The High Performance of a Task Scheduling Algorithm Using Reference Queues for Cloud- Computing Data Centers



Abstract
:1. Introduction
2. Literature Review
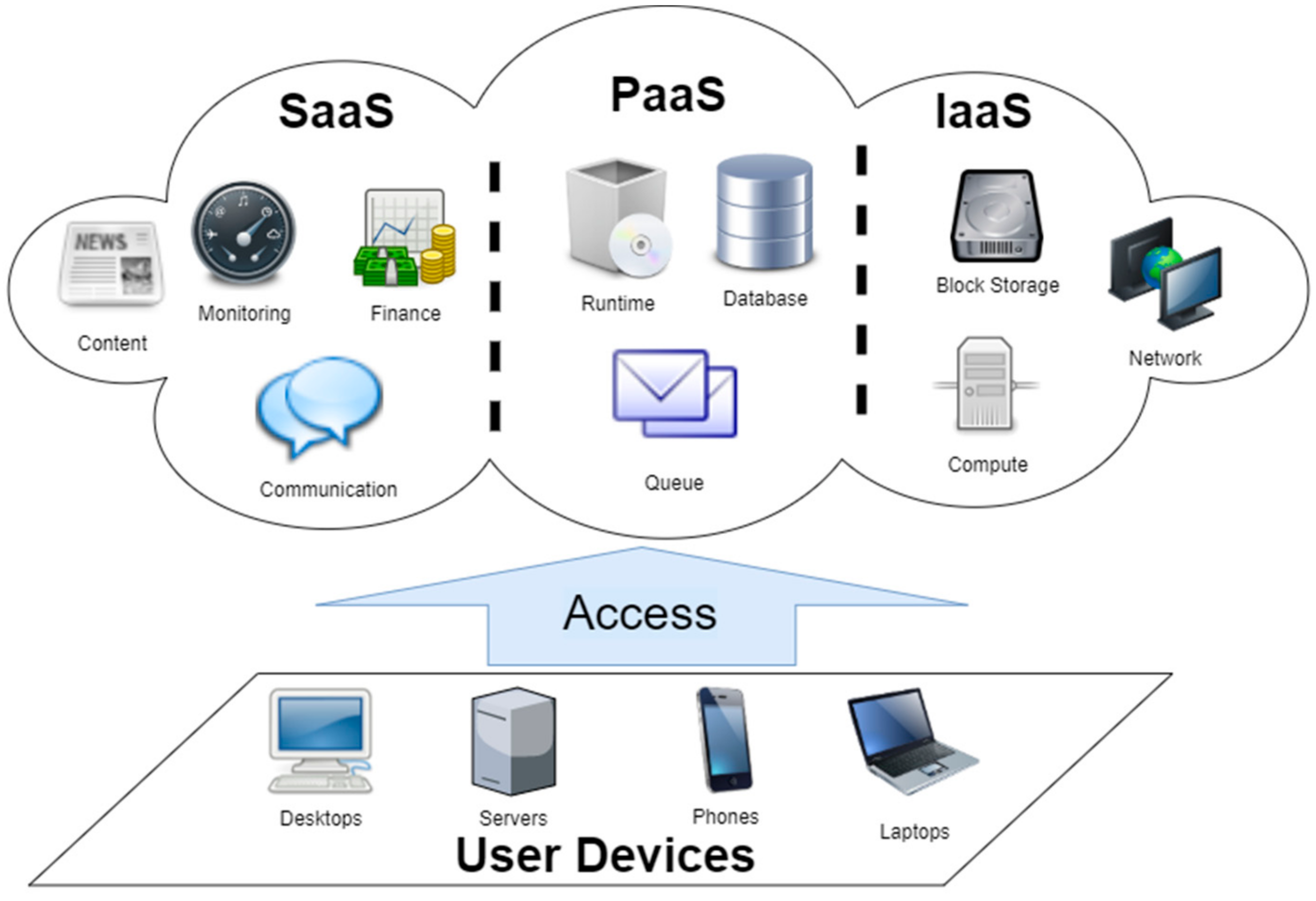
2.1. The Cloud Computing
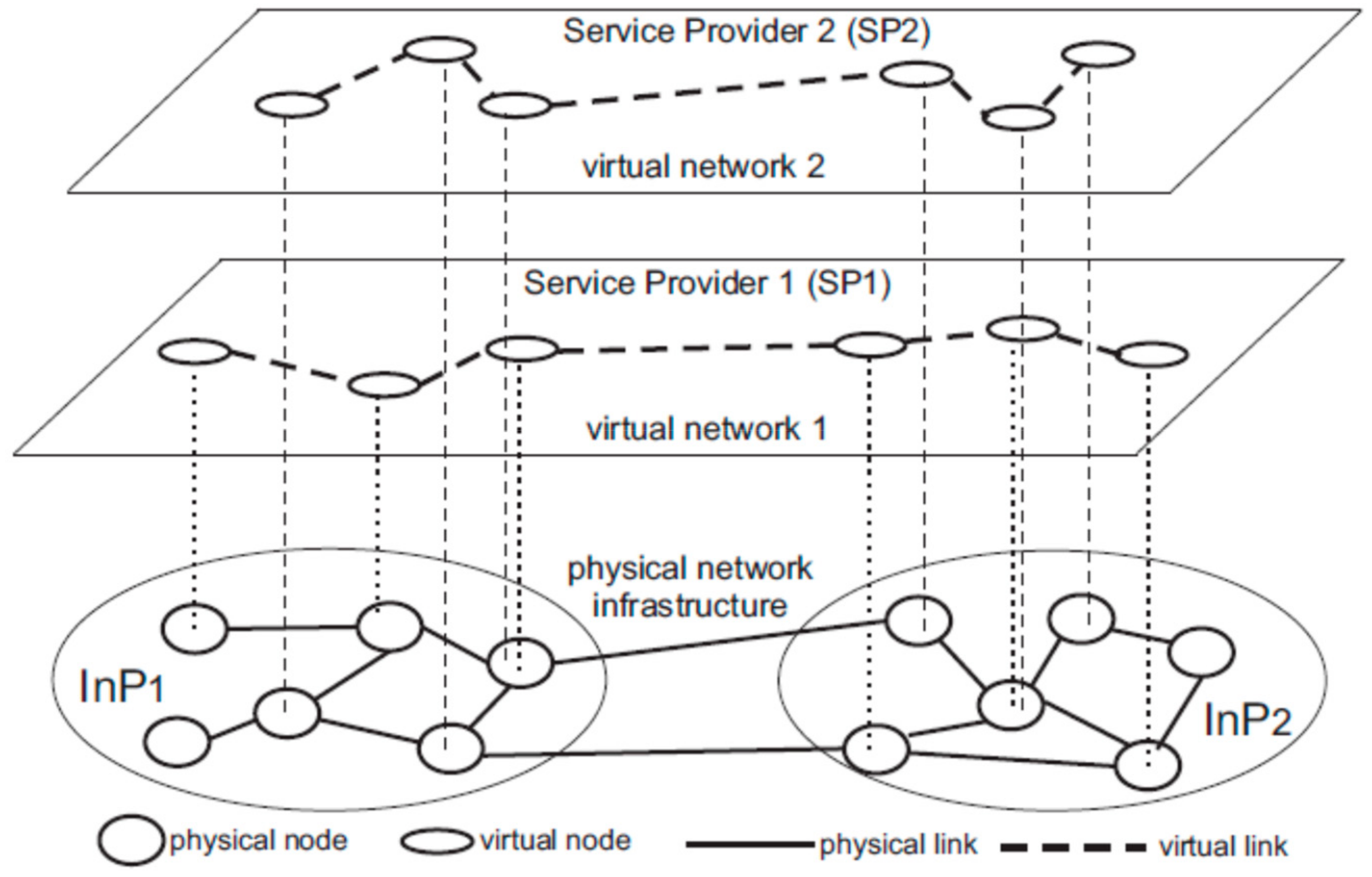
2.2. The Hierarchical Virtualization Topology
2.3. The Related Study of a Scheduling Algorithm
3. The Study Method
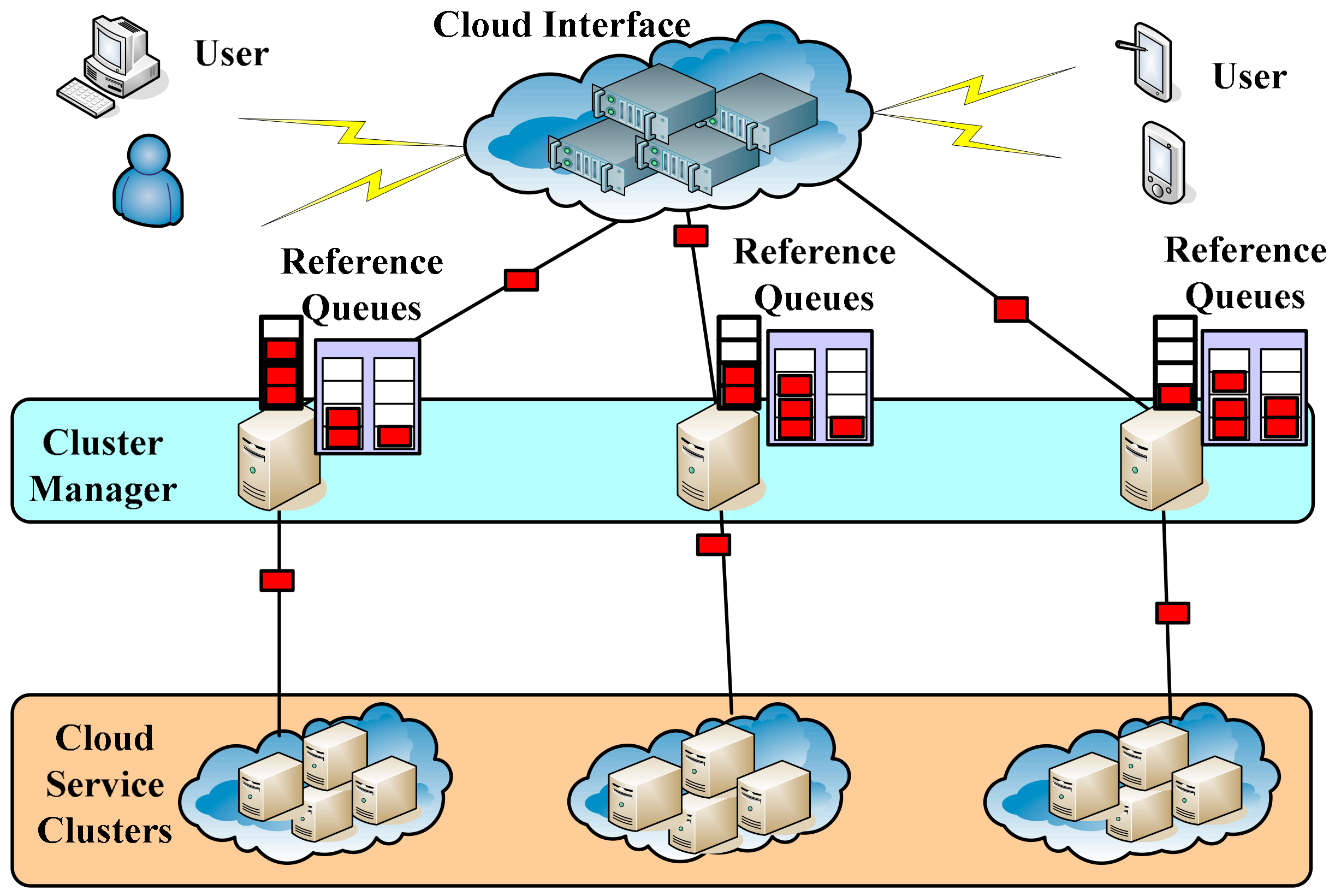
3.1. Reference Queue Based Cloud Service Architecture (RQCSA)
- Cloud Interface (CI): For receiving requests from the users.
- Cluster Manager (CM): Selecting the head cluster from the cloud service cluster. The CM receives jobs from the CI and distributes jobs to the designated cloud service cluster for executing.
- Cloud Service Cluster (CSC): This is the main service node cluster that receives jobs from the CM and executes them.
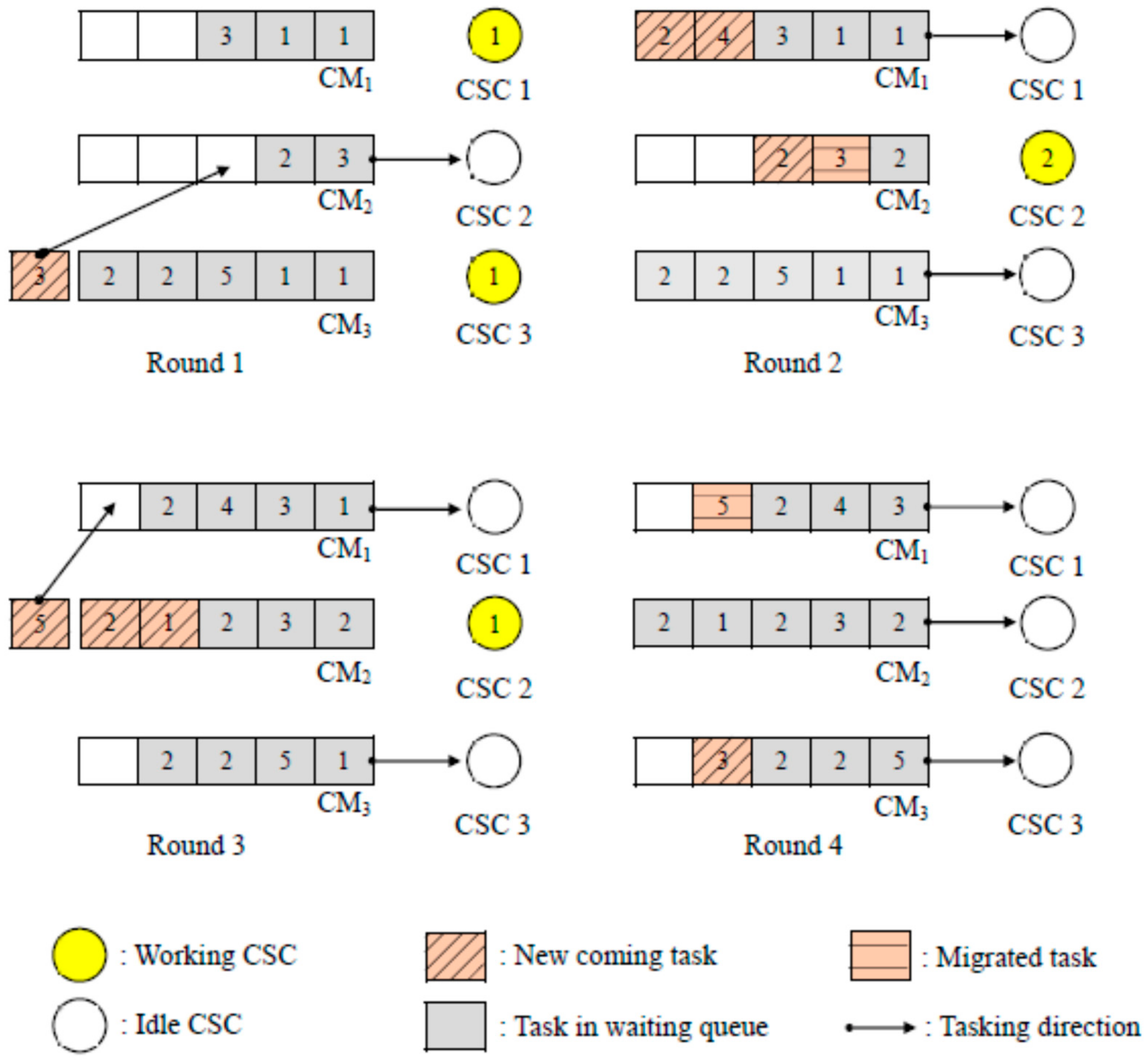
3.2. Fitness Service Queue Selection Mechanism (FSQSM)
4. Experimental Simulation
4.1. The Experimental Environment
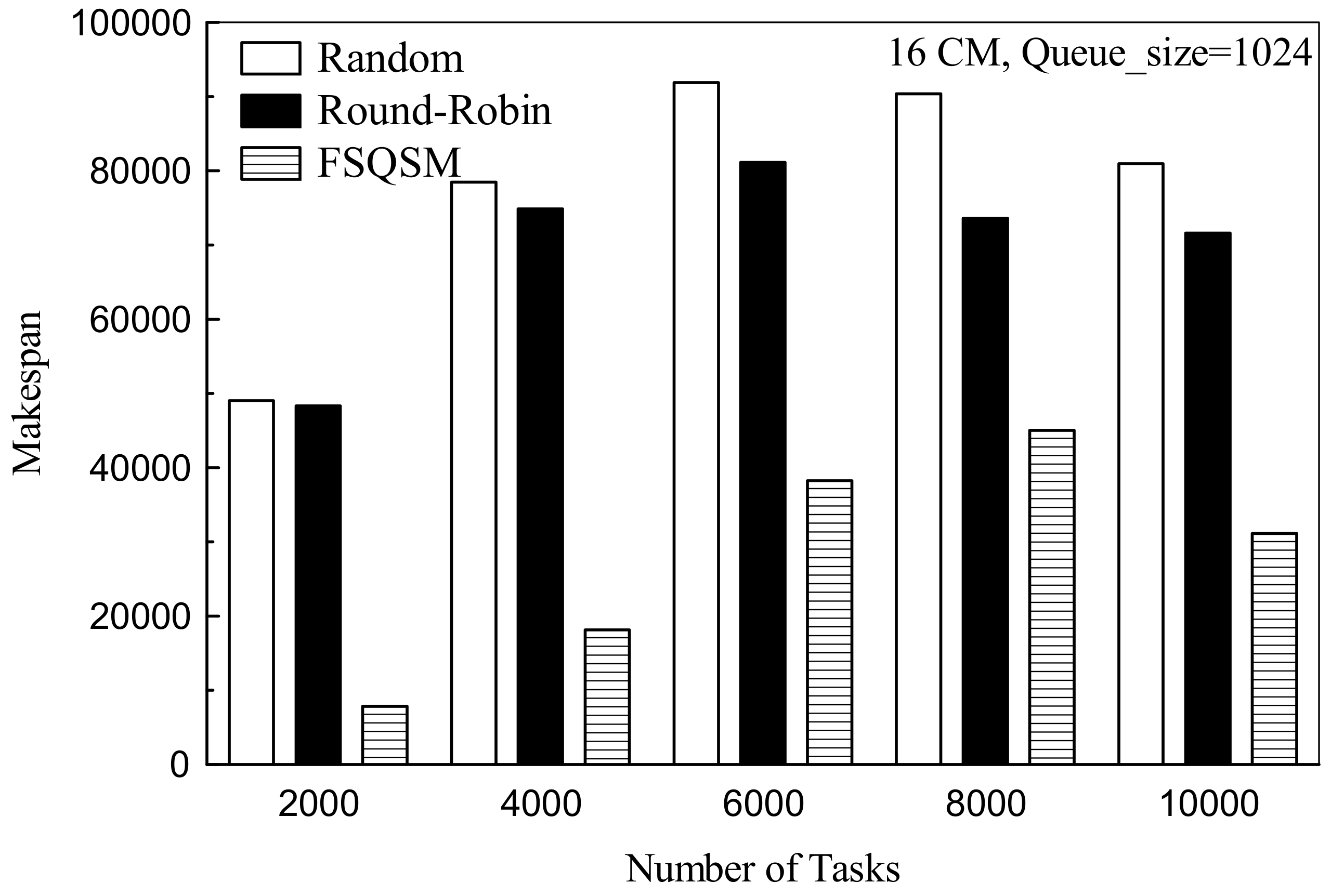
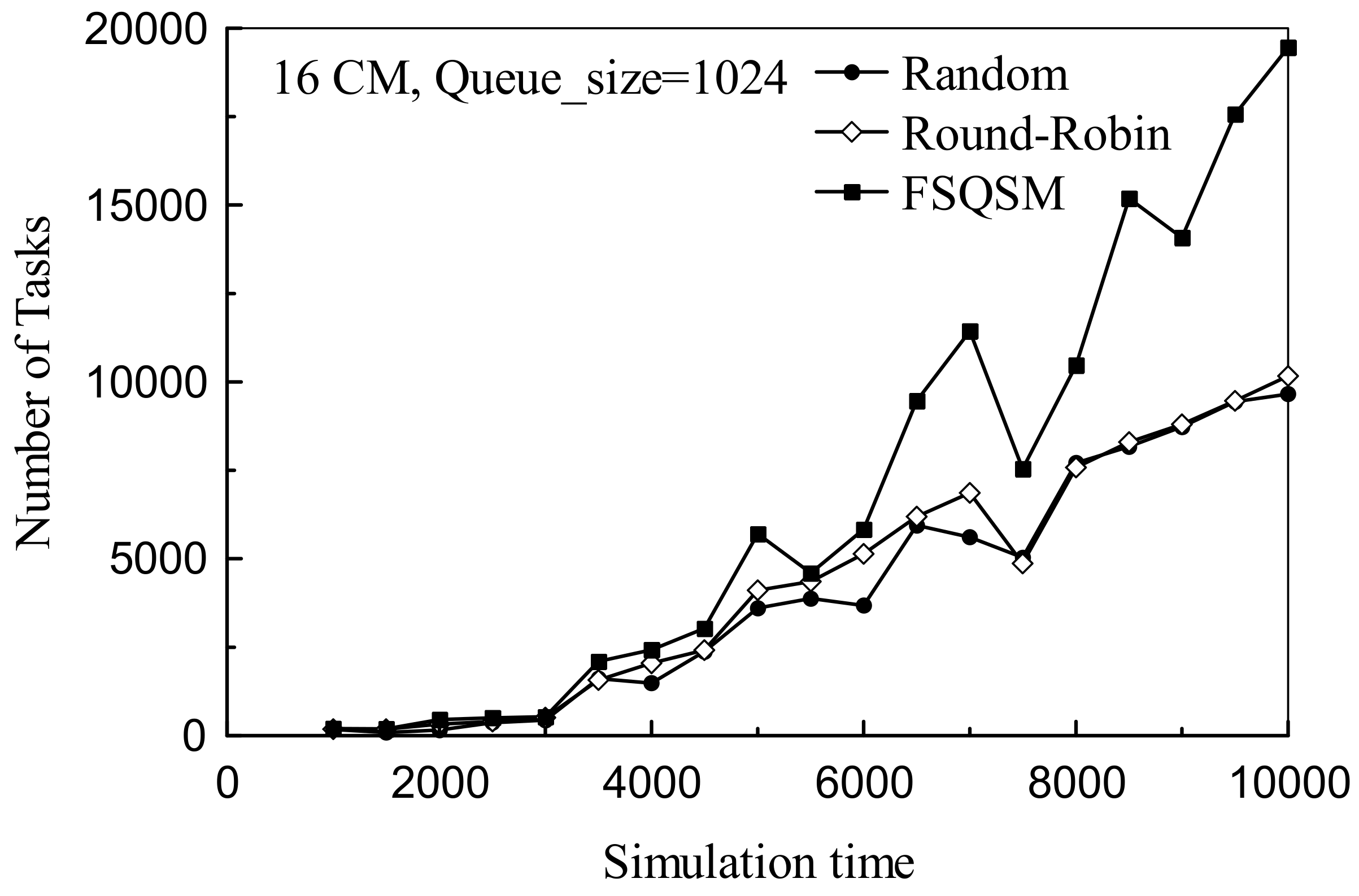
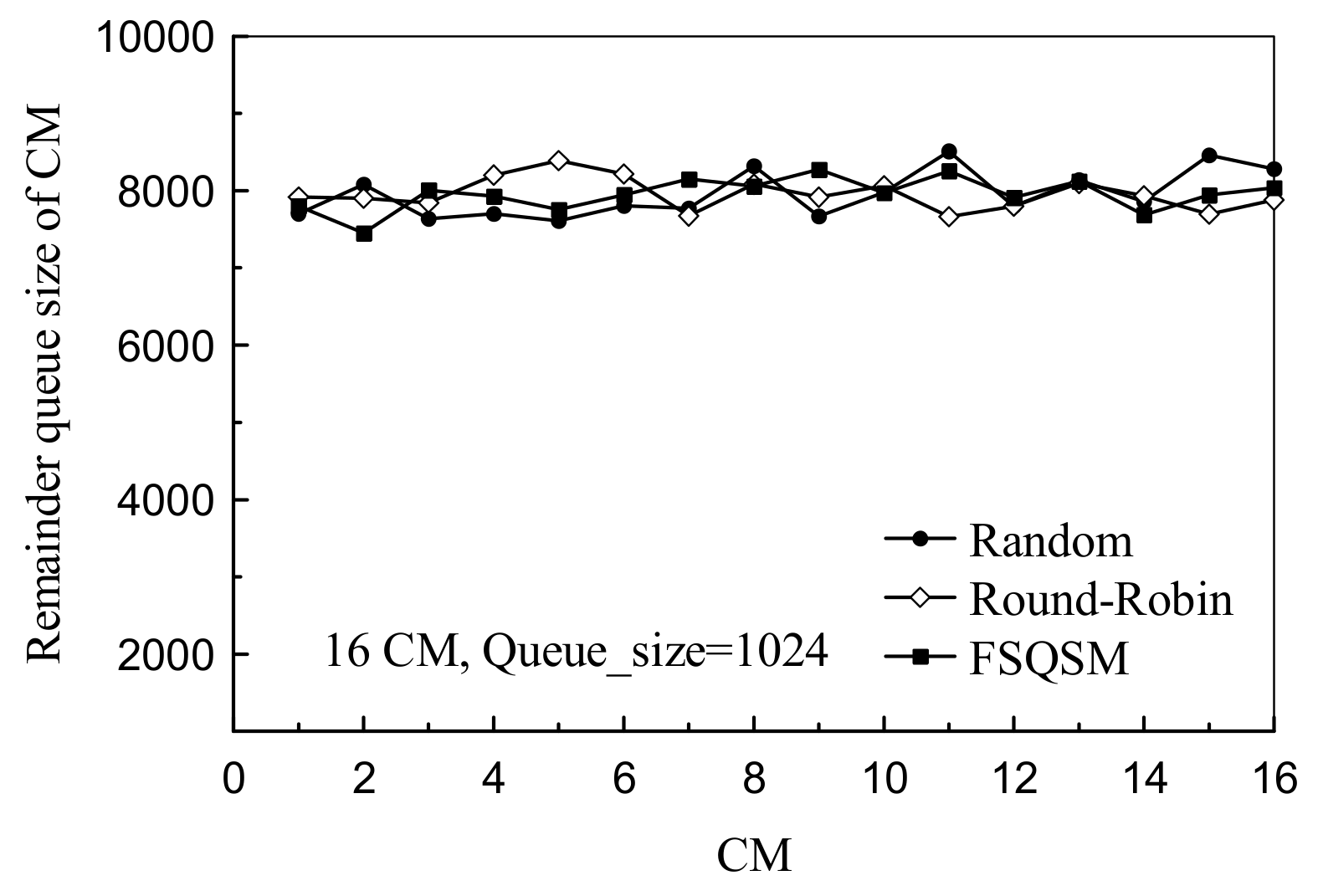
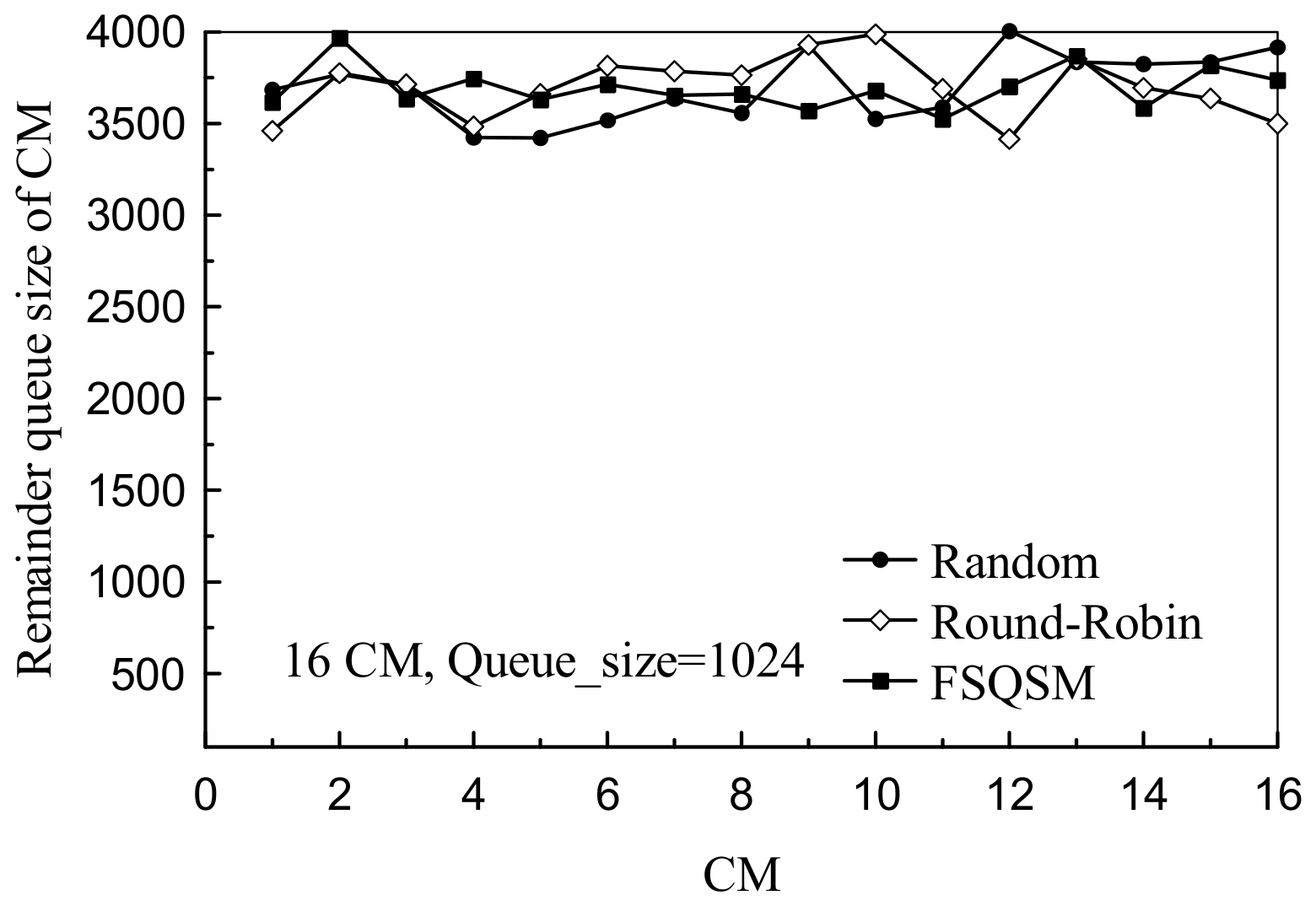
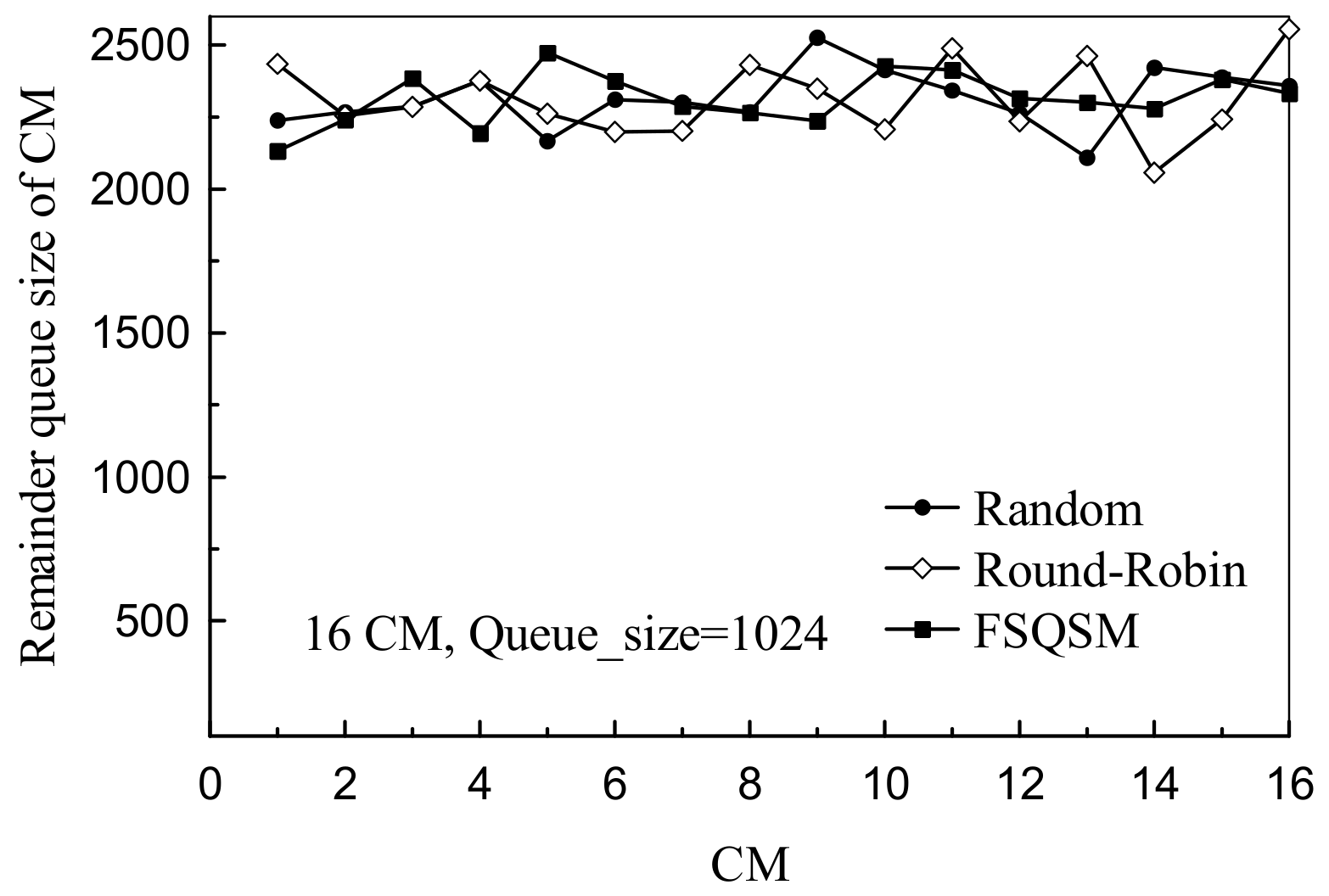
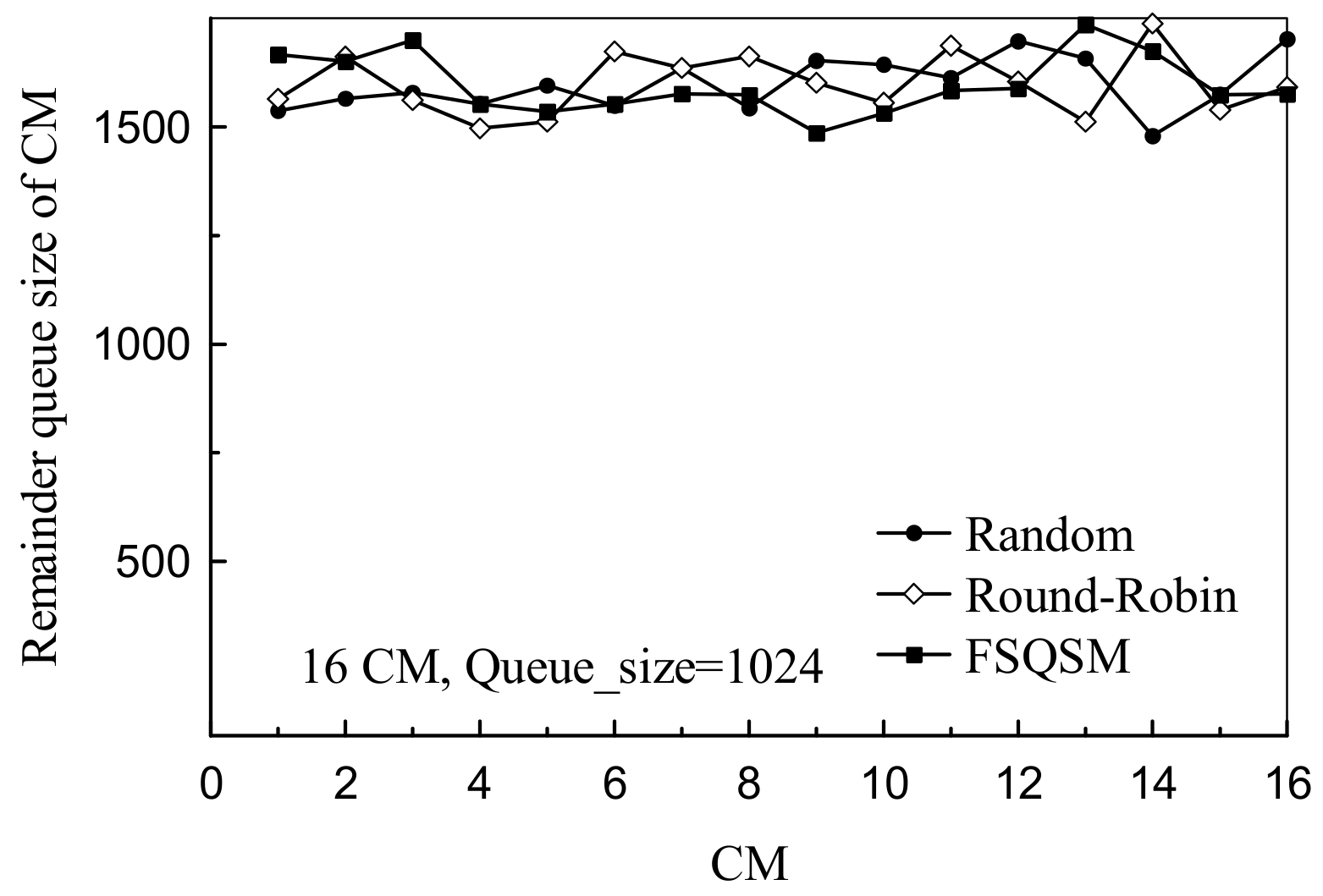
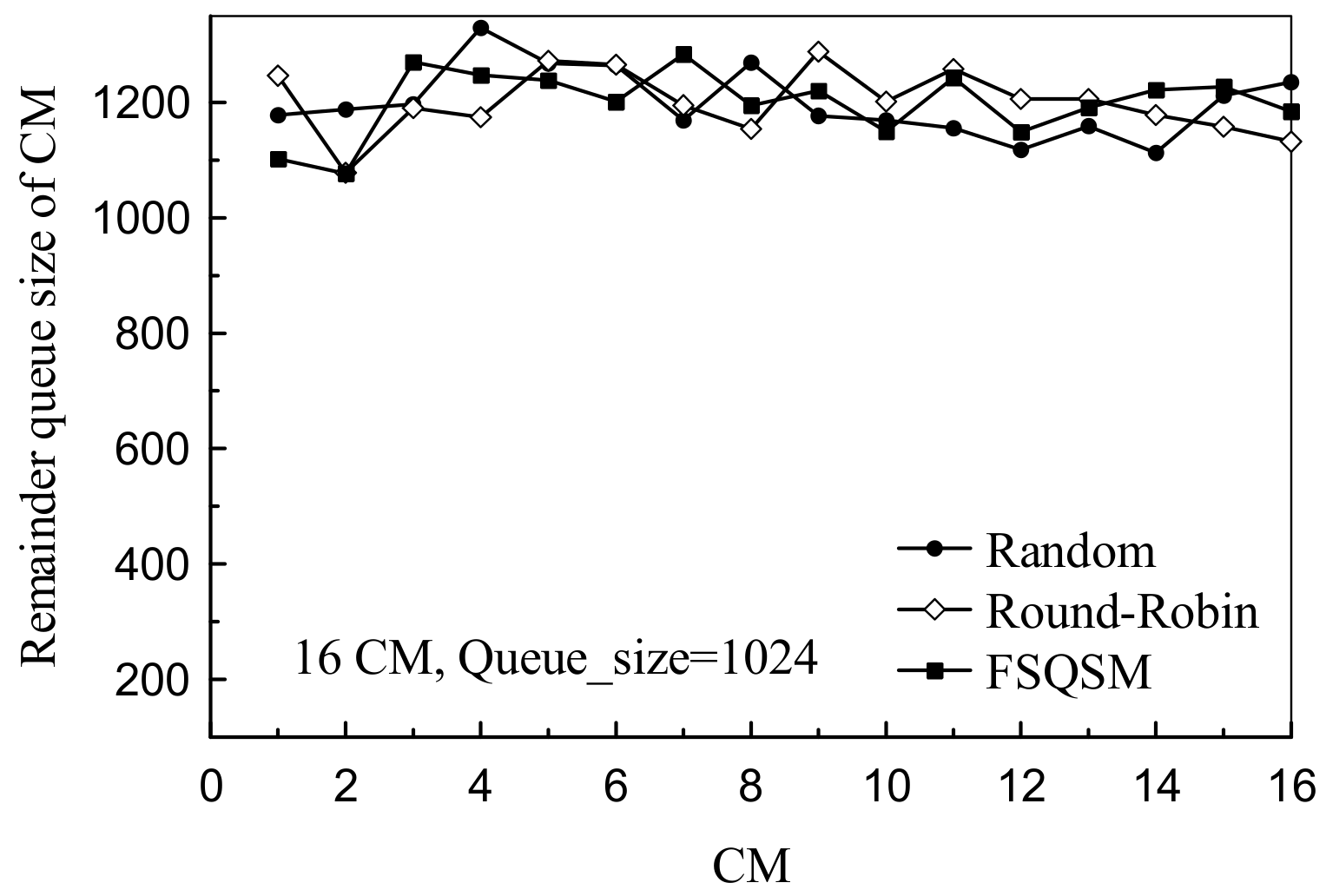
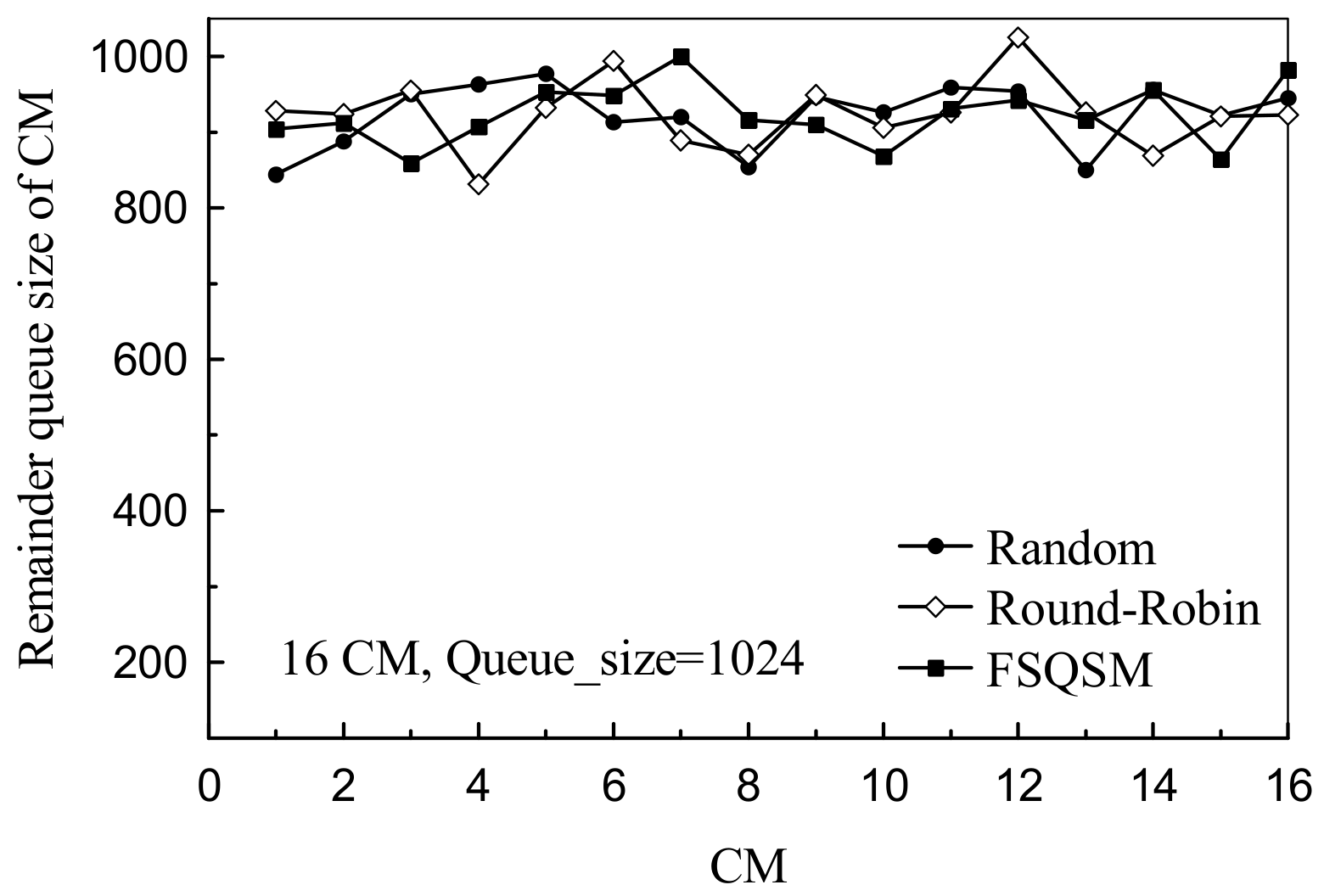
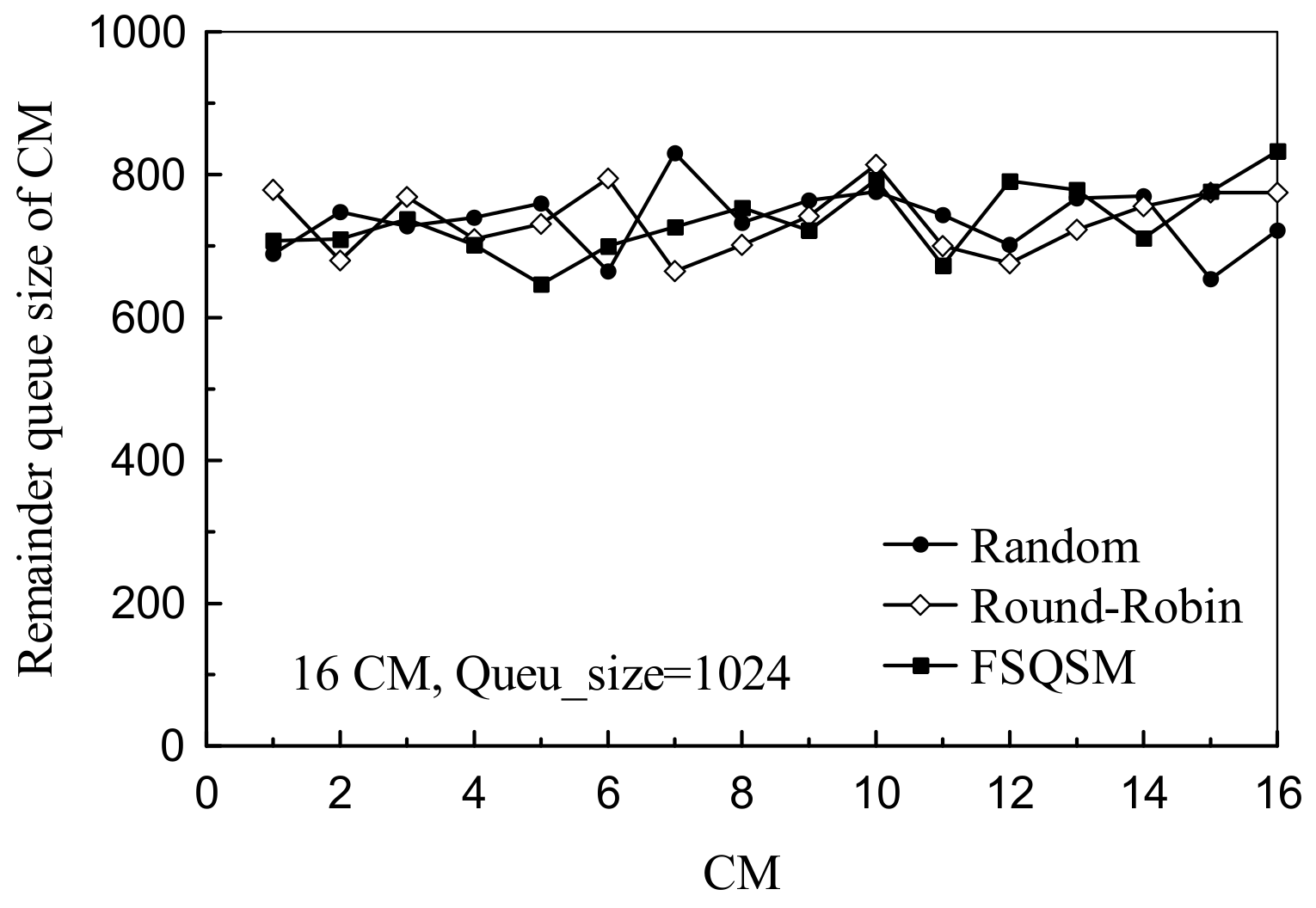
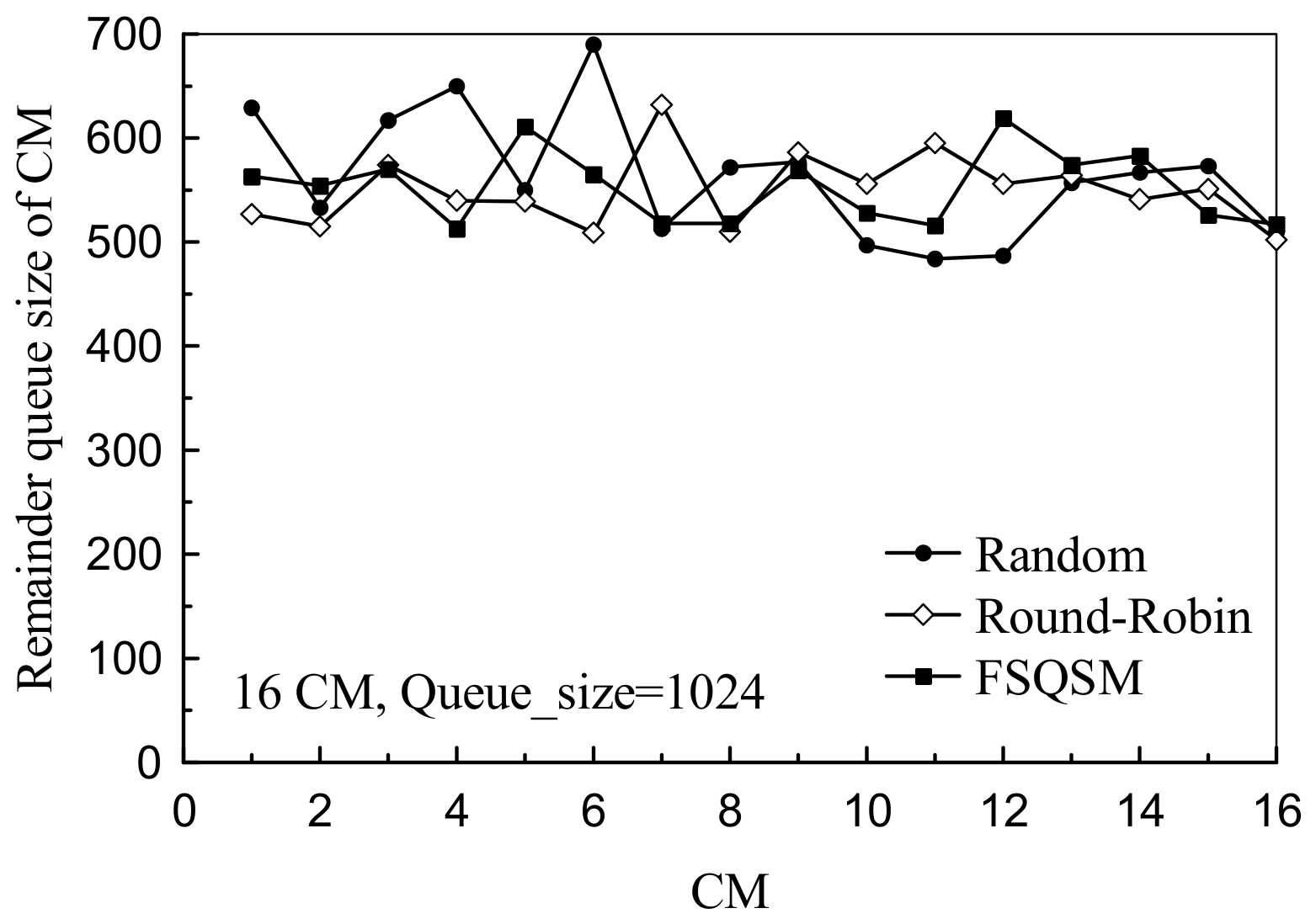
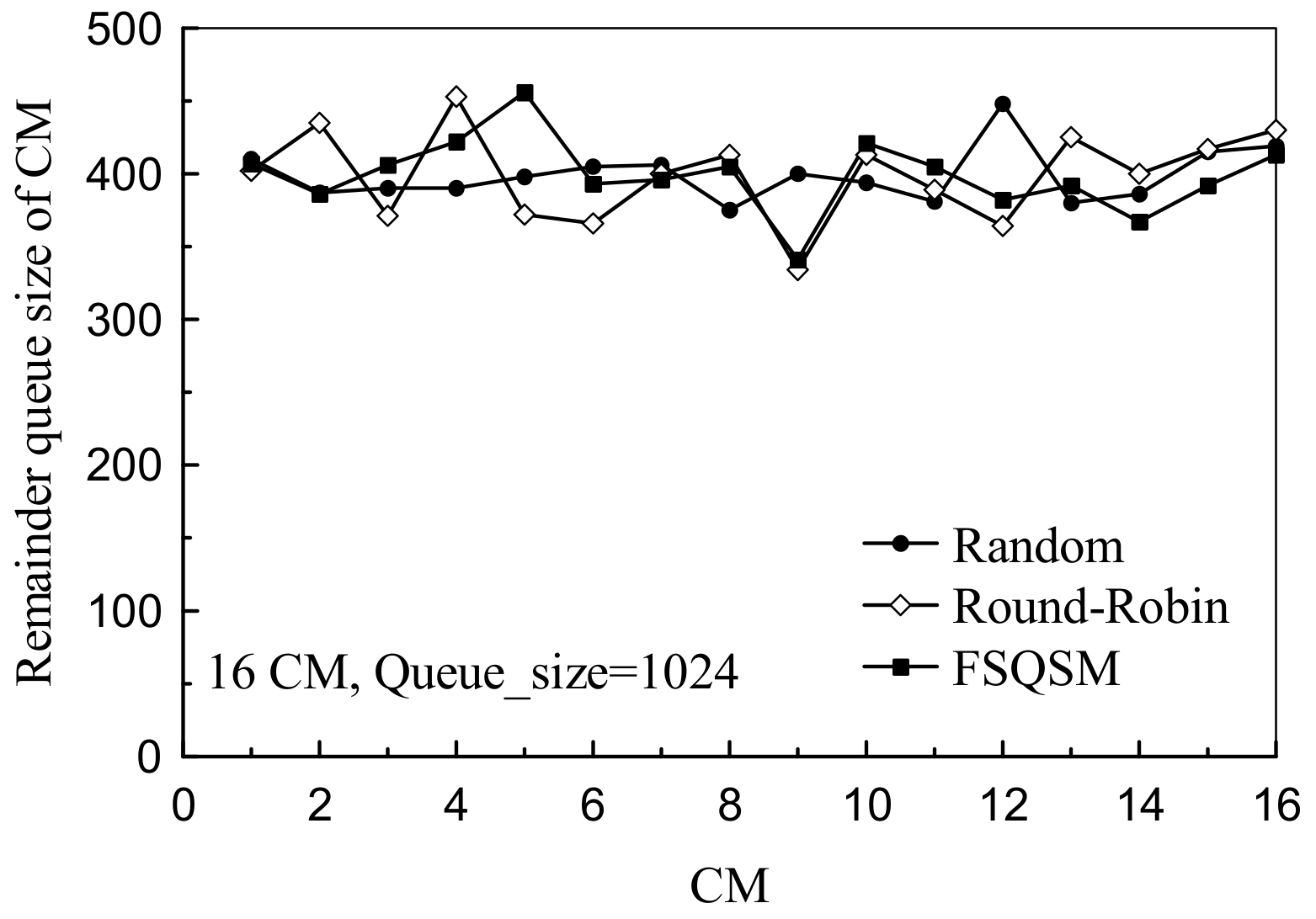
4.2. Performance Analysis
5. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Josep, A.D.; Katz, R.; Konwinski, A.; Gunho, L.E.E.; Patterson, D.; Rabkin, A. A view of cloud computing. Commun. ACM 2010, 53, 50–58. [Google Scholar]
- Wang, J.; Chen, X.; Li, J.; Zhao, J.; Shen, J. Towards achieving flexible and verifiable search for outsourced database in cloud computing. Future Gener. Comput. Syst. 2017, 67, 266–275. [Google Scholar] [CrossRef]
- Rajkumar Buyya, J.B.; Goscinski, A. Cloud Computing Principles and Paradigms; Wiley: Delhi, India, 4 April 2013. [Google Scholar]
- Dinh, H.T.; Lee, C.; Niyato, D.; Wang, P. A survey of mobile cloud computing: Architecture, applications, and approaches. Wirel. Commun. Mob. Comput. 2013, 13, 1587–1611. [Google Scholar] [CrossRef]
- Distributed Computing. July 2015. Available online: https://whatis.techtarget.com/definition/distributed-computing (accessed on 6 January 2020).
- Guo, L.; Shen, H. Efficient approximation algorithms for the bounded flexible scheduling problem in clouds. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 3511–3520. [Google Scholar] [CrossRef]
- Duan, Q.; Yan, Y.; Vasilakos, A.V. A survey on service-oriented network virtualization toward convergence of networking and cloud computing. IEEE Trans. Netw. Serv. Manag. 2013, 9, 373–392. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, X.; Chang, V. Semantic keyword searchable proxy re-encryption for postquantum secure cloud storage. Concurr. Comput. Pract. Exp. 2017, 29, e4211. [Google Scholar] [CrossRef]
- Botta, A.; De Donato, W.; Persico, V.; Pescapé, A. Integration of cloud computing and Internet of things: A survey. Future Gener. Comput. Syst. 2016, 56, 684–700. [Google Scholar] [CrossRef]
- Bailey, S.F.; Scheible, M.K.; Williams, C.; Silva, D.S.; Hoggan, M.; Eichman, C.; Faith, S.A. Secure and robust cloud computing for high-throughput forensic microsatellite sequence analysis and databasing. Forensic Sci. Int. Genet. 2017, 31, 40–47. [Google Scholar] [CrossRef] [PubMed]
- Amazon.com: Online Shopping for Electronics, Apparel, Computers, Books, DVDs & More. January 2020. Available online: http://amazon.com/ (accessed on 6 January 2020).
- Microsoft Azure. January 2020. Available online: http://azure.microsoft.com/en-us/overview/ (accessed on 6 January 2020).
- Shafer, J.; Rixner, S.; Cox, A.L. The hadoop distributed file system: Balancing portability and performance. In Proceedings of the IEEE International Symposium on Performance Analysis of System & Software (ISPASS), White Plains, NY, USA, 28–30 March 2010; pp. 122–133. [Google Scholar]
- Hadoop Distributed File System (HDFS). January 2020. Available online: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html (accessed on 6 January 2020).
- Chen, S.L.; Chen, Y.Y.; Kuo, S.H. CLB: A novel load balancing architecture and algorithm for cloud services. Comput. Electr. Eng. 2017, 58, 154–160. [Google Scholar] [CrossRef]
- Singh, S.; Chana, I. A survey on resource scheduling in cloud computing: Issues and challenges. J. Grid Comput. 2016, 14, 217–264. [Google Scholar] [CrossRef]
- Kumar, N.; Singh, Y. Trust and packet load balancing based secure opportunistic routing protocol for WSN. In Proceedings of the 4th International Conference on Signal Processing, Computing and Control (ISPCC), Solan, India, 21–23 September 2017; pp. 463–467. [Google Scholar]
- Toyoshima, S.; Yamaguchi, S.; Oguchi, M. Storage access optimization with virtual machine migration and basic performance analysis of Amazon EC2. In Proceedings of the 2010 IEEE 24th International Conference on Advanced Information Networking and Applications Workshops, Perth, Australia, 23–23 April 2010; pp. 905–910. [Google Scholar]
- Karthick, A.V.; Ramaraj, E.; Subramanian, R.G. An efficient multi queue job scheduling for cloud computing. In Proceedings of the 2014 IEEE World Congress on Computing and Communication Technologies, Trichirappalli, India, 27 February–1 March 2014; pp. 164–166. [Google Scholar]
- Mathew, T.; Sekaran, K.C.; Jose, J. Study and analysis of various task scheduling algorithms in the cloud computing environment. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), New Delhi, India, 24–27 September 2014; pp. 658–664. [Google Scholar]
- Salot, P. A survey of various scheduling algorithm in cloud computing environment. Int. J. Res. Eng. Technol. 2013, 2, 131–135. [Google Scholar]
- Jyoti, A.; Shrimali, M.; Mishra, R. Cloud Computing and Load Balancing in Cloud Computing-Survey. In Proceedings of the 2019 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 10–11 January 2019; pp. 51–55. [Google Scholar]
- Pal, S.; Pattnaik, P.K. A Simulation-based Approach to Optimize the Execution Time and Minimization of Average Waiting Time Using Queuing Model in Cloud Computing Environment. Int. J. Electr. Comput. Eng. 2016, 6, 2088–8708. [Google Scholar]
- Nayak, B.; Padhi, S.K.; Pattnaik, P.K. Static Task Scheduling Heuristic Approach in Cloud Computing Environment. In Information Systems Design and Intelligent Applications; Springer: Singapore, 2019; pp. 473–480. [Google Scholar]
- Kumar, M.; Sharma, S.C. Dynamic load balancing algorithm for balancing the workload among virtual machine in cloud computing. Procedia Comput. Sci. 2017, 115, 322–329. [Google Scholar] [CrossRef]
- Sharma, S.; Tantawi, A.; Spreitzer, M.; Steinder, M. Decentralized allocation of CPU computation power for web applications. Perform. Eval. 2010, 67, 1187–1202. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Definition |
|---|---|
| CMi | Cluster manager i; (1≦i≦n) |
| RQCMij | The RQ of CMi; (j = i−1) |
| qi | Remainder queue size of CMi |
| rqij | Remainder queue size of RQCMij |
| Item | Specification |
|---|---|
| CPU | Intel Core2 Duo 2.53 GHz |
| Memory | 2 GB |
| Operating System | Ubuntu 10.4 |
| Language | C |
| Analysis Tool | KyPlot |
| qi | remainder queue size of CMi |
| n | The number of CM |
| average(qi) | Average of all qi |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-L.; Chiang, M.-L.; Lin, C.-B. The High Performance of a Task Scheduling Algorithm Using Reference Queues for Cloud- Computing Data Centers. Electronics 2020, 9, 371. https://doi.org/10.3390/electronics9020371
Chen C-L, Chiang M-L, Lin C-B. The High Performance of a Task Scheduling Algorithm Using Reference Queues for Cloud- Computing Data Centers. Electronics. 2020; 9(2):371. https://doi.org/10.3390/electronics9020371
Chicago/Turabian StyleChen, Chin-Ling, Mao-Lun Chiang, and Chuan-Bi Lin. 2020. "The High Performance of a Task Scheduling Algorithm Using Reference Queues for Cloud- Computing Data Centers" Electronics 9, no. 2: 371. https://doi.org/10.3390/electronics9020371
APA StyleChen, C.-L., Chiang, M.-L., & Lin, C.-B. (2020). The High Performance of a Task Scheduling Algorithm Using Reference Queues for Cloud- Computing Data Centers. Electronics, 9(2), 371. https://doi.org/10.3390/electronics9020371