table of contents. [Google Scholar] [CrossRef] [PubMed]
- Woese, C.R.; Fox, G.E. Phylogenetic structure of the prokaryotic domain: The primary kingdoms. Proc. Natl. Acad. Sci. USA 1977, 74, 5088–5090. [Google Scholar] [CrossRef] [PubMed]
- MacLean, B.; Tomazela, D.M.; Shulman, N.; Chambers, M.; Finney, G.L.; Frewen, B.; Kern, R.; Tabb, D.L.; Liebler, D.C.; MacCoss, M.J. Skyline: An open source document editor for creating and analyzing targeted proteomics experiments. Bioinformatics 2010, 26, 966–968. [Google Scholar] [CrossRef]
- Tyanova, S.; Temu, T.; Sinitcyn, P.; Carlson, A.; Hein, M.Y.; Geiger, T.; Mann, M.; Cox, J. The Perseus computational platform for comprehensive analysis of (prote)omics data. Nat. Methods 2016, 13, 731–740. [Google Scholar] [CrossRef]
- Rost, H.L.; Rosenberger, G.; Navarro, P.; Gillet, L.; Miladinovic, S.M.; Schubert, O.T.; Wolski, W.; Collins, B.C.; Malmstrom, J.; Malmstrom, L.; et al. OpenSWATH enables automated, targeted analysis of data-independent acquisition MS data. Nat. Biotechnol. 2014, 32, 219–223. [Google Scholar] [CrossRef]
- Liu, Y.; Buil, A.; Collins, B.C.; Gillet, L.C.; Blum, L.C.; Cheng, L.Y.; Vitek, O.; Mouritsen, J.; Lachance, G.; Spector, T.D.; et al. Quantitative variability of 342 plasma proteins in a human twin population. Mol. Syst. Biol. 2015, 11, 786. [Google Scholar] [CrossRef]
- Saigusa, D.; Okamura, Y.; Motoike, I.N.; Katoh, Y.; Kurosawa, Y.; Saijyo, R.; Koshiba, S.; Yasuda, J.; Motohashi, H.; Sugawara, J.; et al. Establishment of Protocols for Global Metabolomics by LC-MS for Biomarker Discovery. PLoS ONE 2016, 11, e0160555. [Google Scholar] [CrossRef]
- Fan, S.; Kind, T.; Cajka, T.; Hazen, S.L.; Tang, W.H.W.; Kaddurah-Daouk, R.; Irvin, M.R.; Arnett, D.K.; Barupal, D.K.; Fiehn, O. Systematic Error Removal Using Random Forest for Normalizing Large-Scale Untargeted Lipidomics Data. Anal. Chem. 2019, 91, 3590–3596. [Google Scholar] [CrossRef]
- Contrepois, K.; Mahmoudi, S.; Ubhi, B.K.; Papsdorf, K.; Hornburg, D.; Brunet, A.; Snyder, M. Cross-Platform Comparison of Untargeted and Targeted Lipidomics Approaches on Aging Mouse Plasma. Sci. Rep. 2018, 8, 17747. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Psychogios, N.; Young, N.; Wishart, D.S. MetaboAnalyst: A web server for metabolomic data analysis and interpretation. Nucleic Acids Res. 2009, 37, W652–W660. [Google Scholar] [CrossRef]
- Subramanian, I.; Verma, S.; Kumar, S.; Jere, A.; Anamika, K. Multi-omics Data Integration, Interpretation, and Its Application. Bioinform. Biol. Insights 2020, 14, 1177932219899051. [Google Scholar] [CrossRef] [PubMed]
- Misra, B.B.; Langefeld, C.D.; Olivier, M.; Cox, L.A. Integrated Omics: Tools, Advances, and Future Approaches. J. Mol. Endocrinol. 2018. [Google Scholar] [CrossRef] [PubMed]
- Gibbons, R.D.; Hedeker, D.; DuToit, S. Advances in analysis of longitudinal data. Annu. Rev. Clin. Psychol. 2010, 6, 79–107. [Google Scholar] [CrossRef]
- Caruana, E.J.; Roman, M.; Hernandez-Sanchez, J.; Solli, P. Longitudinal studies. J. Thorac. Dis. 2015, 7, E537–E540. [Google Scholar] [CrossRef]
- Huang, S.; Chaudhary, K.; Garmire, L.X. More Is Better: Recent Progress in Multi-Omics Data Integration Methods. Front. Genet. 2017, 8, 84. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Zhou, W.; Sailani, M.R.; Contrepois, K.; Zhou, Y.; Ahadi, S.; Leopold, S.R.; Zhang, M.J.; Rao, V.; Avina, M.; Mishra, T.; et al. Longitudinal multi-omics of host-microbe dynamics in prediabetes. Nature 2019, 569, 663–671. [Google Scholar] [CrossRef]
- Contrepois, K.; Wu, S.; Moneghetti, K.J.; Hornburg, D.; Ahadi, S.; Tsai, M.S.; Metwally, A.A.; Wei, E.; Lee-McMullen, B.; Quijada, J.V.; et al. Molecular Choreography of Acute Exercise. Cell 2020, 181, 1112–1130.e16. [Google Scholar] [CrossRef]
- Chen, R.; Mias, G.I.; Li-Pook-Than, J.; Jiang, L.; Lam, H.Y.; Chen, R.; Miriami, E.; Karczewski, K.J.; Hariharan, M.; Dewey, F.E.; et al. Personal omics profiling reveals dynamic molecular and medical phenotypes. Cell 2012, 148, 1293–1307. [Google Scholar] [CrossRef] [PubMed]
- Csardi, G.; Nepusz, T. The Igraph Software Package for Complex Network Research. InterJ. Complex Syst. 2006, 1695, 1–9. [Google Scholar]
- Handcock, M.S.; Hunter, D.R.; Butts, C.T.; Goodreau, S.M.; Morris, M. Statnet: Software Tools for the Representation, Visualization, Analysis and Simulation of Network Data. J. Stat. Softw. 2008, 24, 1548–7660. [Google Scholar] [CrossRef] [PubMed]
- Kumar, L.; Matthias, E. Mfuzz: A software package for soft clustering of microarray data. Bioinformation 2007, 2, 5–7. [Google Scholar] [CrossRef] [PubMed]
- Piening, B.D.; Zhou, W.; Contrepois, K.; Rost, H.; Gu Urban, G.J.; Mishra, T.; Hanson, B.M.; Bautista, E.J.; Leopold, S.; Yeh, C.Y.; et al. Integrative Personal Omics Profiles during Periods of Weight Gain and Loss. Cell Syst. 2018, 6, 157–170.e8. [Google Scholar] [CrossRef] [PubMed]
- Stanberry, L.; Mias, G.I.; Haynes, W.; Higdon, R.; Snyder, M.; Kolker, E. Integrative analysis of longitudinal metabolomics data from a personal multi-omics profile. Metabolites 2013, 3, 741–760. [Google Scholar] [CrossRef]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Canzler, S.; Schor, J.; Busch, W.; Schubert, K.; Rolle-Kampczyk, U.E.; Seitz, H.; Kamp, H.; von Bergen, M.; Buesen, R.; Hackermuller, J. Prospects and challenges of multi-omics data integration in toxicology. Arch. Toxicol. 2020, 94, 371–388. [Google Scholar] [CrossRef]
- Pinu, F.R.; Beale, D.J.; Paten, A.M.; Kouremenos, K.; Swarup, S.; Schirra, H.J.; Wishart, D. Systems Biology and Multi-Omics Integration: Viewpoints from the Metabolomics Research Community. Metabolites 2019, 9, 76. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lancaster, S.M.; Sanghi, A.; Wu, S.; Snyder, M.P. A Customizable Analysis Flow in Integrative Multi-Omics. Biomolecules 2020, 10, 1606. https://doi.org/10.3390/biom10121606
Lancaster SM, Sanghi A, Wu S, Snyder MP. A Customizable Analysis Flow in Integrative Multi-Omics. Biomolecules. 2020; 10(12):1606. https://doi.org/10.3390/biom10121606
Chicago/Turabian StyleLancaster, Samuel M., Akshay Sanghi, Si Wu, and Michael P. Snyder. 2020. "A Customizable Analysis Flow in Integrative Multi-Omics" Biomolecules 10, no. 12: 1606. https://doi.org/10.3390/biom10121606
APA StyleLancaster, S. M., Sanghi, A., Wu, S., & Snyder, M. P. (2020). A Customizable Analysis Flow in Integrative Multi-Omics. Biomolecules, 10(12), 1606. https://doi.org/10.3390/biom10121606