1. Introduction
Smart grid systems provide real-time capability for managing and monitoring electric usage. With smart grid technology, demand response (DR) offers a cost-effective alternative to increasing electricity supply, when dealing with a small number of capacity-constrained hours. For purposes of this article, DR refers to programs where customers are paid “to reduce their consumption relative to an administratively set baseline level of consumption.” [
1]. While economists have long endorsed dynamic prices such as real-time pricing (RTP) that vary continuously to improve electric system efficiency, regulators have hesitated to implement these programs, particularly for residential customers. Borenstein [
2] has noted that customers have resisted these rates, due to their complexity and the possibility of much higher bills from price surges. To gain greater customer participation, electricity load-serving entities (LSEs) have introduced DR offerings, such as peak-time rebate (PTR), that credit customers for reducing their use during event hours rather than charging a premium during high demand hours.
Some observers, such as in [
3], suggest that subsidies and premiums are equivalent in their effects on load. At the margin, the cost to reducing load is the same whether there is a penalty or a subsidy. However, economists find evidence that customers respond differently to rewards than to penalties (for example, see Gneezy et al. [
4]). There is also a difference in the mechanisms. Unlike RTP, programs such as PTR require providers to determine load reduction. The predominant method is to pay customers the difference between their actual usage and a calculated customer baseline load (CBL), a measure of energy customers would have consumed at their former rate.
The use of a CBL introduces considerable complications. First, the CBL is counterfactual, as the LSE cannot observe what the customer on DR would have used at the previous rate. To calculate a CBL, electricity providers have used several methods, typically based on historical data during non-event periods. However, actual event conditions are likely to differ from historical use during non-event periods, so the CBLs will be, at best, approximations of event-period use. Customer demands can differ during the two periods, due to such factors as weather conditions, different customer activities, and simply random shocks.
There are additional complications that, at the extreme, can result in the provider “paying for nothing,” and customers “free riding.” Williamson and Marrin [
5] identify random variation as one circumstance where “free riding” and “paying for nothing” can arise. Consider two customers with equal average demands, but differing demand volatility. CBLs commonly pay the wholesale rate for reductions below baseline, but charge customers the retail rate for consumption above baseline. The customer with larger demand fluctuations will get a larger rebate, given that wholesale rates during event days generally exceed retail rates. In fact, the customer can get a rebate without changing behavior at all, getting paid PTR for use below the baseline, while paying the traditional retail rate for use above the baseline. Williamson and Marrin predicted revenue losses for two California utilities—Southern California Edison (SCE) and San Diego Gas and Electric (SDG&E)—with PTR programs, and found that for residential customers, one-third to two-thirds of payouts are due to random variations and not actual load reductions in response to price incentives. They note that regulated utilities can pass these costs on to customers, which reduces the utility’s incentive to analyze whether demand reductions are real or illusory. One impediment to CBL that has received extensive attention from the literature is customer behavior to game the system by inflating the baseline. We are unable to consider gaming, as the customers we study are not yet subject to an actual DR program. Instead, we model a potential DR program by simulating event days as the highest demand days for each of twelve months of data, using a sample of customers of the Australian Electric Market Operator (AEMO).
Williamson and Marrin suggested abandoning the use of DR, due to payments for random variations. With the additional problem of choosing a mechanism that accurately predicts for customers with unpredictable demands, due to customer heterogeneity, even in the absence of random variations, the use of CBLs is challenging. However, abandoning DR may not be an option, given its political advantage of rewarding load reductions rather than penalizing customers who do not reduce load. Furthermore, the courts have already established the legal framework for DR. The Supreme Court’s 2016 ruling [
6] upheld FERC Order 745, confirming FERC’s “right to determine both wholesale rates and any rule or practice affecting such rates including the design of compensation rates for load reduction bids.” Practitioners can immediately implement a workable DR system within both the existing legal and technological conditions.
Given the likelihood that DR is here to stay, this article proposes a new method for calculating CBL that reduces error due to customer heterogeneity and reduces payment for random variations in demand. The approach clusters individual consumers based on the size and predictability of their electricity usage. The underlying intuition of reducing randomness by aggregating customers into different clusters is the central limit theorem, which maintains that the aggregation of a large number of mutually independent random variables approaches a normal distribution. The primary innovation in this article is the development of a customer-specific predictability index, that allows us to group relatively homogeneous customers of similar load patterns and load size. Zhang et al. [
7] come closest to our approach and use size and pattern to determine clusters, but they use a randomized control approach and not a predictability index. We discuss the strengths and weaknesses of the randomized control approach, as well as the Zhang et al. study later in the article. Our approach improves upon conventional LSE methods and previous clustering techniques in two ways. First, it performs as well or better in terms of maximizing accuracy and minimizing bias, two widely used measures of baseline precision. Second, it offers greater transparency and fairness. Customers may challenge baselines based on clustering, rather than on their individual demands. In particular, random clustering could elicit pushback from customers, who get smaller payments when the baseline determined by the average demand of the clustered group is lower than the baseline for that individual customer. However, when clustering is formulated on the basis of similar size and demand predictability rather than random clustering, the formulation will increase user understanding and appearance of fairness. The justification is not unlike insurance, where customer rates depend on group characteristics rather than each individual’s characteristics, with transparency and fairness dependent upon the customer’s perception that the group has similar characteristics to the individual. We focus on residential customers, who have received less attention than their commercial and industrial counterparts. With the increase in advanced metering infrastructure (AMI) and load aggregators who offer load reductions to electricity providers from residential customer groups, residential DR potential is growing faster than the commercial and industrial sectors Navigant [
8] suggests that it will be increasingly difficult to find more commercial and industrial customers who are willing to offer demand response, while the residential market is relatively untapped.
As with commercial and industrial customers, residential baselines are subject to “payments for nothing”, due to random variations. Residential demands also have less predictable patterns than commercial and industrial loads as shown in Section 3.3 of Mohajeryami [
9]. Baselines developed for commercial and industrial customers are not readily transferable to residential customers, as residential activities are more random and less predictable, begging for innovation in residential CBL determinations.
We employ a dataset collected by Australian Energy Market Operator (AEMO) for 200 residential customers for 2012 (366 days). In the dataset, each electricity distributor in an AEMO market supplies raw data from a sample of 200 customers for each of their supply areas to the market operator to construct load profiles. The data used in this article is a sample of the raw data for one of the distributors. Data were incomplete for 11 customers and excluded from this study. The analysis includes the remaining 189 customers.
The customers in the sample do not participate in a DR program. Our objective is to compare the accuracy of CBL calculations in predicting demand on a high use day. Such a calculation serves as a needed counterfactual for an actual DR program, so that if the customer’s demand in response to an incentive such as PTR is below the baseline, the customer is receiving compensation based on an accurate baseline, as opposed to a baseline that may have resulted from random fluctuations in individual customer usage during the baseline measurement period.
Using a sample of one year’s worth of hourly data for 200 customers drawn from Australian Energy Market Operator (AEMO) [
10], of whom we use 189 customers with complete hourly data, we compare our method to widely used existing methods that do not use clustering and to methods that use clustering, but do not consider the predictability of customer demands. We have daily data for the year 2012, and develop customer baselines using the 366 days. These hourly data are for customers who were not part of a demand response program, so we simulate 12 event days, typically using the highest monthly demand days, based on the historical highest-use hours of 3–9 pm. CBL inaccuracy is due to customer heterogeneous usage patterns and random variations, as well as the CBL mechanism, among which we consider the most common ones used by utilities, as well as other proposed techniques. We find that our clustering method performs considerably better than non-clustering methods currently used by LSEs, and improves upon previous methods of clustering, based on standard metrics of accuracy and bias commonly used to measure CBL performance.
This article examines the methods of practitioners and the proposals of theorists, then offers a new approach to customer baseline (CBL) methodology.
Section 2 covers baseline methods and metrics in the field, examining utility company and ISO practices for calculating CBLs.
Section 3 reviews the literature and innovations in CBL calculations. The cross-disciplinary nature of this topic has left some of the rigorous engineering studies outside the purview of economists before this article.
Section 4 proposes a new method to improve the error performance of CBL calculations based on k-means clustering, using average loads and a measure of load predictability.
Section 5 presents a case study to evaluate the error performance of the CBL developed with the proposed methodology, using data from AEMO.
Section 6 provides conclusions, policy implications, and suggestions for future work.
3. CBLs: Residential Studies and Clustering Approaches
Two Maryland-vicinity utilities offer residential programs using CBLs. Pepco [
12] investigated a critical peak rebate program for residential customers. Following the methodology of PJM, the company used high XofY, with X = 3 and Y = 30. The company examined the accuracy of the average CBL for a variety of scenarios of between 4 and 15 event days for the hours of noon to 8 pm. They found CBL to have only a small error, using a similar measure to MAE. Remarkably, there was no bias, meaning that the CBL accurately predicted the average hourly demand. However, the study did not report CBLs for individual customers. With a payout of
$1.25/kWh for each kWh reduction below the baseline, there is a lot of revenue at stake if individual customer baselines are not accurate measures of demand.
Baltimore Gas and Electric (BG&E) conducted a pilot program in 2008 through 2011. The company recruited participants, as well as a control group. BG&E opened the program to one million customers in 2015, offering
$1.25 per kWh for reductions below baseline. Due to the fact that customers are automatically enrolled—the default is opt-out rather than opt-in—some customers who make no changes in their behavior will collect payments. The company estimates load savings equivalent to one coal plant, but there has been criticism that they do not appear to have accounted for free riders who randomly decreased load, instead of decreasing load due to the PTR program. (AEE Institute (2019) [
13]).
Wijaya et al. [
14] examined DR baselines for residential customers from the Irish Commission for Energy Regulation (CER) smart metering trial dataset. They found low XofY had the highest accuracy, but the largest negative bias, meaning that the baseline was below actual use. Ordinarily, a negative bias reduces customer revenue, but increases utility revenue. However, in the long run, utility revenues may eventually decrease, as customers are more likely to discontinue their participation if they receive lower payments.
Using the actual smart meter data of 66 residential customers of Australian energy company AGL, Jazaeri et al. [
15] analyzed five CBL estimation methods of High XofY, Last Y days, regression, neural network, and polynomial extrapolation. They found that in terms of bias, machine learning techniques of neural network produce the best results and polynomial extrapolation provides the smallest estimation error.
Hatton et al. [
16] analyzed an experimental DR program of about 700 customers from Electricité de France, using a randomized controlled trial (RCT) to create a suitable control group to measure the DR effect. Unlike CBL, the method is not subject to gaming. RCT aims to minimize the distance between the selected control group’s load curve and the load curve of DR participants. The results showed a significant improvement compared to conventional methods. They also found that an increase in the size of the control group improved accuracy. However, while Mohajeryami and Cecchi [
9] find that RCT shows acceptable performance for individual loads, traditional methods perform better for aggregate loads. RCT also requires many characteristics that utilities do not typically collect to create the best control group. Furthermore, in its current form, RCT employs a static view, unable to portray the dynamics of evolving behavior.
Zhang et al. [
7] clustered urban customers in the southern U.S. to examine event days from June to September. The research proposed a cohort-based CBL approach using k-means clustering, according to the customer power consumption profiles of DR and control group customers. DR baselines were set by cluster, using electricity consumption and demographic data. The calculation compared uses for the two groups for three similar days with the same temperature. Among methods considered in their articles, including conventional CBL methods, the proposed cohort-average method according to k-means clusters consistently showed the best results.
The primary hurdle surrounding CBL calculation with clustering involves defining the key attributes to use for clustering, which is particularly difficult for residential customers, due to high stochasticity and irregular patterns of consumption. In the sections to follow, we present a novel clustering method used to model residential customers and CBL.
4. A New Method of Clustering Residential Consumers and Determining CBL
Mohajeryami et al. [
17] incorporated the effect of the inherent inaccuracy of the CBL, due to its counterfactual nature when applied to heterogeneous residential customers. We build upon those results to examine the impact of the proposed clustering method.
4.1. Stochasticity
We develop a measure for predictability of residential demands, with the purpose of clustering customers of similar size and habit. To carry out the task, we deploy a discrete Fourier transform (DFT) to decompose customer loads into their underlying components. The DFT is a tool that transforms a time-domain signal (demand over time) into a frequency-domain signal. By using DFT, it is possible to sort loads based on the frequency of the repetition of its underlying components. We then compare the accuracy of our method to other methods by calculating MAE, bias, and OPI, with and without same day adjustments.
4.2. Frequency Response Analysis
Frequency domain response requires decomposing the response into underlying predictable and random components (white noise), accomplished using the discrete Fourier transform (DFT). Transforming a finite sequence of data (N samples separated by the sampling time) into coefficients of sinusoids, we ordered the set with a complex-valued function of frequencies. After decomposing a time-domain signal into its underlying components, it is then possible to search for any recurring pattern or periodicity in the initial time-domain data. DFT determines the magnitude of each periodic component, showing the components’ relative strengths. In this section, we treat the hourly electricity consumption of each customer for one year as a signal. Combining DFT and two filters, the method sorts components into high- and low-frequency signals. The equations for discrete Fourier transform and inverse DFT are shown in Equations (4) and (5):
where
N is the number of samples in the signal.
The DFT outcome has N components such that each component has a different frequency, listed in monotonically increasing order. The real parts in the DFT outcome signal mirror half of the data points. Therefore, only half of the information is necessary, as expressed in Equation (6):
where the operator (*) refers to the conjugation operator (the complex conjugate of a complex number contains the same real part and an imaginary part equal in magnitude but opposite in sign. For example, the complex conjugate of
a + bi is
a − bi, where
a and
b are real numbers and
i is the imaginary number representing the square root of −1). One can calculate the frequency of the DFT outcome signal with Equation (7):
where
fr refers to the frequency resolution, and
Ts refers to the time resolution in seconds.
We use a time resolution of 3600 s (1 h) and the frequency resolution, given the 8784 h in a leap year, is 31.6 nHz (Hertz (Hz) is a measure of frequency equal to one cycle per second. A nanohertz (nHz) is a frequency of one cycle per 10−9 s).
4.3. Filters
To decompose the consumption signals into their underlying components, we created two filters of high and low pass frequency around a cut-off frequency (fc). These two filters separate a frequency-domain signal into high and low-frequency components. The cut-off frequency separates the predictable (low frequency) and unpredictable (high frequency) components of the consumption signal.
Figure 1 illustrates the filters; fc is the cut-off frequency, and fs is the sampling frequency, which is 277.7 µHz (10
−6 Hz). Due to the fact that the frequency domain signal symmetrically mirrors itself, low and high-frequency filters must also imitate this characteristic.
The cut-off frequency is 23.1 µHz (equivalent to 12 h in the time domain). The frequency of almost all the spontaneous daytime activities for the residential sector is under 12 h In contrast, some industrial activities have 24-h cycles, in which case 11.5 µHz would capture a 24-h time domain. By applying the filters to the frequency-domain consumption signal, we obtain two high and low frequency signals. Then, an inverse DFT can be applied to these frequency-domain signals to reconstruct their high and low frequency counterparts in time-domain.
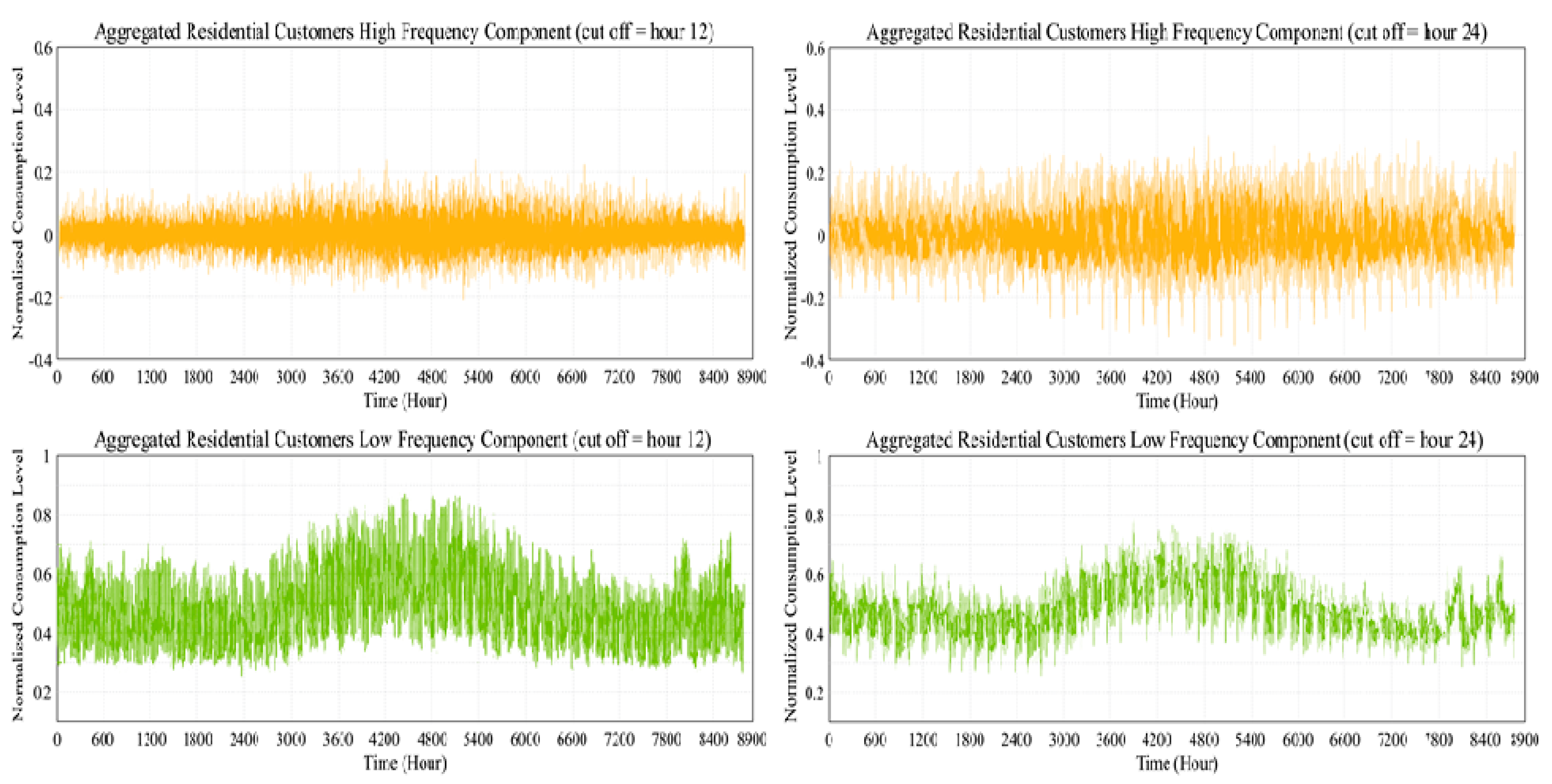
Figure 2 shows the time-domain signals of the aggregated residential customers. For aggregated residential customers, the high frequency components become almost double for a cut-off hour of 24, compared to a cut-off hour of 12. This pattern means that the amount of electricity consumed by activities with a frequency of 1–12 h is almost equal to the amount of electricity consumed by activities with a frequency of 13–24 h.
As shown in
Figure 3, the share of high-frequency components is much higher than low-frequency components for individual residential customers. Residential customers, due to the diversity and spontaneity of their household activities, have highly fluctuating consumption signals.
Unlike industrial and commercial customers, the weekends do not have a major impact on the customers’ routines. This observation is very important, because typically, many load reduction calculation methods exclude weekends from their process. The exclusion of weekends is not necessary for residential customers.
The high-frequency components for a cut-off hour of 24 have a small increase compared to a cut-off hour of 12, which shows that most of the high-frequency activities of residential customers lie in the range of 1–12 h. Comparing the low and high frequency of the customer for a cut-off of hour 24, the low frequency is minimal compared to the high frequency. Therefore, we conclude that most residential activities have frequency ranges of less than 24 h. Spontaneity governs residential customers who typically do not follow schedules for their daily activities.
4.4. Predictability Analysis
An index is proposed to be used as a means for finding and quantifying similarity among the customers’ consumption signals. This index is called the predictability index and reflects the ratio of the low frequency components to the whole of the original consumption signal. The index is calculated by summing the share of high-frequency components and then subtracting the value from one, as shown in Equation (8):
Table 1 shows a comparison between individual and aggregated residential demands. The randomness of individual residential customer demands makes it very difficult to estimate CBL accurately from the historical data of the customers. Mohajeryami [
18], p. 54 shows that industrial and commercial predictability indexes are much higher than that for individual residential customers, but comparable to aggregated residential customers. However, aggregated residential customers show much higher predictability.
6. Conclusions
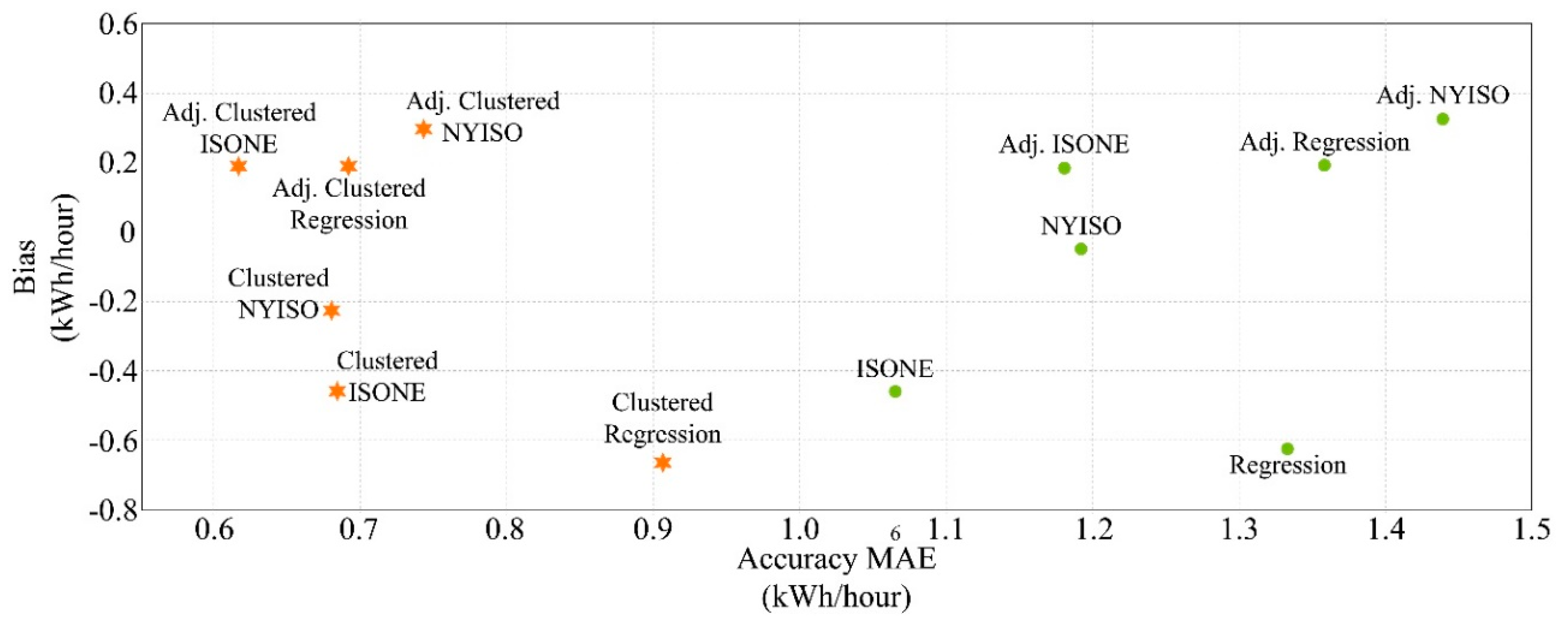
Demand response programs need reliable evaluation, measurement, and verification (EM&V) methods. One of the major EM&V challenges in DR programs is an accurate estimation of the load reduction, particularly for residential customers who show large stochasticity. To ascertain the load reduction for residential DR programs, it is essential to estimate the customer baseline load (CBL) accurately. The necessity of CBL calculation introduces several challenges to DR programs, including random variations in demand and heterogeneous patterns. To address these challenges, we propose k-means clustering based on demand size and predictability. We first show the theoretical merits of this proposed method. We then provide an empirical analysis of residential customers from an Australian electricity provider, showing that clustering customers according to size and predictability improves the error performance. The improvement over random clustering ranges from approximately 3% to 14%, with larger increases compared to no clustering.
The new predictability clustering method provides a meaningful improvement to random clustering. The method produces a lower mean average error (MAE), indicating higher accuracy and better capacity predictions. Our method found a strong correlation between MAE and predictability.
We also consider demand variability. Variability increases MAE. Larger group sizes produce lower MAE, but the decrease is largest for the cluster with the least variability and smallest for the one with greatest variability.
Overestimation and underestimation, and positive and negative bias, respectively, either over- or under- compensate customers. Neither the number of customers in the bin, nor their variability, had a noticeable impact on bias.
Future work can explore alternative methods. Wavelet transform (WT) offers the more robust handling of time-domain data with variable frequency. WT decomposes signals into a set of functions, containing expansions, contractions, and transitions of a single primary function, referred to as a wavelet. The greater division of frequencies can create a higher resolution for analysis, potentially increasing accuracy. Combining predictability methods with randomized controlled trial (RCT) may increase the accuracy of RCT, requiring a less administratively burdensome data set for predictability methods.
Larger data sets should achieve higher levels of predictability and accuracy. If more detailed customer data are available, characteristics such as income, education, and household size may affect predictability. To further increase accuracy, further research can align customer characteristics with predictability assumptions, to decrease error and detect correlations with the size-predictability index.
Actual DR programs likely maintain the information necessary to test the theory. These data will allow one to test CBL accuracy, as well as the revenue of the utility. The successful implementation and development of predictability methods warrants the theory be tested in a variety of conditions, such as differing climates and differing electricity market structures. In particular, actual DR programs can provide the opportunity to minimize the effects of customer stochasticity, so as to avoid “paying for nothing.”





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






