Can We Trust Score Plots?


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Theory
3. Data
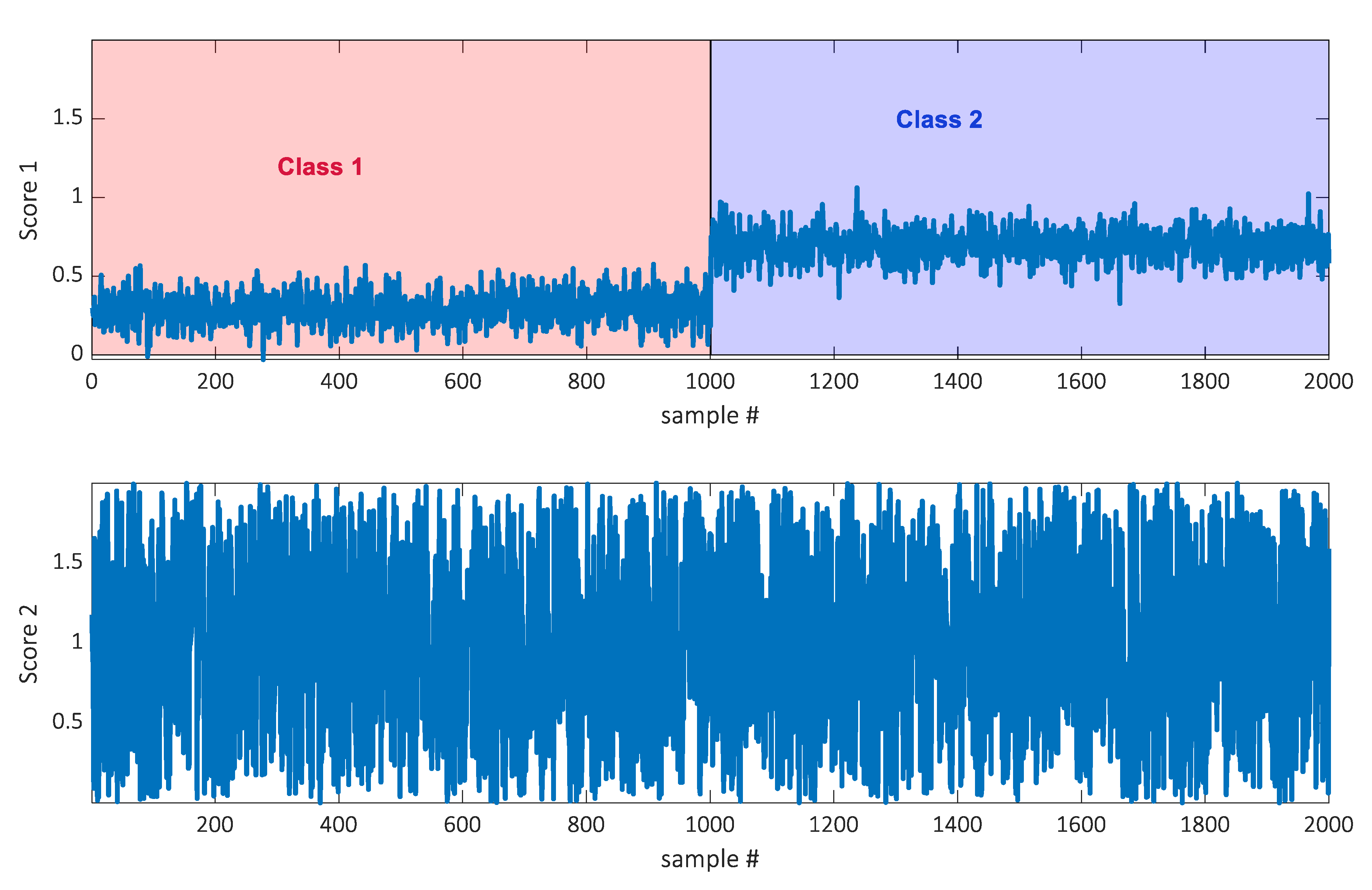
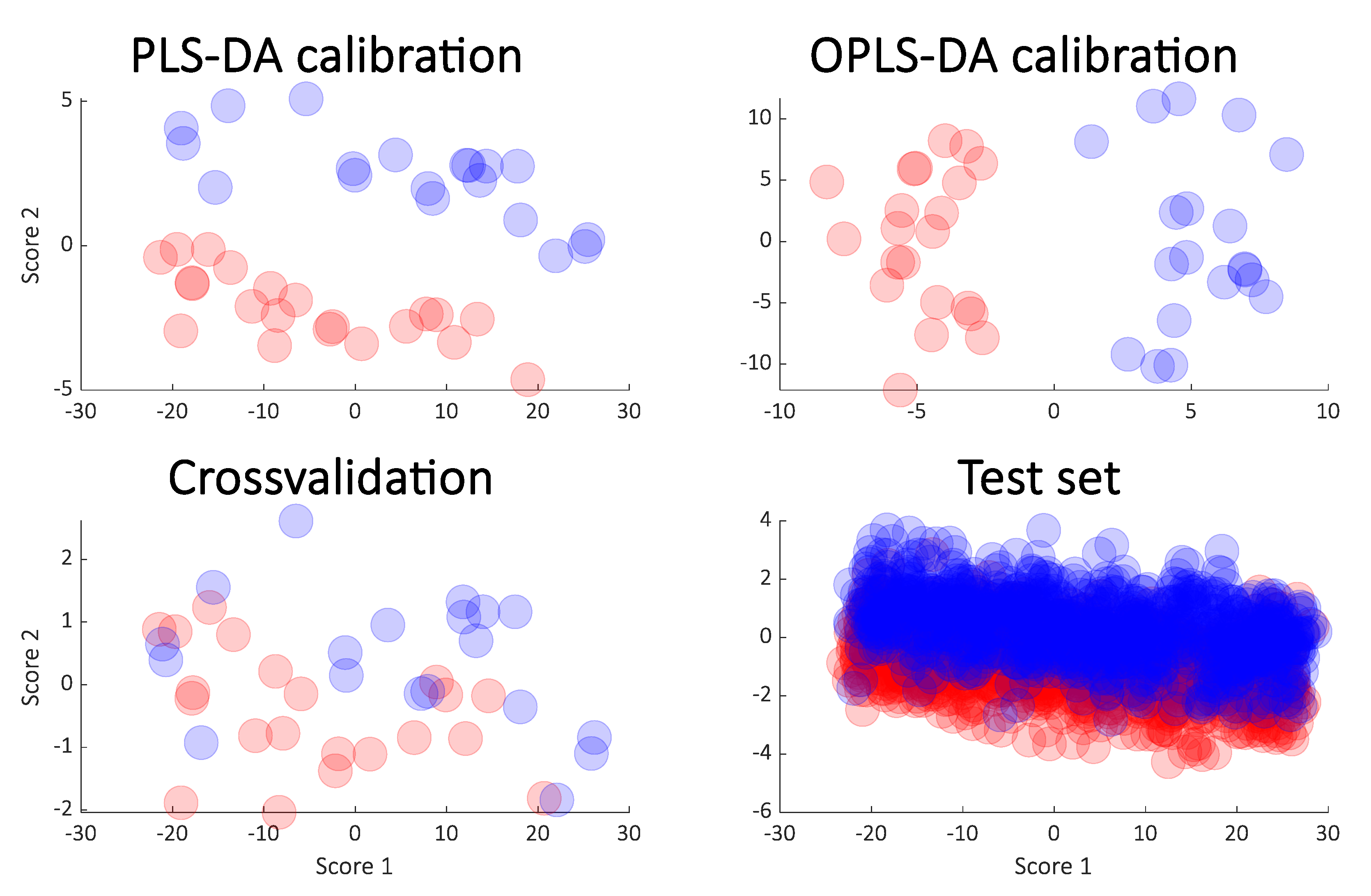
3.1. Simulated Data
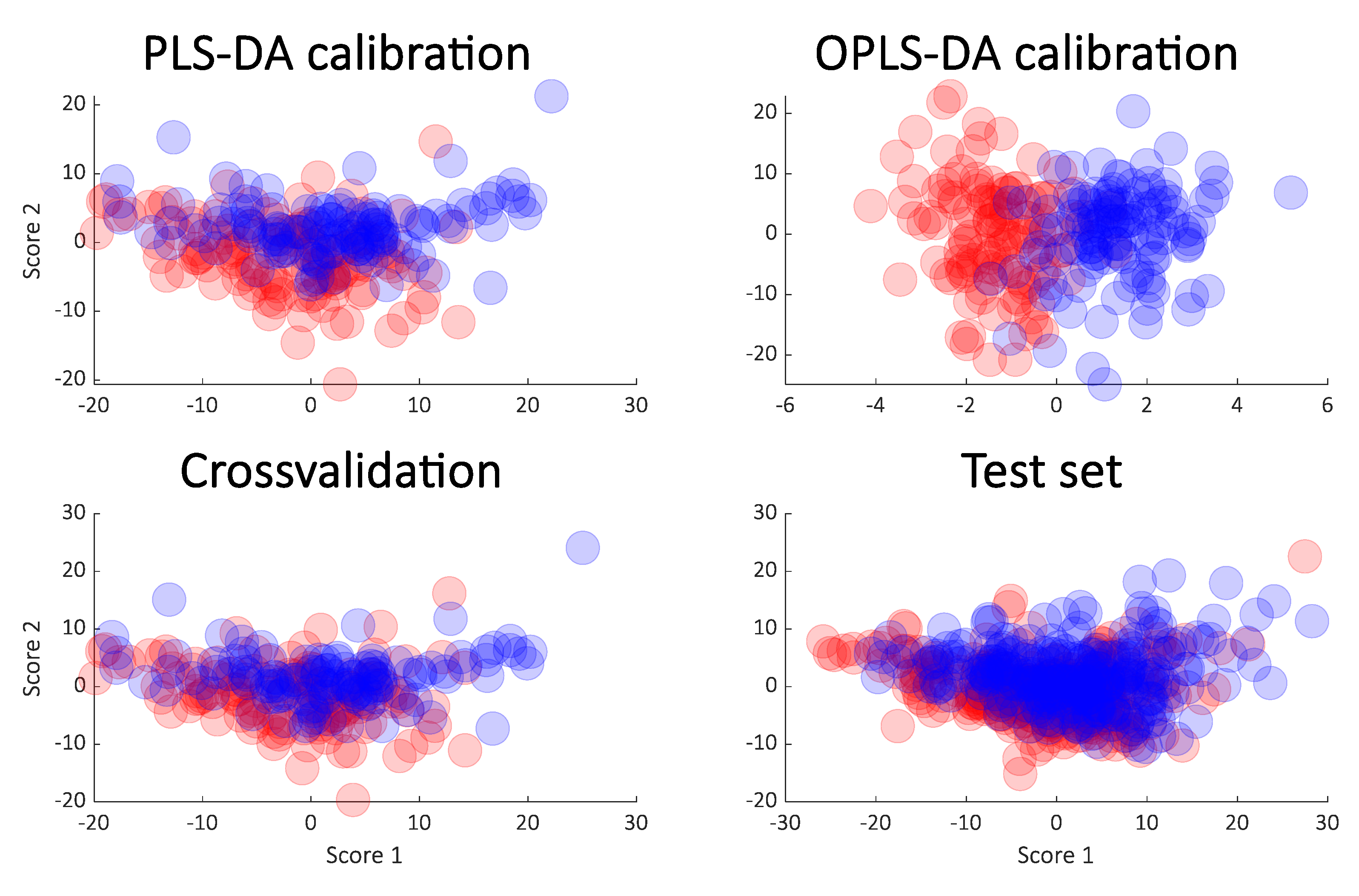
3.2. Cancer Data
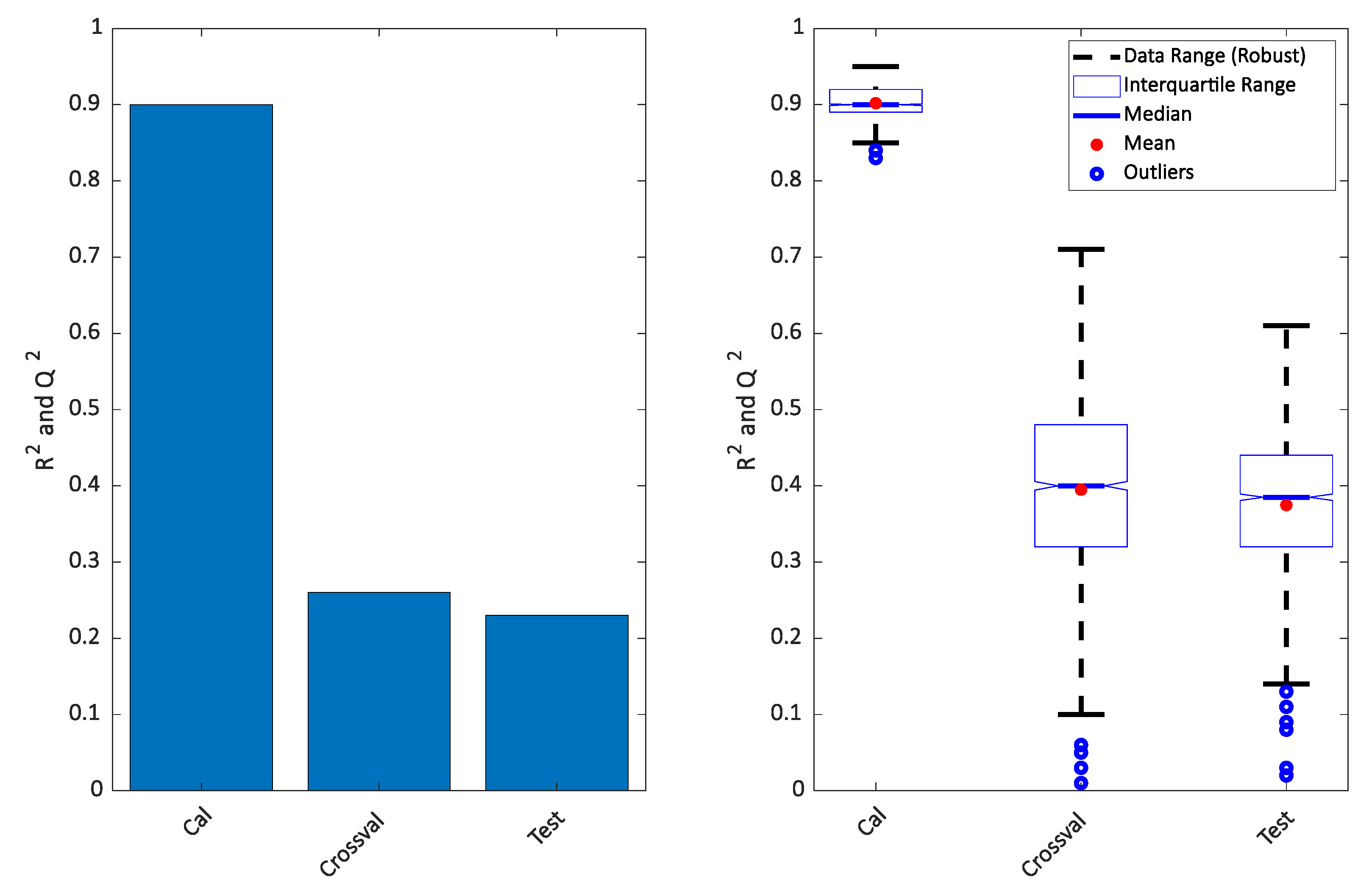
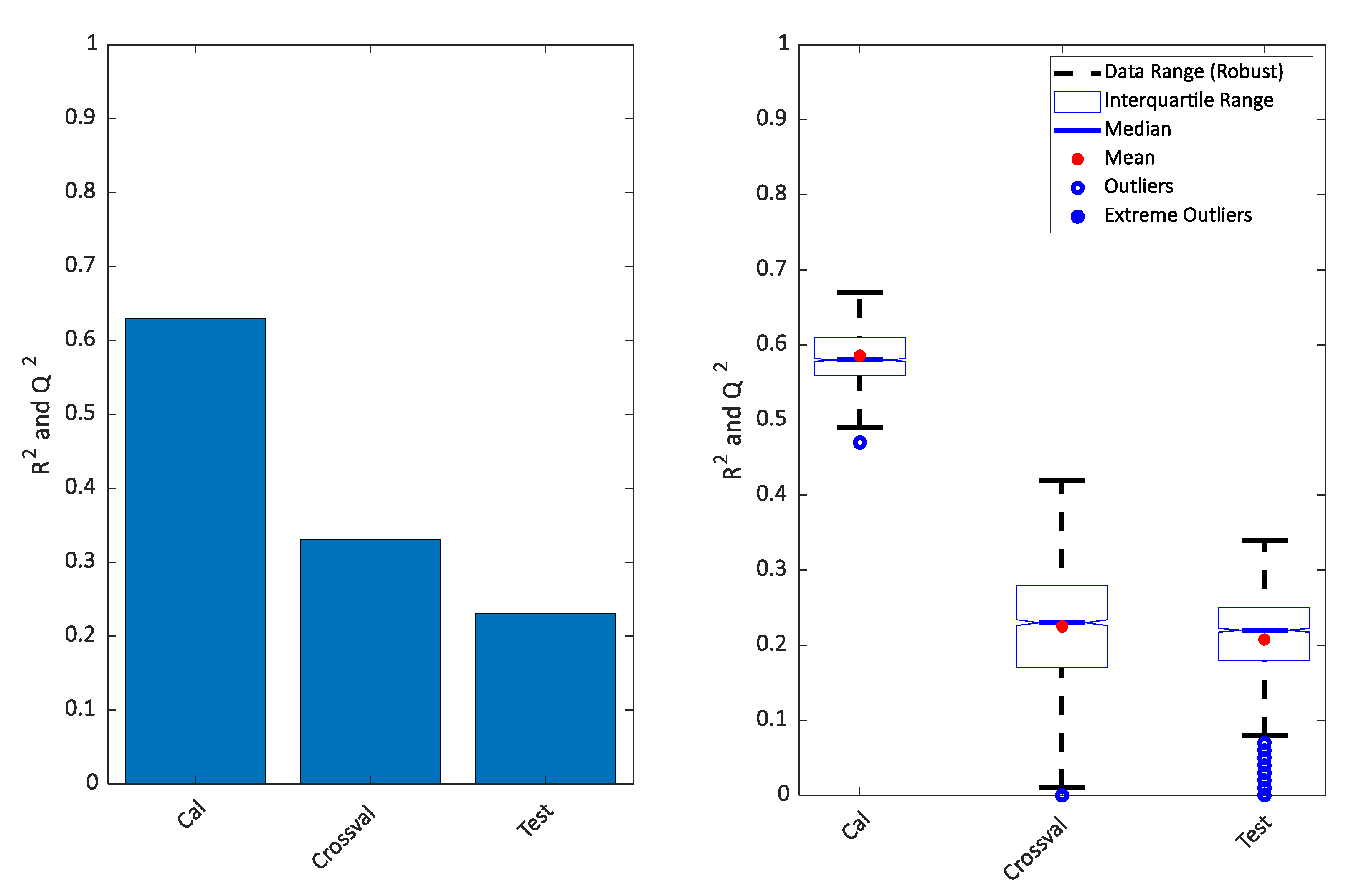
4. Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Wold, S.; Sjostrom, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Höskuldsson, A. PLS regression methods. J. Chemom. 1988, 2, 211–228. [Google Scholar] [CrossRef]
- Wold, S.; Trygg, J.; Berglund, A.; Antti, H. Some recent developments in PLS modeling. Chemom. Intell. Lab. Syst. 2001, 58, 131–150. [Google Scholar] [CrossRef]
- Barker, M.; Rayens, W. Partial least squares for discrimination. J. Chemom. 2003, 17, 166–173. [Google Scholar] [CrossRef]
- Clarke, R.; Ressom, H.W.; Wang, A.; Xuan, J.; Liu, M.C.; Gehan, E.A.; Wang, Y. The properties of high-dimensional data spaces: Implications for exploring gene and protein expression data. Nat. Rev. Cancer 2008, 8, 37–49. [Google Scholar] [CrossRef] [PubMed]
- Defernez, M.; Kemsley, E.K. The use and misuse of chemometrics for treating classification problems. Trends Anal. Chem. 1997, 16, 216–221. [Google Scholar] [CrossRef]
- Pretsch, E.; Wilkins, C.L. Use and abuse of chemometrics. Trac-Trends Anal. Chem. 2006, 25, 1045. [Google Scholar] [CrossRef]
- Martens, H.; Martens, M. Modified Jack-knife estimation of parameter uncertainty in bilinear modelling by partial least squares regression (PLSR). Food Qual. Prefer. 2000, 11, 5–16. [Google Scholar] [CrossRef]
- Eigenvector Research, Inc. PLS_Toolbox, version 8.8.1; Eigenvector Research, Inc.: Manson, WA, USA, 2020. Available online: http://www.eigenvector.com (accessed on 3 July 2020).
- Bro, R.; Kamstrup-Nielsen, M.; Engelsen, S.B.; Savorani, F.; Rasmussen, M.A.; Hansen, L.; Dragsted, L.H. Forecasting individual breast cancer risk using plasma metabolomics and biocontours. Metabolomics 2015, 11, 1376–1380. [Google Scholar] [CrossRef] [PubMed]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bevilacqua, M.; Bro, R. Can We Trust Score Plots? Metabolites 2020, 10, 278. https://doi.org/10.3390/metabo10070278
Bevilacqua M, Bro R. Can We Trust Score Plots? Metabolites. 2020; 10(7):278. https://doi.org/10.3390/metabo10070278
Chicago/Turabian StyleBevilacqua, Marta, and Rasmus Bro. 2020. "Can We Trust Score Plots?" Metabolites 10, no. 7: 278. https://doi.org/10.3390/metabo10070278
APA StyleBevilacqua, M., & Bro, R. (2020). Can We Trust Score Plots? Metabolites, 10(7), 278. https://doi.org/10.3390/metabo10070278