Image Text Deblurring Method Based on Generative Adversarial Network


Abstract
1. Introduction
2. Related Works
3. Image Deblurring Model
3.1. Structure of GAN
3.1.1. Generator Model
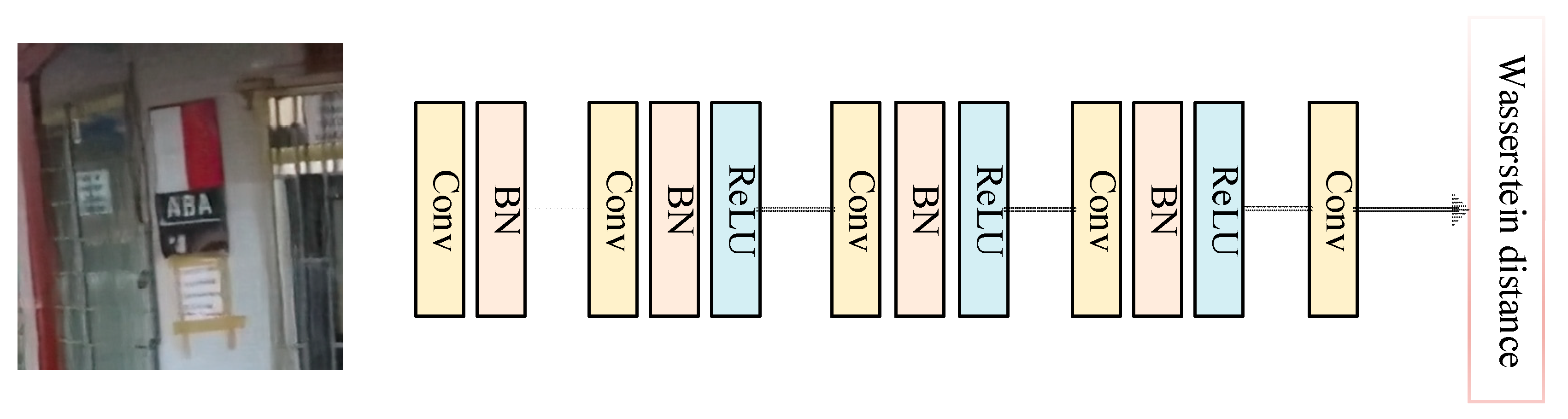
3.1.2. Discriminator Model
3.2. Loss Function of Network
3.2.1. Adversarial Loss
3.2.2. Perceptual Loss
3.3. Algorithm Implementation
| Algorithm 1: The algorithm flow of this model. |
| 1: Initialize the input shape, h = 256, w = 256, s = 3, and the output shape of PatchGAN, pa = h/2**4, and the loss weight, μ = 10, and the optimizer, Adam(0.0002, 0.5) |
| 2: Input (img_1,h,w,s), Input (img_2,h,w,s) |
| 3: Combined model trains generator to discriminator |
| 4: for epoch in range(300): |
| 5: for batch_i, img_1, img_2 in enumerate (dataloader.loadbtach(1)): |
| 6: fake_2 = generator(img_1), fake_1 = generator(img_2) |
| 7: recon_1 = generator(fake_2), recon_2 = generator(fake_1) |
| 8: vali_1 = discriminator(fake_1), vali_2 = discriminator(fake_2) |
| 9: if loss is : |
| 10: clear_image = concatenate (img_1, fake_2, recon_1, img_2, fake_1, recon_2) |
| 11: return clear_image |
4. Experiments and Results
4.1. Datasets
4.1.1. GOPRO Dataset
4.1.2. Unpaired Dataset
4.2. Experimental Results and Comparison
5. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vyas, A.; Yu, S.; Paik, J. Image Restoration. In Multiscale Transforms with Application to Image Processing; Springer: Singapore, 2018; pp. 133–198. [Google Scholar]
- Mahalakshmi, A.; Shanthini, B. A survey on image deblurring. In Proceedings of the 2016 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 7–9 January 2016. [Google Scholar]
- Dawood, A.; Muhanad, F. Image deblurring tecniques2019. J. Sci. Eng. Res. 2019, 6, 94–98. [Google Scholar]
- Leke, C.A.; Marwala, T. Deep Learning Framework Analysis. In Deep Learning and Missing Data in Engineering Systems. Studies in Big Data; Springer: Cham, Switzerland, 2019; Volume 48, pp. 147–171. [Google Scholar]
- Fergus, R.; Singn, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing Camera Shake from a Single Photograph. ACM Trans. Graphics 2006, 25, 787–794. [Google Scholar] [CrossRef]
- Xu, L.; Jia, J. Two-Phase Kernel Estimation for Robust Motion Deblurring. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010. [Google Scholar]
- Babacan, S.D.; Molina, R.; Do, M.N.; Katsaggelos, A.K. Bayesian Blind Deconvolution with General Sparse Image Priors. In Proceedings of the 12th European conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Li, X.; Zheng, S.; Jia, J. Unnatural L0 Sparse Representation for Natural Image Deblurring. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Whyte, O.; Sivic, J.; Zisserman, A.; Ponce, J. Non-uniform Deblurring for Shaken Images. Int. J. Comput. Vision 2012, 98, 168–186. [Google Scholar] [CrossRef]
- Gupta, A.; Joshi, N.; Zitnick, C.; Micheael, C.; Curless, B. Single Image Deblurring Using Motion Density Functions. 6311. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 171–184. [Google Scholar]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a Convolutional Neural Network for Non-uniform Motion Blur Removal. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chakrabarti, A. A Neural Approach to Blind Motion Deblurring. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 221–235. [Google Scholar]
- Gong, D.; Yang, J.; Liu, L.; Zhang, Y.; Reid, I.; Shen, C.; van Den Hengel, A.; Shi, Q. From Motion Blur to Motion Flow: A Deep Learning Solution for Removing Heterogeneous Motion Blur. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3806–3815. [Google Scholar]
- Hu, Q.; Wu, C.; Wu, Y.; Xiong, N. UAV Image High Fidelity Compression Algorithm Based on Generative Adversarial Networks Under Complex Disaster Conditions. IEEE Access 2019, 7, 91980–91991. [Google Scholar] [CrossRef]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Noroozi, M.; Paramanand, C.; Favaro, P. Motion Deblurring in the Wild. In Proceedings of the 39th German Conference on Pattern Recognition, GCPR 2017, Basel, Switzerland, 12–15 September 2017; pp. 65–77. [Google Scholar]
- Ramakrishnan, S.; Pachori, S.; Gangopadhyay, A.; Raman, S. Deep Generative Filter for Motion Deblurring. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2993–3000. [Google Scholar]
- Jiang, X.; Yao, H.; Zhao, S. Text image deblurring via two-tone prior. Neurocomputing 2017, 242, 1–14. [Google Scholar] [CrossRef]
- Huang, Y.; Yao, H.; Zhao, S.; Zhang, Y. Towards more efficient and flexible face image deblurring using robust salient face landmark detection. Multimedia Tools Appl. 2017, 76, 123–142. [Google Scholar] [CrossRef]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shi, J.; Li, Z.; Ying, S.; Wang, C.; Liu, Q.; Zhang, Q.; Yan, P. MR Image Super-Resolution via Wide Residual Networks With Fixed Skip Connection. IEEE J. Biomed. Health Inf. 2018, 23, 1129–1140. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Chang, O.; Tang, X.-L.; Xue, C.; Wei, C. Facial Expression Recognition Method Based on Sparse Batch Normalization CNN. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9608–9613. [Google Scholar]
- Rajeev, R.; Samath, J.A.; Karthikeyan, N.K. An Intelligent Recurrent Neural Network with Long Short-Term Memory (LSTM) BASED Batch Normalization for Medical Image Denoising. J. Med. Syst. 2019, 43, 234. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.-W.; Chung, J.-R.; Kim, J.; Lee, D.Y.; Jeong, S.Y.; Jung, S.-W. Constrained adversarial loss for generative adversarial network-based faithful image restoration. ETRI J. 2019, 41, 415–425. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Xiong, N.N.; Shen, Y.; Yang, K.; Lee, C.; Xu, C. Color sensors and their applications based on real-time color image segmentation for cyber physical systems. J. Image Video Proc. 2018, 23. [Google Scholar] [CrossRef]
- Liu, C.; Zhou, A.; Xu, C.; Zhang, G. Image segmentation framework based on multiple feature spaces. IET Image Proc. 2015, 9, 271–279. [Google Scholar] [CrossRef]
- Xi, S.; Wu, C.; Jiang, L. Super resolution reconstruction algorithm of video image based on deep self encoding learning. Multimedia Tools Appl. 2019, 78, 4545–4562. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from Simulated and Unsupervised Images through Adversarial Training. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | PSNR | SSIM | |
|---|---|---|---|
| Models | |||
| CycleGAN | 22.6 | 0.902 | |
| Ours | 25.6 | 0.929 | |
| DeblurGAN | 26.8 | 0.943 | |
| Parameters | PSNR | SSIM | |
|---|---|---|---|
| Models | |||
| Ours | 25.6 | 0.929 | |
| Ablation | 18.5 | 0.767 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Du, H.; Wu, Q.; Zhang, S. Image Text Deblurring Method Based on Generative Adversarial Network. Electronics 2020, 9, 220. https://doi.org/10.3390/electronics9020220
Wu C, Du H, Wu Q, Zhang S. Image Text Deblurring Method Based on Generative Adversarial Network. Electronics. 2020; 9(2):220. https://doi.org/10.3390/electronics9020220
Chicago/Turabian StyleWu, Chunxue, Haiyan Du, Qunhui Wu, and Sheng Zhang. 2020. "Image Text Deblurring Method Based on Generative Adversarial Network" Electronics 9, no. 2: 220. https://doi.org/10.3390/electronics9020220
APA StyleWu, C., Du, H., Wu, Q., & Zhang, S. (2020). Image Text Deblurring Method Based on Generative Adversarial Network. Electronics, 9(2), 220. https://doi.org/10.3390/electronics9020220