A User Segmentation Method in Heterogeneous Open Innovation Communities Based on Multilayer Information Fusion and Attention Mechanisms


Abstract
1. Introduction
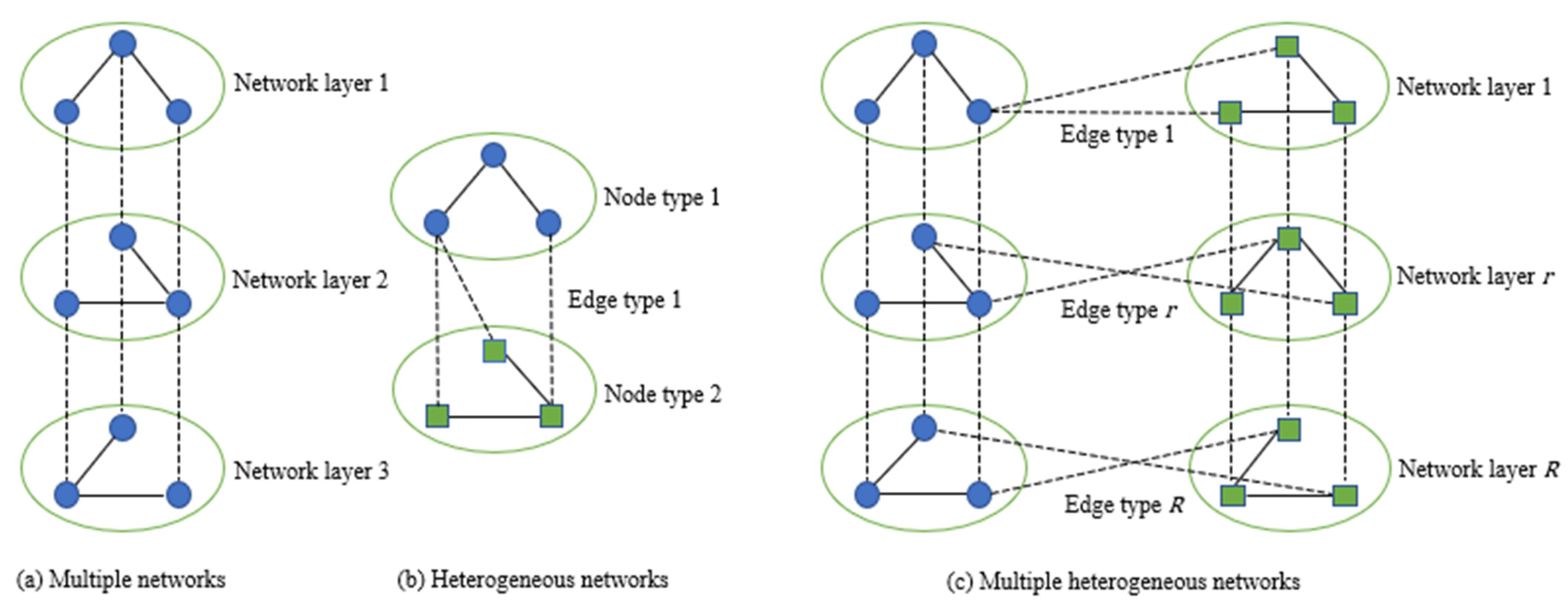
- This study investigates the user segmentation problem in heterogeneous OICs and develops a hierarchical processing method to transform heterogeneous communities into multiple heterogeneous networks in an attempt to better distinguish and fuse network structure information and semantic information and improve the accuracy of community segmentation.
- This study extends the optimization function of the multi-objective Deep Graph Infomax (DGI) [31] algorithm to control the similarity of the community structures explored from different data sources; therefore, the effect of noise can be reduced. In addition, we combine the structural features of heterogeneous OICs with the semantic features of user nodes to accurately construct user node embeddings in a single-layer network.
- This study compares our method with multiple baseline methods based on unsupervised and supervised graph embedding techniques using a real-world dataset collected from OICs developed for business intelligence and analytics tools and stakeholders. Further ablation experiments were conducted to evaluate the effectiveness of different parts of the proposed method.
2. Related Works
2.1. Open Innovation Communities
2.2. User Segmentation in OICs
3. Proposed Method
3.1. User Node Embedding
3.2. Representation Fusion
3.3. Parameter Optimization
3.4. User Clustering
- The influence of user nodes is determined using the user node fusion representation.
- The obtained influence of user nodes is ranked in descending order, and the k user nodes with the highest influence are selected as the initial clustering centroids of the k-means algorithm.
- The k-means algorithm is iteratively applied until a stable user segmentation emerges.
3.5. Algorithm Description
| Algorithm 1. User segmentation algorithm in heterogeneous OIC based on multilayer information and attention mechanisms. | |
| Input: | OIC multi-heterogeneous network GMH = (V, E, F), number of network layers |R|>1, number of user communities k |
| Output: | User segmentation result C = (C1, C2, …, CK) |
| (1) | For each multi-heterogeneous network in layer r ∈ R network |
| (2) | For each user node |
| (3) | Obtain the user node embedding representation of at layer r using Equation (4) |
| (4) | Obtain the layer weights of the user nodes using the layer-based semantic attention mechanism in Equation (5) |
| (5) | Normalize the layer weights of user nodes using Equation (6) |
| (6) | End for |
| (7) | End for |
| (8) | For each user node |
| (9) | Obtain the fused embedding representation of the user node using Equation (7) |
| (10) | Optimize the fused embedding representation of the user node using the objective function using Equation (9) |
| (11) | End for |
| (12) | Calculate the influence of user nodes and select the top k user nodes as the initial user community centers using Equation (10) |
| (13) | Use k-means algorithm for user segmentation |
4. Experimental Analyses
4.1. Datasets
4.2. Evaluation Indicators
4.3. Baseline Methods
- (A)
- Unsupervised algorithms
- DeepWalk [61]: This method uses the Random-Walk strategy to obtain the node sequence; then, the Skip-Gram algorithm is used to obtain the node representations; finally, the objective function is optimized according to the hierarchical Softmax.
- Node2Vec [62]. This method is a more general abstract representation of the DeepWalk algorithm, which mainly improves the former Random-Walk strategy to obtain neighborhood information and more complex node dependencies.
- MetaPath2Vec [28]: This meta path-based method for embedding heterogeneous networks aims to deal with the heterogeneity of nodes. The MetaPath2Vec algorithm degenerates to the DeepWalk algorithm when there is only one node type in the network.
- CommDGI [63]: This method is an unsupervised learning algorithm based on mutual information for dealing with homogeneous networks.
- (B)
- Supervised algorithms
- GCN [30]: This method is a semi-supervised algorithm applied to node classification in homogeneous networks, which uses a convolution operation to merge the feature representation of neighbors into the node feature representation.
- GAT [64]: In this method, the attention mechanism is applied to homogeneous networks that require a supervised setup, and the algorithm learns node embeddings based on the local structure of the nodes.
- HAN [18]: This method uses node-level attention and semantic-level attention to capture information about all meta-paths.
5. Performance Analysis and Evaluation
6. Limitations and Directions for Future Research
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Daradkeh, M. The Relationship Between Persuasion Cues and Idea Adoption in Virtual Crowdsourcing Communities: Evidence from a Business Analytics Community. Int. J. Knowl. Manag. 2022, 18, 1–34. [Google Scholar] [CrossRef]
- Chesbrough, H. Open Innovation the New Imperative for Creating and Profiting from Technology; Harvard Business School Press: Boston, MA, USA, 2003. [Google Scholar]
- Daradkeh, M. The Influence of Sentiment Orientation in Open Innovation Communities: Empirical Evidence from a Business Analytics Community. J. Inf. Knowl. Manag. 2021, 20, 2150029. [Google Scholar] [CrossRef]
- Ober, J. Open Innovation in the ICT Industry: Substantiation from Poland. J. Open Innov. Technol. Mark. Complex. 2022, 8, 158. [Google Scholar] [CrossRef]
- Huang, S.; Chen, J.; Wang, Y.; Ning, L.; Sutherland, D.; Zhou, Z.; Zhou, Y. External heterogeneity and its impact on open innovation performance. Technol. Anal. Strat. Manag. 2015, 27, 182–197. [Google Scholar] [CrossRef][Green Version]
- Chesbrough, H. Open Innovation Results: Going Beyond the Hype and Getting Down to Business; Oxford University Press: Oxford, UK, 2019. [Google Scholar]
- Marullo, C.; Minin, A.D.; Martelli, I.; Piccaluga, A. Solving the ‘heterogeneity puzzle’: A comparative look at SMEs growth determinants in open and closed innovation patterns. Int. J. Entrep. Innov. Manag. 2020, 24, 443–464. [Google Scholar] [CrossRef]
- Capasso, M.; Rybalka, M. Innovation Pattern Heterogeneity: Data-Driven Retrieval of Firms’ Approaches to Innovation. Businesses 2022, 2, 54–81. [Google Scholar] [CrossRef]
- Papa, A.; Mazzucchelli, A.; Ballestra, L.V.; Usai, A. The open innovation journey along heterogeneous modes of knowledge-intensive marketing collaborations: A cross-sectional study of innovative firms in Europe. Int. Mark. Rev. 2022, 39, 602–625. [Google Scholar] [CrossRef]
- Saebi, T.; Foss, N. Business models for open innovation: Matching heterogeneous open innovation strategies with business model dimensions. Eur. Manag. J. 2015, 33, 201–213. [Google Scholar] [CrossRef]
- Turoń, K. Open Innovation Business Model as an Opportunity to Enhance the Development of Sustainable Shared Mobility Industry. J. Open Innov. Technol. Mark. Complex. 2022, 8, 37. [Google Scholar] [CrossRef]
- Muninger, M.; Mahr, D.; Hammedi, W. Social media use: A review of innovation management practices. J. Bus. Res. 2022, 143, 140–156. [Google Scholar] [CrossRef]
- Fursov, K.; Linton, J. Social innovation: Integrating product and user innovation. Technol. Forecast. Soc. Chang. 2022, 174, 121224. [Google Scholar] [CrossRef]
- Bachmann, P.; Frutos-Bencze, D. R&D and innovation efforts during the COVID-19 pandemic: The role of universities. J. Innov. Knowl. 2022, 7, 100238. [Google Scholar]
- Urbinati, A.; Manelli, L.; Frattini, F.; Bogers, M. The digital transformation of the innovation process: Orchestration mechanisms and future research directions. Innovation 2022, 24, 65–85. [Google Scholar] [CrossRef]
- Xiong, B.; Lim, E.T.K.; Tan, C.-W.; Zhao, Z.; Yu, Y. Towards an evolutionary view of innovation diffusion in open innovation ecosystems. Ind. Manag. Data Syst. 2022, 122, 1757–1786. [Google Scholar] [CrossRef]
- Ferdinand, J.; Meyer, U. The social dynamics of heterogeneous innovation ecosystems:Effects of openness on community—Firm relations. Int. J. Eng. Bus. Manag. 2017, 9, 1847979017721617. [Google Scholar] [CrossRef]
- Chen, Y.; Hu, Y.; Li, K.; Yeo, C.L.; Li, K. Approximate personalized propagation for unsupervised embedding in heterogeneous graphs. Inf. Sci. 2022, 600, 287–300. [Google Scholar] [CrossRef]
- Brodny, J.; Tutak, M. Digitalization of Small and Medium-Sized Enterprises and Economic Growth: Evidence for the EU-27 Countries. J. Open Innov. Technol. Mark. Complex. 2022, 8, 67. [Google Scholar] [CrossRef]
- Ge, J.; Shi, L.; Liu, L.; Shi, H. Intelligent Link Prediction Management Based on Community Discovery and User Behavior Preference in Online Social Networks. Wirel. Commun. Mob. Comput. 2021, 2021, 3860083. [Google Scholar] [CrossRef]
- Jia, J.; Liu, P.; Du, X.; Zhang, Y. Multilayer Social Network Overlapping Community Detection Algorithm Based on Trust Relationship. Wirel. Commun. Mob. Comput. 2021, 2021, 9268039. [Google Scholar] [CrossRef]
- Lu, Q.; Chesbrough, H. Measuring open innovation practices through topic modelling: Revisiting their impact on firm financial performance. Technovation 2022, 114, 102434. [Google Scholar] [CrossRef]
- Tang, T.; Fisher, G.; Qualls, W. The effects of inbound open innovation, outbound open innovation, and team role diversity on open source software project performance. Ind. Mark. Manag. 2021, 94, 216–228. [Google Scholar] [CrossRef]
- Weiss-Lehman, C.P.; Werner, C.M.; Bowler, C.H.; Hallett, L.M.; Mayfield, M.M.; Godoy, O.; Aoyomana, L.; Barabás, G.; Chu, C.; Ladouceur, E.; et al. Disentangling key species interactions in diverse and heterogeneous communities: A Bayesian sparse modelling approach. Ecol. Lett. 2022, 25, 1263–1276. [Google Scholar] [CrossRef] [PubMed]
- Yuana, R.; Prasetio, E.A.; Syarief, R.; Arkeman, Y.; Suroso, A.I. System Dynamic and Simulation of Business Model Innovation in Digital Companies: An Open Innovation Approach. J. Open Innov. Technol. Mark. Complex. 2021, 7, 219. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24 August 2014; pp. 701–710. [Google Scholar]
- Dong, Y.; Chawla, N.; Swami, A. metapath2vec: Scalable Representation Learning for Heterogeneous Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Jiang, B.; Zhang, Z.; Lin, D.; Tang, J.; Luo, B. Semi-Supervised Learning with Graph Learning-Convolutional Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Weng, L.; Zhang, Q.; Lin, Z.; Wu, L. Harnessing heterogeneous social networks for better recommendations: A grey relational analysis approach. Expert Syst. Appl. 2021, 174, 114771. [Google Scholar] [CrossRef]
- Zhou, Z.; Hu, Y.; Zhang, Y.; Chen, J.; Cai, H. Multiview Deep Graph Infomax to Achieve Unsupervised Graph Embedding. In IEEE Transactions on Cybernetics; IEEE: Piscataway, NJ, USA, 2022; pp. 1–11. [Google Scholar]
- Zhu, X. Incorporation of sticky information and product diversification into static game of open innovation. Int. J. Innov. Stud. 2022, 6, 11–25. [Google Scholar] [CrossRef]
- Chesbrough, H.; Heaton, S.; Mei, L. Open innovation with Chinese characteristics: A dynamic capabilities perspective. R D Manag. 2021, 51, 247–259. [Google Scholar] [CrossRef]
- Robaeyst, B.; Baccarne, B.; Duthoo, W.; Schuurman, D. The City as an Experimental Environment: The Identification, Selection, and Activation of Distributed Knowledge in Regional Open Innovation Ecosystems. Sustainability 2021, 13, 6954. [Google Scholar] [CrossRef]
- Daradkeh, M. Innovation in Business Intelligence Systems: The Relationship Between Innovation Crowdsourcing Mechanisms and Innovation Performance. Int. J. Inf. Syst. Serv. Sec. 2022, 14, 1–25. [Google Scholar] [CrossRef]
- Abbate, T.; Codini, A.; Aquilani, B.; Vrontis, D. From Knowledge Ecosystems to Capabilities Ecosystems: When Open Innovation Digital Platforms Lead to Value Co-creation. J. Knowl. Econ. 2022, 13, 290–304. [Google Scholar] [CrossRef]
- Jokar, E.; Mosleh, M.; Kheyrandish, M. Discovering community structure in social networks based on the synergy of label propagation and simulated annealing. Multimed. Tools Appl. 2022, 81, 21449–21470. [Google Scholar] [CrossRef]
- Xu, X.; Hu, N.; Li, T.; Trovati, M.; Palmieri, F.; Kontonatsios, G.; Castiglione, A. Distributed temporal link prediction algorithm based on label propagation. Future Gener. Comput. Syst. 2019, 93, 627–636. [Google Scholar] [CrossRef]
- Bai, L.; Cheng, X.; Liang, J.; Guo, Y. Fast graph clustering with a new description model for community detection. Inf. Sci. 2017, 388–389, 37–47. [Google Scholar] [CrossRef]
- Hammoud, Z.; Kramer, F. Multilayer networks: Aspects, implementations, and application in biomedicine. Big Data Anal. 2020, 5, 2. [Google Scholar] [CrossRef]
- He, T.; Bai, L.; Ong, Y. Vicinal Vertex Allocation for Matrix Factorization in Networks. IEEE Trans. Cybern. 2022, 52, 8047–8060. [Google Scholar] [CrossRef]
- Gholami, M.; Sheikhahmadi, A.; Khamforoosh, K.; Jalili, M. Overlapping community detection in networks based on Neutrosophic theory. Phys. A Stat. Mech. Appl. 2022, 598, 127359. [Google Scholar] [CrossRef]
- Su, Z.; Lin, S.; Ai, J.; Li, H. Rating Prediction in Recommender Systems Based on User Behavior Probability and Complex Network Modeling. IEEE Access 2021, 9, 30739–30749. [Google Scholar] [CrossRef]
- Daneshvar, H.; Ravanmehr, R. A social hybrid recommendation system using LSTM and CNN. Concurr. Comput. Pract. Exp. 2022, 34, e7015. [Google Scholar] [CrossRef]
- Liu, H.; He, L.; Zhang, F.; Wang, Z.; Gao, C. Dynamic community detection over evolving networks based on the optimized deep graph infomax. Chaos Interdiscip. J. Nonlinear Sci. 2022, 32, 053119. [Google Scholar] [CrossRef]
- Ahmadian, S.; Joorabloo, N.; Jalili, M.; Ren, Y.; Meghdadi, M.; Afsharchi, M. A social recommender system based on reliable implicit relationships. Knowl. Based Syst. 2020, 192, 105371. [Google Scholar] [CrossRef]
- Huang, M.; Jiang, Q.; Qu, Q.; Chen, L.; Chen, H. Information fusion oriented heterogeneous social network for friend recommendation via community detection. Appl. Soft Comput. 2022, 114, 108103. [Google Scholar] [CrossRef]
- Awati, C.; Shirgave, S. The State of the Art Techniques in Recommendation Systems. In Applied Computational Technologies; Springer: Singapore, 2022. [Google Scholar]
- Schutera, M.; Rettenberger, L.; Pylatiuk, C.; Reischl, M. Methods for the frugal labeler: Multi-class semantic segmentation on heterogeneous labels. PLoS ONE 2022, 17, e0263656. [Google Scholar] [CrossRef]
- Jia, X.; Shang, J.; Liu, D.; Zhang, H.; Ni, W. HeDAN: Heterogeneous diffusion attention network for popularity prediction of online content. Knowl. Based Syst. 2022, 254, 109659. [Google Scholar] [CrossRef]
- Xu, X.; Chen, C.; Mendes, J. Quantifying dissimilarities between heterogeneous networks with community structure. Phys. A Stat. Mech. Appl. 2022, 588, 126574. [Google Scholar] [CrossRef]
- Han, Z.; Huang, Q.; Zhang, J.; Huang, C.; Wang, H.; Huang, X. GA-GWNN: Detecting anomalies of online learners by granular computing and graph wavelet convolutional neural network. Appl. Intell. 2022, 52, 13162–13183. [Google Scholar] [CrossRef]
- Wang, X.; Bo, D.; Shi, C.; Fan, S.; Ye, Y.; Yu, P.S. A Survey on Heterogeneous Graph Embedding: Methods, Techniques, Applications and Sources. arXiv 2022, arXiv:2011.14867. [Google Scholar] [CrossRef]
- Liu, X.; Tang, J. Network representation learning: A macro and micro view. AI Open 2021, 2, 43–64. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, C.; Chang, Y.; Hu, W.; Xing, X.; Zhou, Y.; Zheng, Z. SHNE: Semantics and Homophily Preserving Network Embedding. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: Piscataway, NJ, USA, 2021; pp. 1–12. [Google Scholar]
- Giraudo, M.; Sacerdote, L.; Sirovich, R. Non-Parametric Estimation of Mutual Information through the Entropy of the Linkage. Entropy 2013, 15, 5154–5177. [Google Scholar] [CrossRef]
- Chowdhury, K.; Chaudhuri, D.; Pal, A. An entropy-based initialization method of K-means clustering on the optimal number of clusters. Neural Comput. Appl. 2021, 33, 6965–6982. [Google Scholar] [CrossRef]
- Daradkeh, M. Exploring the Usefulness of User-Generated Content for Business Intelligence in Innovation: Empirical Evidence from an Online Open Innovation Community. Int. J. Enterp. Inf. Syst. 2021, 17, 44–70. [Google Scholar] [CrossRef]
- Hu, J.; Wang, Z.; Chen, J.; Dai, Y. A community partitioning algorithm based on network enhancement. Connect. Sci. 2021, 33, 42–61. [Google Scholar] [CrossRef]
- Qin, J.; Zeng, X.; Wu, S.; Zou, Y. Feature recommendation strategy for graph convolutional network. Connect. Sci. 2022, 34, 1697–1718. [Google Scholar] [CrossRef]
- Berahmand, K.; Nasiri, E.; Rostami, M.; Forouzandeh, S. A modified DeepWalk method for link prediction in attributed social network. Computing 2021, 103, 2227–2249. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Zhang, T.; Xiong, Y.; Zhang, J.; Zhang, Y.; Jiao, Y.; Zhu, Y. CommDGI: Community Detection Oriented Deep Graph Infomax. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 1843–1852. [Google Scholar]
- Li, L.; Jin, L.; Zhang, Z.; Liu, Q.; Sun, X.; Wang, H. Graph Convolution Over Multiple Latent Context-Aware Graph Structures for Event Detection. IEEE Access 2020, 8, 171435–171446. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Node Type | No. of Nodes | Edge Type | Network Layer Corresponding to Edge Type | No. of Edges |
|---|---|---|---|---|---|
| Power BI | User | 2460 | User viewing ideas | UVI | 84,853 |
| Ideas | 33,660 | User contributing ideas | UCI | 64,843 | |
| Tableau | User | 8556 | User viewing ideas | UVI | 49,439 |
| Ideas | 81,633 | User contributing ideas | UCI | 22,751 | |
| Qlik | User | 1129 | User contributing ideas | UVI | 69,108 |
| Ideas | 29,034 | User contributing ideas | UCI | 33,853 | |
| RapidMiner | User | 3908 | User viewing ideas | UVI | 59,482 |
| Ideas | 30,502 | User contributing ideas | UCI | 32,761 |
| Dataset | Power BI | Tableau | Qlik | RapidMiner | ||||
|---|---|---|---|---|---|---|---|---|
| Indicators | NMI | Sim@5 | NMI | Sim@5 | NMI | Sim@5 | NMI | Sim@5 |
| DeepWalk | 0.082 | 0.725 | 0.116 | 0.491 | 0.347 | 0.627 | 0.312 | 0.702 |
| Node2Vec | 0.073 | 0.737 | 0.122 | 0.486 | 0.381 | 0.626 | 0.308 | 0.711 |
| MetaPath2Vec | 0.085 | 0.746 | 0.128 | 0.491 | 0.386 | 0.633 | 0.316 | 0.713 |
| CommDGI | 0.006 | 0.556 | 0.182 | 0.577 | 0.552 | 0.784 | 0.642 | 0.887 |
| GCN | 0.286 | 0.623 | 0.175 | 0.564 | 0.464 | 0.722 | 0.672 | 0.865 |
| GAT | 0.302 | 0.631 | 0.182 | 0.551 | 0.467 | 0.724 | 0.665 | 0.871 |
| HAN | 0.028 | 0.493 | 0.162 | 0.562 | 0.471 | 0.776 | 0.655 | 0.871 |
| Our Method-Average Pooling | 0.342 | 0.743 | 0.187 | 0.602 | 0.556 | 0.774 | 0.683 | 0.874 |
| Our Method | 0.345 | 0.754 | 0.195 | 0.606 | 0.564 | 0.788 | 0.692 | 0.899 |
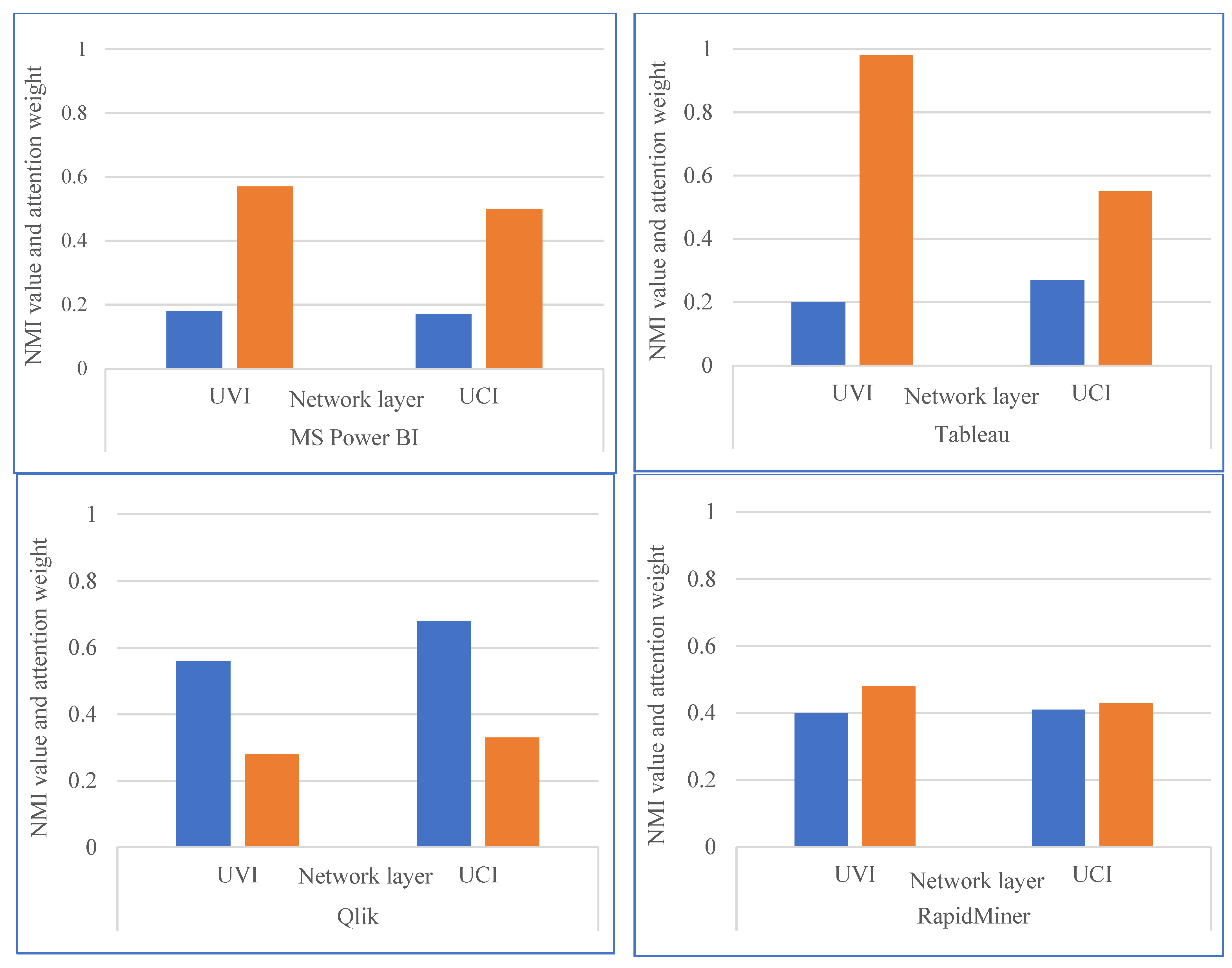
| Dataset | Power BI | |||
|---|---|---|---|---|
| Network Layer | UVI | UCI | ||
| Indicators | NMI | Sim@5 | NMI | Sim@5 |
| E | 0.002 | 0.395 | 0.003 | 0.414 |
| E + R | 0.002 | 0.399 | 0.003 | 0.426 |
| E + I | 0.152 | 0.512 | 0.143 | 0.512 |
| E + I + J | 0.163 | 0.566 | 0.153 | 0.593 |
| Dataset | Tableau | |||
| Network Layer | UVI | UCI | ||
| Indicators | NMI | Sim@5 | NMI | Sim@5 |
| E | 0.547 | 0.801 | 0.087 | 0.493 |
| E + R | 0.551 | 0.804 | 0.077 | 0.491 |
| E + I | 0.512 | 0.802 | 0.144 | 0.524 |
| E + I + J | 0.592 | 0.806 | 0.142 | 0.528 |
| Dataset | Qlik | |||
| Network Layer | UVI | UCI | ||
| Indicators | NMI | Sim@5 | NMI | Sim@5 |
| E | 0.526 | 0.626 | 0.651 | 0.812 |
| E + R | 0.525 | 0.659 | 0.659 | 0.833 |
| E + I | 0.527 | 0.728 | 0.655 | 0.872 |
| E + I + J | 0.527 | 0.708 | 0.656 | 0.874 |
| Dataset | RapidMiner | |||
| Network Layer | UVI | UCI | ||
| Indicators | NMI | Sim@5 | NMI | Sim@5 |
| E | 0.403 | 0.730 | 0.053 | 0.543 |
| E + R | 0.422 | 0.711 | 0.052 | 0.558 |
| E + I | 0.403 | 0.711 | 0.052 | 0.559 |
| E + I + J | 0.407 | 0.732 | 0.056 | 0.571 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daradkeh, M. A User Segmentation Method in Heterogeneous Open Innovation Communities Based on Multilayer Information Fusion and Attention Mechanisms. J. Open Innov. Technol. Mark. Complex. 2022, 8, 186. https://doi.org/10.3390/joitmc8040186
Daradkeh M. A User Segmentation Method in Heterogeneous Open Innovation Communities Based on Multilayer Information Fusion and Attention Mechanisms. Journal of Open Innovation: Technology, Market, and Complexity. 2022; 8(4):186. https://doi.org/10.3390/joitmc8040186
Chicago/Turabian StyleDaradkeh, Mohammad. 2022. "A User Segmentation Method in Heterogeneous Open Innovation Communities Based on Multilayer Information Fusion and Attention Mechanisms" Journal of Open Innovation: Technology, Market, and Complexity 8, no. 4: 186. https://doi.org/10.3390/joitmc8040186
APA StyleDaradkeh, M. (2022). A User Segmentation Method in Heterogeneous Open Innovation Communities Based on Multilayer Information Fusion and Attention Mechanisms. Journal of Open Innovation: Technology, Market, and Complexity, 8(4), 186. https://doi.org/10.3390/joitmc8040186