IoT Based Health—Related Topic Recognition from Emerging Online Health Community (Med Help) Using Machine Learning Technique

 ,
,  ,
,  and
and 
Abstract
1. Introduction
- To extract important keywords of each disease from each cluster.
- To find inter–relationships among three chronic diseases.
- To measure the accuracy of extracted keywords by comparing keywords with the world’s trusted organization reports.
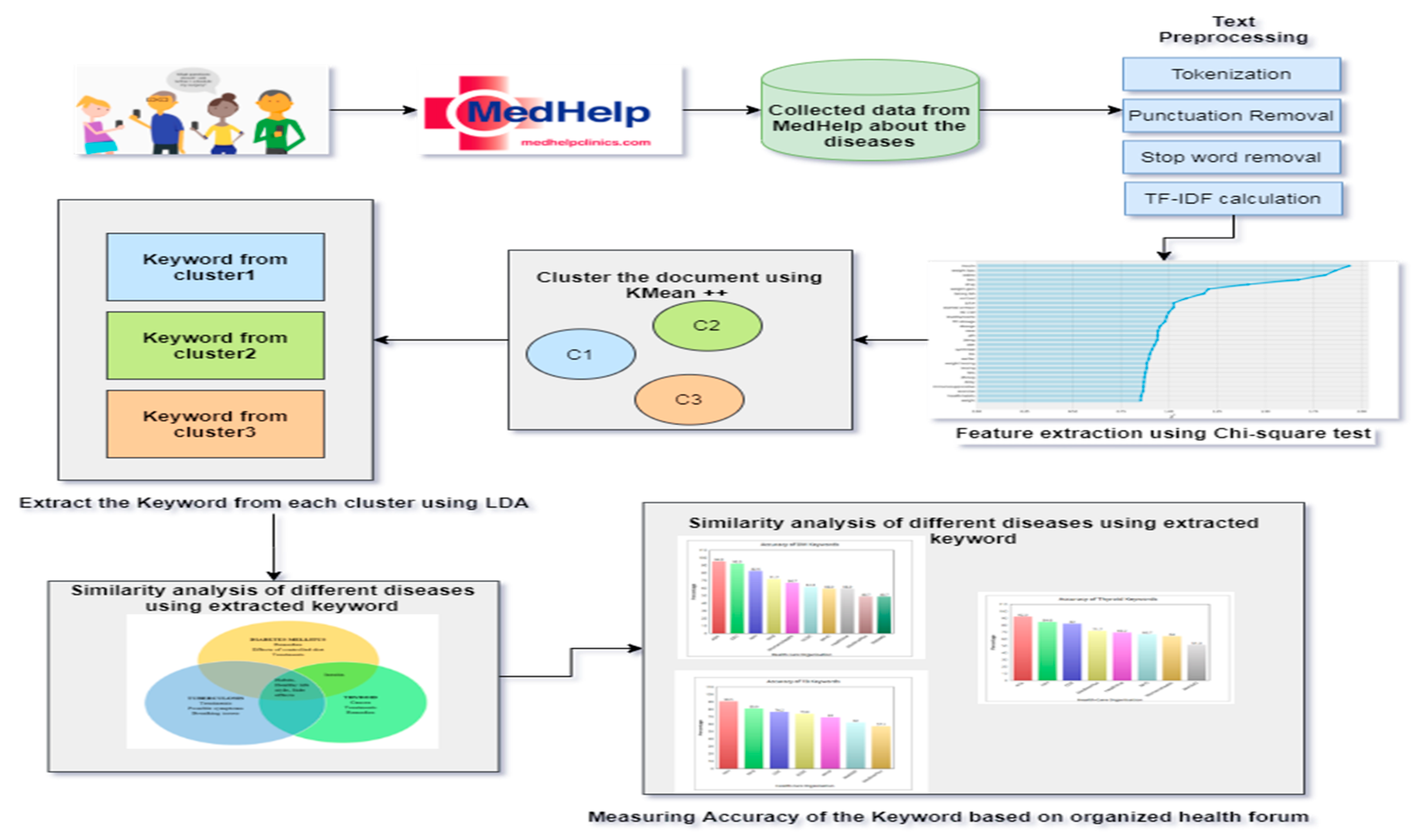
2. Materials and Methods
- The comments discussed by both patients and physicians in the healthcare forum, Med Help, are collected for the three chronic diseases.
- The datasets are pre-processed using NLP techniques such as tokenization, stopword removal and punctuation removal. The term frequency-inverse document frequency (TF–IDF) measure is used to collect the most important words from the collected pre-processed datasets.
- The most important feature words are filtered using the chi-square test from the three pre-processed datasets.
- The K-means++ algorithm is applied to the reduced feature datasets. With evidence of clustering groups, LDA is used to identify the most frequently occurring meaningful keywords.
- Keywords identified from each cluster of all three diseases are compared with the world’s trusted healthcare organizations to measure their accuracy.
2.1. Data Set Gathering and Preprocessing
| Algorithm 1 Text-Preprocessing |
| Input: Dataset Collected from Medhelp. |
| Output: Pre-processed dataset for each disease |
|
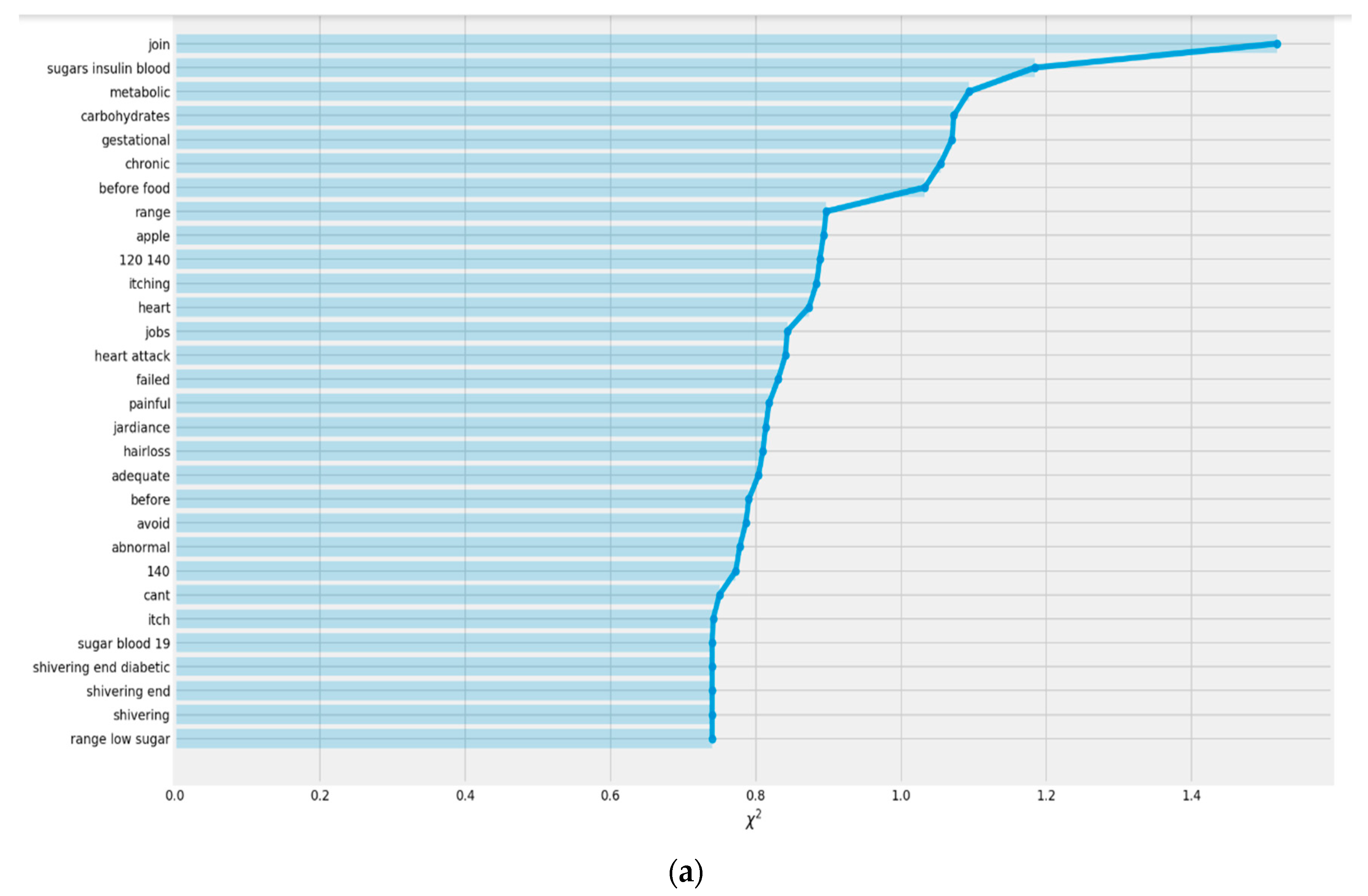
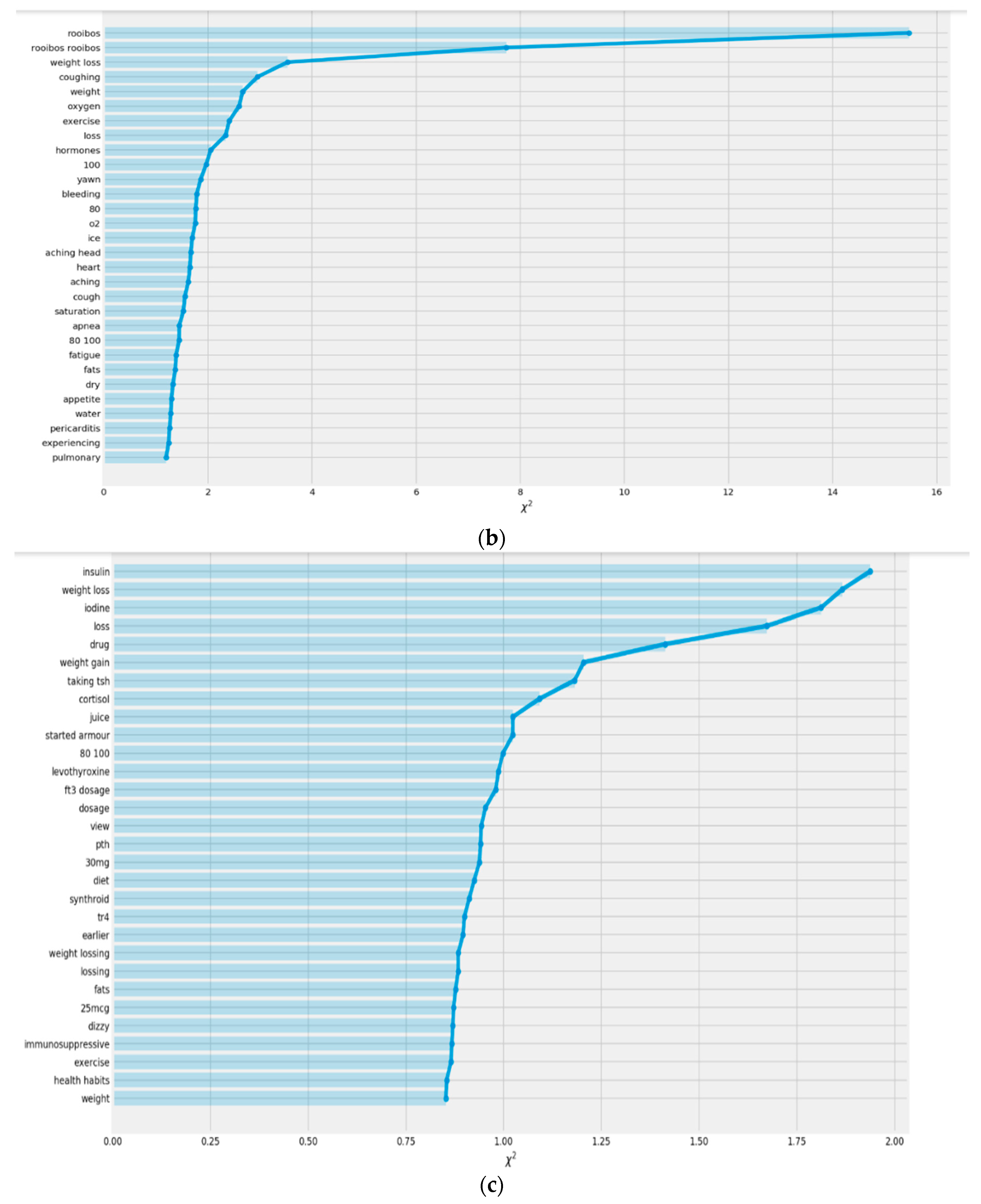
2.2. Chi-Square Test
- Observed frequency is the number of observations of words in a document,
- Expected frequency is the number of expected observations of words in a document if there is no relationship between features.
| Algorithm 2 Chi-Square Test |
| Input: Pre-processed dataset |
| Output: Essential feature dataset, F extracted based on Chi-Square test. |
|
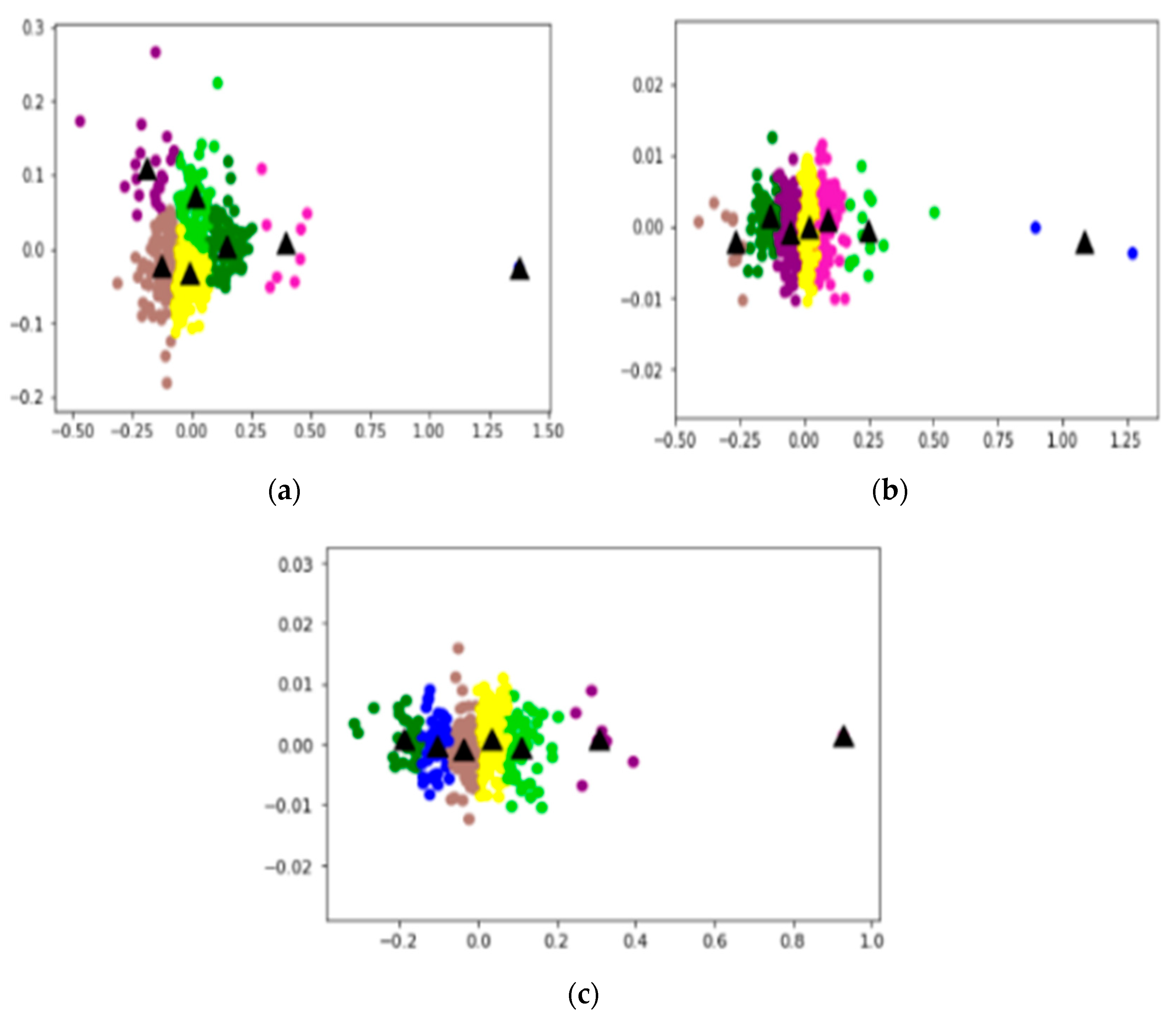
2.3. K-Mean++
| Algorithm 3 K-means++ |
| Input: Essential feature dataset extracted based on the chi-square test. |
| Output: Seven clustered documents. |
|
2.4. LDA
3. Results
3.1. Data Set Gatering and Preprocessing
3.2. Chi-Square Test
3.3. K-Mean++
3.4. LDA
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vrieling, F.; Ronacher, K.; Kleynhans, L.; van den Akker, E.; Walzl, G.; Ottenhoff, T.H.; Joosten, S.A. Patients with Concurrent Tuberculosis and Diabetes have a Pro-Atherogenic Plasma Lipid Profile. EbioMedicine 2018, 32, 192–200. [Google Scholar] [CrossRef] [PubMed]
- Fiarni, C.; Sipayung, E.M.; Maemunah, S. Analysis and Prediction of Diabetes Complication Disease using Data Mining Algorithm. Procedia Comput. Sci. 2019, 161, 449–457. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, H.; Huynh, Q.; Nolan, M.; Negishi, K.; Marwick, T.H. Diagnosis of Nonischaemic Stage B Heart Failure in Type 2 Diabetes Mellitus: Optimal Parameters for Prediction of Heart Failure. JACC Cardiovasc. Imaging 2018, 11, 1390–1400. [Google Scholar] [CrossRef] [PubMed]
- Su, F.C.; Friesen, M.C.; Humann, M.; Stefaniak, A.B.; Stanton, M.L.; Liang, X.; LeBouf, R.F.; Henneberger, P.K.; Virji, M.A. Clustering asthma symptoms and cleaning and disinfecting activities and evaluating their associations among healthcare workers. Int. J. Hyg. Environ. Health 2019, 222, 873–883. [Google Scholar] [CrossRef] [PubMed]
- dos Santos, B.S.; Steiner, M.T.; Fenerich, A.T.; Lima, R.H. Data mining and machine learning techniques applied to public health problems: A bibliometric analysis from 2009 to 2018. Comput. Ind. Eng. 2019, 138, 106120. [Google Scholar] [CrossRef]
- Nilashi, M.; Ibrahim, O.; Yadegaridehkordi, E.; Samad, S.; Akbari, E.; Alizadeh, A. Travelers decision making using online review in social network sites: A case on Trip Advisor. J. Comput. Sci. 2019, 28, 168–179. [Google Scholar] [CrossRef]
- Jia, S.S. Motivation and satisfaction of Chinese and U.S. tourists in restaurants: A cross-cultural text mining of online reviews. Tour. Manag. 2020, 78, 104071. [Google Scholar] [CrossRef]
- Lenzi, A.; Maranghi, M.; Stilo, G.; Velardi, P. The social phenotype: Extracting a patient-centered perspective of diabetes from health-related blogs. Artif. Intell. Med. 2019, 101, 101727. [Google Scholar] [CrossRef]
- Zhou, J.; Zuo, M.; Ye, C. Understanding the factors influencing health professionals’ online voluntary behaviors: Evidence from YiXinli, a Chinese online health community for mental health. Int. J. Med. Inform. 2019, 130, 103939. [Google Scholar] [CrossRef]
- Introne, J.; Goggins, S. Advice reification, learning and emergent collective intelligence in online health support communities. Comput. Hum. Behav. 2019, 99, 205–218. [Google Scholar] [CrossRef]
- Zhang, Y.; Ibaraki, M.; Schwartz, F.W. Disease surveillance using online news: Dengue and zika in tropical countries. J. Biomed. Inform. 2020, 102, 103374. [Google Scholar] [CrossRef] [PubMed]
- Park, A.; Conway, M.; Chen, A.T. Examining thematic similarity, difference and membership in three online mental health communities from reddit: A text mining and visualization approach. Comput. Hum. Behav. 2018, 78, 98–112. [Google Scholar] [CrossRef] [PubMed]
- Smedley, R.M.; Coulson, N.S. A thematic analysis of messages posted by moderators within health-related asynchronous online support forums. Patient Educ. Couns. 2017, 9, 1688–1693. [Google Scholar] [CrossRef] [PubMed]
- Hewison, A.; Atkin, K.; McCaughan, D.; Roman, E.; Smith, A.; Smith, G.; Howell, D. Experiences of living with chronic myeloid leukemia and adhering to tyrosine kinase inhibitors: A thematic synthesis of qualitative studies. Int. J. Nurs. Sci. 2020, 6, 50–57. [Google Scholar]
- Nuntaboot, K.; Boonsawasdgulchai, P.; Bubpa, N. Roles of mutual help of local community networks in community health activities: Improvement for the quality of life of older people in Thailand. Int. J. Nurs. Sci. 2019, 6, 266–271. [Google Scholar] [CrossRef]
- Stoltenberg, D.; Maier, D.; Waldherr, A. Community detection in civil society online networks: Theoretical guide and empirical assessment. Soc. Netw. 2019, 59, 120–133. [Google Scholar] [CrossRef]
- Leung, M.; Chow, C.B.; Ip, P.K.; Yip, S.F. Self-harm attempters’ perception of community services and its implication on service provision. Int. J. Nurs. Sci. 2019, 6, 50–57. [Google Scholar] [CrossRef]
- Lovell, N.; Etkind, S.N.; Bajwah, S.; Maddocks, M.; Higginson, I.J. Control and Context Are Central for People with Advanced Illness Experiencing Breathlessness: A Systematic Review and Thematic Synthesis. J. Pain Symptom Manag. 2019, 57, 140–155. [Google Scholar] [CrossRef]
- Buser, J.M.; Moyer, C.A.; Boyd, C.J.; Zulu, D.; Ngoma-Hazemba, A.; Mtenje, J.T.; Jones, A.D.; Lori, J.R. Cultural beliefs and health-seeking practices: Rural Zambians’ views on maternal-newborn care. Midwifery 2020, 85, 102686. [Google Scholar] [CrossRef]
- Moro, A.; Joanny, G.; Moretti, C. Emerging technologies in the renewable energy sector: A comparison of expert review with a text mining software. Futures 2020, 117, 102511. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, Y.; Zhang, X. An improved association rule mining-based method for discovering abnormal operation patterns of HVAC systems. Energy Procedia 2019, 158, 2701–2706. [Google Scholar] [CrossRef]
- Ghazzawi, A.; Alharbi, B. Analysis of Customer Complaints Data using Data Mining Techniques. Procedia Comput. Sci. 2019, 163, 62–69. [Google Scholar] [CrossRef]
- Ribeiro, J.; Duarte, J.; Portela, F.; Santos, M.F. Automatically detect diagnostic patterns based on clinical notes through Text Mining. Procedia Comput. Sci. 2019, 160, 684–689. [Google Scholar] [CrossRef]
- Song, Y.T.; Wu, S. Slope One Recommendation Algorithm Based on User Clustering and Scoring Preferences. Procedia Comput. Sci. 2020, 166, 539–545. [Google Scholar] [CrossRef]
- Sangaiah, A.K.; Fakhry, A.E.; Abdel-Basset, M.; El-henawy, I. Arabic text clustering using improved clustering algorithms with dimensionality reduction. Clust. Comput. 2019, 22, 4535–4549. [Google Scholar] [CrossRef]
- Sasaki, M.; Shinnou, H. Spam Detection Using Text Clustering. In Proceedings of the International Conference on Cyberworlds, Singapore, 23–25 November 2005. [Google Scholar]
- Chen, X.; Yin, W.; Tu, P.; Zhang, H. Weighted k-means Algorithm Based Text Clustering. In Proceedings of the International Symposium on Information Engineering and Electronic Commerce, Ternopil, Ukraine, 16–17 May 2009. [Google Scholar]
- Wang, C.; Yang, G.; Papanastasiou, G.; Zhang, H.; Rodrigues, J.; Albuquerque, V. Industrial Cyber-Physical Systems-based Cloud IoT Edge for Federated Heterogeneous Distillation. IEEE Trans. Ind. Inform. 2020. [Google Scholar] [CrossRef]
- Wang, C.; Dong, S.; Zhao, X.; Papanastasiou, G.; Zhang, H.; Yang, G. Saliencygan: Deep learning semisupervised salient object detection in the fog of IoT. IEEE Trans. Ind. Inform. 2019, 16, 2667–2676. [Google Scholar] [CrossRef]
- Annamalai, S.; Udendhran, R.; Vimal, S. An Intelligent Grid Network Based on Cloud Computing Infrastructures. Nov. Pract. Trends Grid Cloud Comput. 2019, 59–73. [Google Scholar] [CrossRef]
- Annamalai, S.; Udendhran, R.; Vimal, S. Cloud-Based Predictive Maintenance and Machine Monitoring for Intelligent Manufacturing for Automobile Industry. Nov. Pract. Trends Grid Cloud Comput. 2019, 74–81. [Google Scholar] [CrossRef]
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Du, X.; Guizani, M. CorrAUC: A Malicious Bot-IoT Traffic Detection Method in IoT Network Using Machine Learning Techniques. IEEE Internet Things J. 2020, 132, 1. [Google Scholar] [CrossRef]
- Can, U.; Alatas, B. A new direction in social network analysis: Online social network analysis problems and applications. Phys. A Stat. Mech. Appl. 2019, 5351, 122372. [Google Scholar] [CrossRef]
- Rashid, J.; Shah, S.M.; Irtaza, A.; Mahmood, T.; Nisar, M.W.; Shafiq, M.; Gardezi, A. Topic Modelling technique for text Mining Over Biomedical Text Corpora Through Hybrid Inverse Documents Frequency and Fuzzy K-means Clustering. IEEE Access 2019, 7, 146070–146080. [Google Scholar] [CrossRef]
- Vargas-Calderón, V.; Camargo, J.E. Characterization of citizens using word2vec and latent topic analysis in a large set of tweets. Cities 2019, 92, 187–196. [Google Scholar] [CrossRef]
- Yang, S.; Huang, G.; Cai, B. Discovering Topic Representative terms for Short Text Clustering. IEEE Access 2019, 9, 92037–92047. [Google Scholar] [CrossRef]
- Momtazi, S. Unsupervised Latent Dirichlet Allocation for supervised question classification. Inf. Process. Manag. 2018, 54, 380–393. [Google Scholar] [CrossRef]
- Pradeepa, S.; Manjula, K.R.; Vimal, S.; Khan, M.S.; Chilamkurti, N.; Luhach, A.K. DRFS: Detecting Risk Factor of Stroke Disease from Social Media Using Machine Learning Techniques. Neural Process. Lett. 2020. [Google Scholar] [CrossRef]
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Jolfaei, A.; Yu, X. Data mining and machine learning methods for sustainable smart cities traffic classification: A survey. Sustain. Cities Soc. 2020, 60, 23. [Google Scholar] [CrossRef]
- Geetha, R.; Sivasubramanian, S.; Kaliappan, M.; Vimal, S.; Annamalai, S. Cervical Cancer Identification with Synthetic Minority Oversampling Technique and PCA Analysis using Random Forest Classifier. J. Med. Syst. 2019, 43, 286. [Google Scholar] [CrossRef]
- Ramamurthy, M.; Krishnamurthi, I.; Vimal, S.; Robinson, Y.H. Deep learning based genome analysis and NGS-RNA LL identification with a novel hybrid model. Biosystems 2020, 197, 104211. [Google Scholar] [CrossRef]
- Iweni, C.; Khan, S.; Anajemba, J.H.; Bashir, A.K.; Noor, F. Realizing an efficient IoMT-assisted Patient Diet Recommendation System through Machine Learning Model. IEEE Access 2020, 8, 28462–28474. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
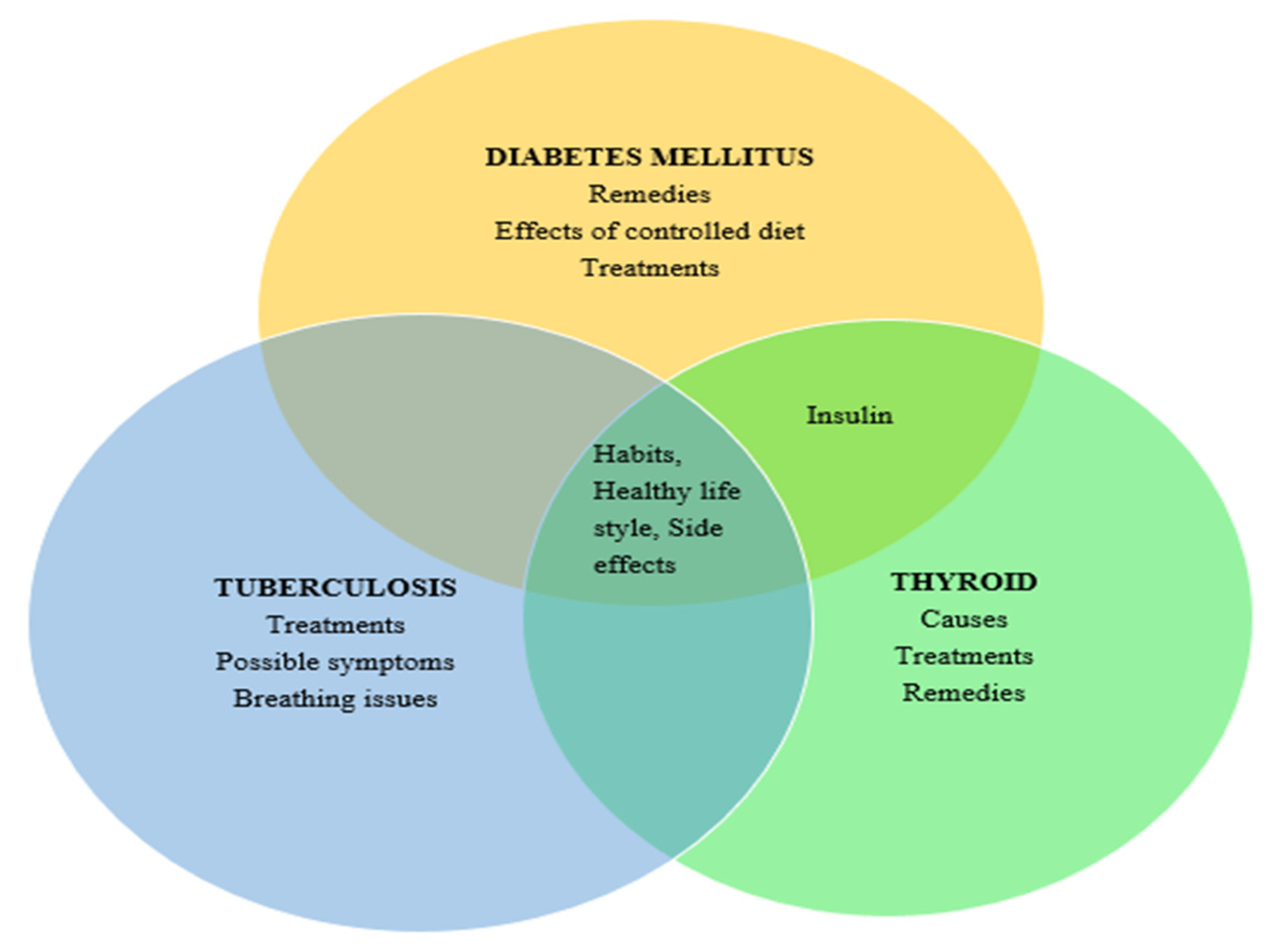
| Clusters of Thyroids | Sample Terms |
|---|---|
| Remedies | Treats ferritin level, maintain iodine level, hormone gland test, eltroxin pills |
| Side effects | Weight problems, fatigue, blood pressure, sleep apnea, iron deficiency, hair loss, heart problems, dizzy |
| Habits | Exercise, diet, healthy food |
| Treatments | Ft3, tsh, ft4 blood test, iodine free, vitamin b12, hormone balancing, treat hashimoto, ferritin level |
| Insulin | Insulin level, hypothyroid, blood sugar level, vitamin and protein level, hormone problem |
| Healthy Lifestyle | Hormone balance, exercise, sleep, steroids |
| causes | Hormone imbalance, auto-immune system disorder, hashimoto, constipation, goiter, high calcium consumption, stress |
| Clusters of DM | Sample Terms |
|---|---|
| Remedies | Hair loss Victoza, diet, control hormone, glucose test, 120–140, low carbs, avoid high carbs, healthy foods |
| Side effects | Weight problems, fatigue, blood pressure, sleep apnea, iron deficiency, hair loss, heart problems, dizzy |
| Habits | Exercise, diet, healthy food |
| Treatments | Hpa1c test, controlling blood pressure, low carbs fasting, treat auto immune system, aerobics, exercise, metformin pills |
| Insulin | Insulin level, hypothyroid, blood sugar level, vitamin and protein level, hormone problem |
| Healthy Lifestyle | Hormone balance, exercise, sleep, steroids |
| Effects of Controlled diet | Reduce heart risk, lower urine infection, maintaining insulin level, treats hypoglycemia |
| Clusters of Tuberculosis | Sample Terms |
|---|---|
| Remedies | Nexium pills, treating migraine, visit psychiatrist, ultrasound scan, yoga, inhalers |
| Side effects | Weight problems, fatigue, blood pressure, sleep apnea, iron deficiency, hair loss, heart problems, dizzy |
| Habits | Exercise, diet, healthy food |
| Treatments | Inhalers, avoid liquids, treat sleep apnea, pulmonary test, drink water, treats chronic |
| Healthy Lifestyle | Hormone balance, exercise, sleep, steroids |
| Possible symptoms | Headache, cough, breathing problem, stomach problem, fungal infections, appetite, chest pain |
| Breathing issues | Smoking, drug, cold water, cold drinks, high blood pressure, lack of sleep, weight, allergy |
| Organization/Clusters of DM Accuracy in % | Remedies | Side Effects | Habits | Treatments | Insulin | Healthy Lifestyle | Effects of Controlled Diet | Overall Accuracy in % |
|---|---|---|---|---|---|---|---|---|
| WHO | 62.5 | 50 | 100 | 42.8 | 60 | 50 | 75 | 58.9 |
| CDC | 87.5 | 100 | 100 | 85.7 | 100 | 75 | 100 | 92.3 |
| Women’s Health | 75 | 62.5 | 100 | 57.1 | 60 | 50 | 75 | 66.7 |
| NHS | 75 | 62.5 | 100 | 42.8 | 80 | 100 | 75 | 71.7 |
| NCDC | 62.5 | 50 | 100 | 57.1 | 60 | 50 | 75 | 61.5 |
| ADA | 87.5 | 100 | 100 | 85.7 | 100 | 100 | 100 | 94.8 |
| NIH | 75 | 75 | 100 | 85.7 | 80 | 75 | 100 | 82.5 |
| MedlinePlus | 50 | 37.5 | 66.6 | 57.1 | 40 | 25 | 75 | 48.7 |
| Healthline | 62.5 | 50 | 100 | 71.4 | 40 | 50 | 50 | 58.9 |
| WebMD | 50 | 50 | 66.6 | 42.8 | 60 | 50 | 75 | 48.7 |
| Organization/Clusters of Thyroid Accuracy in % | Treatments | Side Effects | Insulin | Remedies | Healthy Lifestyle | Habits | Causes | Overall Accuracy in % |
|---|---|---|---|---|---|---|---|---|
| CDC | 87.5 | 75 | 80 | 100 | 75 | 100 | 71.4 | 82 |
| Women’s Health | 62.5 | 75 | 60 | 75 | 50 | 66.7 | 57.1 | 64 |
| NHS | 75 | 75 | 60 | 75 | 50 | 66.7 | 57.1 | 66.7 |
| ATA | 100 | 100 | 80 | 100 | 75 | 100 | 85.7 | 92.3 |
| NIH | 87.5 | 87.5 | 80 | 75 | 75 | 100 | 85.7 | 84.6 |
| MedlinePlus | 100 | 25 | 60 | 100 | 75 | 66.6 | 85.7 | 71.7 |
| Healthline | 87.5 | 75 | 60 | 25 | 75 | 66.6 | 71.4 | 69.2 |
| WebMD | 50 | 37.5 | 60 | 50 | 75 | 66.6 | 42.8 | 51.3 |
| Organization/Clusters of TB Accuracy in % | Side Effects | Possible Symptoms | Habits | Treatments | Remedy | Breathing Issues | Healthy Lifestyle | Overall Accuracy in % |
|---|---|---|---|---|---|---|---|---|
| CDC | 62.5 | 57.1 | 66.7 | 83.3 | 83.3 | 75 | 50 | 69 |
| Women’s Health | 75 | 85.7 | 33.3 | 83.3 | 66.7 | 87.5 | 75 | 76.2 |
| NHS | 62.5 | 100 | 66.7 | 100 | 83.3 | 75 | 75 | 80.9 |
| ATA | 62.5 | 57.1 | 66.7 | 66.7 | 83.3 | 87.5 | 100 | 73.8 |
| NIH | 100 | 85.7 | 66.7 | 83.3 | 100 | 87.5 | 100 | 90.5 |
| MedlinePlus | 62.5 | 71.4 | 66.7 | 66.7 | 50 | 75 | 25 | 62 |
| Healthline | 62.5 | 71.4 | 66.7 | 66.7 | 66.7 | 25 | 25 | 57.1 |
| WebMD | 75 | 71.4 | 33.3 | 33.3 | 83.3 | 75 | 75 | 66.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sampath, P.; Packiriswamy, G.; Pradeep Kumar, N.; Shanmuganathan, V.; Song, O.-Y.; Tariq, U.; Nawaz, R. IoT Based Health—Related Topic Recognition from Emerging Online Health Community (Med Help) Using Machine Learning Technique. Electronics 2020, 9, 1469. https://doi.org/10.3390/electronics9091469
Sampath P, Packiriswamy G, Pradeep Kumar N, Shanmuganathan V, Song O-Y, Tariq U, Nawaz R. IoT Based Health—Related Topic Recognition from Emerging Online Health Community (Med Help) Using Machine Learning Technique. Electronics. 2020; 9(9):1469. https://doi.org/10.3390/electronics9091469
Chicago/Turabian StyleSampath, Pradeepa, Gayathiri Packiriswamy, Nishmitha Pradeep Kumar, Vimal Shanmuganathan, Oh-Young Song, Usman Tariq, and Raheel Nawaz. 2020. "IoT Based Health—Related Topic Recognition from Emerging Online Health Community (Med Help) Using Machine Learning Technique" Electronics 9, no. 9: 1469. https://doi.org/10.3390/electronics9091469
APA StyleSampath, P., Packiriswamy, G., Pradeep Kumar, N., Shanmuganathan, V., Song, O.-Y., Tariq, U., & Nawaz, R. (2020). IoT Based Health—Related Topic Recognition from Emerging Online Health Community (Med Help) Using Machine Learning Technique. Electronics, 9(9), 1469. https://doi.org/10.3390/electronics9091469