1. Introduction
Traffic congestion has been an increasing problem in the busiest urban cities. The main obstacles of traffic congestion are illegal parking, road maintenance, lane closure due to utility work, narrowing roads, accidents, and weather conditions. These incidences lead to traffic bottlenecks, which cause several adverse effects on the number of crashes, the increased cost of travelers and commuters, and fuel consumption. The traffic bottlenecks can often be located at strategic locations in a network, e.g., at off-ramps, on-ramps, and lane drop areas [
1]. Practically, there have been various useful definitions of bottlenecks proposed by several authors identifying traffic fluctuations along with connected roadway segments. A bottleneck implies the congestion evolution and queue formation, which consequently disturb travel delay and worsen the urban traffic environment and safety [
2]. In our previous work [
3], a bottleneck was defined in that the demand and supply are mismatched due to the network structure such as upstream links merging to only one downstream link in each intersection area.
Traffic management and control systems have become increasingly important for developing traffic operations’ efficiency and safety [
4]. To improve traffic management, various sources of data are available via different traffic data collection methods. A series of spot sensors such as inductive loop detectors, remote transportation microwave sensors, and video cameras can provide accurate traffic information. However, these fixed-location sensors can only incorporate the traffic state at specific locations, and these devices might include high maintenance expenditure with frequent malfunction. For urban road networks, sensors need to cover a wide range of areas, especially for bottleneck and upstream/downstream analysis. The high installation and maintenance costs of those sensors are proven to be impractical for many cities.
Compared to the traditional way of using fixed-location sensors, with further advances in technology, using vehicles equipped with Global Positioning System (GPS) sensors as probes to collect traffic data has become popular. Ubiquitous traffic data are available everywhere automatically, and this helps develop Intelligent Transportation Systems (ITSs). The emerging widespread availability of probe data significantly helps to overcome the geographic coverage and spacing restrictions of traditional loop detector data [
5]. Using such vehicles can provide real-time information on the traffic conditions along with the entire road network. These GPS-equipped vehicles can collect and output mobility data periodically, including longitude, latitude, speed, vehicle headings, and timestamps.
Traffic condition prediction is one of the primary components of ITSs, and its attention has grown in transportation research. The objective is to provide individual commuters or travelers with accurate traffic information on time. Some of the most promising predictions could improve travel time reliability with the accurate prediction for the same trips compared with the same day of adjacent weeks because time series of traffic data usually have recurrent temporal patterns. For example, similar traffic congestion happens every morning and evening rush hour. Further, this pattern is likely to occur weekly, monthly, and yearly.
This research aims at identifying bottleneck at each intersection and predicting urban network gridlocks. To summarize, the primary contributions of this paper are listed as follows:
This paper proposes a bottleneck definition in an urban traffic network according to the congestion state of each intersection;
This paper proposes a gridlock definition in the urban traffic network according to the bottleneck states at each intersection in the gridlock-looped intersections;
The difference from the previous work [
3] is in trying to use GPS vehicles to gain advantages over the high installation and maintenance costs of traditional detectors in practice. Concerning the difficulty of obtaining the GPS mobility data due to privacy issues, in this research, the vehicles traveling around the point of interest area in the simulated urban network are assumed as GPS vehicles. However, the critical concern with the limited coverage by GPS vehicles is to study the required minimum number of GPS vehicles while maintaining the desired precision and accuracy levels [
6]. Therefore, this work investigates 1% to 50% available GPS vehicles passing through the links in the simulated gridlock area. For the development of bottleneck and gridlock prediction, we chose the Chula-SSS (Chula-Sathorn SUMO Simulator) dataset [
7], which has already been calibrated with morning and evening cases for the Sathorn road network area, for our study;
This paper proposes gridlock prediction using temporal time series analysis based LSTM with time-lagged observations. This paper considers the lowest 1 min time-lagged observation period as a baseline to compare the prediction error values to study the effectiveness of LSTM on extended time-lagged observations.
The remainder of the paper is organized as follows.
Section 2 provides the related works.
Section 3 presents the simulation framework.
Section 4 proposes the methodology of traffic data processing, the description of bottleneck and gridlock identification, and the study of sample sizes for gridlock detection.
Section 5 presents the urban gridlock prediction based on the bottleneck with LSTM.
Section 6 discusses the experimental results. Finally, concluding remarks are presented in
Section 7.
2. Related Works
Traffic control and management are a primary issue in urban transport networks. In general, bottlenecks are identified and studied to find ways to overcome their negative effects on traffic. The traffic bottlenecks in urban road networks are more challenging to investigate than in freeways or simple arterial networks [
8]. Traffic bottlenecks in urban road networks vary with traffic demands with spatiotemporal characteristics. Other events, such as traffic signals, traffic accidents, roadworks, and severe weather conditions, are required to consider more of their impacts on urban networks than in freeways.
When a bottleneck happens, there is a notable difference between traffic speed in the bottleneck area and its nearby downstream links. Oversaturation is usually caused by vehicle queues first occurring at some bottleneck intersections (i.e., critical intersections) and then propagating to neighboring upstream and downstream links between intersections. In [
9], to identify oversaturated intersections, the authors proposed residual queue length estimation using shockwave speed. The authors also presented the detection of spill-over by identifying long detector occupancy time during the green phase. In [
10], the authors proposed the identification of bottlenecks in an urban area practicing on causal congestion trees and graphs with the correlations of road segments according to the congestion propagation speed. More recently, in [
11], the authors studied a traffic bottleneck identification method based on the traffic speed of loop detector data using the fusion of different collection cycles of loop detector data. To identify urban bottlenecks, in [
1], the authors proposed a congestion analysis on the bottleneck core link and its neighboring links by clustering links based on the ranks of speed.
More recently, GPS-equipped vehicles were used in the field of bottleneck identification. In [
12], the authors presented the processes of identifying and defining bottlenecks using GPS data obtained by trucks. In [
13], the authors explored and identified bottlenecks in urban areas based on recurrent low-speed segments in the road network using GPS data. In [
14,
15], the authors used a spatiotemporal variation of speed to identify and classify bottlenecks using GPS data and crowdsourced traffic data. In [
16], the authors tried to identify recurrent bottlenecks using spatial and temporal concepts on probe-reported speed data. In [
17], the authors proposed a bottleneck identification method on urban expressways based on the traffic speed variance between the bottleneck area and its neighboring downstream links by analyzing the floating car data. In [
18], the authors investigated traffic state and identified traffic bottlenecks on urban expressways using the fusion data accessible from fixed detectors and mobile navigation application data.
Future traffic condition prediction is a general concept [
19]. In [
20], the authors proposed the characterization of the traffic predictor to analyze vehicular traffic behavior for the different road segments using SUMO. In recent years, as deep learning techniques have advanced rapidly, researchers have started to adopt deep neural networks for high-accuracy traffic prediction. The Recurrent Neural Network (RNN) is widely known as a proper method to recognize the spatiotemporal evolution of traffic flow. In [
21], the authors proposed a deep learning architecture based on the Recurrent Neural Network and Restricted Boltzmann Machine (RNN-RBM) to predict the spatiotemporal congestion evolution pattern using GPS data. In [
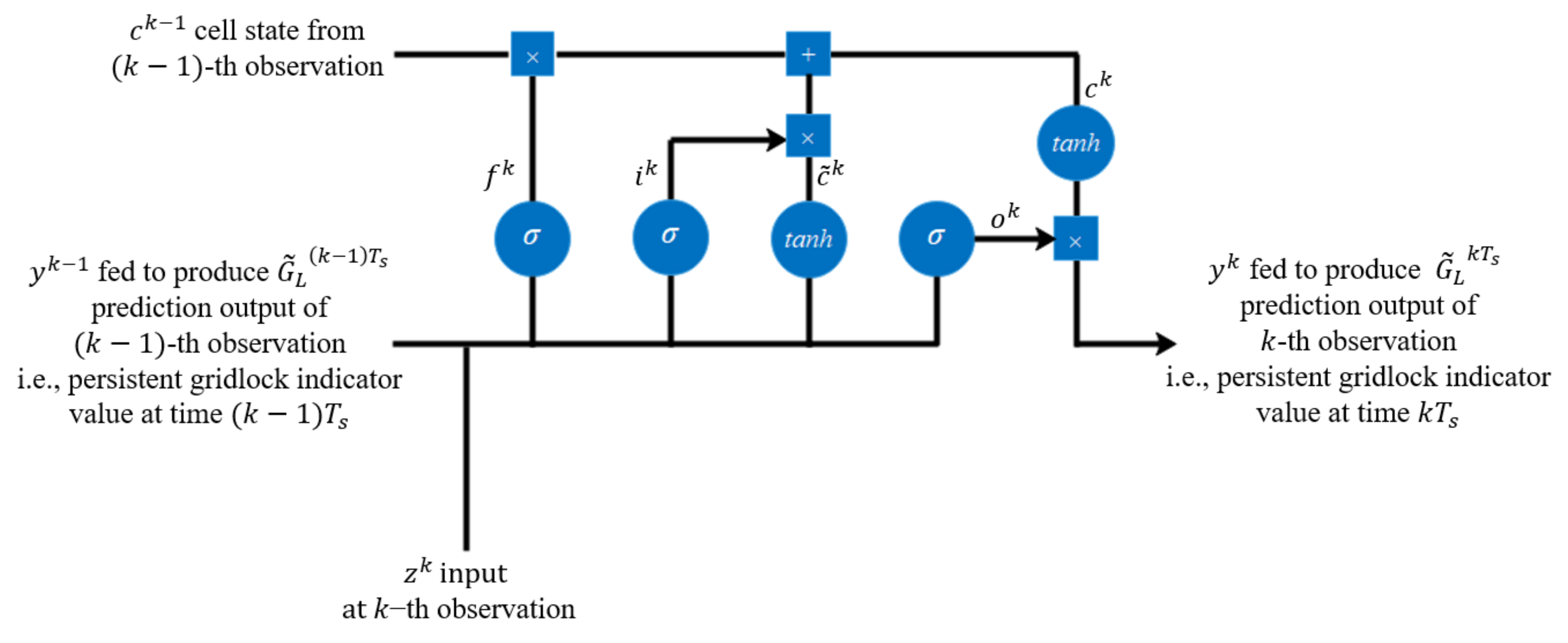
22], the authors used an error-feedback Recurrent Convolutional Neural Network structure (eRCNN) for continuous traffic speed prediction. However, the traditional RNN fails to capture the long-term evolution. To resolve the vanishing gradient problem in RNN, a Long Short-Term Memory (LSTM) network was proposed in [
23]. LSTM is well suited to classify, process, and predict time series given time lags of unknown duration. In [
24], the authors proposed a novel short-term traffic volume prediction model using LSTM. More recently, in [
25], the authors proposed a multiple time step short-term traffic prediction architecture using the RNN framework based on LSTM.
As mentioned above, the studies discussed identifying bottlenecks in intersections and respective upstream and downstream links in urban areas. Furthermore, LSTM has been applied in short-term traffic prediction. However, to the best of our knowledge, research on gridlock analysis has not yet been fully studied. We hope that this research will fill this gap by discussing the bottleneck and gridlock analysis based on the bottleneck at each intersection in the urban area. Congestion from the bottleneck originates traffic jams and propagates to neighboring upstream and downstream vicinities [
26]. Such a situation usually leads to gridlock, which can potentially reduce traffic efficiency to an almost halted state, especially in a complex urban road network. Gridlock is used to describe severe road traffic congestion with zero flow [
27,
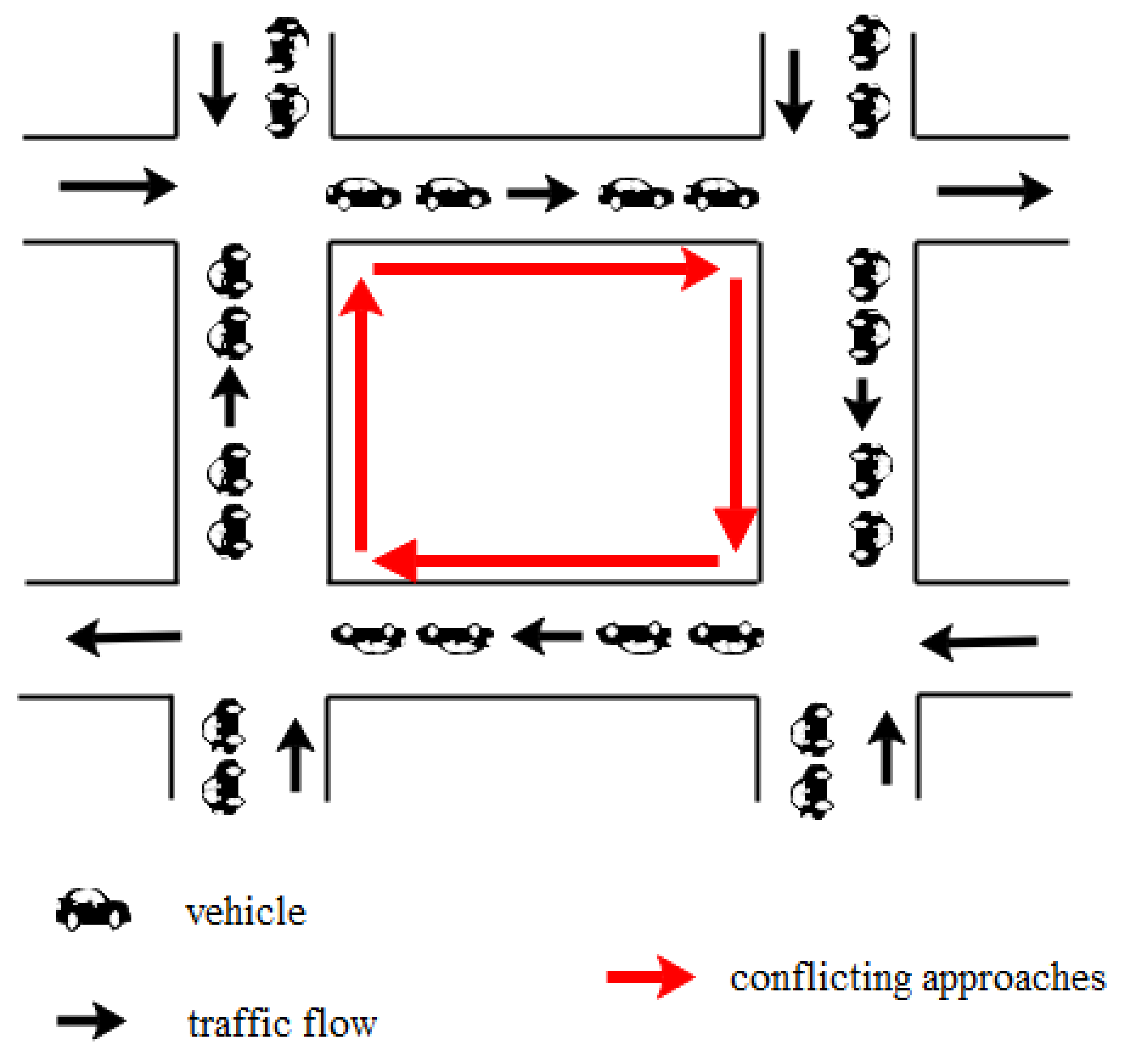
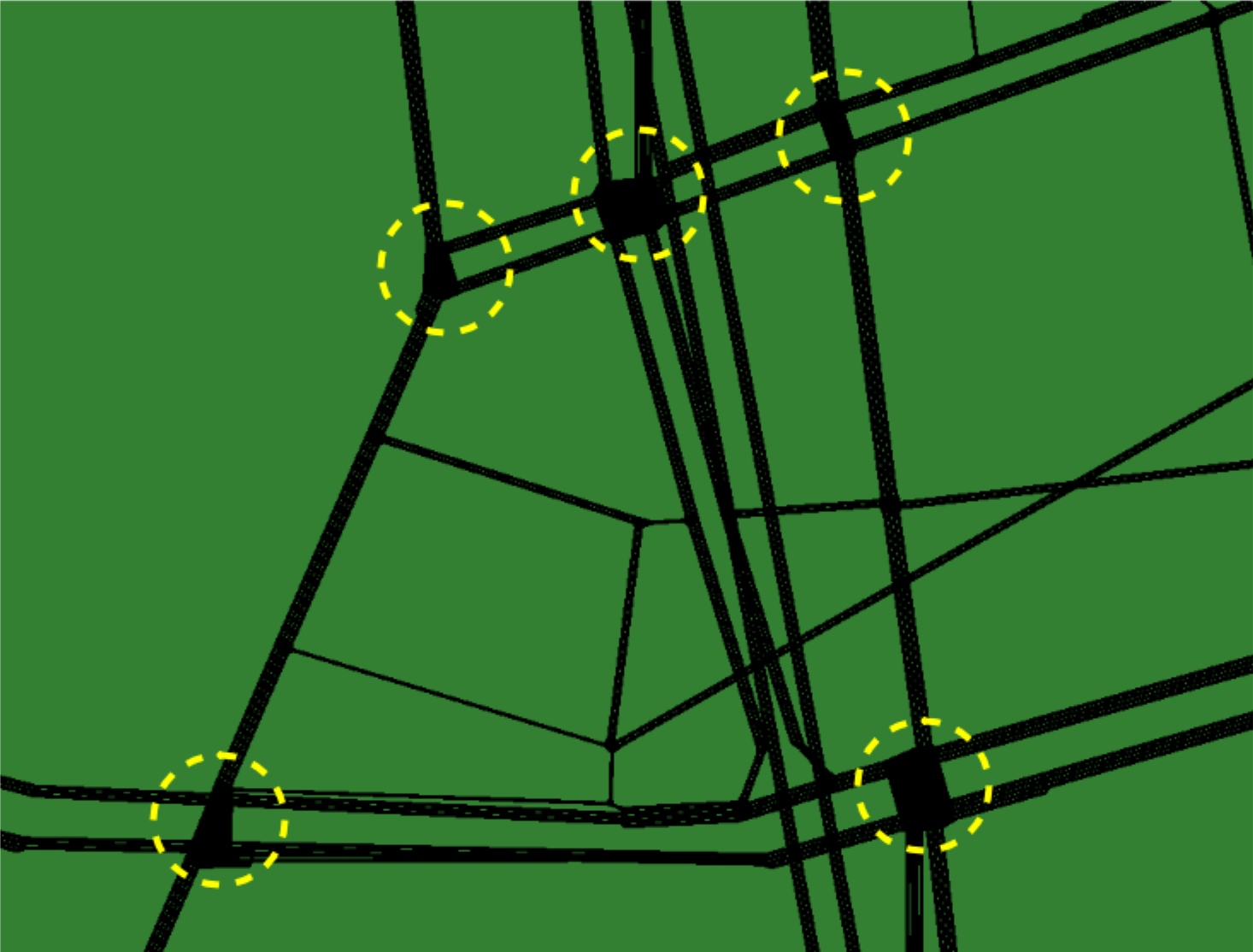
28]. Each interrelated intersection in a road network is fully occupied by slow-speed vehicles, and vehicles on conflicting approaches cannot move forward even when receiving a green traffic light, as shown in
Figure 1. In our previous work [
3], we proposed gridlock detection based on recurrent and non-recurrent congestion using the measurable gridlock characteristics in terms of traffic jam length and speed for both the upstream and downstream links of corresponding intersections. In previous work, we used simulated lane area detectors to detect gridlock, but these fixed-location detectors have some spacing limitations and installation costs in practice, as mentioned above.
3. Simulation Framework
Simulation models that can closely represent the real-world scenario are powerful and useful. In the area of road traffic simulation, three different models [
29] are used, i.e., the (1) microscopic model, (2) macroscopic model, and (3) mesoscopic model. Microscopic simulation models have been used in several transportation areas in developing ITS technologies.
In this research, the Simulation of Urban MObility (SUMO) has been used to handle large, complicated road networks at a microscopic (vehicle-level) scale. SUMO is an open-source microscopic simulator developed by the German Aerospace Centre DLR in 2001 [
30]. SUMO supports the traffic simulation community with a full-featured suite of modeling utilities, including the TraCI tool [
31]. This tool is a Python API allowing users during the simulation run-time to retrieve simulated objects’ values, e.g., in accessing the speed of simulated GPS vehicles on each link in the simulated urban network.
For traffic police and traffic engineer deployment, an educational tool [
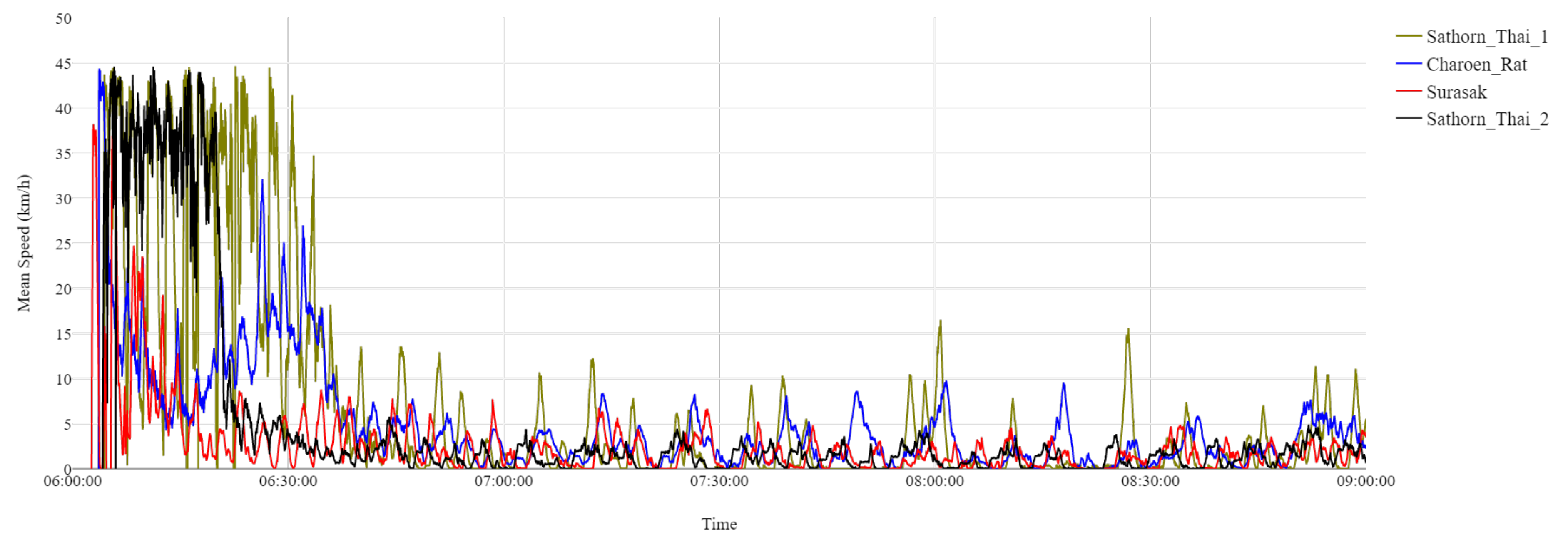
7] has been introduced by the Chulalongkorn University’s Sathorn Model project in Bangkok (Thailand), namely the Chula-Sathorn SUMO Simulator (Chula-SSS). By using this tool, traffic police can see the traffic signal phase, the queue length of vehicles in each upcoming direction at each signalized intersection, and the overall area with neighborhood road segments with user-friendly interfaces. Chula-SSS supports two calibrated datasets (morning and evening rush hours) for the Sathorn road network area. This study chose to investigate the morning case of Chula-SSS from 6 am to 9 am (corresponding to 21,600 s to 32,400 s after midnight). This time interval is the morning congestion period during weekdays [
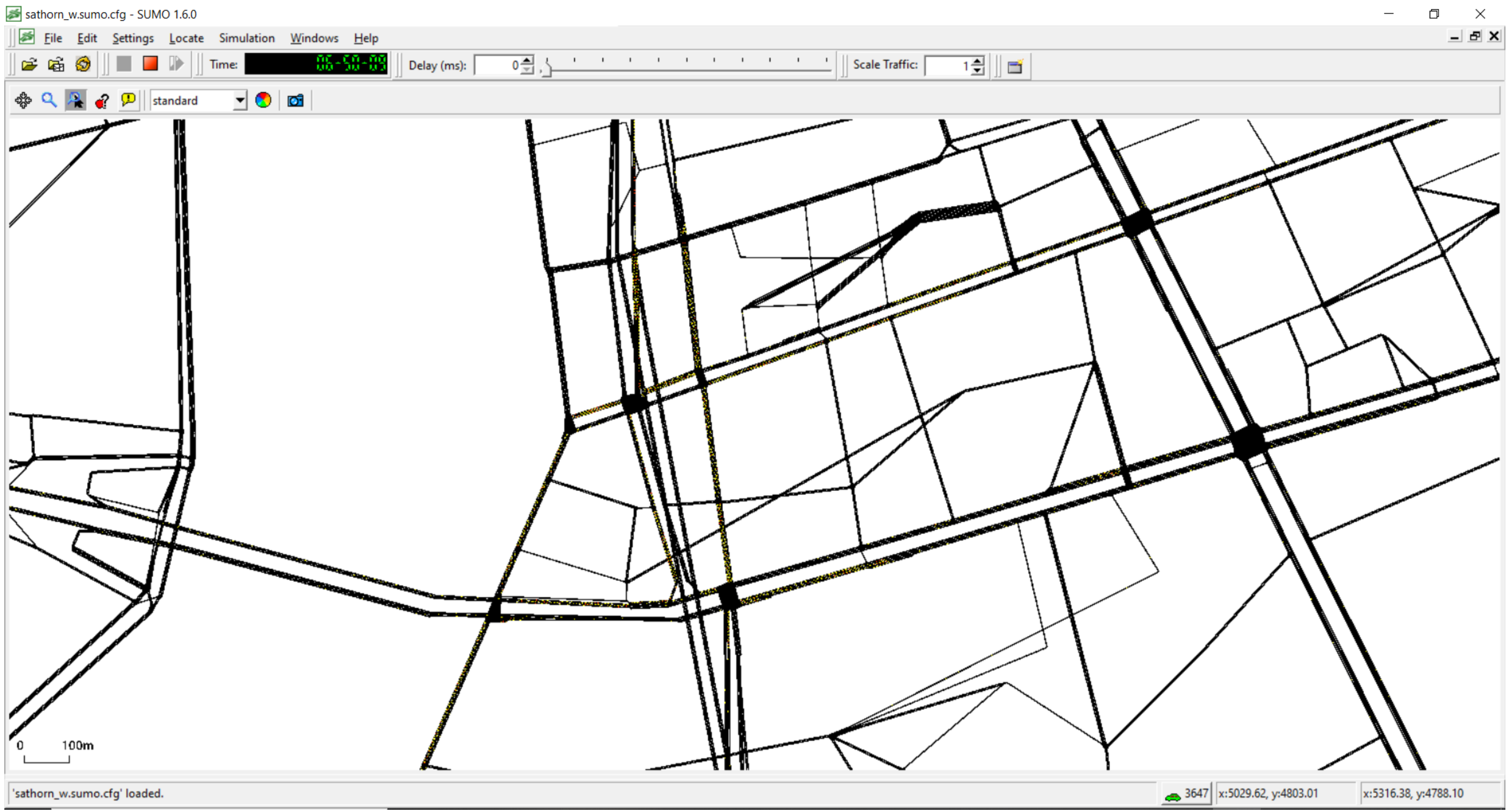
7], whereby in practice, the local traffic police have often observed the real occurrences of gridlocks in the network. The simulated Chula-SSS consists of 2375 intersection nodes, 4517 edges, and 10 signalized intersections, as shown in
Figure 2.
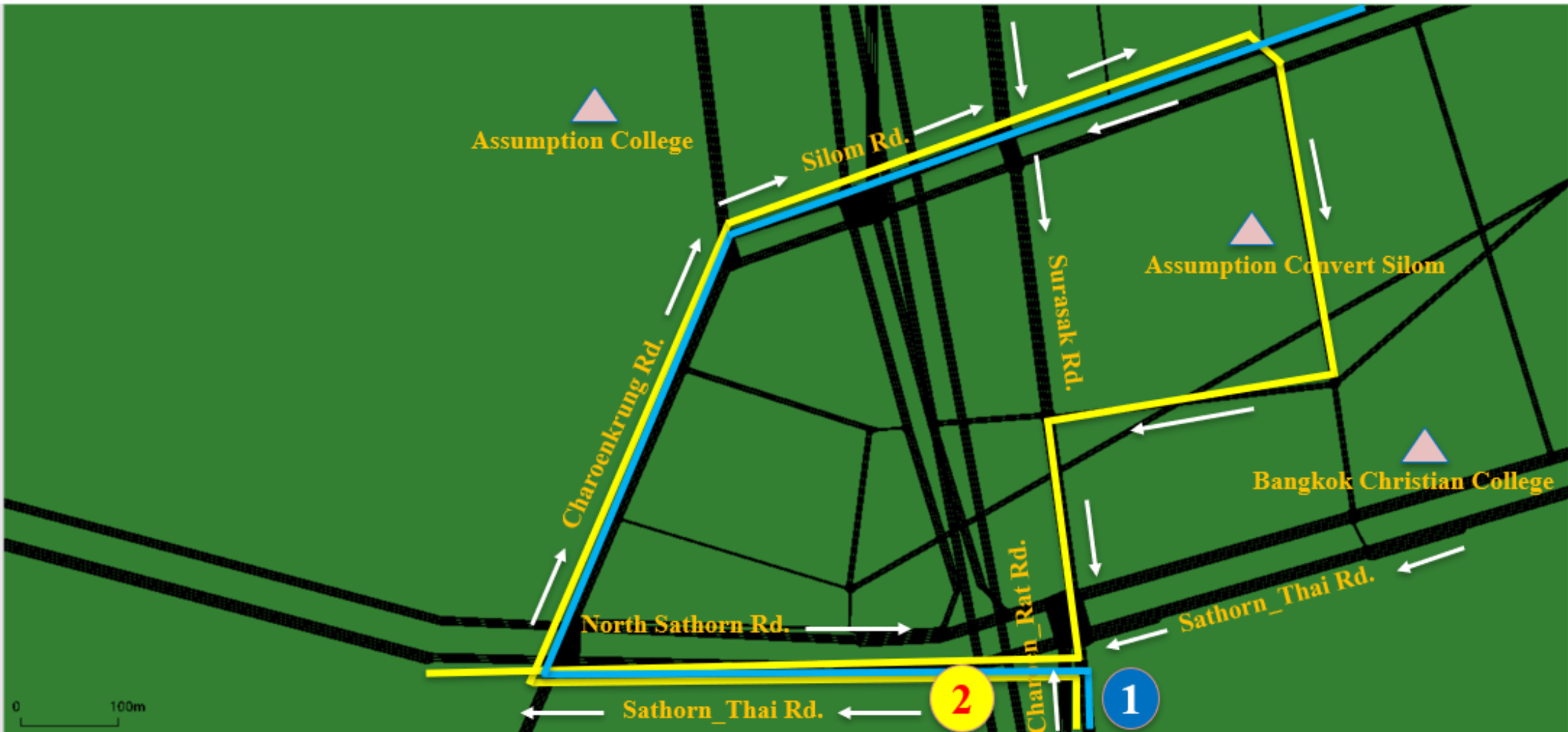
The dataset consists of 55,000 traveling vehicles in the morning or evening rush hours. Recurrent based gridlock happens on a daily basis in both morning and evening rush hours. This gridlock phenomenon has been intentionally disabled during the calibration attempt of Chula-SSS to find the optimal mobility model parameters. To exhibit the case of gridlock during morning rush hours, the previous work [
3] already included two extra routes (1 and 2) to the Sathorn critical region of Chula-SSS with traffic flows of 2125 vehicles (Route 1) and 1500 vehicles (Route 2) per hour, with their routes as shown in
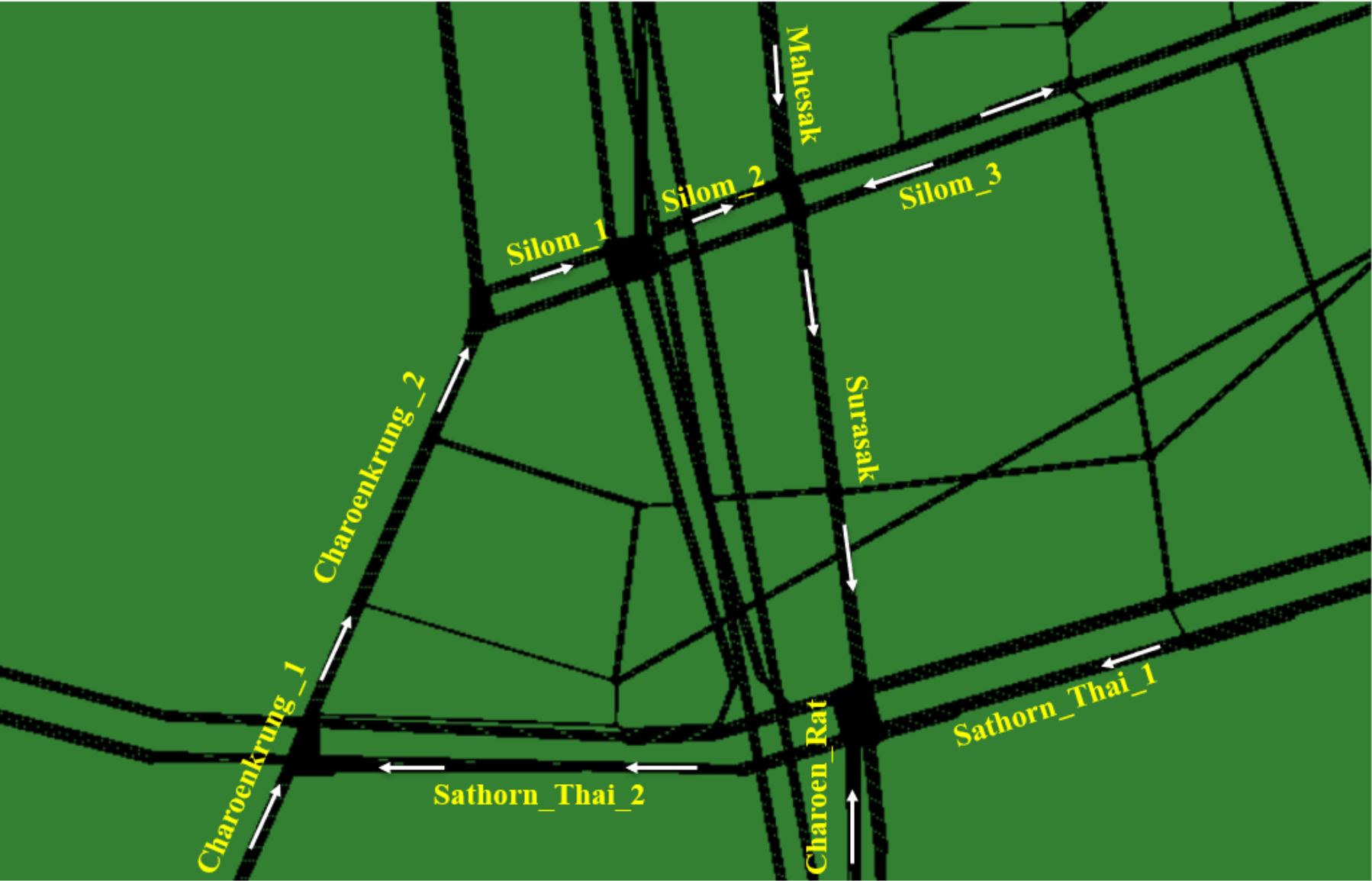
Figure 3. The Sathorn critical region is where about 12,000 out of 55,000 vehicles travel on 10 edges, as shown in
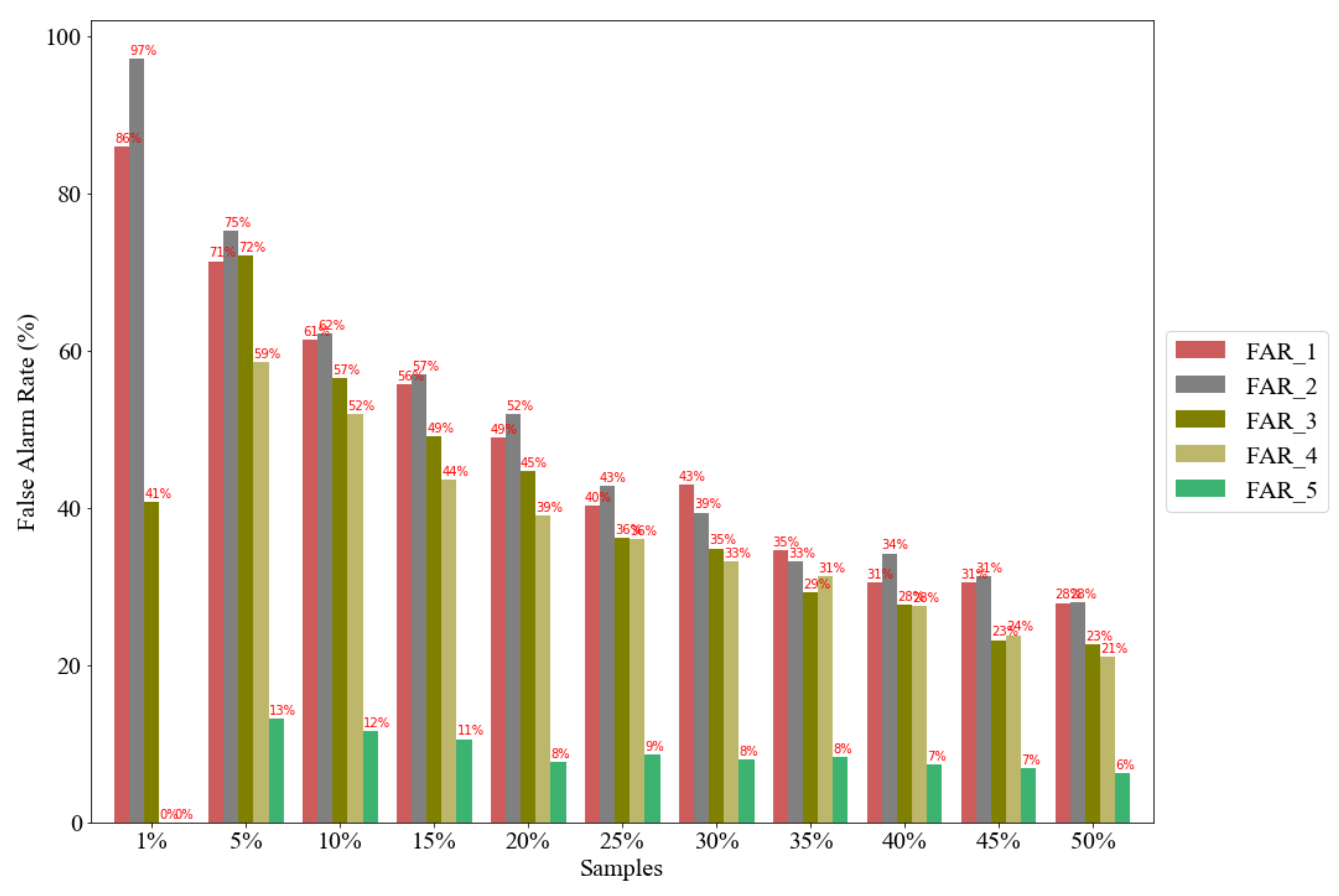
Figure 4. The GPS data collection has different time resolutions (1 s, 5 s, 10 s, 15 s, 20 s, 25 s, 30 s, 35 s, 40 s, 45 s, 50 s, 55 s, 60 s) within the simulation time interval for three hours from 6 am to 9 am. The collected vehicle data are assumed as GPS vehicles. With the limited penetration ratio of GPS vehicles, the different number of samples of GPS vehicles (1%, 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%) that passed through the links in the simulated gridlock area were investigated for the development of the identification of bottlenecks and the prediction of gridlock.
6. Evaluation of the LSTM Based Prediction Experiment on the Chula-SSS Dataset
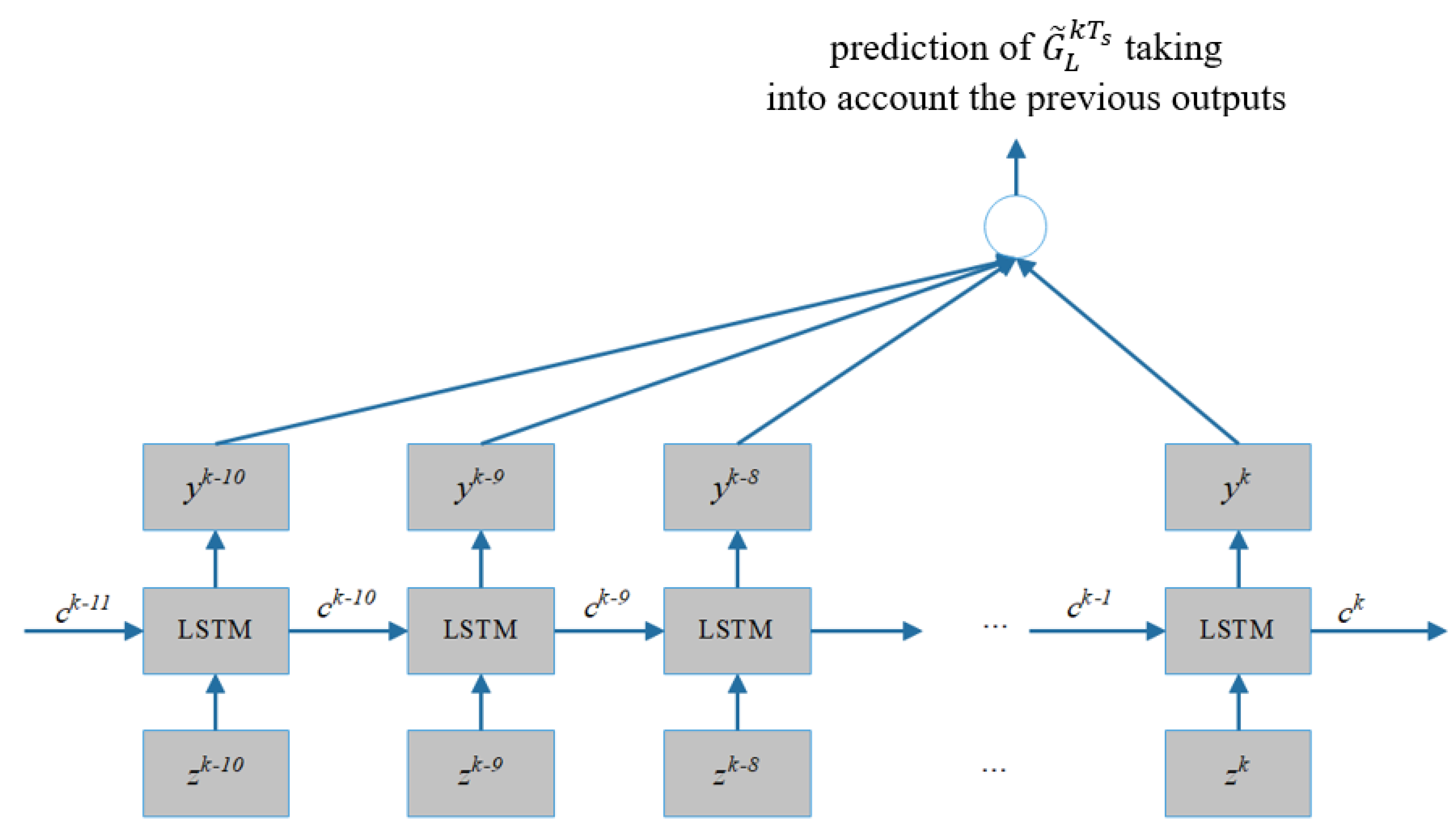
This study used a dataset that has been collected from the GPS vehicles sampled from the calibrated Chula-SSS dataset in SUMO using different random seed numbers for a total of 100 simulated days (each from 6 am to 9 am). The GPS data collection was periodically sampled every 60 s during the simulation time interval. To develop and evaluate the LSTM model, the dataset was divided into training data containing 80 simulated days and testing data containing the remaining 20 simulated days from a total of 100 simulated days. Each simulated day has 181 time steps (every 60 s within 6 am to 9 am) and 6 features by combining the 5 persistent bottleneck indicators of 5 intersections and 1 persistent gridlock indicator. The important step is to select the model hyperparameters. In this investigation, the hyperparameters of LSTM include the number of neurons to improve the network’s learning capacity, the number of epochs, and the batch size, as shown in
Table 3. The number of epochs defines the number of times that the learning algorithm will work through the all training data. The models were developed with the standard Keras library [
34]. Additionally, the standard gradient descent algorithm, ADAM [
35], was used to update the weight values given the batch size value.
To evaluate the effectiveness of the gridlock prediction model, we calculate the Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) [
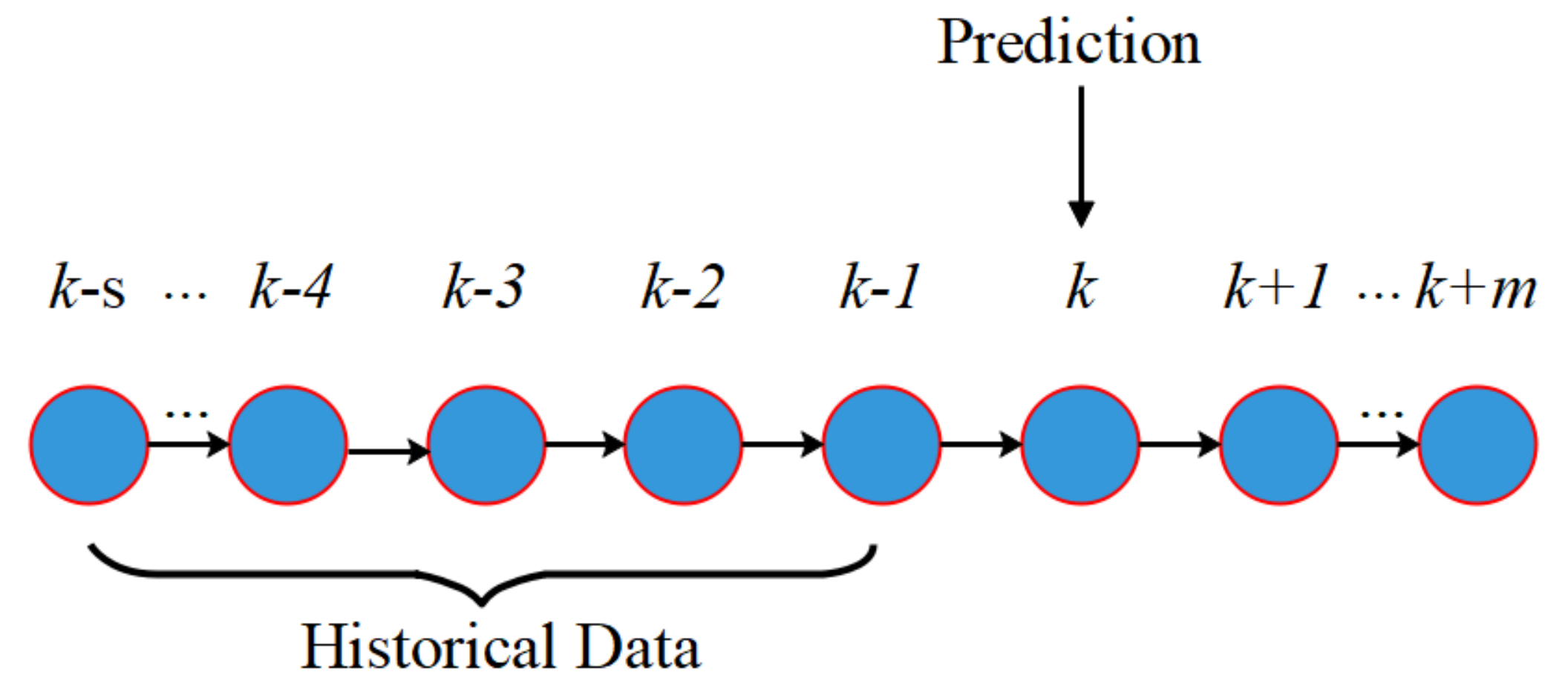
36] in estimating the time sampled values of the persistent gridlock indicator. These metrics are calculated by comparing the time series’s target values and the corresponding time series for the concatenation of all the testing data, each lasting for three hours. The proposed approach for predicting time series is applied to predict gridlock based on the bottleneck state for each intersection in the experiments with different sample sizes by varying the GPS vehicle penetration ratio in percentage and with various settings on the time-lagged observation period (
) and the time sampling interval
.
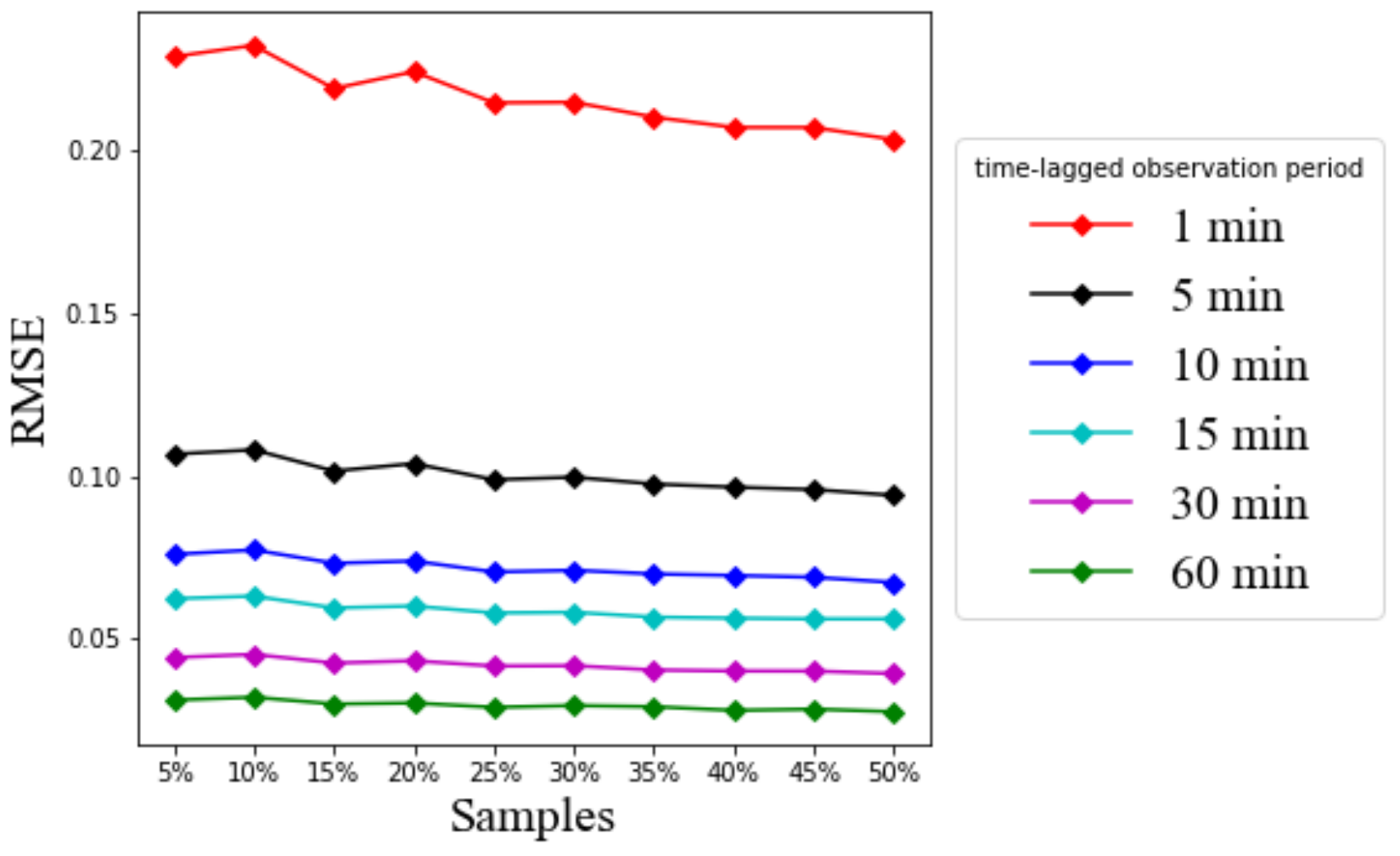
Figure 13,
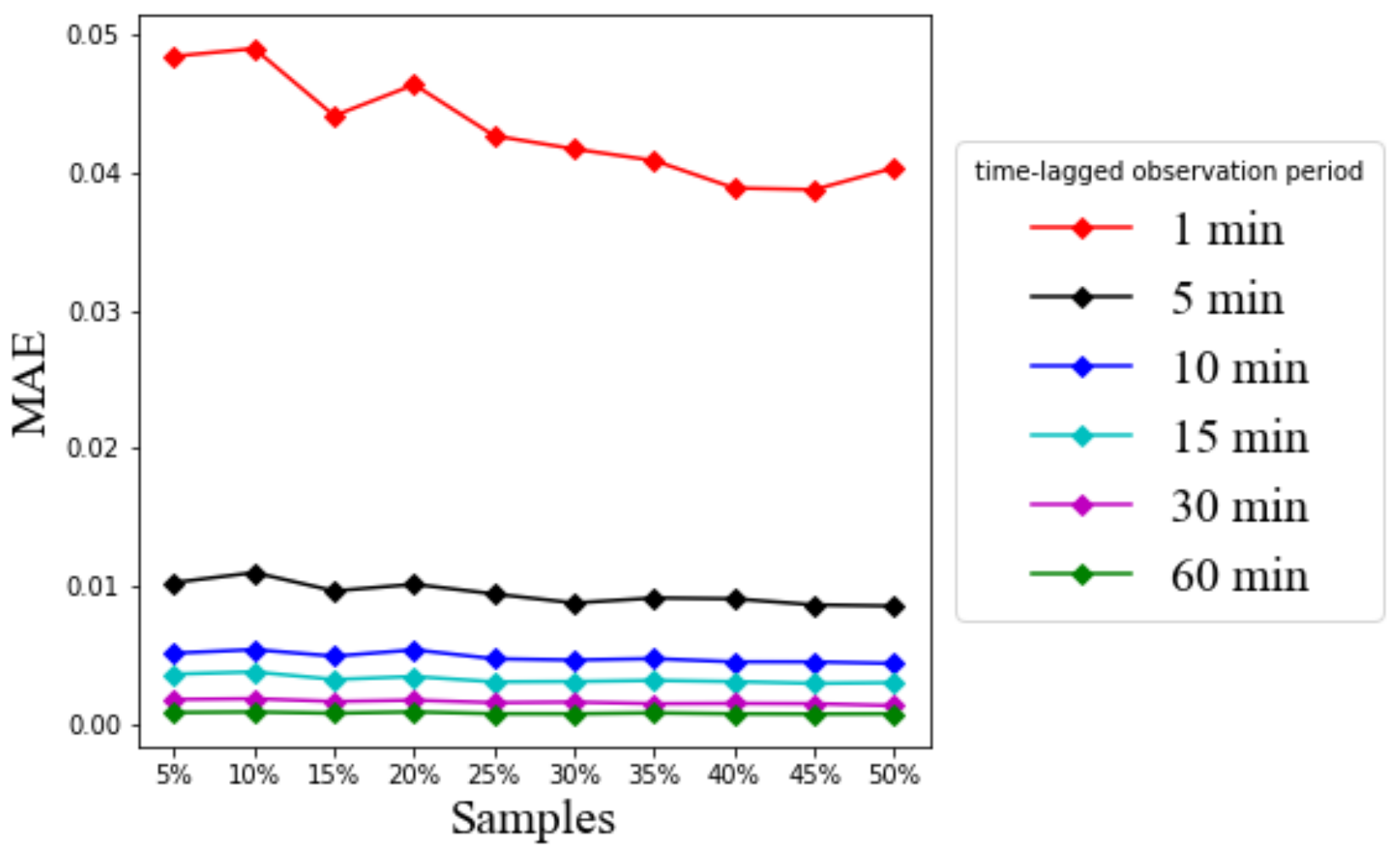
Figure 14 and
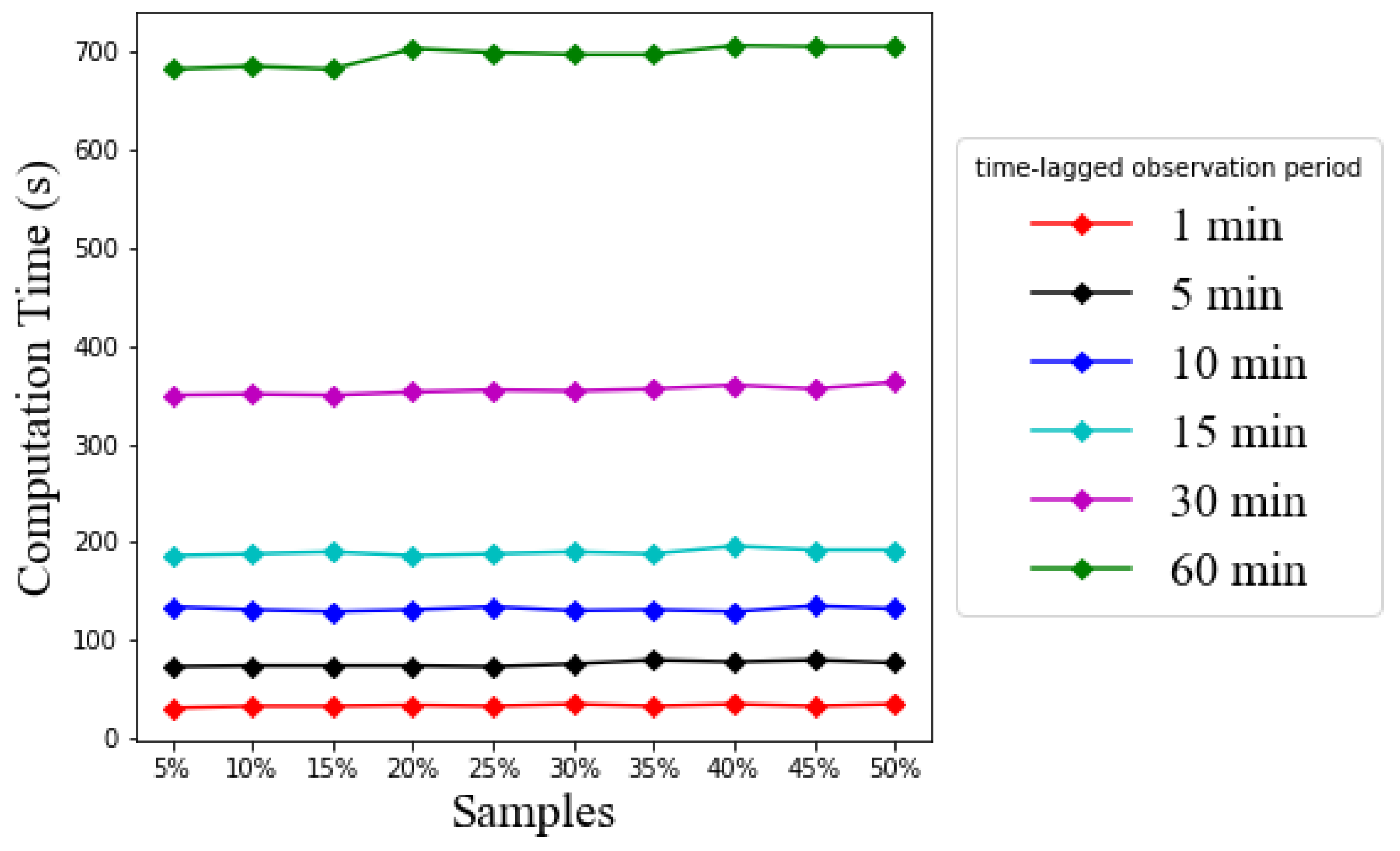
Figure 15 report the obtained results, i.e., the RMSE and the MAE, as well as the required computation time of LSTM.
6.1. Effect of Time-Lagged Observation Period
Firstly, the time-lagged observation period (
) was varied as 1, 5, 10, 15, 30, and 60 min, as shown in
Figure 13,
Figure 14 and
Figure 15. Herein, the time sampling interval (
) for every 60 s was used.
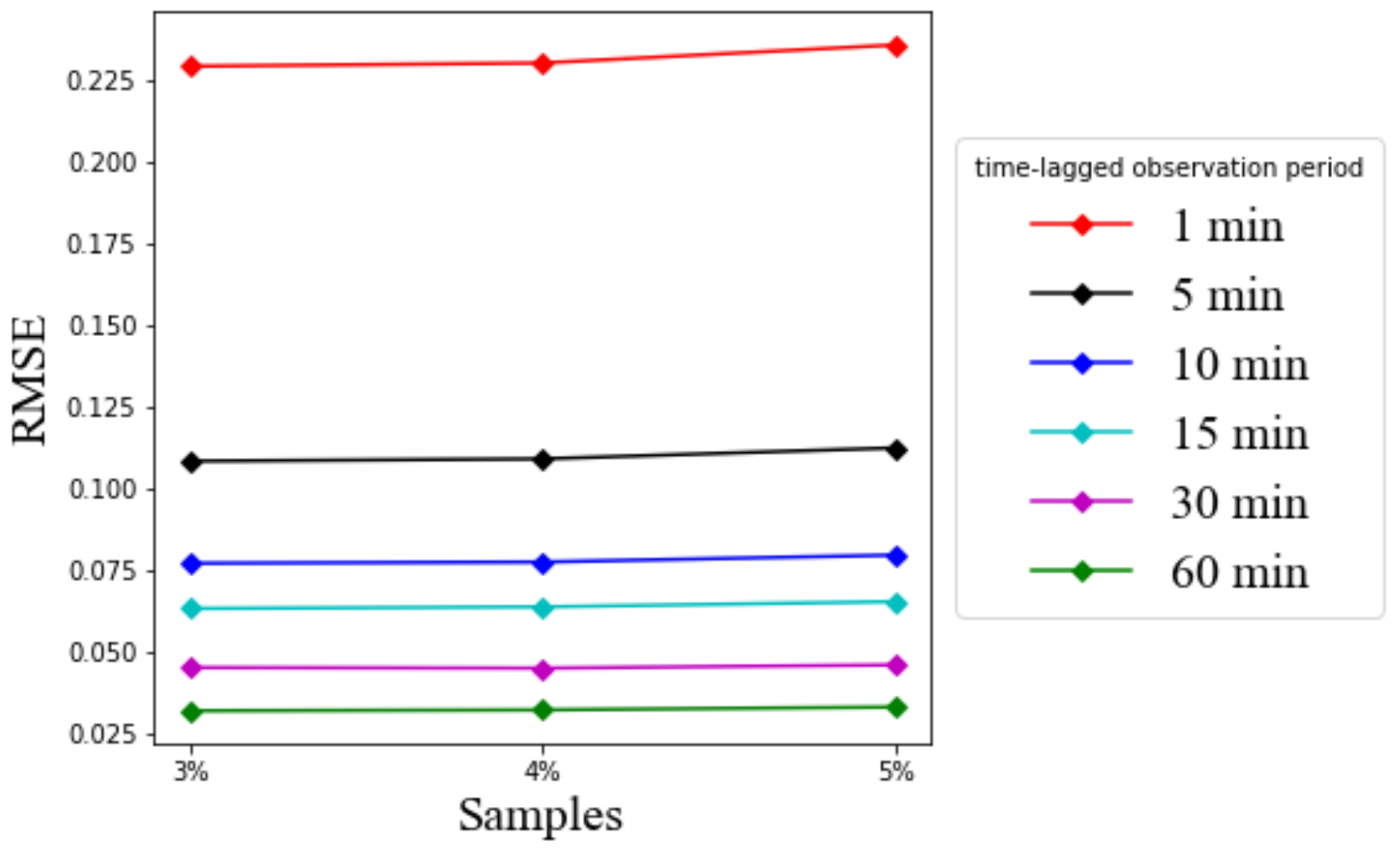
Figure 13 shows the RMSE values for different time-lagged observation periods using 10 neurons of LSTM outputs linearly combined with the final dense layer with one prediction output, 10 epochs, and a batch size of 50.
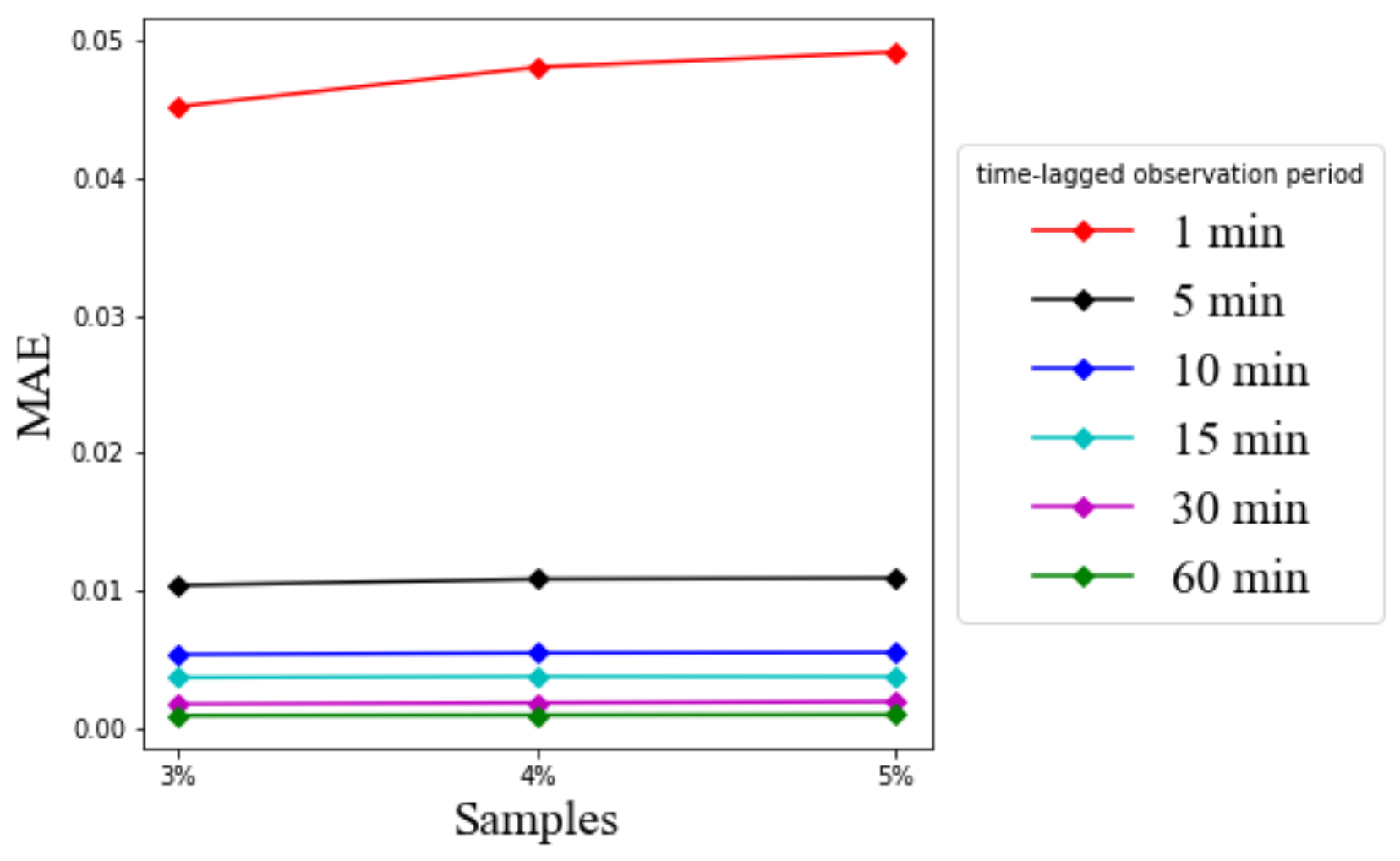
Figure 14 shows the MAE values for different time-lagged observation periods using the same parameters. These hyperparameter values were searched by brute force and finally selected to show the achieved performance of LSTM in our considered case studies. To compare the prediction error values, this study considered as a baseline the lowest 1 min time-lagged observation period, i.e., LSTM is allowed to look back into the past for only 1 min.
Figure 13 and
Figure 14 show that the RMSE and MAE eventually decrease with the increase of the past observation interval length allowable for LSTM based prediction. When the time-lagged observation is 1 min, there is a big gap between the RMSE values and the other time-lagged observations of 5 min to 60 min. It is understandable that the short historical observation interval cannot provide adequate information for accurate prediction. However, the gap of the RMSE and MAE values between 5 min and other time-lagged observation periods from 10 min to 60 min is relatively not as much as that from 1 min to 5 min.
Although a short historical observation interval does not generally provide accurate prediction,
Figure 13 and
Figure 14 suggest that the RMSE and MAE values are still acceptable even at the 1 min time-lagged observation, i.e., less than 0.25 for RMSE and 0.05 for MAE from the presumed linear scale of five. On the other hand, if LSTM has more information on the extended time-lagged observation, the RMSE value is reducible to as low as 0.02, and the MAE value is as low as 0.001 with the 60 min time-lagged observation. Therefore, the result confirms that LSTM has good performance over the whole practical range of time-lagged observations. The performance improves further when the input time-lagged observations are sufficiently long.
Although prediction accuracy is improved, if the number of time-lagged observations is increased, the computation is unavoidably increased, as shown in
Figure 15. The computation time reported here is based on the currently used hardware of NVIDIA GeForce GTX 1080 Ti with 11 GB memory. At the 60 min time-lagged observation period, it is found that the computation time is up to 700 s or almost 12 min. Such a computation time can be further reduced if the hardware capacity is upgraded. In practice, engineers can design the needed hardware so that the computation can be completed within the time sampling interval, resulting in a real-time prediction effect.
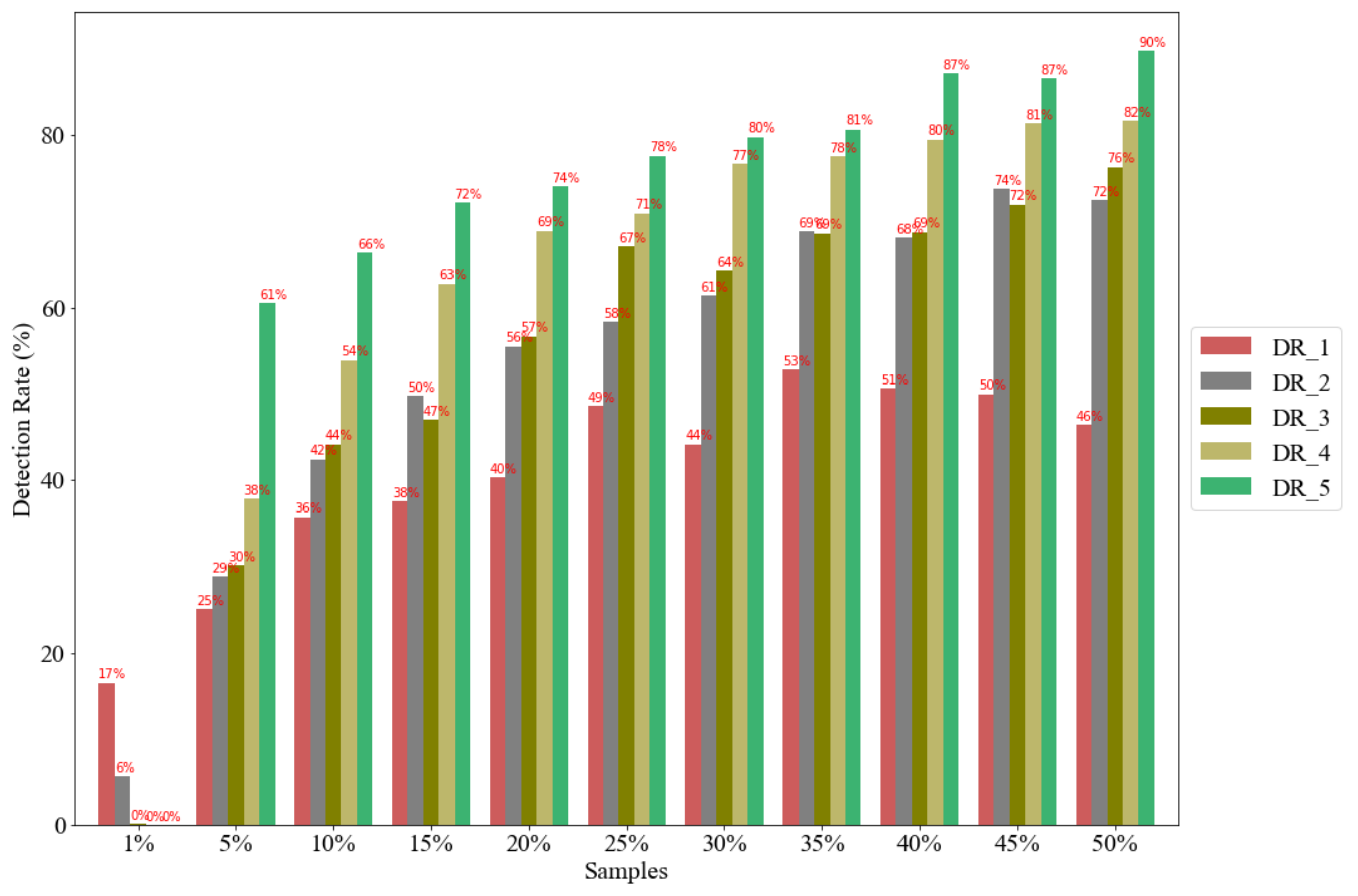
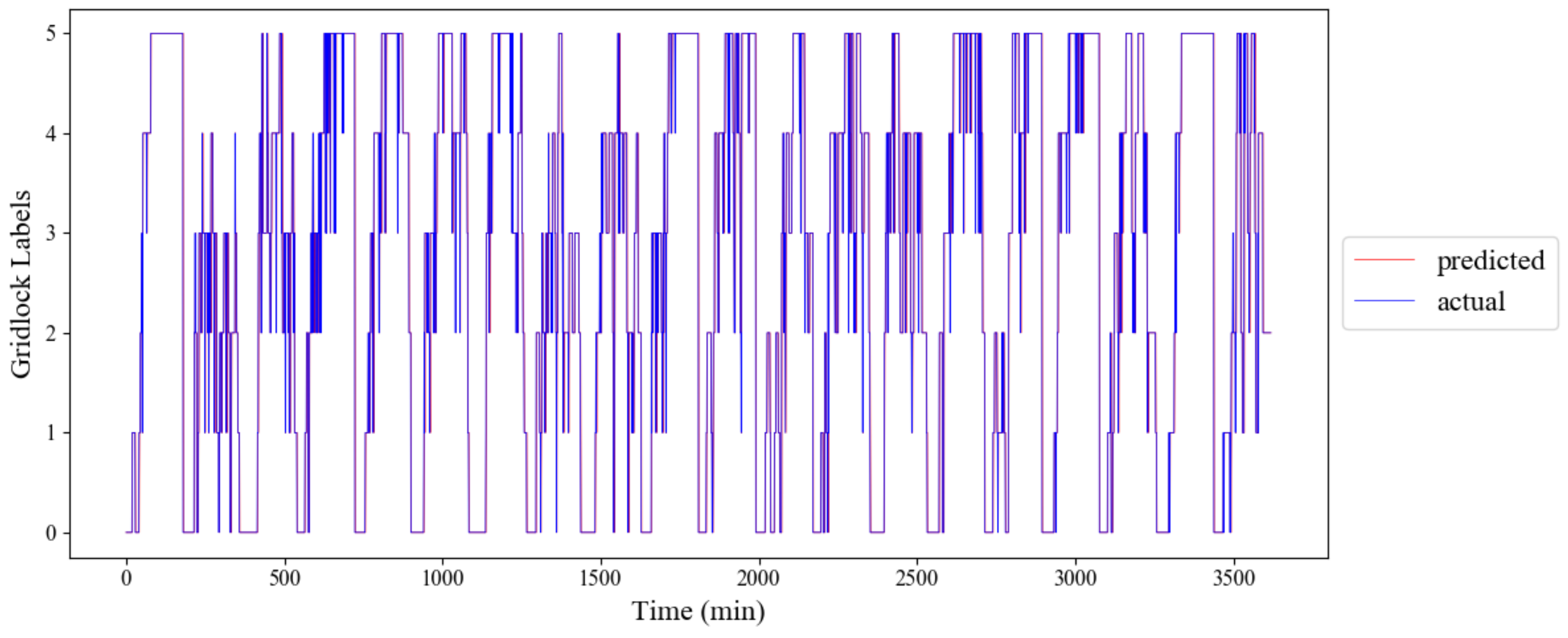
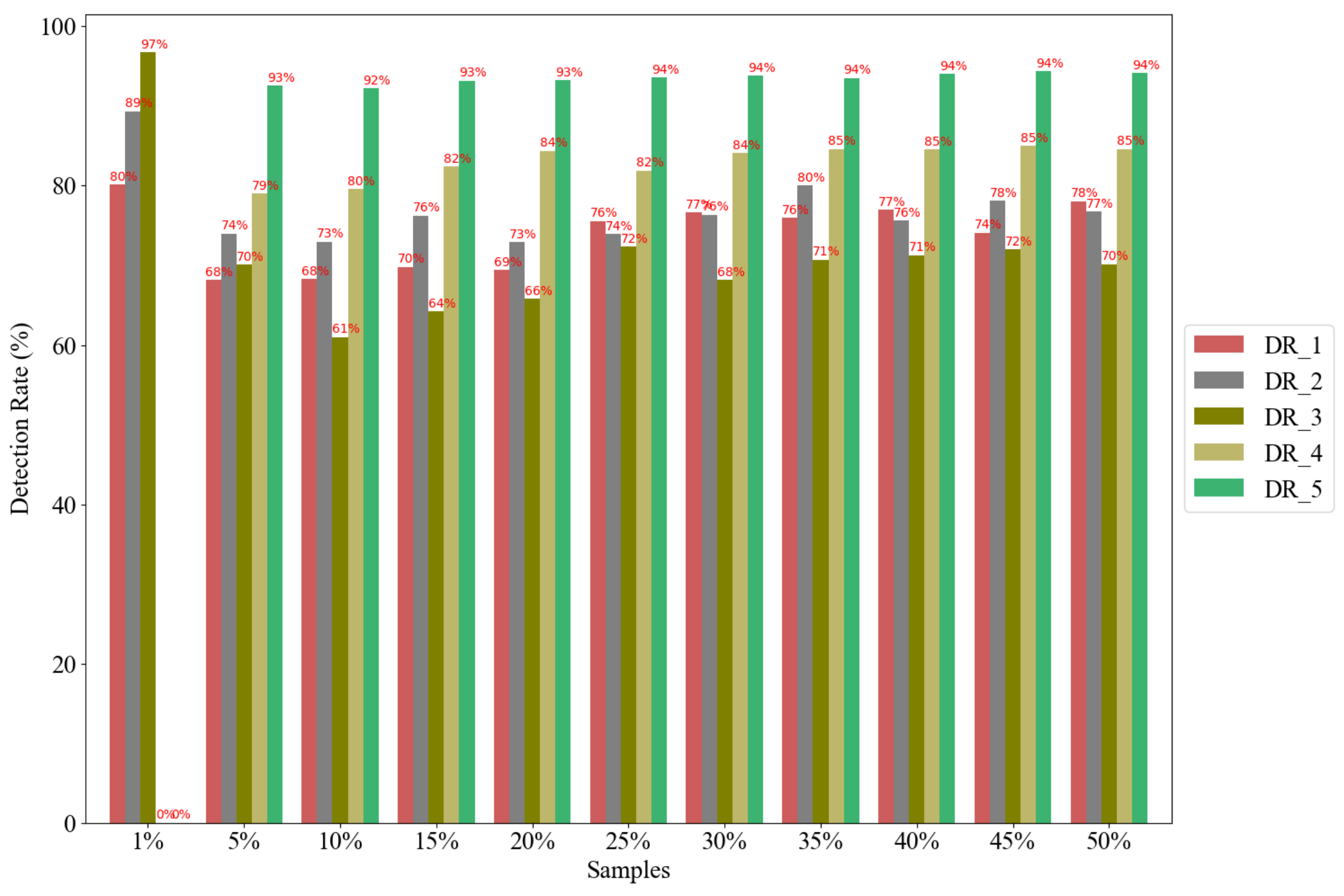
Figure 16 shows the predicted and actual gridlock labels with 1 min time-lagged observation using the 5% sample size.
Figure 17 shows the detection rate for all gridlock labels after prediction with LSTM. In
Section 4.3, this study presents the effect of sample size to detect gridlock, and the detection rate is 80% on the sample size of 30% GPS vehicles. However, after prediction with LSTM, our proposed LSTM model can predict more gridlock labels, 1, 2, and 3, as low as the 1% sample, but the 1% sample cannot predict the gridlock labels 4 and 5 using the insufficient information of the loop. In
Figure 17, the reported DR is 93% for the 5% sample size. This reported detection rate after LSTM confirms that LSTM has good performance using the time-lagged observation in the rolling forecast fashion.
In
Figure 18 and
Figure 19, the reported RMSE and MAE values are decreased to as low as 0.03 and 0.001 with the 60 min time-lagged observation using the 3% sample. Therefore, the results confirm that the required minimum sample size of 3% GPS vehicles traveling on each link of the loop is enough to predict the gridlock. Using the mean speed of this penetration ratio of GPS vehicles, in practice, can successfully and effectively detect gridlock.
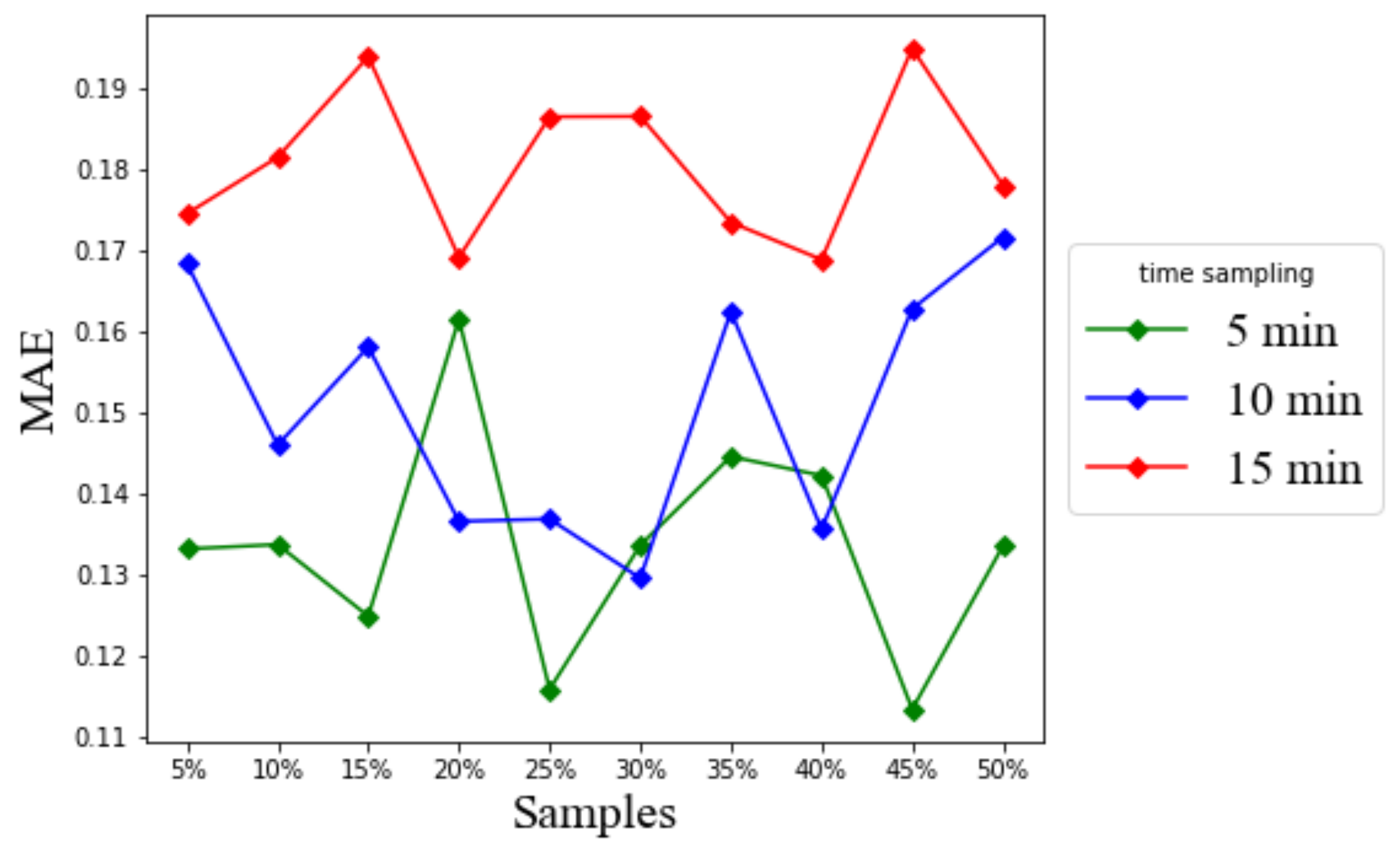
6.2. Effect of Time-Sampling
A short time sampling interval of data collection refers to a high sampling rate, while a long time sampling interval of data collection refers to a low sampling rate. The higher sampling rate of GPS vehicle trajectories gives more sampling points to form the trajectory path. However, because of the strict limits of battery storage for hand-held GPS-embedded devices carried inside moving vehicles, they are often unable to collect high sampling rate data for a long period [
37]. Therefore, the time sampling rate interval of GPS vehicle data is an important issue. To study the effect of the sampling interval in gridlock prediction, this study used the time sampling interval
of the GPS vehicle data in
Figure 20,
Figure 21 and
Figure 22 at 5, 10, and 15 min. Like in
Figure 13,
Figure 14 and
Figure 15, we selected the LSTM hyperparameter values of 10 neurons, 10 epochs, and a batch size of 50.
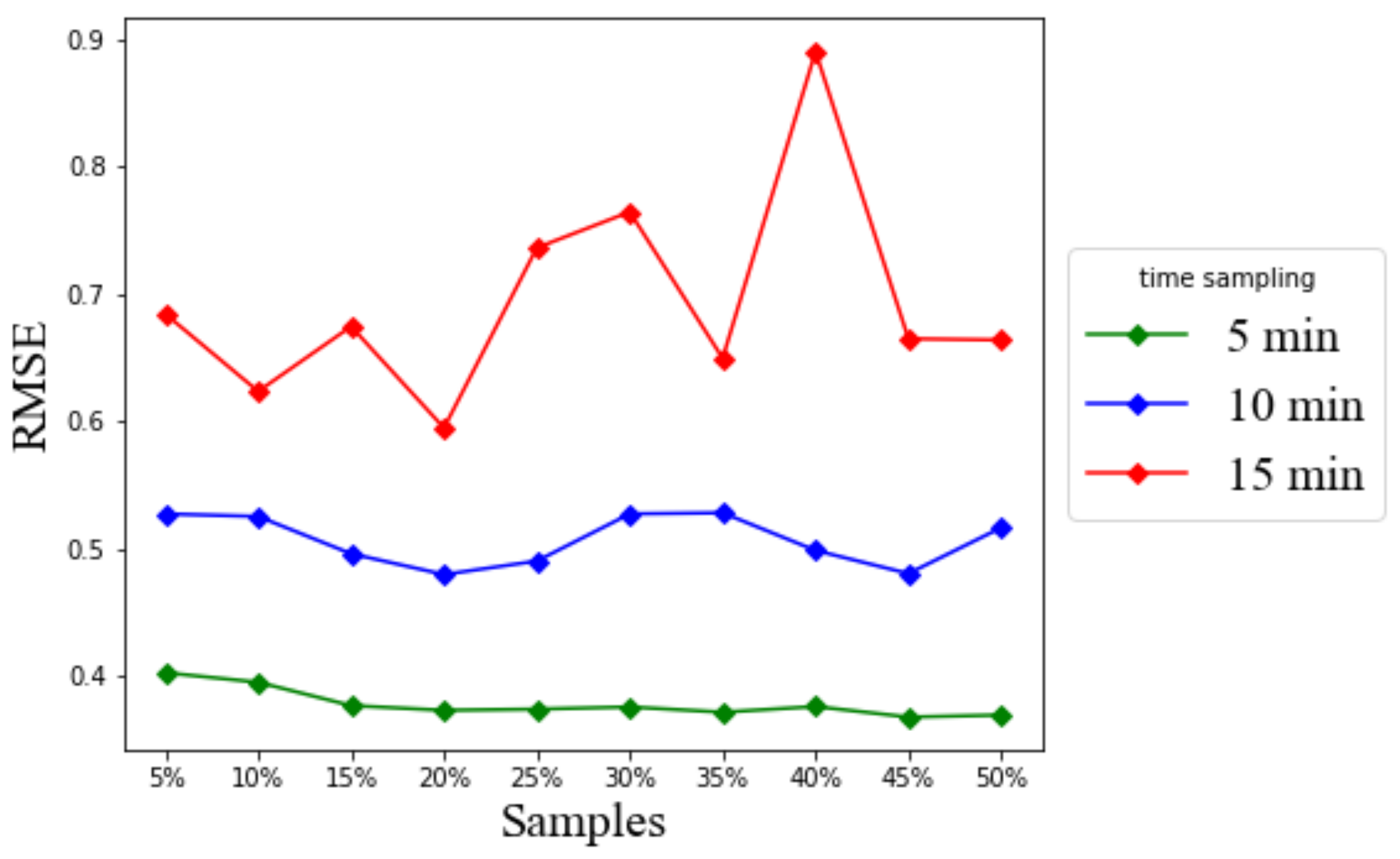
Our findings suggest that the time sampling interval directly affects the achievable accuracy of LSTM prediction for persistent gridlock indicators. In
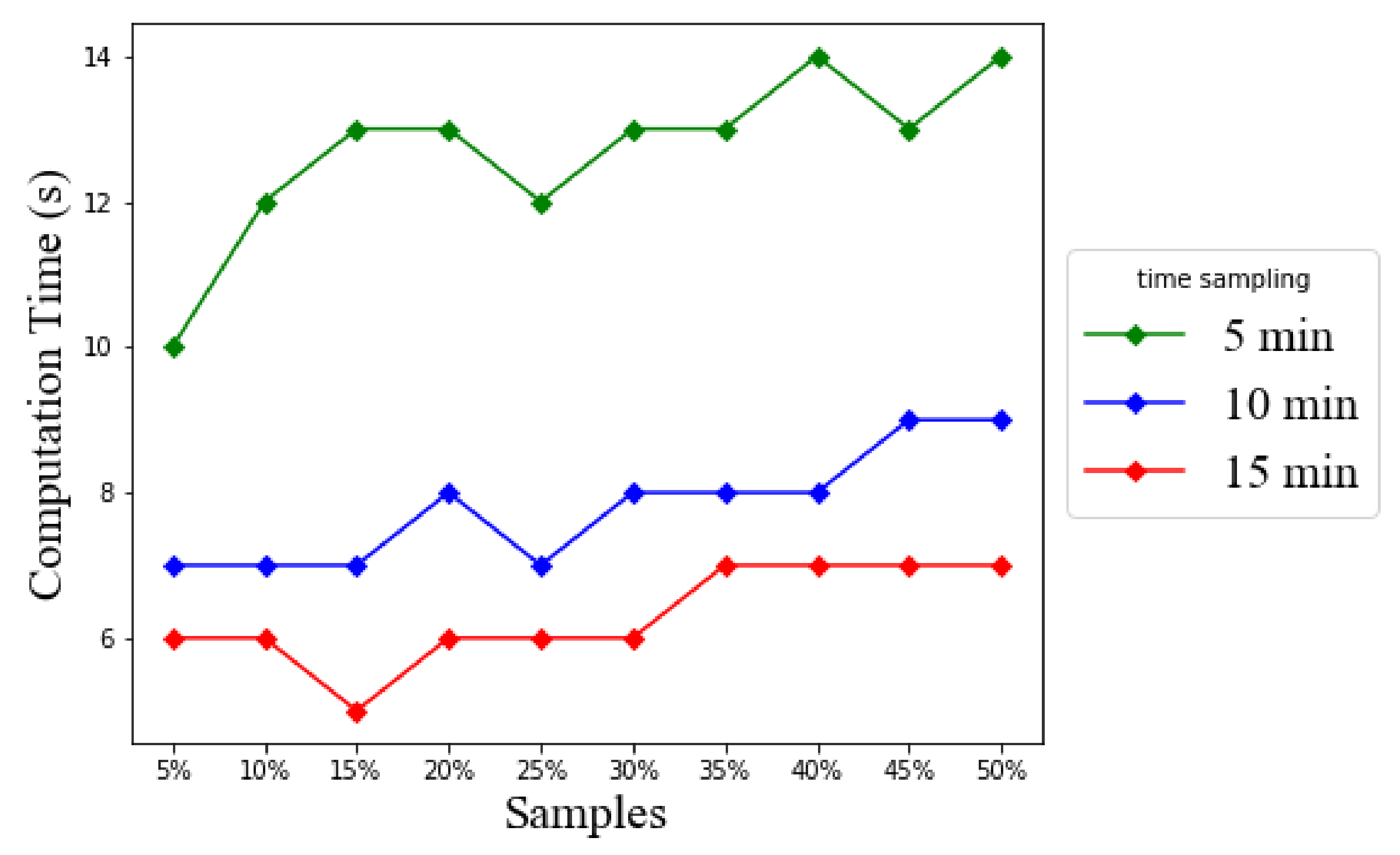
Figure 20, the reported prediction error increases as the time sampling interval increases. The prediction error obtained from the time sampling interval of 5 min is at most 0.4 for RMSE for the minimally required 5% GPS vehicle sample. However, a long time sampling interval results in a large RMSE value, for example up to 0.9 for RMSE for the 15 min time sampling. From the computation time point of view, the longer the time sampling interval, the less the computation time, as shown in
Figure 22. For example, the 15 min time sampling lasts only around 6 s or 7 s.
In practice, one can evaluate the quantized gridlock label by rounding off the predicted gridlock label value first. In this case, an RMSE less than 0.5 should be considered as acceptable. Under such practical concerns, based on
Figure 20,
Figure 21 and
Figure 22, the proposed LSTM based model can predict the gridlock label for effectively 5 min into the future and at the affordable up to 15 s computation time. That lead time of 5 min is comparable to a reasonable cycle length of adjusting traffic signal lights. Therefore, by foreseeing such gridlock occurrences by one control cycle, at least, the operational traffic signal controller can adaptively try to correct its signal interval settings to either mitigate the occurring gridlock effects or prevent the gridlock from happening in the first place.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}