Density Peak Clustering Algorithm Considering Topological Features



Abstract
1. Introduction
2. DPCTF Algorithm
2.1. Clustering by Fast Search and Find of Density Peaks
2.2. DeepWalk
2.2.1. Random Walk Generator
2.2.2. Skipgram
2.3. Topological Structure
2.4. Density Peak Clustering Algorithm Considering Topological Features
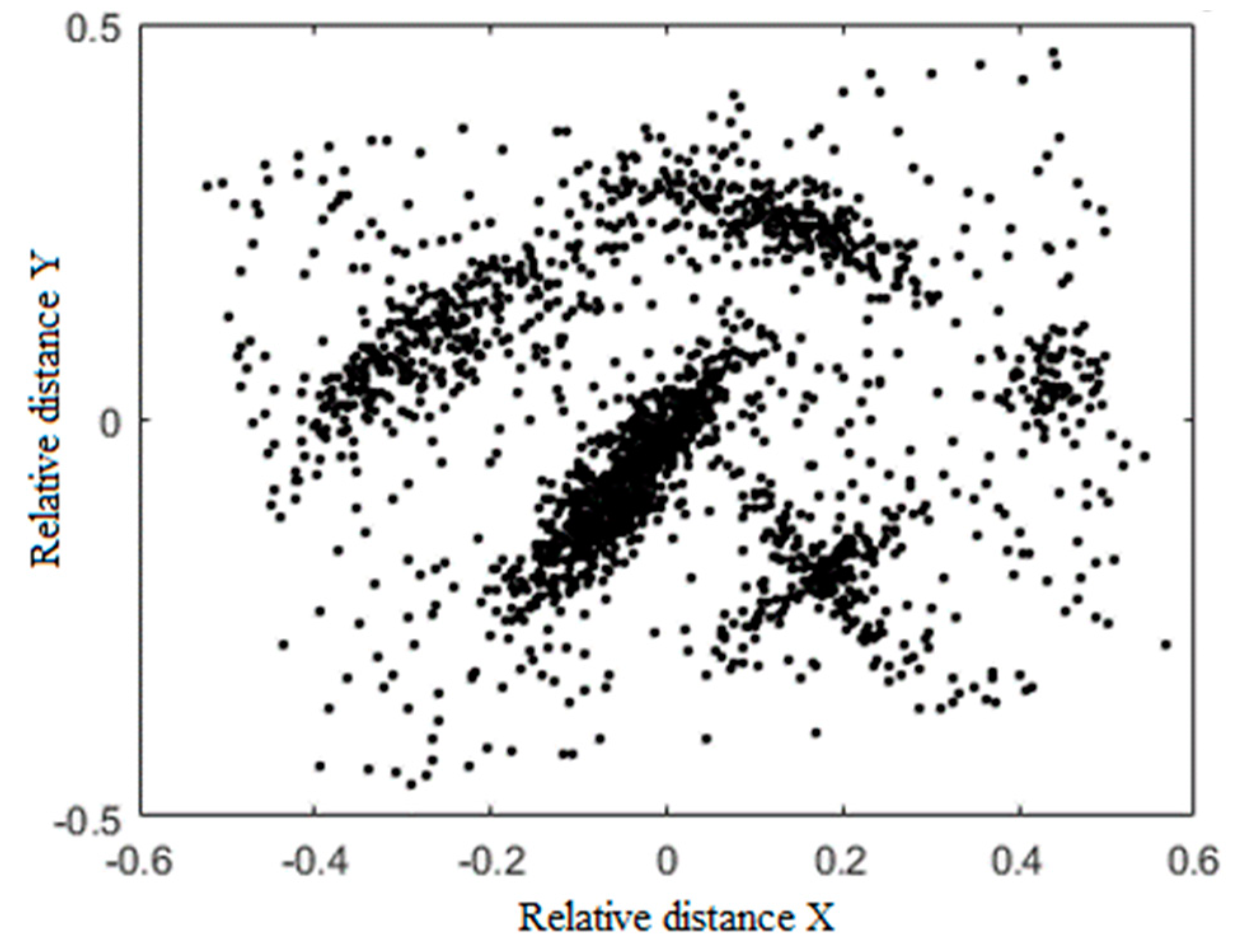
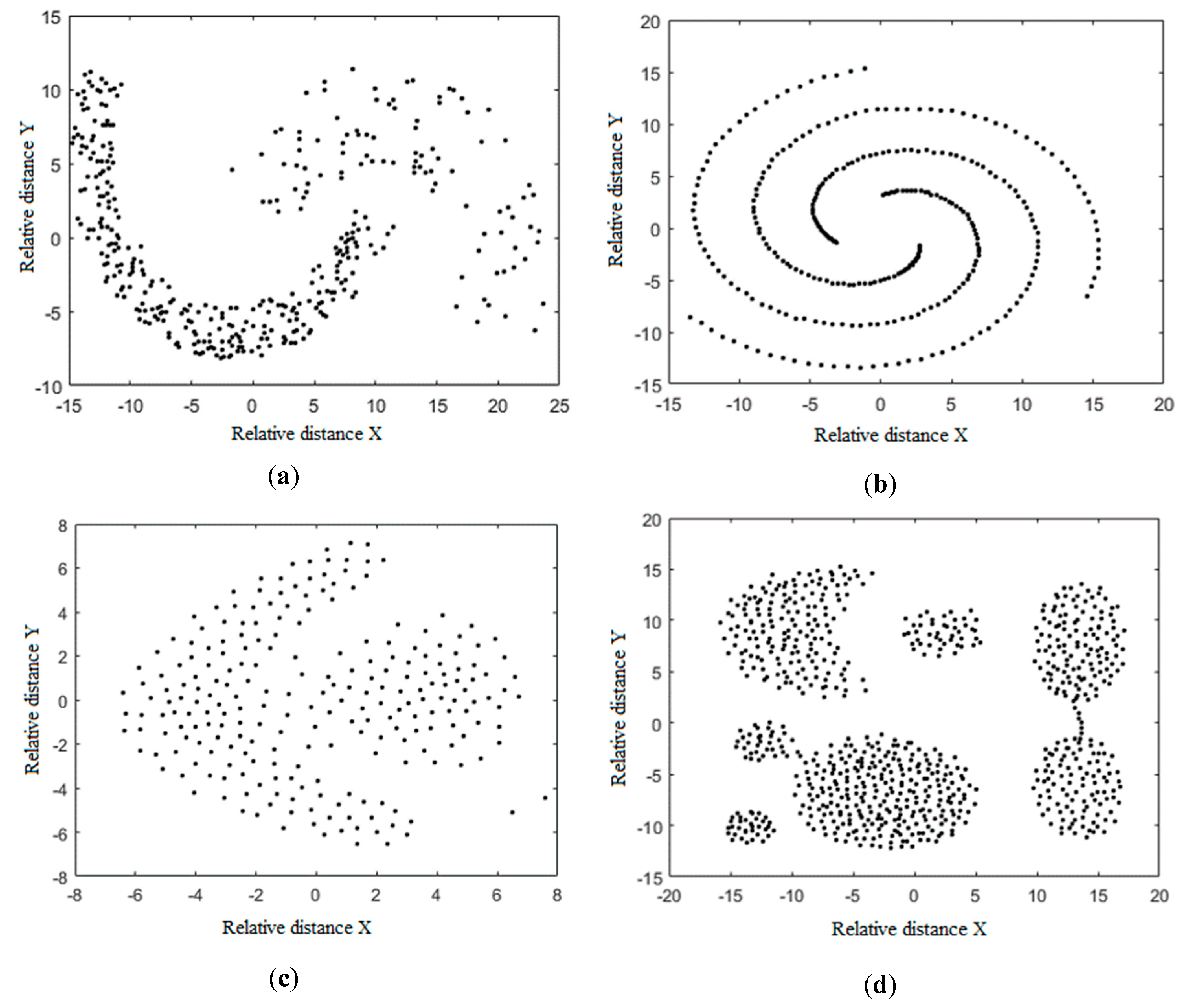
3. Experiments
3.1. Environmental Design
3.2. Results
3.3. Discussion
4. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- McAfee, A.; Brynjolfsson, E.; Davenport, T.H.; Patil, D.J.; Barton, D. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar] [PubMed]
- Zhang, C.; Zhang, H.; Qiao, J.; Yuan, D.; Zhang, M. Deep transfer learning for intelligent cellular traffic prediction based on cross-domain big data. IEEE J. Sel. Areas Commun. 2019, 37, 1389–1401. [Google Scholar] [CrossRef]
- Yao, Z.; Zhang, G.; Lu, D.; Liu, H. Data-driven crowd evacuation: A reinforcement learning method. Neurocomputing 2019, 366, 314–327. [Google Scholar] [CrossRef]
- Zhang, H.; Li, M. RWO-Sampling: A random walk over-sampling approach to imbalanced data classification. Inf. Fusion 2014, 20, 99–116. [Google Scholar] [CrossRef]
- Yan, Y.; Wu, L.; Gao, G.; Wang, H.; Xu, W. A dynamic integrity verification scheme of cloud storage data based on lattice and Bloom filter. J. Inf. Secur. Appl. 2018, 39, 10–18. [Google Scholar] [CrossRef]
- Alelyani, S.; Tang, J.; Liu, H. Feature Selection for Clustering: A Review; Data Clustering; Chapman and Hall/CRC: New York, NY, USA, 2018; pp. 29–60. [Google Scholar]
- Zhang, H.; Cao, L. A spectral clustering based ensemble pruning approach. Neurocomputing 2014, 139, 289–297. [Google Scholar] [CrossRef]
- Cheng, D.; Nie, F.; Sun, J.; Gong, Y. A weight-adaptive Laplacian embedding for graph-based clustering. Neural Comput. 2017, 29, 1902–1918. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef]
- Liu, R.; Wang, H.; Yu, X. Shared-nearest-neighbor-based clustering by fast search and find of density peaks. Inf. Sci. 2018, 450, 200–226. [Google Scholar] [CrossRef]
- Maamar, A.; Benahmed, K. A hybrid model for anomalies detection in AMI system combining k-means clustering and deep neural network. CMC-Computers. Mater. Contin. 2019, 60, 15–39. [Google Scholar]
- Wang, C.; Zhu, E.; Liu, X.; Qin, J.; Yin, J.; Zhao, K. Multiple kernel clustering based on self-weighted local kernel alignment. CMC-Computers. Mater. Contin. 2019, 61, 409–421. [Google Scholar]
- Bodenhofer, U.; Kothmeier, A.; Hochreiter, S. AP Cluster: An R package for affinity propagation clustering. Bioinformatics 2011, 27, 2463–2464. [Google Scholar] [CrossRef]
- Shang, F.; Jiao, L.C.; Shi, J.; Wang, F.; Gong, M. Fast affinity propagation clustering: A multilevel approach. Pattern Recognit. 2012, 45, 474–486. [Google Scholar] [CrossRef]
- Duan, L.; Xu, L.; Guo, F.; Lee, J.; Yan, B. A local-density based spatial clustering algorithm with noise. Inf. Syst. 2007, 32, 978–986. [Google Scholar] [CrossRef]
- De Oliveira, D.P.; Garrett, J.H., Jr.; Soibelman, L. A density-based spatial clustering approach for defining local indicators of drinking water distribution pipe breakage. Adv. Eng. Inform. 2011, 25, 380–389. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering Points to Identify the Clustering Structure; ACM Sigmod record; ACM: New York, NY, USA, 1999; Volume 28, pp. 49–60. [Google Scholar]
- Xu, D.; Tian, Y. A comprehensive survey of clustering algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef]
- Zhang, H.; Lu, J. SCTWC: An online semi-supervised clustering approach to topical web crawlers. Appl. Soft Comput. 2010, 10, 490–495. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA; pp. 855–864. [Google Scholar]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]
- Valdeolivas, A.; Tichit, L.; Navarro, C.; Perrin, S.; Odelin, G.; Levy, N.; Baudot, A. Random walk with restart on multiplex and heterogeneous biological networks. Bioinformatics. 2019, 35, 497–505. [Google Scholar] [CrossRef]
- Jian, M.; Zhao, R.; Sun, X.; Luo, H.; Zhang, W.; Zhang, H.; Lam, K.M. Saliency detection based on background seeds by object proposals and extended random walk. J. Vis. Commun. Image Represent. 2018, 57, 202–211. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA; pp. 701–710. [Google Scholar]
- Zou, S.R.; Zhou, T.; Liu, A.F.; Xu, X.L.; He, D.R. Topological relation of layered complex networks. Phys. Lett. A 2010, 374, 4406–4410. [Google Scholar] [CrossRef]
- Hou, S.; Zhou, S.; Liu, W.; Zheng, Y. Classifying advertising video by topicalizing high-level semantic concepts. Multimed. Tools Appl. 2018, 77, 25475–25511. [Google Scholar] [CrossRef]
- Tan, L.; Li, C.; Xia, J.; Cao, J. Application of self-organizing feature map neural network based on k-means clustering in network intrusion detection. CMC Comput. Mater. Contin. 2019, 61, 275–288. [Google Scholar]
- Qiong, K.; Li, X. Some topological indices computing results if archimedean lattices L(4, 6, 12). CMC Comput. Mater. Contin. 2019, 58, 121–133. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining. ACM: San Francisco, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA; pp. 1225–1234. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Sui, X.; Zheng, Y.; Wei, B.; Bi, H.; Wu, J.; Pan, X.; Zhang, S. Choroid segmentation from optical coherence tomography with graph-edge weights learned from deep convolutional neural networks. Neurocomputing 2017, 237, 332–341. [Google Scholar] [CrossRef]
- Wang, L.; Liu, H.; Liu, W.; Jing, N.; Adnan, A.; Wu, C. Leveraging logical anchor into topology optimization for indoor wireless fingerprinting. CMC Comput. Mater. Contin. 2019, 58, 437–449. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3730–3738. [Google Scholar]
- Qiu, X.; Mao, Q.; Tang, Y.; Wang, L.; Chawla, R.; Pliner, H.A.; Trapnell, C. Reversed graph embedding resolves complex single-cell trajectories. Nat. Methods 2017, 14, 979. [Google Scholar] [CrossRef]
- Zhang, B.; Zhu, L.; Sun, J.; Zhang, H. Cross-media retrieval with collective deep semantic learning. Multimed. Tools Appl. 2018, 77, 22247–22266. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, K. Superpixel guided structure sparsity for multispectral and hyperspectral image fusion over couple dictionary. Multimed. Tools Appl. 2019, 79, 1–16. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, H.; Meng, L. An angle structure descriptor for image retrieval. China Commun. 2016, 13, 222–230. [Google Scholar] [CrossRef]
- He, L.; Ouyang, D.; Wang, M.; Bai, H.; Yang, Q.; Liu, Y.; Jiang, Y. A method of identifying thunderstorm clouds in satellite cloud image based on clustering. CMC Comput. Mater. Contin. 2018, 57, 549–570. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, H.; Sun, J. A novel image retrieval method based on multi-trend structure descriptor. J. Vis. Commun. Image Represent. 2016, 38, 73–81. [Google Scholar] [CrossRef]
- He, L.; Bai, H.; Ouyang, D.; Wang, C.; Wang, C.; Jiang, Y. Satellite cloud-derived wind inversion algorithm using GPU. CMC Comput. Mater. Contin. 2019, 60, 599–613. [Google Scholar] [CrossRef]
- Roman, R.C.; Precup, R.E.; Bojan-Dragos, C.A.; Szedlak-Stinean, A.I. Combined Model-Free Adaptive Control with Fuzzy Component by Virtual Reference Feedback Tuning for Tower Crane Systems. Procedia Comput. Sci. 2019, 162, 267–274. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, X.; Ji, H.; Hou, Z.; Fan, L. Multi-Agent-Based Data-Driven Distributed Adaptive Cooperative Control in Urban Traffic Signal Timing. Energies 2019, 12, 1402. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Size | Attributes | Classes |
|---|---|---|---|
| Jain | 373 | 3 | 2 |
| Spiral | 312 | 3 | 3 |
| Flame | 240 | 3 | 2 |
| Aggregation | 788 | 3 | 7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, S.; Zheng, Y.; Luo, R.; Jia, W.; Lian, J.; Li, C. Density Peak Clustering Algorithm Considering Topological Features. Electronics 2020, 9, 459. https://doi.org/10.3390/electronics9030459
Lu S, Zheng Y, Luo R, Jia W, Lian J, Li C. Density Peak Clustering Algorithm Considering Topological Features. Electronics. 2020; 9(3):459. https://doi.org/10.3390/electronics9030459
Chicago/Turabian StyleLu, Shuyi, Yuanjie Zheng, Rong Luo, Weikuan Jia, Jian Lian, and Chengjiang Li. 2020. "Density Peak Clustering Algorithm Considering Topological Features" Electronics 9, no. 3: 459. https://doi.org/10.3390/electronics9030459
APA StyleLu, S., Zheng, Y., Luo, R., Jia, W., Lian, J., & Li, C. (2020). Density Peak Clustering Algorithm Considering Topological Features. Electronics, 9(3), 459. https://doi.org/10.3390/electronics9030459