


Lane Line Detection and Object Scene Segmentation Using Otsu Thresholding and the Fast Hough Transform for Intelligent Vehicles in Complex Road Conditions


 ,
,  , , ,
, , ,  ,
,  and
and
Abstract
1. Introduction
2. Methodology
2.1. Image Editing before Uploading
2.2. Grayscale Image
2.3. Noise Reduction
2.4. Sobel Edge Detection Operator (SEDO)
2.5. Non-Local Maximum Suppression (NLMS)
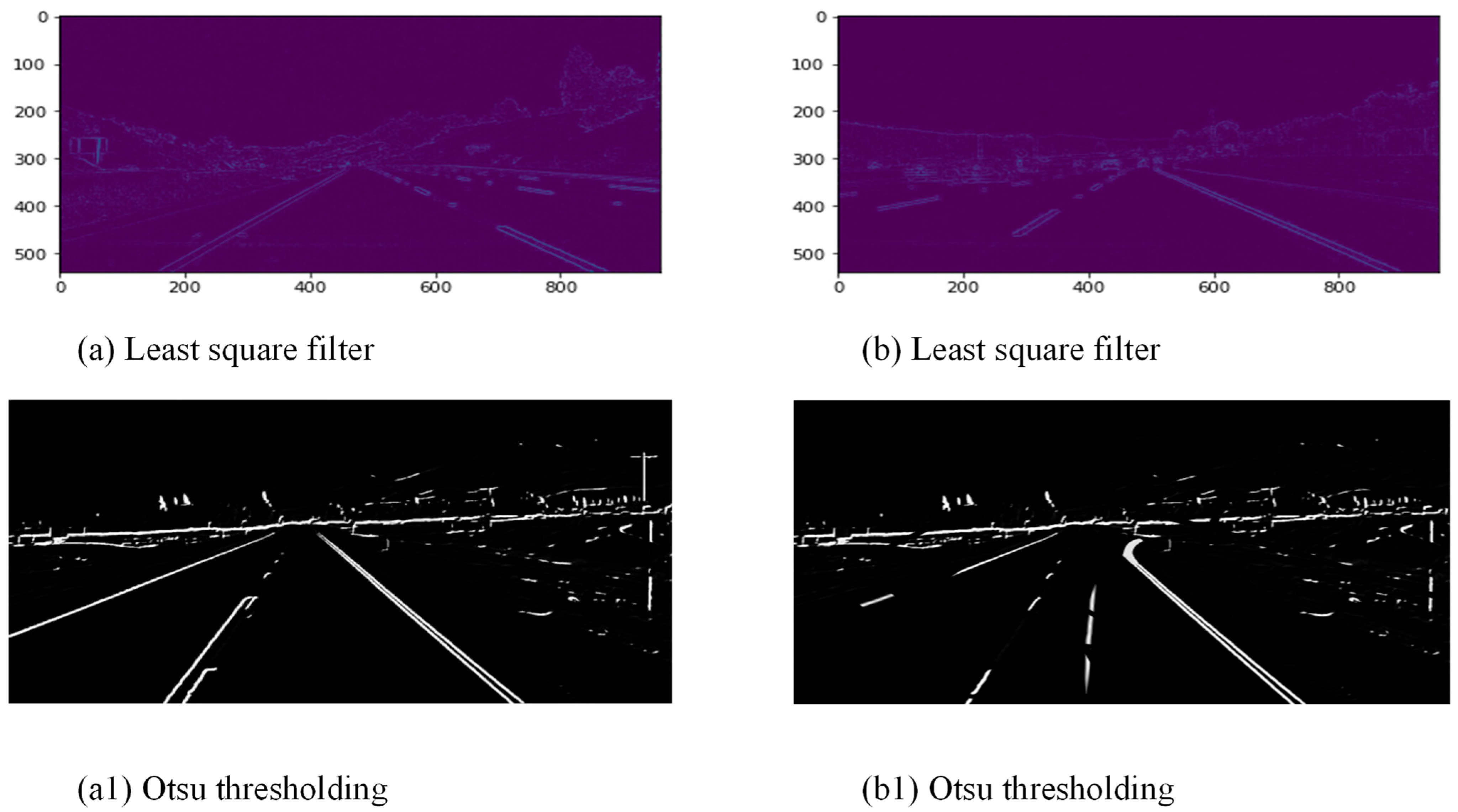
2.6. Otsu Thresholding
2.7. Canny Edge Detection
2.8. Region of Interest (ROI) Selection
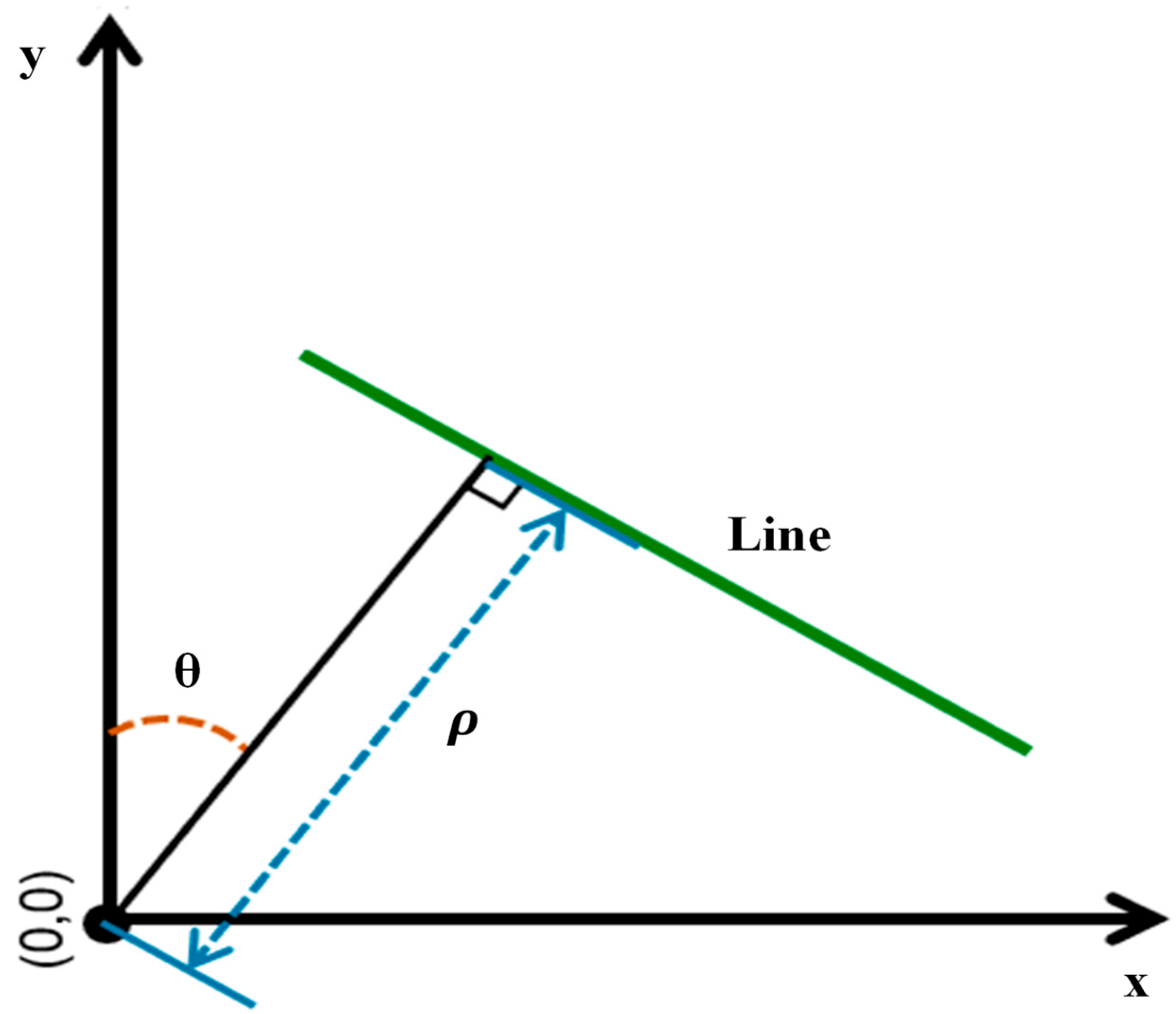
2.9. Fast Hough Transform (FHT)
2.10. The Algorithm
- Decide on the range of and . Often, the range of is [0, 180] degrees and the range of is [−d, d], where d is the length of the edge image’s diagonal. It is important to quantize the range of and so that there should be a finite number of possible values.
- Create a 2D array called the accumulator representing the Hough space with dimension (num_rhos, num_thetas) and initialize all its values to zero.
- Perform edge detection on the original image. This can be done with any edge detection algorithm of your choice.
- For every pixel on the edge image, check whether the pixel is an edge pixel. If it is an edge pixel, loop through all possible values of , calculate the corresponding , find the and ρ index in the accumulator, and increment the accumulator based on those index pairs.
- Loop through all the values in the accumulator. If the value is larger than a certain threshold, obtain the and index, as well as the value of and from the index pair, which can then be converted back to the form of .
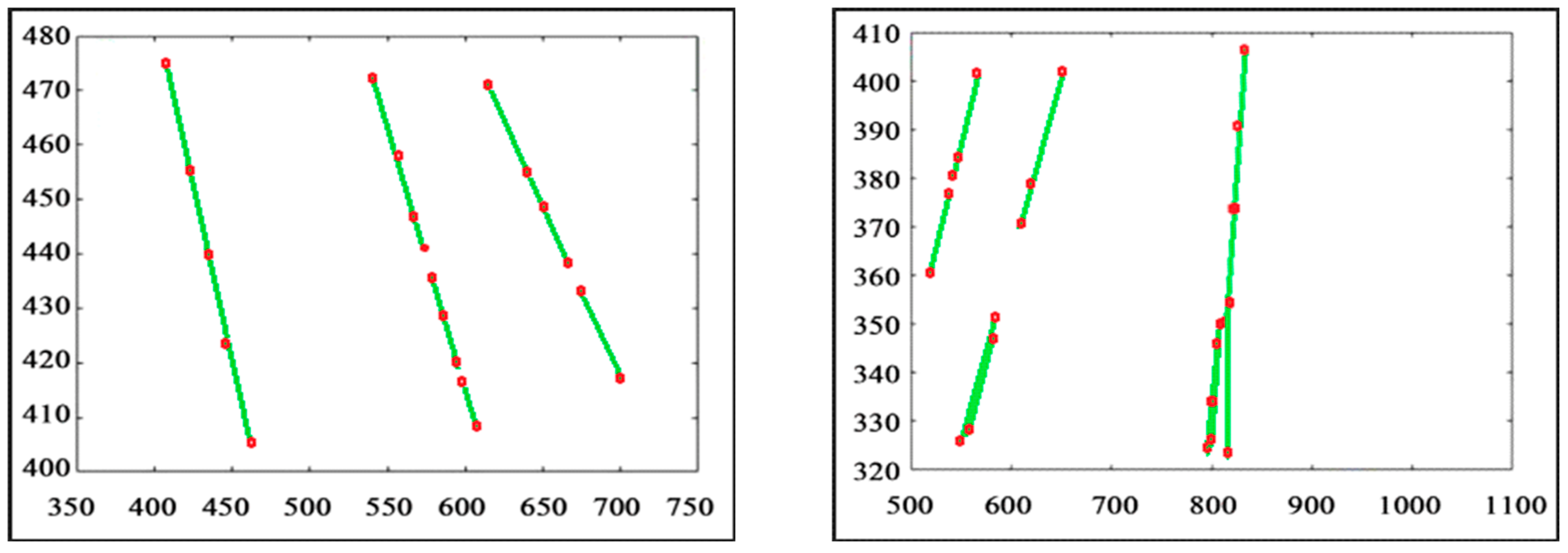
3. Experimental Results
4. Advantages, Limitations, and Real-Time Application Usage
4.1. Advantages
- Automatic threshold selection: The proposed method used Otsu’s method for thresholding, which is an automated method for selecting a threshold value that separates the foreground from the background. This can be useful in cases where the lighting conditions are variable, allowing the algorithm to adapt to the current lighting conditions.
- Robust line detection: The proposed method used the Hough transform, which is a powerful tool for detecting lines in images. This can allow the algorithm to accurately see lane lines, even in cases where the lines are somewhat curved or partially occluded.
- Fast processing: the implementation of the Hough transform is rapid, which is essential for real-time lane detection in a vehicle.
- Robust in complex road conditions: The method is powerful in challenging road conditions, such as when there are shadows or when the road is curved. This can allow the algorithm to perform well in various environments.
4.2. Limitations
- The proposed method may be sensitive to the parameters used for thresholding and line detection, which may need to be tuned for different conditions.
- Further testing and evaluation are necessary to assess the performance and robustness of the proposed method thoroughly.
- The proposed method may not perform well in lane lines that are faint or difficult to distinguish from the road surface.
4.3. Real-Time Application Usage
- Increased safety: lane line detection can help to keep a vehicle within its lane, improving safety in complex road conditions.
- Enhanced driver assistance: by detecting lane lines, a vehicle can provide additional service to the driver, such as lane departure warnings or assisting with staying in lane.
- Improved navigation: lane line detection can help a vehicle to accurately determine its position on the road, improving navigation accuracy.
- Enhanced autonomous driving capabilities: lane line detection is an essential component of autonomous vehicle systems, as it allows the vehicle to identify its surroundings and make driving decisions.
- Reduced driver fatigue: assisting the driver with staying in lane and lane line detection tasks can help to reduce driver fatigue.
- Increased fuel efficiency: by helping the vehicle maintain a consistent speed and position within the lane, lane line detection can improve fuel efficiency.
- Improved traffic flow: lane line detection can help vehicles to maintain a consistent speed and position within their lanes, improving traffic flow.
- Enhanced intersection safety: lane line detection can help a vehicle to accurately determine its position at an intersection, improving safety.
- Improved weather performance: lane lines may be harder to see in adverse weather conditions, but lane line detection can still help a vehicle stay within its lane.
- Enhanced road maintenance: lane line detection can help a vehicle to accurately determine its position on the road, aiding in the care of roads by providing data on vehicle usage patterns.
5. Conclusions
6. Future Scope
- Improving the robustness and accuracy of lane line detection algorithms under various lighting and weather conditions, such as rain, snow, and fog.
- Developing methods for detecting and tracking lane lines in the presence of other visual distractions, such as pedestrians, vehicles, and road signs.
- Investigating machine learning techniques, such as deep learning, to improve the performance of lane line detection algorithms.
- Developing approaches for integrating lane line detection with other perception tasks, such as object detection and classification, to enable more comprehensive identification of the environment.
- Exploring the use of multiple sensors, such as cameras, lidar, and radar, to improve the accuracy and reliability of lane line detection in complex road conditions.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hou, H.; Guo, P.; Zheng, B.; Wang, J. An Effective Method for Lane Detection in Complex Situations. In Proceedings of the 2021 9th International Symposium on Next Generation Electronics (I.S.N.E.), Changsha, China, 9–11 July 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Zhang, Z.; Ma, X. Lane recognition algorithm using the hough transform based on complicated conditions. J. Comput. Commun. 2019, 7, 65. [Google Scholar] [CrossRef]
- Qiu, D.; Weng, M.; Yang, H.; Yu, W.; Liu, K. Research on Lane Line Detection Method Based on Improved Hough Transform. In Proceedings of the 2019 Chinese Control And Decision Conference (C.C.D.C.), Nanchang, China, 3–5 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Gu, K.X.; Li, Z.Q.; Wang, J.J.; Zhou, Y.; Zhang, H.; Zhao, B.; Ji, W. The Effect of Cryogenic Treatment on the Microstructure and Properties of Ti-6Al-4V Titanium Alloy. In Materials Science Forum; Trans Tech Publications Ltd.: Wollerau, Switzerland, 2013. [Google Scholar]
- Li, X.; Yin, P.; Zhi, Y.; Duan, C. Vertical Lane Line Detection Technology Based on Hough Transform. IOP Conf. Ser. Earth Environ. Sci. 2020, 440, 032126. [Google Scholar] [CrossRef]
- Wu, P.-C.; Chang, C.-Y.; Lin, C.H. Lane-mark extraction for automobiles under complex conditions. Pattern Recognit. 2014, 47, 2756–2767. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, D.; Teoh, E.K. Lane detection using spline model. Pattern Recognit. Lett. 2000, 21, 677–689. [Google Scholar] [CrossRef]
- Savant, K.V.; Meghana, G.; Potnuru, G.; Bhavana, V. Lane Detection for Autonomous Cars Using Neural Networks. In Machine Learning and Autonomous Systems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 193–207. [Google Scholar]
- Borkar, A.; Hayes, M.; Smith, M.T. Robust Lane Detection and Tracking with Ransac and Kalman Filter. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (I.C.I.P.), Cairo, Egypt, 7–10 November 2009; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Lee, J.W.; Yi, U.K. A lane-departure identification based on L.B.P.E., Hough transform, and linear regression. Comput. Vis. Image Underst. 2005, 99, 359–383. [Google Scholar] [CrossRef]
- Gabrielli, A.; Alfonsi, F.; del Corso, F.J.E. Simulated Hough Transform Model Optimized for Straight-Line Recognition Using Frontier FPGA Devices. Electronics 2022, 11, 517. [Google Scholar] [CrossRef]
- Zhao, Y.; Wen, C.; Xue, Z.; Gao, Y. 3D Room Layout Estimation from a Cubemap of Panorama Image via Deep Manhattan Hough Transform. In European Conference on Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Xu, H.; Li, H. Study on a Robust Approach of Lane Departure Warning Algorithm. In Proceedings of the IEEE International Conference on Signal Processing System (I.C.S.P.S.), Dalian, China, 5–7 July 2010; pp. 201–204. [Google Scholar]
- Zhao, K.; Meuter, M.; Nunn, C.; Muller, D.; Schneiders, S.M.; Pauli, J. A Novel Multi-Lane Detection and Tracking System. In Proceedings of the IEEE Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 1084–1089. [Google Scholar]
- Obradović, Ð.; Konjović, Z.; Pap, E.; Rudas, I.J. Linear fuzzy space based road lane model and detection. Knowl.-Based Syst. 2013, 38, 37–47. [Google Scholar] [CrossRef]
- An, X.; Shang, E.; Song, J.; Li, J.; He, H. Real-time lane departure warning system based on a single fpga. EURASIP J. Image Video Process. 2013, 38, 38. [Google Scholar] [CrossRef]
- Cheng, H.Y.; Jeng, B.S.; Tseng, P.T.; Fan, K.C. Lane detection with moving vehicles in the traffic scenes. IEEE Trans. Intell. Transp. Syst. 2006, 7, 571–582. [Google Scholar] [CrossRef]
- Son, J.; Yoo, H.; Kim, S.; Sohn, K. Realtime illumination invariant lane detection for lane departure warning system. Expert Syst. Appl. 2015, 42, 1816–1824. [Google Scholar] [CrossRef]
- Mammeri, A.; Boukerche, A.; Tang, Z. A real-time lane marking localization, tracking and communication system. Comput. Commun. 2016, 73, 132–143. [Google Scholar] [CrossRef]
- Aziz, S.; Wang, H.; Liu, Y.; Peng, J.; Jiang, H. Variable universe fuzzy logic-based hybrid LFC control with real-time implementation. IEEE Access 2019, 7, 25535–25546. [Google Scholar] [CrossRef]
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. El-Gan: Embedding Loss Driven Generative Adversarial Networks for Lane Detection. In Proceedings of the European Conference on Computer Vision (E.C.C.V.), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Gurghian, A.; Koduri, T.; Bailur, S.V.; Carey, K.J.; Murali, V.N. Deeplanes: End-to-End Lane Position Estimation using Deep Neural Networksa. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 38–45. [Google Scholar]
- Chougule, S.; Koznek, N.; Ismail, A.; Adam, G.; Narayan, V.; Schulze, M. Reliable Multilane Detection and Classification by Utilizing CNN as a Regression Network. In Proceedings of the European Conference on Computer Vision (E.C.C.V.), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, Z.; Ren, W.; Qiu, Q. Lanenet: Real-time lane detection networks for autonomous driving. arXiv 2018, arXiv:1807.01726. [Google Scholar]
- Van Gansbeke, W.; De Brabandere, B.; Neven, D.; Proesmans, M.; Van Gool, L. End-to-End Lane Detection Through Differentiable Least-Squares fitting. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Khan, M.A.M.; Haque, M.F.; Hasan, K.R.; Alajmani, S.H.; Baz, M.; Masud, M.; Nahid, A.A. LLDNet: A Lightweight Lane Detection Approach for Autonomous Cars Using Deep Learning. Sensors 2022, 22, 5595. [Google Scholar] [CrossRef] [PubMed]
- Lin, Q.; Han, Y.; Hahn, H. Real-Time Lane Departure Detection Based on Extended Edge-Linking Algorithm. In Proceedings of the 2010 Second International Conference on Computer Research and Development, Kuala Lumpur, Malaysia, 7–10 May 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Aziz, S.; Peng, J.; Wang, H.; Jiang, H. Admm-based distributed optimization of hybrid mtdc-ac grid for determining smooth operation point. IEEE Access 2019, 7, 74238–74247. [Google Scholar] [CrossRef]
- Ding, F.; Wang, A.; Zhang, Q. Lane Line Identification and Research Based on Markov Random Field. World Electr. Veh. J. 2022, 13, 106. [Google Scholar] [CrossRef]
- Zhang, J.-Y.; Yan, C.; Huang, X.-X. Edge detection of images based on improved Sobel operator and genetic algorithms. In Proceedings of the 2009 International Conference on Image Analysis and Signal Processing, Linhai, China, 11–12 April 2009; pp. 31–35. [Google Scholar]
- Available online: https://github.com/SunnyKing342/Lane-line-detection-Hough-Transform.git (accessed on 24 December 2022).
- Aggarwal, N.; Karl, W.C. Line Detection in Images Through Regularized Hough Transform. IEEE Trans. Image Process. 2006, 15, 582–591. [Google Scholar] [CrossRef] [PubMed]
- Marzougui, M.; Alasiry, A.; Kortli, Y.; Baili, J. A lane tracking method based on progressive probabilistic Hough transform. IEEE Access 2020, 8, 84893–84905. [Google Scholar] [CrossRef]
- Ali, M.; Clausi, D. Using the Canny Edge Detector for Feature Extraction and Enhancement of Remote Sensing Images. In Proceedings of the I.G.A.R.S.S. 2001 Scanning the Present and Resolving the Future Proceedings IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No. 01CH37217), Sydney, NSW, Australia, 9–13 July 2001; IEEE: Piscataway, NJ, USA, 2001. [Google Scholar]
- Traoré, C.A.D.G.; Séré, A. Straight-Line Detection with the Hough Transform Method Based on a Rectangular Grid. In Proceedings of the Information and Communication Technology for Competitive Strategies (I.C.T.C.S. 2020), Jaipur, India, 11–12 December 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 599–610. [Google Scholar]
- Cao, J.; Song, C.; Xiao, F.; Peng, S. Lane detection algorithm for intelligent vehicles in complex road conditions and dynamic environments. Sensors 2019, 19, 3166. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Methods | Advantages | Limitations |
|---|---|---|---|
| Xu and Li (2010) [13] | a: Straight-line model, median filtering, and histogram-based contrast enhancement. b: Sobel edge operator. c: Kalman filter and the Hough transform. | A failure judgment module is added to improve the algorithm’s accuracy. | It is challenging to detect lanes in unstructured road conditions. In situations with shadows and water, lane detection fails. |
| Zhao et al. (2012) [14] | a: Model based on the spline. b: Kalman extension filter. | Spline model is straightforward, flexible, and robust. The first-time mix of spline-based path model and broadened Kalman filter for path-following. | Light impedance around evening time might degrade the presentation. |
| Obradovic et al. (2013) [15] | a: Set of fluffy places and smooth lines for street path detection. b: Modified edge ex-footing. c: Modified fluffy c-means grouping calculation (FLDetector). | Tried on PC-based stages and cell phones. Execution is autonomous of the accuracy of extraction of component focuses. | Execution time relies upon the places of fluffy focuses on a picture and the quantity of recognized smooth lines. Not appropriate for applications requiring countless element focuses, where Hough |
| Shang et al. (2013) [16] | a: Progression of 2D FIR filter + Gaussian noise decrease. b: Evaporating point-based steerable filter. c: Evaporating point-based Hough change. d: Kalman filters + takeoff cautioning unit executed on MicroBlaze Programming. | Fewer capacity prerequisites. Upgrade location ability. | In forcefully bent streets, variety in the place of the vanishing point seriously influences the path discovery results as follows: (1) Casting a ballot of pixels in lines does not collect at similar peaks; instead, it brings about a progression of discrete peaks. (2) The real vanishing point is not reasonable for the coordinate beginning. |
| Wu et al. (2014) [17] | a: Direct explanatory model. b: Canny edge locator + misleading edge end in light of slope direction and width of path mark + edge compensation. c: Local versatile thresholding + path marking verification given distance rules and following using a Kalman filter. | Distinguish path marks in complex situations such as shadow impact, night situations (streetlights, front light, and taillight of vehicle), and bent path markers. | Difficult to extricate path marks from the picture sequence that are genuinely debased by thick haze and the recorder runs at a shallow illuminance level. Working continuously would be required for the proposed strategy regarding discovery rate and execution time. |
| Sohn et al. (2015) [18] | a: Vanishing point-based versatile ROI selection + invariance properties of path tone. b: Canny edge identification. c: Path bunching and lane fitting have given the most un-square strategy. d: Path offset and path mark heading point. | Handles various illumination conditions due to weather changes (rain, fog, etc.), streetlamps, and headlights of vehicles. Vanishing-point-based adaptive ROI selection reduces computational complexity. | Difficult-to-identify path checking in the accompanying areas of strength for circumstances reflection, path break, and obscure path marks. |
| Mammeri et al. (2016) [19] | a: MSER (maximally stable external region) masses utilized for return for ROI and feature extraction. b: Moderate probabilistic Hough transform. c: Kalman filter. | HSV variety space is utilized to recognize path tones (for example, white/yellow). | Traffic thickness and lighting frameworks on the street might affect path discovery execution around evening time. |
| Zhu et al. (2017) [20] | Principal advances in intelligent vehicles regarding path and street locations. | A straight line is an essential and robust model for short-range streets or highways. Splines are great models for bent roads. | To work on the presentation of the framework, combination-based strategies are required, which are complex. |
| Mohsen Ghafoorian et al. (2018) [21] | Division—CGAN organization. Classification—join earlier position and classification result to gauge path position. | The implanting misfortune in the discriminator can control the result limit nearer to the label. | An enormous number of parameters are required. |
| Gurghian et al. (2016) [22] | Classification—consolidate earlier position and classification result to gauge path position. | 1: Quick location. 2: Basic organization structure. | 1: Restricted application situations. 2: Fixed camera parameters. |
| Shriyash Chougule et al. (2018) [23] | Regression—a: Multi-branch. b: Coordinate relapse. c: Information augmentation. | 1: This strategy does not need a clustering step. 2: Lightweight networks. | Fixed number of path lines can be distinguished. |
| Wang Ze et al. (2018) [24] | Regression—a: Edge proposition. b: Parameters relapse. | 1: The LSTM fills in as a solution for an unsure number. 2: Need not bother with any post-handling. | The ordinate of the three focuses to be identified is predefined. |
| Van Gansbeke et al. (2019) [25] | Segmentation—a: Producing coordinate weight map. b: A differentiable least-squares fitting module. | This is a more general procedure with no predefined condition. | Fixed number of path lines can be identified. 2: While adding the number of weight maps, the exhibition will be debased. |
| Catgory | Algorithms | ρ = rho | Gaussian Blur | Mini Length | Max Length | Threshold | Accuracy Rate/% | Average Processing Time (ms) |
|---|---|---|---|---|---|---|---|---|
| No line | Fast Hough Transform | 4 | 5 × 5 | 20 | 15 | 160 | 89.5% | 19.7 |
| Crowded | Fast Hough Transform | 5 | 7 × 7 | 20 | 15 | 160 | 90.3% | 19.9 |
| Shadow | Fast Hough Transform | 5 | 9 × 9 | 20 | 15 | 140 | 92.4% | 20.5 |
| Curve | Fast Hough Transform | 5 | 9 × 9 | 20 | 15 | 160 | 93.5% | 20.9 |
| Crossroad | Fast Hough Transform | 6 | 9 × 9 | 20 | 15 | 160 | 94.2% | 21.4 |
| Normal | Fast Hough Transform | 6 | 9 × 9 | 20 | 25 | 160 | 96.7% | 22.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Javeed, M.A.; Ghaffar, M.A.; Ashraf, M.A.; Zubair, N.; Metwally, A.S.M.; Tag-Eldin, E.M.; Bocchetta, P.; Javed, M.S.; Jiang, X. Lane Line Detection and Object Scene Segmentation Using Otsu Thresholding and the Fast Hough Transform for Intelligent Vehicles in Complex Road Conditions. Electronics 2023, 12, 1079. https://doi.org/10.3390/electronics12051079
Javeed MA, Ghaffar MA, Ashraf MA, Zubair N, Metwally ASM, Tag-Eldin EM, Bocchetta P, Javed MS, Jiang X. Lane Line Detection and Object Scene Segmentation Using Otsu Thresholding and the Fast Hough Transform for Intelligent Vehicles in Complex Road Conditions. Electronics. 2023; 12(5):1079. https://doi.org/10.3390/electronics12051079
Chicago/Turabian StyleJaveed, Muhammad Awais, Muhammad Arslan Ghaffar, Muhammad Awais Ashraf, Nimra Zubair, Ahmed Sayed M. Metwally, Elsayed M. Tag-Eldin, Patrizia Bocchetta, Muhammad Sufyan Javed, and Xingfang Jiang. 2023. "Lane Line Detection and Object Scene Segmentation Using Otsu Thresholding and the Fast Hough Transform for Intelligent Vehicles in Complex Road Conditions" Electronics 12, no. 5: 1079. https://doi.org/10.3390/electronics12051079
APA StyleJaveed, M. A., Ghaffar, M. A., Ashraf, M. A., Zubair, N., Metwally, A. S. M., Tag-Eldin, E. M., Bocchetta, P., Javed, M. S., & Jiang, X. (2023). Lane Line Detection and Object Scene Segmentation Using Otsu Thresholding and the Fast Hough Transform for Intelligent Vehicles in Complex Road Conditions. Electronics, 12(5), 1079. https://doi.org/10.3390/electronics12051079