1. Introduction
Indoor localisation is essential for mobile systems (smartphones, robots, Internet of Things devices, etc.) at several places such as exhibition halls, shopping malls, and office buildings [
1]. Accurate, reliable, and real-time localisation is the basis for automatic navigation and task allocation [
2]. In particular, the easy accessibility of the Global Positioning System (GPS) from mobile devices such as smartphones has enabled travellers to move around the world more freely. However, the GPS is sensitive to occlusion and cannot be accessed from indoor environments. Several indoor localisation systems [
3,
4,
5,
6] with different sensors have been presented. With the pervasive penetration of wireless local area networks and wireless access equipment [
7,
8,
9,
10,
11,
12], Wi-Fi-based indoor localisation [
13] has recently attracted considerable attention. In such localisation systems, the use of fingerprint approaches [
14] based on the received signal strength have shown significant advantages. If a series of physical locations are selected in a workspace, the signals received at these locations from the access points (APs) in the vicinity of the locations are defined as the fingerprints for the locations. Furthermore, the locations for their corresponding fingerprints are defined as reference points (RPs). In the training phase for fingerprint positioning, the received signal strength indication (RSSI) values are acquired at the identified RPs. In the positioning phase, the observed RSSI is used to determine the device location based on a fingerprint map. WiFi-based fingerprint approaches require neither AP locations nor angle measurements of the signal receiver, and therefore, they are highly feasible for indoor localisation. However, several key problems in Wi-Fi-based indoor localisation are yet to be solved. First, the Wi-Fi signal strength is relatively susceptible to multipath effects and external interference. In addition, the presence of noise may cause the received signal strength to deviate from its true value, leading to a large location error. Second, higher localisation accuracy requires faster Wi-Fi scanning and intensive CPU computations, which involve higher energy consumption. Third, most indoor localisation systems have a time-consuming calibration process. An extensive site survey for fingerprint map construction is time-consuming and labour-intensive. Moreover, a change in the spatial distribution or Wi-Fi environment increases the site survey cost. Consequently, it is required to reduce deployment effort during the calibration of maps for indoor Wi-Fi localisation systems.
Different machine learning methods are used for WiFi fingerprinting to build localization models like k-Nearest Neighbours (KNN) [
15], Random forest [
16] and Support Vector Machines (SVM) [
17]. However, these methods can suffer from limitations on their ability to fully to learn complex features from the training data. On the other hand, deep learning (DL) has been widely applied in various fields. Therefore, the recent works on WiFi-based indoor localization started to use DL models to estimate nodes’ locations [
18,
19].
The purpose of an augmentation technique is to increase the number of data according to a given measured training set. In [
20], mean and uniform random number (MURn) augmentation was proposed to generate the training dataset for the convolutional neural network (CNN) model, for achieving optimum performance for WiFi-based fingerprint indoor localisation. The augmented data were subsequently used to enhance the robustness and accuracy of indoor localisation. In our previous study [
21], we employed the data augmentation techniques and resulted in simulation results with the CNN model for indoor positioning. The CNN model was utilized to compare the performance with other CNN applications such as AlexNet, ResNet, ZFNet, Inception v3, and MobileNet v2, for WiFi-based fingerprint datasets. We performed comprehensive testing of our algorithms with these CNN applications to demonstrate the effectiveness of our proposed CNN model.
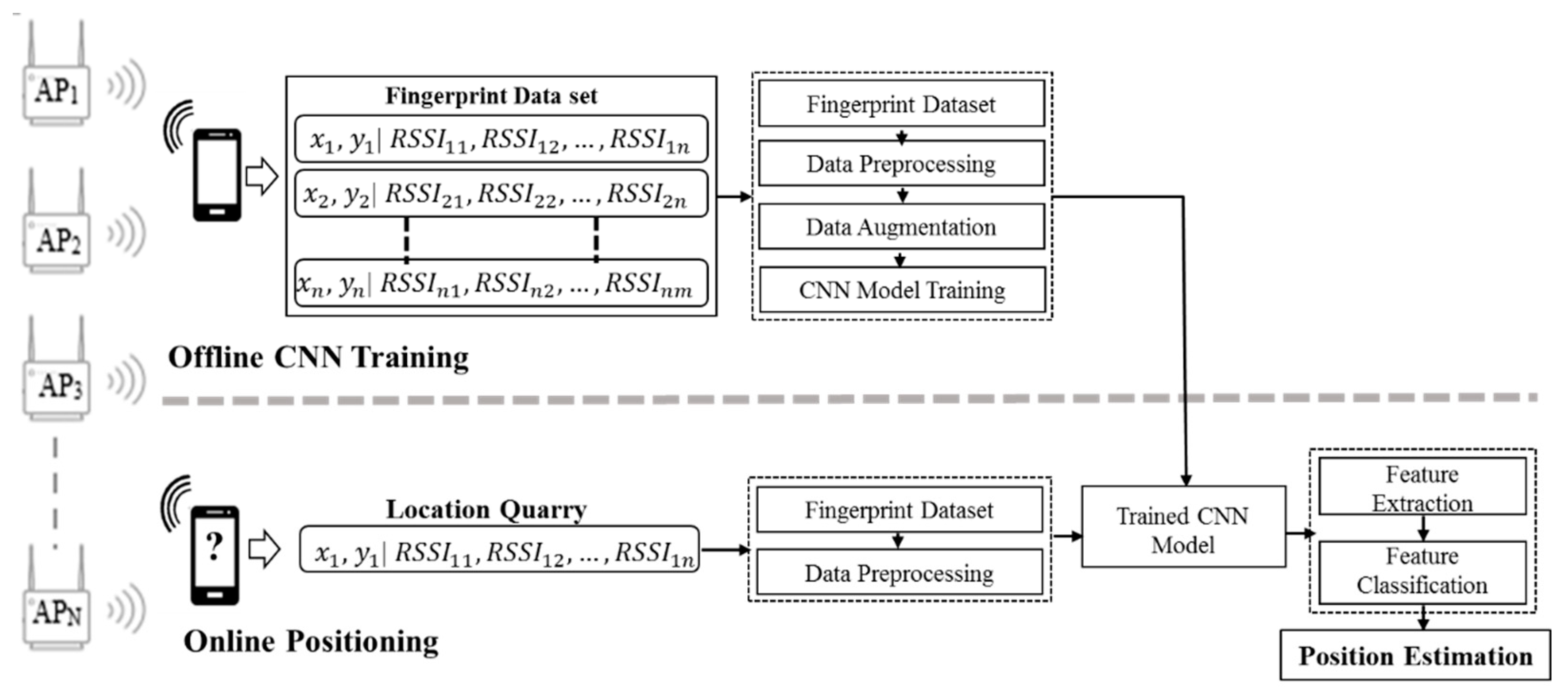
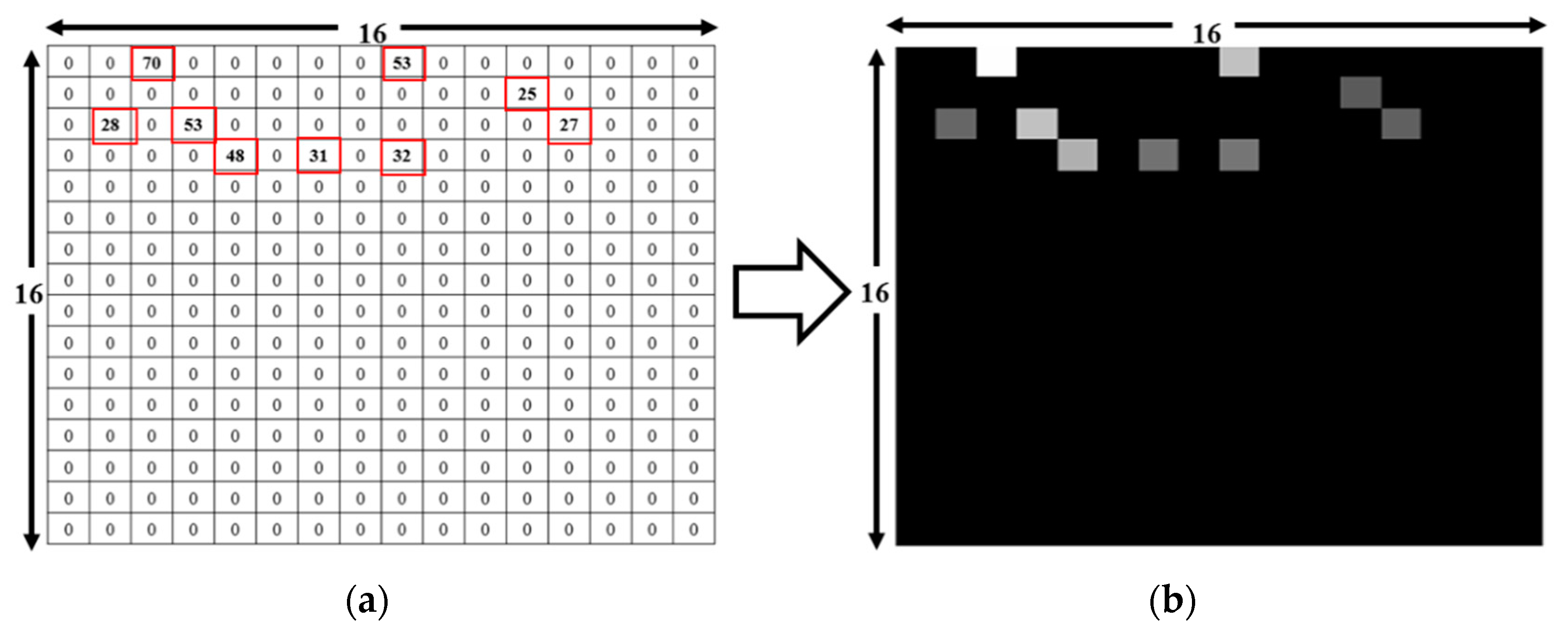
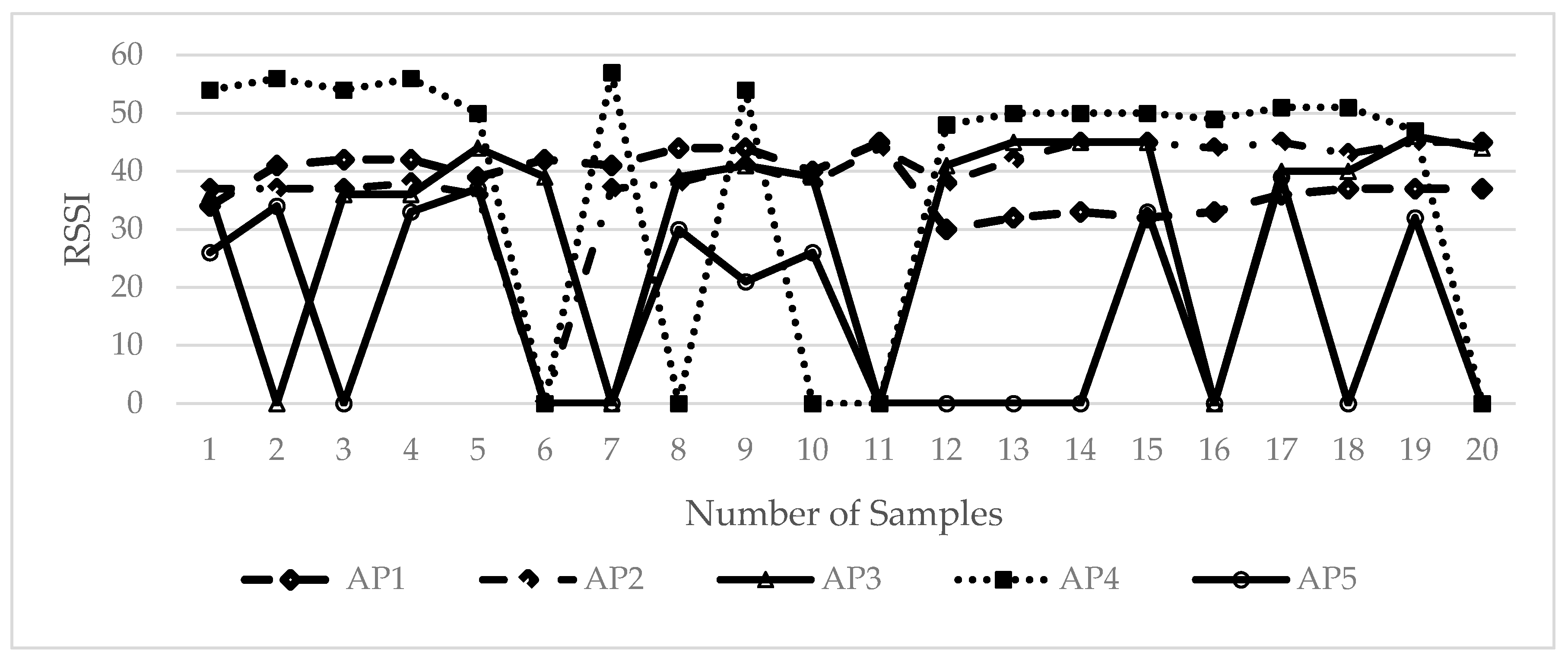
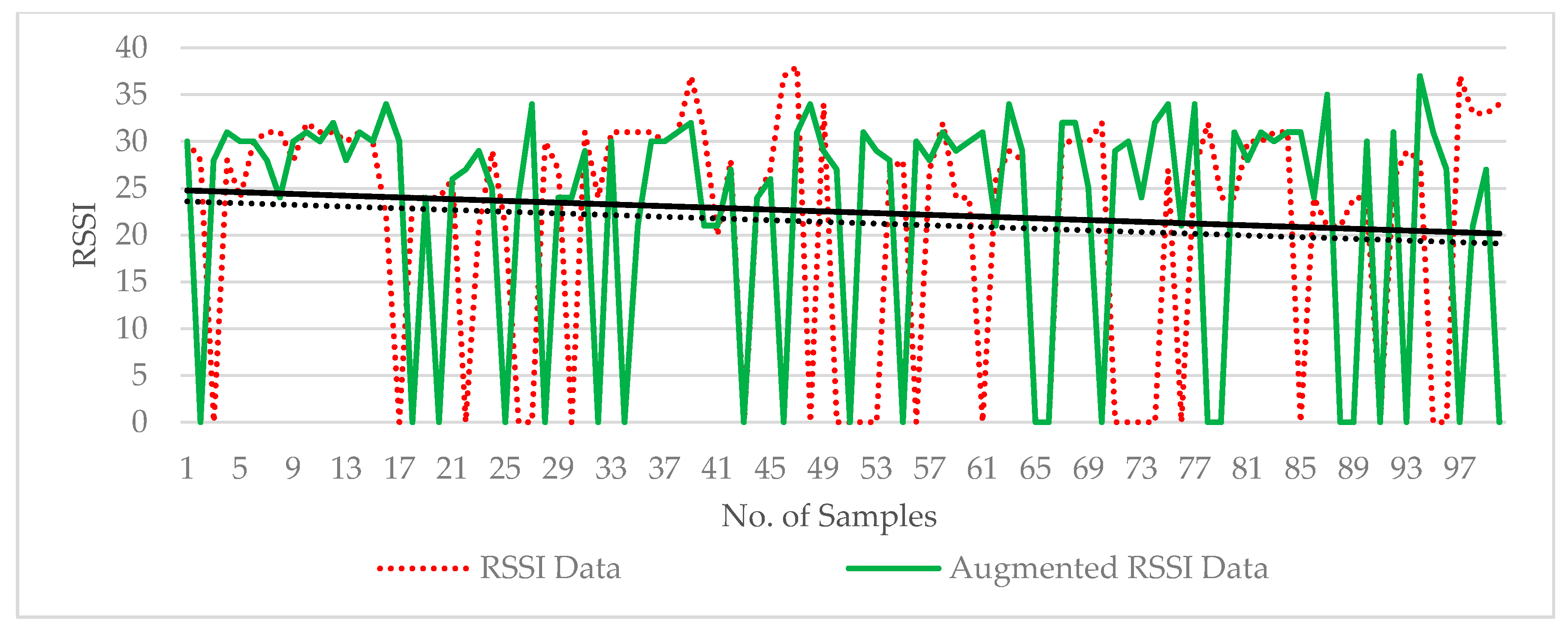
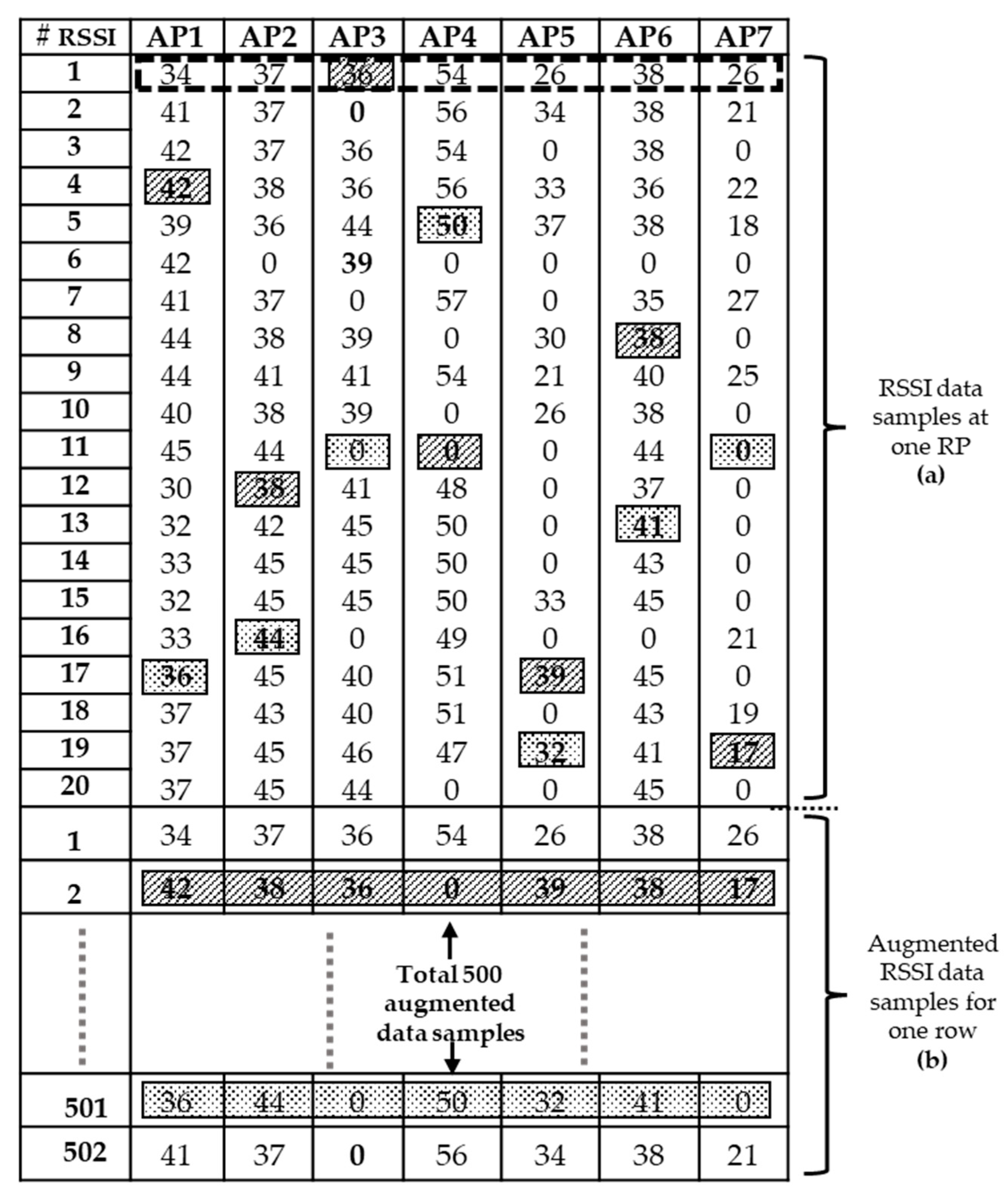
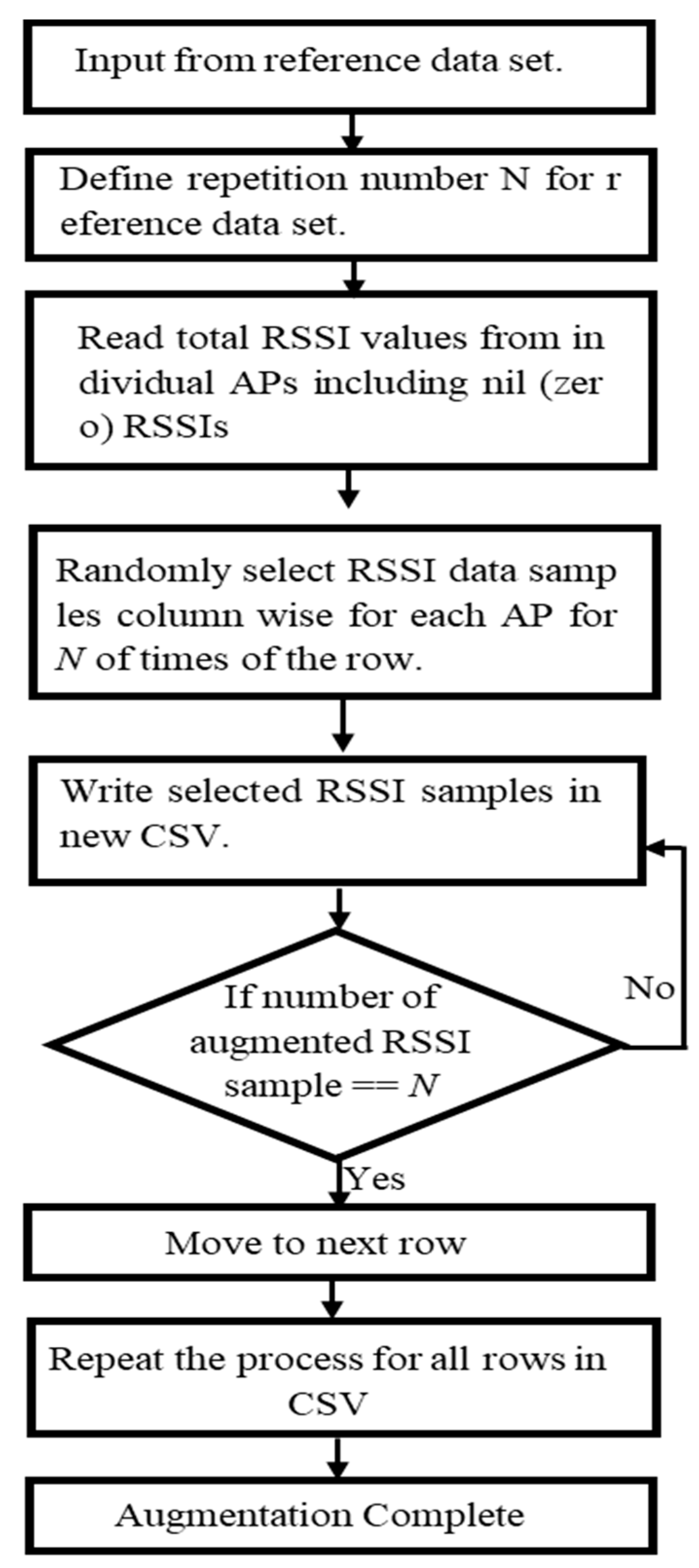
In this study, fingerprint augmentation is conducted for indoor Wi-Fi localisation in order to reduce site survey work and improve the location accuracy in the deployment stage. The RSSI augmentation technique that can be implemented in any deep-learning-based fingerprinting system is proposed. Here, an improved augmentation technique based on RSSI values at APs is introduced. The proposed RSSI-based augmentation is robust, unique and simple to implement, which based on only RSSI values collected at each RP to produce augmented output. The RSSI value present at target RP is randomly selected and written in new output. The robustness lies in the fact that the pattern of augmented output matches with the input RSSI pattern of the target RP. The number of repeated times for random RSSI selection is decided by ‘N’ which is global repetition number. The generated output is based on only target RSSI values for augmentation. Furthermore, we compare the RSSI-based augmentation technique with the MURn augmentation technique with evaluating the performance of the localisation in a six-layer CNN model. The comparison is performed through both laboratory simulation and real-time experiment. The remainder of the paper is structured as follows.
Section 2 describes the background work of this study. The proposed RSSI technique is described in
Section 3, and a system model and an experimental setup are presented in
Section 4.
Section 5 compares the numerical results of the RSSI and MURn augmentation techniques. Finally,
Section 6 concludes the paper.
4. System Model and Experimental Setup
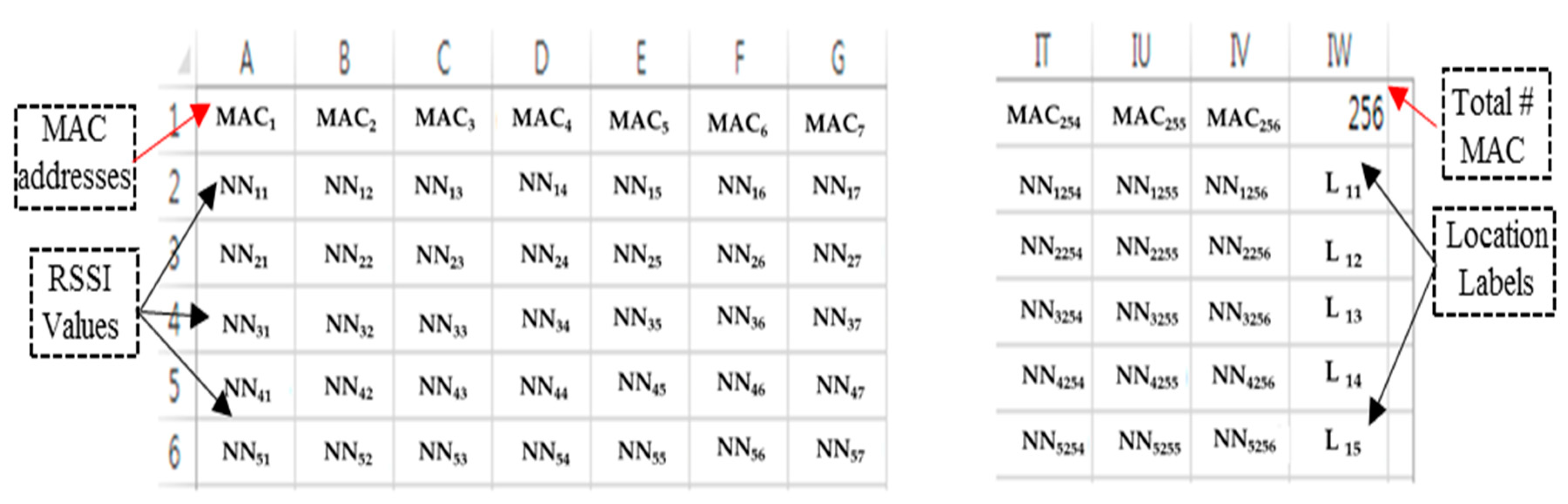
The CSV files used in this study contained 257 columns and 74 RPs in the 257th column; the RPs served as labels. Data conversion was performed using Python. The input for the file converter code (written in Python) comprised folders containing text files. To assess the validity of our approach, we collected seven data sets over a week, which were then used to assess the CNN layer that was best suited to transfer knowledge from classification to indoor positioning as well as to identify the optimal classification algorithm. The results showed that a relatively simple classification model fitted the data well, producing about 95% generalisation over a one-week period in laboratory-based simulations with RSSI augmentation. It was necessary to train the classification model with data reflecting the effect of the introduction of new APs’ and changes in the existing APs. To generate the data set, the data were collected over seven days in four directions namely forward, backward, left and right at the 74 RPs to reflect the dynamic environment on training data set. As summarized in
Table 1, the training data set was collected over two time periods, namely, Morning/Afternoon and Afternoon/Evening to reflect the human activities. The Morning/Afternoon includes 09:30 to 11:30, a highly active period and 12:00 to 14:00, a moderately active period. The Afternoon/Evening covers low to high active time from 14:30 to 16:30 and 17:00 to 19:00. Also, the orientation of the device is kept in four directions to reflect the diversity in the training data set, which considered the diversity of the RSSI values from the surrounding APs with the different directions. Using this training with such data set, the CNN classifier may correctly predict the use position for online experiment, even if the user moves in a slightly or fully left- or right-oriented way. In the real time testing, the movement of people went forward and backward, which was done for five days.
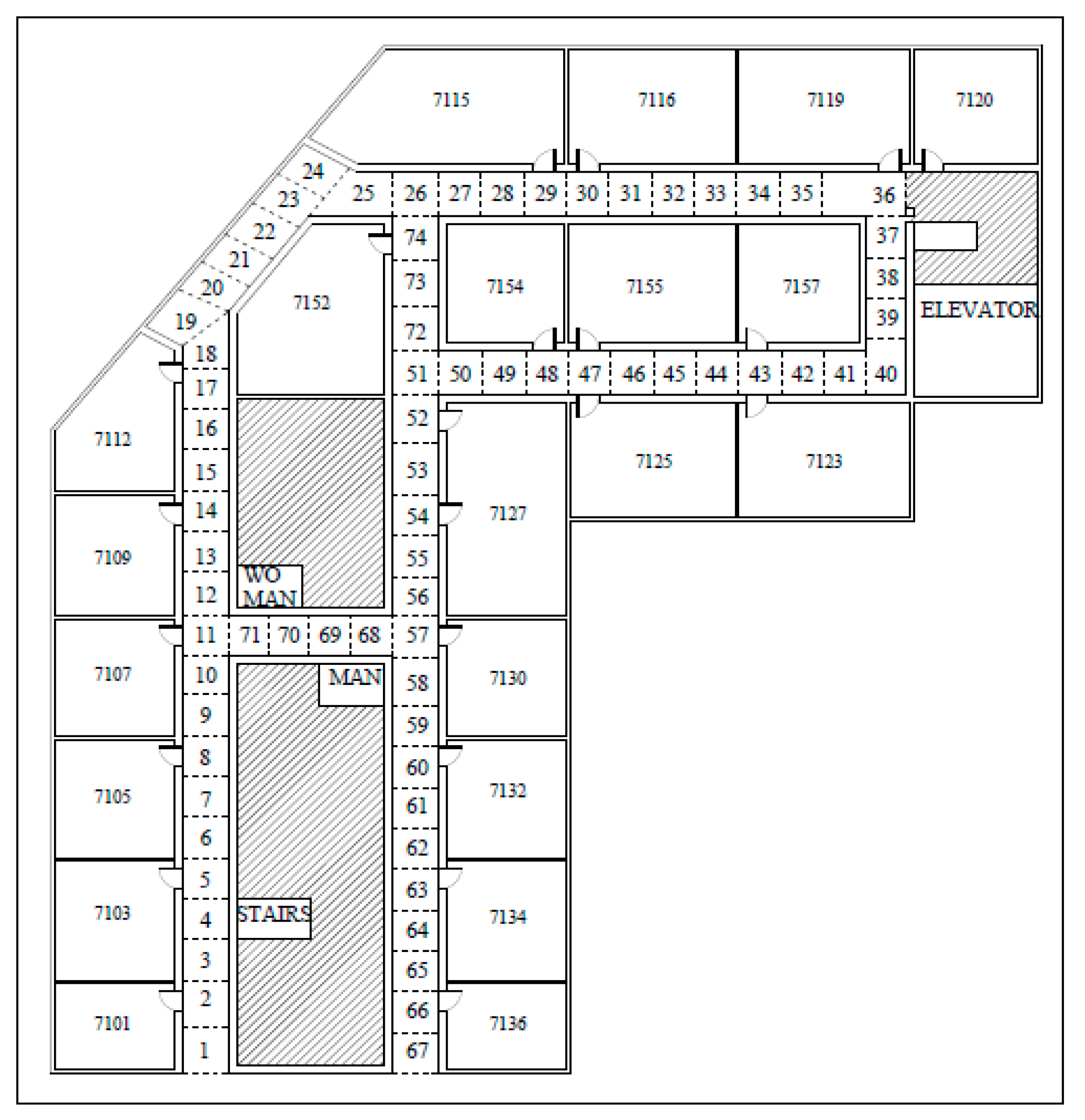
RSSI fingerprint data collection and the final experiment were both performed on the 7th floor of the new engineering building at Dongguk University, Seoul, Korea. As shown in
Figure 9, the 52 × 32 m target area with the roof height of 3 m is divided into 74 target RPs. The RPs such as 1, 25, 36, 40 and 67 are at the corner and their sizes vary between 2 m to 3 m, i.e., +1 m difference. Meanwhile, the RPs such as 10, 11, 18, 50, and 71 are at the ending spot and their sizes vary between 1 m to 2 m, i.e., −1 m difference. Note that the RP block size is approximately 2 m × 2 m while ranging from 1 m to 3 m for specific locations. The positioning server used in this study is a Dell Alienware Model P31E (Alienware, hardware subsidiary of Dell, Miami, FL, USA), and the smartphone for data collection is a Samsung SHV-E310K (chip fabrication Yongin-si, Gyeonggi-do, Korea). The fingerprint database construction, classification (i.e., position prediction), and online experimental setup are developed with Python.
The data read by an Android device were stored in a buffer. If there was an error in the recorded data, an error message was displayed on a serially connected console. Otherwise, the RSSI data were stored in the buffer, and after a complete scan, they were transferred by the Android console, which was connected by an interface cable to the server, to the server through a Wi-Fi AP. The server determines the Android device’s location by comparing the measured RSSI values with reference data. It was serially connected to the Android console and processed the RSSIs obtained from the surrounding APs with its CPU. The operating frequency of the device was 2.412–2.480 GHz for the 802.11bgn wireless standard. The input/output sensitivity was 15–93 dBm.
5. Numerical Results
We compared our RSSI augmentation technique with MURn augmentation. As mentioned in the previous section, the RSSI data samples were collected over seven days. The total number of RSSI data samples for one RP was approximately 130. These RSSI data samples were used as the input image for the augmentation. Few RPs had only 128 or 129 samples since the collected RSSI sample text file sometimes contained no data and was therefore deleted from the data set. The global value of RSSI augmentation was 500, and the total number of images for one RP was about 65,130. A total of 4,819,620 CNN training images were used for the RSSI-based augmentation technique and 596,440 CNN training images were employed for MURn augmentation. The total number of images used for the MURn augmentation technique for the 130 input image files was about 8060. The total number of test images for the laboratory simulations is 1479. The laboratory simulation is a process where the augmented data set is used to train the CNN classifier and the remaining data set is tested by the trained CNN classifier. Meanwhile, real time testing is a process where, with the trained CNN classifier, the user’s position is predicted by using the RSSI dataset received from the APs.
The global repetition number is important when choosing an augmentation technique.
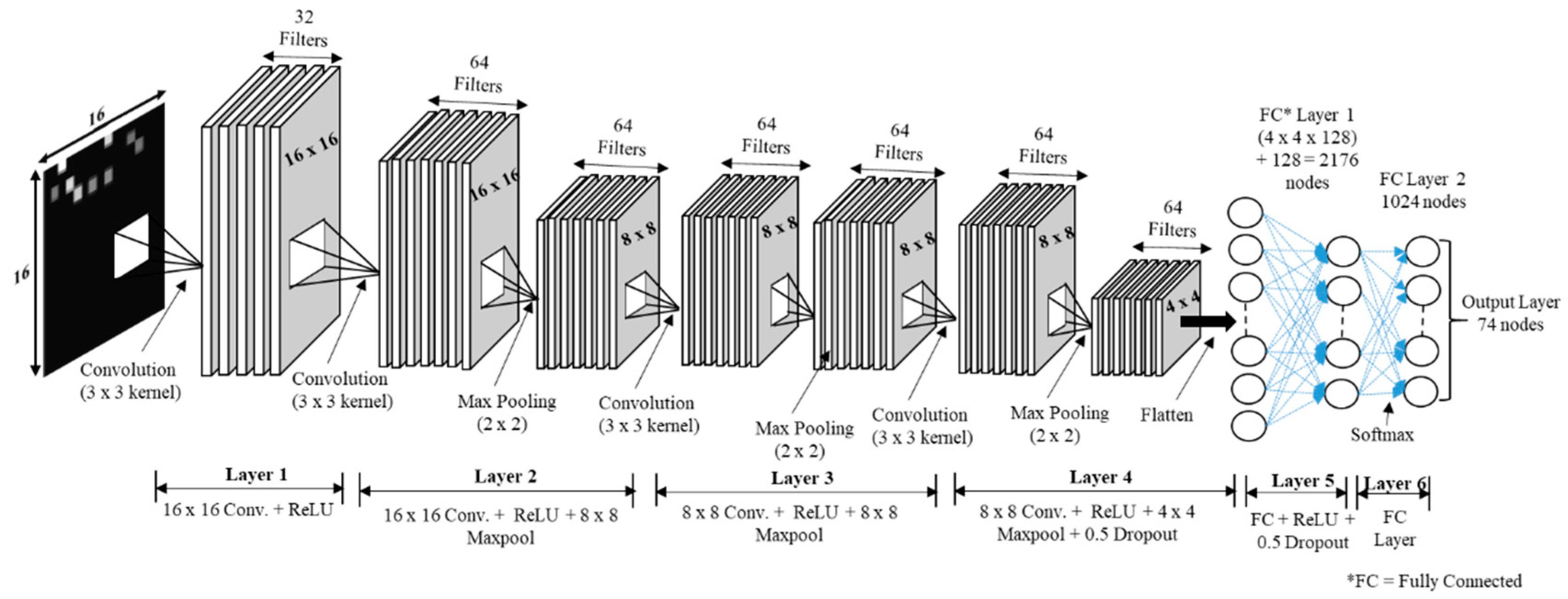
Table 2 shows the impact of N with six different values on the augmentation technique. The value of N determines whether the training of the CNN model is optimised, since it can help the CNN model to learn more efficiently. The training accuracy can be defined in the terms of loss value, which tells how well the CNN classifier learns from the training images to predict the test image correctly for each reference point. The test accuracy indicates how many test data are identified correctly. A higher test accuracy is desirable in accuracy of positioning case since it reflects least error between training and testing environments. With N = 60, the training accuracy of the CNN model is 63.10% for RSSI-based augmentation and 86.99% for MURn augmentation, and the test accuracy is 93.80% and 94.11%, respectively. Similarly, at N = 200 the training accuracy is 61.92% and 83.95% and the test accuracy is 95.06% and 93.78%, respectively. For N = 500, the training accuracy is 63.26% and the test accuracy is 95.26% which is the highest for the RSSI-based augmentation. Meanwhile, the test accuracy for MURn augmentation is as low as 89.04%. Therefore, the RSSI-based augmentation gives an advantage in test accuracy since increasing the data set size can retain the characteristics of the RSSI values for the augmentation.
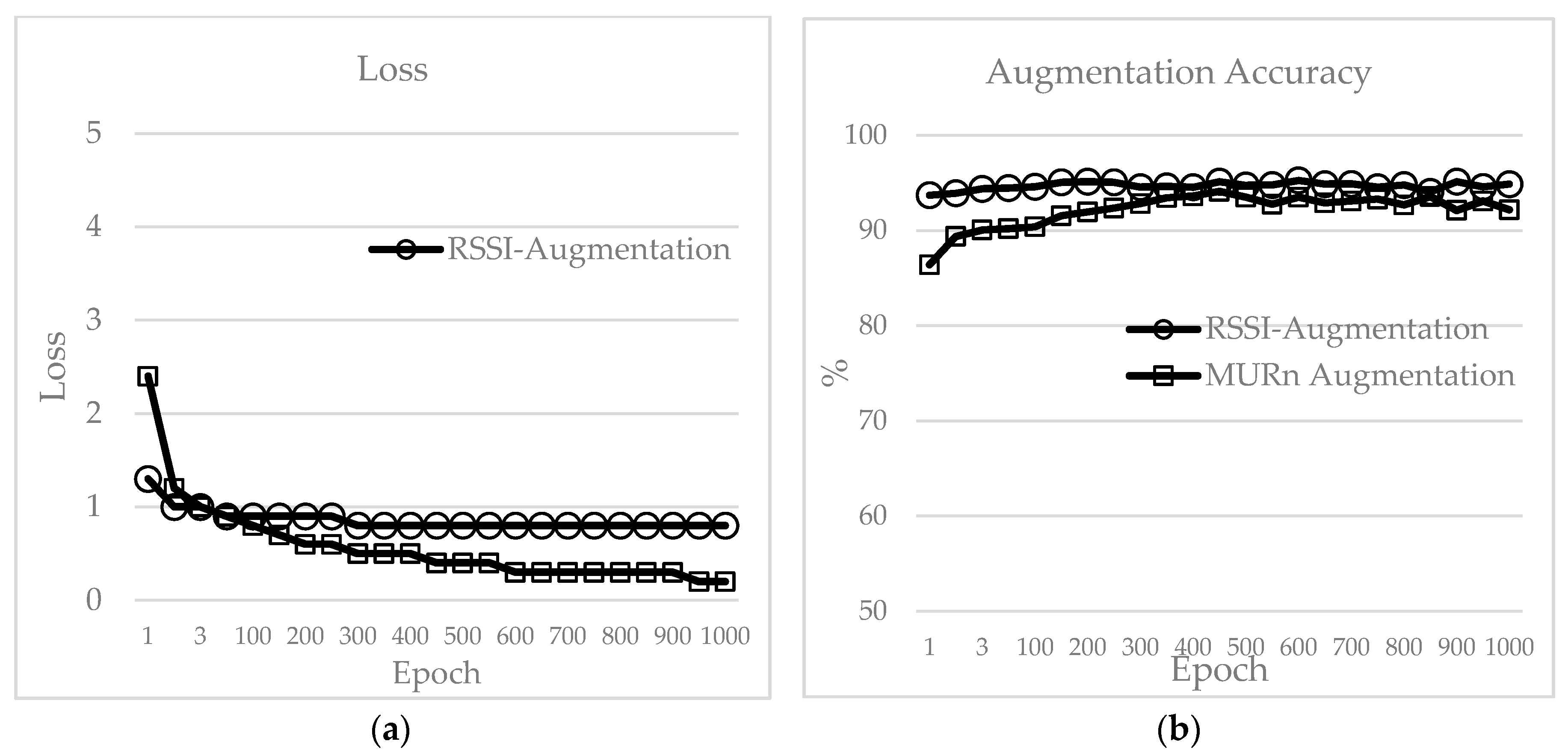
Figure 10a,b shows the laboratory simulation results for the loss and test accuracy of the RSSI augmentation and MURn augmentation techniques. The loss values for RSSI and MURn augmentation start at 1.3 and 2.4, respectively, and they reach to 0.8 and 0.4, at epoch 500, respectively. The loss value after epoch 1000 remains at 0.8 for the RSSI augmentation technique, while for MURn augmentation, the loss reduces to 0.2. The loss decreases after epoch 1000 for MURn, and this shows the robustness of the training data and CNN model. However, the accuracy of the model also decreases, which is undesirable for indoor positioning. The highest accuracy achieved in the laboratory simulations for each of the techniques was used as the optimum value to generate the metafile [
7] for the real-time testing of the techniques. Therefore, the highest accuracies were chosen for the RSSI augmentation and MURn augmentation data sets in this study. The highest accuracy for the RSSI augmentation data set was 95.26%, and it was achieved after epoch 643; the loss value was 0.8. For the MURn augmentation technique, the highest accuracy chosen was 94.44% at epoch 450, and the loss at this point was 0.4. After epoch 1000, the test accuracy of RSSI augmentation remained constant at about 94% (loss: 0.8), while the MURn augmentation accuracy decreased to about 92% (loss: 0.2).
Table 3 summarises the CNN model performance for both augmentation techniques. The longer epoch time of RSSI augmentation compared to that of MURn augmentation was because of the effect of
N (
Table 3). Each collected RSSI sample was repeated N (=500) times, and therefore, the overall data set size increased to 2 GB, thereby increasing the epoch time. Thus, there is a trade-off between the test accuracy and the epoch time in the RSSI augmentation technique.
The number of RPs predicted accurately in the real-time experiment by the CNN model trained with augmented RSSI data sets was called the zero-margin accuracy, i.e., zero meter error. When the predicted test RP matches with neighbouring RP it is called one margin accuracy, i.e., 2 m error. Similarly, when the test RP matches with difference of two RP it is known as two margin accuracy, i.e., 4 m error. A comparison of the real-time prediction accuracies of the CNN mode for different margins and for the two techniques is presented in
Table 4. The model had the highest zero-margin accuracy, 43.78%, for RSSI augmentation, while for MURn augmentation, the zero-margin accuracy was 37.30%, which is lower than that for RSSI augmentation by 6.48%. A two-meter difference between the actual and predicted RP was termed one-margin accuracy. For RSSI augmentation and MURn augmentation, the one-margin accuracy was 83.24% and 75.40%, respectively, is the difference being 7.84%. A difference of four meters between the predicted and actual outputs was called two-margin accuracy. The highest two-margin accuracy for RSSI and MURn augmentation was 94.54% and 92.44%, respectively. Thus, the two-margin accuracy difference between both augmentation techniques was only 2.15%.
An indoor localisation system is best evaluated on the basis of performance statistics by using the mean value, variations, and standard deviation. The mean is the average value of all distance errors in terms of metres for indoor localisation, which is desirable to be as close to zero as possible.
Table 5 shows a comparison of the performance of both augmentation techniques in the laboratory simulation as well as real-time experiment. RSSI augmentation achieved mean errors as low as 1.60 m in the real-time experiment, which is close to the laboratory simulation mean error of 1.45 m. The MURn augmentation mean error was 2.06 m in the real-time experiment and 1.48 m in the laboratory simulation. The mean errors of the two augmentation techniques in the laboratory simulation were very close, while they varied by 0.5 m in the real-time experiment. This variation is continued to be observed in real time and lab simulation for both augmentation results. The RSSI augmentation variation was 3.33 m in the experiment and 3.22 m in the simulation. The variation for MURn augmentation was 5.96 m in the experiment and 5.54 m in the simulation, which was about 2 m higher compared with that for the RSSI augmentation technique. The standard deviation for RSSI augmentation was 1.83 m in the experiment and 1.79 m in the simulation; the values are close to each other. The standard deviations for MURn augmentation in the experiment and simulation were 2.44 and 2.38 m, respectively. The performance in the lab simulation matches with that in the real-time experiment for both augmentation techniques. The RSSI augmentation technique’s performance was better that the MURn augmentation technique’s performance.
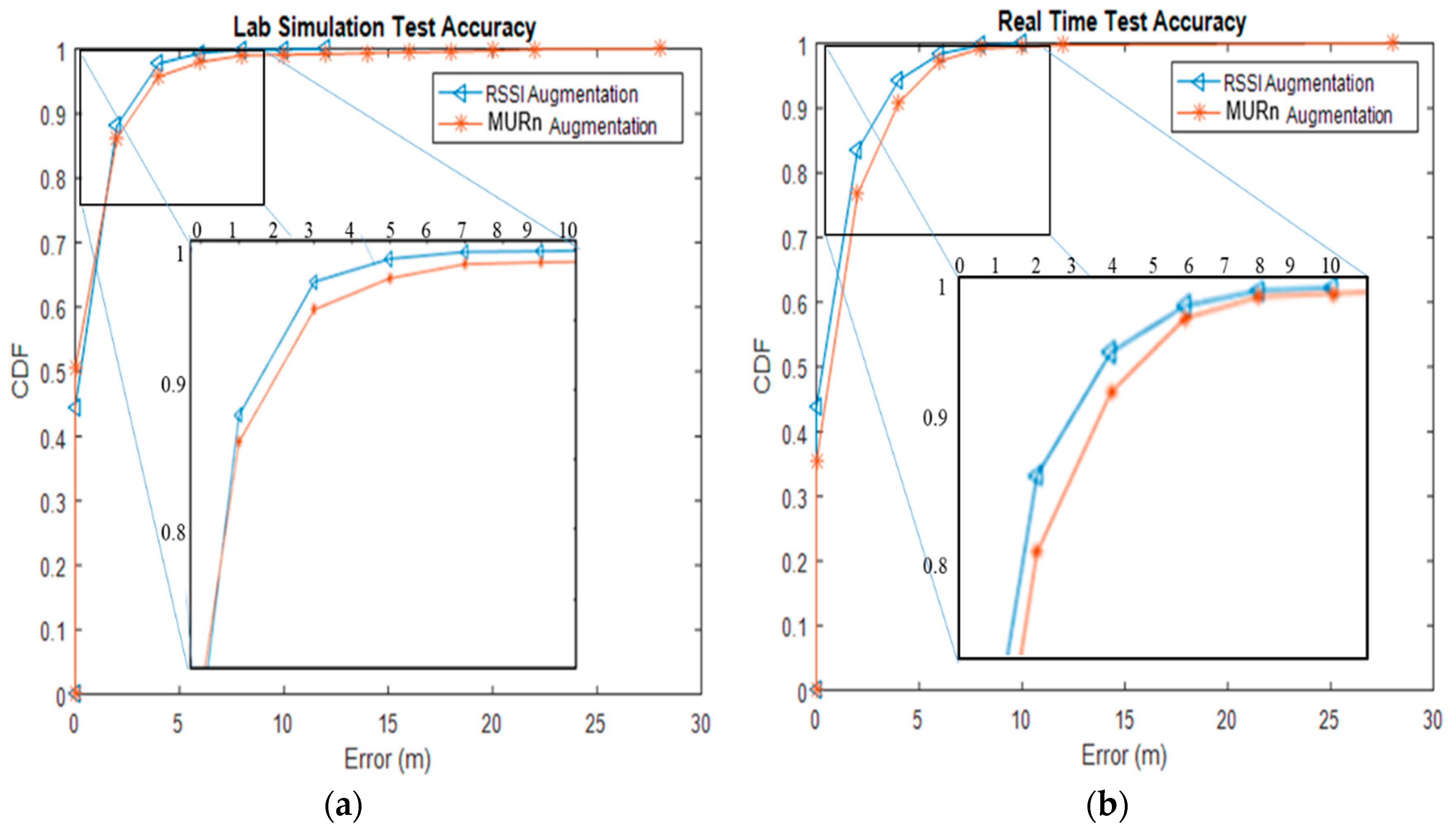
We also evaluated the effectiveness of indoor positioning (i.e., positioning accuracy), defined as the cumulative percentage of the location error within a specified distance (
Figure 11). This was evaluated in real time as well as in the laboratory simulation. In the laboratory simulation, the test accuracy of the RSSI augmentation technique did not differ significantly with a change in the positioning accuracy (e.g., cases where the error distance was within 5 m). The probability of being within an error distance of 5 m was above 90% for both augmentation techniques. However, for cumulative distribution functions over 90%, the positioning accuracy of MURn augmentation falls below that of the RSSI augmentation technique. Under 90%, the error distance for the augmentation techniques in the laboratory simulation was about 2.5 m, with RSSI augmentation being more accurate than MURn augmentation by around 0.50 m. The performance gap between the two techniques increased gradually, and eventually the error distance increased to nearly 10 m for RSSI augmentation and 28 m for MURn augmentation. The real-time position accuracies for both augmentation techniques are shown in
Figure 11b. The error distance of the RSSI augmentation technique was lower than that of the MURn augmentation technique in the range 0–10 m. Under 90%, the error distance for both augmentation techniques in the real-time simulation was about 2.5 m, with the RSSI augmentation technique being more accurate by around 0.50 m. The performance gap between the two techniques increased gradually, and eventually the error distance increased to nearly 10 m for the RSSI augmentation technique and 28 m for MURn augmentation.
The average test accuracies for both augmentation techniques were compared for a real environment. The environmental conditions were the same for all five days of the test. The RSSI augmentation technique showed the highest accuracy of 94.53% for Day 5 and the lowest test accuracy of 86.36% for Day 2. MURn augmentation showed the highest accuracy of 92.44% for Day 1 and the lowest accuracy of 87.03% for Day 4. Overall, the RSSI augmentation technique performed better. For example, this technique had a mean error of 1.60 m when an augmented training data set with data for seven days was used to assist in localisation, while MURn had a mean error of 2.06 m. In other words, the RSSI augmentation technique performed better than MURn augmentation by 2.65%. Furthermore, the performance of the former in terms of accuracy was very close to the lower error bound, for which the median error was 1.45 m.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}