In this section, we compare the presented implementations for OMP, by theoretical and empirical analysis.
4.1. Theoretical Analysis of Computational Complexities and Memory Requirements
Table 1 compares the expected computational complexities (in the implementations with
memories (to store
, the Gram matrix of the dictionary), we assume that
has been computed offline and stored) and memory requirements of the existing and proposed OMP implementations in the
k-th iteration (
), where the complexities are the numbers of multiplications and additions, which include both dominating terms and coefficients. It can be seen that each implementation needs nearly the same number of multiplications and additions. “Dominating terms” here means that we omit the terms that are
,
or
. For example, “Dominating terms” for Chol-2 only include the terms for (
18) and to solve the triangular systems (
17), (
21) and (
22). When evaluating the memory requirements for
Table 1, we neglect the fact that we may only store parts of some matrices, such as the Hermitian Gram matrix
and the triangular Cholesky factor. The entries in
Table 1 are counted from the above-described relevant equations. The complexities of the existing OMP implementations listed in
Table 1 are consistent with those in Table 1 of [
24], while the complexity of each proposed OMP implementation is broken down for each equation in
Table 2.
In
Table 1, Naive, Chol-1, Chol-2, QR-1, QR-2, MIL-1 and MIL-2 denote the naive OMP implementation (i.e., Algorithm 1), two implementations by the Cholesky factorization (i.e., Algorithm 2), two implementations by the QR factorization (i.e., Algorithm 3), and two implementations by the Matrix Inversion Lemma (i.e., Algorithm 4), respectively. On the other hand, Proposed-v0, Proposed-v1, Proposed-v2, Proposed-v3 and Proposed-v4 in
Table 1 and
Table 2 denote the proposed implementation of OMP (v0) and the proposed 4 memory-saving versions, which have been described in Algorithms 5–9, respectively.
From
Table 1, it can be seen that the proposed OMP implementation (i.e., Proposed-v0) needs the least computational complexities. With respect to any of the existing efficient implementations (i.e., Chol-2, MIL-2, Chol-1, MIL-1 and QR-2) spending
memories for
, Proposed-v1 requires less computational complexities and the same or less memories. On the other hand, with respect to the only existing efficient implementation not storing
, i.e., QR-1, Proposed-v2 needs less computational complexities and a little more memories, while Proposed-v3 needs the same complexities and less memories. Lastly, with respect to Naive, Proposed-v4 needs much less computational complexities and only a little more memories.
4.2. Empirical Comparison for OMP Implementations
We perform MATLAB simulations to compare all the proposed 5 versions of OMP implementations with the existing ones, on a 64-bit 2.4-GHz Microsoft-Windows Xeon workstation with 15.9 GB of RAM. We give the simulation results for numerical errors and computational time (the MATLAB code to generate
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 of this paper is shared in
https://github.com/zhuhufei/OMP.git) in
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6. Moreover, we show the floating-point operations (flops) required by different OMP implementations in
Figure 7,
Figure 8 and
Figure 9, where the complexities listed in
Table 1 are utilized to count the flops. To obtain
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9, the shared simulation code [
42] is utilized.
As Figure 1 in [
24],
Figure 1 here shows the accumulation of numerical errors in the recursive computation of the inner products
s and the solutions
s, where the errors mean the differences in the computed
s and
s between the naive implementation and any considered efficient implementation. For example, the numerical errors of Chol-2 are defined by
and
We perform 100 independent trials, and the other simulation parameters are usually identical to those for Figure 1 in [
24]. For example, we set
,
and the sparsity
, and sample sparse vectors from a Rademacher or Normal distribution. For any
k-th (
) iteration, we compute the mean relative errors of the inner products and those of the solutions, which are plotted in
Figure 1a and
Figure 1b, respectively. Since Figure 1 in [
24] shows that QR-1, Chol-2 and MIL-1 have nearly the same numerical errors, here we only compare the numerical errors of the proposed five versions with those of Chol-2. Moreover, we do the same simulations in
Figure 2 as in
Figure 1, except that we set the sparsity
instead of
.
In
Figure 3, we perform Monte Carlo simulations to show the Signal-to-Reconstruction-Error Ratio (SRER) of different OMP implementations versus Indeterminacy
(i.e., Fraction of Measurements), where we follow the simulations for Figures 1 and 2 in [
44], and SRER is defined by
As Figure 1 in [
44],
Figure 3a gives the SRER performance for Normal (i.e., Gaussian) sparse signals in the clean measurement case and the noisy measurement case with
dB, where SMNR denotes Signal to Measurement-Noise Ratio and satisfies
Similarly,
Figure 3b gives the SRER performance for Rademacher sparse signals, as
Figure 2 in [
44]. In
Figure 3, we set
and
. Moreover, we generate the dictionary
100 times and for each realization of
, we generate a sparse signal
100 times.
From
Figure 1,
Figure 2 and
Figure 3, it can be seen that the differences in numerical errors between the implementations are inconsequential. Then let us show the computational time of 100 independent runs of
K iterations for
of size
in
Figure 4, where we follow (Figure 2 in [
24] gives the computational time of four existing OMP implementations, i.e., Naive, QR-1, Chol-2 and MIL-1. Instead of MIL-1 in Figure 2 of [
24], we simulate MIL-2 in our
Figure 4, since MIL-1 is slower than MIL-2 in our simulations. Actually Chol-1 and QR-2 omitted in both Figure 2 of [
24] and our
Figure 4 are also slower than Chol-2 and QR-1, respectively) the simulations for Figure 2 in [
24]. We measure time by tic/toc in MATLAB, and show
for two different
N in
Figure 4. To do fair comparisons, the MATLAB code for the proposed five versions is similar to the shared simulation code [
42] (of [
24]). Moveover, we show several sections of the 3D
Figure 4b in
Figure 5 and
Figure 6, where we show
instead of
in
Figure 4.
Figure 5a,b set the Indeterminacies
to be
and
, respectively, to show time ratios as a function of the Sparsity
. Then
Figure 6a,b set the Sparsities
to be
and
, respectively, to show time ratios as a function of the indeterminacies
.
From
Figure 4,
Figure 5 and
Figure 6, it can be seen that Proposed-v0 is the fastest for almost all
N,
M and
K, while Proposed-v2 and Proposed-v3 are faster than the existing implementations for most problem sizes.
Figure 5 and
Figure 6 also show that in most cases, the speedups in computational time of Proposed-v0, Proposed-v2, Proposed-v3 and QR-1 over Naive grow almost linearly with the increase of the sparsity
for the two fixed indeterminacies
, and grow almost linearly with the increase of the indeterminacy
for the two fixed sparsities
. The computational time of Proposed-v4 is near or less than that of an existing efficient implementation (e.g., MIL-2 or QR-1) for most problem sizes, while the memory requirements of Proposed-v4 are much less than those of any existing efficient implementation, and are only a little more than the (known) minimum requirements (i.e., the requirements of Naive). Thus Proposed-v4 seems to be a good choice when we need an efficient implementation with the minimum memory requirements. Moreover, from
Table 1,
Figure 4,
Figure 5 and
Figure 6, it can be seen that with respect to Chol-2 and MIL-2, Proposed-v1 needs the same size of memories and
less of complexities, and is usually a little faster.
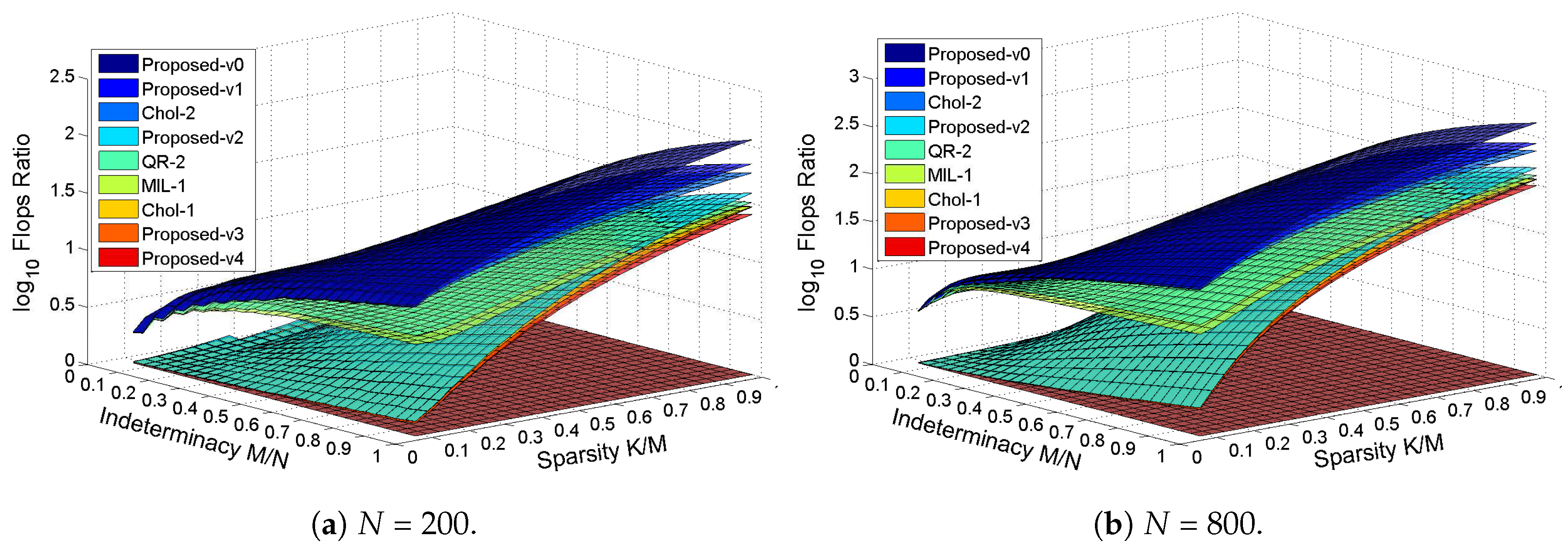
In
Figure 7, we show
for two different
N. Then in
Figure 8 and
Figure 9, we show the flops ratios of Chol-2 over Proposed-v0, Proposed-v1 and MIL-2, respectively, to compare flops among the efficient OMP implementations storing
, and we also show the flops ratios of of QR-1 over Proposed-v2, Proposed-v3 and Proposed-v4, respectively, to compare flops among the efficient implementations that do not store
. In
Figure 8, we give the flops ratios as a function of the sparsity
for the indeterminacies
and
, respectively, while in
Figure 9, we give the flops ratios as a function of the indeterminacy
for the sparsities
and
, respectively.
From
Figure 7, it can be seen that the speedups in flop numbers of Proposed-v0, Proposed-v1, Chol-2, QR-2 and MIL-1 over Naive are obvious for almost all problem sizes. From
Figure 8 and
Figure 9, it can be seen that the speedups in flop numbers of Proposed-v0 and Proposed-v1 over Chol-2 and those of Proposed-v2 over QR-1 grow linearly with the increase of the sparsity
for the two fixed indeterminacies
, and grow linearly with the increase of the indeterminacy
for the two fixed sparsities
. On the other hand, with respect to QR-1, Proposed-v3 requires the similar number of flops and Proposed-v4 requires a little more flops, while as shown in
Table 1, both Proposed-v3 and Proposed-v4 require less memories.
Figure 4 and
Figure 7 indicate that Proposed-v1, Chol-2 and MIL-2 need less flops and more computational time, with respect to Proposed-v2, Proposed-v3 and QR-1, while
Table 1 and Figure 2 of [
24] also indicate that with respect to QR-1, Chol-2 and MIL-1 need less flops and more computational time. One possible reason for this phenomenon could be that the computational time is decided not only by the required flops, but also by the required operations for memory access. Specifically, this reason can partly explain why MIL-2 is obviously slower than Chol-2, since in the
k-th iteration, MIL-2 needs to access
memories in (
38) to obtain the inverse of
, while Chol-2 only needs to access
k memories in (
20) to obtain the Cholesky factor of
.
In addition to the flops and the operations for memory access, the parallelizability of the OMP implementation can also affect the the computational time. When considering this factor, notice that the proposed five versions do not need any back-substitution in each iteration, and only include parallelizable matrix-vector products [
45]. Contrarily, the existing Chol-1, Chol-2 and QR-2 usually solve triangular systems by back-substitutions [
43], which are inherent serial processes unsuitable for parallel implementations [
45]. It can be easily seen that Chol-1 and Chol-2 both need
multiplications and additions for the back-substitutions to solve 3
triangular systems (
17), (
21) and (
22), while QR-2 needs
multiplications and additions for the back-substitutions to solve 2
triangular systems (
25) and (
26).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}