1. Introduction and Background
The number of user interface description languages that use markup languages has increased during the last years. The main reason behind their growth is their use in the Web.
The Extensible Markup Language (XML) [
1] is one of the most popular markup languages. For instance, the Extensible HyperText Markup Language (XHTML) [
2] enables developers to define static HyperText Markup Language (HTML) [
3] pages as valid XML documents.
The use of XML is not limited to the definition of static Web pages, most technologies supporting the generation of dynamic Web pages use XML-based languages; for instance, Java Server Pages (JSP) [
4], Java Server Faces (JSF) [
5], Standard Tag Library for JavaServer Pages (JSTL) [
6], ASP.NET Web Pages [
7], Extensible Application Markup Language (XAML) [
8], Polymer components [
9], AngularJS directives [
10], Extensible 3D (X3D) [
11], and so forth.
The use of XML to define user interfaces is not limited to the Web; it also used to define user interfaces in mobile platforms such as the Android [
12] platform. It is neither limited to the description of UIs, the XML language is also employed to represent the information exchanged in Web Services. For instance, the Simple Object Access Protocol (SOAP) [
13] defines the Web service communication using XML documents.
Another example that exposes the versatility of XML to represent information is the definition of the XML Model Interchange (XMI) [
1] format which is the standard format defined by the Object Management Group (OMG) [
14] that enables the use and manipulation of model information in Model-driven Architectures (MDAs) [
15].
An interesting capability of XML is definition of XML meta-data in XML documents. For instance, the XML Schema Definition (XSD) [
16] language is an XML-based language to specify the structure of valid XML documents. Besides, the XML Stylesheet Language Transformation (XSLT) [
17] language enables developers to define XML document transformations in XML.
Model-driven Architectures (MDAs) enables developers to generate Platform Specific Models (PSMs) using Platform Independent Models (PIMs) as input parameters of model-to-model transformations. These PSMs are used as input parameters of model-to-text transformations to generate the source code of the application.
Most popular model-to-text transformation languages tend to adopt an archetype-based paradigm. Some examples of this type of language are ACCELEO [
18], MOFScript [
19], Java Emitter Templates (JET) [
20], and so forth. These languages use text templates interwoven with OCL expressions. While the text templates generate static text; the OCL expressions generate dynamic text. They enable developers to define transformations any language or purpose.
This article describes a proposal that captures XML characteristics to enable developers to use model-to-model transformation languages to generate collections of XML documents. Unlike most popular model-to-text transformation languages, model-to-model transformation languages, such as Query View Transformation (QVT) [
21] or Atlas Transformation Language (ATL) [
22], tend to adopt a declarative paradigm where rules are defined using OCL expressions.
The level of abstraction is leveraged introducing the TagML meta-model to capture the essential properties of XML to model XML documents. In addition, the level of reuse is improved by defining the TagML-to-XML model-to-text transformation that generates collections of XML documents using the TagML models.
The novelty of this approach lays on the way XML documents are generated using model-to-model transformations instead of traditional model-to-text transformations. Consequently, junior developers do not have to learn another programming paradigm to write model-to-text transformations to generate this kind of documents reducing costs (it is assumed that they already have skills in model-to-model transformation languages which usually employ declarative programming paradigms) [
23]. Moreover, the simplicity of the proposed approach enables the generation of collections of XML documents without the need for any transformation configuration. This fact does not penalize model reuse due to the proposed generation process.
Our proposal enables developers to generate collections of XML documents using model-to-model transformations. To carry out this task, we encourage the interoperability of the architecture at design time following the MDA principles of leveraging the level of abstraction and reuse [
24].
In Reference [
25], the authors argue for the importance of integrating XML-based models in the MDE process. In that article, the authors propose a lightweight approach for providing first-class support for managing XML documents within Epsilon model management language family [
18] using the EOL [
26] OCL-based imperative language to manipulate models. The philosophy behind our approach is the definition of an Implementation Specific Model (ISM) to deal with XML document generation using a declarative programming paradigm to make this process as simple as possible for junior developers (e.g., our approach does not require Epsilon to work). Though the goal and purpose of both approaches may be similar, the perspective to board the problem is completely different (i.e., imperative versus declarative paradigm to define model transformations).
Main difference between the study presented in Reference [
27] and our approach is the level of abstraction they use to address similar problems. While Reference [
27] formalizes templates engines; our approach is focused on the definition of an Implementation Specific Meta-model and a generation process for the specific purpose of generating tag-based documents using a model-to-model transformation engine (ATL) [
22] instead of a model-to-text transformation engines that are traditionally employed to generate this type of documents.
Unlike the proposal presented in Reference [
28] where a concrete instantiation of a framework employing string, tree or triple graph grammars is required to generate source code; our approach only requires the definition of a model-to-model transformation to generate code because it addresses a more specific problem: the generation of tag-based documents only. As result, the generation process is simpler requiring only developers with skills EMF and ATL to generate code (i.e., any junior developer with basic skill in MDA can handle it).
We share the view presented in Reference [
29] where authors propose the use of small Domain Specific Languages (DSLs) well-focused on meta-models, instead of monolithic languages like UML. The authors illustrate this approach to solve the bug-tracking by defining a meta-model to represent XML documents in
Section 3.1. Although the meta-model presented in Reference [
29] seems to be similar to the meta-model presented in this proposal, the purpose is completely different. While the goal of our approach is the definition of an Implementation Specific Model (ISM) to generate collections of XML documents for application development; the goal of the meta-model presented in Reference [
29] is the definition of a generic document representation to pivot among different file formats. For instance, the meta-model presented in Reference [
29] lacks on the capability to define file and folder structures to model the location of XML documents. This may not be a major issue if you are dealing with document formats; however, it is a minor issue in code generation because this characteristic is present in all model-to-text transformation languages. Finally, authors in Reference [
29] do not provide any reference to the transformation that generates XML text documents, which is understandable because it is not the paper focus.
The work presented in Reference [
30] describes a representation to convert model structures using model-to-model transformations. Although
Section 3 of Reference [
30] presents a similar process to tackle the problem of generating source code using model-to-model transformations instead of model-to-text transformation; the meta-model defined to carry out this task, which consists in a single meta-class (see
Section 3.4 of Reference [
30]), provides a high level of genericity at the expense of an overload of StringNode instance specification (e.g., the prefix and suffix definition is mandatory for all instances, including those that do not require any, such as plain text). The proposed solution is based on the definition of the meta-model presented in
Section 3.1 of this article where XML document specific characteristics are abstracted to represent these documents employing less effort to generate text (e.g., no need to specify prefixes and suffixes for each tag or attribute). In addition, our approach enables developers to create XML document structures in terms of folders to organize the generated collection of XML documents.
Regarding Xtend language, this approach employs a Java dialect to describe transformations using an imperative programming paradigm instead of a declarative paradigm which is the same that is employed by most of model-to-model transformation languages. Thus, developers do not need to use different programming paradigms to generate XML documents.
Therefore, main article contributions can be summarized as follows:
Enables developers to define the folder structure for the collection of XML documents to be generated according to a TagML model;
Improves XML document generation inexpensiveness avoiding developers the need to learn model-to-text transformation languages (using a different programming paradigm) to generate XML documents;
Reduces syntax errors derived from the definition of model-to-text transformations improving XML document generation accuracy;
Improves transformation readability/understandability simplifying XML document representation;
Improves transformation maintainability enabling developers to easily extend XML document model characteristics;
Improves XML document generation predictiveness employing a unique model-to-text transformation.
This paper continues in
Section 2 we highlight the main characteristics of collections of XML documents and the limitations of using traditional model-to-text transformation languages that adopt the archetype-based paradigm. Then, in
Section 3 we describe the generation method for XML documents defined in different markup language formats. This section includes
Section 3.1 to describe the TagML meta-model which captures the essential characteristics of documents defined in markup formats, and
Section 3.2 that describes the definition of the model-to-text transformation that generates the textual representation of these documents in markup formats. A case study is presented in
Section 4 to illustrate how the defined method is applied in a scenario where input models are defined by a subset of the entities defined in the Essential Meta-object Facility (EMOF) [
31]. The discussion about pro and cons of using this approach to generate documents in markup format is exposed in
Section 5. Finally, in
Section 6 we present the conclusions and future works.
2. Motivation
This section describes the main characteristics of collections of XML documents and the limitations of using traditional model-to-text transformation languages using archetype-based paradigms. From the syntax perspective, these are the most relevant ones:
The same tag keyword is used to define the beginning and the ending of XML document blocks. For instance, in XHTML, paragraphs are defined between the <P> and </P> tags where P represents the tag keyword.
The same delimiters enclose keywords representing the beginning and the ending of XML document blocks. For instance, in XML, while the beginning of document blocks is defined by tag keywords enclosed by the <and> delimiters; the ending of document blocks is defined by tag keywords enclosed by the </and> delimiters.
The shortened text representation for empty document blocks do not require end tags. For instance; the BR document block in XHTML is enclosed by the <and /> delimiters.
The same delimiter is used to separate attributes in lists. For instance, the blank space is used to separate the rel = "stylesheet" and href = "./css/bootstrap.min.css" attributes in the XHTML rel = "stylesheet" href = "./css/bootstrap.min.css" attribute list.
Attribute keys and values are separated by the same delimiters. For instance, in XHTML, the = character is used to separate the rel attribute key from the "stylesheet" attribute value.
Attribute values are enclosed by the same delimiter. For instance, in XHTML, the " character is used to enclose the stylesheet attribute value.
Collections of XML documents are usually structured in folders according to their contents
Most transformation languages that define model-to-text transformations are based on archetypes. Some examples of this type of languages are JET Templates [
20], MOFScript [
19] and ACCELEO [
18].
These languages are very versatile because they enable developers to generate code for any programming language. For instance, the listing in
Figure 1 depicts the except of code that defines a model-to-text transformation rule in ACCELEO to generate XHTML documents.
Figure 1 shows how the characteristics of XML documents are still present in the definition of model-to-text transformations using archetype-based languages that generate XML documents. The impact of these characteristics leads to information redundancy when defining model-to-text transformations.
The transformation rule depicted in
Figure 1 requires developers to write tag keywords twice to define document blocks; for instance, to define the BODY block, developers have to explicitly write the <BODY> and </BODY> tags.
It also requires developers to write terminals for all opening, closing and empty tag keywords; for instance, the <, /> have to be explicitly introduced when defining tags such as <BODY>, </HTML> and <LINK/>.
Attribute list, attribute key-value and attribute value delimiters are required too. For instance, developers introduce spaces when defining the rel and href attributes of the <LINK rel = "stylesheet" href = "./css/bootstrap.min.css"/> document block. They also separate attribute keys from values using the = character (i.e., href = "./css/bootstrap.min.css"). And they enclose attribute values using quotes (i.e., "./css/bootstrap.min.css").
Another interesting issue to highlight about the definition of model-to-text transformations that generate XML documents using archetype-based languages is the fact that the generation of the textual representation of the XML document is inter-weaved with OCL expressions that calculates the information to be generated.
Under this scenario, the reuse of OCL expressions is poor because small changes in the syntax have a considerable impact in the definition of the transformation. For instance, suppose that the tag keyword delimiters changes from <and> to [and]. All transformations that have been defined using the <and> should be modified, or at least should be copied and modified if both versions of the transformation should be kept. This alternative present the same problems addressed by Model-driven architectures. For instance, the problem of divergent versions of the transformations when modifying model calculus [
24].
As the result of the analysis of the peculiarities of the definition of model-to-text transformations using archetype-based languages, this proposal captures redundant information in XML document models following the Model-driven Architecture philosophy that leverages the abstraction and reuse principles to encourage the interoperability at design-time.
While the abstraction process captures XML document characteristics in the definition of a meta-model which is used to create XML document models; the reuse process is implemented by a model-to-text transformation that turns XML document models into text which generates redundant text.
Therefore, this approach enables developers to define model-to-model transformations instead of model-to-text transformations to generate XML text documents. It leads a clear separation between calculus and syntax where model calculus is captured by the model-to-model transformation, and syntax modifications are captured by the model-to-text transformation. For instance, to change <and> tag keyword delimiters by [ and ], developers modify, or copy and modify, the model-to-text transformation avoiding any change on the calculus. Conversely, to change model calculus, developers modify, or copy and modify, the model-to-model transformation, avoiding any change on the text generation.
Consequently, the proposed approach reduces the amount of information required to generate XML text documents which results on an increment of transformation definition reliability and a reduction of transformation maintenance costs.
3. The Method to Generate Documents
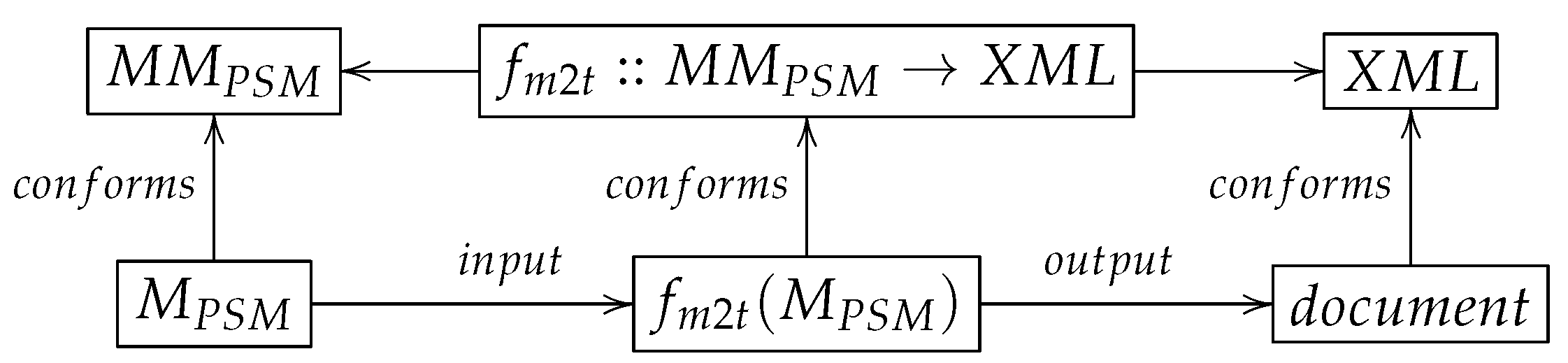
Figure 2 depicts the traditional process to generate XML documents using model-to-text transformations in archetype-based languages.
The traditional process defines the model-to-text transformation function where represents the Platform Specific Model (PSM) that should be turned into the text representation in XML format represented by . Thus, conforms to the expression where represents the PSM meta-model and represents the XML format.
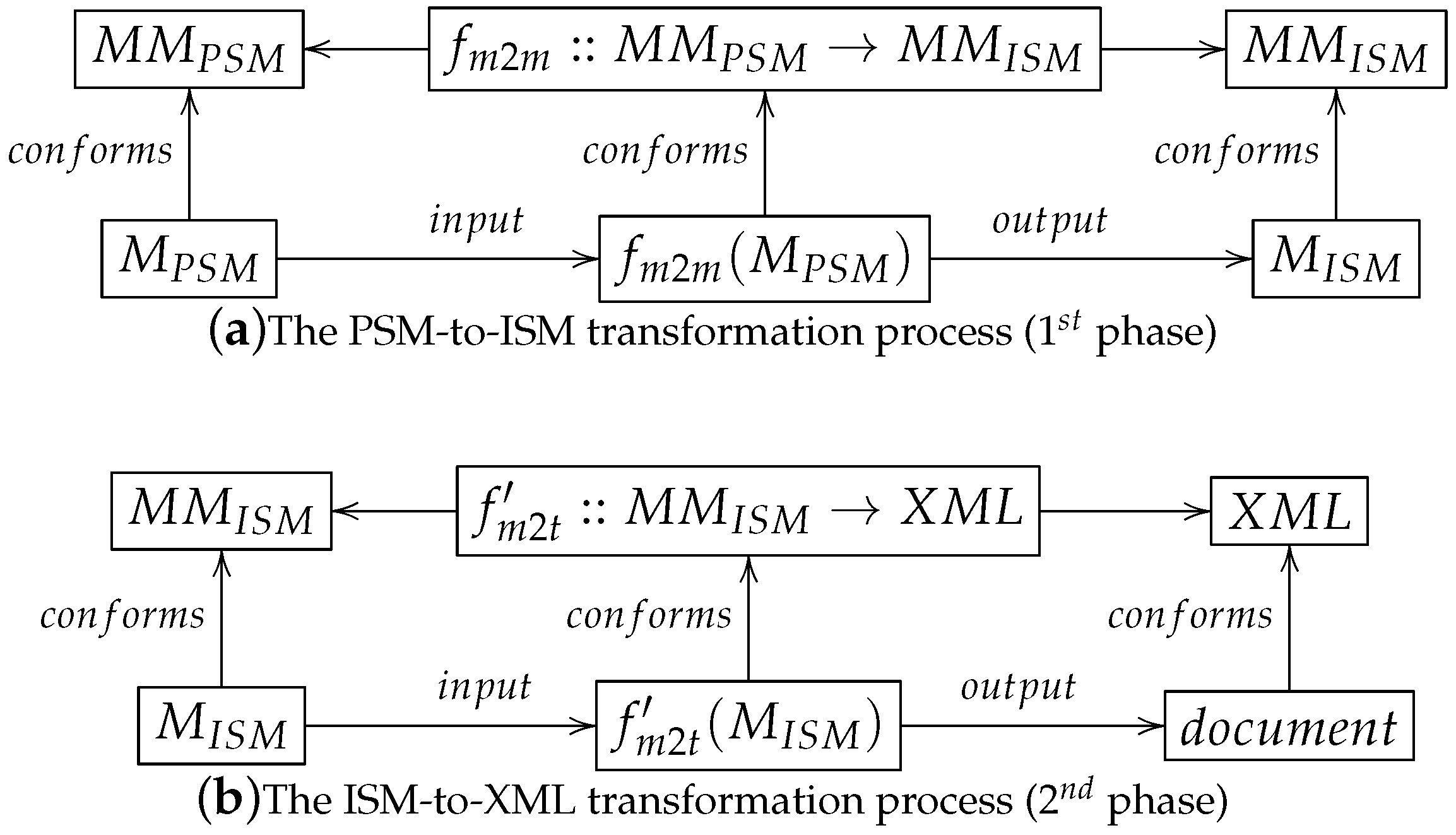
Conversely to the traditional approach, our proposal defines the process depicted in
Figure 3.
This proposal takes advantage of the XML document characteristics described in
Section 2 to raise the level of abstraction while maximizing the reuse in the definition of model-to-text transformations that generate XML documents. Following the MDA philosophy, this proposal defines the Implementation Specific Model (ISM) abstraction layer described in
Section 3.1 between the Platform Specific Model(PSM) and the textual representation of XML documents to decouple the text generation process from the model calculus.
This process is divided into two phases. The first phase of the transformation process is depicted in
Figure 3. In this phase, transformation developers define the
model-to-model transformation function that turns the
PSM conforming the
meta-model into the
ISM conforming the
meta-model which captures the XML document characteristics described in
Section 2.
The second phase of the transformation process is depicted in
Figure 3. It defines the
model-to-text transformation function, which is defined in
Section 3.2. This function turns the
ISM conforming the
meta-model generated in the previous phase into the textual representation of the XML
the
ISM represents. It also crates the folder structure to organize generated XML documents.
Employing this approach, transformation developers focus on the development of the model-to-model transformation that defines model calculus leaving the syntax issues to the model-to-text transformation.
3.1. The Implementation Specific Meta-Model
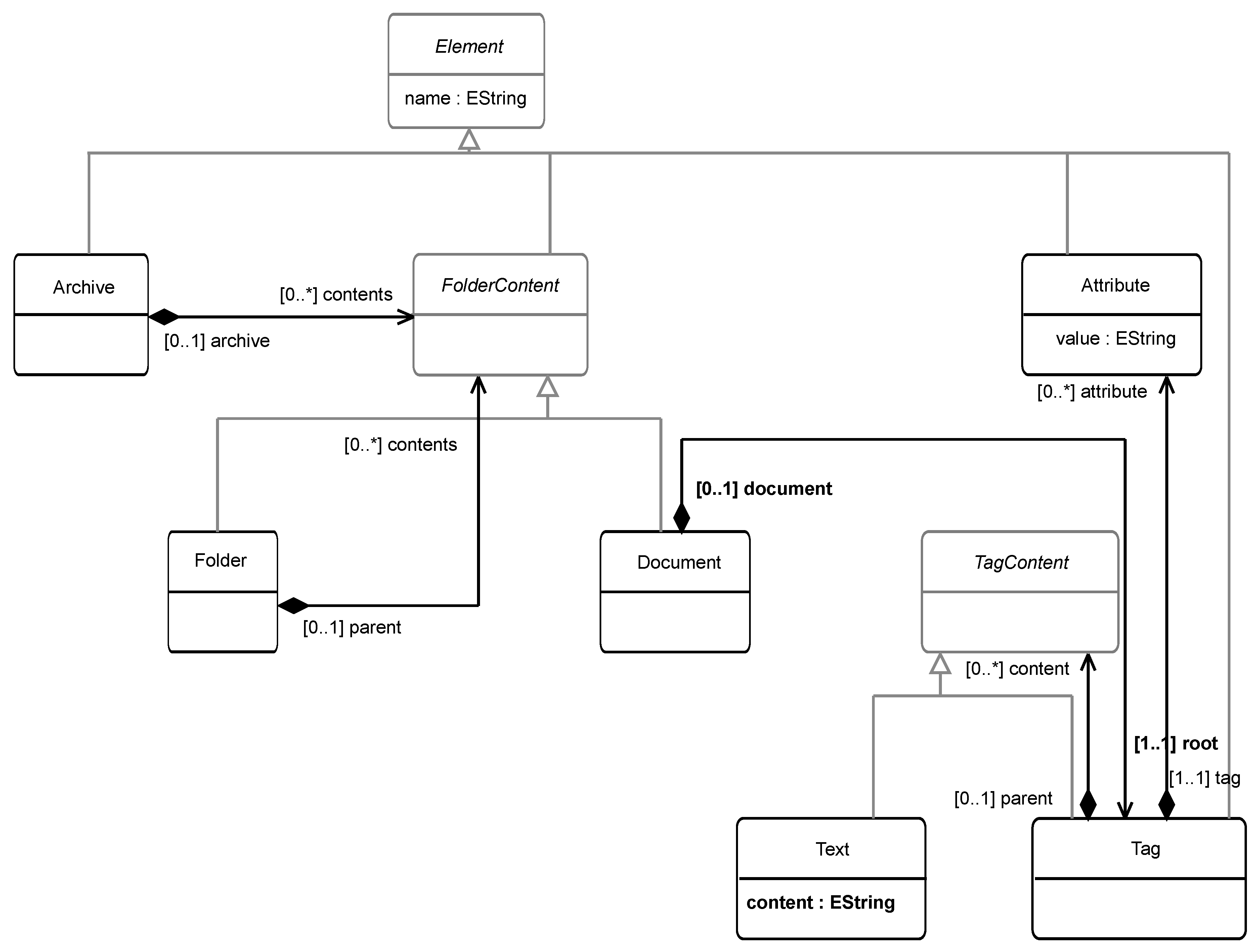
The Implementation Specific Model (ISM) is defined in TagML. TagML is a Domain Specific Language (DSL) which was designed to capture XML-based documents characteristics to leverage the level of abstraction and reuse when defining model-to-text transformations that generate collections of XML documents. It is defined in terms of the meta-model depicted in
Figure 4.
TagML was developed as an Eclipse platform feature using the Eclipse Modeling Framework (EMF) [
32]. Consequently, this feature consists on a set of plugins that follow the Object Management Group (OMG) standards which ensure the interoperability of this tool with third party software. This way of developing tools presents some advantages with respect to those developed ad-hoc.
The capability of integrating this plugin with third part plugins (e.g., UML plugins, transformation tools, etc.), the capability of Eclipse plugins to be executed in different platforms (e.g., Windows, Linux, Mac, etc.), the functionality that is inherited from the Eclipse platform (e.g., workspace, project and file management, user configuration, customized text editors, plugin configuration management, task management, model repositories, etc.)
Both the TagML model editor and the M2T transformation have been developed as Eclipse plugins. These plugins were developed with the Eclipse Modeling Framework (EMF) technology. The use of EMF ensures that these tools follow the standards of the Object Management Group (OMG) ensuring their interoperability with third-party tools.
Developing tools such as Eclipse plugins has certain advantages with respect to the development of ad-hoc environments. The first one is to have a multi-platform development environment. In addition, we can mention the inherited functionality of the environment, which, for example, provides management of workspaces, projects, files, configuration for the user, custom text editors, integration with third-party tools, management of plugins configuration, management of tasks, model management, and so forth.
The goal of the TagML meta-model is to capture the characteristics of tag-based languages to raise the level of reuse of M2T transformations.
Figure 4 shows the meta-model TagML.
As you can see in the
Figure 4, this meta-model defines Archive as the root of a TagML model by defining a collection of FolderContent instances. The FolderContent, Folder and Document meta-classes define an instance of the Composite design pattern [
33]. The role of FolderContent is that of Component, that of Folder is that of Composite and that of Document is that of Leaf. This design pattern is ideal for representing the structure of files and folders that contain the XML documents to be generated.
Each Document instance defines a Tag instance as the root label of the document. This instance is part of another instance of the design pattern Composite where the TagContent fulfills the role Composite, Text the role Leaf and Tag fulfills the role Composite. Again, this design pattern is best suited to represent the tree structure that all label-based documents define.
Text instances represent plain text that can be part of the content of a label. Tag instances represent a tag that defines a collection of attributes represented by Attribute instances.
All meta-classes, except TagContent, define the attribute name, inherited from the Element meta-class abstract.
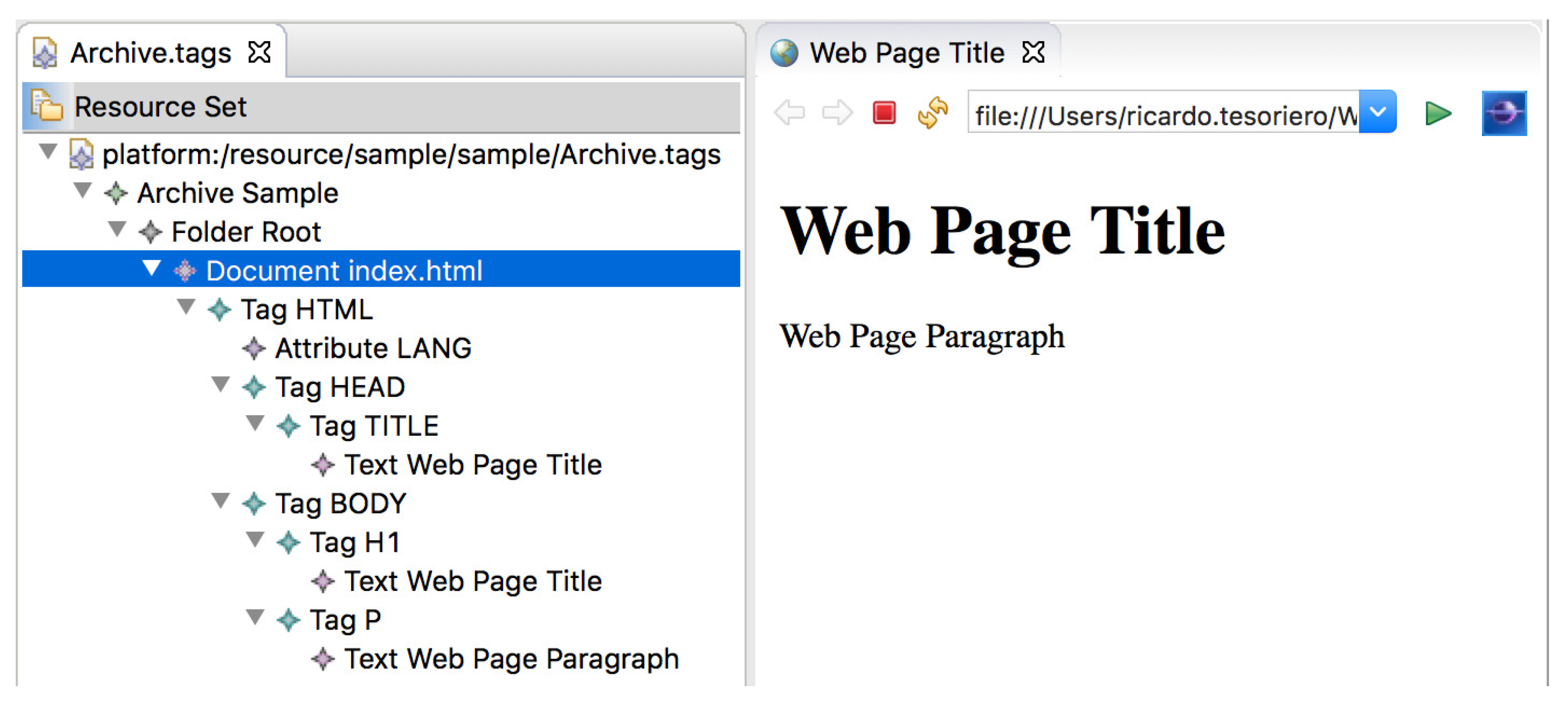
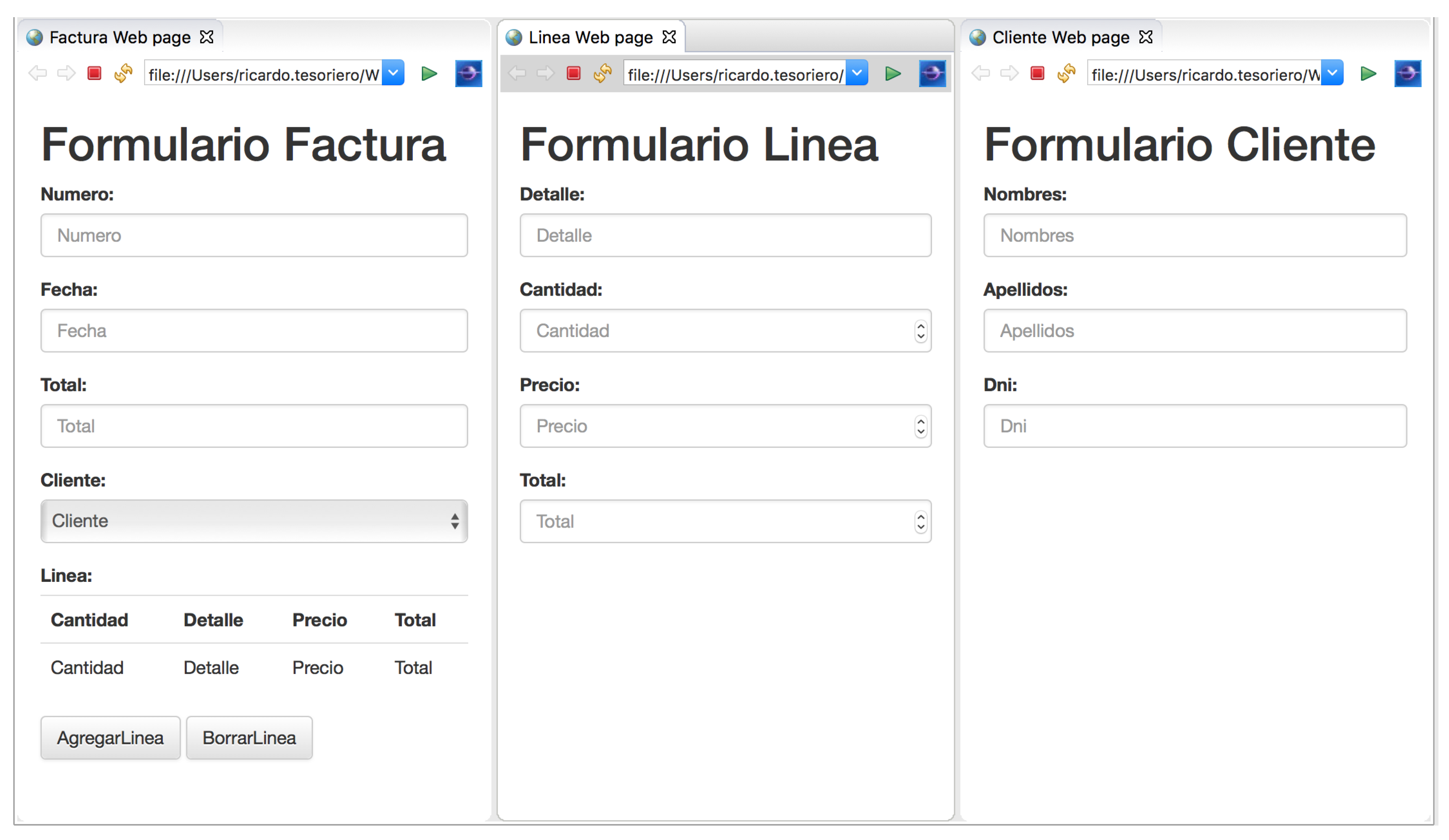
Figure 5 shows the example of a TagML instance model of a Web document in XHTML and its representation in a Web browser.
3.2. Model-to-Text Transformation
The M2T transformation of a PSM is carried out in 2 phases:
- 1.
The execution of the M2M transformation of the PSM to the TagML model;
- 2.
The execution of the M2T transformation of the TagML model to the tag language.
In this section, we will focus on the M2T transformation that uses a model in TagML as an input model and, as an output, generates a document based on labels.
As mentioned above, TagML models are independent of the domain of the application. They only describe the content of the document to be generated.
The M2T transformation has been developed in ACCELEO. ACCELEO is an M2T transformation language based on archetypes.
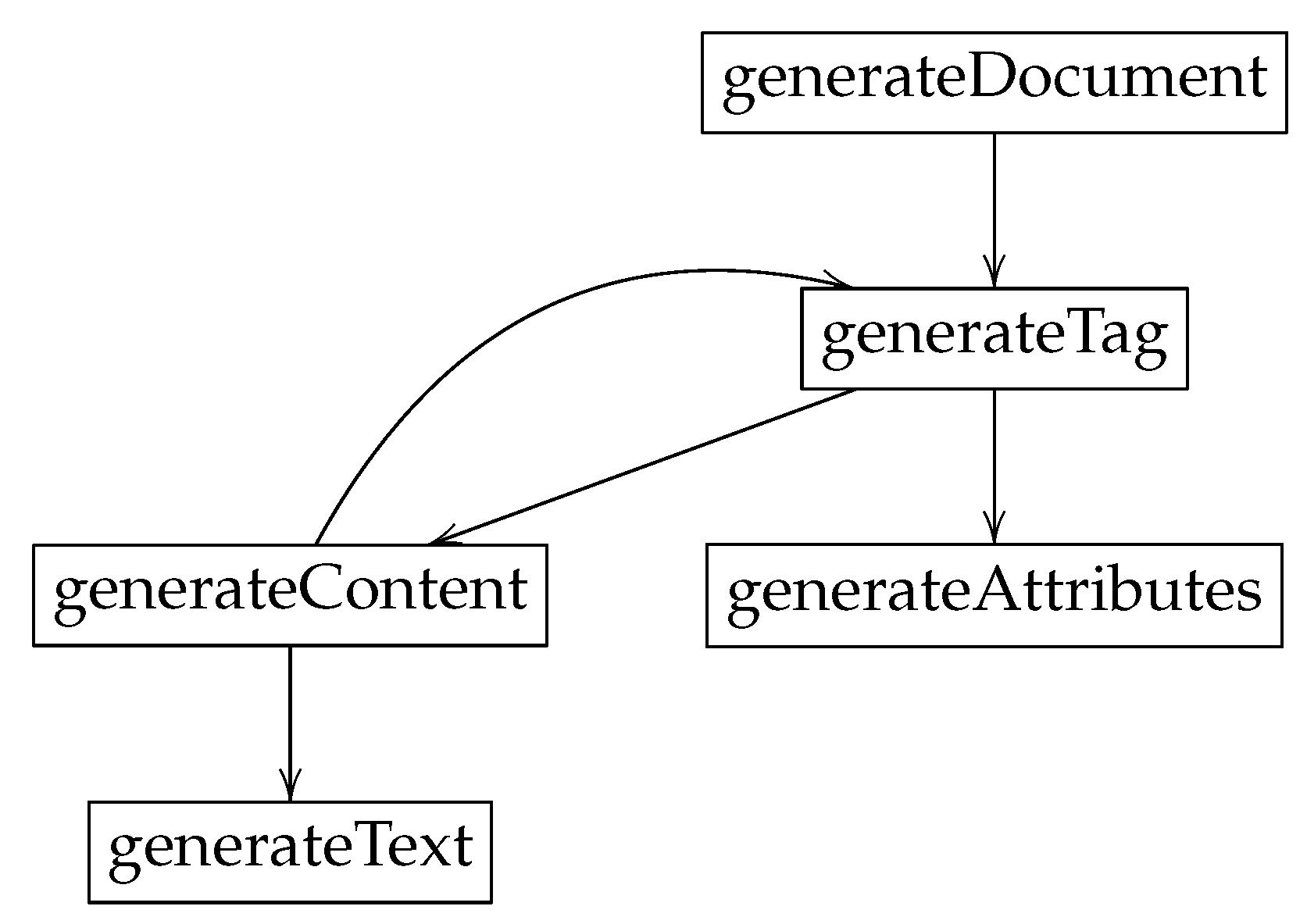
The transformation module defines 7 templates (template) and 2 queries (query). The structure of document generation can be seen in the
Figure 6.
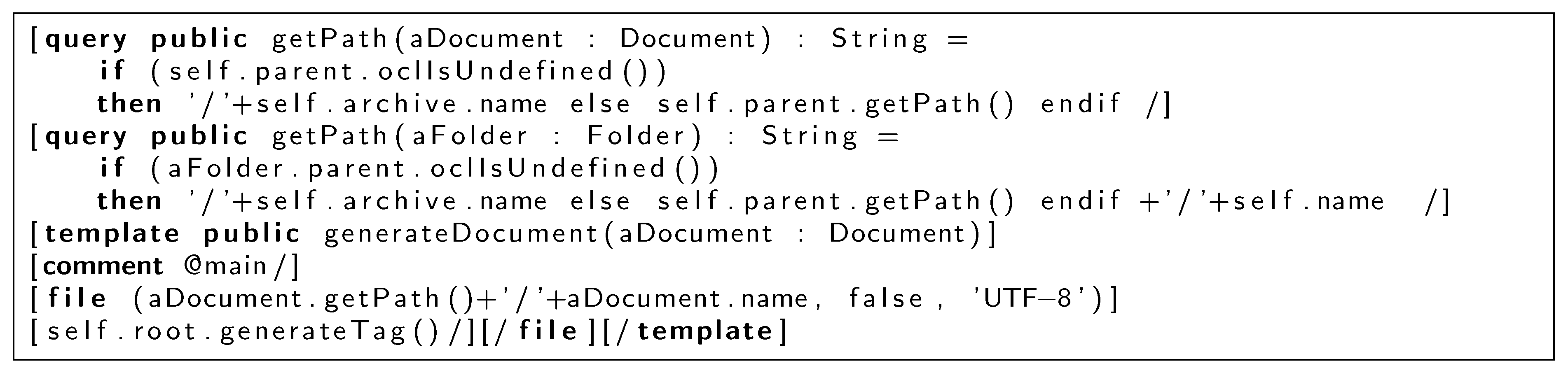
Figure 7 shows the code in ACCELEO of the transformation of an XML document described in a TagML model. This code template generates the file that will contain the XML document. The calculation of the file name is calculated with the query getPath (). In addition, it starts the code generation of the tags, starting with the root tag.
The
Figure 8 shows the code related to the generation of labels. This code is responsible for generating the code associated with a label, the attributes associated with it and the recursive call to the nested labels.
To generate the code of the attributes, the code is shown in
Figure 9.
The recursive call to generate the nested tags is carried out by calling the polymorphic function generateContent in FolderContent. This function which distributes its execution according to the type of element that is treated. If it is a label, then the function generateTag shown in
Figure 8 is executed. Otherwise, the function generateText that can be seen in
Figure 10 is executed. This function generates the content associated with a plain text.
3.3. Implementation Issues
Both, the TagML model editor and the M2T transformation, have been developed as Eclipse plugins. These plugins were developed with the Eclipse Modeling Framework (EMF) technology. The use of EMF ensures that these tools follow the standards of the Object Management Group (OMG) ensuring their interoperability with third-party tools.
Developing tools such as Eclipse plugins has certain advantages with respect to the development of ad-hoc environments. The first one is to have a multi-platform development environment. In addition, we can mention the inherited functionality of the environment, which, for example, provides management of workspaces, projects, files, configuration for the user, custom text editors, integration with third-party tools, management of plugins configuration, management of tasks, model management, and so forth.
3.4. Extensions
The TagML meta-model enables developers to represent XML documents that are part of a document structure where XML documents are transformed into files organized in folders. This meta-model defines two types of document contents: tags and free text. However, XML documents allow other types of content other than just tags or free text (e.g., comments, cdata, xml version, etc.) which are not explicitly defined in the meta-model. This fact leads to the use of free text type to represent these characteristics; for instance, you can represent a comment using an instance of Text which content is . Although it is a valid approach; it is not a good one because the advantages of using TagML are not applied to these elements.
A good approach to solve this issue begins with the definition of new sub-meta-class of the TagContent meta-class (e.g.,
Comment) defining the
content:EString attribute to represent the comment contents (without the stating and ending marks). Then, it continues with the overload of the
generateContent template method following the pattern defined in
Figure 10 and
Figure 11 as seen on
Figure 12. Finally, regenerate EMF plugin and compile the model-to-text transformation to support comments. Note that the same approach can be used to extend the language to any structure.
4. Case Study
Once defined the meta-model that allows to model collections of XML documents, and the transformation that allows the generation of the code associated with these models, we proceed to show a case study to demonstrate the versatility of the proposed generation method.
The case study described in this section, is a generator of Web documents in XHTML from a UML class model [
34,
35].
Figure 13 presents an example of an input model that defines 3 classes. This model has been generated with the Papyrus tool [
36].
Figure 14 shows the result of applying the transformation method proposed in the
Section 3.
As seen in the
Section 3, the process defines two phases. While the first phase requires the definition of an M2M transformation of the PSM to a TagML model, the second one does not require any intervention from the developer being fully automatic and independent of the PSM. Therefore, we will focus on the definition of the first transformation.
The first step in defining the first transformation is to identify the meta-input and output models. In this case they are UML and TagML.
To define this transformation we used ATL [
22] which is a declarative language to define model-to-model transformations. However, you can use any other, for example, QVT [
21]. The reason for this is that the model-to-text transformation is carried out from the TagML model.
The code shown in
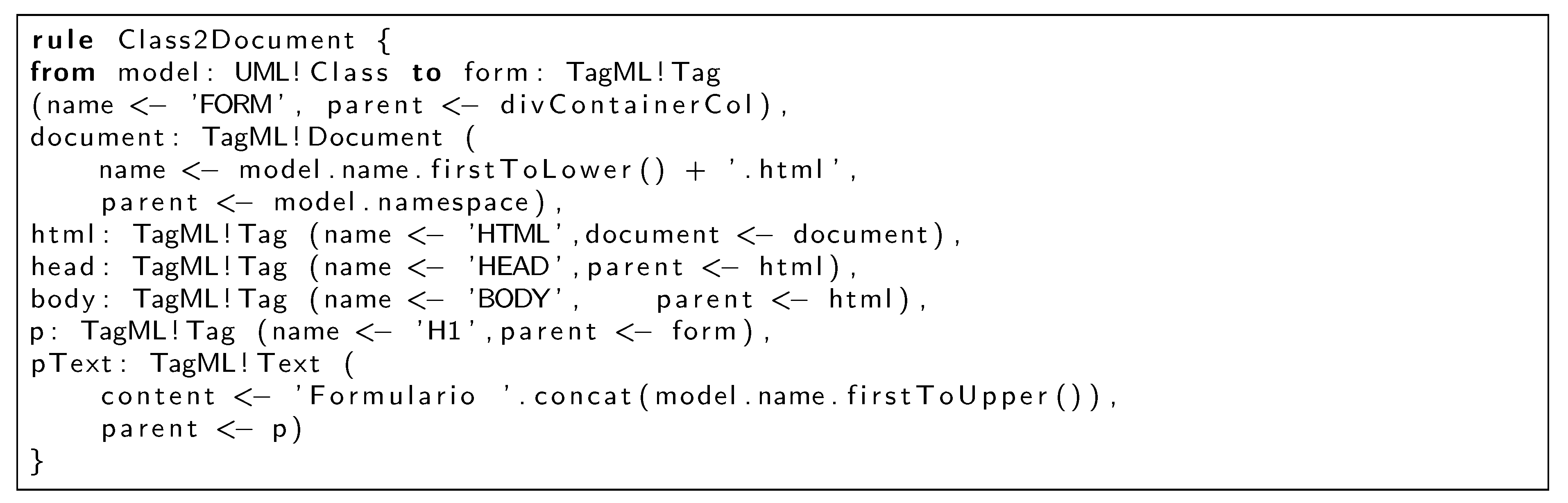
Figure 15 converts the instance of Model into an Archive instance and the Package instance into Folder instances.
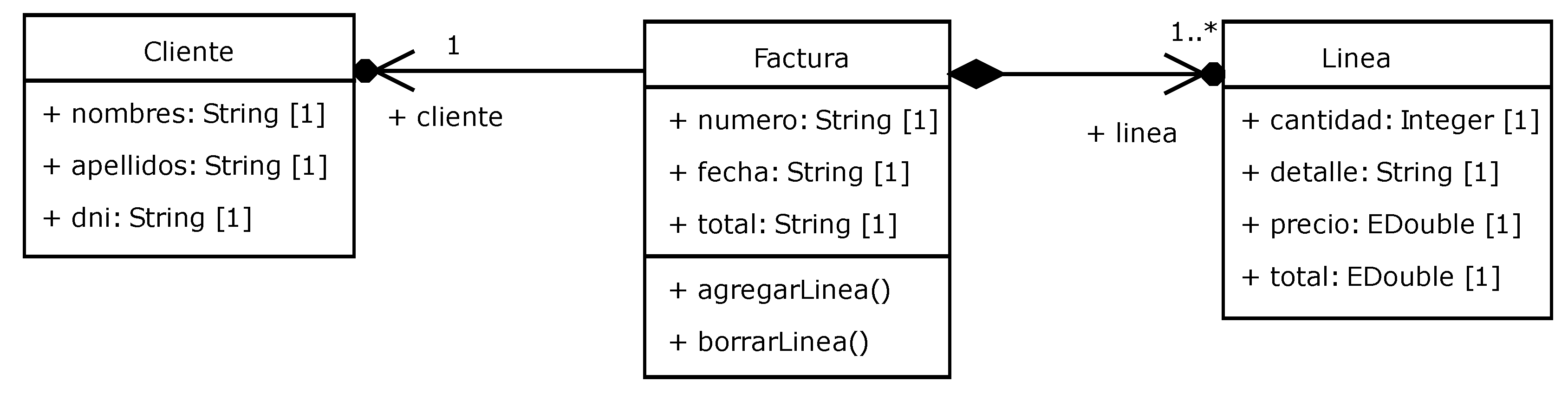
Figure 16 shows the most relevant lines of code of how classes are converted to documents.
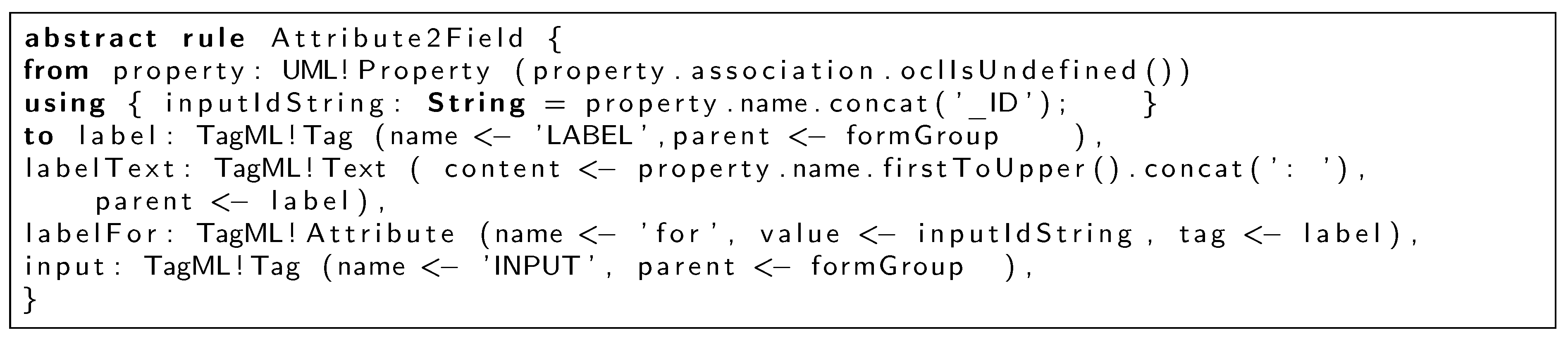
The code in
Figure 17 shows the rule that transforms the properties of a class into the fields of the form associated to the class.
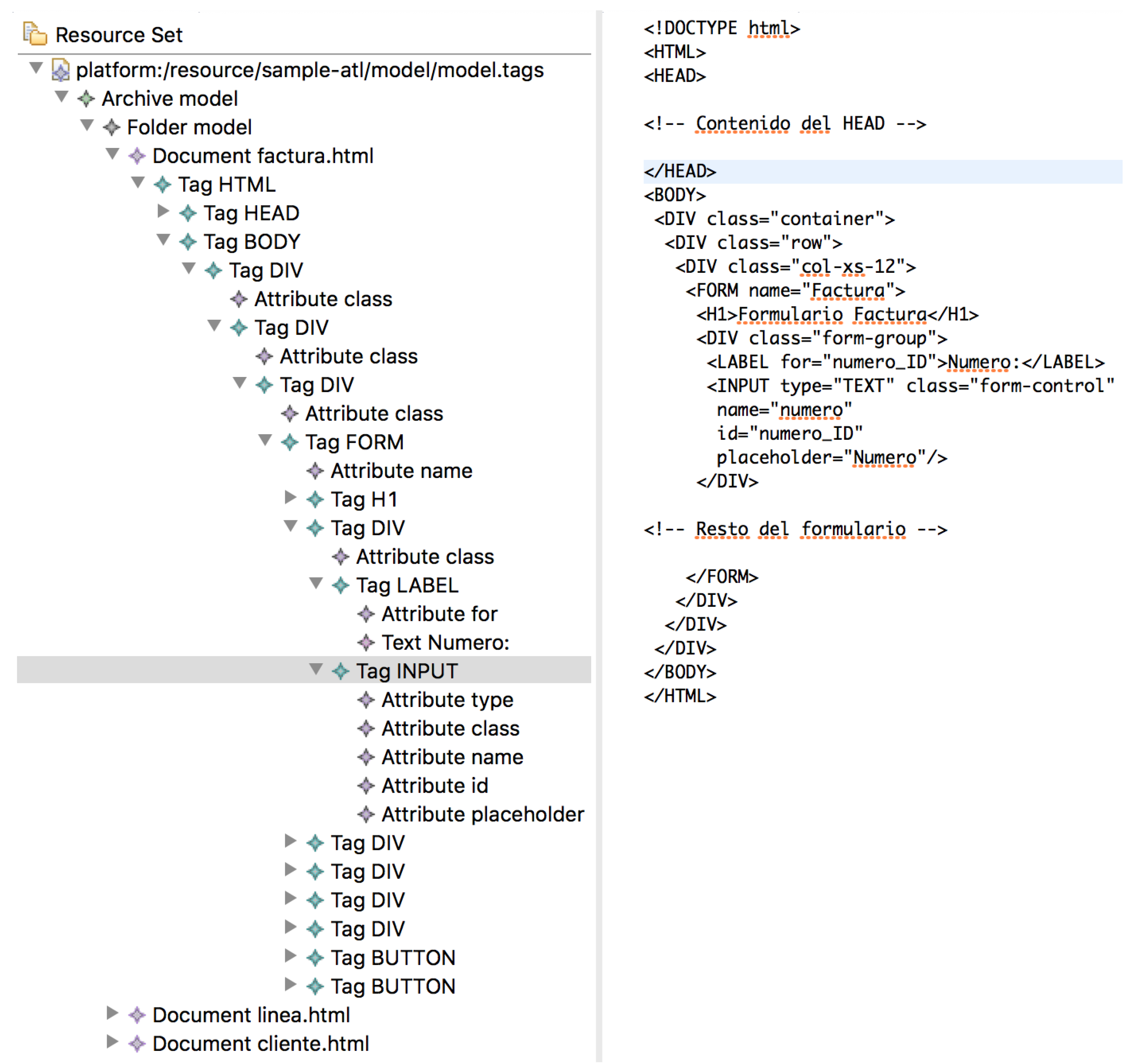
The model resulting from executing the transformations can be seen in
Figure 18. The result of the M2M transformation can be seen in the left half of
Figure 18. In it, you can see that the root node is an instance of Archive. This node contains the model folder, which is an instance of Folder. Inside the folder model you can see three documents (Document instances): invoice.html, linea.html and client.html. The content of the document factura.html defines a set of labels that make up its structure. In this case, we can see the labels that present the branch of the tree that contain the form that corresponds to the class Invoice. An extract of the result of the M2T transformation is shown in the left half of
Figure 18. In this extract you can see the correspondence of the Tag instances and the generated XML tags.
For instance, an example of the benefit of employing this approach from the maintainability perspective is the simplicity of changing tag delimiters (i.e., “<”, “>”, “/>” by “[”, “]” and “/]”) by duplicating the proposed transformation and performing a small modification of 4 characters in lines 2, 3 and 6 of the code presented in
Figure 8. This fact reduces maintainability costs because all models represented with the proposed meta-model can be reused to generate the same documents suing a different format without changing XML document models at all.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
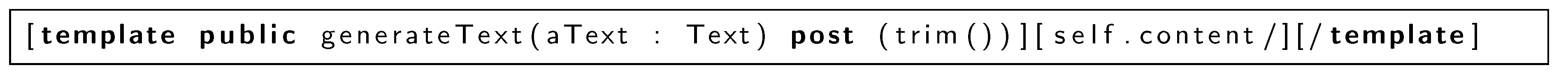{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















