Abstract
In recent years, the escalating environmental challenges have contributed to a rising incidence of cancer. The precise anticipation of cancer incidence and mortality rates has emerged as a pivotal focus in scientific inquiry, exerting a profound impact on the formulation of public health policies. This investigation adopts a pioneering machine learning framework to address this critical issue, utilizing a dataset encompassing 72,591 comprehensive records that include essential variables such as age, case count, population size, race, gender, site, and year of diagnosis. Diverse machine learning algorithms, including decision trees, random forests, logistic regression, support vector machines, and neural networks, were employed in this study. The ensuing analysis revealed testing accuracies of 62.17%, 61.92%, 54.53%, 55.72%, and 62.30% for the respective models. This state-of-the-art model not only enhances our understanding of cancer dynamics but also equips researchers and policymakers with the capability of making meticulous projections concerning forthcoming cancer incidence and mortality rates. Considering sustainability, the application of this advanced machine learning framework emphasizes the importance of judiciously utilizing extensive and intricate databases. By doing so, it facilitates a more sustainable approach to healthcare planning, allowing for informed decision-making that takes into account the long-term ecological and societal impacts of cancer-related policies. This integrative perspective underscores the broader commitment to sustainable practices in both health research and public policy formulation.
1. Introduction
Cancer poses a formidable threat to global health and well-being [1], with a staggering estimated 18.1 million new cases and 9.6 million cancer-related deaths occurring worldwide annually [2,3]. Gender disparities are evident, with higher cancer incidence and mortality rates among males compared to females. Approximately 20% of males and 17% of females will experience cancer during their lifetime, while 13% of males and 9% of females will succumb to the disease [2,3]. Accurately predicting cancer incidence and mortality rates is a crucial pursuit in cancer research. Numerous factors, including demographic, lifestyle, environmental, and genetic elements, influence incidence rates. Moreover, healthcare accessibility and quality significantly impact mortality rates [4]. Precise predictions in these areas are vital, empowering policymakers and healthcare providers to design targeted and effective strategies and interventions, thereby combating cancer’s devastating impact on individuals and communities [5].
Traditionally, cancer prediction relied on mathematical calculations [6,7]. This process involved data collection, followed by the development of formulas connecting cancer occurrence with factors like family history, age, height, BMI, and age at first childbirth. Subsequently, these formulas were utilized for cancer prediction, and their accuracy was assessed [6]. However, such predictions heavily depended on the accuracy of the formula, which, in turn, relied on researchers’ assumptions and expertise, potentially introducing biases. To address these concerns and minimize the risk of erroneous assumptions, a novel approach has emerged—machine learning (ML). ML models establish direct connections between input data and cancer prediction outputs, bypassing the need for explicit formulas. The accuracy of ML predictions hinges on the quality and quantity of data, making it a promising technique for anticipating cancer incidence and mortality rates (Table 1).

Table 1.
Comparison between traditional cancer and new ML models on cancer prediction.
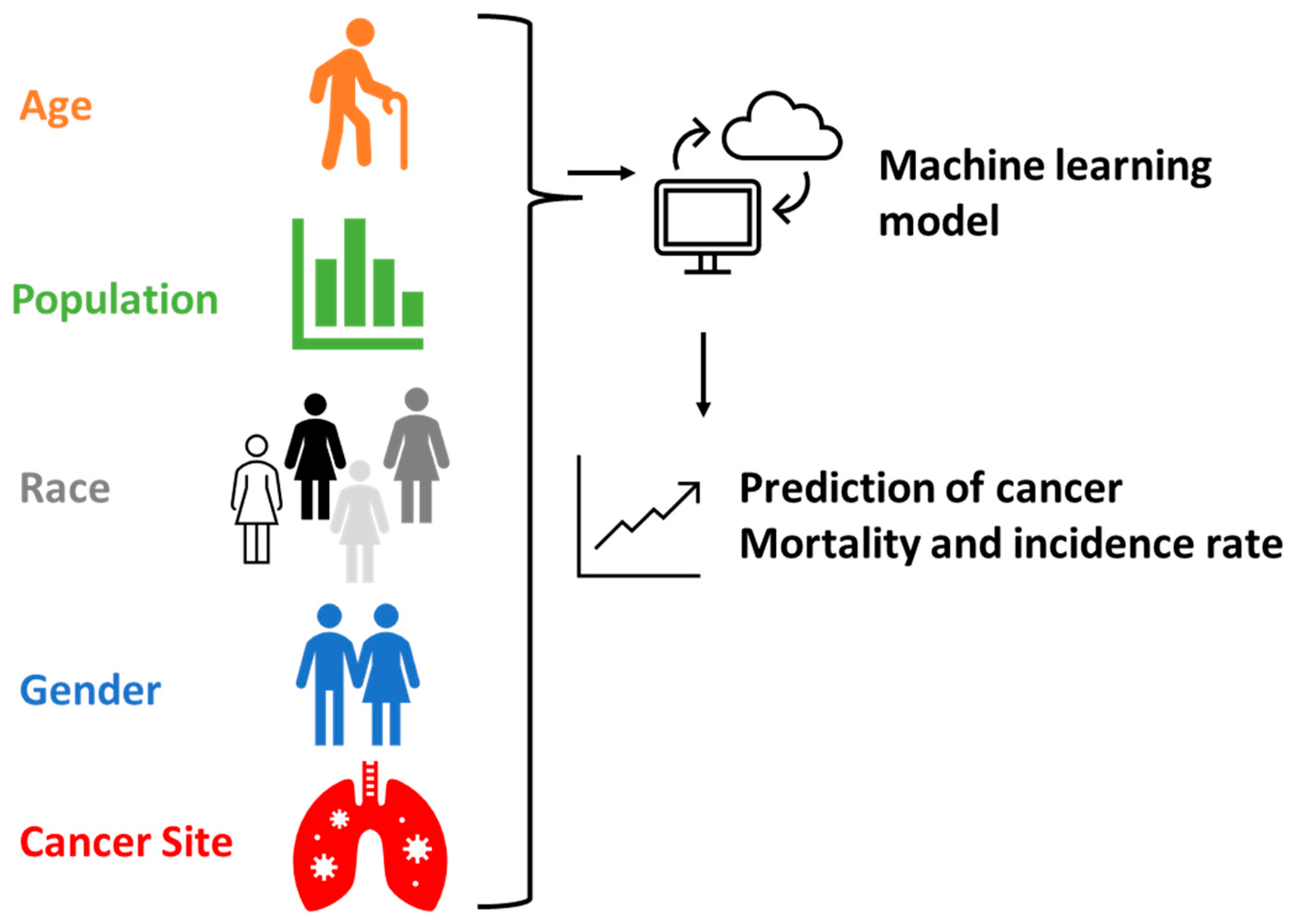
The novelty of this study lies in investigating the feasibility of utilizing ML models to predict cancer incidence and mortality rates (Figure 1). The specific objectives are as follows: (1) collecting large datasets of cancer and conducting data cleaning; (2) constructing ML models using the collected data; (3) predicting cancer outcomes using the ML models; and (4) validating the prediction results and calculating accuracy. The significance of this study is in demonstrating the viability of ML models, which can then be used by policymakers to forecast cancer outbreaks and proactively plan for medical resource allocation.
Figure 1.
Schematic illustration showing the process of ML model setup and prediction.
2. Materials and Methods
2.1. Data Source and Selection
This study utilized data from the Centers for Disease Control and Prevention (CDC), United States Cancer Statistics (USCS), unless otherwise specified (https://www.cdc.gov/cancer/uscs/dataviz/download_data.htm, accessed on 1 March 2023). Prior to analysis, all incomplete records were removed from the dataset. Specifically, we extracted the following categories: “age”, “count”, “population”, “race”, “gender”, “site”, “year”, “incidence rate”, and “mortality rate.” To facilitate analysis, a relationship matrix was generated to compare the different categories [8,9] (Tables S1 and S2). To ensure consistency in data formatting, all data were converted to positive integers based on the classification presented in Table 2.
Table 2.
Categorizing approaches for data treatment.
2.2. Training and Testing: Division of Data for Model Evaluation
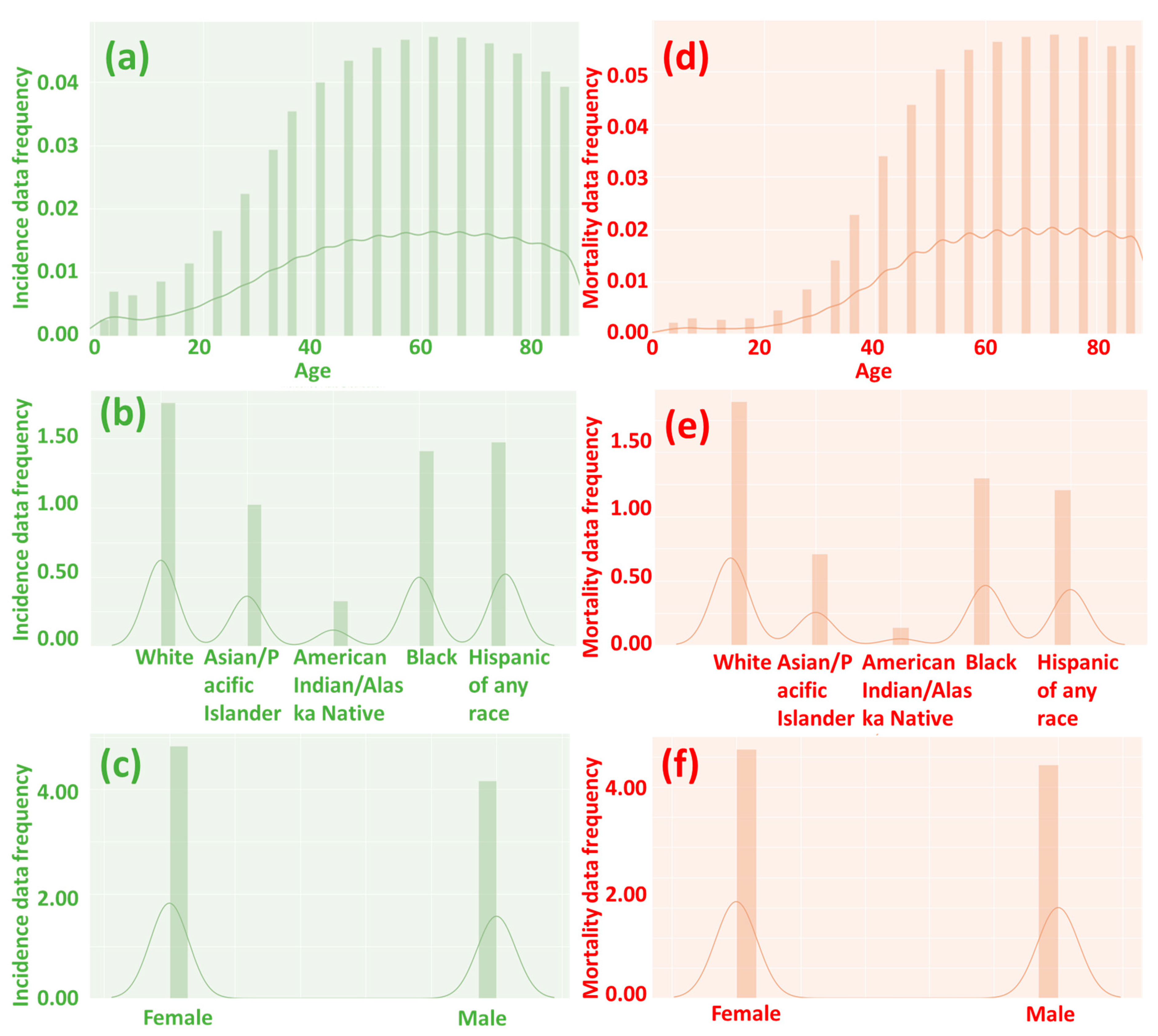
In this study, we built upon previous research [8,9] by making slight modifications to the ML models used. A total of 72,591 records (44,220 records for incidence and 28,371 records for mortality; the global distribution and data structure are shown in Figure 2) were utilized for the ML calculations, with 75% of the records used for training the models and the remaining 25% for testing. The ML models were implemented on the Anaconda 3 and Jupyter 6.3.0 platform using programming tools such as Scikit-learn, Graphviz, Numpy, Pandas, Matplotlib, and SciPy, as detailed in Tables S1 and S2. We employed five different ML methods for the calculations: decision tree, random forest, logistic regression, support vector machine (SVC), and neural network. For the random forest model, we utilized a hyper-tuning process via the random search method (Tables S3 and S4). Our neural network model comprised a total of 100 hidden layers, with each layer containing 100 nodes.
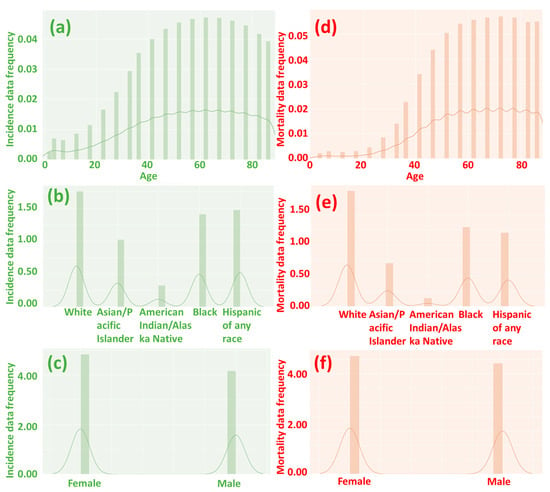
Figure 2.
The frequency of incidence (a–c) and mortality (d–f) data by age, race, and gender. A value of 0 suggests no incidence or mortality, while a higher number indicates a higher incidence and mortality rate. When people are over 40 years old, the likelihood of cancer incidence and mortality significantly increases.
After training the models, we analyzed the testing accuracy to identify the ML model with the highest performance, referencing methodologies established in previous studies [14,15]. Subsequently, we performed a detailed investigation into two significant factors—“age” and “site”—and their influence on the incidence and mortality rates of cancer. Our analysis yielded important insights into the factors that contribute to the incidence and mortality rates of different types of cancer. Ultimately, based on our study’s results, we provided recommendations to enhance the ML models and control the most lethal cancers identified. These recommendations could assist policymakers and healthcare providers in developing targeted and effective policies and interventions to combat cancer’s pervasive and devastating impact on individuals and communities. Overall, this study underscores the potential of ML models in aiding cancer prediction and highlights the importance of continued research in this field.
3. Results
3.1. Influential Factors in Cancer Incidence
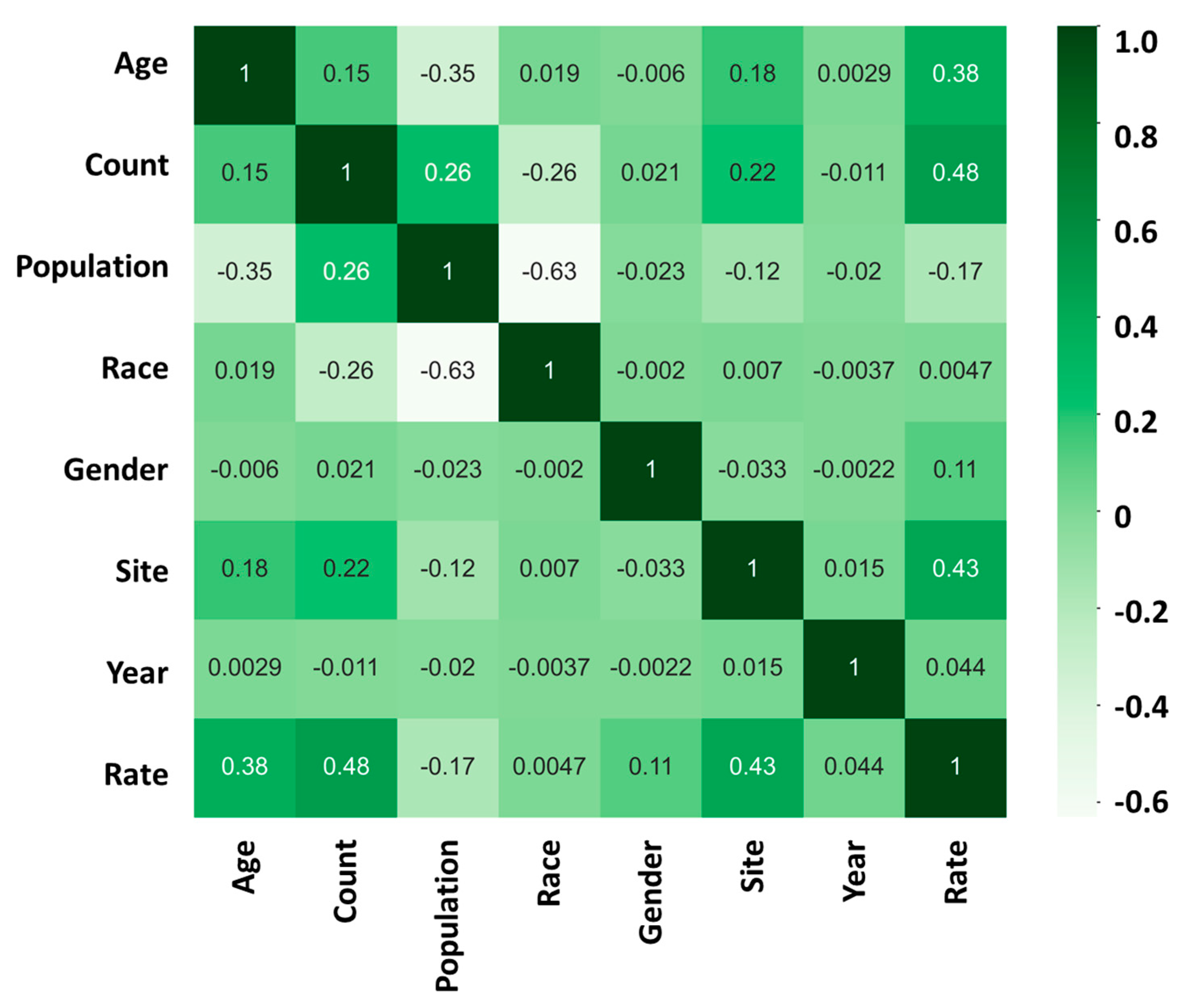
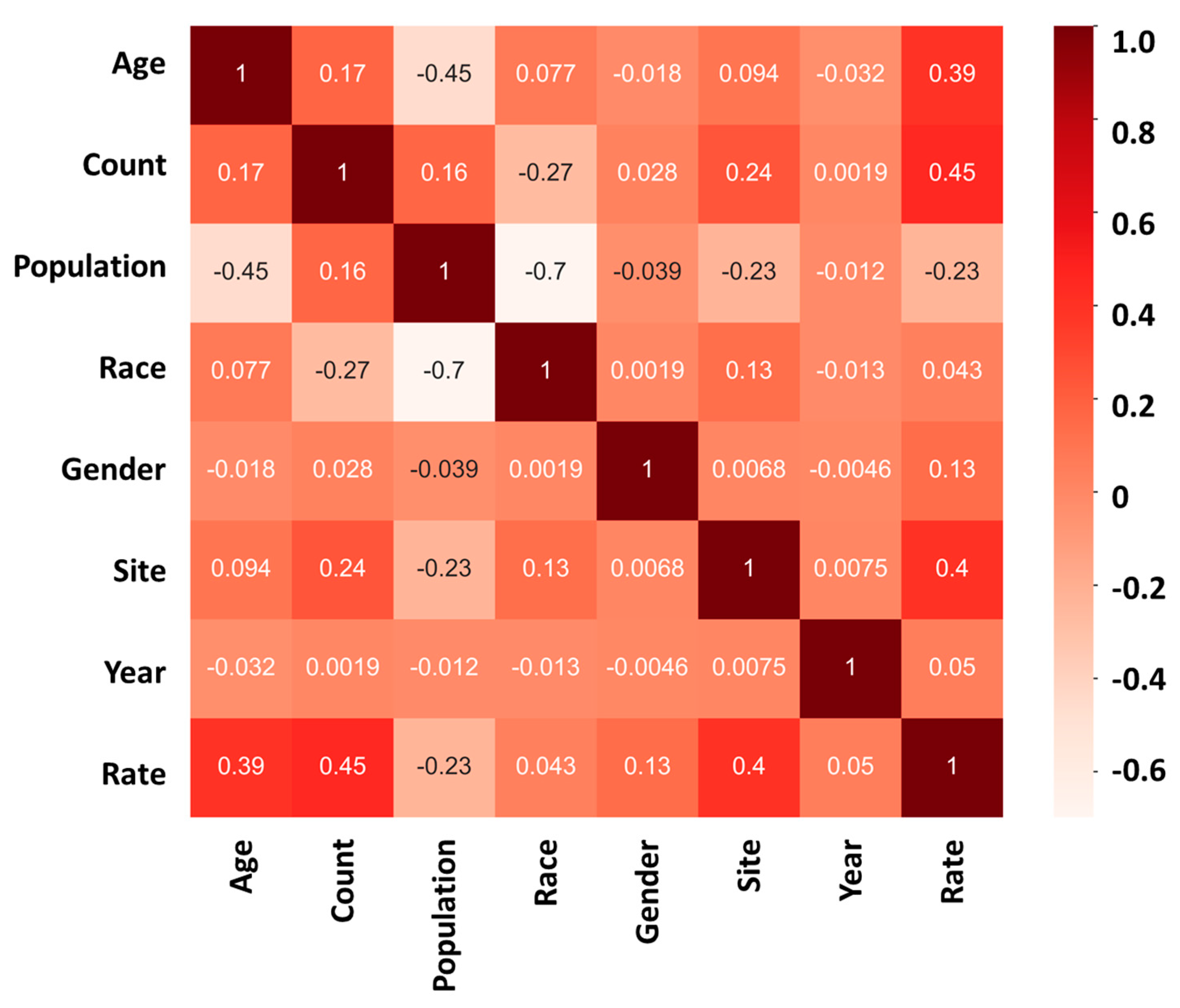
After conducting a comprehensive analysis of the data, our findings revealed that the risk of developing cancer is highly influenced by two major factors: “age” and “site.” We used a heatmap analysis to evaluate the relationship between these factors and the cancer incidence rate. Our results indicate that the correlation coefficient between “age” and the cancer incidence rate was found to be +0.38 (Figure 3). This suggests that, as individuals age, they become more susceptible to developing cancer.
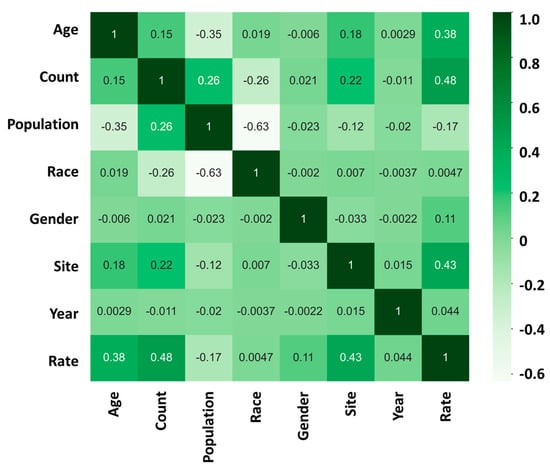
Figure 3.
Incidence heatmap analysis showing the relationship between “age”, “count”, “population”, “race”, “gender”, “site”, “year”, and “rate” in cancer incidence rate; 1 (dark green) represents a strong positive correlation between the two sets of data; 0 represents no correlation between the two sets of data; −1 (light white) represents a strong negative correlation between the two sets of data.
Furthermore, our analysis also showed that the “site” of cancer is another crucial factor that affects the incidence rate of cancer. The correlation coefficient between “site” and the cancer incidence rate was found to be +0.43 (Figure 3). This implies that the location or the specific organ where the cancer is found has a significant impact on its progression.
In contrast, our study found that factors such as “race”, “gender”, and “year of discovery” have a relatively low impact on the incidence rate of cancer. The correlation coefficient between race and the cancer incidence rate was found to be +0.0047, while that between gender and the cancer incidence rate was found to be +0.11. Similarly, the correlation coefficient between the year of discovery and the cancer incidence rate was found to be +0.044. Although these factors are important, their influence on the incidence rate of cancer is comparatively low.
Our study underscores the importance of identifying and understanding the factors that affect the incidence rate of cancer. By recognizing the significant impact of “age” and “site”, health professionals and policymakers can develop more targeted prevention and treatment strategies. Our findings provide a foundation for further research to identify additional factors that may influence the incidence rate of cancer, ultimately leading to more effective prevention and treatment methods.
The mortality rate analysis of the study further confirms the significance of age and site in influencing the outcome of cancer. The heatmap analysis revealed that “age” and “site” have a high positive correlation coefficient with the mortality rate, indicating that they are important predictors of cancer death. The correlation coefficient for “age” was found to be +0.39 (Figure 4), implying that the likelihood of cancer death increases with age. Similarly, the correlation coefficient for “site” was +0.40 (Figure 4), indicating that the location of cancer significantly affects its progression and outcome.
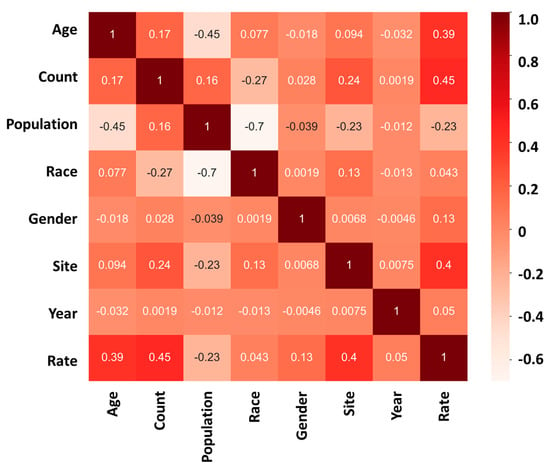
Figure 4.
Mortality heatmap analysis showing the relationship between “age”, “count”, “population”, “race”, “gender”, “site”, “year”, and “rate” in cancer mortality rate; 1 (dark red) represents a strong positive correlation between the two sets of data; 0 represents no correlation between the two sets of data; −1 (light white) represents a strong negative correlation between the two sets of data.
On the other hand, the study found that the impact of race, gender, and year of discovery on the cancer mortality rate is relatively low, with correlation coefficients of +0.043, +0.13, and +0.05, respectively. These findings suggest that, although these factors may have some influence on cancer mortality, their effect is much weaker compared to age and site.
The results of the mortality rate analysis highlight age and site as critical predictors of cancer outcomes. Older age is associated with higher cancer mortality rates, emphasizing the need for targeted prevention and treatment strategies for older populations. These findings suggest that healthcare professionals should prioritize screening and early detection programs for individuals at higher risk of developing cancer due to their age or the cancer site. Furthermore, this study underscores the necessity of additional research to elucidate the mechanisms linking age and site to cancer development and progression. Such research could inform the creation of more personalized and effective treatment approaches.
3.2. Advancements in ML Methods and Prediction Accuracy
In this research endeavor, we employed a diverse set of five machine learning methodologies, specifically, decision trees, random forests, logistic regression, support vector machines (SVC), and neural networks, to undertake a comprehensive evaluation and comparative analysis of their efficacy in the prediction of cancer incidence and mortality rates, as illustrated in Table 3. Subsequent to the model training phase, we conducted a rigorous performance assessment by scrutinizing the testing accuracy. The findings unequivocally demonstrated that the neural network model emerged as the most proficient, attaining an accuracy rate of 58.92% for the prediction of cancer incidence and 62.30% for mortality rate prognostication, thereby outperforming the other four models. Additionally, the neural network model exhibited superior precision levels, achieving 58.21% for cancer incidence prediction and 59.32% for mortality rate prediction, thereby surpassing the performance of the alternative models under investigation.
Table 3.
Comparison of ML prediction method.
When comparing the neural network with the other models, namely, the decision tree, random forest, logistic regression, and SVC models, they exhibited lower testing accuracy, indicating that they are less effective in predicting cancer incidence and mortality rates. Table 3 provides a summary of the testing accuracy of each model. It is worth noting that the selection of ML methods should consider various factors, such as data characteristics, model complexity, and computational resources. Therefore, future studies may need to further evaluate and compare different ML methods with larger datasets and more complex models to improve the prediction accuracy of cancer incidence and mortality rates.
4. Discussion
4.1. Consistent Findings: Aligning with Previous Studies on Aging and Cancer Rates
Our analysis of the heatmap (Figure 3 and Figure 4) has provided valuable insights into the impact of age on the incidence and mortality rates of cancer, surpassing the influence of race, gender, and year of discovery. Notably, the majority of cancer cases occurred after the age of 40, with the highest incidence rate frequency observed in the “60–64” age category and the highest mortality rate frequency in the “70–74” age category (Figure 2a,d). These results align with previous studies that have consistently demonstrated an increasing trend in cancer rates with advancing age [16]. For instance, breast cancer incidence is typically low before the age of 30 but steadily rises, reaching its peak around the age of 80 [17]. Moreover, most patients diagnosed with invasive cancer are over the age of 65, potentially attributed to the accumulation of protein-altering mutations with age [18].
The substantial impact of age on cancer incidence and mortality rates does not come as a surprise, considering that aging is a multifaceted process that affects all systems within the body. As individuals age, cells accumulate genetic mutations and undergo various alterations that heighten the risk of cancer development [19,20]. Additionally, the aging immune system experiences a decline in efficiency, rendering it less capable of detecting and combating cancer cells [21,22]. Collectively, these factors contribute to the elevated incidence and mortality rates of cancer in older adults.
Our research outcomes underscore the paramount importance of age as a prominent risk factor for cancer, while indicating that gender and race play comparatively less significant roles in this regard. These findings highlight the imperative need for tailored strategies in cancer prevention and treatment that take into account the age of the patient. Furthermore, our results accentuate the value of ongoing investigations into the intricate interplay between the process of aging and the development of cancer. Such endeavors aim to elucidate additional intricacies within the relationship between these factors. These insights, when gained, hold the potential to substantially advance our comprehension of cancer biology and contribute to the formulation of more efficacious interventions and therapeutic approaches, particularly tailored for the aging demographic. In terms of public policy, directing limited healthcare resources more towards the elderly population (age > 40, see Figure 2) and specific cancer sites would likely contribute to enhancing the efficiency of public resource utilization and improving both life expectancy and quality of life per capita.
4.2. Revealing Menacing Cancer Mortality Rates
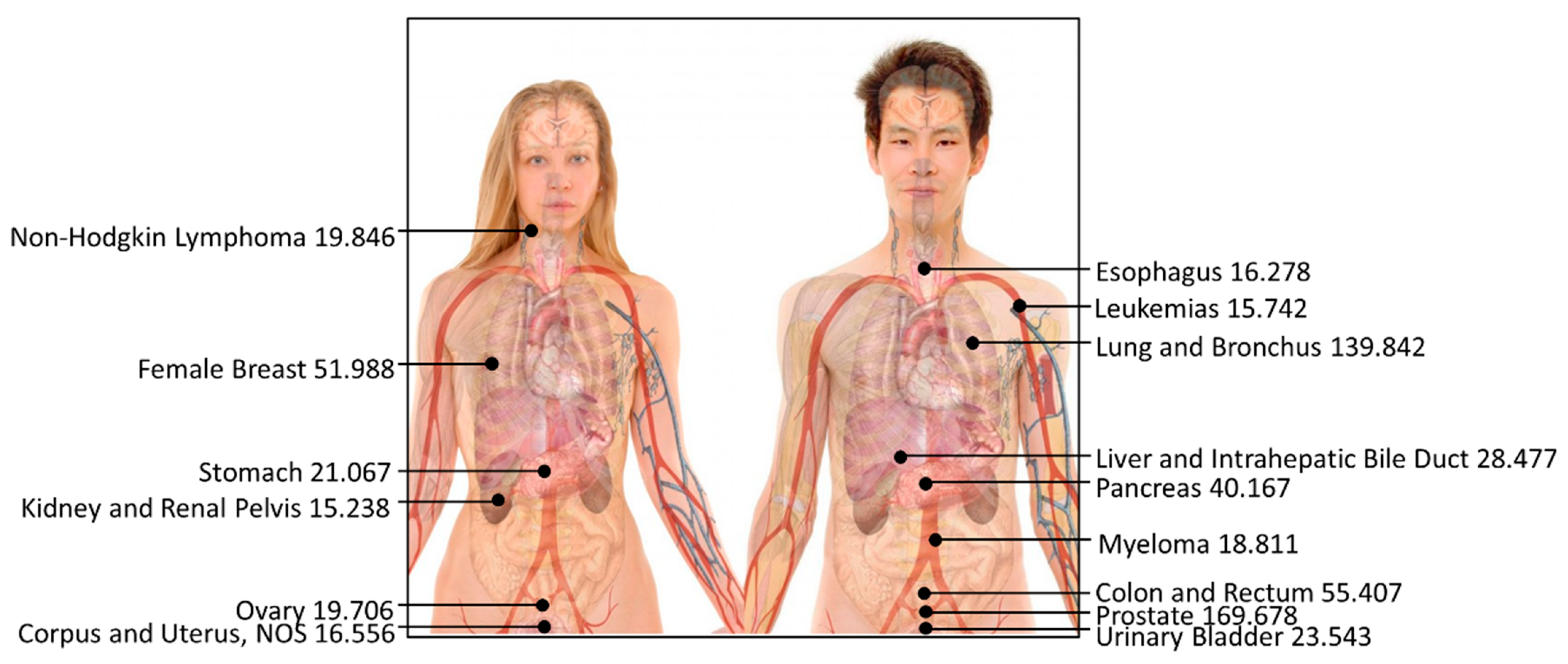
Our analysis of cancer mortality rates unveiled prostate cancer and lung and bronchus cancer as the most menacing, with 170 and 140 reported deaths per 100,000 individuals, respectively (Figure 5). This highlights the elevated mortality rates associated with these cancers compared to other types of cancer, as depicted in Table 4. Conversely, the incidence of testis cancer, Hodgkin lymphoma cancer, and thyroid cancer yielded the lowest reported deaths per 100,000 individuals, with rates of 0.416, 1.052, and 2.675, respectively.
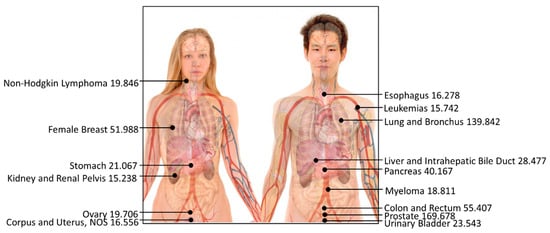
Figure 5.
Top-15 most dangerous cancers affecting human beings (reported death rate per 100,000; the higher the data, the greater the risk of cancer). The photo has been revised from a public source authored by Mikael Häggström with Creative Commons license, and the data are presented by this study.
Table 4.
Average mortality rate by different sites of cancer.
It is important to note that our findings align with previous studies that have also identified prostate and lung cancer as the leading causes of cancer deaths worldwide. For instance, the World Health Organization reported that lung cancer is the most common cancer globally, accounting for 2.1 million new cases in 2018, representing 11.6% of all new cancer cases, and 1.8 million deaths, contributing to 18.4% of all cancer-related deaths [23]. Similarly, the American Cancer Society estimates that prostate cancer ranks as the second-most common cancer and the second leading cause of cancer death among men in the United States, with an estimated 248,530 new cases and 34,130 deaths in 2021 [24,25].
Given these corroborating findings, it becomes crucial to prioritize measures focused on prevention, early detection, and effective treatment for these types of cancer to alleviate the associated morbidity and mortality rates. This may involve the implementation of regular screening programs, advocating lifestyle modifications, such as smoking cessation and physical activity, and spearheading research to develop innovative therapies for advanced-stage cancers.
Our comprehensive analysis of cancer mortality rates underscores the profound significance of cancer type in predicting cancer-related outcomes. While prostate and lung cancer are associated with the highest mortality rates, testis cancer, Hodgkin lymphoma cancer, and thyroid cancer have comparatively fewer reported deaths. Recognizing these distinct patterns allows us to better comprehend the underlying risk factors and enables us to devise tailored and effective strategies to improve cancer prevention and treatment outcomes. By embracing a comprehensive approach, combining research, public health initiatives, and individualized patient care, we can strive towards mitigating the burden of cancer and enhancing the overall quality of life for those affected.
According to recent research, emerging evidence suggests that bacteria and biofilm infection may contribute to the development of prostate cancer and lung cancer [26,27,28,29]. Bacteria and biofilms are known to play a crucial role in the genesis of prostate calcifications [28,30,31], which can induce inflammation and ultimately lead to prostate cancer. Similarly, biofilm formation can lead to lung infections caused by microorganisms such as Pseudomonas aeruginosa and Enterococcus faecalis [32,33,34], potentially progressing to lung cancer.
Biofilm essentially represents a community of microorganisms that attach to a surface and embed themselves in extracellular polymeric substances, encompassing extracellular DNA, proteins, and polysaccharides [35,36,37,38,39]. In recent years, researchers have harnessed the potential of engineered biofilms for various applications, ranging from electricity generation [40,41,42] to pollutant removal [36,37,38] and concrete enhancements [43,44]. However, as biofilms also possess detrimental effects on human health, it becomes imperative to explore strategies aimed at reducing biofilm presence in the environment. For instance, researchers can investigate the development of anti-biofilm cementitious materials [45,46,47,48], offering a promising avenue to foster a cleaner environment and potentially diminish the risk of cancer. By devising effective approaches to combat biofilms, we may hold the key to lowering the incidence of prostate cancer and lung cancer, thereby enhancing overall public health.
Continuing research efforts in understanding the intricate interplay between biofilms and cancer development will pave the way for innovative interventions and preventive measures. By targeting this underlying factor, we can move closer to reducing the burden of cancer and fortifying public health on a global scale. Additionally, investigations into the mechanisms through which biofilms influence cancer initiation and progression may unveil novel therapeutic targets, opening new avenues for cancer treatment and management. Ultimately, with a multifaceted approach that encompasses both scientific advancements and public health initiatives, we can strive towards a future with improved cancer outcomes and better quality of life for affected individuals.
4.3. Promising Direction: ML Models for Cancer Incidence and Mortality Prediction
This paper suggests a promising direction for applying ML models to predict cancer incidence and mortality rates. Like any statistical model, prediction accuracy is influenced by several factors. In the context of cancer prediction, three key factors that affect accuracy are the number of input factors, the quantity of records used, and the choice of appropriate ML methods.
The number of input factors plays a crucial role in determining the accuracy of the predictions. This feasibility study employs seven factors (“age”, “count”, “population”, “race”, “gender”, “site”, and “year”) to predict cancer incidence and mortality rates. However, due to computational limitations, the number of input factors is currently restricted. In the future, with the availability of higher computational power, it will be possible to incorporate additional factors (e.g., height, weight, smoking habit, drinking habit, family inheritance, migration history, current city, and living environment) into the ML model. This expansion of input factors is expected to enhance the ML methods, leading to higher prediction accuracy [49].
Similarly, the quantity of records used in the study significantly impacts prediction accuracy. The current analysis employs a dataset comprising 72,591 records to calculate cancer incidence and mortality rates. As data size improves, incorporating a larger dataset (e.g., 1 million records) in the future would enable more accurate predictions of cancer incidence and mortality rates [50,51]. By harnessing a more extensive pool of data, ML models can gain a deeper understanding of underlying patterns and relationships, further contributing to improved prediction accuracy.
Furthermore, this study specifically compares different ML methods, with the neural network exhibiting the highest testing accuracy and highest precision. Nevertheless, it is worth exploring the potential of other ML methods that might yield superior results. Methods such as k-means [52], nearest neighbor [53], linear discriminant analysis [54], and hidden Markov [55] are plausible candidates for comparison to identify the most accurate method.
4.4. Comparative Study of Prediction Models
Several studies employ machine learning to predict cancer. For instance, one study showed how it enhances cancer diagnosis, prognosis, and personalized medicine [12], while another focuses on modeling cancer progression and treatment [56]. Additionally, a group improved breast cancer prediction accuracy using machine learning techniques [57]. Another paper evaluated five machine learning methods for early disease detection, highlighting ANNs’ superior performance [15]. Another study systematically reviewed AI techniques for COVID-19 severity assessment, highlighting XGBoost and SVM as effective in predicting severity with high sensitivity and specificity [58]. In comparison, our study’s advantage lies in using a small dataset, quickly setting up prediction models (typically within a day), and achieving reasonable testing accuracy.
5. Conclusions
This study highlights the transformative impact of ML models on predicting cancer incidence and mortality rates. Moving beyond traditional, assumption-laden approaches, data-driven methodologies are poised to redefine precision in cancer prediction. The ML model presented here, utilizing a robust dataset and diverse algorithms, demonstrates promising potential for enhanced accuracy and adaptability in forecasting. Achieving testing accuracies reaching up to 62.30%, this innovative approach empowers scientists and policymakers to anticipate future cancer trends and optimize healthcare strategies. Looking ahead, leveraging big data and AI holds promise for proactive interventions, facilitating timely resource allocation, and significantly improving global cancer care outcomes.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/diseases12070139/s1, Table S1. Coding for cancer incidence prediction; Table S2. Coding for cancer incidence prediction; Table S3. Random search for random forest (incidence rate); Table S4. Random search for random forest (mortality rate).
Funding
This research received no funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study is available on request from the corresponding author.
Acknowledgments
The authors acknowledged the computation support from School of Geography and the Environment, University of Oxford.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Siegel, R.L.; Miller, K.D.; Wagle, N.S.; Jemal, A. Cancer statistics, 2023. CA A Cancer J. Clin. 2023, 73, 17–48. [Google Scholar] [CrossRef] [PubMed]
- Qawoogha, S.S.; Shahiwala, A. Identification of potential anticancer phytochemicals against colorectal cancer by structure-based docking studies. J. Recept. Signal Transduct. 2020, 40, 67–76. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Meng, Z.; Wu, X.; Zhang, M.; Zhang, S.; Jin, T. Mortalin promotes breast cancer malignancy. Exp. Mol. Pathol. 2021, 118, 104593. [Google Scholar] [CrossRef] [PubMed]
- Kolonel, L.N.; Altshuler, D.; Henderson, B.E. The multiethnic cohort study: Exploring genes, lifestyle and cancer risk. Nat. Rev. Cancer 2004, 4, 519–527. [Google Scholar] [CrossRef] [PubMed]
- Ferlay, J.; Colombet, M.; Soerjomataram, I.; Mathers, C.; Parkin, D.M.; Piñeros, M.; Znaor, A.; Bray, F. Estimating the global cancer incidence and mortality in 2018: GLOBOCAN sources and methods. Int. J. Cancer 2019, 144, 1941–1953. [Google Scholar] [CrossRef] [PubMed]
- Tyrer, J.; Duffy, S.W.; Cuzick, J. A breast cancer prediction model incorporating familial and personal risk factors. Stat. Med. 2004, 23, 1111–1130. [Google Scholar] [CrossRef] [PubMed]
- Antoniou, A.C.; Easton, D.F. Risk prediction models for familial breast cancer. Future Oncol. 2006, 2, 257–274. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Ding, Y. Machine learning and its applications in studying the geographical distribution of ants. Diversity 2022, 14, 706. [Google Scholar] [CrossRef]
- Chen, S.; Ding, Y. A Machine Learning Approach to Predicting Academic Performance in Pennsylvania’s Schools. Soc. Sci. 2023, 12, 118. [Google Scholar] [CrossRef]
- Chen, S.; Ding, Y.; Liu, X. Development of the growth mindset scale: Evidence of structural validity, measurement model, direct and indirect effects in Chinese samples. Curr. Psychol. 2021, 42, 1712–1726. [Google Scholar] [CrossRef]
- Wabartha, M.; Durand, A.; Francois-Lavet, V.; Pineau, J. Handling black swan events in deep learning with diversely extrapolated neural networks. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 7–15 January 2021; pp. 2140–2147. [Google Scholar]
- Cruz, J.A.; Wishart, D.S. Applications of machine learning in cancer prediction and prognosis. Cancer Inform. 2006, 2, 117693510600200030. [Google Scholar] [CrossRef]
- Wang, G.; Lam, K.-M.; Deng, Z.; Choi, K.-S. Prediction of mortality after radical cystectomy for bladder cancer by machine learning techniques. Comput. Biol. Med. 2015, 63, 124–132. [Google Scholar] [CrossRef] [PubMed]
- Erickson, B.J.; Kitamura, F. Magician’s corner: 9. Performance metrics for machine learning models. Radiol. Artif. Intell. 2021, 3, e200126. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.M.; Haque, M.R.; Iqbal, H.; Hasan, M.M.; Hasan, M.; Kabir, M.N. Breast cancer prediction: A comparative study using machine learning techniques. SN Comput. Sci. 2020, 1, 290. [Google Scholar] [CrossRef]
- Jemal, A.; Bray, F.; Center, M.M.; Ferlay, J.; Ward, E.; Forman, D. Global cancer statistics. CA Cancer J. Clin. 2011, 61, 69–90. [Google Scholar] [CrossRef] [PubMed]
- Singletary, S.E. Rating the risk factors for breast cancer. Ann. Surg. 2003, 237, 474. [Google Scholar] [CrossRef] [PubMed]
- Vogelstein, B.; Papadopoulos, N.; Velculescu, V.E.; Zhou, S.; Diaz Jr, L.A.; Kinzler, K.W. Cancer genome landscapes. Science 2013, 339, 1546–1558. [Google Scholar] [CrossRef] [PubMed]
- Preston-Martin, S.; Pike, M.C.; Ross, R.K.; Jones, P.A.; Henderson, B.E. Increased cell division as a cause of human cancer. Cancer Res. 1990, 50, 7415–7421. [Google Scholar]
- Rubin, J.B.; Lagas, J.S.; Broestl, L.; Sponagel, J.; Rockwell, N.; Rhee, G.; Rosen, S.F.; Chen, S.; Klein, R.S.; Imoukhuede, P. Sex differences in cancer mechanisms. Biol. Sex Differ. 2020, 11, 17. [Google Scholar] [CrossRef]
- Marasco, V.; Carniti, C.; Guidetti, A.; Farina, L.; Magni, M.; Miceli, R.; Calabretta, L.; Verderio, P.; Ljevar, S.; Serpenti, F. T-cell immune response after mRNA SARS-CoV-2 vaccines is frequently detected also in the absence of seroconversion in patients with lymphoid malignancies. Br. J. Haematol. 2022, 196, 548–558. [Google Scholar] [CrossRef]
- Mellman, I.; Coukos, G.; Dranoff, G. Cancer immunotherapy comes of age. Nature 2011, 480, 480–489. [Google Scholar] [CrossRef] [PubMed]
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed]
- Berglund, A.; Matta, J.; Encarnación-Medina, J.; Ortiz-Sanchéz, C.; Dutil, J.; Linares, R.; Marcial, J.; Abreu-Takemura, C.; Moreno, N.; Putney, R. Dysregulation of DNA Methylation and Epigenetic Clocks in Prostate Cancer among Puerto Rican Men. Biomolecules 2022, 12, 2. [Google Scholar] [CrossRef] [PubMed]
- Spieker, A.J.; Gordetsky, J.B.; Maris, A.S.; Dehan, L.M.; Denney, J.E.; Arnold Egloff, S.A.; Scarpato, K.; Barocas, D.A.; Giannico, G.A. PTEN expression and morphological patterns in prostatic adenocarcinoma. Histopathology 2021, 79, 1061–1071. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Konstantinov, S.R.; Smits, R.; Peppelenbosch, M.P. Bacterial biofilms in colorectal cancer initiation and progression. Trends Mol. Med. 2017, 23, 18–30. [Google Scholar] [CrossRef] [PubMed]
- Mirzaei, R.; Sabokroo, N.; Ahmadyousefi, Y.; Motamedi, H.; Karampoor, S. Immunometabolism in biofilm infection: Lessons from cancer. Mol. Med. 2022, 28, 10. [Google Scholar] [CrossRef] [PubMed]
- Parsonnet, J. Bacterial infection as a cause of cancer. Environ. Health Perspect. 1995, 103, 263–268. [Google Scholar] [PubMed]
- Uemura, N.; Okamoto, S.; Yamamoto, S.; Matsumura, N.; Yamaguchi, S.; Yamakido, M.; Taniyama, K.; Sasaki, N.; Schlemper, R.J. Helicobacter pylori infection and the development of gastric cancer. New Engl. J. Med. 2001, 345, 784–789. [Google Scholar] [CrossRef] [PubMed]
- Cai, T.; Santi, R.; Tamanini, I.; Galli, I.C.; Perletti, G.; Bjerklund Johansen, T.E.; Nesi, G. Current knowledge of the potential links between inflammation and prostate cancer. Int. J. Mol. Sci. 2019, 20, 3833. [Google Scholar] [CrossRef]
- Cai, T.; Tessarolo, F.; Caola, I.; Piccoli, F.; Nollo, G.; Caciagli, P.; Mazzoli, S.; Palmieri, A.; Verze, P.; Malossini, G. Prostate calcifications: A case series supporting the microbial biofilm theory. Investig. Clin. Urol. 2018, 59, 187–193. [Google Scholar] [CrossRef]
- Chudzik-Rząd, B.; Zalewski, D.; Kasela, M.; Sawicki, R.; Szymańska, J.; Bogucka-Kocka, A.; Malm, A. The Landscape of Gene Expression during Hyperfilamentous Biofilm Development in Oral Candida albicans Isolated from a Lung Cancer Patient. Int. J. Mol. Sci. 2023, 24, 368. [Google Scholar] [CrossRef] [PubMed]
- Vijayakumar, S.; Vaseeharan, B.; Malaikozhundan, B.; Gopi, N.; Ekambaram, P.; Pachaiappan, R.; Velusamy, P.; Murugan, K.; Benelli, G.; Kumar, R.S. Therapeutic effects of gold nanoparticles synthesized using Musa paradisiaca peel extract against multiple antibiotic resistant Enterococcus faecalis biofilms and human lung cancer cells (A549). Microb. Pathog. 2017, 102, 173–183. [Google Scholar] [CrossRef] [PubMed]
- Bjarnsholt, T.; Buhlin, K.; Dufrêne, Y.F.; Gomelsky, M.; Moroni, A.; Ramstedt, M.; Rumbaugh, K.P.; Schulte, T.; Sun, L.; Åkerlund, B. Biofilm formation–what we can learn from recent developments. J. Intern. Med. 2018, 284, 332–345. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Ding, Y.; Cohen, Y.; Cao, B. Elevated level of the second messenger c-di-GMP in Comamonas testosteroni enhances biofilm formation and biofilm-based biodegradation of 3-chloroaniline. Appl. Microbiol. Biotechnol. 2015, 99, 1967–1976. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Peng, N.; Du, Y.; Ji, L.; Cao, B. Disruption of putrescine biosynthesis in Shewanella oneidensis enhances biofilm cohesiveness and performance in Cr (VI) immobilization. Appl. Environ. Microbiol. 2014, 80, 1498–1506. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Zhou, Y.; Yao, J.; Szymanski, C.; Fredrickson, J.; Shi, L.; Cao, B.; Zhu, Z.; Yu, X.-Y. In situ molecular imaging of the biofilm and its matrix. Anal. Chem. 2016, 88, 11244–11252. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Zhou, Y.; Yao, J.; Xiong, Y.; Zhu, Z.; Yu, X.-Y. Molecular evidence of a toxic effect on a biofilm and its matrix. Analyst 2019, 144, 2498–2503. [Google Scholar] [CrossRef] [PubMed]
- Flemming, H.-C.; Wingender, J. The biofilm matrix. Nat. Rev. Microbiol. 2010, 8, 623–633. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Ding, Y.; Hu, Y.; Cao, B.; Rice, S.A.; Kjelleberg, S.; Song, H. Enhancing bidirectional electron transfer of Shewanella oneidensis by a synthetic flavin pathway. ACS Synth. Biol. 2015, 4, 815–823. [Google Scholar] [CrossRef]
- Zhao, C.-e.; Chen, J.; Ding, Y.; Wang, V.B.; Bao, B.; Kjelleberg, S.; Cao, B.; Loo, S.C.J.; Wang, L.; Huang, W. Chemically functionalized conjugated oligoelectrolyte nanoparticles for enhancement of current generation in microbial fuel cells. ACS Appl. Mater. Interfaces 2015, 7, 14501–14505. [Google Scholar] [CrossRef]
- Zhao, C.e.; Wu, J.; Ding, Y.; Wang, V.B.; Zhang, Y.; Kjelleberg, S.; Loo, J.S.C.; Cao, B.; Zhang, Q. Hybrid conducting biofilm with built-in bacteria for high-performance microbial fuel cells. ChemElectroChem 2015, 2, 654–658. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, D.; Ding, Y.; Wang, S. Mechanical performance of strain-hardening cementitious composites (SHCC) with bacterial addition. J. Infrastruct. Preserv. Resil. 2022, 3, 3. [Google Scholar] [CrossRef]
- Zhang, Z.; Weng, Y.; Ding, Y.; Qian, S. Use of genetically modified bacteria to repair cracks in concrete. Materials 2019, 12, 3912. [Google Scholar] [CrossRef]
- Hamdany, A.H.; Ding, Y.; Qian, S. Visible light antibacterial potential of graphene-TiO2 cementitious composites for self-sterilization surface. J. Sustain. Cem.-Based Mater. 2022, 12, 972–982. [Google Scholar] [CrossRef]
- Hamdany, A.H.; Ding, Y.; Qian, S. Cementitious Composite Materials for Self-Sterilization Surfaces. ACI Mater. J. 2022, 119, 197–210. [Google Scholar] [CrossRef]
- Hamdany, A.H.; Ding, Y.; Qian, S. Mechanical and antibacterial behavior of photocatalytic lightweight engineered cementitious composites. J. Mater. Civ. Eng. 2021, 33, 04021262. [Google Scholar] [CrossRef]
- Hamdany, A.H.; Ding, Y.; Qian, S. Graphene-Based TiO2 Cement Composites to Enhance the Antibacterial Effect of Self-Disinfecting Surfaces. Catalysts 2023, 13, 1313. [Google Scholar] [CrossRef]
- Taninaga, J.; Nishiyama, Y.; Fujibayashi, K.; Gunji, T.; Sasabe, N.; Iijima, K.; Naito, T. Prediction of future gastric cancer risk using a machine learning algorithm and comprehensive medical check-up data: A case-control study. Sci. Rep. 2019, 9, 12384. [Google Scholar] [CrossRef]
- Al-Jarrah, O.Y.; Yoo, P.D.; Muhaidat, S.; Karagiannidis, G.K.; Taha, K. Efficient machine learning for big data: A review. Big Data Res. 2015, 2, 87–93. [Google Scholar] [CrossRef]
- Bzdok, D.; Krzywinski, M.; Altman, N. Machine learning: A primer. Nat. Methods 2017, 14, 1119. [Google Scholar] [CrossRef]
- Zhao, M.; Tang, Y.; Kim, H.; Hasegawa, K. Machine learning with k-means dimensional reduction for predicting survival outcomes in patients with breast cancer. Cancer Inform. 2018, 17, 1176935118810215. [Google Scholar] [CrossRef] [PubMed]
- Moitra, D.; Mandal, R.K. Automated grading of non-small cell lung cancer by fuzzy rough nearest neighbour method. Netw. Model. Anal. Health Inform. Bioinform. 2019, 8, 24. [Google Scholar] [CrossRef]
- Jessica, E.O.; Hamada, M.; Yusuf, S.I.; Hassan, M. The Role of Linear Discriminant Analysis for Accurate Prediction of Breast Cancer. In Proceedings of the 2021 IEEE 14th International Symposium on Embedded Multicore/Many-Core Systems-on-Chip (MCSoC), Singapore, 20–23 December 2021; pp. 340–344. [Google Scholar]
- Nguyen, T.; Khosravi, A.; Creighton, D.; Nahavandi, S. Hidden Markov models for cancer classification using gene expression profiles. Inf. Sci. 2015, 316, 293–307. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef]
- Naji, M.A.; El Filali, S.; Aarika, K.; Benlahmar, E.L.H.; Abdelouhahid, R.A.; Debauche, O. Machine learning algorithms for breast cancer prediction and diagnosis. Procedia Comput. Sci. 2021, 191, 487–492. [Google Scholar] [CrossRef]
- Ghaderzadeh, M.; Asadi, F.; Ramezan Ghorbani, N.; Almasi, S.; Taami, T. Toward artificial intelligence (AI) applications in the determination of COVID-19 infection severity: Considering AI as a disease control strategy in future pandemics. Iran. J. Blood Cancer 2023, 15, 93–111. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).