Pose Recognition of 3D Human Shapes via Multi-View CNN with Ordered View Feature Fusion


Abstract
:1. Introduction
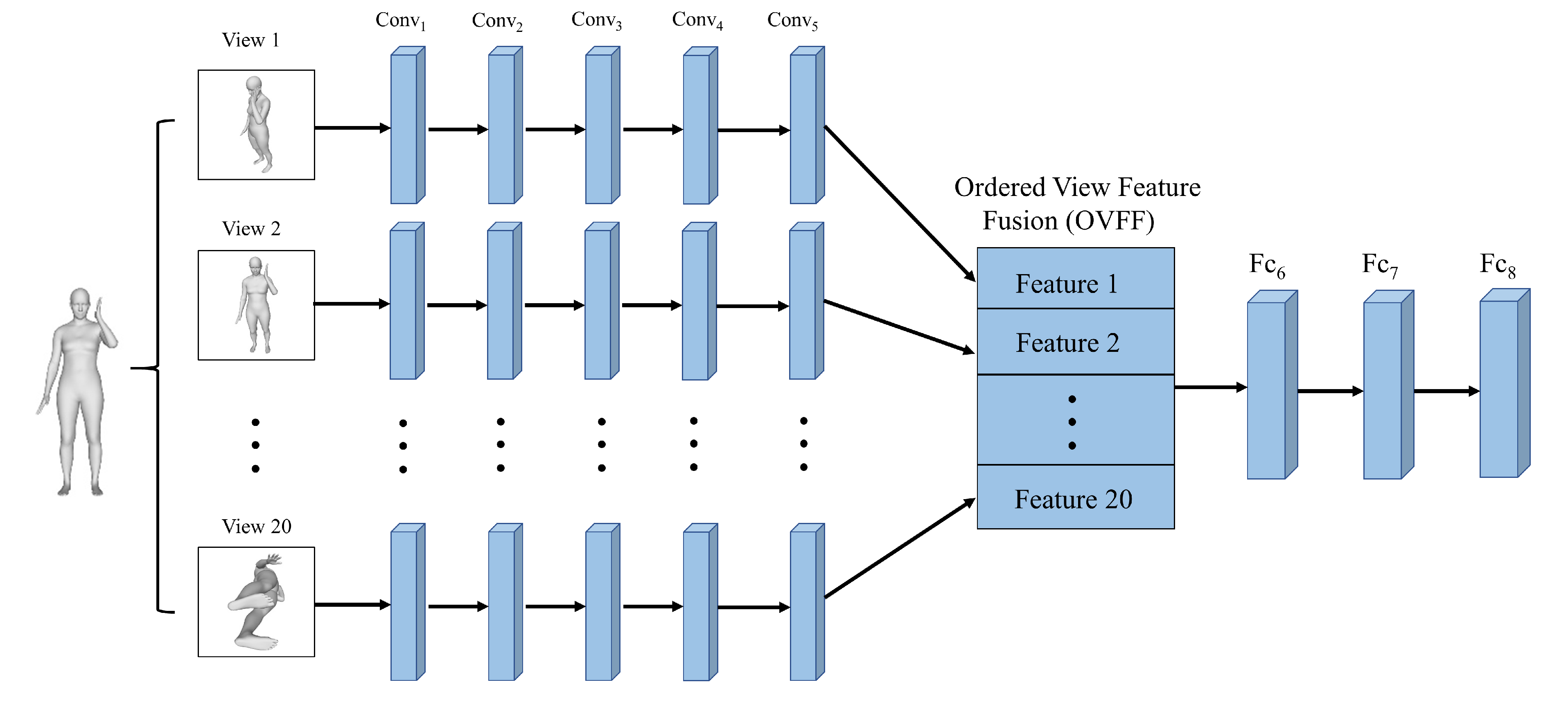
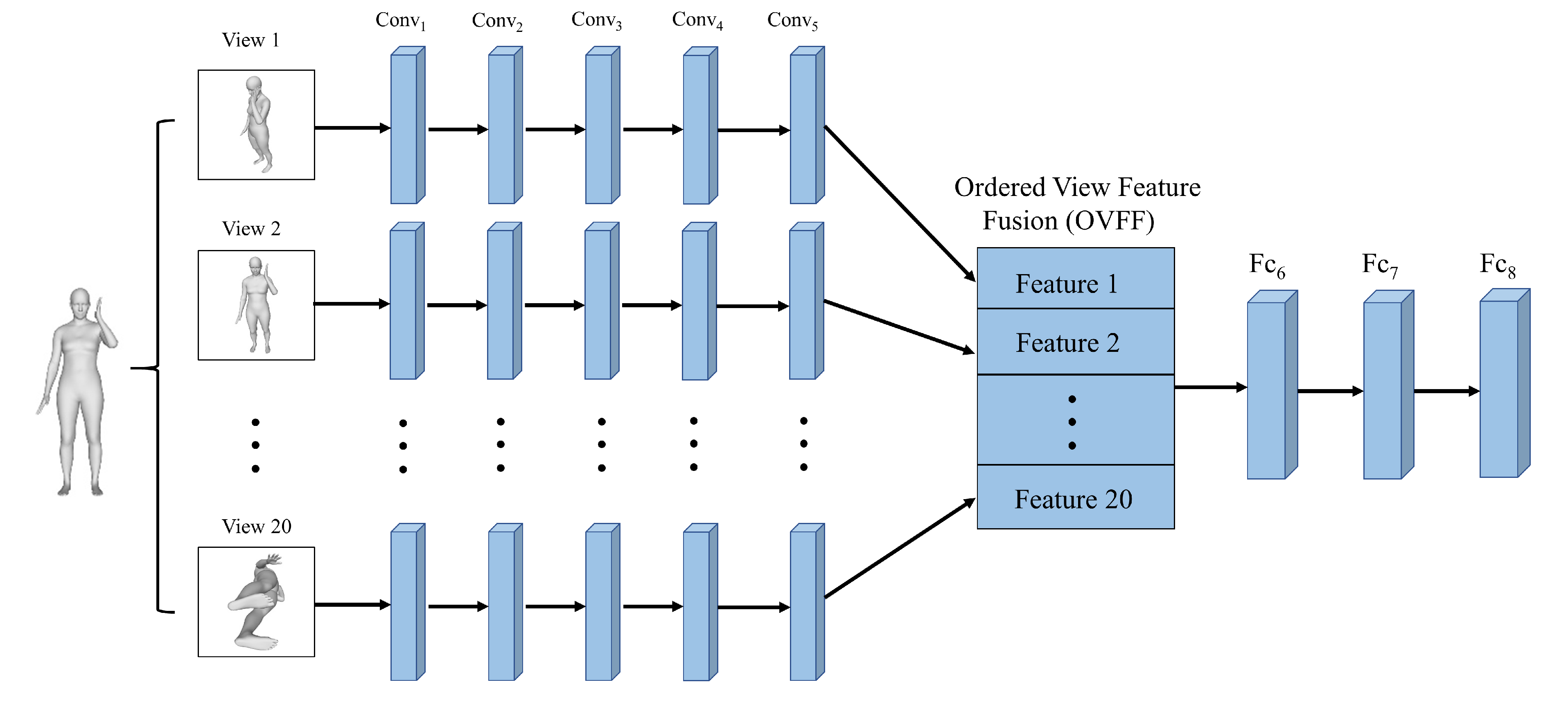
- Due to the max view-pooling in the original MVCNN being orientation-invariant, we combine the learned feature in each view in an orderly manner after the last convolutional layer and before the fully connected layers in the well known AlexNet [15] for pose recognition.
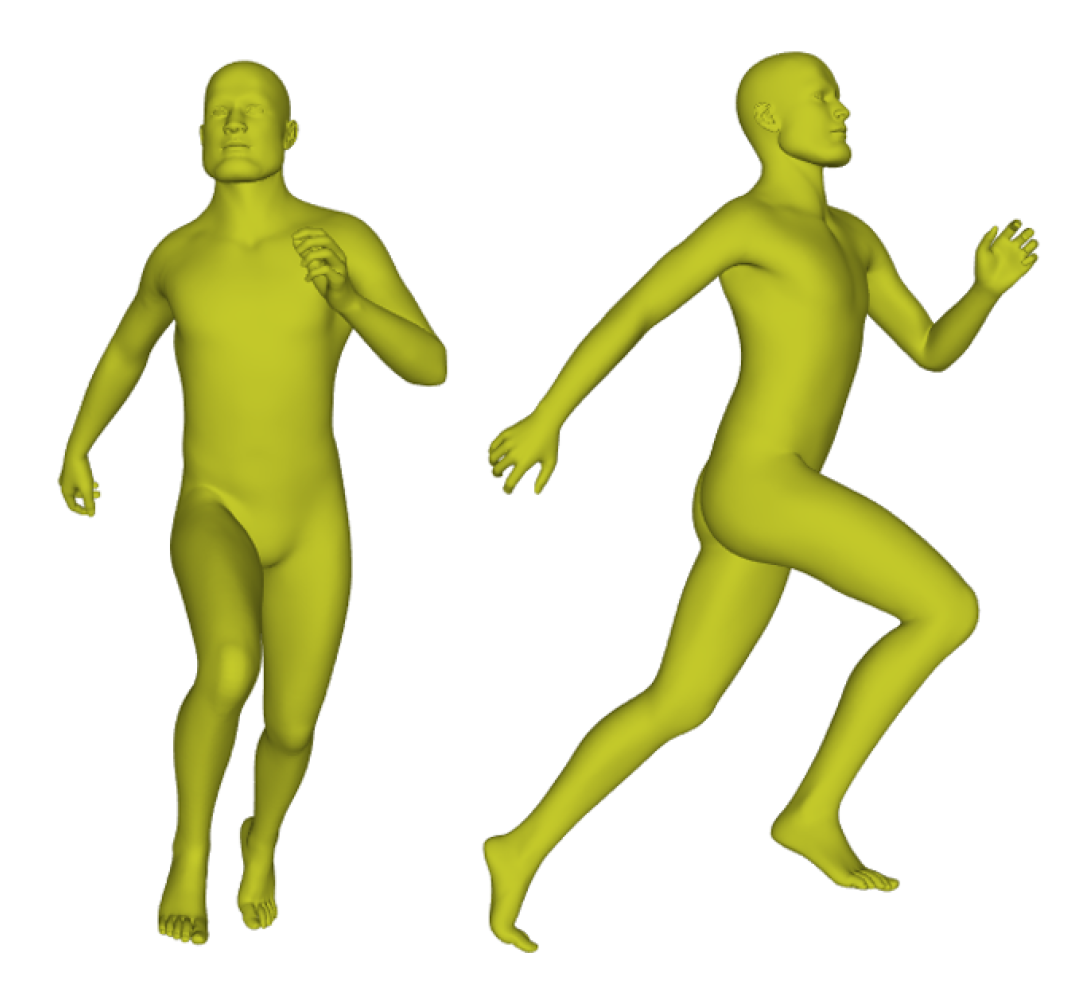
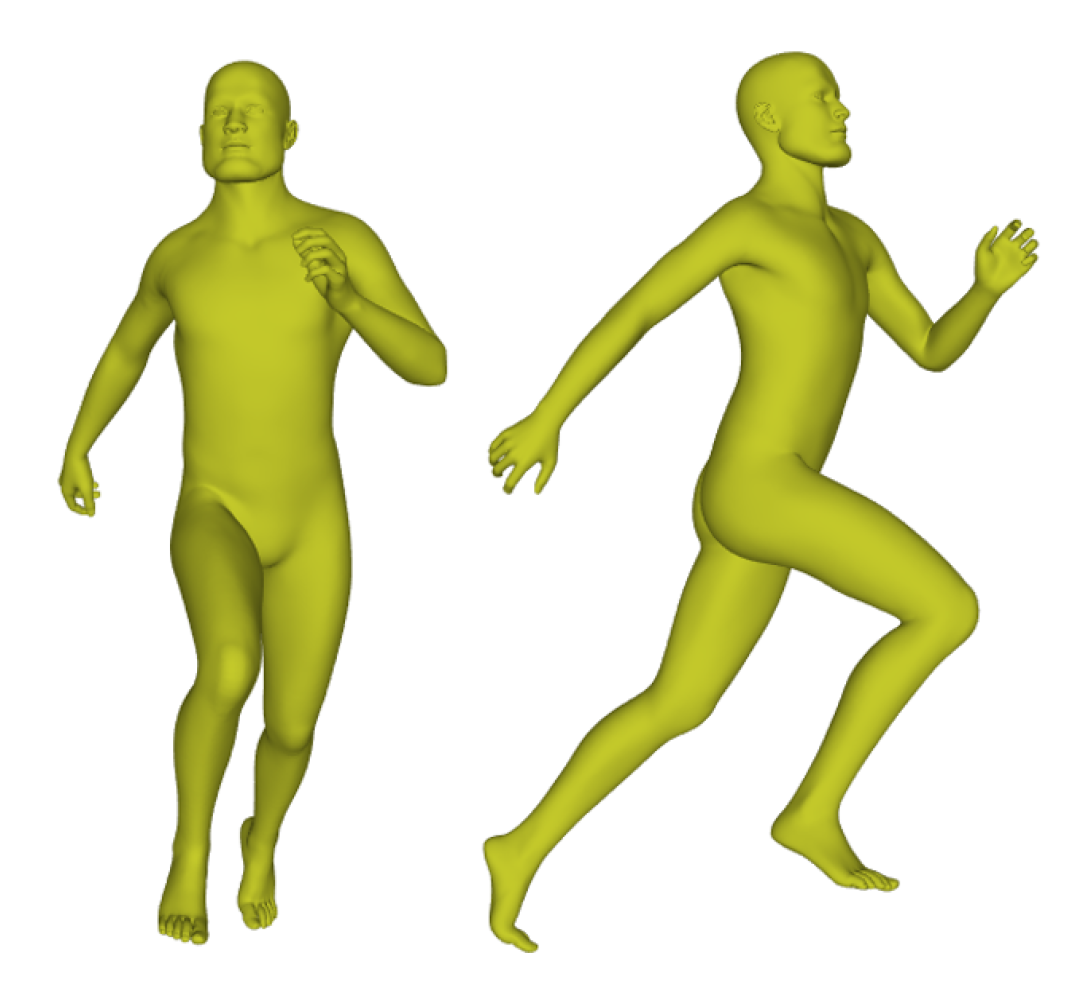
- Due to the existing 3D human datasets, such as SHREC’14 [1], the statistical model shape [2], CAESAR [3], and FAUST [4], only including hundreds of shapes, we construct a larger 3D Human Pose Recognition Dataset (HPRD), which includes 1000 subjects, with each subject in 100 poses, for the evaluation of pose classification and retrieval.
2. Related Works
3. Methods
3.1. Pose Classification
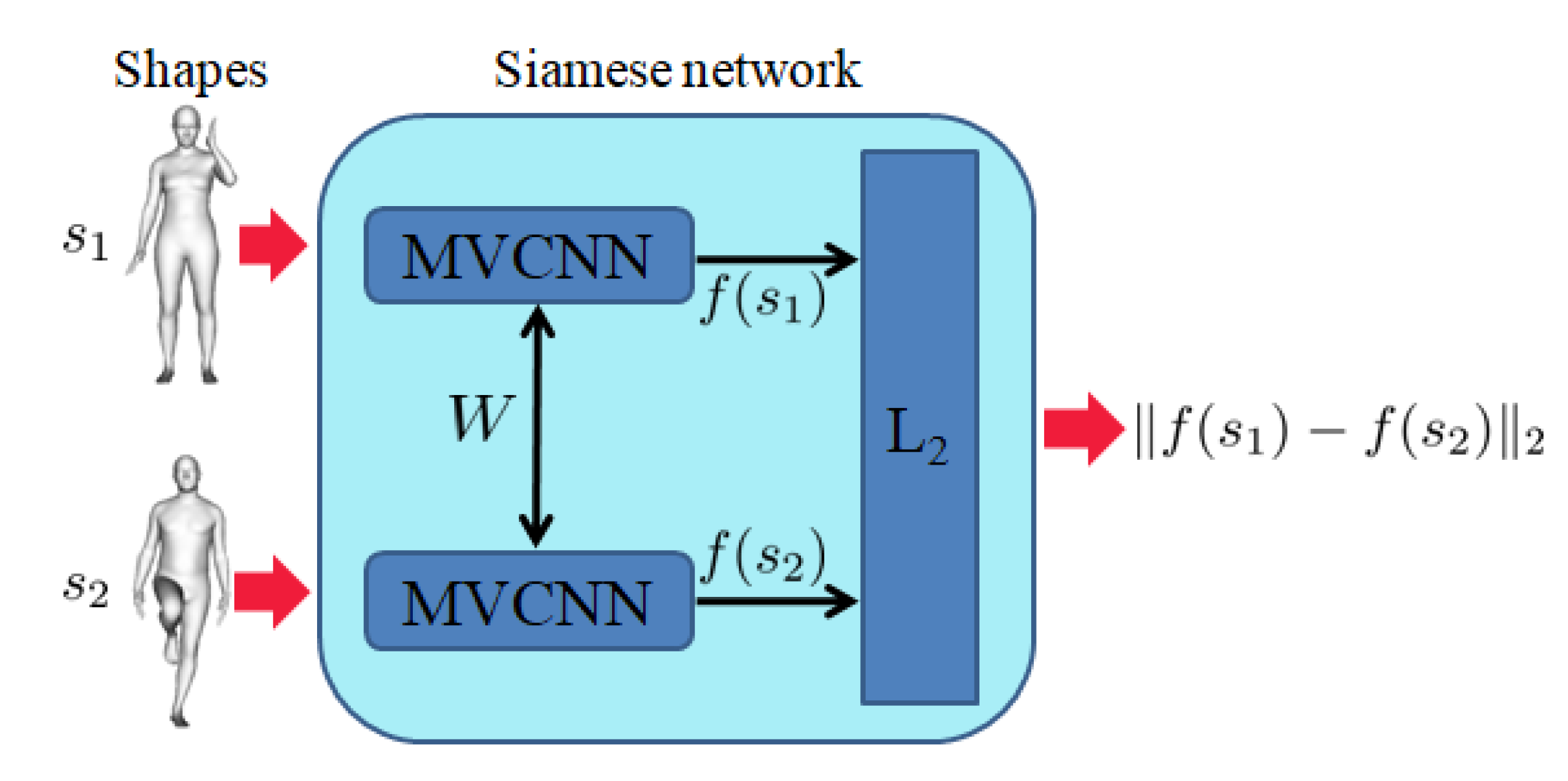
3.2. Pose Retrieval
4. Experiments
4.1. 3D Human Datasets
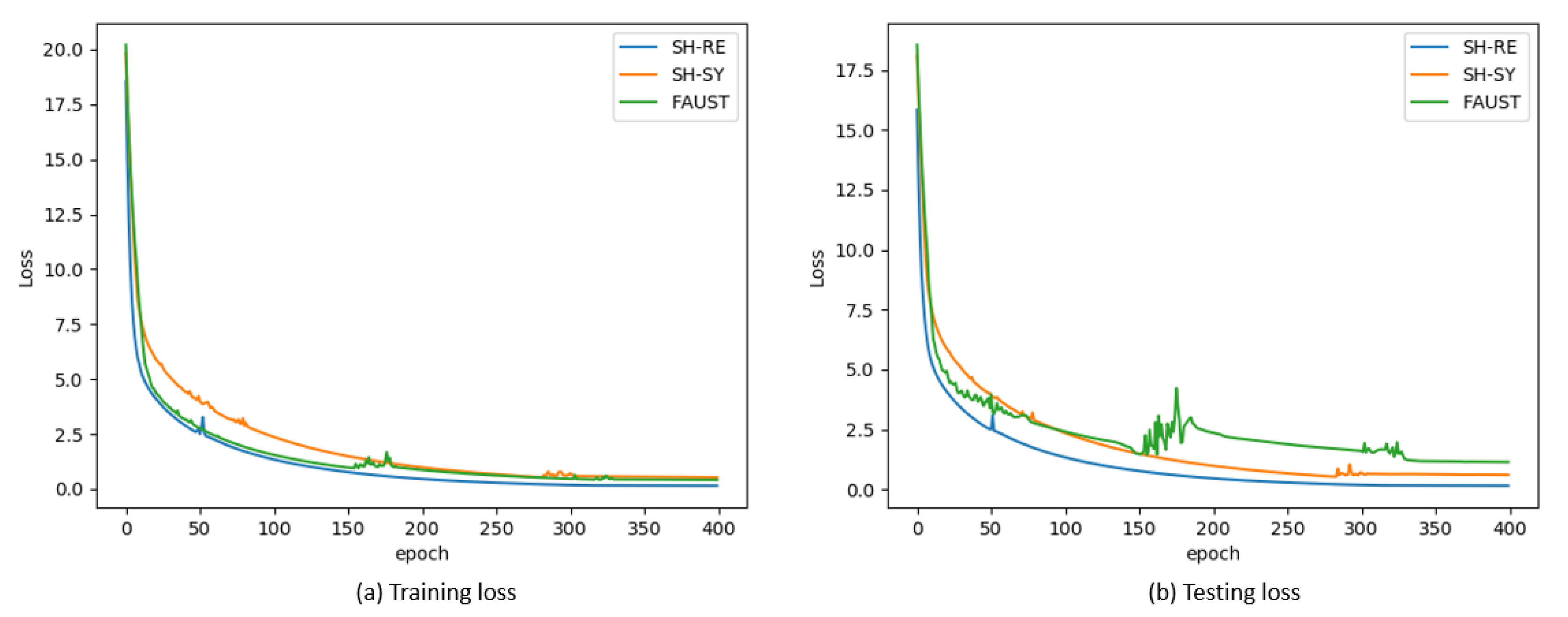
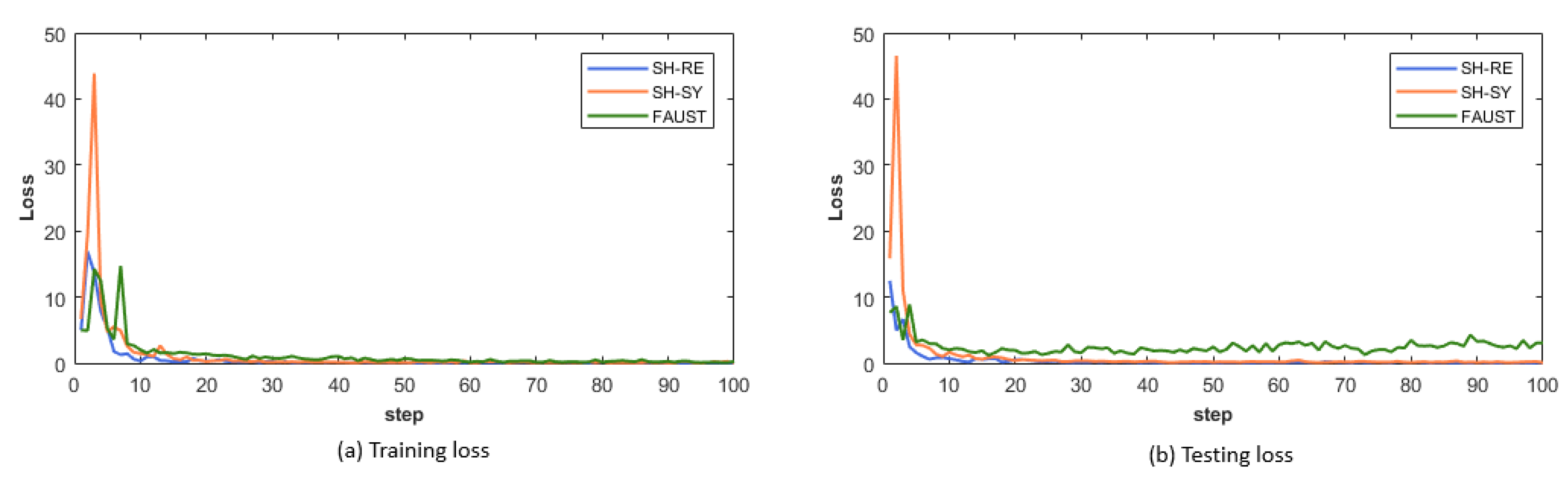
4.2. Performance of Pose Classification
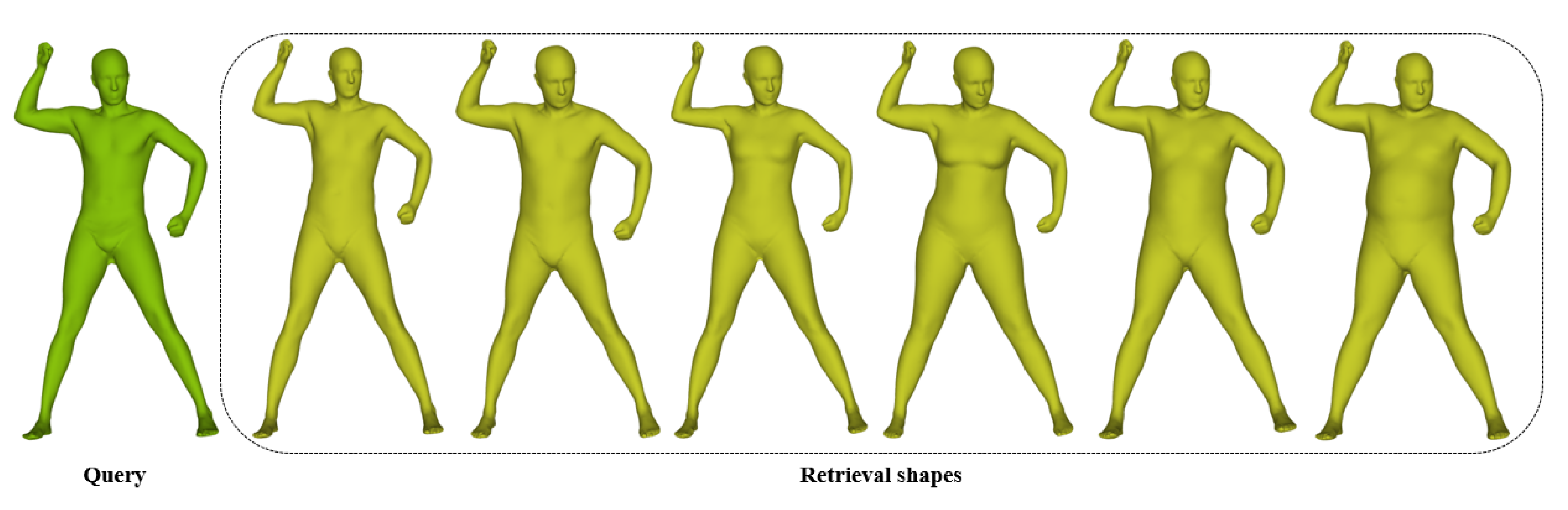
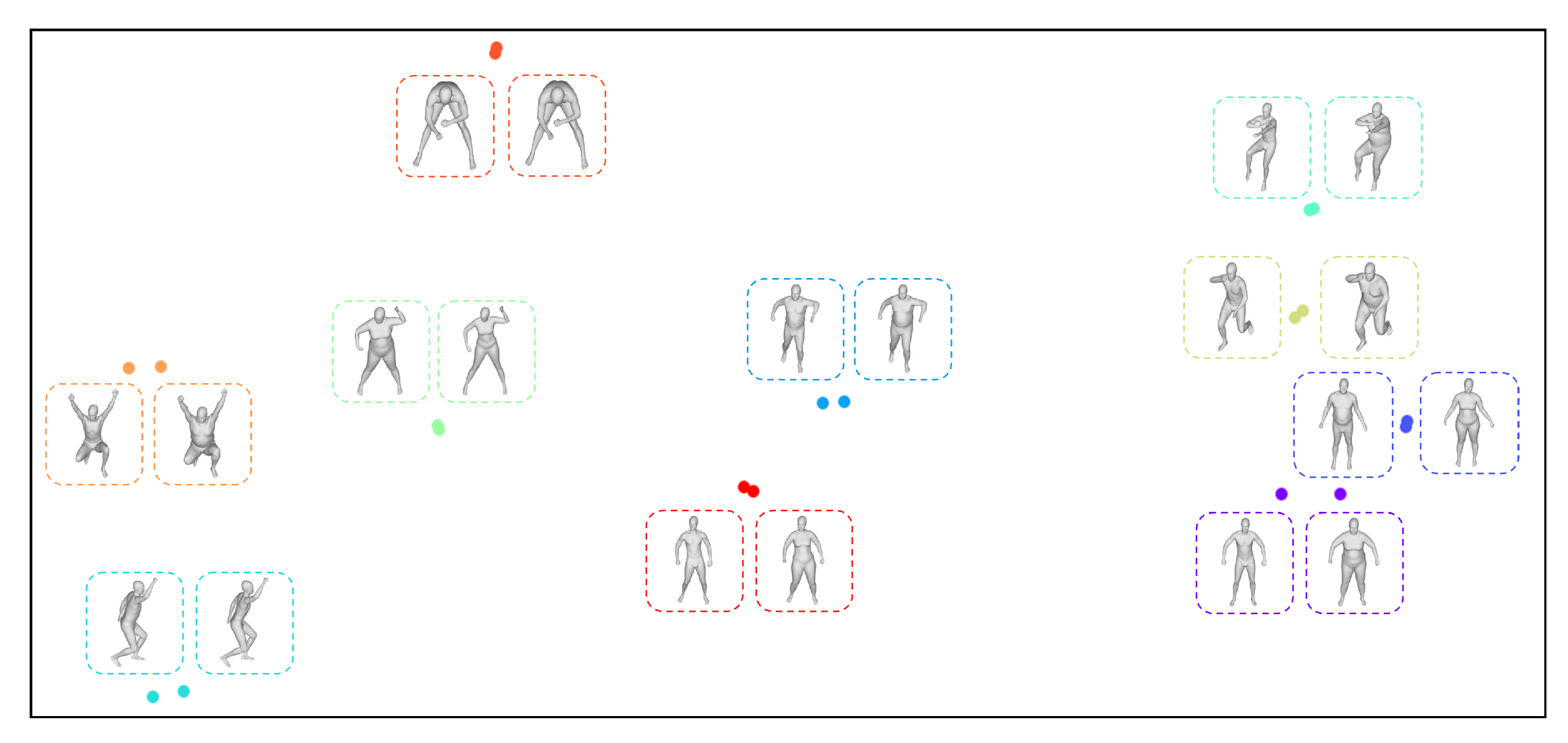
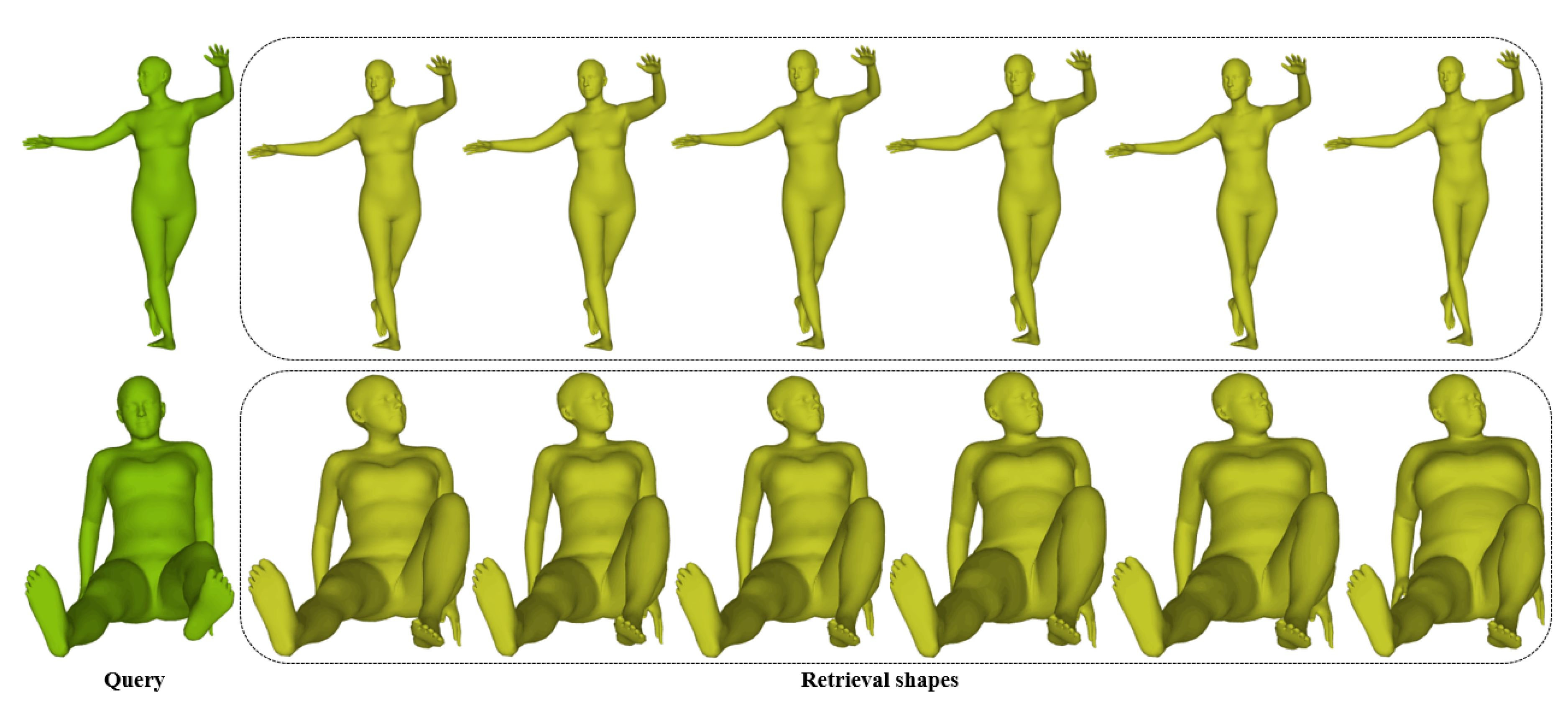
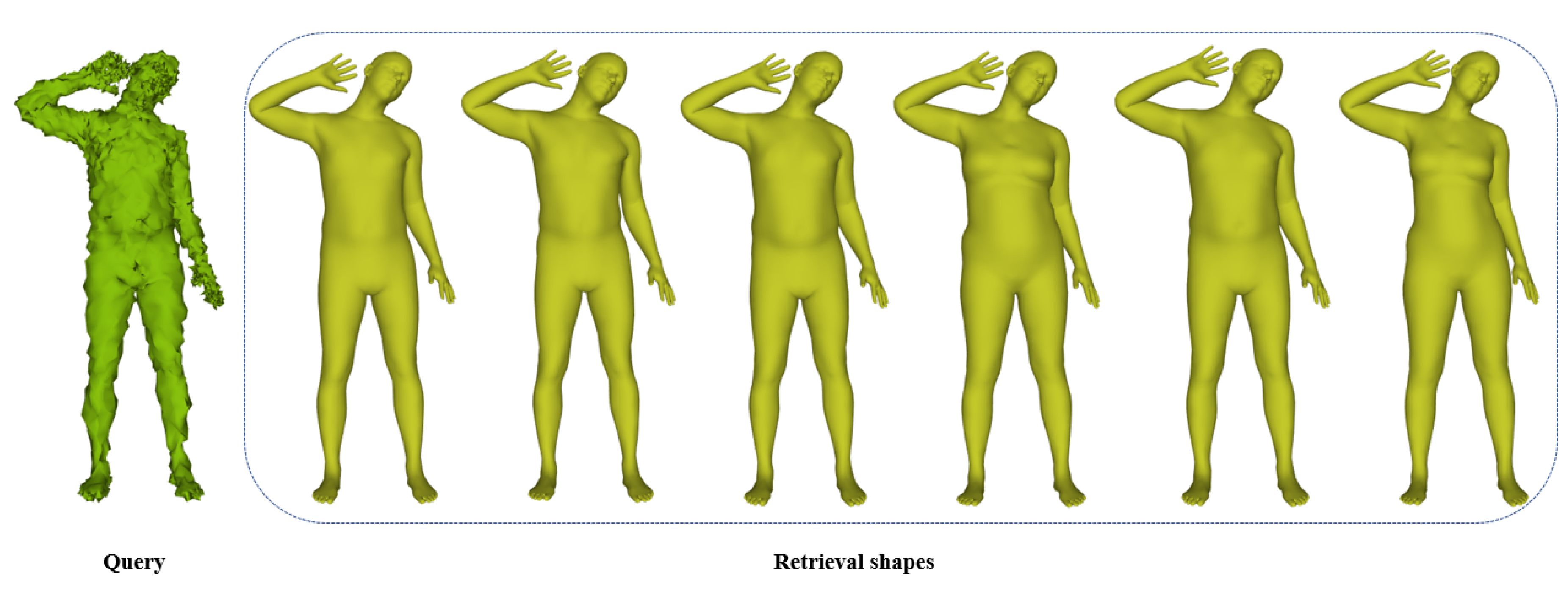
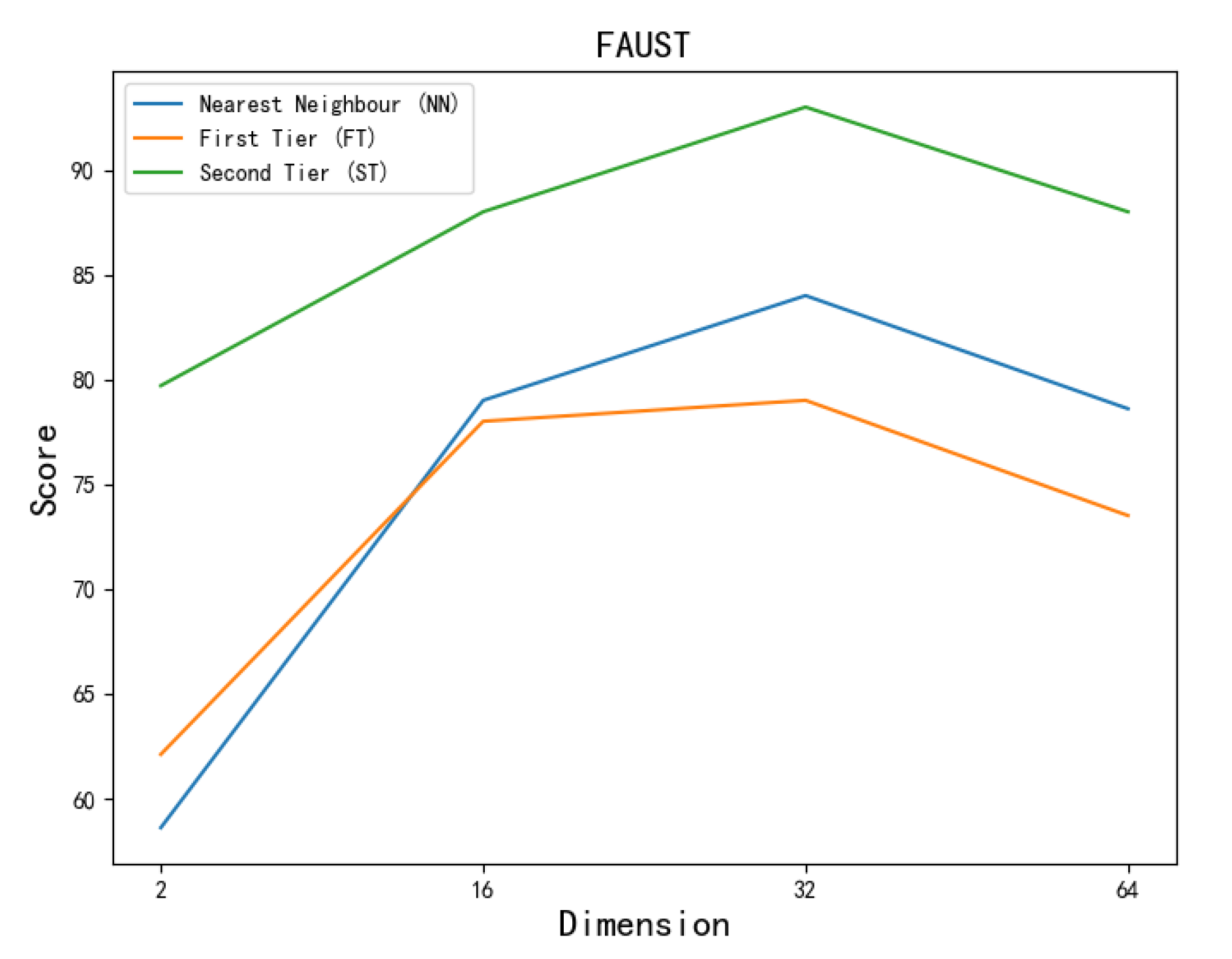
4.3. Performance of Pose Retrieval
- Nearest Neighbour (NN): the percentage of the closest matches that belongs to the same class as the query (here, ).
- First Tier (FT): the recall for the smallest K that could possibly include of the models in the query class.
- Second Tier (ST): the same type of the result as FT, but a little less stringent (i.e., K is twice as big).
5. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pickup, D.; Sun, X.; Rosin, P.L.; Martin, R.R.; Cheng, Z.; Lian, Z.; Bu, S. SHREC’14 Track: Shape retrieval of non-rigid 3D human Models. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Strasbourg, France, 6 April 2014; pp. 1–10. [Google Scholar]
- Hasler, N.; Stoll, C.; Sunkel, M.; Rosenhahn, B.; Seidel, H.P. A statistical model of human pose and body shape. In Proceedings of the Computer Graphics Forum, Budmerice, Slovakia, 23–25 April 2009; Volume 28, pp. 337–346. [Google Scholar]
- CAESAR. Available online: http://store.sae.org/caesar (accessed on 20 August 2020).
- Bogo, F.; Romero, J.; Loper, M.; Black, M.J. FAUST: Dataset and evaluation for 3D mesh registration. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3794–3801. [Google Scholar]
- Varol, G.; Romero, J.; Martin, X.; Mahmood, N.; Black, M.J.; Laptev, I.; Schmid, C. Learning from synthetic humans. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 109–117. [Google Scholar]
- Anguelov, D.; Srinivasan, P.; Koller, D.; Thrun, S.; Rodgers, J.; Davis, J. SCAPE: Shape completion and animation of people. In Proceedings of the ACM SIGGRAPH, Anaheim, CA, USA, 24–28 July 2016. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Michael, B.; Javier, R.; Gerard, P.M.; Federica, B.; Naureen, M. Learning human body shapes in motion. In Proceedings of the ACM SIGGRAPH 2016 Courses, New York, NY, USA, 24–28 July 2016; pp. 1–411. [Google Scholar]
- Cheng, Z.Q.; Chen, Y.; Martin, R.R.; Wu, T.; Song, Z. Parametric modeling of 3D human body shape-a survey. Comput. Graph. 2018, 71, 88–100. [Google Scholar] [CrossRef]
- Berretti, S.; Daoudi, M.; Turaga, P.; Basu, A. Representation, analysis, and recognition of 3D humans: A survey. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–36. [Google Scholar] [CrossRef]
- Pickup, D.; Sun, X.; Rosin, P.L.; Martin, R.R.; Cheng, Z.; Lian, Z.; Bu, S. Shape retrieval of non-rigid 3D human models. Int. J. Comput. Vis. 2016, 120, 169–193. [Google Scholar] [CrossRef] [Green Version]
- Slama, R.; Wannous, H.; Daoudi, M. 3D human motion analysis framework for shape similarity and retrieval. Image Vis. Comput. 2014, 32, 131–154. [Google Scholar] [CrossRef]
- Bonis, T.; Ovsjanikov, M.; Oudot, S.; Chazal, F. Persistence-based pooling for shape pose recognition. In Proceedings of the International Workshop on Computational Topology in Image Context, Marseille, France, 15–17 June 2016; pp. 19–29. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–2 December 1993; pp. 737–744. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively with application to face verification. In Proceedings of the Computer Vision and Pattern Recognition, Hofgeismar, Germany, 7–9 April 2005; pp. 539–546. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative learning of deep convolutional feature point descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 118–126. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese instance search for tracking. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Ferrari, V.; Marin-Jimenez, M.; Zisserman, A. Pose search: Retrieving people using their pose. In Proceedings of the Computer Vision and Pattern Recognition, Voss, Norway, 1–5 June 2009; pp. 1–8. [Google Scholar]
- Eichner, M.; Marin-Jimenez, M.; Zisserman, A.; Ferrari, V. 2D articulated human pose estimation and retrieval in (almost) unconstrained still images. Int. J. Comput. Vis. 2012, 99, 190–214. [Google Scholar] [CrossRef] [Green Version]
- Jammalamadaka, N.; Zisserman, A.; Jawahar, C.V. Human pose search using deep networks. Image Vis. Comput. 2017, 59, 31–43. [Google Scholar] [CrossRef]
- Jammalamadaka, N.; Zisserman, A.; Eichner, M. Video retrieval by mimicking poses. In Proceedings of the ACM International Conference on Multimedia Retrieval, Nara, Japan, 27–31 October 2012; pp. 1–8. [Google Scholar]
- Pehlivan, S.; Duygulu, P. 3D human pose search using oriented cylinders. In Proceedings of the International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 16–22. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Sarafianos, N.; Boteanu, B.; Ionescu, B.; Kakadiaris, I.A. 3D human pose estimation: A review of the literature and analysis of covariates. Comput. Vis. Image Underst. 2016, 152, 1–20. [Google Scholar] [CrossRef]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2D/3D pose estimation and action recognition using multitask deep learning. In Proceedings of the Computer Vision and Pattern Recognition, Guangzhou, China, 23–26 November 2018; pp. 5137–5146. [Google Scholar]
- Wang, P.S.; Sun, C.Y.; Liu, Y.; Tong, X. Adaptive O-CNN: A patch-based deep representation of 3D shapes. ACM Trans. Graph. 2018, 37, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution on x-transformed points. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 820–830. [Google Scholar]
- Hoang, L.; Lee, S.H.; Kwon, K.R. A 3D shape recognition method using hybrid deep learning network CNN-SVM. Electronics 2020, 9, 649. [Google Scholar] [CrossRef] [Green Version]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Y.P.; Lai, Y.K.; Zhang, F.L.; Li, C.; Gao, L. A survey on deep geometry learning: From a representation perspective. Comput. Vis. Media 2020, 6, 113–133. [Google Scholar] [CrossRef]
- Wang, C.; Pelillo, M.; Siddiqi, K. Dominant set clustering and pooling for multi-view 3D object recognition. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Huang, H.; Kalogerakis, E.; Chaudhuri, S.; Ceylan, D.; Kim, V.G.; Yumer, E. Learning local shape descriptors from part correspondences with multiview convolutional networks. ACM Trans. Graph. 2017, 37, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Zeng, H.; Wang, Q.; Liu, J. Multi-feature fusion based on multi-view feature and 3D shape feature for non-rigid 3D model retrieval. IEEE Access 2019, 7, 41584–41595. [Google Scholar] [CrossRef]
- Fried, O.; Avidan, S.; Cohen-Or, D. Patch2Vec: Globally consistent image patch representation. In Proceedings of the Computer Graphics Forum, Barcelona, Spain, 12–16 June 2017; Volume 36, pp. 183–194. [Google Scholar]
- Mao, D.; Hao, Z. A novel sketch-based three-dimensional shape retrieval method using multi-view convolutional neural network. Symmetry 2019, 11, 703. [Google Scholar] [CrossRef] [Green Version]
- Loper, M.; Mahmood, N.; Black, M.J. MoSh: Motion and shape capture from sparse markers. ACM Trans. Graph. 2014, 33, 220–233. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Convolutional Kernel | Stride | Output Size |
|---|---|---|---|
| Input | - | - | 227 × 227 × 3 |
| Conv | 96 × 11 × 11 | 4 | 55 × 55 × 96 |
| Pool | 3 × 3 | 2 | 27 × 27 × 96 |
| Conv | 256 × 5 × 5 | 1 | 27 × 27 × 256 |
| Pool | 3 × 3 | 2 | 13 × 13 × 256 |
| Conv | 384 × 3 × 3 | 1 | 13 × 13 × 384 |
| Conv | 384 × 3 × 3 | 1 | 13 × 13 × 384 |
| Conv | 256 × 3 × 3 | 1 | 13 × 13 × 256 |
| Pool | 3 × 3 | 2 | 6 × 6 × 256 |
| OVFF | - | - | 20 × 6 × 6 × 256 |
| Fc | - | - | 4096 |
| Fc | - | - | 4096 |
| Fc | - | - | k |
| Dataset | Pose | Subject | Epoch | Accuracy (%) |
|---|---|---|---|---|
| SH-RE | 10 | 40 | 300 | 100 |
| SH-SY | 20 | 15 | 300 | 99.38 |
| FAUST | 30 | 10 | 300 | 88.33 |
| HPRD | 100 | 1000 | 100 | 97 |
| Dataset | Pose | Subject | Accuracy(%) | ||
|---|---|---|---|---|---|
| Max View-Pooling | Mean View-Pooling | OVFF (Our) | |||
| RAP | 4 | 800 | 25 | 25 | 100 |
| SH-RE-RO | 340 | 40 | 29.4 | 30.2 | 99.3 |
| Dataset | Step | NN(%) | FT (%) | ST (%) | ||
|---|---|---|---|---|---|---|
| SH-RE | 10 | 10 | 500 | 100 | 100 | 100 |
| SH-SY | 20 | 40 | 500 | 100 | 97 | 100 |
| FAUST | 30 | 30 | 500 | 84 | 79 | 93 |
| HPRD | 50 | 50 | 3000 | 100 | 99.8 | 100 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; He, P.; Li, N.; Cao, J. Pose Recognition of 3D Human Shapes via Multi-View CNN with Ordered View Feature Fusion. Electronics 2020, 9, 1368. https://doi.org/10.3390/electronics9091368
Wang H, He P, Li N, Cao J. Pose Recognition of 3D Human Shapes via Multi-View CNN with Ordered View Feature Fusion. Electronics. 2020; 9(9):1368. https://doi.org/10.3390/electronics9091368
Chicago/Turabian StyleWang, Hui, Peng He, Nannan Li, and Junjie Cao. 2020. "Pose Recognition of 3D Human Shapes via Multi-View CNN with Ordered View Feature Fusion" Electronics 9, no. 9: 1368. https://doi.org/10.3390/electronics9091368
APA StyleWang, H., He, P., Li, N., & Cao, J. (2020). Pose Recognition of 3D Human Shapes via Multi-View CNN with Ordered View Feature Fusion. Electronics, 9(9), 1368. https://doi.org/10.3390/electronics9091368