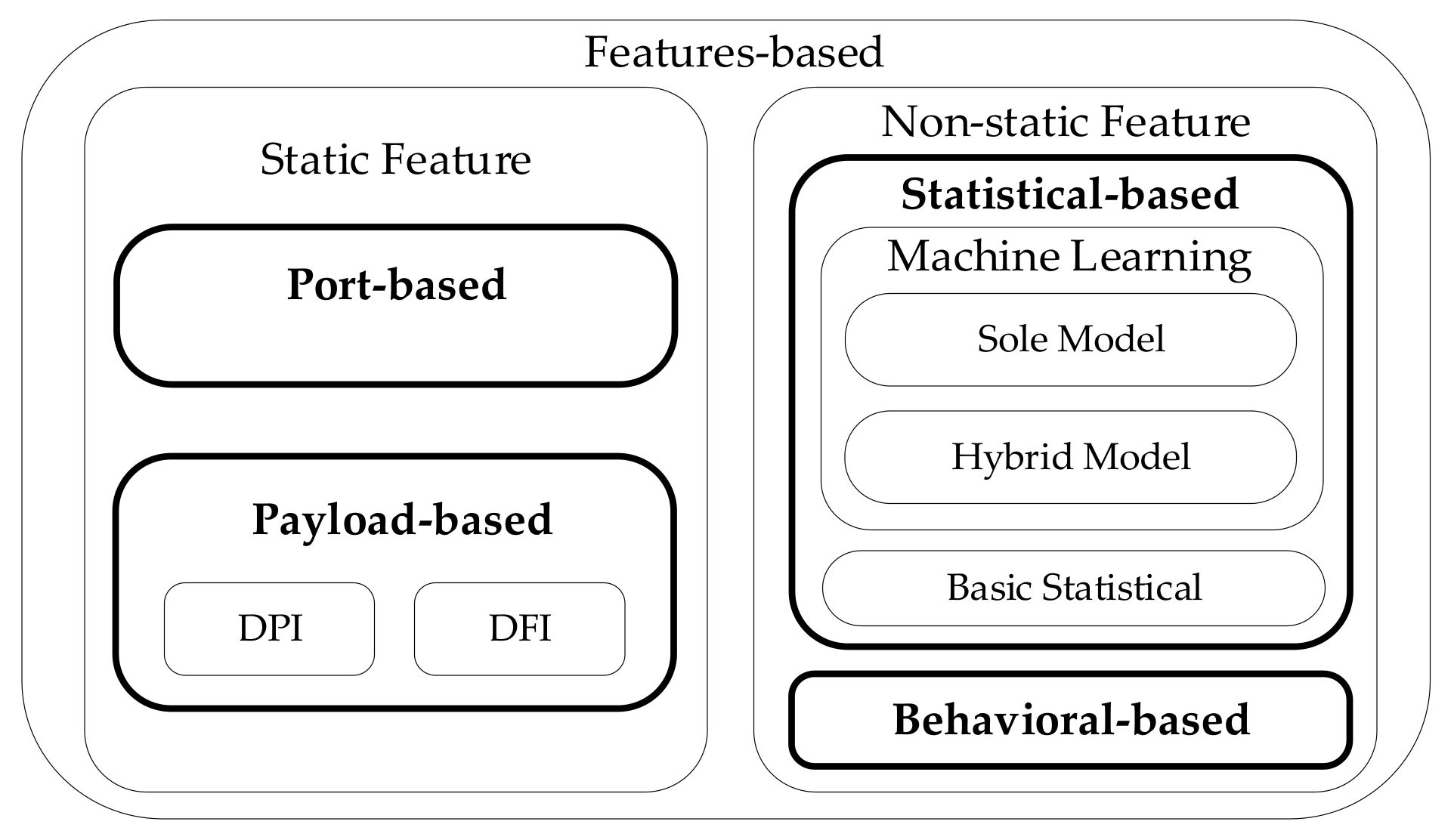
This section introduces the notion of feature weight, improves the distance calculation formula in KNN, and proposes the weighted feature KNN (WKNN). Furthermore, this section also includes our proposed feature selection and feature weight self-adaptive algorithm for WKNN (WKNN-Selfada), considering how to choose the appropriate feature set and the optimal feature weight set.
3.1. Weighted-Feature KNN
KNN is a supervised machine learning algorithm that finds a similarity between two points by calculating the distance between them. KNN first calculates the distances between each training sample and the target point, and then selects the k-nearest samples to the target point. These k samples jointly determine the class of the target point. The distance calculation of features is a direct means for expressing the similarity of points, and KNN shows excellent performance in predicting the target network flow.
Minkowski distance is one of the widely used distance metrics in traditional KNN, shown in below. If traffic features have no scale and have the same data distribution, Minkowski distance can express the actual distance between two points. In this paper, the exponent of the differences between the feature values is set to 2, which is Euclidean distance, because square sum is beneficial to describe the multi-dimension point distance. When the feature dimension of points is m, the formula for calculating the point distance between training sample and test point is given by distance . The shorter the distance between the two points, the greater is the similarity between them. After calculating the distances of all point pairs, the k-nearest training samples determine the class of the test point.
The distance calculation of traditional KNN is non-weighted, which means that it does not reflect the different effects of different features in traffic classification. This paper introduces feature weight and weighted feature-based point distance to improve the adaptation of the classification model to encrypted traffic-classification tasks. We use data normalization to eliminate the data scales for the implementation of Minkowski distance. Based on Euclidean distance, we make improvements on the traditional KNN, and several definitions are shown below.
Definition 1 (Feature weight)
. is the coefficient of the feature when calculating the distance between two points. The weights of features are represented by a column vector,, where m is the dimension of the features.
Feature weights reflect the importance of features during distance calculation. The larger the feature weight, the greater is the influence of the feature on the traffic classification.
Definition 2 (Feature distance)
. is the square of the difference between two points’ feature of the dimension. For pointsand, the feature distances are calculated and represented by, wheremeans squaring each elements of the vector. If there are several pairs of two points, the feature distances would be formed a matrix, represented by FD, andmeans the ith pair’s feature distances.
Definition 3 (Weighted feature-based point distance)
. is based on the Minkowski distance with the additional introduction of the feature weight. For points p, q and the feature weights w, the weighted feature-based point distance is given by distance.
The weighted-feature KNN (WKNN) algorithm is proposed in this paper, shown in Algorithm 1. The inputs of the algorithm are the training sample set, a matrix P, target point q, parameter k, and feature weight w. The shape of the matrix P is (n, m), where n is the number of training points and m is the feature dimension, and means the ith row of P. The outputs are the class prediction result of the target point q, the weighted feature-based point distances between the k-nearest neighbors and q, kDistances, the matrix of feature distances between each k-nearest neighbor and q, KFD, and the classes of the k-nearest neighbors, kClass. Some of the outputs are used for Algorithm 2, which will be described later.
First, in lines 1–5, the algorithm calculates the feature distances between each training point and q, and then calculates the corresponding weighted feature-based point distance, where distances[i] means the ith pair’s weighted feature-based point distance and distances is an array.
Next, in lines 6–9, the algorithm calculates the information of the k-nearest neighbors. knnIndex is the corresponding indexes of the k-nearest neighbors. kDistances is the weighted feature-based point distances of the k-nearest neighbors. KFD is the feature distances matrix of the k-nearest neighbors. kClass is the labels of the k-nearest neighbors. argminK() is a function to get the indexes of the k smallest elements from small to large, and class() is to get the label of the point.
Finally, in lines 10–14, it calculates the prediction scores. WKNN uses the reciprocal of each k distance value as a weight to be added to the score of the corresponding class and output the class with the highest score as the prediction result.
| Algorithm 1: WKNN |
 |
3.2. Feature Selection and Feature Weight Self-Adaptive Algorithm for Weighted Feature KNN (WKNN)
The selection of the feature set and the setting of the corresponding feature weights determine whether the calculated point distance can accurately represent the similarity between two points. To achieve more effective classification, a feature selection and feature weight self-adaptive algorithm for WKNN (WKNN-Selfada) is proposed, which can adapt feature weights by itself based on training data, instead of by manual setting. The algorithm learns the influence and updates the weights of features by analyzing only one sample at a time, so it can fully learn and adapt well to the law of each training sample and realize accurate classification just with a small training set.
The algorithm includes two parts, which runs two times and achieves a single part each time. The first time of the algorithm adapts the feature weight of each feature in the candidate feature set and selects the optimal feature set by comparing the weights with the feature selection threshold. In the second time of the algorithm, after feature selection in the first time, the weights of the selected features are retrained, because the new feature set is not the same with the original feature set and the weights of the original features cannot express the actual influences and mutual relation of the newly selected features. In the process of weight adjustment, the algorithm suggests that the feature with a larger feature distance would play a greater role in distinguishing the two points with different classes once misclassification. Therefore, when updating the weights, the weights of features with a large feature distance are supposed to increase while those with a small feature distance are supposed to decrease in order to increase the point distance between two points with different classes and reduce the possibility of misclassification. Thus, the accuracy of identifying the class of the test point can be improved further.
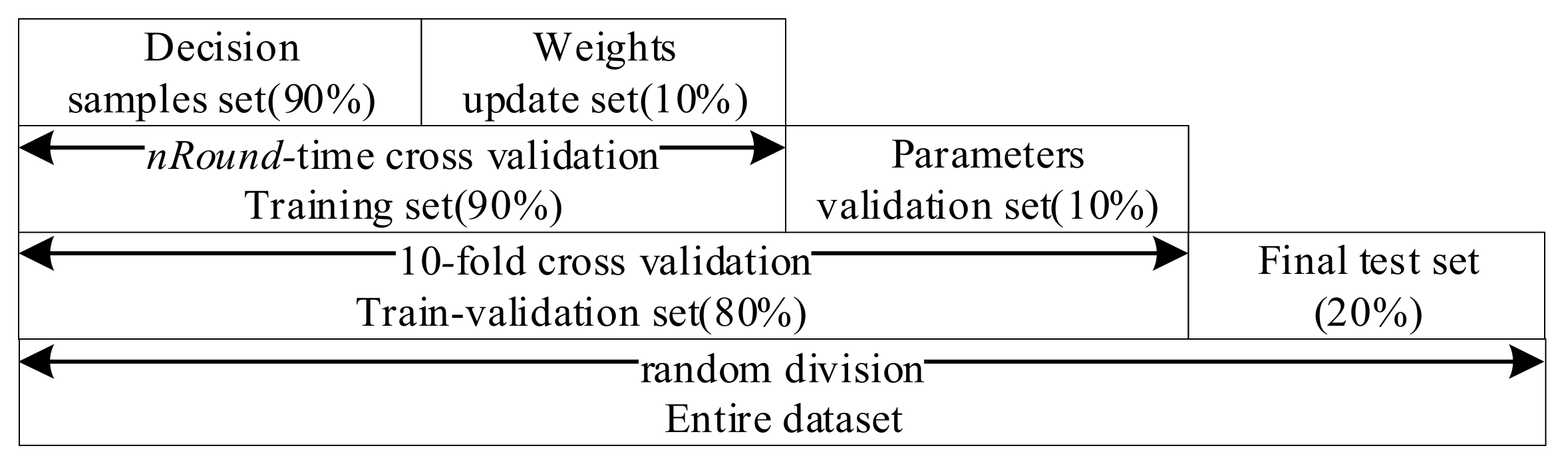
Unlike the traditional KNN algorithm, the improved algorithm presented in this paper involves a training process. Therefore, not only to compare with the target point for distance calculation, the training data needs to be divided for updating the weights. For clarity, the two training sets are called the decision samples set and the weights update set.
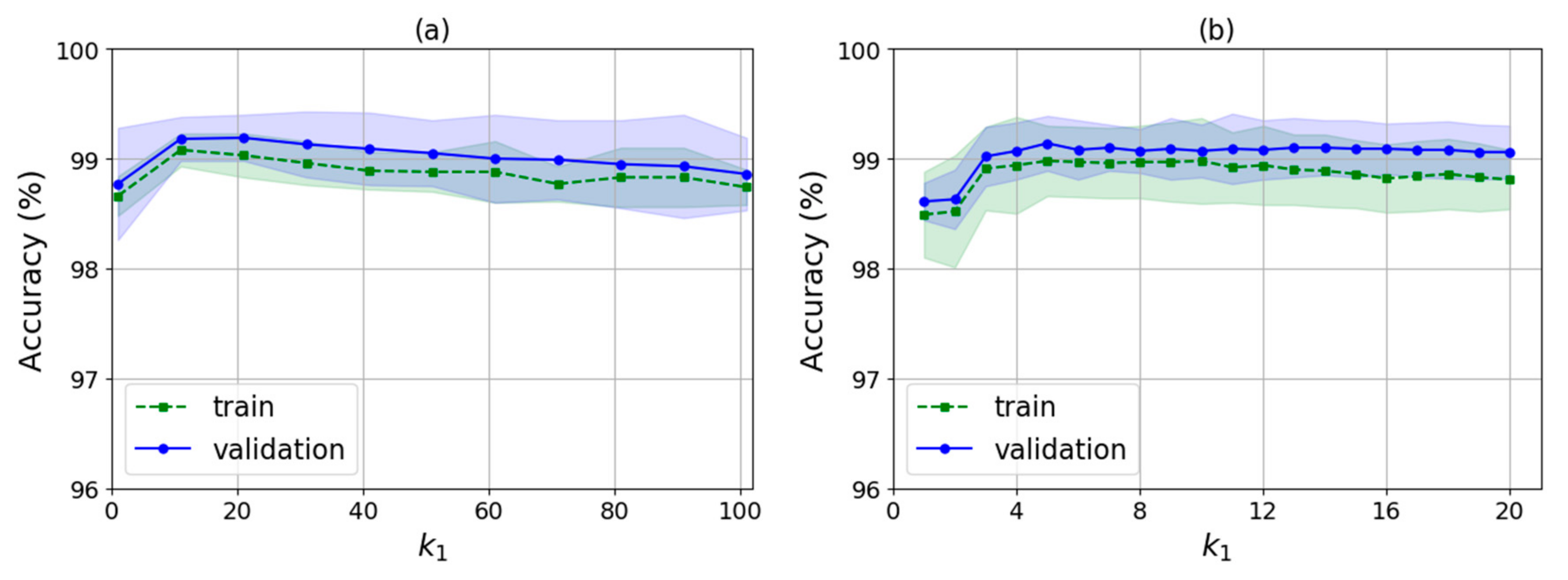
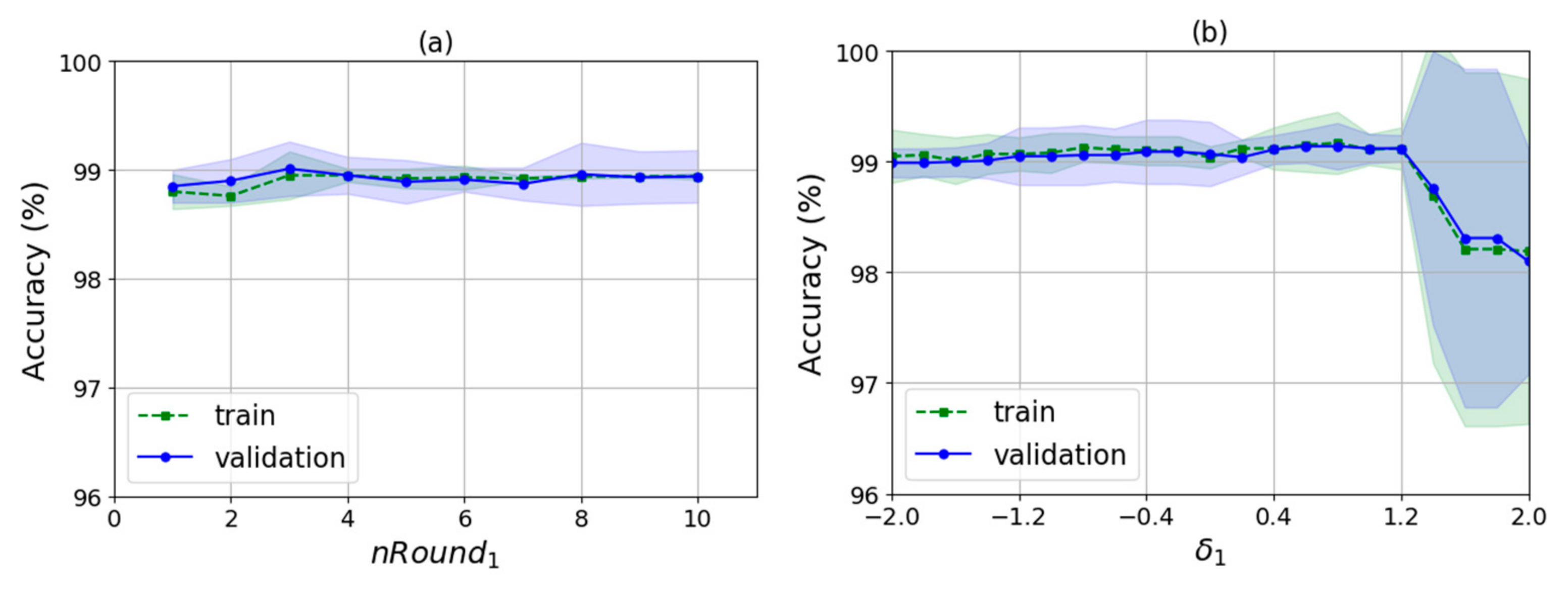
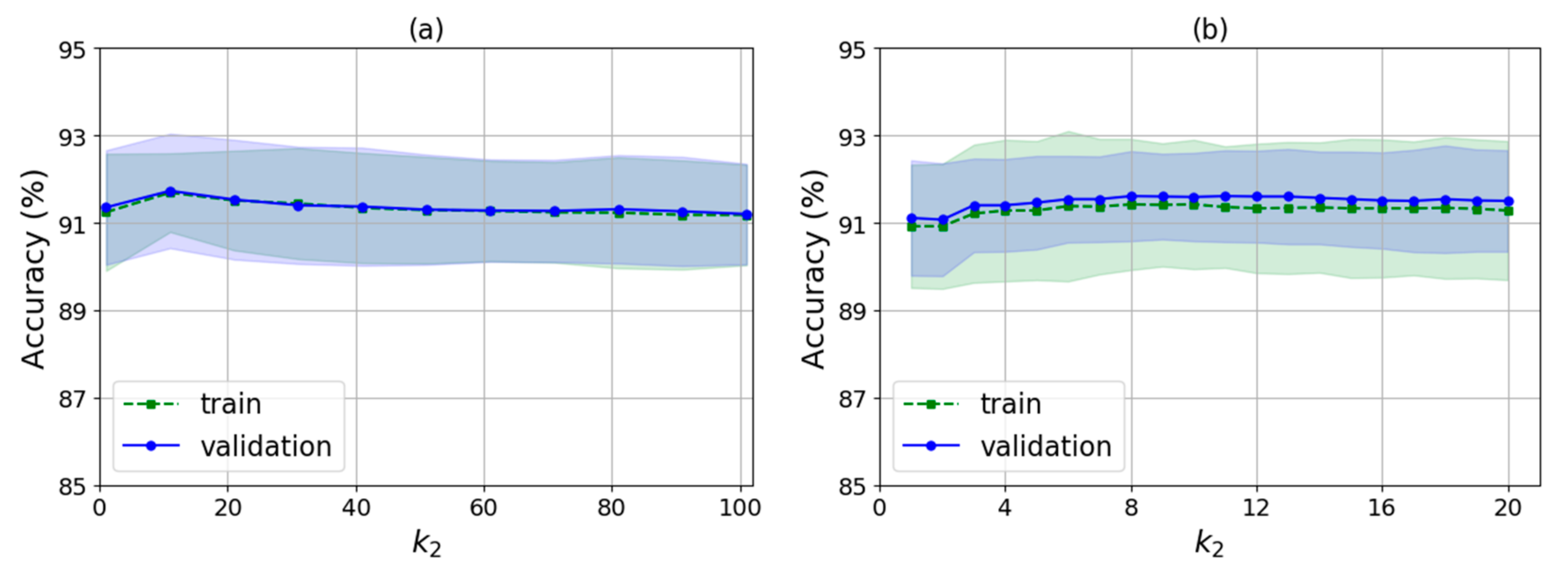
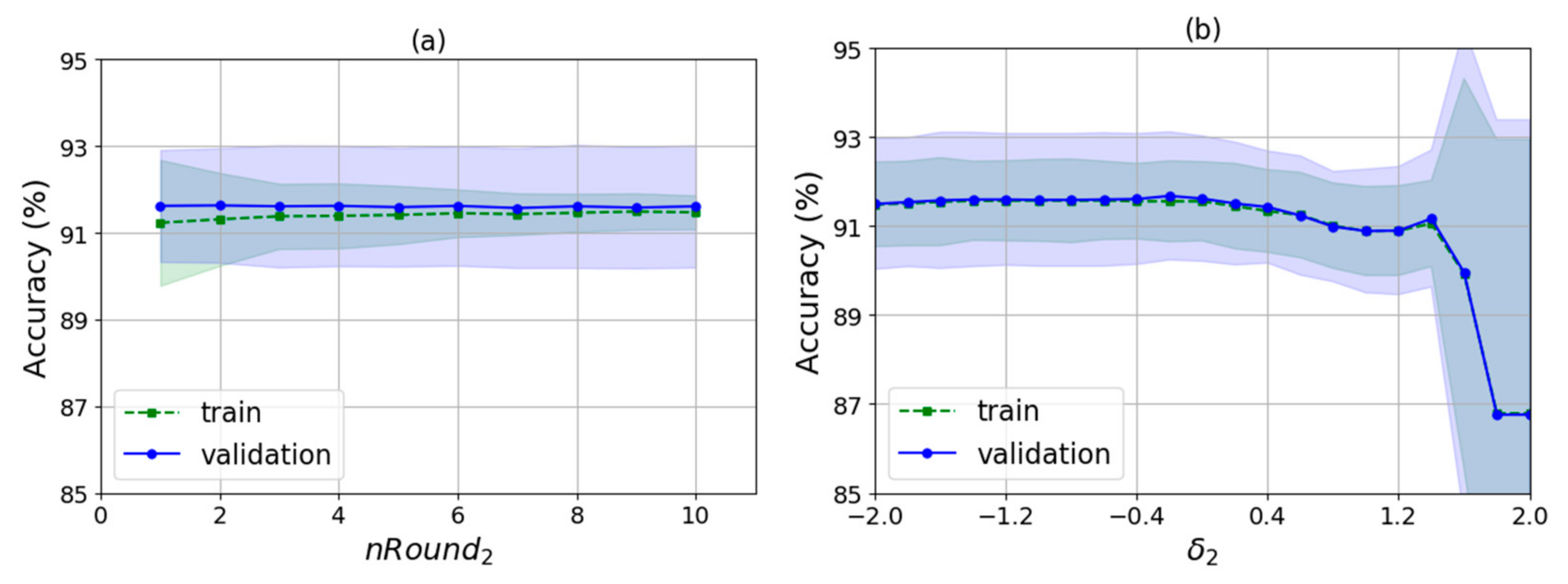
As shown in Algorithm 2, there are several input parameters: trainData is the data used for training, k is the k value of WKNN, nRound is the number of rounds for training, raDiv is the ratio for dividing the training samples into the decision samples set and the weights update set, and is an adjustment parameter used to calculate the feature selection threshold. It finally outputs the indexes of the selected features and the corresponding feature weights. The algorithm runs two times automatically by judging whether the value of is null. The first time is to select a feature set with no null and the second is to train the feature weights for the new features with null .
First, in lines 1–3, WKNN-Selfada initializes the selected feature index set, selectedFeatureIndex, as all feature indexes, i.e., {0, ..., m−1}. Then it uses the function DataProcessing() to extract the feature values of the data according to the selected feature and initializes the feature weights, w, as values of 1/m, where m is the feature dimension.
Next, in lines 4–22, it loops several times at the value of nRound. At the beginning of each round, the method starts with a data division function, dataDivide(), which proportionally divides trainData into a decision samples set P and a weights-update set Q in the ratio raDiv. One training round involves multiple instances of training, which is equal to the size of the weights-update set Q. Line 7 implements the WKNN algorithm on decision sample set P and the weights-update sample q and yields the class prediction named prediction, the weighted feature-based point distances of the k-nearest decision samples, kDistances, the matrix of feature distances between each k-nearest decision samples and q, KFD, and the classes of the k-nearest decision samples, kClass. Then, it judges whether the prediction class is true. If false, it then implements the feature weights-update, which judges in sequence whether the class of each nearest k decision sample is equal to the true class of target point q. If not, the algorithm starts to update the weights, as shown in lines 11–17. In the phase of weights update, the process in the class of the ith k-nearest decision sample is different from the target sample, which is described below.
| Algorithm 2: WKNN-Selfada |
 |
Step 1: obtain the ranks of each feature based on the feature distances . For example, if , the ranks of the features are (3,1,2), where the ith element of rank means the rank of the ith feature according to the feature distance from small to large.
Step 2: obtain the parameter , which is the update ratio of the weights. It is set to the ratio of the smallest weighted feature-based point distance in this loop, min(kDistances), to the weighted feature-based point distance between this decision sample and the target sample, kDistances[i].
Step 3: calculate the denominator of the new weights, . The denominator increment is given by , where is the update ratio and m is the dimension of the feature vector. Thus, the new denominator is .
Step 4: calculate the molecular of the new weights, . The molecular increments are given by , where i is the feature index. Thus, the new molecular are , where is the weight’s molecular of the ith feature.
Step 5: calculate the new feature weights, . The sum of all weights equal to 1 under any situation.
The misclassified decision sample at a shorter distance from the test point produces a larger update ratio , which means that it has a greater influence on the training process for feature weight update. After additional rounds of processing the feature weight self-adaptively, each feature weight converges to a certain value. In particular, if the influence of one feature is extremely low (or extremely high), the weight will converge to .
Then, in lines 23–31, the algorithm determines whether feature selecting is finished by judging whether is null. As does not have a null value in the first iteration, the processing of feature selection would be performed, i.e., lines 24–28. The algorithm selects the features by judging whether the weight of each feature is smaller than the feature selection threshold, ranging from the 1st dimension to the mth dimension in order. If so, the feature index corresponding to the weight is removed from selectedFeatureIndex. The threshold is obtained by calculating the difference between the average value of the weights, 1/m and times the standard deviation of the weights. Here, is an adjustable parameter and std() is the standard deviation function. The basic idea behind the threshold design is that the feature weights obey normal distribution, so values lower than the confidence intervals are rare and have low influences on the classification. In statistics, once the mean and standard deviation of the data are given, the can be determined based on the confidence level such as 95%, and the confidence intervals can be calculated, so values lower than the intervals can be removed. However, WKNN-Selfada does not use the notion of confidence level, but sets the and the threshold by experimental verification instead. At the end of the first iteration, the algorithm sets the to null and then begins the second iteration from line 2. In the second iteration, it calculates the new weights of the new feature according to the selectedFeatureIndex, shown in lines 4–22. After finishing the weight update, the algorithm ends up in the of null value, and outputs the feature indexes of the new feature set, selectedFeatureIndex, and the corresponding new feature weights, .


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}