Modelling the Publishing Process of Big Location Data Using Deep Learning Prediction Methods




Abstract
1. Introduction
- Temporal correlation: Although the total volume and update frequency of big location data change at a dynamic pace, the variation is not that huge for the adjacent data release within a certain time frame. This implies that observations at the adjacent time intervals are highly relevant. For example, a traffic congestion taking place during the morning peak hour, i.e., around 7:00 a.m, would probably last until 9:00 a.m.
- Spatial correlation: Combined with the distribution of urban roadside infrastructure and traffic networks, there is a certain spatial distribution pattern in the dense traffic areas of location big data. That is, the observations gained at nearby locations are correlated with each other, subsequently leading to local coherence in space.
- Periodicity: Peoples’ work and life follow a certain regularity, for instance both working days and off days have alternate patterns reflected in big location data. Through the visual analysis and long-term observation of the spatial and temporal distribution, it is easy to note that there is a clear similarity among the days and between the weeks.
- Heterogeneity: Heterogeneity means that the contribution of correlations to the final prediction results is not globally the same. Location data have a heterogeneous nature both in space and time. For instance, the peak hours and rapid changes are much more important than the off-peak hours for the purpose of ensuring accurate forecasting. Similarly, even within the same period of time, the densely populated commercial area is more important than the inaccessible far suburbs from the aspect of spatial characteristics.
- Randomness: Randomness primarily refers to the irregularity of location data in both time and space distribution. Although there are certain patterns in the time, place, and trajectory of peoples’ lives and work, we still cannot accurately predict when and where users would appear or even the exact number of people in the preceding second within a certain area.
- Uncertainty: Uncertainty mainly refers to the unpredictability of location data. For example, owing to weather changes, traffic events, and the behaviour of traffic participants, location data may suffer fluctuations and shift in the highest and lowest values in contrast to normal ones.
- We propose an adaptive adjusted sampling method to convert the problem of finding an optimal release time of big location data into a prediction problem for ascertaining the release time interval. This sampling and transformation method makes it possible to use deep learning methods in the later stage.
- We introduce the Maximal Overlap Discrete Wavelet Transform (MODWT) [10] method into the decomposition process of the location data sampling interval, which has proven to be helpful in describing sub-sequences with different characteristics and for enhancing the time series prediction accuracy.
- By analysing the characteristics of big location data, we select the main trends and fluctuations to be the two major features and accordingly adopt appropriate deep learning models to propose a release interval prediction method. Experimental results demonstrate that the prediction results of the proposed method improve to a significant degree as compared to the traditional models.
2. Literature Review
3. Sampling and Transformation Method
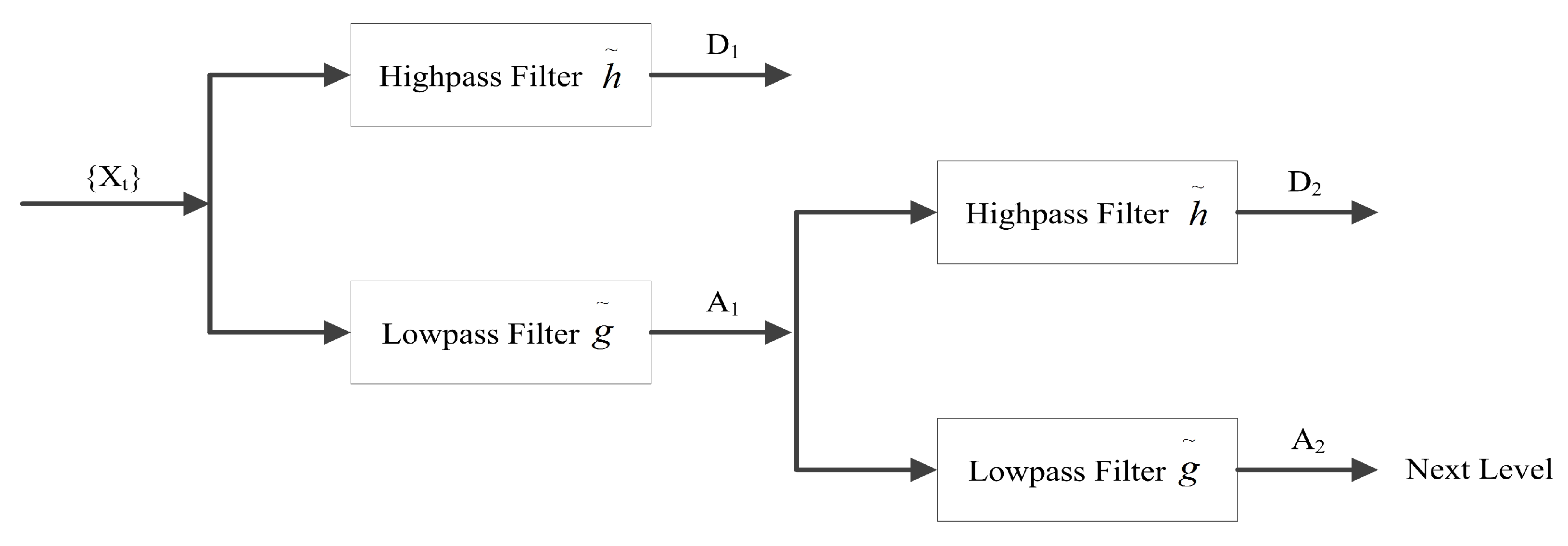
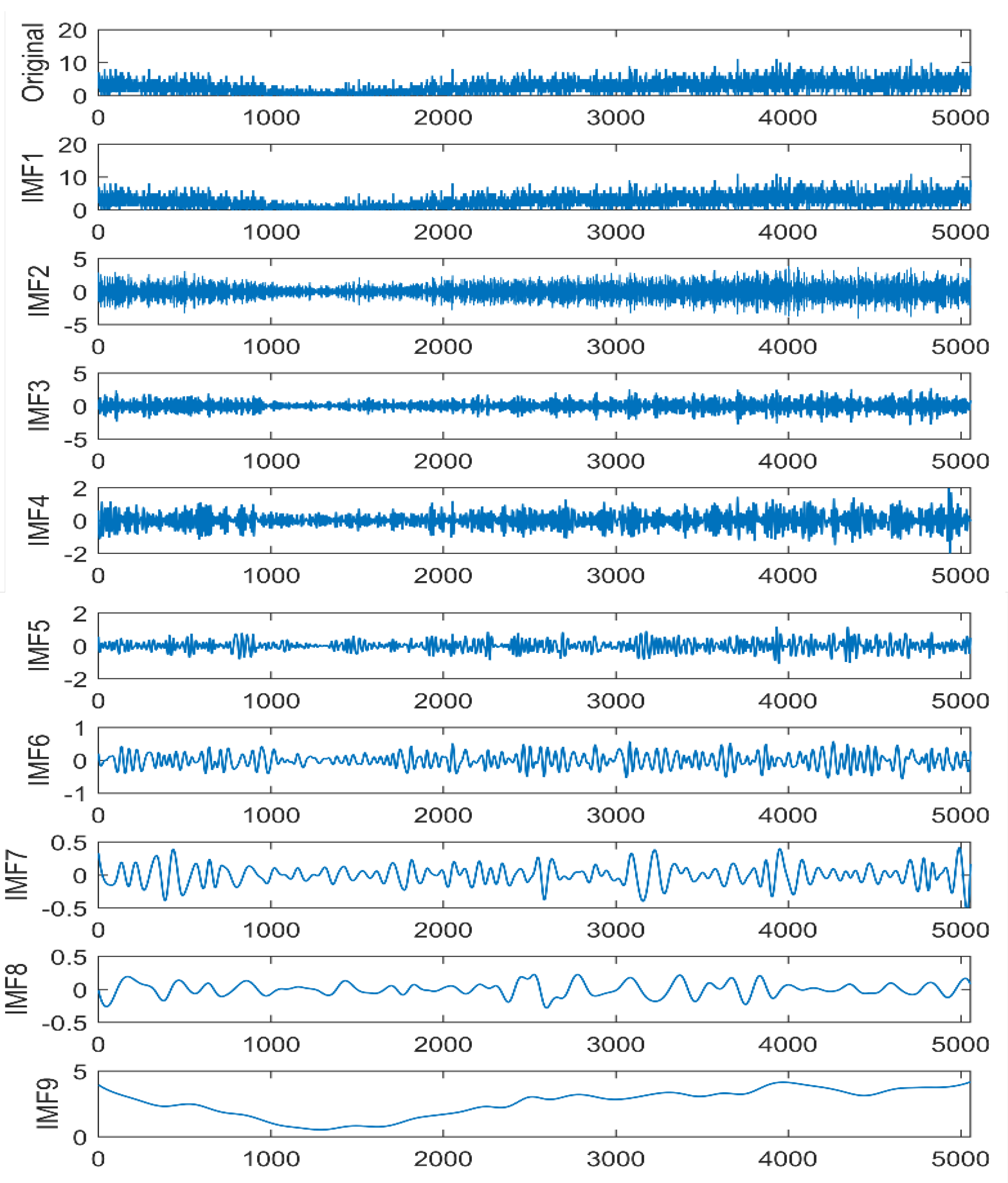
4. Time Series Decomposition
5. Predicting Publishing Interval Using Deep Learning Models
6. Experiments and Analysis
6.1. Experimental Dataset and Baseline Methods
- HA: The average value of historical records at each corresponding time interval was used for ascertaining the prediction result.
- ARIMA: The Autoregressive Integrated Moving Average model is a classical method for time series analysis [31].
- LSTM: Long Short-Term Memory model is a special kind of RNN, which consists of a cell, an input gate, an output gate, and a forget gate. We used a simple LSTM model in our experiment, which contained 32 hidden units.
- GRU: The Gated Recurrent Unit model is a variant of LSTM, which only consists of a reset gate and an update gate. In our experiment, the GRU model also contained 32 hidden units.
- CNN: We used the 1-dimensional Convolutional Neural Network [32] to carry out the prediction work on publishing time interval series, which contained 32 filters, one maxpooling layer (size = 2), and 50 hidden units.
- CNN-LSTM: The Convolutional LSTM model [33] combines the characteristics of both the CNN and LSTM models and is widely used for the prediction of short-term traffic flow. During the experiments, the parameter settings were the same as those of the separate CNN and LSTM.
6.2. Comparison and Analysis of the Results
6.2.1. Sampling and Transformation Effect
6.2.2. Time Series Decomposition Effect
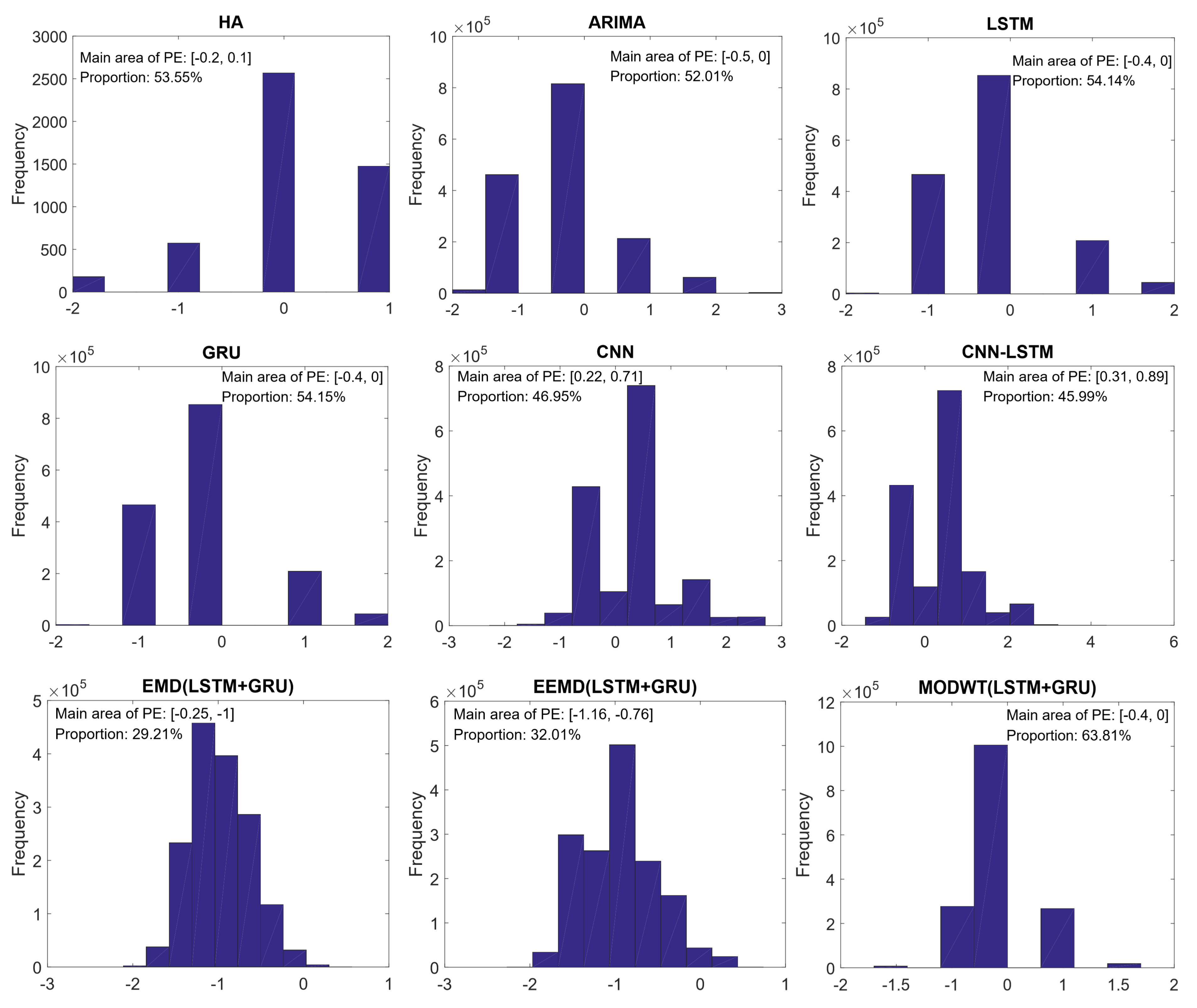
6.2.3. Prediction Effect
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ge, M.Z.; Bangui, H.; Buhnova, B. Big data for internet of things: A survey. Future Gener. Comput. Syst. 2018, 87, 601–614. [Google Scholar] [CrossRef]
- Zhu, L.; Yu, F.R.; Wang, Y.; Ning, B.; Tang, T. Big Data Analytics in Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2019, 20, 383–398. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, L.X.; Sheng, Q.Z.; Wang, B.Q.; Gao, X.; Cong, Y.M. Dynamic release of location big data based on adaptive sampling and differential privacy. IEEE Access 2019, 7, 164962–164974. [Google Scholar] [CrossRef]
- Pan, T.L.; Sumalee, A.; Zhong, R.X.; Indra-payoong, N. Short-Term Traffic State Prediction Based on Temporal–Spatial Correlation. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1242–1254. [Google Scholar] [CrossRef]
- Atluri, G.; Karpatne, A.; Kumar, V. Spatio-temporal data mining: A survey of problems and methods. ACM Comput. Surv. 2018, 51, 83. [Google Scholar] [CrossRef]
- Zayed, A. Advances in Shannon’s Sampling Theory; Routledge: New York, NY, USA, 1993. [Google Scholar]
- Weigend, A.S.; Gershenfeld, N.A. Time Series Prediction: Forecasting the Future and Understanding the Past; Taylor&Francis Group: Milton, UK, 2018. [Google Scholar]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent neural networks for multivariate time series with missing values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef] [PubMed]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Percival, D.B.; Walden, A.T. Wavelet Methods for Time Series Analysis; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar] [CrossRef]
- Koesdwiady, A.; Soua, R.; Karray, F. Improving traffic flow prediction with weather information in connected cars: A deep learning approach. IEEE Trans. Veh. Technol. 2016, 65, 9508–9517. [Google Scholar] [CrossRef]
- Yang, H.F.; Dillon, T.S.; Chen, Y.P.P. Optimized structure of the traffic flow forecasting model with a deep learning approach. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2371–2381. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef]
- Chen, W.; An, J.; Li, R.; Fu, L.; Xie, G.; Bhuiyan, M.Z.A.; Li, K. A novel fuzzy deep-learning approach to traffic flow prediction with uncertain spatial-temporal data features. Future Gener. Comput. Syst. 2018, 89, 78–88. [Google Scholar] [CrossRef]
- Qu, L.; Li, W.; Li, W.; Ma, D.; Wang, Y. Daily long-term traffic flow forecasting based on a deep neural network. Expert Syst. Appl. 2019, 121, 304–312. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, Y.; Qi, D. Deep spatio-temporal residual networks for citywide crowd flows prediction. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1655–1661. [Google Scholar]
- Ren, Y.; Cheng, T.; Zhang, Y. Deep spatio-temporal residual neural networks for road-network-based data modelling. Int. J. Geogr. Inf. Sci. 2019, 33, 1894–1912. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Qin, L.; Ran, B.; Jiang, Z. A hybrid deep learning based traffic flow prediction method and its understanding. Transp. Res. Part C 2018, 90, 166–180. [Google Scholar] [CrossRef]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Guo, S.; Lin, Y.; Li, S.; Chen, Z.; Wan, H. Deep spatial-temporal 3D convolutional neural networks for traffic data forecasting. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3913–3926. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Chao, T.; Liu, H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Qiu, X.; Ren, Y.; Suganthan, P.N.; Amaratunga, G.A.J. Empirical mode decomposition based ensemble deep learning for load demand time series forecasting. Appl. Soft Comput. 2017, 54, 246–255. [Google Scholar] [CrossRef]
- Wang, W.; Chau, K.; Xu, D.; Chen, X.Y. Improving forecasting accuracy of annual runoff time series using ARIMA based on EEMD decomposition. Water Resour. Manag. 2015, 29, 2655–2675. [Google Scholar] [CrossRef]
- Ghosh, I.; Chaudhuri, T.D. Fractal Investigation and Maximal Overlap Discrete Wavelet Transformation (MODWT)-based Machine Learning Framework for Forecasting Exchange Rates. Stud. Microecon. 2017, 5, 105–131. [Google Scholar] [CrossRef]
- He, F.; Zhang, Y.; Liu, D.; Dong, Y.; Liu, C.; Wu, C. Mixed Wavelet-Based Neural Network Model for Cyber Security Situation Prediction Using MODWT and Hurst Exponent Analysis. In Proceedings of the International Conference on Network and System Security, Helsinki, Finland, 21–23 August 2017; pp. 99–111. [Google Scholar]
- Prasad, R.; Deo, R.C.; Li, Y.; Maraseni, T. Input selection and performance optimization of ANN-based streamflow forecasts in the drought-prone Murray Darling Basin region using IIS and MODWT algorithm. Atmos. Res. 2017, 97, 42–63. [Google Scholar] [CrossRef]
- Menon, A.K.; Lee, Y. Predicting short-term public transport demand via in homogeneous poisson processes. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2207–2210. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modelling. In Proceedings of the NIPS Deep Learning of Representations, Montreal, QC, Canada, 12 December 2014. [Google Scholar]
- Ahmed, M.S.; Cook, A.R. Analysis of freeway traffic time-series data by using Box-Jenkins techniques. Transp. Res. Rec. J. Transp. Res. Board 1979, 722, 1–9. [Google Scholar]
- Abdeljabera, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Xingjian, S.H.I.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2015; pp. 802–810. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Attribute Name | Description |
|---|---|---|
| 1 | Year | Year of the data (in “yyyy” format) |
| 2 | Month | The numerical value of the month in “mm” format (ranges from 1 to 12) |
| 3 | Weekdays | Days of a week, e.g., Monday; the values are displayed in numerical format ranging from 1 to 7, where 6 represents Saturday and 7 represents Sunday |
| 4 | Day | Defines the day of a month in “dd” format (ranges from 1 to 31) |
| 5 | Hours | Clock hours in numbers (starting from 0 to 23) |
| 6 | Interval Value | Numerical value of sampling intervals obtained by the adaptive adjusted sampling method on the experimental dataset |
| Model | Details | ||
|---|---|---|---|
| LSTM | Layer (type) | Output Shape | Param |
| LSTM | (None,32) | 4992 | |
| Dense | (None,1) | 33 | |
| Total params: 5025 | |||
| GRU | GRU | (None,32) | 3744 |
| Dense | (None,1) | 33 | |
| Total params: 3777 | |||
| CNN | Conv1D | (None,5,32) | 96 |
| Maxpooling | (None,2,32) | 0 | |
| Flatten | (None,64) | 0 | |
| Dense | (None,50) | 3250 | |
| Dense | (None,1) | 51 | |
| Total params: 3397 | |||
| CNN-LSTM | TimeDist | (None,None,2,32) | 96 |
| TimeDist | (None,None,1,32) | 0 | |
| TimeDist | (None,None,32) | 0 | |
| LSTM | (None,32) | 8320 | |
| Dense | (None,1) | 33 | |
| Total params: 8449 | |||
| Measurement | Original | Fixed Sampling | Poisson Sampling | Adaptive Sampling | |
|---|---|---|---|---|---|
| Entropy | Value | 2.9278 | 2.8998 | 2.9296 | 2.9287 |
| Distortion | - | 0.0096 | 0.0006 | 0.0003 | |
| Time-domain skewness | - | 0.0472 | 0.1821 | 0.0179 | |
| Expectation | Value | 2.7854 | 2.7939 | 2.8008 | 2.7968 |
| Distortion | - | 0.0031 | 0.0055 | 0.0041 | |
| Variance | Value | 4.4019 | 3.8174 | 5.2299 | 4.2788 |
| Distortion | - | 0.1328 | 0.1881 | 0.028 | |
| Covariance | Value | 4.402 | 3.8175 | 5.2301 | 4.2797 |
| Distortion | - | 0.1328 | 0.1881 | 0.0278 | |
| Model | RMSE | MAE | MAPE |
|---|---|---|---|
| HA | 0.7592 | 0.5018 | 2.952 |
| ARIMA | 0.6967 | 0.4745 | 2.8105 |
| LSTM | 0.6813 | 0.4642 | 2.7197 |
| GRU | 0.6806 | 0.4632 | 2.7143 |
| CNN | 0.7345 | 0.4851 | 2.879 |
| CNN-LSTM | 0.8435 | 0.544 | 3.2471 |
| EMD (LSTM+GRU) | 2.5042 | 1.8901 | 11.1532 |
| EEMD (LSTM+GRU) | 0.6747 | 0.4422 | 2.6282 |
| MODWT (LSTM+GRU) | 0.6003 | 0.3417 | 2.0301 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Y.; Wang, B.; Sheng, Q.Z.; Mahmood, A.; Feng, T.; Xie, P. Modelling the Publishing Process of Big Location Data Using Deep Learning Prediction Methods. Electronics 2020, 9, 420. https://doi.org/10.3390/electronics9030420
Yan Y, Wang B, Sheng QZ, Mahmood A, Feng T, Xie P. Modelling the Publishing Process of Big Location Data Using Deep Learning Prediction Methods. Electronics. 2020; 9(3):420. https://doi.org/10.3390/electronics9030420
Chicago/Turabian StyleYan, Yan, Bingqian Wang, Quan Z. Sheng, Adnan Mahmood, Tao Feng, and Pengshou Xie. 2020. "Modelling the Publishing Process of Big Location Data Using Deep Learning Prediction Methods" Electronics 9, no. 3: 420. https://doi.org/10.3390/electronics9030420
APA StyleYan, Y., Wang, B., Sheng, Q. Z., Mahmood, A., Feng, T., & Xie, P. (2020). Modelling the Publishing Process of Big Location Data Using Deep Learning Prediction Methods. Electronics, 9(3), 420. https://doi.org/10.3390/electronics9030420