1. Introduction
The infrared band is crucial in astronomical observations, offering the ability to penetrate the dust and reveal celestial structures and phenomena that are challenging to observe in the visible band. This capability provides essential insights into the internal structure and evolutionary processes of galaxies. With the advancement of astronomical technology, the quantity and performance of infrared telescopes have significantly improved, enhancing the value of infrared astronomical research.
For instance, the launch of the Infrared Astronomical Satellite (IRAS) [
1] in 1983 marked a pioneering effort in infrared surveys; the Infrared Space Observatory (ISO) [
2] in 1995 enhanced observational accuracy and coverage; The Spitzer Space Telescope [
3] launched in 2003, delivered high-resolution infrared images; The Wide-field Infrared Survey Explorer (WISE) [
4] in 2009 covered the entire sky and amassed a vast amount of high-quality infrared data. The James Webb Space Telescope (JWST) [
5], launched in December 2021, has significantly increased the depth and sensitivity of infrared observations.
In this paper, the data utilized are derived from WISE. Since its launch on 14 December 2009, WISE has systematically conducted infrared observations of the entire sky. Covering four infrared bands (W1, W2, W3, and W4, corresponding to 3.4, 4.6, 12, and 22 microns, respectively), WISE has detected hundreds of millions of stars and galaxies, thereby amassing a wealth of high-quality infrared image data.
In recent years, Convolutional Neural Networks (CNNs) and Transformer networks have made significant advancements in the field of galaxy morphology classification, presenting new opportunities and challenges. For example, Zhu et al. [
6] employed the ResNet for galaxy morphology classification on the Galaxy Zoo 2 dataset, achieving an overall accuracy of 95.21%. Wu et al. [
7] developed the GalSpecNet convolutional neural network model to classify emission-line galaxy spectra, attaining an accuracy of over 93% in their classification tasks. This model was also successfully applied to the SDSS DR16 and LAMOST DR8 datasets to produce a public catalog of 41,699 star-forming candidate galaxies and 55,103 AGN candidate galaxies. Wang et al. [
8] applied the RepViT, which integrates the strengths of convolutional neural networks (CNNs) and visual transformers (ViTs), for a five-class galaxy morphology classification task, and achieved an accuracy of 98%. These study results demonstrate that deep learning techniques substantially enhance the accuracy of galaxy classification, laying a robust foundation for future research.
In the task of galaxy morphology classification, CNNs, and Transformer networks have been extensively researched and have achieved significant progress. Concurrently, increasingly efficient network architectures are emerging, demonstrating strong potential. Notable examples include VMamba [
9], RMT [
10], StarNet [
11], and EfficientFormerV2 [
12]. VMamba achieves the retention of a global receptive field through Visual State Space (VSS) blocks and Cross-Scan Modules (CSM) while maintaining linear computational complexity. RMT utilizes explicit decay and a Manhattan distance-based spatial decay matrix to retain the global receptive field, also achieving linear computational complexity. StarNet employs the star operation to map high-dimensional implicit feature spaces, achieving efficient image classification performance while maintaining a streamlined design. EfficientFormerV2 combines the self-attention mechanism of Transformers with the local perception capability of CNNs, optimizing network structure and lightweight design to achieve efficient image classification performance, making it an ideal choice for large-scale image classification tasks.
The objective is to enhance galaxy classification capabilities by refining the EfficientFormerV2 architecture through an innovative approach that leverages its strengths. To address this challenge, a lightweight, learnable upsampling framework, termed “Dysample”, is introduced to enhance overall classification accuracy and efficiency, particularly for small-scale targets.
The structure of this paper is organized as follows:
Section 2 describes the dataset, data band fusion, and data preprocessing techniques;
Section 3 provides a detailed description of the classification model and its modified version (incorporating WISE magnitude);
Section 4 presents and discusses the experimental results; finally,
Section 5 summarizes the main conclusions of the paper and outlines future research work.
2. Data
To acquire the necessary galaxy data from WISE, a cross-matching with the Galaxy Zoo 2 dataset [
13] is utilized to ensure precise labeling of galaxy types. A crossover radius of 5 arcseconds is employed using the nearest-neighbor principle to account for pixel scale differences between SDSS (0.396 arcsec/pix) and WISE (1.375 arcsec/pix), which minimizes photometric center offsets and ensures accurate galaxy target labeling. The Galaxy Zoo 2 dataset comprises classifications from volunteers who completed 11 tasks and provided 37 responses for each galaxy image. By leveraging this dataset, a collection of 12,852 elliptical galaxies and 12,088 spiral galaxies was identified through a systematic process of visual inspection and classification.
In addition, using a cropped image size of 46.75 arcseconds (34 pixels) ensures that galaxy targets are consistently centered. The previously mentioned cross-matching radius of 5 arcseconds, combined with the WISE pixel scale of approximately 1.375 arcseconds per pixel, translates to an effective radius of about 3.6 pixels on the WISE images. This configuration allows the 34-pixel cropped image to accommodate the radius, permitting a center offset of 3.6 pixels and ensuring that the target galaxies are accurately positioned at the center. Consequently, this method enhances the reliability and accuracy of data marking. Accuracy is defined as the ratio of the number of correctly classified samples to the total number of samples. Finally, the identified galaxies are divided into training, validation, and test sets in a proportion of 7:2:1, with the detailed parameters presented in
Table 1.
The classification of spiral and elliptical galaxies in the Galaxy Zoo 2 dataset was conducted using a series of stringent threshold criteria to ensure morphological accuracy (
Table 1). For spiral galaxies, the selection process first requires the frequency of disk or smooth structures (T01) to be no less than 0.430, ensuring that the chosen galaxies exhibit prominent disk structures. Additionally, the frequency of non-edge views (T02) must reach 0.715 or higher to reduce errors caused by edge-on perspectives and to enhance the clarity of spiral structures. Furthermore, the frequency of identified spiral structures (T04) must not fall below 0.619, ensuring that the galaxies possess a distinct spiral morphology. These conditions effectively filter out readily identifiable spiral galaxies but may inadvertently lead to the misclassification of edge-on galaxies as elliptical. When observed edge-on, spiral galaxies may not exhibit their characteristic spiral structure or disk morphology clearly, which can result in their erroneous categorization as elliptical galaxies. Despite rigorous efforts to mitigate the impact of edge-on perspectives in the data processing stage, completely eliminating such misclassifications remains challenging.
Similarly, the classification criteria for elliptical galaxies require the frequency of smooth structures (T01) to be no less than 0.469, effectively excluding galaxies with disk-like features. Moreover, the frequency of perfectly rounded galaxies (T07) must meet or exceed 0.5, confirming that the galaxies exhibit the characteristic elliptical morphology. These rigorous screening conditions enable the accurate identification of disk and spiral structures in spiral galaxies, while elliptical galaxies are characterized by smoother, more circular forms.
Task T06 emphasizes the identification and processing of unique features within images, including galaxy mergers and interactions, which can profoundly influence the classification outcomes of other tasks (e.g., T01 and T07). Through the analysis of complex images, T06 facilitates the precise classification of spiral and elliptical galaxies, thereby ensuring adherence to the criteria of smooth structure and optimal roundness.
In particular, T06 has a substantial impact on classifying spiral and elliptical galaxies by focusing on exotic features present in the images. These features include galaxy mergers, multiple object phenomena, lensing effects, and image bias. All of these factors can seriously affect the accuracy of the classification. Merging galaxies may mix disk and spiral structures, causing classification models to fail to accurately recognize spiral features; multi-celestial phenomena may mask spiral structures, making classification difficult; and lensing galaxies and image bias may distort the actual morphology of galaxies, affecting the accuracy of classification. For elliptical galaxies, these special features may also make their smooth and rounded nature less obvious. Therefore, special attention needs to be paid to identifying and dealing with these unusual features when processing these galaxy data. The contamination of the sample by these features can be minimized by image enhancement processing.
Positional information in terms of RA and Dec was obtained from the Galaxy Zoo 2 dataset. Based on these coordinates, data in the W1 band (3.4 µm), W2 band (4.6 µm), and W3 band (12 µm) were extracted from the WISE database for cross-matching. The W1, W2, and W3 bands of WISE are widely utilized in Color–Color diagrams to characterize the color features and spectral properties of celestial objects. This is crucial for the accurate classification and identification of objects. The W1 and W2 bands provide detailed observations in the near-infrared range, revealing the fundamental structure of galaxies and the distribution of interstellar dust. The W3 band, on the other hand, is instrumental in detecting thermal emissions and dust clouds.
In contrast, the W4 band (22 µm) of WISE was excluded from this study due to its lower sensitivity and larger point spread function (PSF), which resulted in less clear and detailed images. Therefore, data from the W1 (3.4 µm), W2 (4.6 µm), and W3 (12 µm) bands were selected. These bands are assumed to capture sufficient detail in the synthetic images and minimize the impact of background noise on the classification results.
The image synthesis and preprocessing methods proposed by Pan et al. [
14] were employed to enhance the quality and classification accuracy of galaxy images. The effectiveness of the methods was further demonstrated through an ablation study conducted by Pan et al. During the image synthesis process, the make_lupton_rgb function was used to combine the WISE data. Initially, the
W1,
W2, and
W3 bands were normalized to ensure that the data from each band were fused on the same scale. The stretch factor of the make_lupton_rgb function was set to 0.5, and the brightness factor Q was set to 2. These parameter settings enhance the contrast and brightness of the images, thereby clarifying the details. The synthesized images effectively integrated information from different bands, providing a more comprehensive view of the celestial bodies. The results of the synthesis are illustrated in
Figure 1.
To enhance the synthesized RGB image, we applied a non-local means denoising technique during the subsequent image preprocessing stage. This approach was selected to maintain the integrated context of the image by cohesively addressing noise characteristics across the combined bands. By denoising the RGB image, we ensured a unified treatment of noise across all channels, thus preserving both structural details and color information in the final composite. In the image preprocessing stage, a non-local means denoising technique was initially applied to effectively remove random noise while preserving important structural details. Subsequently, image enhancement techniques were employed to improve the contrast and sharpness of the images. These enhancements adjust the brightness and contrast, making the galaxy features more distinct and the images visually smoother. The results of these preprocessing steps are shown in
Figure 2.
3. EWGC
3.1. Backbone—Efficient Former V2
A series of novel network structures, including VMamba, RMT, StarNet, EfficientFormerV2, etc., were evaluated on the galaxy morphology classification task, with the results presented in
Table 2. As indicated in the table, EfficientFormerV2 demonstrated superior performance across all key metrics. Therefore, EfficientFormerV2 was selected as the foundational model for this study.
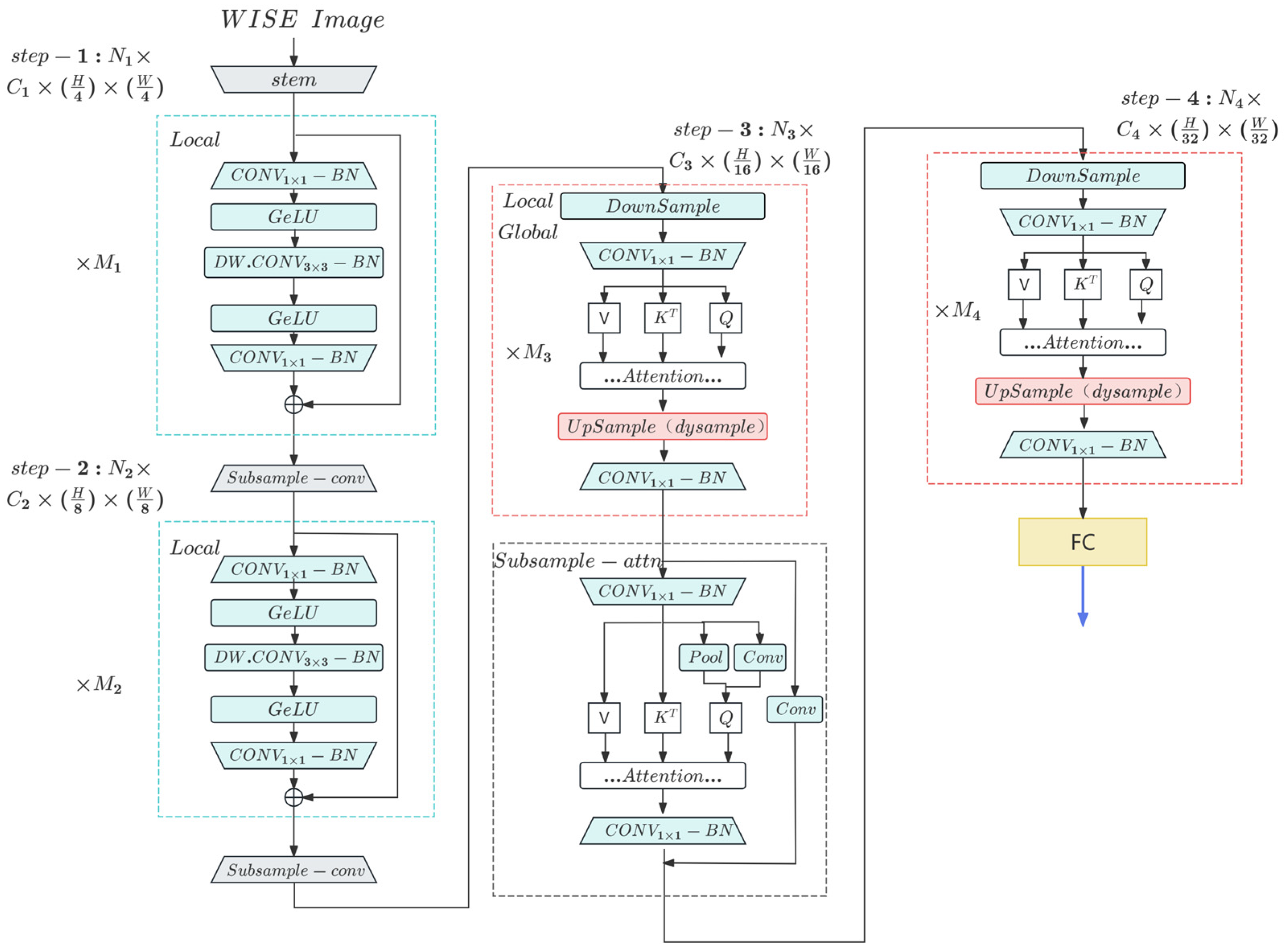
The EWGC, as illustrated in
Figure 3, is designed based on the EfficientFormerV2 model. It efficiently extracts features from the input WISE images through a four-layered structure, achieving accurate classification while maintaining low latency and small model size.
In the first two stages of the model, the primary focus is on the extraction of local features. Deep convolution (DW.CONV) is used as the local token mixer. A new efficient FFN structure is formed by integrating the local token mixer (DW.CONV) and channel mixer (FFN) within the Transformer structure in the same residual structure. This modification enhances the performance without adding delay. Additionally, the downsampling is achieved through a 3 × 3 convolution with a stride of 2, aligning with the design concept of localized feature extraction.
The model shows improvement in classification accuracy metrics such as Area Under the Curve (AUC) and the Matthews Correlation Coefficient (MCC). The AUC of the Receiver Operating Characteristic (ROC) curve reflects the model’s overall ability to distinguish between classes, while the MCC provides a balanced measure of performance even with imbalanced classes, by calculating the correlation between observed and predicted classifications. At the same time, the false positive rate (FPR) of EWGC is reduced, the training efficiency is optimized while the training time is reduced, and the computational efficiency is improved by reducing the FLOPs and the number of covariates, achieving a more balanced model performance.
The latter two stages of the model primarily focus on the efficient fusion of global information, a key strength of the attention mechanism. EfficientFormerV2 incorporates an improved version of Attention for Higher Resolution Mechanisms and Dual-Path Attention downsampling for feature extraction and downsampling. To efficiently handle higher resolution inputs, EfficientFormerV2 introduces Stride Attention, which downscales the Query, Key, and Value tokens to a fixed resolution, significantly reducing computational complexity. Additionally, the Dual-Path Attentional downsampling mechanism combines static local downsampling with global dependency modeling to further enhance the accuracy. These two newly introduced attention mechanisms simultaneously utilize a new Multi-Head Self-Attention (MHSA) computation approach, including the infusion of local information into the value matrix using deep convolution (DW.CONV), and the communication of global information between heads using Talking Heads.
After the “2 + 2” local and global feature extraction process, the network achieves the classification task by utilizing a fully connected layer.
3.2. Lightweight Learnable Upsampling Framework—Dysample
In Efficient former v2, efficient global attention computation is achieved by performing downsampling before the attention mechanism, followed by upsampling at the end to restore the original image scale. Downsampling is typically implemented through a convolutional operation, which can be effectively tailored to the data characteristics during training. However, the upsampling process employs standard bilinear interpolation, often insufficient in accurately reconstructing feature maps. This limitation is particularly pronounced for small-scale targets (less than 34 × 34 pixels), such as those in this study, where inefficient upsampling can negatively impact classification accuracy. To address this issue, this work introduces a lightweight, learnable upsampling framework—Dysample [
15]. The design specifics of the Dysample are described in the following (shown in
Figure 4).
A simple implementation of the Dysample is illustrated in
Figure 4a. Given a feature map of size
and a sampling set of size
, the two in the first dimension denote the x and y coordinates. The grid_sample function resamples the hypothetical bilinearly interpolated
X using the positions in
S, generating an
X′ of size
. This process is defined as follows:
provided an upsampling scale factor s and a feature map
X of size
. A linear layer with input and output channels
C and
, respectively, is utilized to yield an offset
O of size
. Then, it is reshaped into
using Pixel Shuffling. The sampling set
S is then the sum of the offset
O and the original sampling grid G, as follows:
Eventually, with the grid sample and sampling set S, an upsampled feature map of size can be created, as shown in Equation (1).
To enhance the accuracy of the initial sampling positions, a “static scope factor” is employed. In the original method, all the sampling locations were fixed at the same initial position, as shown in
Figure 5a, which neglects the spatial relationships between neighboring points. To address this issue, the sampling process was refined using a “bilinear initialization” approach, as illustrated in
Figure 5b. However, the overlap of sampling locations introduces prediction errors near the boundaries, which propagate incrementally, resulting in output artifacts. To mitigate this, the offset is multiplied by 0.25 to limit the displacement range of the sampling positions, as shown in
Figure 5c. This “static range factor” effectively regulates the theoretical boundary conditions between overlapping and non-overlapping areas, ensuring a smoother and more precise sampling process. Accordingly, Equation (2) is rewritten as follows:
3.3. EWGC_mag
Early releases of WISE data demonstrated that elliptical and spiral galaxies can be effectively distinguished through color–color diagrams, highlighting the critical role of magnitude information in the morphological classification of galaxies. The significance of this approach was further emphasized in the work of Pan et al. [
14], where the integration of magnitude data proved beneficial. Building on this foundation, the present study investigates the potential of incorporating magnitude information to enhance image-based galaxy morphology classification. Building on this approach, the EWGC_mag network was designed to fuse image features with magnitude parameter features. As illustrated in
Figure 6, the images are first processed to extract features, which are then flattened into a one-dimensional vector with 256 elements. Subsequently, the magnitude parameters (
W1,
W2, and
W3) corresponding to each image are concatenated with this vector, resulting in a one-dimensional vector with 259 elements. This concatenated vector is finally input into a fully connected module for further processing.
5. Conclusions
The EWGC is introduced to classify spiral and elliptical galaxies. The study utilized a dataset comprising 12,088 spiral galaxies and 12,852 elliptical galaxies. This dataset was divided into a training set, a validation set, and a test set in the proportion of 7:2:1. The EWGC achieved a classification accuracy of 90.02% on the test set, with 89.37% accuracy for spiral galaxies and 90.63% for elliptical galaxies. Comparative tests with other classification networks confirmed the superior performance of the EWGC, particularly highlighting the effectiveness of its improvement module.
Additionally, the performance of the EWGC in “single” and “multiple” galaxy classification tasks is further analyzed. The results demonstrated that the EWGC maintains high classification accuracy even when processing complex images containing multiple celestial bodies. Following the principle of multimodal feature fusion, the EWGC_mag network was developed to combine WISE image features with magnitude features. While the overall classification accuracy did not significantly change from the original network, this design showcased the model’s capability to extract and utilize galaxy magnitude information.
To further enhance the accuracy of galaxy morphology classification, future work will focus on two key directions. First, deep generative models (e.g., variational autoencoders) will be explored to generate high-quality synthetic images, thereby expanding the dataset and improving the classification model’s performance. Second, incorporating spectral data will be considered to provide a more comprehensive analysis of the physical properties of galaxies. These efforts are expected to further improve the accuracy of galaxy classification and broaden the applicability of the models.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







































