Access Control Role Evolution Mechanism for Open Computing Environment


Abstract
1. Introduction
2. Related Work
3. Preliminaries
3.1. Terms and Definitions
3.2. Genetic Algorithm
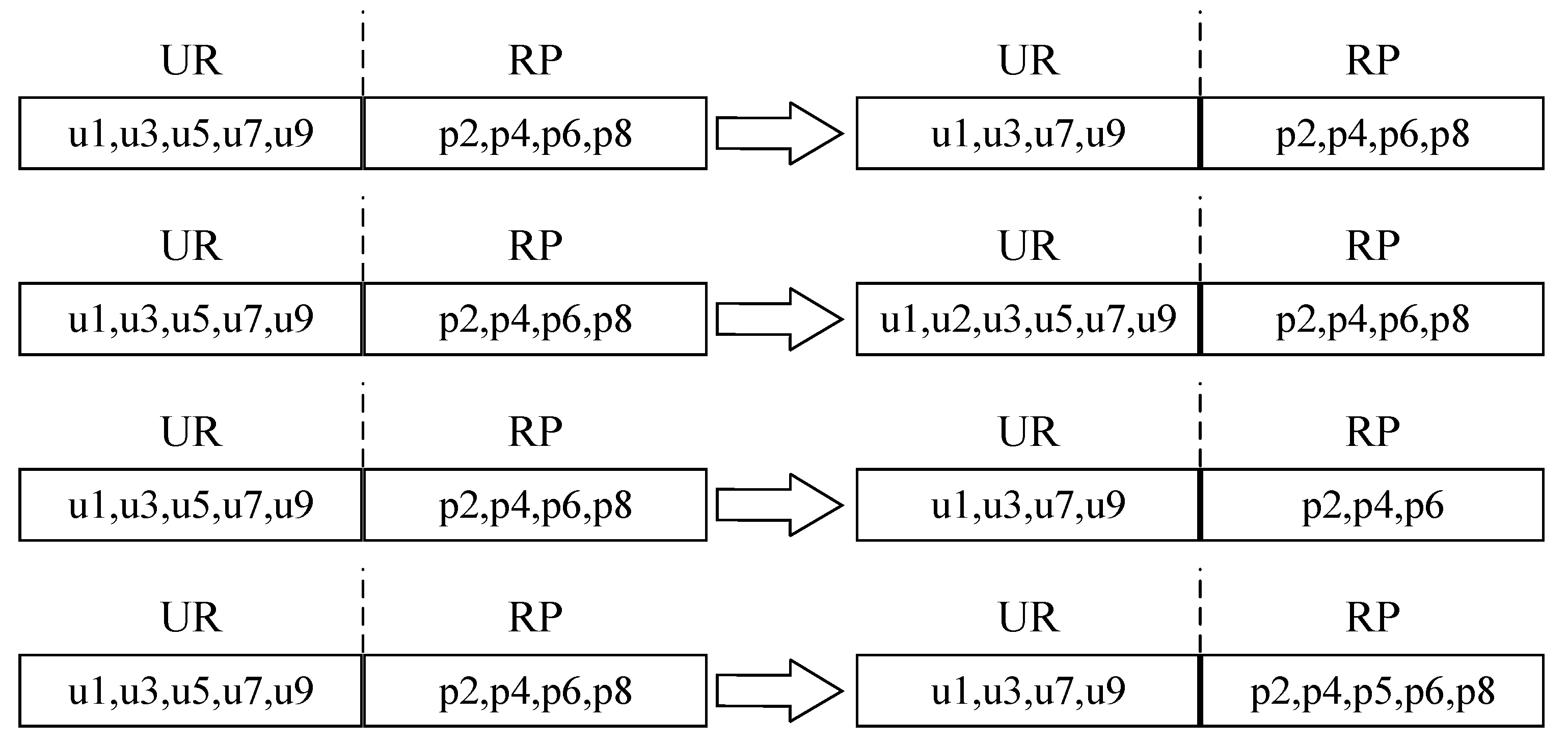
4. Role Evolution Mechanism
5. Role Evolution Method Based on Genetic Algorithm
5.1. Core Permission Evaluation
5.2. Encoding and Decoding of Role Genes
5.3. Selection, Ccrossover and Mutation of Role Genes
5.4. Evaluation Indicators and Fitness Calculation
5.5. Role Optimization
5.6. Description of Algorithm
| Algorithm 1 Preprocessing algorithm |
| INPUT: UPM, Rmax (Role size), θ (Initialization index), |
| threshold(Complexity threshold) OUTPUT: InitRoleModel(Initial role model), |
| CorePerSet(Core permission set) |
| 1: InitNum = Random(θ•Rmax, Rmax), InitRoleModel = null |
| 2: for I = 1 to InitNum do |
| 3: TempRole = null |
| 4: for j = 1 to Random (1,UPM.UserNum) do |
| 5: TempRole.Users.append(Random (1,UPM.UserNum)) |
| 6: for k = 1 to Random (1,UPM.PermNum) do |
| 7: TempRole.Perms.append(Random (1,UPM.PermNum)) |
| 8: InitRoleModel.append(TempRole) |
| 9: for k = 1 to UPM.PermNum do |
| 10: index = PSC(k) |
| 11: if (index> threshold) |
| 12: CorePerSet.append(k) |
| Algorithm 2 Role evolution algorithm |
| INPUT: n_pop(Population size), n_gen(Number of evolutions), |
| Pc(Probability of gene crossover), |
| Pm(Probability of gene mutation) |
| OUTPUT: RoleModel |
| 1: Initialize pop, t = 0 |
| 2: do{ Calculate the fitness F(i) of each individual |
| 3: do{ I1, I2 = chose2indivial(pop) |
| 4: if (random(0, 1) < Pc): |
| 5: Ig1, Ig2 = crossChr(I1, I2) |
| 6: else: |
| 7: Ig1, Ig2 = I1, I2 |
| 8: if (random(0, 1) < Pm) |
| 9: Ig1, Ig2 = mutChr(Ig1, Ig2) |
| 10: popt+1.append(Ig1, Ig2) |
| 11: } while( len(popt+1) < n_pop ) |
| 12: pop = popt+1, t = t + 1 |
| 13: }while( F(pop.chr) < Fe and t < n_gen ) |
| Algorithm 3 Post-processing algorithm |
| INPUT: RoleModel, CorePerSet(Core permission set) |
| OUTPUT: FinalRoleModel() |
| 1: for each Rolei∈RoleModel do |
| 2: for each Rolej∈RoleModel do |
| 3: if (Rolei.Users=Rolej.Users or Rolei. Perms=Rolej. Perms) |
| 4: RoleModel.merge(Rolej, Rolej) |
| 5: else if (Rolei.Users ⊇ Rolej.Users and Rolei.Perms ⊇ Rolej. Perms) |
| 6: RoleModel.delete(Rolej) |
| 7: for each CorePeri∈CorePerSet do |
| 8: flag = 0 |
| 9: for each Rolej∈RoleModel do |
| 10: if(Rolej contains CorePeri) |
| 11: flag = 1 |
| 12: if(flag == 0) |
| 13: RoleModel.append(CorePeri) |
6. Role Relationship Aggregation Algorithm
| Algorithm 4 Role relationship aggregation algorithm |
| INPUT: RoleVecSet(Role vector set), radius |
| OUTPUT: RoleClu(Role clustering model) |
| 1: Initialize RoleClu=null, countVec, tempData=null |
| 2: for each RoleVeci∈RoleVecSet do |
| 3: clu_center = RoleVeci |
| 4: while True: |
| 5: for each RoleVecj∈RoleVecSet do |
| 6: if(RoleVecj - clu_center)<=radius |
| 7: tempData.append(RoleVecj) |
| 8: countVec[i] += 1 |
| 9: new_cen = Average(tempData) |
| 10: if(RoleVeci.equal(new_cen)) |
| 11: break |
| 12: new_clu=newCluster(countVec) |
| 13:sameClu = False |
| 14:for each Clui∈RoleClu do |
| 15: if((Clui .cen-new_cen)<=radius) |
| 16: combine(Clui, new_clu) |
| 17: sameClu = True |
| 18: if (has_same == Flase) |
| 19: RoleClu.append(new_clu) |
7. Experimental Evaluations
7.1. Datasets and Experimental Settings
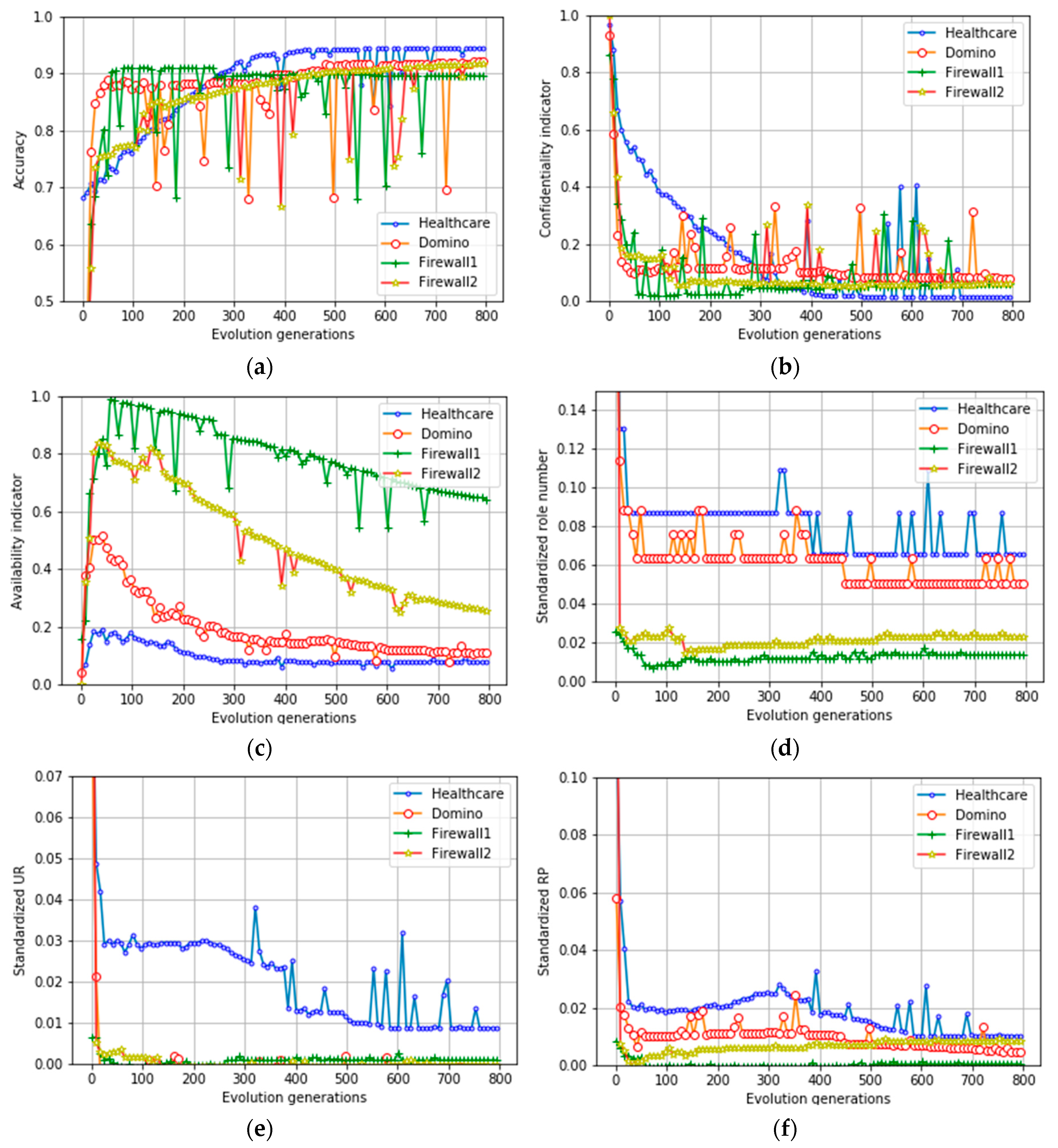
7.2. Performance Evaluation of Role Evolution
7.3. Performance Evaluation of Role Relationship Aggregation
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wu, X.; Zhu, X.; Wu, G.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2013, 26, 97–107. [Google Scholar]
- Li, S.; Da Xu, L.; Zhao, S. The internet of things: A survey. Inf. Syst. Front. 2014, 17, 243–259. [Google Scholar] [CrossRef]
- Barua, H.B.; Mondal, K.C. A Comprehensive Survey on Cloud Data Mining (CDM) Frameworks and Algorithms. ACM Comput. Surv. 2019, 52, 1–62. [Google Scholar] [CrossRef]
- O’Halloran, K.L.; Tan, S.; Wignell, P.; Bateman, J.; Pham, S.; Grossman, M.; Moere, A.V. Interpreting Text and Image Relations in Violent Extremist Discourse: A Mixed Methods Approach for Big Data Analytics. Terror. Politi-Violence 2016, 31, 454–474. [Google Scholar] [CrossRef]
- Data Breaches Compromised 4.5 Billion Records in First Half of 2018. Available online: https://www.gemalto.com/press/Pages/Data-Breaches-Compromised-4-5-Billion-Records-in-First-Half-of-2018.aspx (accessed on 23 October 2018).
- Lazouski, A.; Martinelli, F.; Mori, P. Usage control in computer security: A survey. Comput. Sci. Rev. 2010, 4, 81–99. [Google Scholar] [CrossRef]
- Power, D.; Slaymaker, M.; Simpson, A. On Formalizing and Normalizing Role-Based Access Control Systems. Comput. J. 2008, 52, 305–325. [Google Scholar] [CrossRef]
- Wang, G.H. Role-Based Access Control. Computer 1996, 29, 38–47. [Google Scholar]
- Vaidya, J.; Atluri, V.; Warner, J.; Guo, Q. Role Engineering via Prioritized Subset Enumeration. IEEE Trans. Dependable Secur. Comput. 2008, 7, 300–314. [Google Scholar] [CrossRef]
- Baumgrass, A.; Strembeck, M. Bridging the gap between role mining and role engineering via migration guides. Inf. Secur. Tech. Rep. 2013, 17, 148–172. [Google Scholar] [CrossRef]
- Coyne, E.J.; Davis, J.M. Role Engineering for Enterprise Security Management; Artech House: Norwood, MA, USA, 2007. [Google Scholar]
- Fang, L.; Yin, L.H.; Guo, Y.C.; Fang, B.X. A Survey of Key Technologies in Attribute-Based Access Control Scheme. Chin. J. Comput. 2017, 40, 1680–1698. [Google Scholar]
- Li, H.; Zhang, M.; Feng, D.G.; Hui, Z. Research on Access Control of Big Data. Chin. J. Comput. 2017, 1, 72–91. [Google Scholar]
- Liu, A.D.; Du, X.H.; Wang, N.; Li, S.Z. A blockchain-based access control mechanism for big data. J. Softw. 2019, 9, 2636–3654. [Google Scholar]
- Hui, Z.; Li, H.; Zhang, M.; Feng, D.G. Risk-adaptive access control model for big data in healthcare. J. Commun. 2015, 36, 190–199. [Google Scholar]
- Strembeck, M. Scenario-Driven Role Engineering. IEEE Secur. Priv. Mag. 2010, 8, 28–35. [Google Scholar] [CrossRef]
- Kuhlmann, M.; Shohat, D.; Schimpf, G. Role mining—Revealing business roles for security administration using data mining technology. In Proceedings of the Eighth Acm Symposium on Access Control Models & Technologies, Huhehaote, China, 10–13 October 2003. [Google Scholar]
- Mitra, B.; Sural, S.; Vaidya, J.; Atluri, V. A Survey of Role Mining. ACM Comput. Surv. 2016, 48, 1–37. [Google Scholar] [CrossRef]
- Vaidya, J.; Atluri, V.; Guo, Q.; Lu, H. Role Mining in the Presence of Noise. In DBSec’10: Proceedings of the 24th Annual IFIP WG 11.3 Working Conference on Data and Applications Security and Privacy, Rome, Italy, 21–23 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6166, pp. 97–112. [Google Scholar]
- Vaidya, J.; Atluri, V.; Guo, Q. The role mining problem: A formal perspective. ACM Trans. Inf. Syst. Secur. 2010, 13, 27. [Google Scholar] [CrossRef]
- Huang, H.; Shang, F.; Zhang, J. Approximation Algorithms for Minimizing the Number of Roles and Administrative Assignments in RBAC. In Proceedings of the 2012 IEEE 36th Annual Computer Software and Applications Conference Workshops, Izmir, Turkey, 16–20 July 2012; pp. 427–432. [Google Scholar]
- Mitra, B.; Sural, S.; Atluri, V.; Vaidya, J. The generalized temporal role mining problem. J. Comput. Secur. 2015, 23, 31–58. [Google Scholar] [CrossRef]
- Lu, H.; Vaidya, J.; Atluri, V. An optimization framework for role mining. J. Comput. Secur. 2014, 22, 1–31. [Google Scholar] [CrossRef]
- Sarana, P.; Roy, A.; Sural, S.; Vaidya, J.; Atluri, V. Role Mining in the Presence of Separation of Duty Constraints. In ICISS 2015: Proceedings of the 11th International Conference on Information Systems Security, Kolkata, India, 16–20 December 2015; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9478, pp. 98–117. [Google Scholar]
- Zhang, L.; Zhang, H.L.; Han, D.J.; Shen, X.J. Theory and Algorithm for Roles Minization Problem in RBAC Based on Concept Lattice. Acta Electron. Sin. 2014, 42, 2371–2378. [Google Scholar]
- Zhou, C.; Ren, Z.Y.; Wu, W.C. Semantic Roles Mining Algorithms Based on Formal Concept Analysis. Comput. Sci. 2018, 45, 118–129. [Google Scholar]
- Dong, L.; Wang, Y.; Liu, R.; Pi, B.; Wu, L. Toward edge minability for role mining in bipartite networks. Phys. A Stat. Mech. Its Appl. 2016, 462, 274–286. [Google Scholar] [CrossRef]
- Vavilis, S.; Egner, A.I.; Petkovic, M.; Zannone, N. Role Mining with Missing Values. In Proceedings of the 2016 11th International Conference on Availability, Reliability and Security (ARES), Salzburg, Austria, 31 August–2 September 2016; pp. 167–176. [Google Scholar]
- Harika, P.; Nagajyothi, M.; John, J.C.; Sural, S.; Vaidya, J.; Atluri, V. Meeting Cardinality Constraints in Role Mining. IEEE Trans. Dependable Secur. Comput. 2014, 12, 71–84. [Google Scholar] [CrossRef]
- Mitra, B.; Sural, S.; Vaidya, J.; Atluri, V. Mining temporal roles using many-valued concepts. Comput. Secur. 2016, 60, 79–94. [Google Scholar] [CrossRef]
- Stoller, S.D.; Bui, T. Mining hierarchical temporal roles with multiple metrics. J. Comput. Secur. 2017, 26, 121–142. [Google Scholar] [CrossRef]
- Narouei, M.; Takabi, H. Towards an Automatic Top-down Role Engineering Approach Using Natural Language Processing Techniques. In SACMAT’15: Proceedings of the 20th ACM Symposium on Access Control Models and Technologies, Vienna, Austria, 1–3 June 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 157–160. [Google Scholar]
- Kumar, R.; Sural, S.; Gupta, A. Mining RBAC Roles under Cardinality Constraint. In ICISS’10: Proceedings of the 6th International Conference on Information Systems Security, Gandhinaga, India, 15 December 2010; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6503, pp. 171–185. [Google Scholar]
- Molloy, I.; Li, N.; Li, T.; Mao, Z.; Wang, Q.; Lobo, J. Evaluating role mining algorithms. In Proceedings of the 14th ACM Symposium on Performance Evaluation of Wireless Ad Hoc, Sensor, & Ubiquitous Networks—PE-WASUN ’17, Bodrum, Turkey, 17–18 October 2010; pp. 95–104. [Google Scholar]
- Vaidya, J.; Atluri, V.; Warner, J. RoleMiner: Mining roles using subset enumeration. In CCS’06: Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 144–153. [Google Scholar]
- Zhang, D.; Ramamohanarao, K.; Ebringer, T. Role engineering using graph optimisation. In SACMAT’07: Proceedings of the 12th ACM Symposium on Access Control Models and Technologies, Sophia Antipolis, France, 20–22 June, 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 139–144. [Google Scholar]
- Molloy, I.; Chen, H.; Li, T.; Wang, Q.; Li, N.; Bertino, E.; Calo, S.B.; Lobo, J. Mining roles with semantic meanings. In SACMAT’08: Proceedings of the 13th ACM Symposium on Access Control Models and Technologies, Estes Park, CO, USA, 11–13 June 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 21–30. [Google Scholar]
- Dong, L.; Wu, K.; Tang, G. A Data-Centric Approach to Quality Estimation of Role Mining Results. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2678–2692. [Google Scholar] [CrossRef]
- Zhai, Z.G.; Wang, J.D.; Cao, Z.N.; Mao, Y.G. Hybrid Role Mining Methods with Minimal Perturbation. J. Comput. Res. Dev. 2013, 50, 951–960. [Google Scholar]
- Kunz, M.; Fuchs, L.; Netter, M.; Pernul, G. How to Discover High-Quality Roles? A Survey and Dependency Analysis of Quality Criteria in Role Mining. Commun. Comput. Inf. Sci. 2015, 576, 49–67. [Google Scholar]
- Blundo, C.; Cimato, S.; Siniscalchi, L. PRUCC-RM: Permission-Role-Usage Cardinality Constrained Role Mining. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Turin, Italy, 4–8 July 2017; Volume 2, pp. 149–154. [Google Scholar]
- Pan, N.; Zhu, Z.; He, L.; Sun, L. An efficiency approach for RBAC reconfiguration with minimal roles and perturbation. Concurr. Comput. Pr. Exp. 2017, 30, e4399. [Google Scholar] [CrossRef]
- Han, L.I.; Zheng, S.; Chen, F. Research on Role Engineering of Legacy System. J. Front. Comput. Sci. Technol. 2017. [Google Scholar]
- Hachana, S.; Cuppens, F.; Cuppens-Boulahia, N.; Garcia-Alfaro, J. Semantic analysis of role mining results and shadowed roles detection. Inf. Secur. Tech. Rep. 2013, 17, 131–147. [Google Scholar] [CrossRef][Green Version]
- Saenko, I.; Kotenko, I. Administrating role-based access control by genetic algorithms. In GECCO’17: Proceedings of the Genetic and Evolutionary Computation Conference Companion, Berlin, Germany, 15–19 July, 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1463–1470. [Google Scholar]
- Saenko, I.; Kotenko, I. Genetic algorithms for role mining in critical infrastructure data spaces. In GECCP’18” Proceedings of the Genetic and Evolutionary Computation Conference Companion, Kyoto, Japan, 15–19 July 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1688–1695. [Google Scholar]
- Wu, L.; Dong, L.; Wang, Y.; Zhang, F.; Lee, V.E.; Kang, X.; Liang, Q. Uniform-scale assessment of role minimization in bipartite networks and its application to access control. Phys. A Stat. Mech. Its Appl. 2018, 507, 381–397. [Google Scholar] [CrossRef]
- Xu, Z.; Stoller, S.D. Algorithms for mining meaningful roles. In SACMAT’12: Proceedings of the 17th ACM Symposium on Access Control Models and Technologies, Newark, NJ, USA, 20–22 June 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 57–66. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Yousefi, B.; Sfarra, S.; Ibarra-Castanedo, C.; Maldague, X.P. Comparative analysis on thermal non-destructive testing imagery applying Candid Covariance-Free Incremental Principal Component Thermography (CCIPCT). Infrared Phys. Technol. 2017, 85, 163–169. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | |U| | |P| | |UPM| | Density of |UPM| |
|---|---|---|---|---|
| Healthcare | 46 | 46 | 1486 | 0.7023 |
| Domino | 79 | 231 | 730 | 0.0400 |
| Firewall1 | 365 | 709 | 31,951 | 0.1235 |
| Firewall2 | 325 | 590 | 36,428 | 0.1900 |
| America-small | 3477 | 1587 | 10,5205 | 0.0191 |
| America-large | 3485 | 10,127 | 18,5294 | 0.0053 |
| Datasets | CRM | PC | CM | GO | HM | Our Method |
|---|---|---|---|---|---|---|
| Healthcare | 14 | 24 | 31 | 16 | 17 | 13 |
| Domino | 20 | 64 | 62 | 20 | 27 | 20 |
| Firewall1 | 66 | 248 | 278 | 71 | 91 | 61 |
| Firewall2 | 10 | 14 | 21 | 10 | 10 | 9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, A.; Du, X.; Wang, N. Access Control Role Evolution Mechanism for Open Computing Environment. Electronics 2020, 9, 517. https://doi.org/10.3390/electronics9030517
Liu A, Du X, Wang N. Access Control Role Evolution Mechanism for Open Computing Environment. Electronics. 2020; 9(3):517. https://doi.org/10.3390/electronics9030517
Chicago/Turabian StyleLiu, Aodi, Xuehui Du, and Na Wang. 2020. "Access Control Role Evolution Mechanism for Open Computing Environment" Electronics 9, no. 3: 517. https://doi.org/10.3390/electronics9030517
APA StyleLiu, A., Du, X., & Wang, N. (2020). Access Control Role Evolution Mechanism for Open Computing Environment. Electronics, 9(3), 517. https://doi.org/10.3390/electronics9030517