MDEAN: Multi-View Disparity Estimation with an Asymmetric Network

 and
and
Abstract
1. Introduction
2. Related Work
2.1. Monocular Depth Estimation
2.2. Multi-View Depth Estimation
2.3. Depth Estimation
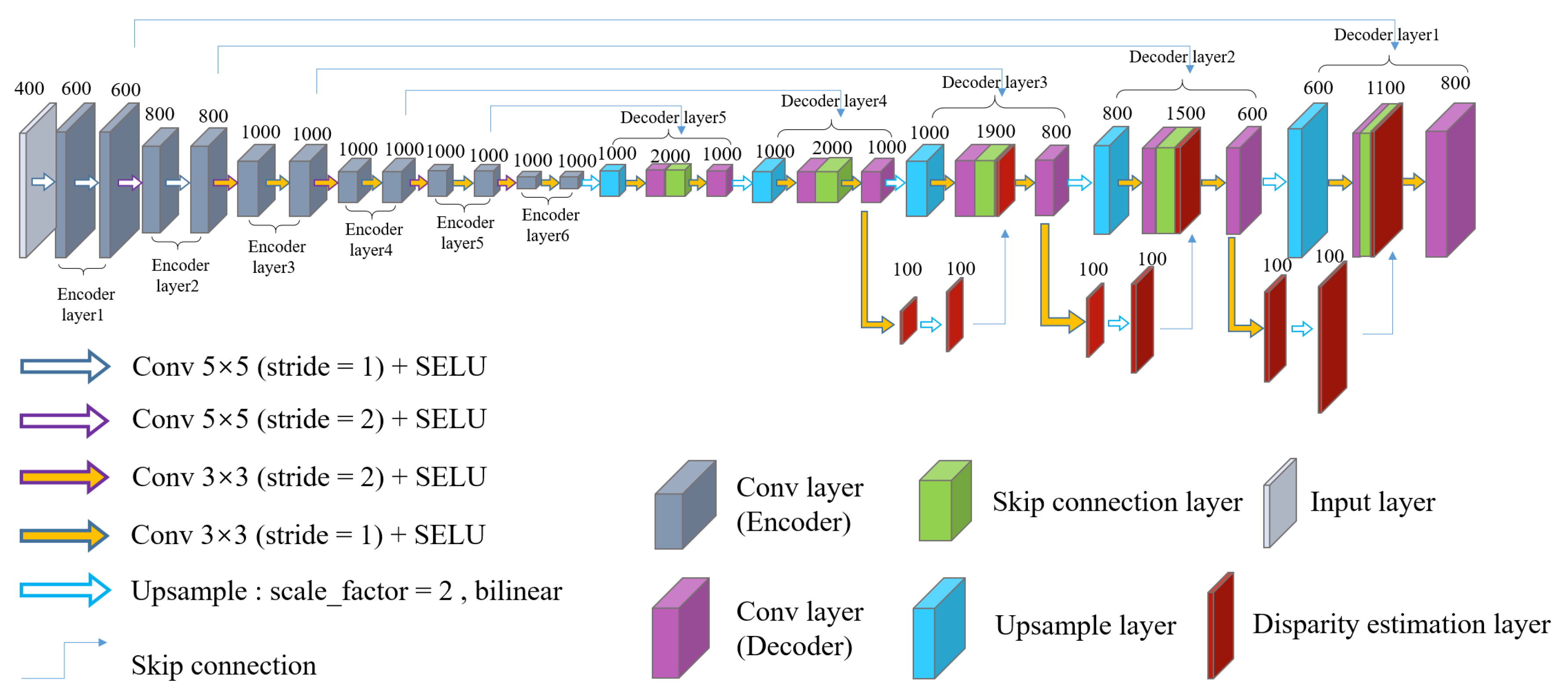
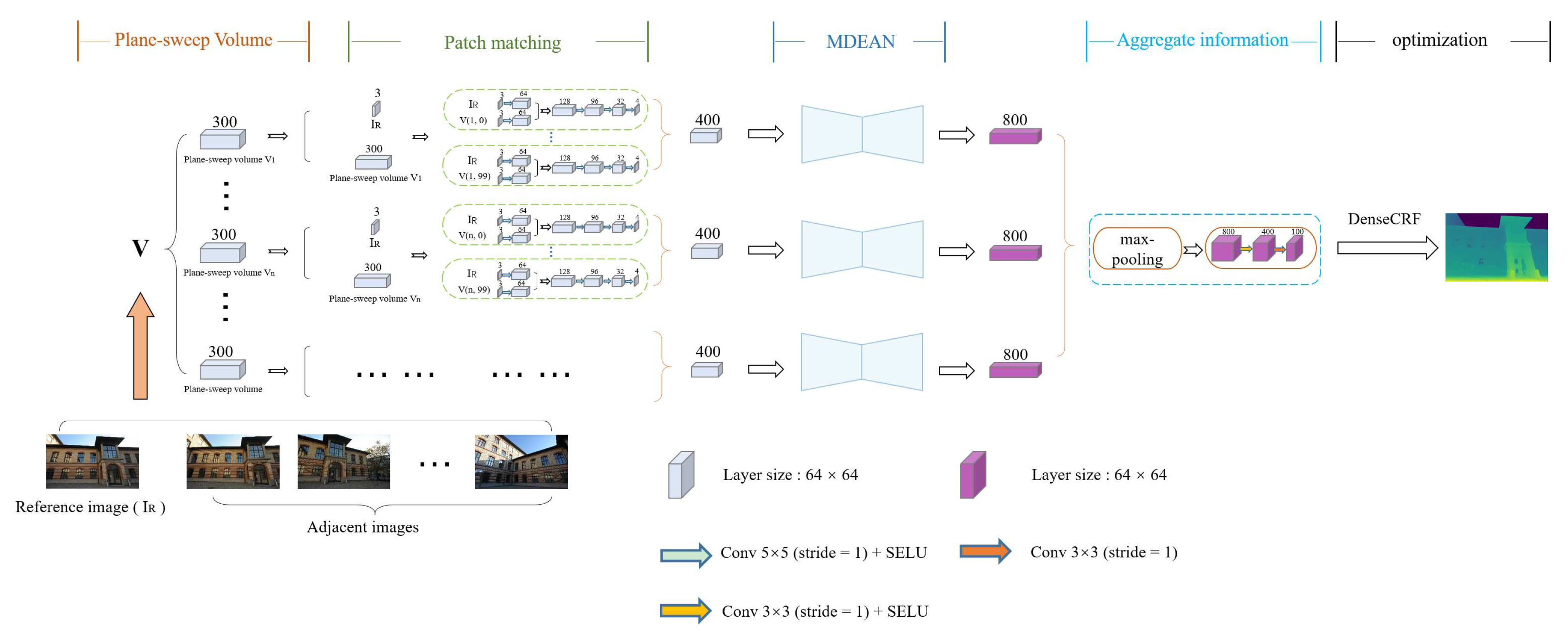
3. MDEAN
3.1. Problem Definition
3.2. Network Input
3.3. Architecture of MDEAN
| Algorithm 1 Disparity estimation algorithm based on an asymmetric structure. |
| Use COLMAP [17] to generate camera internal parameters and poses using an image sequence; Construct plane-sweep volumes of adjacent images and the reference image; Input the reference image, plane-sweep volumes of adjacent images, and ground truth disparity maps of the reference image to the network; while iterations t < do for each minibatch(=1) from the training set do for each adjacent volume of the reference image do for each layer in the volume do Each layer is convolved with the reference image to generate a 4-channel volume shown in Figure 4; end for Stack all generated volumes; Disparity estimation is carried out by the MDEAN shown in Figure 3 and generate a volume containing disparity; end for Aggregate information from any number of volumes using max-pooling operation and extract features by convolution to generate the disparity map; Calculate the loss according to Equation (1) and the ground truth disparity maps, and perform back propagation to update each weight w in the network. end for end while |
4. Results
4.1. Dataset
4.2. Experimental Details
4.3. Evaluation Method
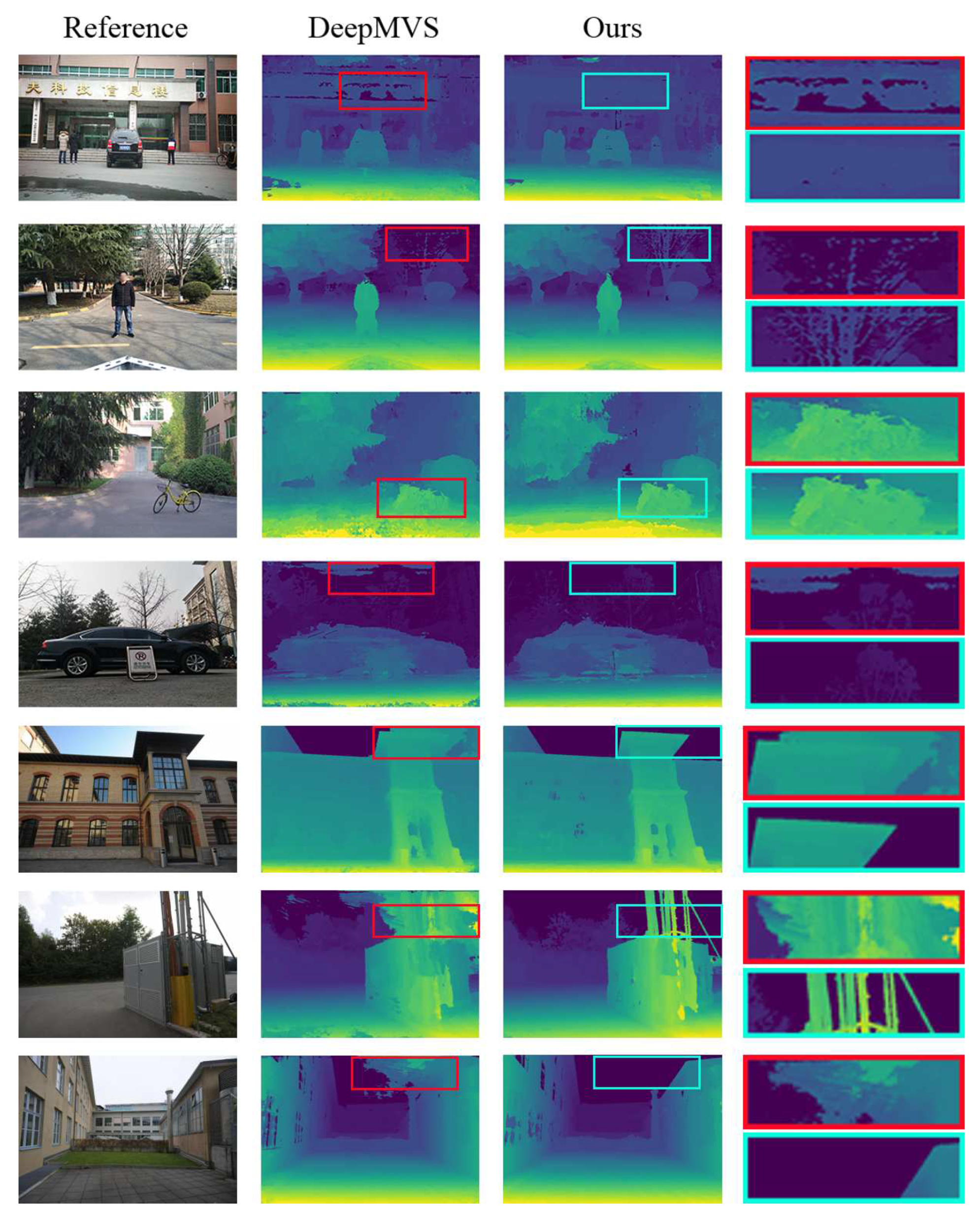
4.4. Evaluation Results
4.5. Ablation Studies
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MDEAN | Multi-View Disparity Estimation with an Asymmetric Network |
References
- Szeliski, R. Structure from motion. In Computer Vision; Springer: London, UK, 2011; pp. 303–334. [Google Scholar]
- Kang, L.; Wu, L.; Yang, Y.H. Robust multi-view l2 triangulation via optimal inlier selection and 3d structure refinement. Pattern Recognit. 2014, 47, 2974–2992. [Google Scholar] [CrossRef]
- Im, S.; Jeon, H.G.; Lin, S.; Kweon, I.S. DPSNet: End-to-end Deep Plane Sweep Stereo. arXiv 2019, arXiv:1905.00538. [Google Scholar]
- Furukawa, Y.; Hernández, C. Multi-view stereo: A tutorial. Found. Trends® Comput. Graph. Vis. 2015, 9, 1–148. [Google Scholar] [CrossRef]
- Langguth, F.; Sunkavalli, K.; Hadap, S.; Goesele, M. Shading-aware multi-view stereo. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 469–485. [Google Scholar]
- Kim, H.; Hilton, A. Block world reconstruction from spherical stereo image pairs. Comput. Vis. Image Underst. 2015, 139, 104–121. [Google Scholar] [CrossRef]
- Häne, C.; Zach, C.; Cohen, A.; Pollefeys, M. Dense semantic 3d reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1730–1743. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, S.; Snavely, N.; Simon, I.; Seitz, S.M.; Szeliski, R. Building rome in a day. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 72–79. [Google Scholar]
- Li, X.; Wu, C.; Zach, C.; Lazebnik, S.; Frahm, J.M. Modeling and recognition of landmark image collections using iconic scene graphs. In Proceedings of the European Conference on Computer Vision, Palais des Congrès Parc Chanot, Marseille, France, 12–18 October 2008; pp. 427–440. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yin, S.; Qian, Y.; Gong, M. Unsupervised hierarchical image segmentation through fuzzy entropy maximization. Pattern Recognit. 2017, 68, 245–259. [Google Scholar] [CrossRef]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Feng, Y.; Liang, Z.; Liu, H. Efficient deep learning for stereo matching with larger image patches. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics, Shanghai, China, 14–16 October 2017; pp. 1–5. [Google Scholar]
- Huang, P.H.; Matzen, K.; Kopf, J.; Ahuja, N.; Huang, J.B. DeepMVS: Learning Multi-view Stereopsis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2821–2830. [Google Scholar]
- MMayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Frahm, J.M.; Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 10–16 October 2016; pp. 501–518. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the Advances in Neural Information Processing Systems, Palais des Congrès de Montréal, Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6602–6611. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3d: Learning 3d scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 824–840. [Google Scholar] [CrossRef] [PubMed]
- Ji, R.; Cao, L.; Wang, Y. Joint depth and semantic inference from a single image via elastic conditional random field. Pattern Recognit. 2016, 59, 268–281. [Google Scholar] [CrossRef]
- Mancini, M.; Costante, G.; Valigi, P.; Ciarfuglia, T.A.; Delmerico, J.; Scaramuzza, D. Toward domain independence for learning-based monocular depth estimation. IEEE Robot. Autom. Lett. 2017, 2, 1778–1785. [Google Scholar] [CrossRef]
- Li, B.; Dai, Y.; He, M. Monocular depth estimation with hierarchical fusion of dilated cnns and soft-weighted-sum inference. Pattern Recognit. 2018, 83, 328–339. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, C.; Yang, J.; Tai, Y.; Chen, L. Deep hierarchical guidance and regularization learning for end-to-end depth estimation. Pattern Recognit. 2018, 83, 430–442. [Google Scholar] [CrossRef]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Furukawa, Y.; Curless, B.; Seitz, S.M.; Szeliski, R. Towards internet-scale multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1434–1441. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-End Learning of Geometry and Context for Deep Stereo Regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar]
- Pizzoli, M.; Forster, C.; Scaramuzza, D. REMODE: Probabilistic, monocular dense reconstruction in real time. In Proceedings of the International Conference on Robotics and Automation, Hong Kong, China, 31 May–5 June 2014; pp. 2609–2616. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 785–801. [Google Scholar]
- Ummenhofer, B.; Zhou, H.; Uhrig, J.; Mayer, N.; Ilg, E.; Dosovitskiy, A.; Brox, T. Demon: Depth and motion network for learning monocular stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5622–5631. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8934–8943. [Google Scholar]
- Shi, J.; Jiang, X.; Guillemot, C. A framework for learning depth from a flexible subset of dense and sparse light field views. IEEE Trans. Image Process. 2019, 28, 5867–5880. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Jiang, X.; Guillemot, C. A learning based depth estimation framework for 4D densely and sparsely sampled light fields. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 2257–2261. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 971–980. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 109–117. [Google Scholar]
- Schops, T.; Schonberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A Multi-view Stereo Benchmark with High-Resolution Images and Multi-camera Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2538–2547. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Fuhrmann, S.; Langguth, F.; Goesele, M. MVE: A multi-view reconstruction environment. In Proceedings of the Eurographics Workshop on Graphics and Cultural Heritage, Darmstadt, Germany, 6–8 October 2014; pp. 11–18. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Metric | L1-inv | L1-rel | SC-inv | |
|---|---|---|---|---|
| Algorithm Error Metric | ||||
| DeMoN | 0.259 | 0.300 | 0.110 | |
| COLMAP | 0.051 | 0.392 | 0.306 | |
| DeepMVS | 0.048 | 0.285 | 0.215 | |
| MVSNet | 0.199 | 1.695 | 0.503 | |
| DPSNet | 0.052 | 0.760 | 0.624 | |
| ours | 0.044 | 0.220 | 0.209 | |
| Range Transformation Method | |||||
|---|---|---|---|---|---|
| Error Metric | L1-inv | L1-rel | SC-inv | Sum | |
| Algorithm | |||||
| DeMoN | 1 | 0.054 | 0 | 1.054 | |
| COLMAP | 0.033 | 0.117 | 0.381 | 0.531 | |
| DeepMVS | 0.019 | 0.044 | 0.204 | 0.267 | |
| MVSNet | 0.721 | 1 | 0.764 | 2.485 | |
| DPSNet | 0.037 | 0.366 | 1 | 1.403 | |
| ours | 0 | 0 | 0.192 | 0.192 | |
| Z-Score Standardization Method | |||||
| DeMoN | 1.731 | −0.597 | −1.214 | −0.08 | |
| COLMAP | −0.667 | −0.419 | −0.121 | −1.207 | |
| DeepMVS | −0.701 | −0.626 | −0.628 | −1.955 | |
| MVSNet | 1.039 | 2.102 | 0.976 | 4.117 | |
| DPSNet | −0.655 | 0.293 | 1.650 | 1.288 | |
| ours | −0.747 | −0.752 | −0.662 | −2.161 | |
| Error Metric | L1-inv | L1-rel | SC-inv | |
|---|---|---|---|---|
| Components | ||||
| AL | 0.059 | 0.692 | 0.395 | |
| AL+DenseCRF | 0.051 | 0.490 | 0.281 | |
| AL+disp | 0.056 | 0.322 | 0.283 | |
| Sym+disp+DenseCRF | 0.050 | 0.332 | 0.251 | |
| AL+disp+DenseCRF | 0.044 | 0.220 | 0.209 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pei, Z.; Wen, D.; Zhang, Y.; Ma, M.; Guo, M.; Zhang, X.; Yang, Y.-H. MDEAN: Multi-View Disparity Estimation with an Asymmetric Network. Electronics 2020, 9, 924. https://doi.org/10.3390/electronics9060924
Pei Z, Wen D, Zhang Y, Ma M, Guo M, Zhang X, Yang Y-H. MDEAN: Multi-View Disparity Estimation with an Asymmetric Network. Electronics. 2020; 9(6):924. https://doi.org/10.3390/electronics9060924
Chicago/Turabian StylePei, Zhao, Deqiang Wen, Yanning Zhang, Miao Ma, Min Guo, Xiuwei Zhang, and Yee-Hong Yang. 2020. "MDEAN: Multi-View Disparity Estimation with an Asymmetric Network" Electronics 9, no. 6: 924. https://doi.org/10.3390/electronics9060924
APA StylePei, Z., Wen, D., Zhang, Y., Ma, M., Guo, M., Zhang, X., & Yang, Y.-H. (2020). MDEAN: Multi-View Disparity Estimation with an Asymmetric Network. Electronics, 9(6), 924. https://doi.org/10.3390/electronics9060924