
Drug Repurposing for Non-Alcoholic Fatty Liver Disease by Analyzing Networks Among Drugs, Diseases, and Genes

 ,
, 
 ,
, 
 and
and
Abstract
1. Introduction
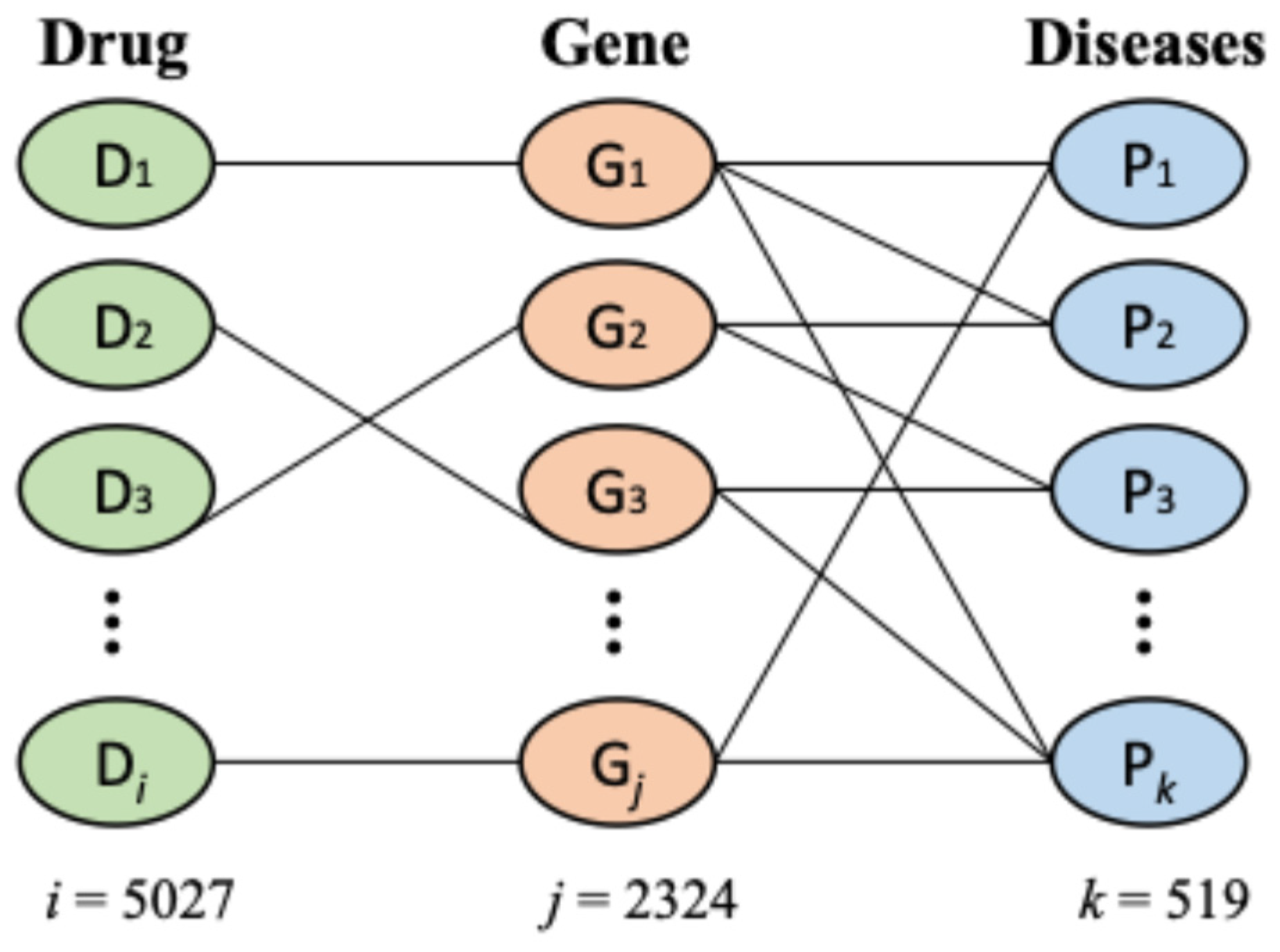
2. Materials and Methods
2.1. Data
2.2. Methods
2.2.1. Drug Selection by Bi-Clustering
2.2.2. Drug Selection Based on Disease Similarity
2.3. Ranking and Final Selection
3. Results
3.1. Screening Potential Drugs by Bi-Clustering
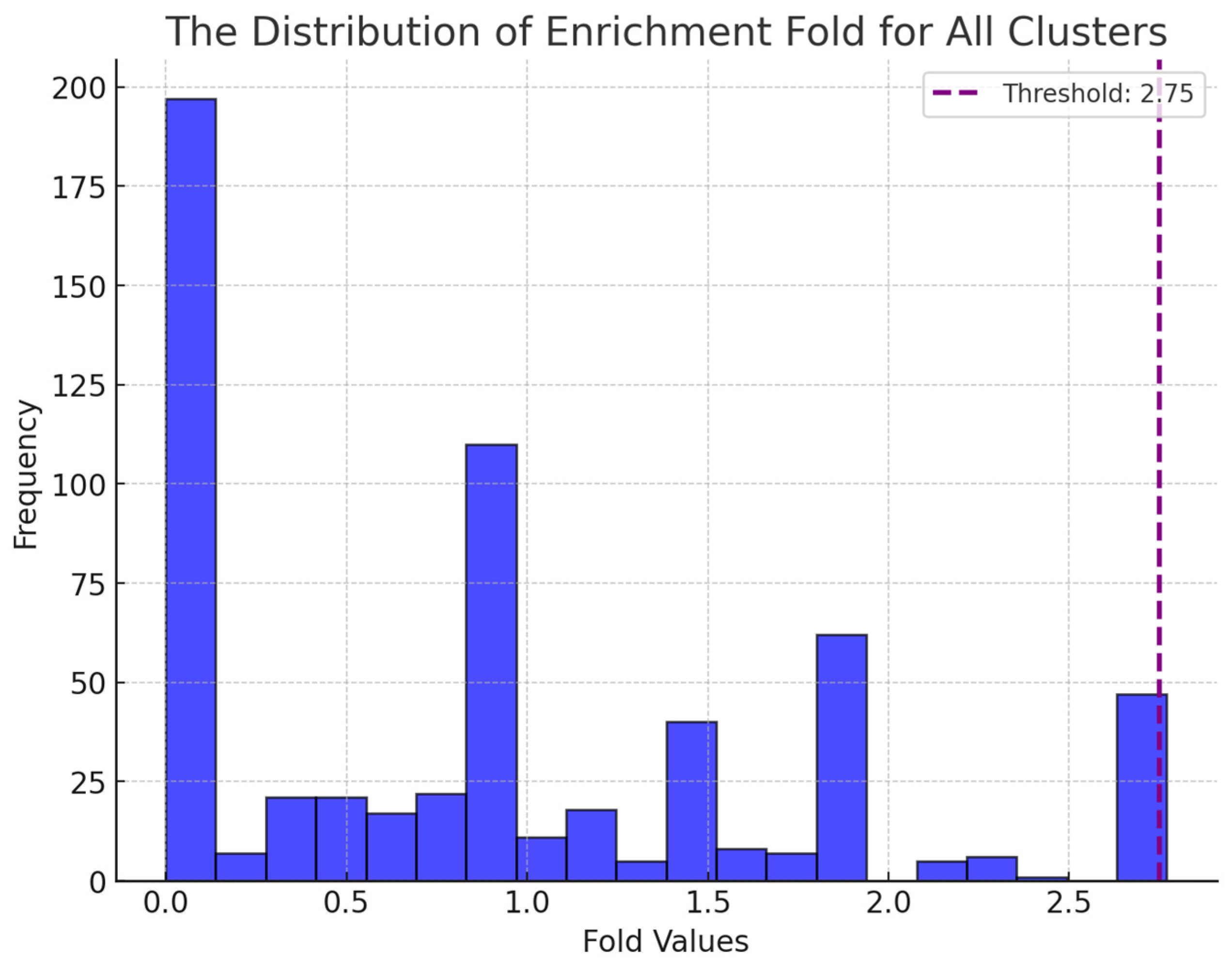
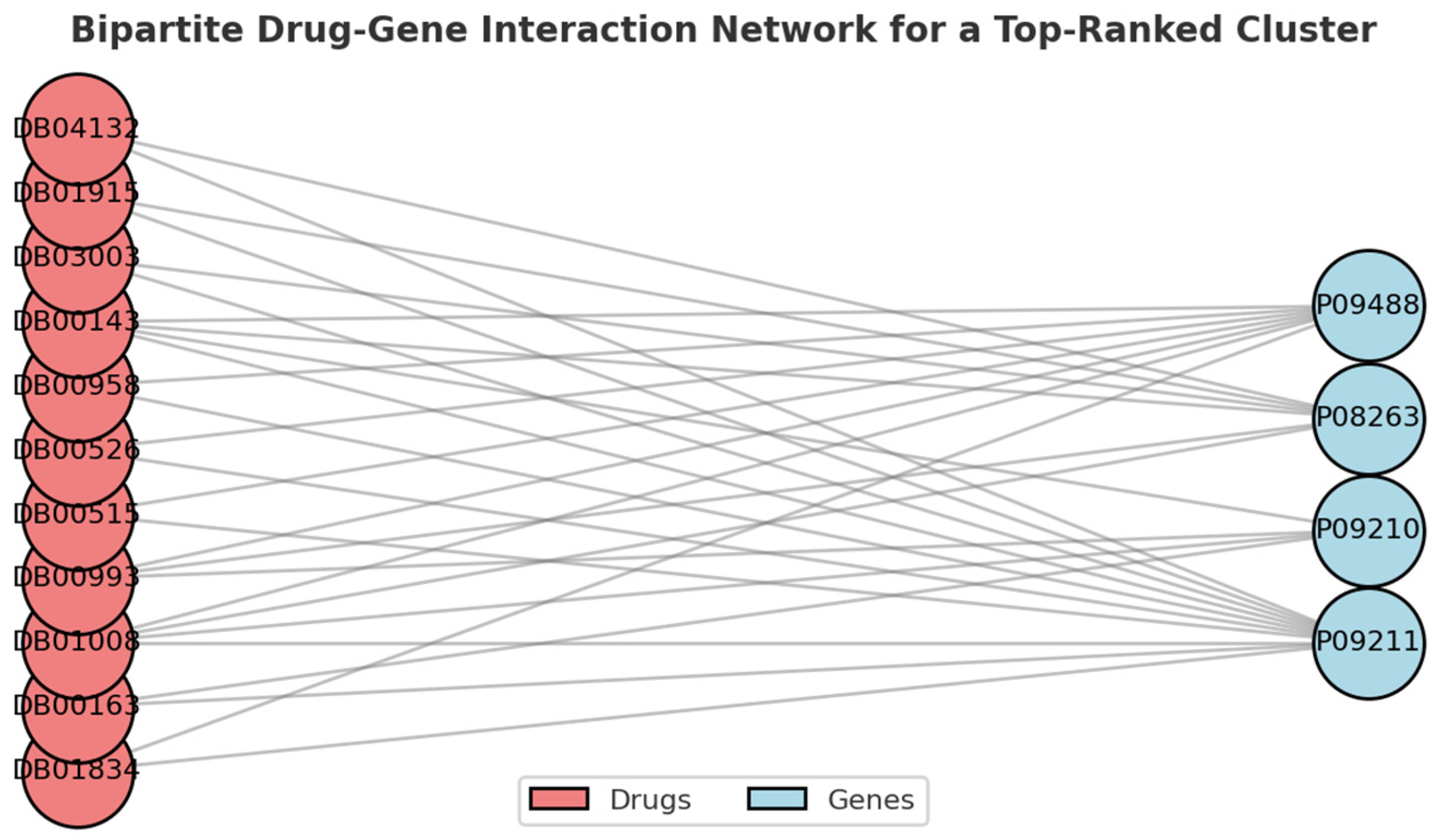
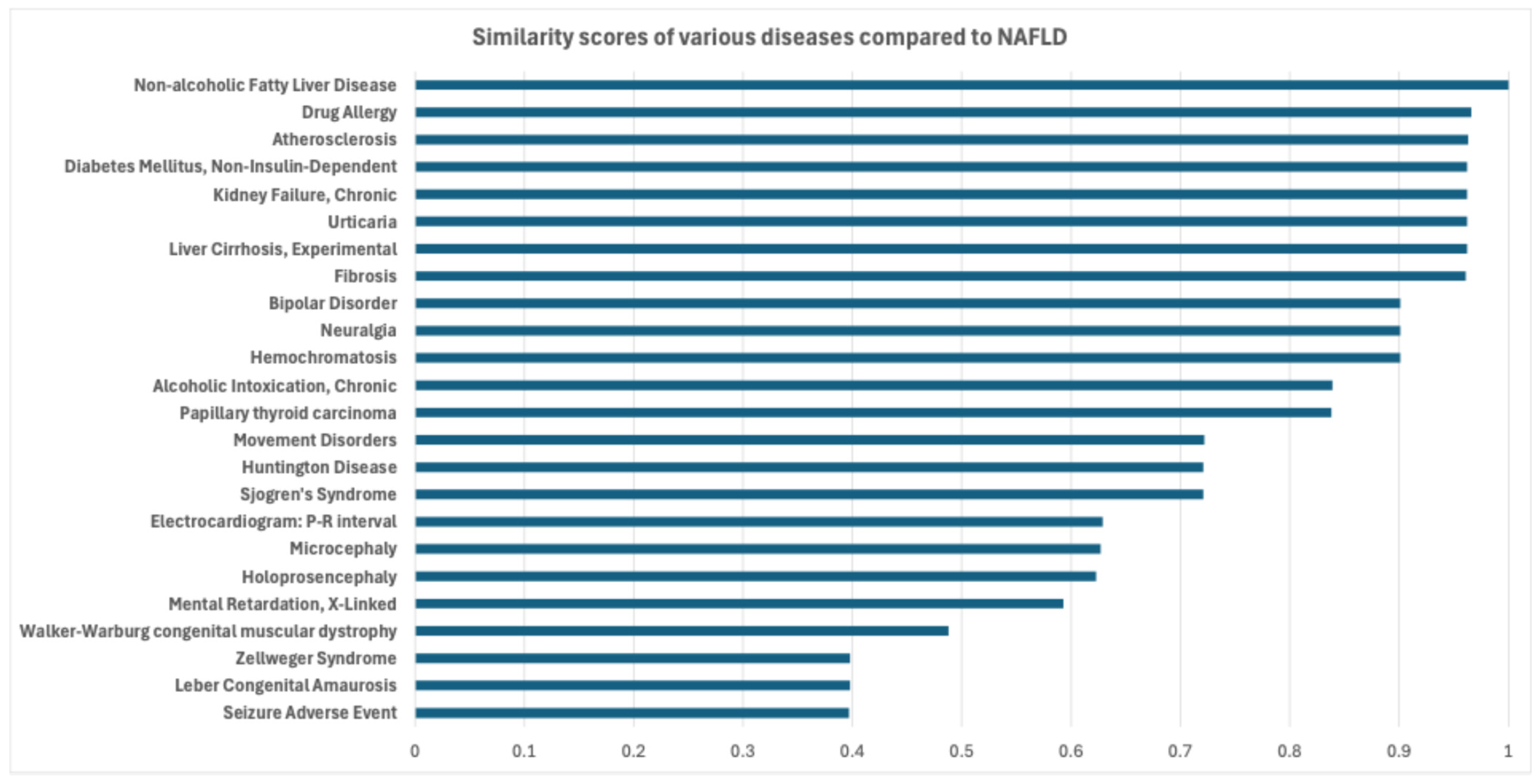
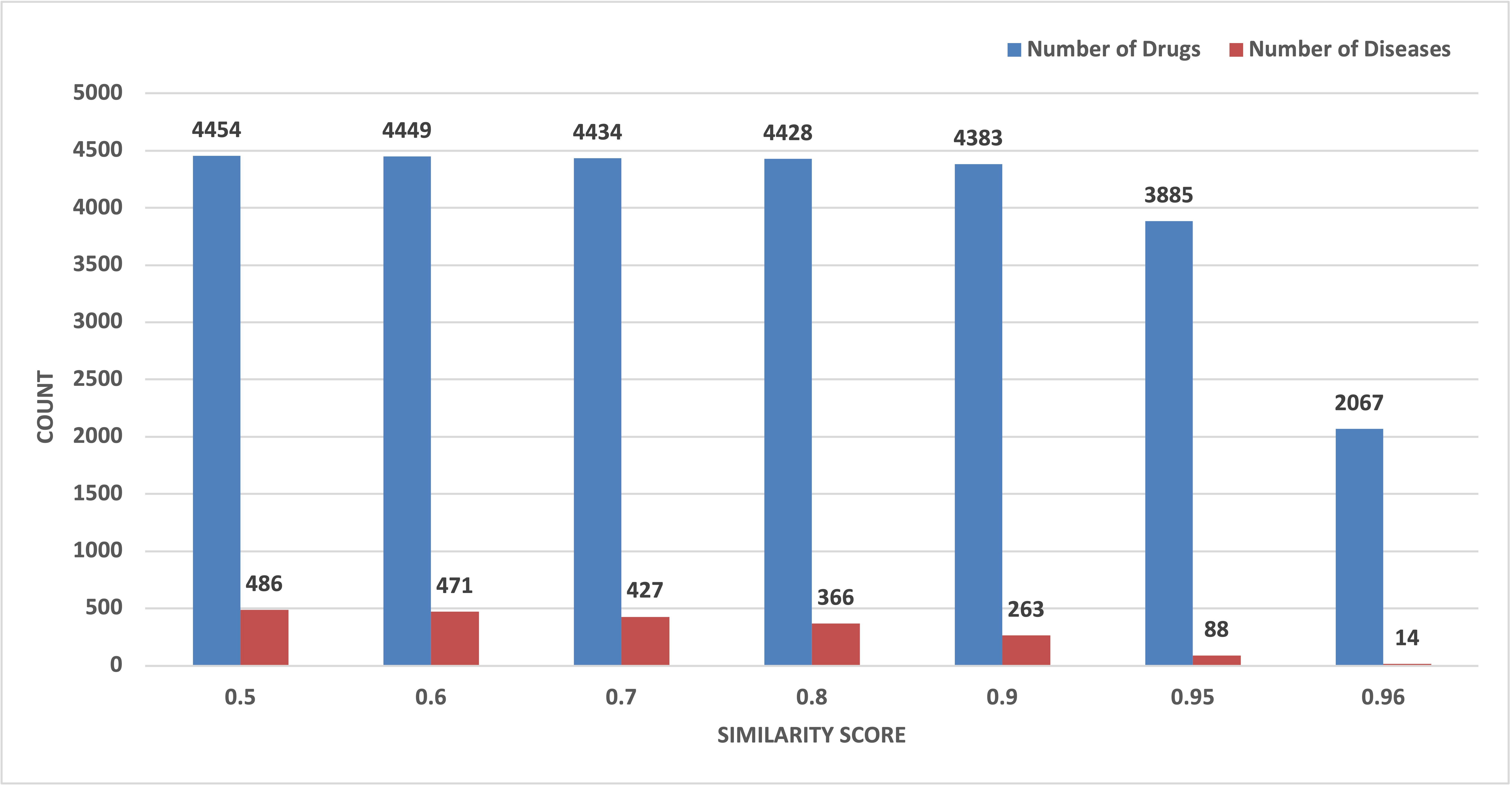
3.2. Screening Potential Drugs by Disease Similarity
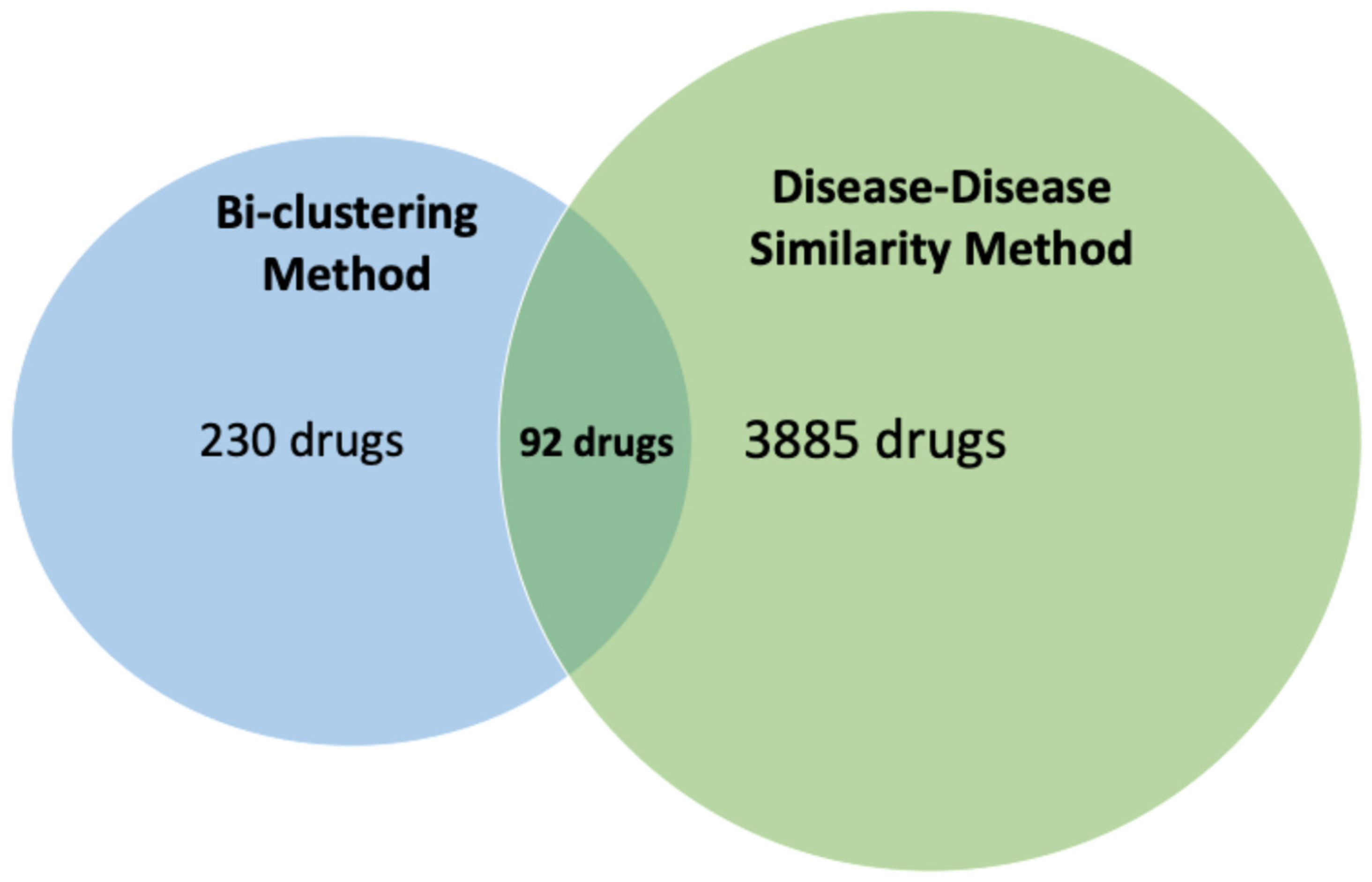
3.3. Final Selection
3.4. Validation of Potential Drugs
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pushpakom, S.; Iorio, F.; Eyers, P.A.; Escott, K.J.; Hopper, S.; Wells, A.; Doig, A.; Guilliams, T.; Latimer, J.; McNamee, C.; et al. Drug repurposing: Progress, challenges and recommendations. Nat. Rev. Drug Discov. 2019, 18, 41–58. [Google Scholar] [PubMed]
- Roundtable on Translating Genomic-Based Research for Health; Board on Health Sciences Policy; Institute of Medicine. Drug Repurposing ad Repositioning: Workshop Summary; National Academies Press: Washington, DC, USA, 2014. [Google Scholar]
- Ashburn, T.T.; Thor, K.B. Drug Repositioning: Identifying and Developing New Uses for Existing Drugs. Nat. Rev. Drug Discov. 2004, 3, 673–683. [Google Scholar] [CrossRef]
- Reeves, H.L.; Zaki, M.Y.W.; Day, C.P. Hepatocellular carcinoma in obesity, type 2 diabetes, and NAFLD. Dig. Dis. Sci. 2016, 61, 1234–1245. [Google Scholar] [PubMed]
- Tada, T.; Kumada, T.; Toyoda, H.; Mizuno, K.; Sone, Y.; Akita, T.; Tanaka, J. Progression of liver fibrosis is associated with non-liver-related mortality in patients with nonalcoholic fatty liver disease. Hepatol. Commun. 2017, 1, 899–910. [Google Scholar] [PubMed]
- Valenzuela-Vallejo, L.; Guatibonza-García, V.; Mantzoros, C.S. Recent guidelines for Non-Alcoholic Fatty Liver disease (NAFLD)/Fatty Liver Disease (FLD): Are they already outdated and in need of supplementation? Metabolism 2022, 136, 155248. [Google Scholar] [CrossRef]
- Younossi, Z.M.; Zelber-Sagi, S.; Henry, L.; Gerber, L.H. Lifestyle interventions in nonalcoholic fatty liver disease. Nat. Rev. Gastroenterol. Hepatol. 2023, 20, 708–722. [Google Scholar] [CrossRef]
- Zhang, C.; Shi, M.; Kim, W.; Arif, M.; Klevstig, M.; Li, X.; Yang, H.; Bayram, C.; Bolat, I.; Tozlu, Ö.Ö.; et al. Discovery of therapeutic agents targeting PKLR for NAFLD using drug repositioning. eBioMedicine 2022, 83, 104234. [Google Scholar]
- Piñero, J.; Ramírez-Anguita, J.M.; Saüch-Pitarch, J.; Ronzano, F.; Centeno, E.; Sanz, F.; Furlong, L.I. The DisGeNET knowledge platform for disease genomics: 2019 update. Nucleic Acids Res. 2020, 48, D845–D855. [Google Scholar] [CrossRef]
- Huang, L.; Luo, H.M.; Yang, M.; Wu, F.X.; Wang, J. Drug and disease similarity calculation platform for drug repositioning. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 124–129. [Google Scholar]
- Upton, G.J.G. Fisher’s exact test. J. R. Stat. Soc. Ser. A (Stat. Soc.) 1992, 155, 395–402. [Google Scholar]
- Altaf-Ul-Amin, M. Drug repurposing for inflammatory bowel disease based on relations among drugs, diseases and genes. J. Gastroenterol. Hepatol. 2023, 9, 1–8. [Google Scholar]
- Leskovec, J.; Sosic, R. Snap: A general-purpose network analysis and graph-mining library. ACM Trans. Intell. Syst. Technol. (TIST) 2016, 8, 1–20. [Google Scholar] [CrossRef]
- Sollis, E.; Mosaku, A.; Abid, A.; Buniello, A.; Cerezo, M.; Gil, L.; Groza, T.; Günes, O.; Hall, P.; Hayhurst, J.; et al. The NHGRI-EBI GWAS catalog: Knowledgebase and deposition resource. Nucleic Acids Res. 2023, 51, D977–D985. [Google Scholar] [CrossRef]
- Davis, A.P.; Wiegers, T.C.; Johnson, R.J.; Sciaky, D.; Wiegers, J.; Mattingly, C.J. Comparative toxicogenomics database (CTD): Update 2023. Nucleic Acids Res. 2023, 51, D1257–D1262. [Google Scholar] [CrossRef] [PubMed]
- Altaf-Ul-Amin, M.; Shinbo, Y.; Mihara, K.; Kurokawa, K.; Kanaya, S. Development and implementation of an algorithm for detection of protein complexes in large interaction networks. BMC Bioinform. 2006, 7, 207. [Google Scholar] [CrossRef] [PubMed]
- Karim, M.B.; Kanaya, S.; Altaf-Ul-Amin, M. DPClusSBO: An integrated software for clustering of simple and bipartite graphs. SoftwareX 2021, 16, 100821. [Google Scholar] [CrossRef]
- Karim, M.B.; Huang, M.; Ono, N.; Kanaya, S.; Altaf-Ul-Amin, M. BiClusO: A novel biclustering approach and its application to species–VOC relational data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 17, 1955–1965. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.; Gao, L.; Wang, B.; Guo, X. HPOSim: An R package for phenotypic similarity measure and enrichment analysis based on the human phenotype ontology. PLoS ONE 2015, 10, e0115692. [Google Scholar] [CrossRef]
- Duan, Y.; Pan, X.; Luo, J.; Xiao, X.; Li, J.; Bestman, P.L.; Luo, M. Association of Inflammatory Cytokines with Non-Alcoholic Fatty Liver Disease. Front. Immunol. 2022, 13, 880298. [Google Scholar] [CrossRef]
- Chang, G.-R.; Liu, H.-Y.; Yang, W.-C.; Wang, C.-M.; Wu, C.-F.; Lin, J.-W.; Lin, W.-L.; Wang, Y.-C.; Lin, T.-C.; Liao, H.-J.; et al. Clozapine Worsens Glucose Intolerance, Nonalcoholic Fatty Liver Disease, Kidney Damage, and Retinal Injury and Increases Renal Reactive Oxygen Species Production and Chromium Loss in Obese Mice. Int. J. Mol. Sci. 2021, 22, 6680. [Google Scholar] [CrossRef]
- Lawan, A.; Bennett, A.M. Mitogen-Activated Protein Kinase Regulation in Hepatic Metabolism. Trends Endocrinol. Metab. 2017, 28, 868–878. [Google Scholar]
- Yang, W.; Liao, W.; Li, X.; Ai, W.; Pan, Q.; Shen, Z.; Jiang, W.; Guo, S. Hepatic p38α MAPK Controls Gluconeogenesis via FOXO1 Phosphorylation at S273 during Glucagon Signalling in Mice. Diabetologia 2023, 66, 1322–1339. [Google Scholar] [CrossRef] [PubMed]
- Hadi, H.E.; Vettor, R.; Rossato, M. Vitamin E as a treatment for nonalcoholic fatty liver disease: Reality or myth? Antioxidants 2018, 7, 12. [Google Scholar] [CrossRef] [PubMed]
- Sato, K.; Gosho, M.; Yamamoto, T.; Kobayashi, Y.; Ishii, N.; Ohashi, T.; Nakade, Y.; Ito, K.; Fukuzawa, Y.; Yoneda, M. Vitamin E Has a Beneficial Effect on Nonalcoholic Fatty Liver Disease: A Meta-Analysis of Randomized Controlled Trials. Nutrients 2015, 31, 923–930. [Google Scholar] [CrossRef] [PubMed]
- Usman, M.; Bakhtawar, N. Vitamin E as an Adjuvant Treatment for Non-Alcoholic Fatty Liver Disease in Adults: A Systematic Review of Randomized Controlled Trials. Cureus 2020, 12, e9274. [Google Scholar] [CrossRef]
- Li, L.; Wang, H.; Yao, Y.; Cao, J.; Jiang, Z.; Yan, W.; Chu, X.; Li, Q.; Lu, M.; Ma, H. The Sex Steroid Precursor Dehydroepiandrosterone Prevents Nonalcoholic Steatohepatitis by Activating the AMPK Pathway Mediated by GPR30. Redox Biol. 2021, 48, 102187. [Google Scholar]
- Murali, G.; Milne, G.L.; Webb, C.D.; Stewart, A.B.; McMillan, R.P.; Lyle, B.C.; Hulver, M.W.; Saraswathi, V. Fish Oil and Indomethacin in Combination Potently Reduce Dyslipidemia and Hepatic Steatosis in LDLR−/− Mice. J. Lipid Res. 2012, 53, 2186–2197. [Google Scholar] [PubMed]
- Moghadam, H.; Jafaripour, L. Beneficial Effects of Propofol and Silymarin on the Liver: Silymarin Lowers the Hyperlipidemia Induced by Propofol. Iran. J. Toxicol. 2024, 18, 158–165. [Google Scholar]
- Martínez Soriano, B.; Güemes, A.; Pola, G.; Gonzalo, A.; Palacios Gasós, P.; Navarro, A.C.; Martínez-Beamonte, R.; Osada, J.; García, J.J. Effect of melatonin as an antioxidant drug to reverse hepatic steatosis: Experimental model. Can. J. Gastroenterol. Hepatol. 2020, 2020, 7315253. [Google Scholar]
- Bahrami, M.; Cheraghpour, M.; Jafarirad, S.; Alavinejad, P.; Asadi, F.; Hekmatdoost, A.; Mohammadi, M.; Yari, Z. The Effect of Melatonin on Treatment of Patients with Non-Alcoholic Fatty Liver Disease: A Randomized Double Blind Clinical Trial. Complement. Ther. Med. 2020, 52, 102452. [Google Scholar] [CrossRef]
- Zhao, P.; Yang, W.; Xiao, H.; Zhang, S.; Gao, C.; Piao, H.; Liu, L.; Li, S. Vitamin K2 Protects Mice Against Non-Alcoholic Fatty Liver Disease Induced by High-Fat Diet. Sci. Rep. 2024, 14, 3075. [Google Scholar] [CrossRef] [PubMed]
- Ramanathan, R.; Ali, A.H.; Ibdah, J.A. Mitochondrial Dysfunction Plays Central Role in Nonalcoholic Fatty Liver Disease. Int. J. Mol. Sci. 2022, 23, 7280. [Google Scholar] [CrossRef] [PubMed]
- Jensen, T.; Abdelmalek, M.F.; Sullivan, S.; Nadeau, K.J.; Green, M.; Roncal, C.; Nakagawa, T.; Kuwabara, M.; Sato, Y.; Kang, D.-H.; et al. Fructose and Sugar: A Major Mediator of Non-Alcoholic Fatty Liver Disease. J. Hepatol. 2018, 68, 1063–1075. [Google Scholar] [CrossRef]
- Paniz, G.R.; Arroyo-Mercado, F.M.; Ling, C.L.; Choi, E.E.; Snow, H.E.; Rakov, N.E.; Castillo, E.F. Assessment of Mesalamine in the Alterations of Metabolic Parameters in Comorbid Ulcerative Colitis and Metabolic Syndrome Patients: A Retrospective Study. medRxiv 2021. [Google Scholar] [CrossRef]
- Gibiino, G.; Sartini, A.; Gitto, S.; Binda, C.; Sbrancia, M.; Coluccio, C.; Sambri, V.; Fabbri, C. The Other Side of Malnutrition in Inflammatory Bowel Disease (IBD): Non-Alcoholic Fatty Liver Disease. Nutrients 2021, 13, 2772. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Initial Data | Processing Method | Final Data |
|---|---|---|---|
| CTD | 37,193 | Top 2.5% inference score | 924 |
| DisGeNET | 1058 | - | 1058 |
| GWAS | 407 | Uniprot ID conversion | 312 |
| Parameter | Value | Description |
|---|---|---|
| Cluster property | 0.5 | Used for periphery tracking in simple graph clustering. |
| Cluster density | 0.5 | Minimum density for generated simple clusters. |
| Tanimoto coefficient | 0.1 | Used as a threshold to convert a bipartite graph to a simple graph. |
| Relation number | 1 | Used as a threshold to convert a bipartite graph to a simple graph. |
| Attachment probability | 0.5 | Threshold for finding the second set of nodes of a bi-cluster. |
| Potential Drug | DrugBank Id | DC Score | GA Score | Total Score |
|---|---|---|---|---|
| Andrographolide | DB05767 | 76 | 5 | 81 |
| Clozapine | DB00363 | 42 | 38 | 80 |
| VX-702 | DB05470 | 76 | 4 | 80 |
| Dilmapimod | DB05250 | 76 | 3 | 79 |
| Vitamin E | DB00163 | 59 | 18 | 77 |
| YSIL6 | DB05017 | 75 | 2 | 77 |
| Talmapimod | DB05412 | 68 | 4 | 72 |
| Prasterone | DB01708 | 37 | 34 | 71 |
| Indomethacin | DB00328 | 55 | 14 | 69 |
| Propofol | DB00818 | 32 | 35 | 67 |
| Sulfasalazine | DB00795 | 54 | 11 | 65 |
| Melatonin | DB01065 | 48 | 17 | 65 |
| Menadione | DB00170 | 44 | 20 | 64 |
| ATP | DB00171 | 30 | 34 | 64 |
| Mesalazine | DB00244 | 56 | 7 | 63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altaf-Ul-Amin, M.; Nasution, A.K.; Islam, R.M.; Gao, P.; Ono, N.; Kanaya, S. Drug Repurposing for Non-Alcoholic Fatty Liver Disease by Analyzing Networks Among Drugs, Diseases, and Genes. Metabolites 2025, 15, 255. https://doi.org/10.3390/metabo15040255
Altaf-Ul-Amin M, Nasution AK, Islam RM, Gao P, Ono N, Kanaya S. Drug Repurposing for Non-Alcoholic Fatty Liver Disease by Analyzing Networks Among Drugs, Diseases, and Genes. Metabolites. 2025; 15(4):255. https://doi.org/10.3390/metabo15040255
Chicago/Turabian StyleAltaf-Ul-Amin, Md., Ahmad Kamal Nasution, Rumman Mahfujul Islam, Pei Gao, Naoaki Ono, and Shigehiko Kanaya. 2025. "Drug Repurposing for Non-Alcoholic Fatty Liver Disease by Analyzing Networks Among Drugs, Diseases, and Genes" Metabolites 15, no. 4: 255. https://doi.org/10.3390/metabo15040255
APA StyleAltaf-Ul-Amin, M., Nasution, A. K., Islam, R. M., Gao, P., Ono, N., & Kanaya, S. (2025). Drug Repurposing for Non-Alcoholic Fatty Liver Disease by Analyzing Networks Among Drugs, Diseases, and Genes. Metabolites, 15(4), 255. https://doi.org/10.3390/metabo15040255