An Efficient Hardware Implementation of Residual Data Binarization in HEVC CABAC Encoder


Abstract
1. Introduction
- ▪
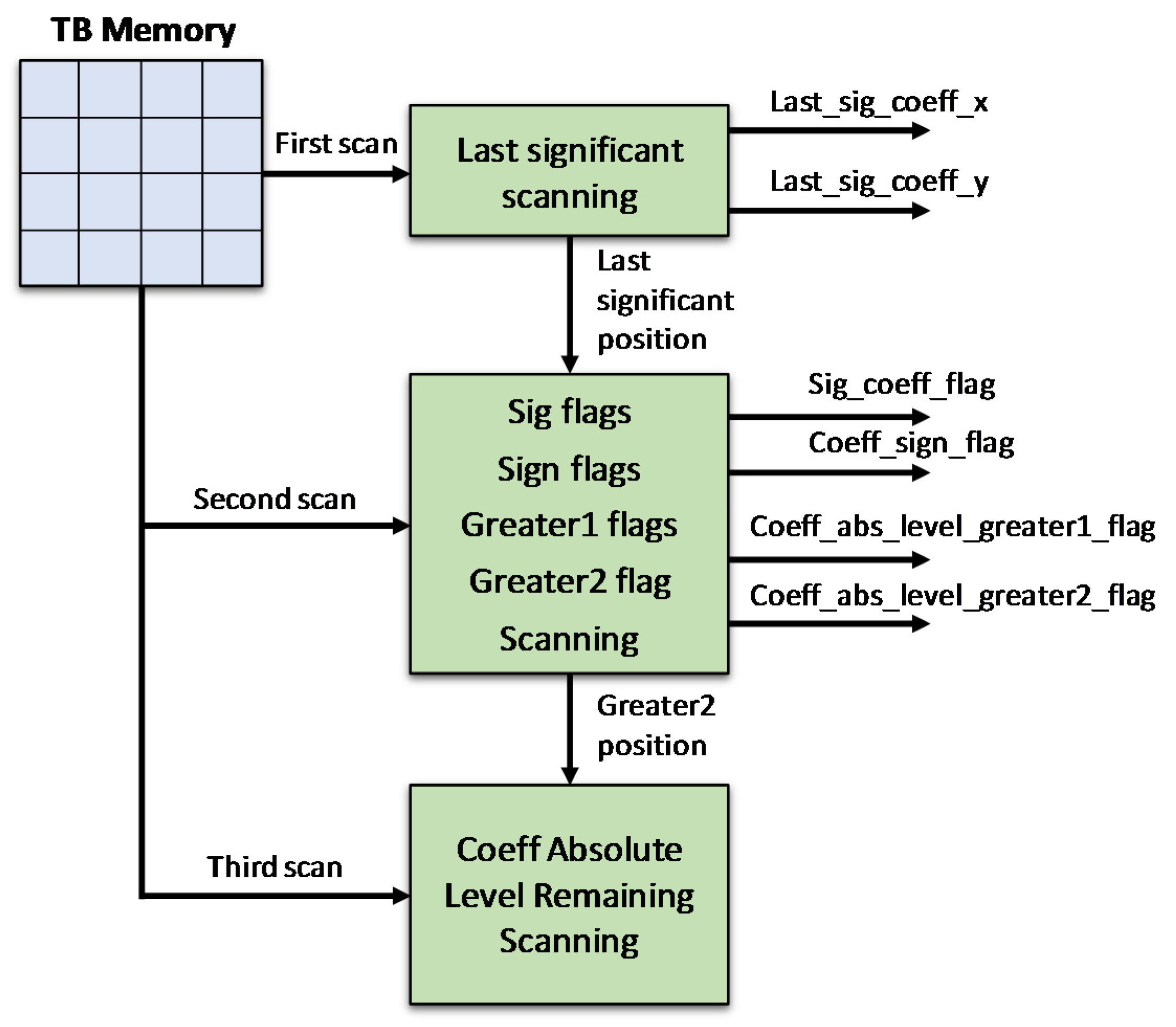
- The procedure of residual SEs generation experiences multiple scans that require multiple accesses of TB memory. This operation causes high power consumption and increases processing delay. Thus, the performance of the residual SE generation would also influence the overall CABAC performance. For that reason, in this work we propose a residual SE generation algorithm and its hardware architecture which is able to reduce memory access load; therefore, it potentially leads to power saving.
- ▪
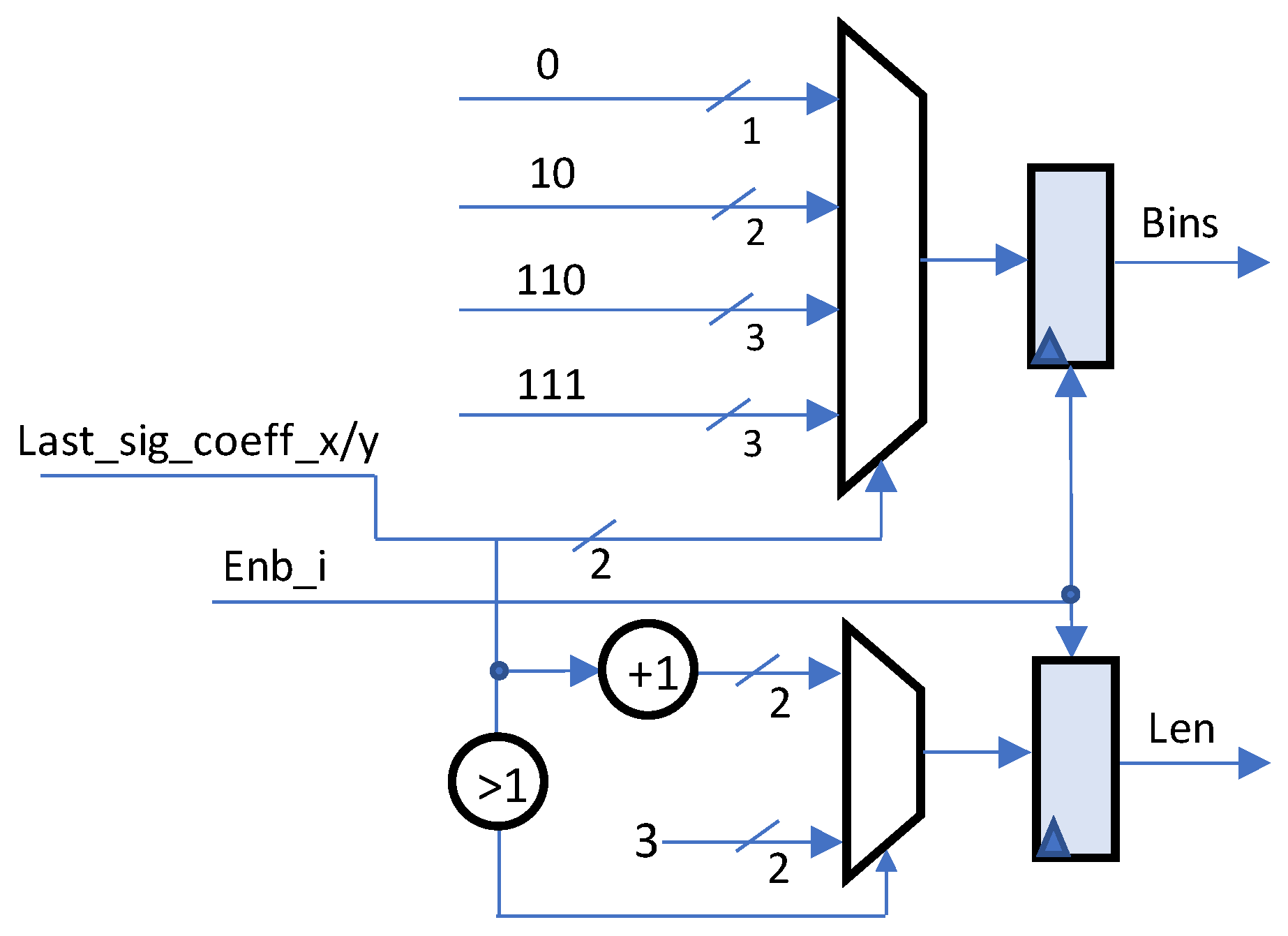
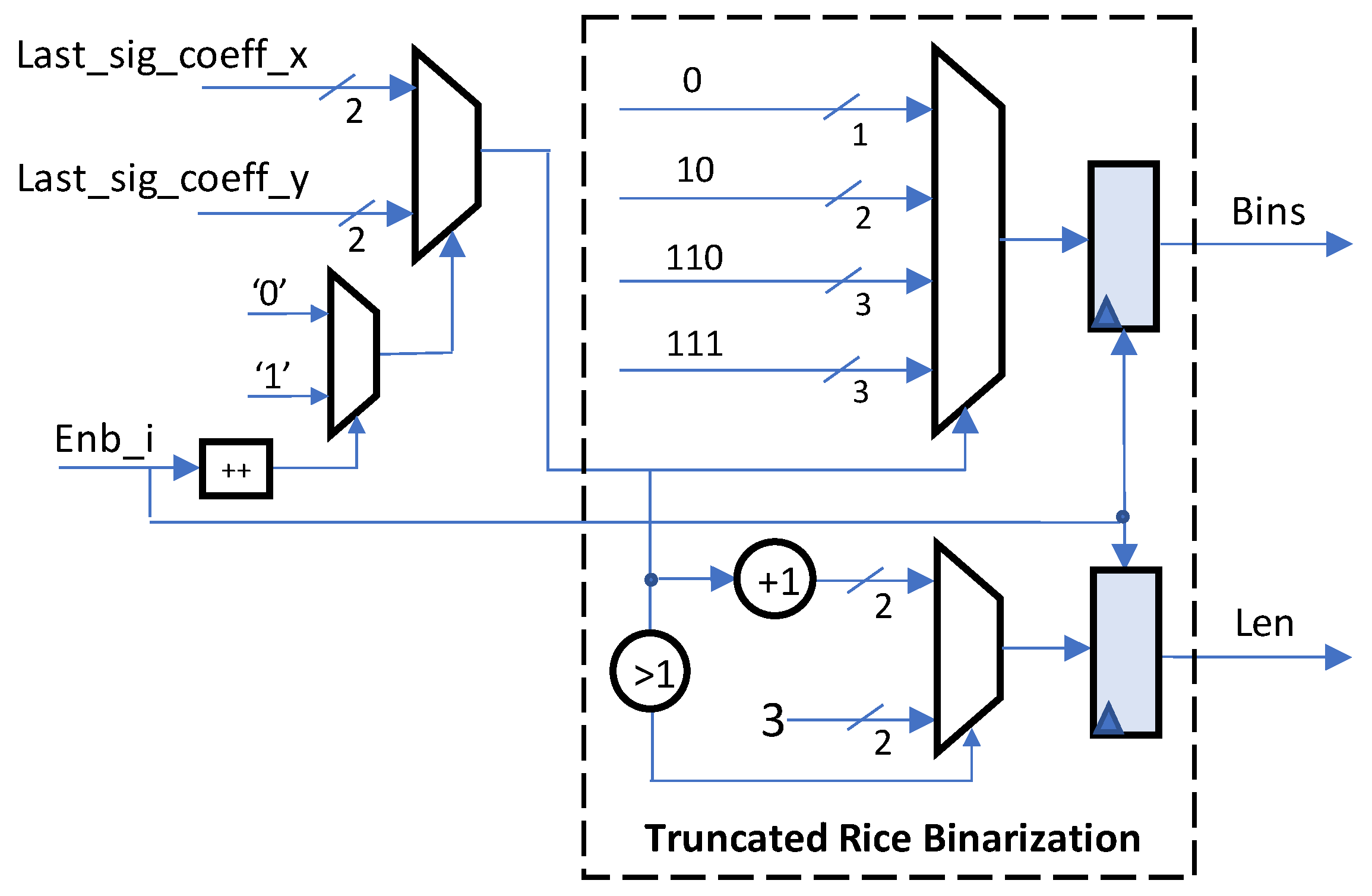
- As one of the syntax elements in residual SEs set for each TB coefficient, the last significant coefficient position is represented by its X and Y coordinates. Theses coordinates are generated simultaneously and converted to bin strings by the same binarization method. Therefore, in this paper, we propose an efficient design of combined SE binarization for these coordinates to save the area cost.
2. Overview of Entropy Coding and Residual Binarization Algorithm in HEVC
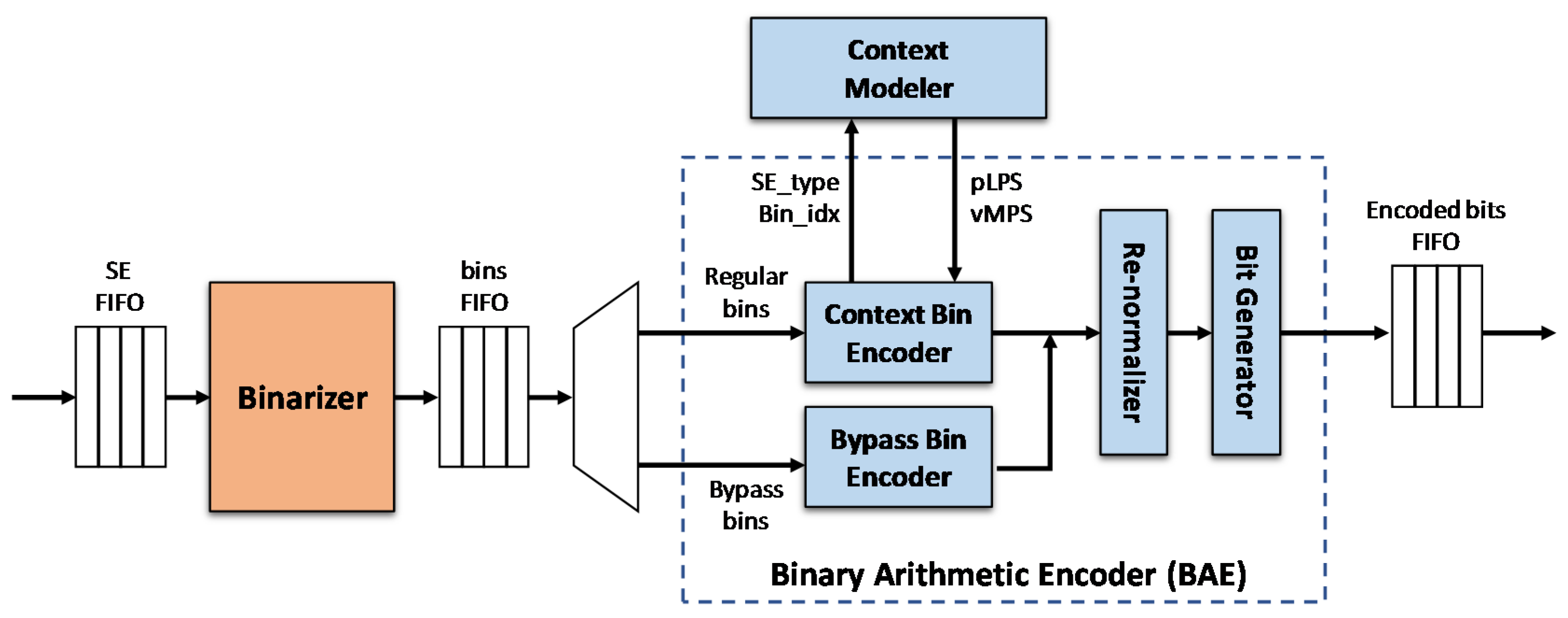
2.1. General Architecture of CABAC
2.2. Binarization in CABAC for HEVC Standard
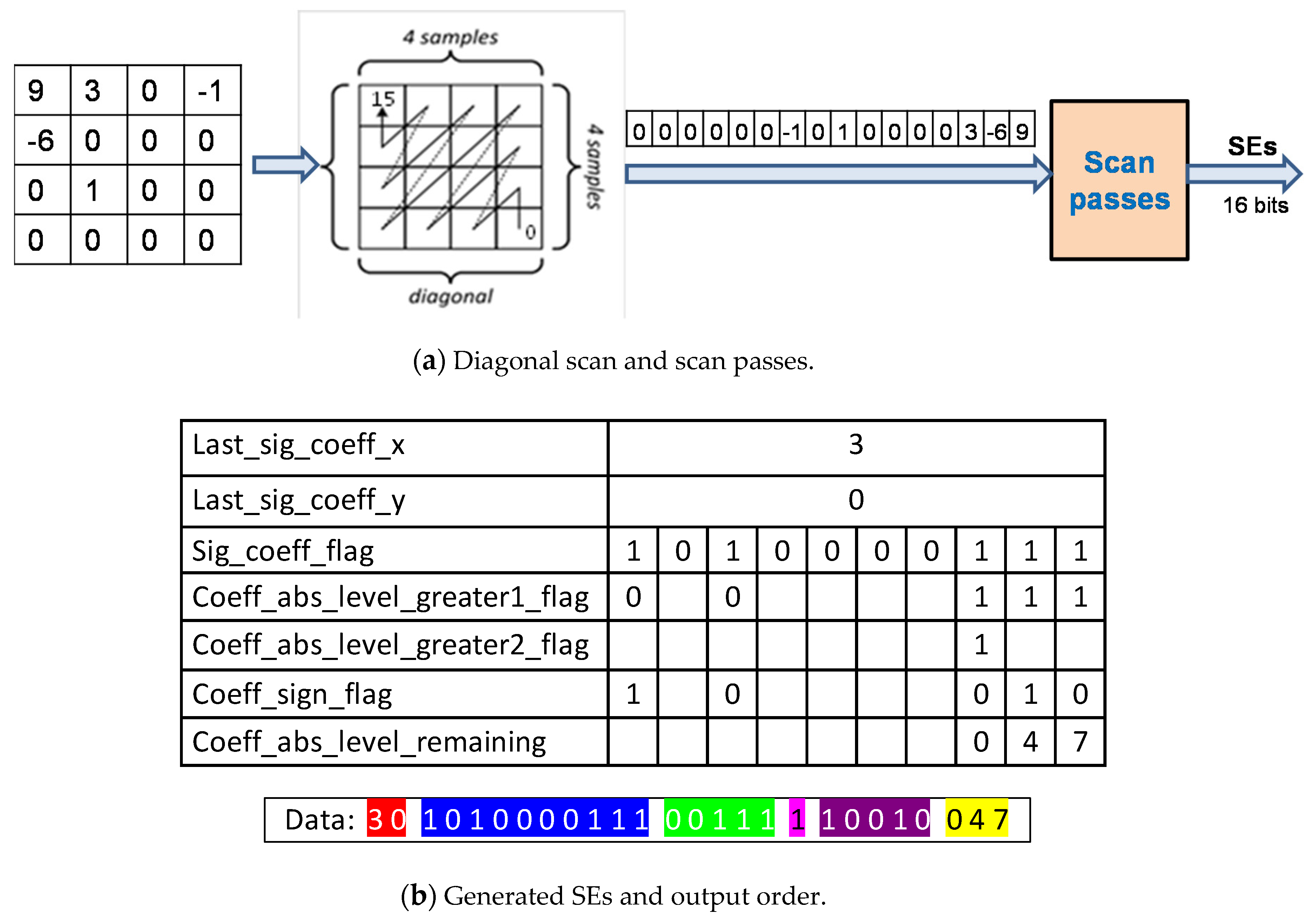
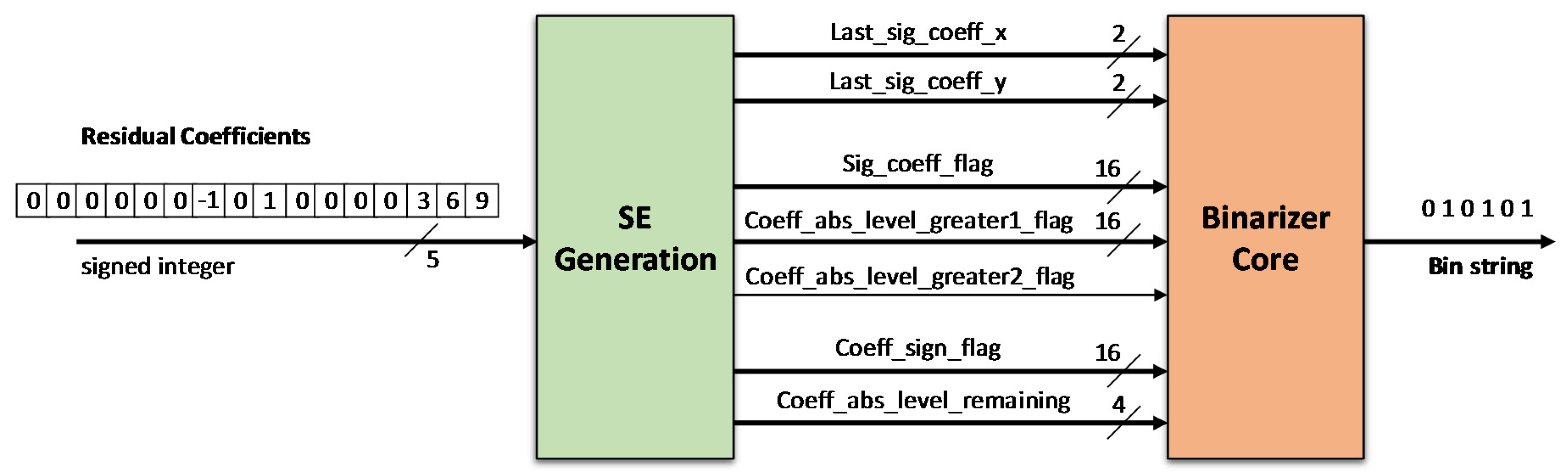
2.3. Residual Syntax Generation and Binarization
2.4. State-of-the-Art
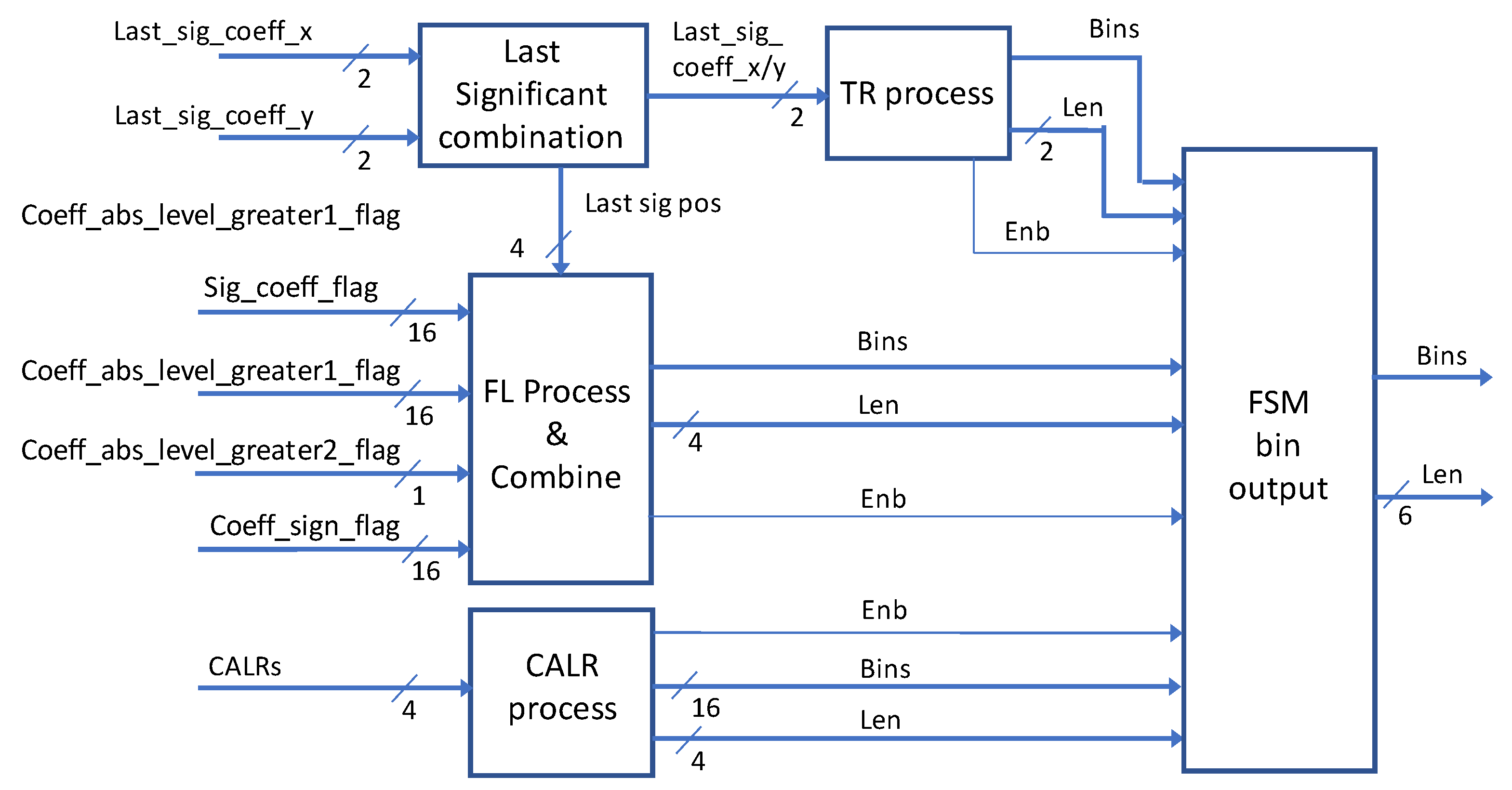
3. Proposed Hardware Architecture and its Implementation for Residual Binarization
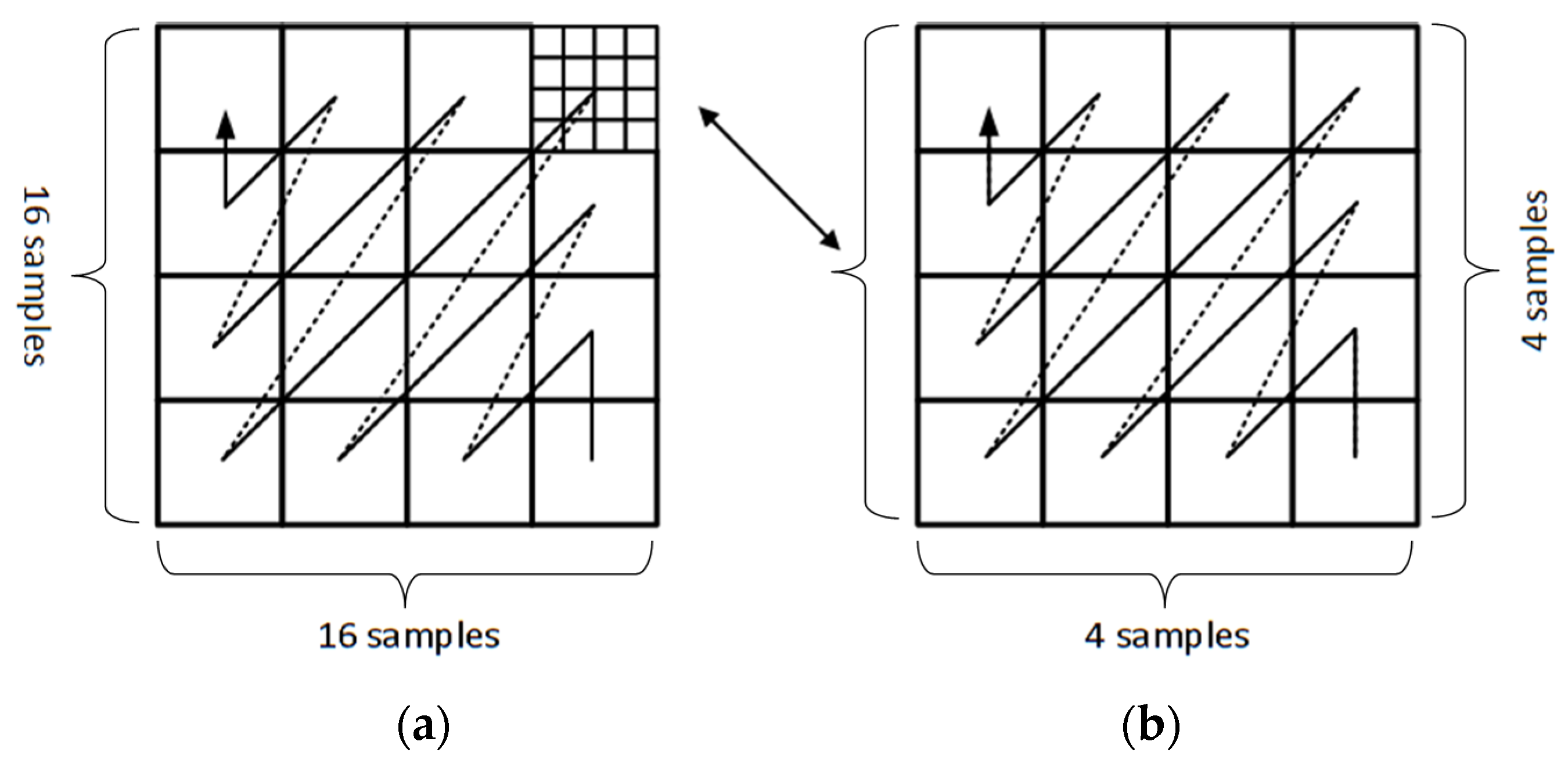
3.1. Overall Hardware Architecture with an Efficient Scanning Algorithm
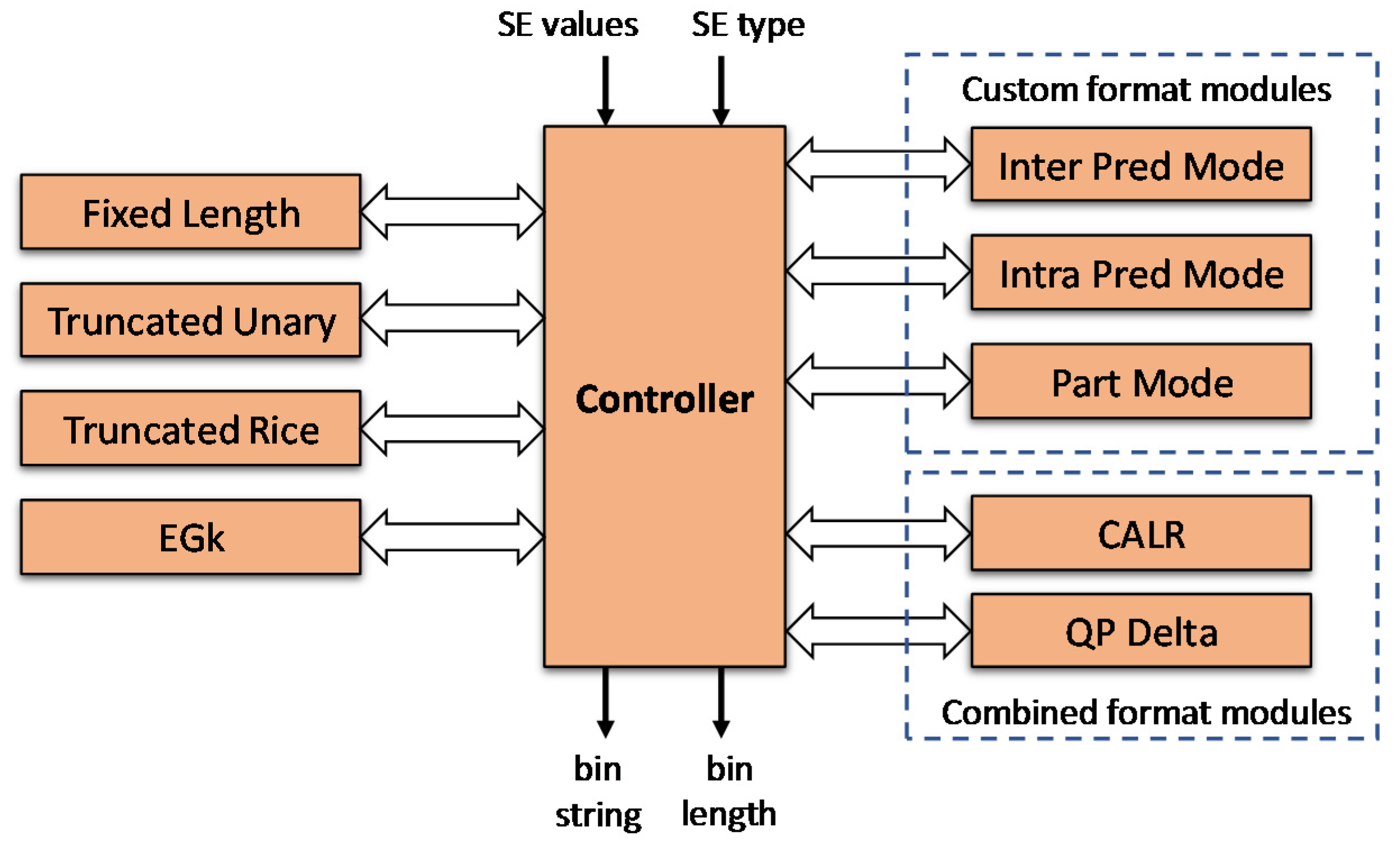
3.2. Combined SE Binarization Hardware for Low Area Cost
4. Experimental Results and Comparisons
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bossen, F.; Bross, B.; Suhring, K.; Flynn, D. HEVC Complexity and Implementation Analysis. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1685–1696. [Google Scholar] [CrossRef]
- Ohm, J.-R.; Sullivan, G.J.; Schwarz, H.; Tan, T.K.; Wiegand, T. Comparison of the Coding Efficicency of Video Coding Standard—Including High Efficient Video Coding (HEVC). IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1669–1684. [Google Scholar] [CrossRef]
- Sze, V.; Budagavi, M. A Comparison of CABAC Throughput for HEVC/H.265 vs. AVC/H.264. In Proceedings of the IEEE Workshop on Signal Processing Systems, Taipei City, Taiwan, 16–18 October 2013. [Google Scholar]
- Tran, D.-L.; Pham, V.-H.; Nguyen, K.H.; Tran, X.-T. A Survey of High-Efficient CABAC Hardware Implementations in HEVC Standard. VNU J. Comput. Sci. Commun. Eng. 2019, 35, 1–21. [Google Scholar]
- Peng, B.; Ding, D.; Zhu, X.; Yu, L. A Hardware CABAC Encoder for HEVC. In Proceedings of the IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013. [Google Scholar]
- Alonso, C.-M.; Ramos, F.-L.-L.; Zatt, B.; Porto, M.; Bampi, S. Low-power HEVC Binarizer Architecture for the CABAC Block targeting UHD Video Processing. In Proceedings of the 30th Symposium on Integrated Circuits and Systems Design, Fortaleza, Brazil, 28 August–1 September 2017. [Google Scholar]
- Ramos, F.-L.-L.; Saggiorato, A.-V.-P.; Zatt, B.; Porto, M.; Bampi, S. Residual Syntax Elements Analysis and Design Targeting High-Throughput HEVC CABAC. IEEE Trans. Circuits Syst. 2019, 67, 475–488. [Google Scholar] [CrossRef]
- Zhou, D.; Zhou, J.; Fei, W.; Goto, S. Ultra-high-throughput VLSI Architecture of H.265/HEVC CABAC Encoder for UHDTV Applications. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 497–507. [Google Scholar] [CrossRef]
- Ramos, F.-L.-L.; Zatt, B.; Porto, M.; Bampi, S. High-Throughput Binary Arithmetic Encoder using Multiple-Bypass Bins Processing for HEVC CABAC. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems, Florence, Italy, 27–30 May 2018. [Google Scholar]
- Saggiorato, A.-V.-P.; Ramos, F.-L.-L.; Zatt, B.; Porto, M.; Bampi, S. HEVC Residual Syntax Elements Generation Architecture for High-Throughput CABAC Design. In Proceedings of the 25th IEEE International Conference on Electronics, Circuits and Systems, Bordeaux, France, 9–12 December 2018. [Google Scholar]
- Nguyen, Q.-L.; Tran, D.-L.; Bui, D.-H.; Mai, D.-T.; Tran, X.-T. Efficient Binary Arithmetic Encoder for HEVC with Multiple Bypass Bin Processing. In Proceedings of the 7th International Conference on Integrated Circuits, Design, and Verification, Hanoi, Vietnam, 5–6 October 2017. [Google Scholar]
- Vizzotto, B.; Mazui, V.; Bampi, S. Area Efficient and High Throughput CABAC Encoder Architecture for HEVC. In Proceedings of the IEEE International Conference on Electronics, Circuits, and Systems, Cairo, Egypt, 6–9 December 2015. [Google Scholar]
- Neji, N.; Jridi, M.; Alfalou, A.; Masmoudi, N. FPGA Implementation of Improved Binarizer Design for Context-Based Adaptive Binary Arithmetic Coder. In Proceedings of the International Image Processing, Applications and Systems, Hammamet, Tunisia, 5–7 November 2016. [Google Scholar]
- Pham, D.-H.; Moon, J.; Le, S. Hardware Implementation of HEVC CABAC Binarizer. J. IKEEE 2014, 18, 356–361. [Google Scholar] [CrossRef]
- Cetin, Y.; Celebi, A. On the Hardware Implementation of Binarization for High Efficiency Video Coding. In Proceedings of the Academicsera International Conference, Istanbul, Turkey, 23–24 October 2017. [Google Scholar]
- Sole, J.; Joshi, R.; Nguyen, N.; Ji, T.; Karczewicz, M.; Clare, G.; Henry, F.; Duenas, A. Transform Coefficient Coding in HEVC. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1765–1777. [Google Scholar] [CrossRef]
- Nguyen, T.; Helle, P.; Winken, M.; Bross, B.; Marpe, D. Transform Coding Techniques in HEVC. IEEE J. Sel. Top. Signal Process. 2013, 7, 978–989. [Google Scholar] [CrossRef]
- Kim, D.; Moon, J.; Lee, S. Hardware Implementation of HEVC CABAC Encoder. In Proceedings of the International SoC Design Conference, Gyungju, Korea, 2–5 November 2015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Common Test Condition | |||||
|---|---|---|---|---|---|
| Hierarchy Level | AI | LD-P | LD-B | RA | Worst-Case |
| Coding tree unit/coding unit bins | 5.4% | 15.8% | 16.7% | 11.7% | 1.4% |
| Prediction unit bins | 9.2% | 20.6% | 19.5% | 18.8% | 5.0% |
| Transform unit bins | 85.4% | 63.7% | 63.8% | 69.4% | 94.0% |
| Syntax Element | Descriptions |
|---|---|
| Last_significant_coeff | The first non-zero coefficient in scanning order within coefficient group. |
| Significant_coeff_flag | Significance of a coefficient (zero/non-zero). |
| Coeff_abs_level_greater1_flag | Flags indicating whether the absolute value of a coefficient level is greater than 1. |
| Coeff_abs_level_greater2_flag | Flag indicating whether the absolute value of a coefficient level is greater than 2. |
| Coeff_sign_flag | Sign of a significant coefficient (0: positive; 1: negative). |
| Coeff_abs_level_remaining | Remaining value for the absolute value of a coefficient level. |
| Kim 2015 [18] | Alonso 2017 [6] | Peng 2013 [5] | Vizzotto 2015 [12] | Zhou 2015 [8] | Pham 2014 [14] | Ramos 2019 [7] | Our Work | |
|---|---|---|---|---|---|---|---|---|
| SE Gen + Bin Core | ||||||||
| Standard | HEVC | HEVC | HEVC | HEVC | HEVC | HEVC | HEVC | HEVC |
| Technology process (nm) | 180 | 65 | 130 | 130 | 90 | 45 | 65 | 45 |
| Clock frequency (MHz) | 158 | 834 | 357 | 380 | 420 | 200 | 668 | 500 |
| Gate count (Kgates) | 3.41 | 11.85 | 48.94 | 31.18 | 64.1 | 1.678 | 3.67 | 9.45 (6.41 binarizer core only) |
| Throughput (bins/cycle) | 1 bin/cycle | 8.34 bins/cycle (4 SEs/cycle) | 1.18 bins/cycle | 2.37 bins/cycle (6 SEs/cycle) | 4.36 bins/cycle (2 ÷ 4 SEs/cycle) | 1 bins/cycle | 4.5 bins/cylcle | 3.05 bins/cycle (3.5 SEs/cycle) |
| Throughput (Mbins/s) | 158 | 6956 | 421 | 901 | 1835 | 200 | 2672 | 1525 |
| Power consumption (mW) | - | 1.87 | - | - | - | 0.05325 | 11.52 | 0.239 (0.184 binarizer core) |
| Resolution | 1920 × 1080 | 8K UHD | 2560 × 1600 | UHD | 8K UHD | 1920 × 1080 | 2560 × 1600 | UHD |
| Area-Efficiency (Mbins/Kgate) | 0.046 | 0.587 | 0.009 | 0.029 | 0.029 | 0.119 | 0.728 | 0.238 |
| Overhead-Efficiency (Mbin/Kgate/mW) | - | 0.314 | - | - | - | 2.238 | 0.063 | 1.293 |
| Power-Efficiency (Mbins/mW) | - | 3719.551 | - | - | - | 3755.869 | 231.944 | 8288.043 |
| Notes | Binarizer | Binarizer | CABAC | CABAC | CABAC | Binarizer | Residual SE Generation | Residual SE Generation & Binarizer |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, D.-L.; Tran, X.-T.; Bui, D.-H.; Pham, C.-K. An Efficient Hardware Implementation of Residual Data Binarization in HEVC CABAC Encoder. Electronics 2020, 9, 684. https://doi.org/10.3390/electronics9040684
Tran D-L, Tran X-T, Bui D-H, Pham C-K. An Efficient Hardware Implementation of Residual Data Binarization in HEVC CABAC Encoder. Electronics. 2020; 9(4):684. https://doi.org/10.3390/electronics9040684
Chicago/Turabian StyleTran, Dinh-Lam, Xuan-Tu Tran, Duy-Hieu Bui, and Cong-Kha Pham. 2020. "An Efficient Hardware Implementation of Residual Data Binarization in HEVC CABAC Encoder" Electronics 9, no. 4: 684. https://doi.org/10.3390/electronics9040684
APA StyleTran, D.-L., Tran, X.-T., Bui, D.-H., & Pham, C.-K. (2020). An Efficient Hardware Implementation of Residual Data Binarization in HEVC CABAC Encoder. Electronics, 9(4), 684. https://doi.org/10.3390/electronics9040684