

A Comprehensive Guide to Interpretable AI-Powered Discoveries in Astronomy

Abstract
1. Introduction
2. Foundations of Trustworthy AI in Astronomy
- Transparency refers to the accessibility and understandability of the model’s internal mechanics. This involves knowledge of the architecture, algorithms, learned parameters (e.g., weights in a neural network), and potentially the training data [25,28]. A model can be transparent (e.g., open source and well-documented) yet still lack intuitive comprehensibility for domain experts.
- Interpretability captures the extent to which a human—especially a domain expert—can understand the relationship between inputs and outputs, or the decision logic of a model [29,30]. Models like linear regression or decision trees are inherently interpretable; their outputs can be directly tied to feature contributions. In contrast, deep neural networks and ensemble models (e.g., random forests) present significant challenges to interpretation due to their layered complexity and non-linearity.
- Explainability (xAI) refers to methods that provide human-understandable post hoc explanations for model behavior, particularly for opaque models [31,32]. These explanations may be local (explaining a single decision) or global (overall behavior). Tools like SHAP [33], LIME [34], and attention-based visualizations [35] approximate model reasoning or highlight influential features, providing insights without full interpretability.
3. AI Applications and Discoveries in Astronomy
3.1. Strong Lensing
3.2. Galaxy Morphology
3.3. Transient Detection and Classification
3.4. Galaxy Cluster Mass Estimation
3.5. Galactic Archaeology
4. Interpretable Machine Learning Methods
4.1. Feature Importance
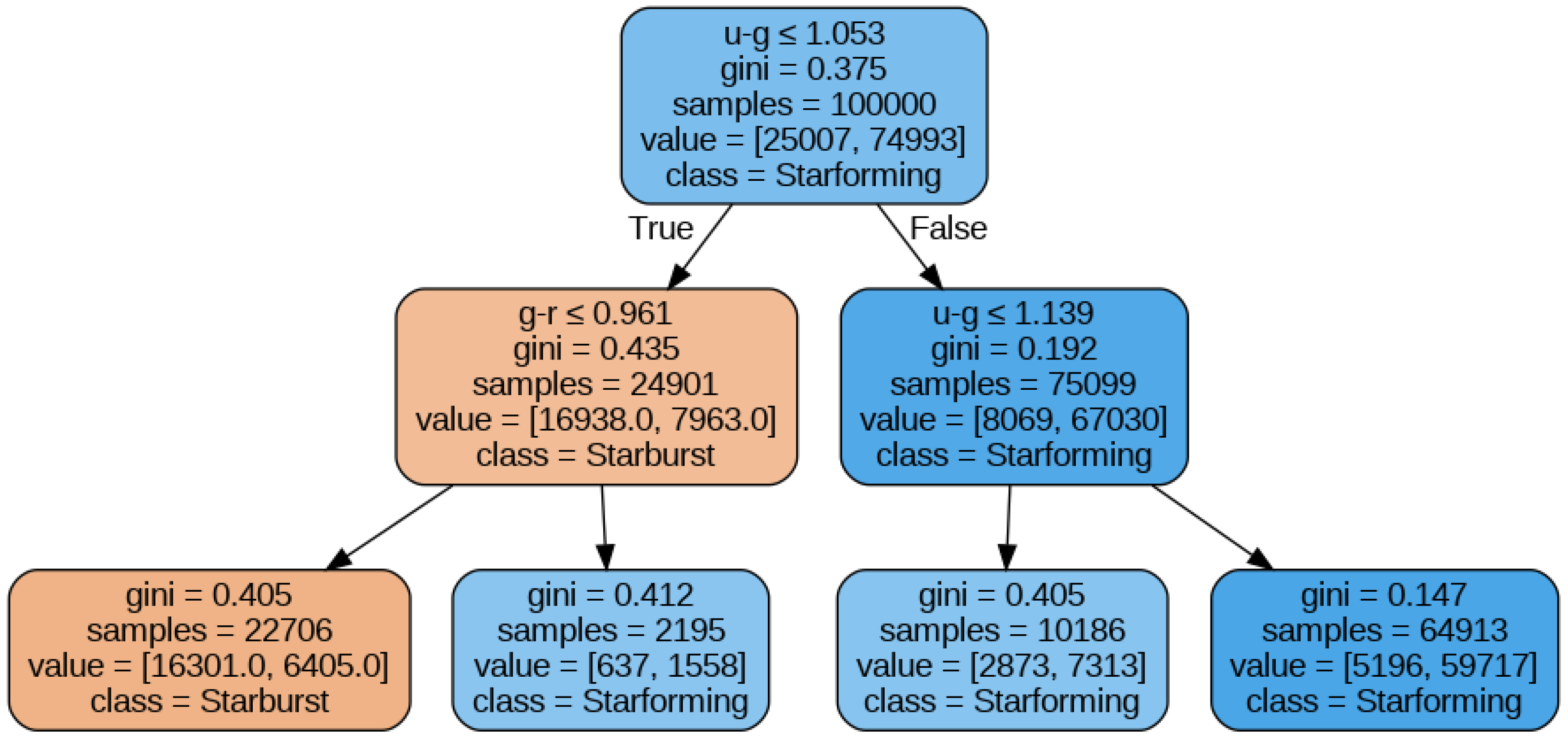
4.1.1. Gini Importance
4.1.2. Permutation Importance
4.2. Saliency-Based Methods
4.2.1. Vanilla Saliency
4.2.2. Guided Backpropagation or SmoothGrad
4.2.3. Integrated Gradients
4.2.4. Grad-CAM (Gradient-Weighted Class Activation Mapping)
4.3. Model Agnostic Methods
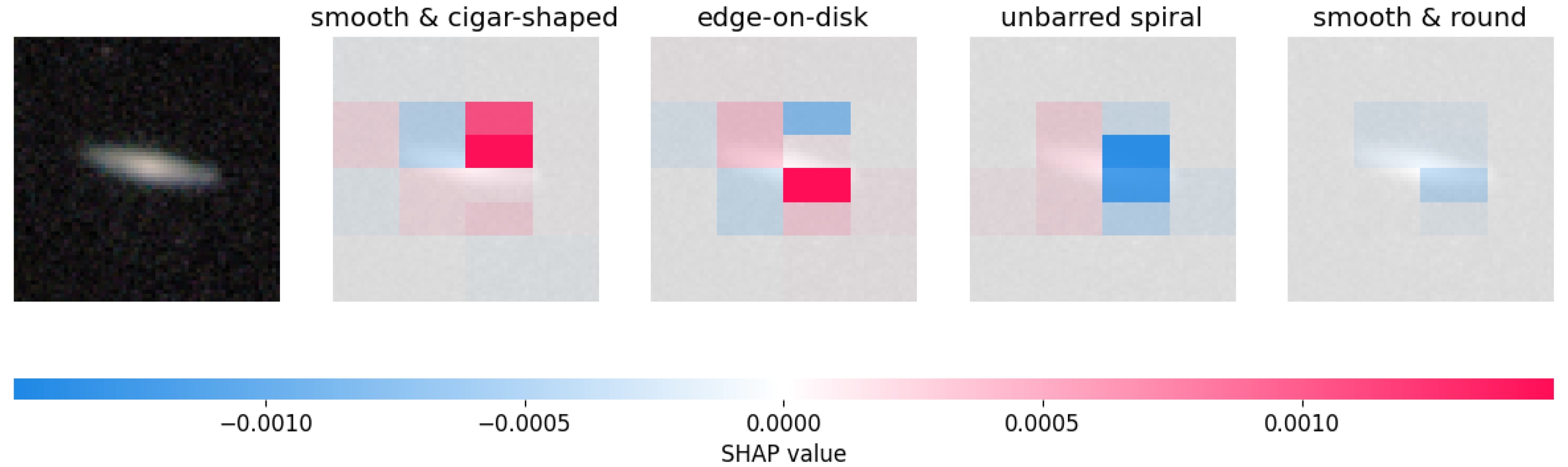
4.3.1. SHAP: SHapley Additive Explanations
4.3.2. LIME: Local Interpretable Model-Agnostic Explanations
4.4. Interpretable Models by Design
4.4.1. Rule-Based Methods
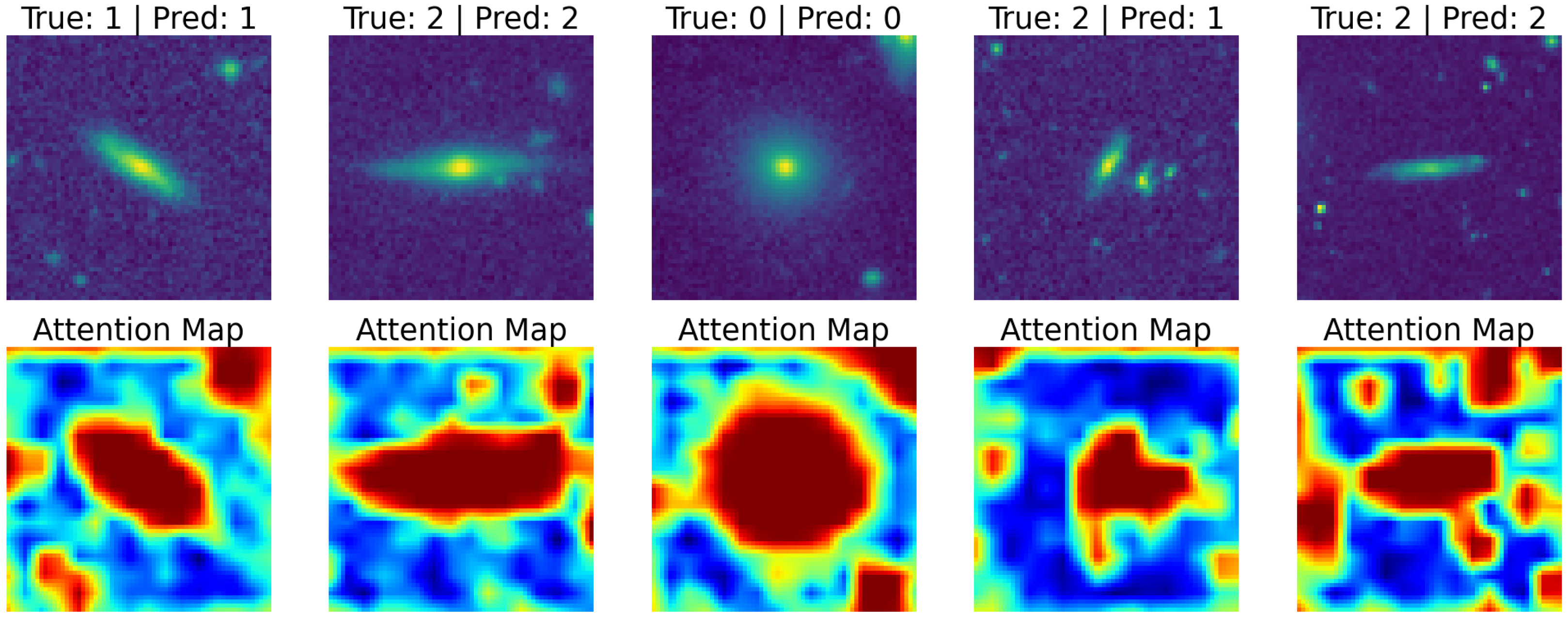
4.4.2. Attention Mechanisms
4.4.3. Symbolic Regression
4.4.4. Learning Interpretable Latent Representations
- Disentanglement techniques, which aim to separate independent factors of variation in the latent representation by adding additional constraints to the loss function to encourage each latent dimension to capture an independent aspect of the data. Models like -variational autoencoders (-VAEs) or other disentangled VAEs perform this. The -VAE loss is defined aswhere is the original loss, is the Kullback–Leibler (KL) divergence that measures how much the learned latent distribution deviates from a chosen prior distribution (typically a standard Gaussian), and the hyperparameter encourages the model to learn a latent distribution that is closer to the simple prior and, thus, promotes disentanglement.
- Conditional generation models like conditional variational autoencoders (CVAEs) condition the model on known variables like class labels. By observing how the latent space changes when conditioned on different known variables, its possible to infer how certain learned features in the latent space relate to these explicit conditions.
- Latent traversals involve systematically changing one latent variable at a time (while keeping others fixed) and observing the generated outputs. This technique can reveal what each dimension represents and whether it aligns with human-understandable concepts.
- Post hoc analysis of latent space structure: After training, dimensionality reduction techniques like principal component analysis (PCA) and clustering on the latent space can be an effective way to further explore the latent space to gain insights to what the model has learned.
4.4.5. Physics-Informed Neural Networks (PINNs)
4.5. Prototypes and Exemplars
4.6. AI Reasoning Models
5. Navigating the Future and Concluding Remarks
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hubble, E.P. A spiral nebula as a stellar system, Messier 31. Astrophys. J. 1929, 69, 103–158. [Google Scholar] [CrossRef]
- Benn, C.R.; Sanchez, S.F. Scientific impact of large telescopes. Publ. Astron. Soc. Pac. 2001, 113, 385. [Google Scholar] [CrossRef]
- O’Riordan, C.; Oldham, L.; Nersesian, A.; Li, T.; Collett, T.; Sluse, D.; Altieri, B.; Clément, B.; Vasan, K.; Rhoades, S.; et al. Euclid: A complete Einstein ring in NGC 6505. Astron. Astrophys. 2025, 694, A145. [Google Scholar] [CrossRef]
- Martinez-Delgado, D.; Stein, M.; Pawlowski, M.S.; Makarov, D.; Makarova, L.; Donatiello, G.; Lang, D. Tracing satellite planes in the Sculptor group: II. Discovery of five faint dwarf galaxies in the DESI Legacy Survey. arXiv 2024, arXiv:2405.03769. [Google Scholar]
- MacDonald, E.A.; Donovan, E.; Nishimura, Y.; Case, N.A.; Gillies, D.M.; Gallardo-Lacourt, B.; Archer, W.E.; Spanswick, E.L.; Bourassa, N.; Connors, M.; et al. New science in plain sight: Citizen scientists lead to the discovery of optical structure in the upper atmosphere. Sci. Adv. 2018, 4, eaaq0030. [Google Scholar] [CrossRef]
- Lintott, C.J.; Schawinski, K.; Slosar, A.; Land, K.; Bamford, S.; Thomas, D.; Raddick, M.J.; Nichol, R.C.; Szalay, A.; Andreescu, D.; et al. Galaxy Zoo: Morphologies derived from visual inspection of galaxies from the Sloan Digital Sky Survey. Mon. Not. R. Astron. Soc. 2008, 389, 1179–1189. [Google Scholar] [CrossRef]
- York, D.G.; Adelman, J.; Anderson Jr, J.E.; Anderson, S.F.; Annis, J.; Bahcall, N.A.; Bakken, J.; Barkhouser, R.; Bastian, S.; Berman, E.; et al. The sloan digital sky survey: Technical summary. Astron. J. 2000, 120, 1579. [Google Scholar] [CrossRef]
- Kaiser, N.; Aussel, H.; Burke, B.E.; Boesgaard, H.; Chambers, K.; Chun, M.R.; Heasley, J.N.; Hodapp, K.W.; Hunt, B.; Jedicke, R.; et al. Pan-STARRS: A large synoptic survey telescope array. In Proceedings of the Survey and Other Telescope Technologies and Discoveries; SPIE: Bellingham, WA, USA, 2002; Volume 4836, pp. 154–164. [Google Scholar]
- Ivezić, Ž.; Kahn, S.M.; Tyson, J.A.; Abel, B.; Acosta, E.; Allsman, R.; Alonso, D.; AlSayyad, Y.; Anderson, S.F.; Andrew, J.; et al. LSST: From science drivers to reference design and anticipated data products. Astrophys. J. 2019, 873, 111. [Google Scholar] [CrossRef]
- Dewdney, P.E.; Hall, P.J.; Schilizzi, R.T.; Lazio, T.J.L. The square kilometre array. Proc. IEEE 2009, 97, 1482–1496. [Google Scholar] [CrossRef]
- Laureijs, R.; Amiaux, J.; Arduini, S.; Augueres, J.L.; Brinchmann, J.; Cole, R.; Cropper, M.; Dabin, C.; Duvet, L.; Ealet, A.; et al. Euclid definition study report. arXiv 2011, arXiv:1110.3193. [Google Scholar]
- Gardner, J.P.; Mather, J.C.; Clampin, M.; Doyon, R.; Greenhouse, M.A.; Hammel, H.B.; Hutchings, J.B.; Jakobsen, P.; Lilly, S.J.; Long, K.S.; et al. The james webb space telescope. Space Sci. Rev. 2006, 123, 485–606. [Google Scholar] [CrossRef]
- Spergel, D.; Gehrels, N.; Baltay, C.; Bennett, D.; Breckinridge, J.; Donahue, M.; Dressler, A.; Gaudi, B.; Greene, T.; Guyon, O.; et al. Wide-field infrarred survey telescope-astrophysics focused telescope assets WFIRST-AFTA 2015 report. arXiv 2015, arXiv:1503.03757. [Google Scholar]
- Vogelsberger, M.; Marinacci, F.; Torrey, P.; Puchwein, E. Cosmological simulations of galaxy formation. Nat. Rev. Phys. 2020, 2, 42–66. [Google Scholar] [CrossRef]
- Skoda, P.; Adam, F. Knowledge Discovery in Big Data from Astronomy and Earth Observation: AstroGeoInformatics; Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Collaboration, E.; Böhringer, H.; Chon, G.; Cucciati, O.; Dannerbauer, H.; Bolzonella, M.; De Lucia, G.; Cappi, A.; Moscardini, L.; Giocoli, C.; et al. Euclid preparation. Astron. Astrophys. 2025, 693, A58. [Google Scholar] [CrossRef]
- Narayan, G.; Zaidi, T.; Soraisam, M.D.; Wang, Z.; Lochner, M.; Matheson, T.; Saha, A.; Yang, S.; Zhao, Z.; Kececioglu, J.; et al. Machine-learning-based Brokers for Real-time Classification of the LSST Alert Stream. Astrophys. J. Suppl. Ser. 2018, 236, 9. [Google Scholar] [CrossRef]
- Lieu, M.; Cheng, T.Y. Machine Learning methods in Astronomy. Astron. Comput. 2024, 47, 100830. [Google Scholar] [CrossRef]
- Mehta, P.; Bukov, M.; Wang, C.H.; Day, A.G.; Richardson, C.; Fisher, C.K.; Schwab, D.J. A high-bias, low-variance introduction to machine learning for physicists. Phys. Rep. 2019, 810, 1–124. [Google Scholar] [CrossRef]
- Graham, M.J.; Kulkarni, S.; Bellm, E.C.; Adams, S.M.; Barbarino, C.; Blagorodnova, N.; Bodewits, D.; Bolin, B.; Brady, P.R.; Cenko, S.B.; et al. The zwicky transient facility: Science objectives. Publ. Astron. Soc. Pac. 2019, 131, 078001. [Google Scholar] [CrossRef]
- Masci, F.J.; Laher, R.R.; Rusholme, B.; Shupe, D.L.; Groom, S.; Surace, J.; Jackson, E.; Monkewitz, S.; Beck, R.; Flynn, D.; et al. The zwicky transient facility: Data processing, products, and archive. Publ. Astron. Soc. Pac. 2018, 131, 018003. [Google Scholar] [CrossRef]
- Mahabal, A.; Rebbapragada, U.; Walters, R.; Masci, F.J.; Blagorodnova, N.; van Roestel, J.; Ye, Q.Z.; Biswas, R.; Burdge, K.; Chang, C.K.; et al. Machine learning for the zwicky transient facility. Publ. Astron. Soc. Pac. 2019, 131, 038002. [Google Scholar] [CrossRef]
- Metzger, B.D.; Berger, E. What is the most promising electromagnetic counterpart of a neutron star binary merger? Astrophys. J. 2012, 746, 48. [Google Scholar] [CrossRef]
- Jia, P.; Jia, Q.; Jiang, T.; Yang, Z. A simulation framework for telescope array and its application in distributed reinforcement learning-based scheduling of telescope arrays. Astron. Comput. 2023, 44, 100732. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Kamath, U.; Liu, J. Explainable Artificial Intelligence: An Introduction to Interpretable Machine Learning; Springer Nature: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Ćiprijanović, A.; Kafkes, D.; Snyder, G.; Sánchez, F.J.; Perdue, G.N.; Pedro, K.; Nord, B.; Madireddy, S.; Wild, S.M. DeepAdversaries: Examining the robustness of deep learning models for galaxy morphology classification. Mach. Learn. Sci. Technol. 2022, 3, 035007. [Google Scholar] [CrossRef]
- Walmsley, J. Artificial intelligence and the value of transparency. AI Soc. 2021, 36, 585–595. [Google Scholar] [CrossRef]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A survey on neural network interpretability. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 726–742. [Google Scholar] [CrossRef]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.Z. XAI—Explainable artificial intelligence. Sci. Robot. 2019, 4, eaay7120. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Huppenkothen, D.; Ntampaka, M.; Ho, M.; Fouesneau, M.; Nord, B.; Peek, J.E.; Walmsley, M.; Wu, J.F.; Avestruz, C.; Buck, T.; et al. Constructing impactful machine learning research for astronomy: Best practices for researchers and reviewers. arXiv 2023, arXiv:2310.12528. [Google Scholar]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Rudin, C.; Chen, C.; Chen, Z.; Huang, H.; Semenova, L.; Zhong, C. Interpretable machine learning: Fundamental principles and 10 grand challenges. Stat. Surv. 2022, 16, 1–85. [Google Scholar] [CrossRef]
- Ntampaka, M.; Vikhlinin, A. The importance of being interpretable: Toward an understandable machine learning encoder for galaxy cluster cosmology. Astrophys. J. 2022, 926, 45. [Google Scholar] [CrossRef]
- Schneider, P.; Ehlers, J.; Falco, E.E.; Schneider, P.; Ehlers, J.; Falco, E.E. Gravitational Lenses as Astrophysical Tools; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Treu, T. Strong lensing by galaxies. Annu. Rev. Astron. Astrophys. 2010, 48, 87–125. [Google Scholar] [CrossRef]
- Collett, T.E.; Oldham, L.J.; Smith, R.J.; Auger, M.W.; Westfall, K.B.; Bacon, D.; Nichol, R.C.; Masters, K.L.; Koyama, K.; van den Bosch, R. A precise extragalactic test of General Relativity. Science 2018, 360, 1342–1346. [Google Scholar] [CrossRef] [PubMed]
- Walsh, D.; Carswell, R.F.; Weymann, R.J. 0957+ 561 A, B: Twin quasistellar objects or gravitational lens? Nature 1979, 279, 381–384. [Google Scholar] [CrossRef]
- Metcalf, R.B.; Meneghetti, M.; Avestruz, C.; Bellagamba, F.; Bom, C.R.; Bertin, E.; Cabanac, R.; Courbin, F.; Davies, A.; Decencière, E.; et al. The strong gravitational lens finding challenge. Astron. Astrophys. 2019, 625, A119. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- de Jong, J.T.; Verdoes Kleijn, G.A.; Kuijken, K.H.; Valentijn, E.A.; KiDS; Consortiums, A.W. The kilo-degree survey. Exp. Astron. 2013, 35, 25–44. [Google Scholar] [CrossRef]
- Hartley, P.; Flamary, R.; Jackson, N.; Tagore, A.; Metcalf, R. Support vector machine classification of strong gravitational lenses. Mon. Not. R. Astron. Soc. 2017, 471, 3378–3397. [Google Scholar] [CrossRef]
- Jacobs, C.; Glazebrook, K.; Collett, T.; More, A.; McCarthy, C. Finding strong lenses in CFHTLS using convolutional neural networks. Mon. Not. R. Astron. Soc. 2017, 471, 167–181. [Google Scholar] [CrossRef]
- Lieu, M.; Conversi, L.; Altieri, B.; Carry, B. Detecting Solar system objects with convolutional neural networks. Mon. Not. R. Astron. Soc. 2019, 485, 5831–5842. [Google Scholar] [CrossRef]
- Huang, X.; Baltasar, S.; Ratier-Werbin, N. DESI Strong Lens Foundry I: HST Observations and Modeling with GIGA-Lens. arXiv 2025, arXiv:2502.03455. [Google Scholar]
- Lines, N.; Collett, T.; Walmsley, M.; Rojas, K.; Li, T.; Leuzzi, L.; Manjón-García, A.; Vincken, S.; Wilde, J.; Holloway, P.; et al. Euclid Quick Data Release (Q1). The Strong Lensing Discovery Engine C-Finding lenses with machine learning. arXiv 2025, arXiv:2503.15326. [Google Scholar]
- Wilde, J.; Serjeant, S.; Bromley, J.M.; Dickinson, H.; Koopmans, L.V.; Metcalf, R.B. Detecting gravitational lenses using machine learning: Exploring interpretability and sensitivity to rare lensing configurations. Mon. Not. R. Astron. Soc. 2022, 512, 3464–3479. [Google Scholar] [CrossRef]
- Applebaum, K.; Zhang, D. Classifying galaxy images through support vector machines. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration, San Francisco, CA, USA, 13–15 August 2015; pp. 357–363. [Google Scholar]
- Reza, M. Galaxy morphology classification using automated machine learning. Astron. Comput. 2021, 37, 100492. [Google Scholar] [CrossRef]
- Dieleman, S.; Willett, K.W.; Dambre, J. Rotation-invariant convolutional neural networks for galaxy morphology prediction. Mon. Not. R. Astron. Soc. 2015, 450, 1441–1459. [Google Scholar] [CrossRef]
- Domínguez Sánchez, H.; Huertas-Company, M.; Bernardi, M.; Tuccillo, D.; Fischer, J. Improving galaxy morphologies for SDSS with Deep Learning. Mon. Not. R. Astron. Soc. 2018, 476, 3661–3676. [Google Scholar] [CrossRef]
- Bhambra, P.; Joachimi, B.; Lahav, O. Explaining deep learning of galaxy morphology with saliency mapping. Mon. Not. R. Astron. Soc. 2022, 511, 5032–5041. [Google Scholar] [CrossRef]
- Muthukrishna, D.; Narayan, G.; Mandel, K.S.; Biswas, R.; Hložek, R. RAPID: Early classification of explosive transients using deep learning. Publ. Astron. Soc. Pac. 2019, 131, 118002. [Google Scholar] [CrossRef]
- Villar, V.A.; Cranmer, M.; Berger, E.; Contardo, G.; Ho, S.; Hosseinzadeh, G.; Lin, J.Y.Y. A deep-learning approach for live anomaly detection of extragalactic transients. Astrophys. J. Suppl. Ser. 2021, 255, 24. [Google Scholar] [CrossRef]
- Denker, J.; LeCun, Y. Transforming Neural-Net Output Levels to Probability Distributions. In Proceedings of the Advances in Neural Information Processing Systems; Lippmann, R., Moody, J., Touretzky, D., Eds.; Morgan-Kaufmann: San Francisco, CA, USA, 1990; Volume 3. [Google Scholar]
- Ishida, E.E. Machine learning and the future of supernova cosmology. Nat. Astron. 2019, 3, 680–682. [Google Scholar] [CrossRef]
- Lochner, M.; McEwen, J.D.; Peiris, H.V.; Lahav, O.; Winter, M.K. Photometric supernova classification with machine learning. Astrophys. J. Suppl. Ser. 2016, 225, 31. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, C.; Hobbs, G.; Russell, C.; Li, D.; Zhang, S.B.; Dai, S.; Wu, J.W.; Pan, Z.C.; Zhu, W.W.; et al. Applying saliency-map analysis in searches for pulsars and fast radio bursts. Astron. Astrophys. 2020, 642, A26. [Google Scholar] [CrossRef]
- Kravtsov, A.V.; Borgani, S. Formation of galaxy clusters. Annu. Rev. Astron. Astrophys. 2012, 50, 353–409. [Google Scholar] [CrossRef]
- Ntampaka, M.; ZuHone, J.; Eisenstein, D.; Nagai, D.; Vikhlinin, A.; Hernquist, L.; Marinacci, F.; Nelson, D.; Pakmor, R.; Pillepich, A.; et al. A deep learning approach to galaxy cluster x-ray masses. Astrophys. J. 2019, 876, 82. [Google Scholar] [CrossRef]
- Mordvintsev, A.; Olah, C.; Tyka, M. Deepdream-a code example for visualizing neural networks. Google Res. 2015, 2, 67. [Google Scholar]
- Collaboration, G.; Prusti, T.; de Bruijne, J.; Brown, A.; Vallenari, A.; Babusiaux, C.; Bailer-Jones, C.; Bastian, U.; Biermann, M.; Evans, D.; et al. The Gaia mission. Astron. Astrophys. 2016, 595, A1. [Google Scholar] [CrossRef]
- Marchetti, T.; Rossi, E.; Kordopatis, G.; Brown, A.; Rimoldi, A.; Starkenburg, E.; Youakim, K.; Ashley, R. An artificial neural network to discover hypervelocity stars: Candidates in Gaia DR1/TGAS. Mon. Not. R. Astron. Soc. 2017, 470, 1388–1403. [Google Scholar] [CrossRef]
- Van Groeningen, M.; Castro-Ginard, A.; Brown, A.; Casamiquela, L.; Jordi, C. A machine-learning-based tool for open cluster membership determination in Gaia DR3. Astron. Astrophys. 2023, 675, A68. [Google Scholar] [CrossRef]
- Fotopoulou, S. A review of unsupervised learning in astronomy. Astron. Comput. 2024, 48, 100851. [Google Scholar] [CrossRef]
- Malhan, K.; Ibata, R.A. STREAMFINDER—I. A new algorithm for detecting stellar streams. Mon. Not. R. Astron. Soc. 2018, 477, 4063–4076. [Google Scholar] [CrossRef]
- Koppelman, H.H.; Helmi, A.; Massari, D.; Price-Whelan, A.M.; Starkenburg, T.K. Multiple retrograde substructures in the Galactic halo: A shattered view of Galactic history. Astron. Astrophys. 2019, 631, L9. [Google Scholar] [CrossRef]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016. [Google Scholar]
- Hoyle, B.; Rau, M.M.; Zitlau, R.; Seitz, S.; Weller, J. Feature importance for machine learning redshifts applied to SDSS galaxies. Mon. Not. R. Astron. Soc. 2015, 449, 1275–1283. [Google Scholar] [CrossRef]
- Ribeiro, F.; Gradvohl, A.L.S. Machine learning techniques applied to solar flares forecasting. Astron. Comput. 2021, 35, 100468. [Google Scholar] [CrossRef]
- Chaini, S.; Mahabal, A.; Kembhavi, A.; Bianco, F.B. Light curve classification with DistClassiPy: A new distance-based classifier. Astron. Comput. 2024, 48, 100850. [Google Scholar] [CrossRef]
- Lucie-Smith, L.; Peiris, H.V.; Pontzen, A. An interpretable machine-learning framework for dark matter halo formation. Mon. Not. R. Astron. Soc. 2019, 490, 331–342. [Google Scholar] [CrossRef]
- Davies, A.; Serjeant, S.; Bromley, J.M. Using convolutional neural networks to identify gravitational lenses in astronomical images. Mon. Not. R. Astron. Soc. 2019, 487, 5263–5271. [Google Scholar] [CrossRef]
- Kosiba, M.; Lieu, M.; Altieri, B.; Clerc, N.; Faccioli, L.; Kendrew, S.; Valtchanov, I.; Sadibekova, T.; Pierre, M.; Hroch, F.; et al. Multiwavelength classification of X-ray selected galaxy cluster candidates using convolutional neural networks. Mon. Not. R. Astron. Soc. 2020, 496, 4141–4153. [Google Scholar] [CrossRef]
- Jerse, G.; Marcucci, A. Deep Learning LSTM-based approaches for 10.7 cm solar radio flux forecasting up to 45-days. Astron. Comput. 2024, 46, 100786. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Walmsley, M.; Lintott, C.; Géron, T.; Kruk, S.; Krawczyk, C.; Willett, K.W.; Bamford, S.; Kelvin, L.S.; Fortson, L.; Gal, Y.; et al. Galaxy Zoo DECaLS: Detailed visual morphology measurements from volunteers and deep learning for 314 000 galaxies. Mon. Not. R. Astron. Soc. 2022, 509, 3966–3988. [Google Scholar] [CrossRef]
- Jacobs, C.; Glazebrook, K.; Qin, A.K.; Collett, T. Exploring the interpretability of deep neural networks used for gravitational lens finding with a sensitivity probe. Astron. Comput. 2022, 38, 100535. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? arXiv 2016, arXiv:1611.07450. [Google Scholar]
- Tanoglidis, D.; Ćiprijanović, A.; Drlica-Wagner, A. DeepShadows: Separating low surface brightness galaxies from artifacts using deep learning. Astron. Comput. 2021, 35, 100469. [Google Scholar] [CrossRef]
- Shirasuna, V.Y.; Gradvohl, A.L.S. An optimized training approach for meteor detection with an attention mechanism to improve robustness on limited data. Astron. Comput. 2023, 45, 100753. [Google Scholar] [CrossRef]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity checks for saliency maps. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Srinivas, S.; Fleuret, F. Rethinking the role of gradient-based attribution methods for model interpretability. arXiv 2020, arXiv:2006.09128. [Google Scholar]
- Shapley, L.S. Stochastic games. Proc. Natl. Acad. Sci. USA 1953, 39, 1095–1100. [Google Scholar] [CrossRef]
- Heyl, J.; Butterworth, J.; Viti, S. Understanding molecular abundances in star-forming regions using interpretable machine learning. Mon. Not. R. Astron. Soc. 2023, 526, 404–422. [Google Scholar] [CrossRef]
- Ye, S.; Cui, W.Y.; Li, Y.B.; Luo, A.L.; Jones, R.H. Deep learning interpretable analysis for carbon star identification in Gaia DR3. Astron. Astrophys. 2024, 697, A107. [Google Scholar] [CrossRef]
- Goh, K.M.; Lim, D.H.Y.; Sham, Z.D.; Prakash, K.B. An Interpretable Galaxy Morphology Classification Approach using Modified SqueezeNet and Local Interpretable Model-Agnostic Explanation. Res. Astron. Astrophys. 2025, 25, 065018. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar]
- Friedman, J.H.; Popescu, B.E. Predictive Learning via Rule Ensembles. Ann. Appl. Stat. 2008, 2, 916–954. [Google Scholar] [CrossRef]
- Odewahn, S.; De Carvalho, R.; Gal, R.; Djorgovski, S.; Brunner, R.; Mahabal, A.; Lopes, P.; Moreira, J.K.; Stalder, B. The Digitized Second Palomar Observatory Sky Survey (DPOSS). III. Star-Galaxy Separation. Astron. J. 2004, 128, 3092. [Google Scholar] [CrossRef]
- Bailey, S.; Aragon, C.; Romano, R.; Thomas, R.C.; Weaver, B.A.; Wong, D. How to find more supernovae with less work: Object classification techniques for difference imaging. Astrophys. J. 2007, 665, 1246. [Google Scholar] [CrossRef]
- Chacón, J.; Vázquez, J.A.; Almaraz, E. Classification algorithms applied to structure formation simulations. Astron. Comput. 2022, 38, 100527. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Jain, S.; Wallace, B.C. Attention is not explanation. arXiv 2019, arXiv:1902.10186. [Google Scholar]
- Wiegreffe, S.; Pinter, Y. Attention is not not explanation. arXiv 2019, arXiv:1908.04626. [Google Scholar]
- Bowles, M.; Scaife, A.M.; Porter, F.; Tang, H.; Bastien, D.J. Attention-gating for improved radio galaxy classification. Mon. Not. R. Astron. Soc. 2021, 501, 4579–4595. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic programming as a means for programming computers by natural selection. Stat. Comput. 1994, 4, 87–112. [Google Scholar] [CrossRef]
- Schmidt, M.; Lipson, H. Distilling free-form natural laws from experimental data. Science 2009, 324, 81–85. [Google Scholar] [CrossRef] [PubMed]
- Cranmer, M. Interpretable machine learning for science with PySR and SymbolicRegression.jl. arXiv 2023, arXiv:2305.01582. [Google Scholar]
- Udrescu, S.M.; Tegmark, M. AI Feynman: A physics-inspired method for symbolic regression. Sci. Adv. 2020, 6, eaay2631. [Google Scholar] [CrossRef] [PubMed]
- Cranmer, M.; Sanchez Gonzalez, A.; Battaglia, P.; Xu, R.; Cranmer, K.; Spergel, D.; Ho, S. Discovering symbolic models from deep learning with inductive biases. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual, 6–12 December 2020; pp. 17429–17442. [Google Scholar]
- Jin, Z.; Davis, B.L. Discovering Black Hole Mass Scaling Relations with Symbolic Regression. arXiv 2023, arXiv:2310.19406. [Google Scholar]
- Sousa-Neto, A.; Bengaly, C.; González, J.E.; Alcaniz, J. No evidence for dynamical dark energy from DESI and SN data: A symbolic regression analysis. arXiv 2025, arXiv:2502.10506. [Google Scholar]
- Wadekar, D.; Villaescusa-Navarro, F.; Ho, S.; Perreault-Levasseur, L. Modeling assembly bias with machine learning and symbolic regression. arXiv 2020, arXiv:2012.00111. [Google Scholar]
- Guo, N.; Lucie-Smith, L.; Peiris, H.V.; Pontzen, A.; Piras, D. Deep learning insights into non-universality in the halo mass function. Mon. Not. R. Astron. Soc. 2024, 532, 4141–4156. [Google Scholar] [CrossRef]
- Klys, J.; Snell, J.; Zemel, R. Learning latent subspaces in variational autoencoders. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Wang, S.; Teng, Y.; Perdikaris, P. Understanding and mitigating gradient flow pathologies in physics-informed neural networks. SIAM J. Sci. Comput. 2021, 43, A3055–A3081. [Google Scholar] [CrossRef]
- Caruana, R.; Kangarloo, H.; Dionisio, J.D.; Sinha, U.; Johnson, D. Case-based explanation of non-case-based learning methods. In Proceedings of the AMIA Symposium, Washington, DC, USA, 6–10 November 1999; p. 212. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022; pp. 24824–24837. [Google Scholar]
- Yugeswardeenoo, D.; Zhu, K.; O’Brien, S. Question-analysis prompting improves LLM performance in reasoning tasks. arXiv 2024, arXiv:2407.03624. [Google Scholar]
- Turpin, M.; Michael, J.; Perez, E.; Bowman, S. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. In Proceedings of the Advances in Neural Information Processing Systems 36 (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023; pp. 74952–74965. [Google Scholar]
- Li, J.; Cao, P.; Chen, Y.; Liu, K.; Zhao, J. Towards faithful chain-of-thought: Large language models are bridging reasoners. arXiv 2024, arXiv:2405.18915. [Google Scholar]
- Arcuschin, I.; Janiak, J.; Krzyzanowski, R.; Rajamanoharan, S.; Nanda, N.; Conmy, A. Chain-of-thought reasoning in the wild is not always faithful. arXiv 2025, arXiv:2503.08679. [Google Scholar]
- Lanham, T.; Chen, A.; Radhakrishnan, A.; Steiner, B.; Denison, C.; Hernandez, D.; Li, D.; Durmus, E.; Hubinger, E.; Kernion, J.; et al. Measuring faithfulness in chain-of-thought reasoning. arXiv 2023, arXiv:2307.13702. [Google Scholar]
- Bentham, O.; Stringham, N.; Marasović, A. Chain-of-thought unfaithfulness as disguised accuracy. arXiv 2024, arXiv:2402.14897. [Google Scholar]
- Wang, Z.; Han, Z.; Chen, S.; Xue, F.; Ding, Z.; Xiao, X.; Tresp, V.; Torr, P.; Gu, J. Stop Reasoning! When Multimodal LLM with Chain-of-Thought Reasoning Meets Adversarial Image. arXiv 2024, arXiv:2402.14899. [Google Scholar]
- Yamada, Y.; Lange, R.T.; Lu, C.; Hu, S.; Lu, C.; Foerster, J.; Clune, J.; Ha, D. The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search. arXiv 2025, arXiv:2504.08066. [Google Scholar]
- Moss, A. The AI Cosmologist I: An Agentic System for Automated Data Analysis. arXiv 2025, arXiv:2504.03424. [Google Scholar]
- Fluke, C.J.; Jacobs, C. Surveying the reach and maturity of machine learning and artificial intelligence in astronomy. WIREs Data Min. Knowl. Discov. 2020, 10, e1349. [Google Scholar] [CrossRef]
- Khakzar, A.; Baselizadeh, S.; Navab, N. Rethinking positive aggregation and propagation of gradients in gradient-based saliency methods. arXiv 2020, arXiv:2012.00362. [Google Scholar]
- Zhang, Y.; Gu, S.; Song, J.; Pan, B.; Bai, G.; Zhao, L. XAI benchmark for visual explanation. arXiv 2023, arXiv:2310.08537. [Google Scholar]
- Moiseev, I.; Balabaeva, K.; Kovalchuk, S. Open and Extensible Benchmark for Explainable Artificial Intelligence Methods. Algorithms 2025, 18, 85. [Google Scholar] [CrossRef]
- Information Commissioner’s Office. Guidance on AI and Data Protection; Information Commissioner’s Office: Cheshire, UK, 2023; Available online: https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/artificial-intelligence/guidance-on-ai-and-data-protection/ (accessed on 23 April 2025).
- Bereska, L.; Gavves, E. Mechanistic Interpretability for AI Safety—A Review. arXiv 2024, arXiv:2404.14082. [Google Scholar]
- Bluck, A.F.L.; Maiolino, R.; Brownson, S.; Conselice, C.J.; Ellison, S.L.; Piotrowska, J.M.; Thorp, M.D. The quenching of galaxies, bulges, and disks since cosmic noon. A machine learning approach for identifying causality in astronomical data. Astron. Astrophys. 2022, 659, A160. [Google Scholar] [CrossRef]
- Moschou, S.; Hicks, E.; Parekh, R.; Mathew, D.; Majumdar, S.; Vlahakis, N. Physics-informed neural networks for modeling astrophysical shocks. Mach. Learn. Sci. Technol. 2023, 4, 035032. [Google Scholar] [CrossRef]
- Ni, S.; Qiu, Y.; Chen, Y.; Song, Z.; Chen, H.; Jiang, X.; Quan, D.; Chen, H. Application of Physics-Informed Neural Networks in Removing Telescope Beam Effects. arXiv 2024, arXiv:2409.05718. [Google Scholar]
- Mengaldo, G. Explain the Black Box for the Sake of Science: The Scientific Method in the Era of Generative Artificial Intelligence. arXiv 2025, arXiv:2406.10557. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interpretability Goal | Image Data | Tabular Data | Time Series Data |
|---|---|---|---|
| What matters? (global) | SHAP PI | SHAP PI/GI | SHAP PI |
| Why this decision? (local) | Saliency LIME/SHAP attention - | - LIME/SHAP - rule-based | Saliency LIME/SHAP attention - |
| Where is it looking? | Saliency LIME/SHAP attention | - - - | Saliency - attention |
| How does it generalise? | Symbolic regression | Symbolic regression | Symbolic regression |
| What is similar? | Prototype/ Exempler | Prototype/ Exempler | Prototype/ Exempler |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lieu, M. A Comprehensive Guide to Interpretable AI-Powered Discoveries in Astronomy. Universe 2025, 11, 187. https://doi.org/10.3390/universe11060187
Lieu M. A Comprehensive Guide to Interpretable AI-Powered Discoveries in Astronomy. Universe. 2025; 11(6):187. https://doi.org/10.3390/universe11060187
Chicago/Turabian StyleLieu, Maggie. 2025. "A Comprehensive Guide to Interpretable AI-Powered Discoveries in Astronomy" Universe 11, no. 6: 187. https://doi.org/10.3390/universe11060187
APA StyleLieu, M. (2025). A Comprehensive Guide to Interpretable AI-Powered Discoveries in Astronomy. Universe, 11(6), 187. https://doi.org/10.3390/universe11060187