Infrared and Visible Image Fusion Techniques Based on Deep Learning: A Review



Abstract
1. Introduction
2. Fusion Methods of Infrared and Visible Images Based on Deep Learning
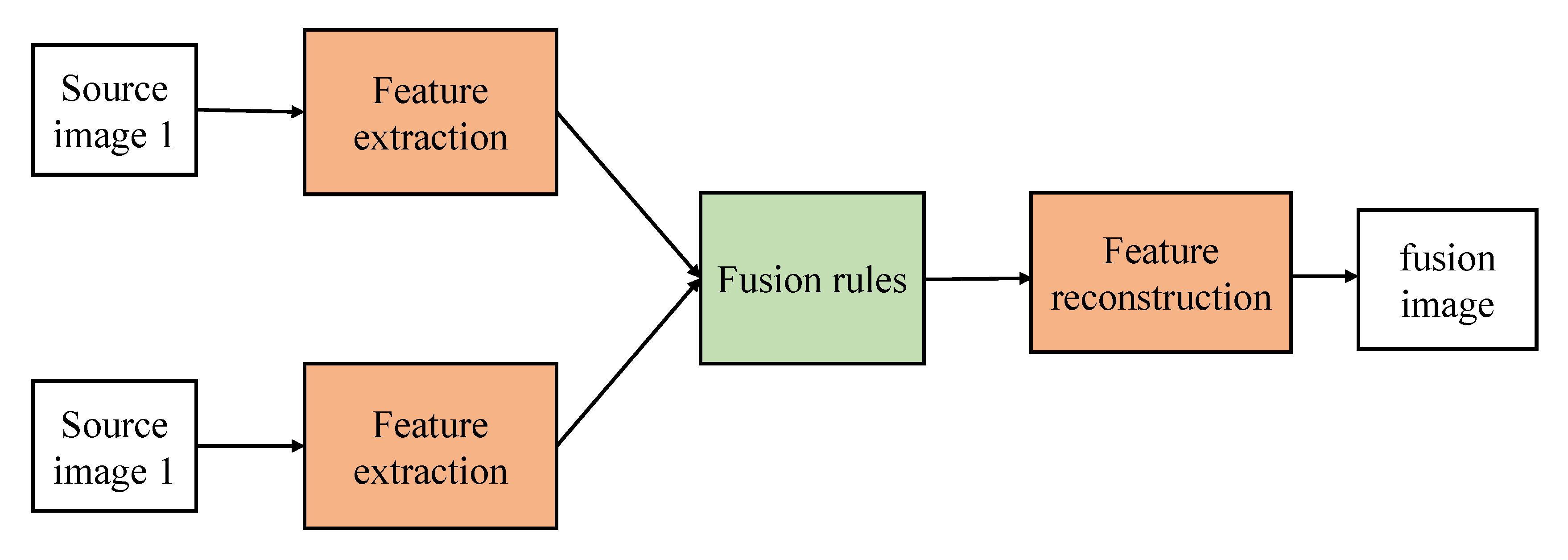
2.1. CNN-Based Fusion Methods
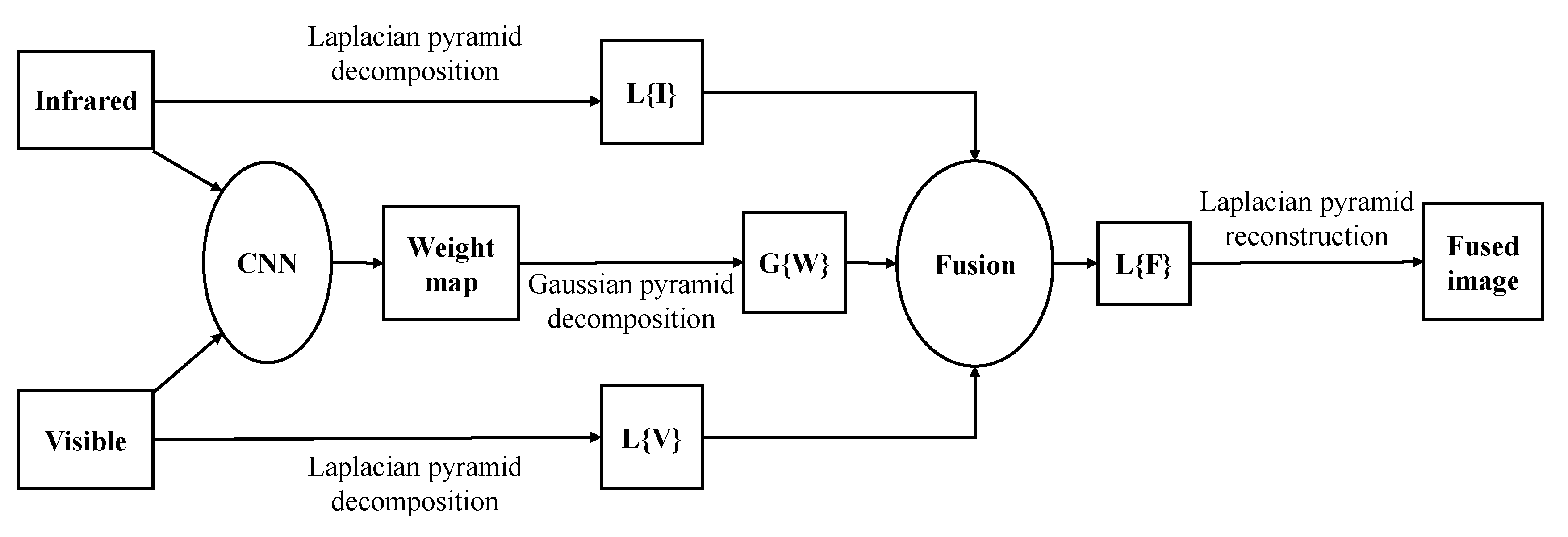
2.2. Siamese Networks-Based Fusion Methods
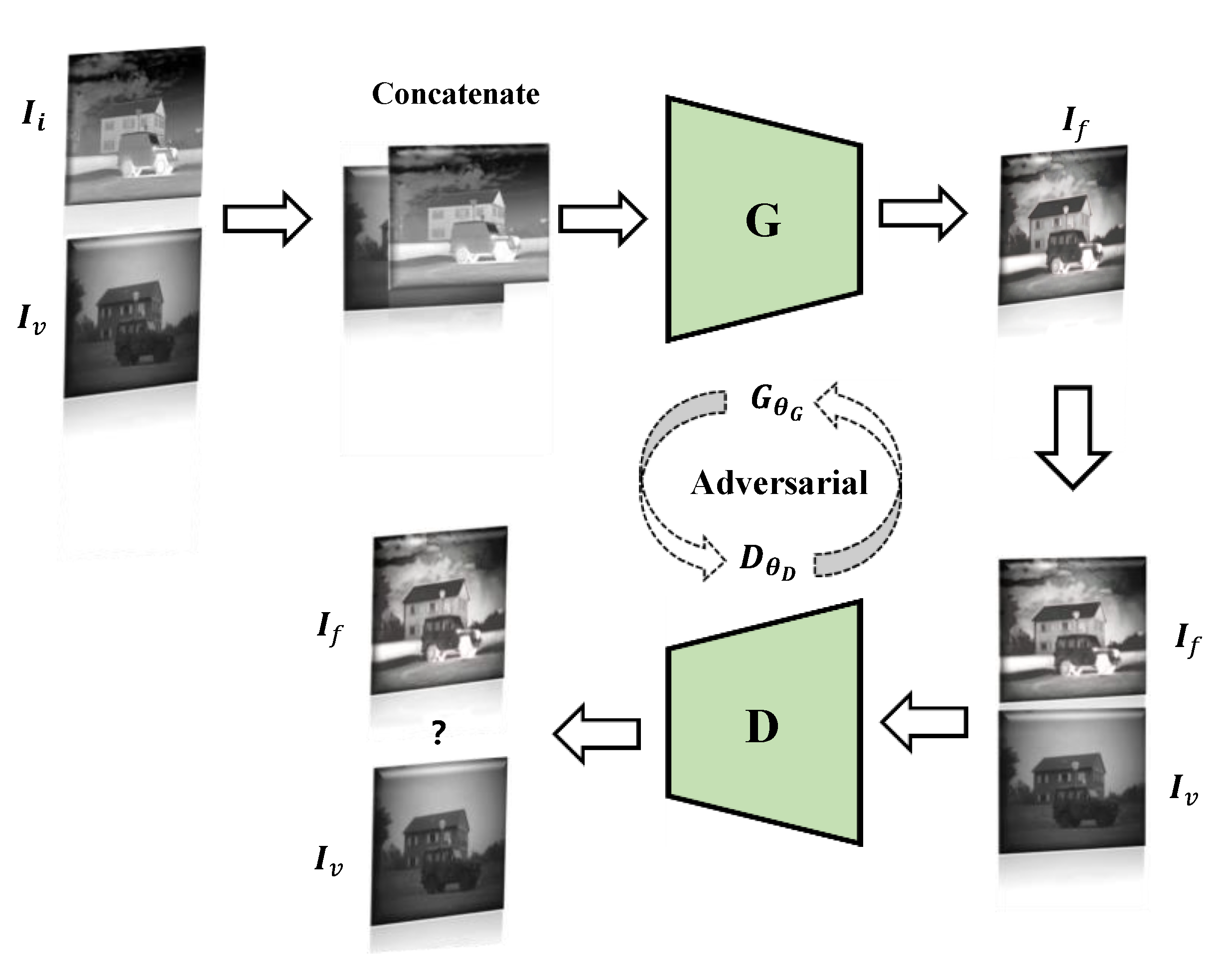
2.3. GAN-Based Fusion Methods
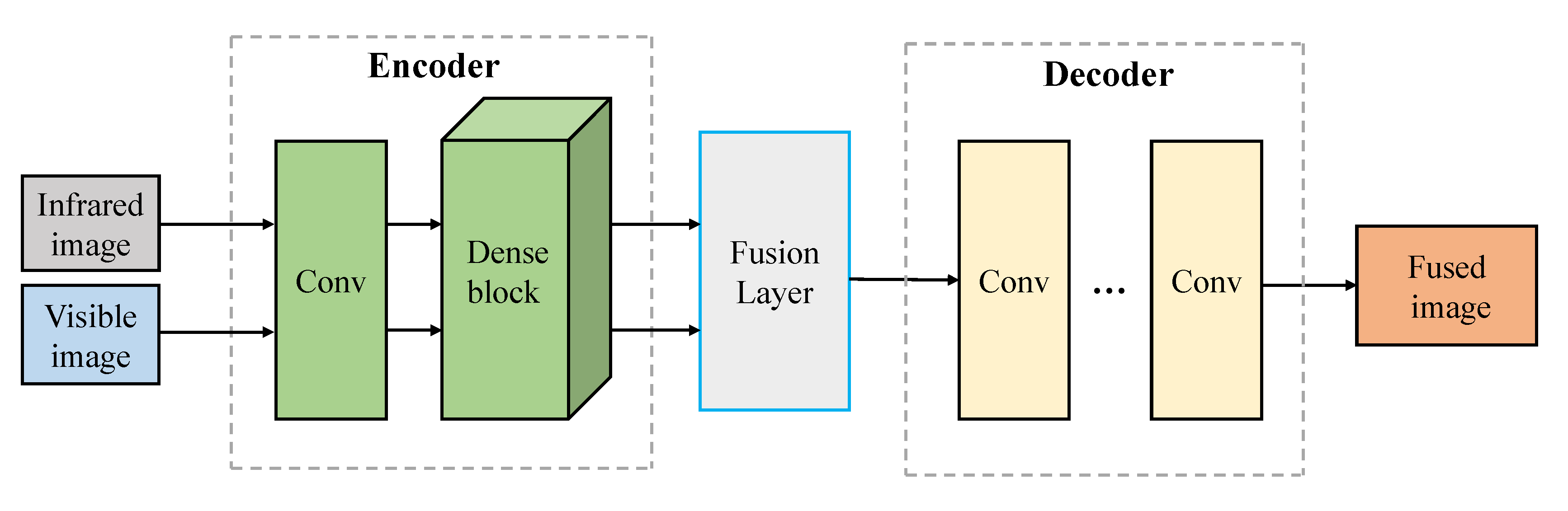
2.4. Autoencoder-Based Fusion Methods
3. Assessment of Fused Image
3.1. Subjective Evaluation Methods
3.2. Objective Evaluation Metrics
3.2.1. Entropy (EN)
3.2.2. Spatial Frequency (SF)
3.2.3. Similarity (COSIN)
3.2.4. Correlation Coefficient (CC)
3.2.5. Standard Deviation (SD)
3.2.6. Structural Similarity Index Measure (SSIM)
3.2.7. Mutual Information (MI)
3.2.8. Average Gradient (AG)
3.2.9. Mean Squared Error (MSE)
3.2.10. Gradient-Based Fusion Performance (QAB/F)
3.2.11. Peak Signal-to-Noise Ration (PSNR)
3.2.12. Visual Information Fidelity of Fusion (VIFF)
3.2.13. Other Metrics
4. Experiments
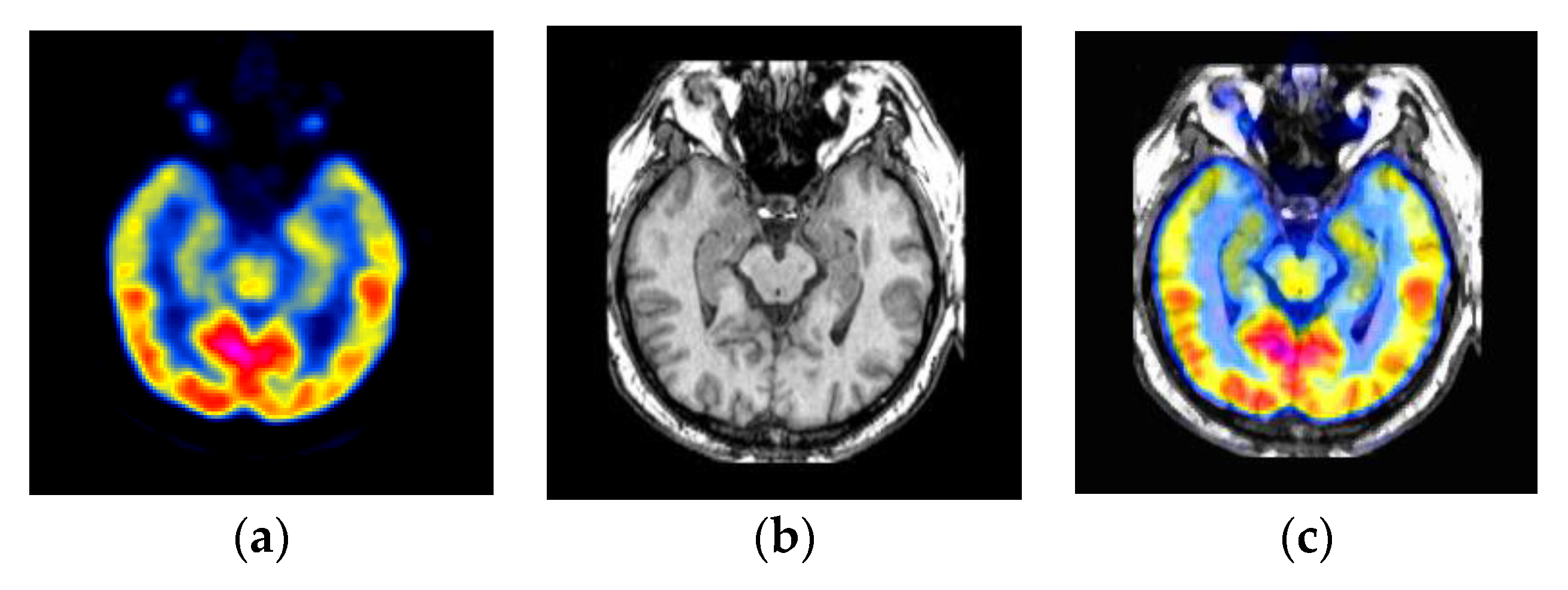
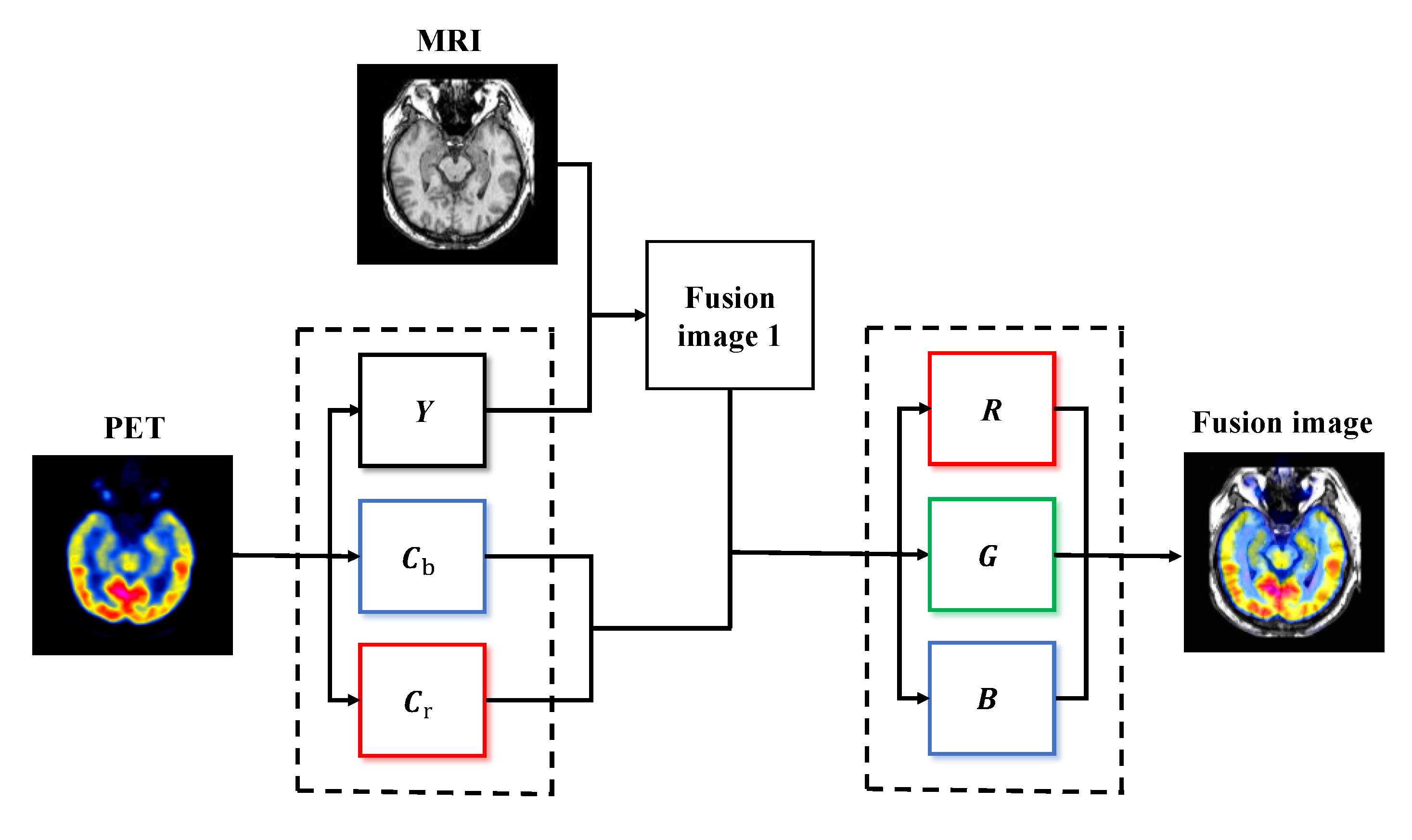
4.1. Medical Diagnosis Applications
4.2. Experiment for Typical Methods
5. Future Trends
- At present, many image fusion models based on the convolutional neural network have good performance, but most of them are not perfect. For example, in order to retain the infrared thermal radiation information of the source image and the texture feature information of the visible image, the pixel intensity of the image is reduced;
- The fusion method based on the convolution neural network should pay attention to enhancing the liquidity of the middle layer network’s features to fully retain the feature details extracted from each layer of convolution. In line with the future trend of unsupervised development, it can avoid human factors affecting image fusion performance;
- The existing fusion method generally has a large amount of calculation, and it is challenging to meet the real-time requirements. There are still many shortcomings for multi-source image registration;
- Different fusion methods have their advantages and disadvantages and should be universal for different application scenarios;
- In the future, different fields can be combined, such as image super-resolution, image denoising, and image fusion, and it is not limited to traditional fusion mechanisms;
- There is no standard fusion evaluation index in the field of image fusion. There are still some defects in the existing image fusion performance evaluation, such as image resolution, complex background environment, computational complexity. There is a lack of code libraries and benchmarks that can gauge the state-of-the-art.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Baohua, Z.; Xiaoqi, L.; Haiquan, P.; Ying, Z. A fusion algorithm for infrared and visible images based on saliency analysis and non-subsampled shearlet transform. Infrared Phys. Technol. 2015, 73, 286–297. [Google Scholar]
- Guo, W.; Xiong, N.; Chao, H.C.; Hussain, S.; Chen, G. Design and analysis of self-adapted task scheduling strategies in wireless sensor networks. Sensors 2011, 11, 6533–6554. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Y.; Sreenan, C.J.; Xiong, N.; Yang, L.T.; Park, J.H. Connectivity and coverage maintenance in wireless sensor networks. J. Supercomput. 2010, 52, 23–46. [Google Scholar] [CrossRef]
- Shu, L.; Zhang, Y.; Yu, Z.; Yang, L.T.; Hauswirth, M.; Xiong, N. Context-aware cross-layer optimized video streaming in wireless multimedia sensor networks. J. Supercomput. 2010, 54, 94–121. [Google Scholar] [CrossRef]
- Guo, W.; Xiong, N.; Vasilakos, A.V.; Chen, G.; Cheng, H. Multi-source temporal data aggregation in wireless sensor networks. Wirel. Pers. Commun. 2011, 56, 359–370. [Google Scholar] [CrossRef]
- Lin, C.; He, Y.X.; Xiong, N. An energy-efficient dynamic power management in wireless sensor networks. In Proceedings of the 2006 Fifth International Symposium on Parallel and distributed computing, Timisoara, Romania, 6–9 July 2006; pp. 148–154. [Google Scholar]
- Huang, K.; Zhang, Q.; Zhou, C.; Xiong, N.; Qin, Y. An efficient intrusion detection approach for visual sensor networks based on traffic pattern learning. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2704–2713. [Google Scholar] [CrossRef]
- Wu, W.; Xiong, N.; Wu, C. Improved clustering algorithm based on energy consumption in wireless sensor networks. IET Netw. 2017, 6, 47–53. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, D.; Xiong, N. Post-cloud computing paradigms: A survey and comparison. Tsinghua Sci. Technol. 2017, 22, 714–732. [Google Scholar] [CrossRef]
- He, R.; Xiong, N.; Yang, L.T.; Park, J.H. Using multi-modal semantic association rules to fuse keywords and visual features automatically for web image retrieval. Inf. Fusion 2011, 12, 223–230. [Google Scholar] [CrossRef]
- Jin, H.; Wang, Y. A fusion method for visible and infrared images based on contrast pyramid with teaching learning based optimization. Infrared Phys. Technol. 2014, 64, 134–142. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multiscale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Xu, L.; Cui, G.; Zheng, C.; Zhao, J. Visible infrared image fusion method based on multiscale decomposition and saliency region extraction. Laser Optoelectron. Prog. 2017, 54, 111–120. [Google Scholar]
- Han, J.; Bhanu, B. Fusion of color and infrared video for moving human detection. Pattern Recognit. 2007, 40, 1771–1784. [Google Scholar] [CrossRef]
- Singh, R.; Vatsa, M.; Noore, A. Integrated multilevel image fusion and match score fusion of visible and infrared face images for robust face recognition. Pattern Recognit. 2008, 41, 880–893. [Google Scholar] [CrossRef]
- Reinhard, E.; Adhikhmin, M.; Gooch, B.; Shirley, P. Color transfer between images. IEEE Comput 2001, 21, 34–41. [Google Scholar] [CrossRef]
- Simone, G.; Farina, A.; Morabito, F.C.; Serpico, S.B.; Bruzzone, L. Image fusion techniques for remote sensing applications. Inf. Fusion 2002, 3, 3–15. [Google Scholar] [CrossRef]
- Mendoza, F.; Lu, R.; Cen, H. Comparison and fusion of four nondestructive sensors for predicting apple fruit firmness and soluble solids content. Postharvest Biol. Technol. 2012, 73, 89–98. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Burks, T.F.; Alchanatis, V. Image fusion of visible and thermal images for fruit detection. Biosyst. Eng. 2009, 103, 12–22. [Google Scholar] [CrossRef]
- Hanna, B.V.; Gorbach, A.M.; Gage, F.A.; Pinto, P.A.; Silva, J.S.; Gilfillan, L.G.; Elster, E.A. Intraoperative assessment of critical biliary structures with visible range/infrared image fusion. J. Am. Coll. Surg. 2008, 206, 1227–1231. [Google Scholar] [CrossRef]
- Sanchez, V.; Prince, G.; Clarkson, J.P.; Rajpoot, N.M. Registration of thermal and visible light images of diseased plants using silhouette extraction in the wavelet domain. Pattern Recognit. 2015, 48, 2119–2128. [Google Scholar]
- Apatean, A.; Rogozan, A.; Bensrhair, A. Visible-infrared fusion schemes for road obstacle classification. Transp. Res. Part 2013, 35, 180–192. [Google Scholar] [CrossRef]
- Eisler, K.; Homma, C.; Goldammer, M.; Rothenfusser, M.; Arnold, W. Fusion of visual and infrared thermography images for advanced assessment in non-destructive testing. Rev. Sci. Instrum. 2013, 84, 064902. [Google Scholar] [CrossRef]
- Wang, J.; Peng, J.; Feng, X.; He, G.; Fan, J. Fusion method for infrared and visible images by using non-negative sparse representation. Infrared Phys. Technol. 2014, 67, 477–489. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [PubMed]
- Yang, B.; Li, S. Visual attention guided image fusion with sparse representation. Opt. Int. J. Light Electron. Opt. 2014, 125, 4881–4888. [Google Scholar] [CrossRef]
- Kong, W.; Zhang, L.; Lei, Y. Novel fusion method for visible light and infrared images based on NSST–SF–PCNN. Infrared Phys. Technol. 2014, 65, 103–112. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Liu, G. Multi-sensor image fusion based on fourth order partial differential equations. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–9. [Google Scholar]
- Bavirisetti, D.P.; Dhuli, R. Two-scale image fusion of visible and infrared images using saliency detection. Infrared Phys. Technol. 2016, 76, 52–64. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multiscale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Shi, W.; Zhu, C.; Tian, Y.; Nichol, J. Wavelet-based image fusion and quality assessment. Int. J. Appl. Earth Obs. Geoinf. 2005, 6, 241–251. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the International Conference on Pattern Recognition 2018 IEEE, Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Prabhakar, K.R.; Srikar, V.S.; Babu, R.V. DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs. ICCV 2017, 1, 3. [Google Scholar]
- Ma, Y.; Chen, J.; Chen, C.; Fan, F.; Ma, J. Infrared and visible image fusion using total variation model. Neurocomputing 2016, 202, 12–19. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Durrani, T.S. Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 2019, 102, 103039. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. FusionDN: A Unified Densely Connected Network for Image Fusion. AAAI 2020, 34, 12484–12491. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef]
- Chen, Y.; Xie, H.; Shin, H. Multi-layer fusion techniques using a CNN for multispectral pedestrian detection. IET Comput. Vis. 2018, 12, 1179–1187. [Google Scholar] [CrossRef]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y.; Yu, C. VIF-Net: An unsupervised framework for infrared and visible image fusion. IEEE Trans. Comput. Imaging 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. International Journal of Wavelets. Multiresolut. Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Qiao, D.; Zhao, J.; Peng, S.; Xiao, G. Object fusion tracking based on visible and infrared images using fully convolutional siamese networks. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Zhang, X.; Ye, P.; Peng, S.; Liu, J.; Gong, K.; Xiao, G. SiamFT: An RGB-infrared fusion tracking method via fully convolutional siamese networks. IEEE Access 2019, 7, 122122–122133. [Google Scholar] [CrossRef]
- Piao, J.; Chen, Y.; Shin, H. A new deep learning based multispectral image fusion method. Entropy 2019, 21, 570. [Google Scholar] [CrossRef]
- Yuan, C.; Sun, C.Q.; Tang, X.Y.; Liu, R.F. FLGC-Fusion GAN: An Enhanced Fusion GAN Model by Importing Fully Learnable Group Convolution. Math. Probl. Eng. 2020. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Liang, P.; Yu, W.; Chen, C.; Guo, X.; Wu, J.; Jiang, J. Infrared and visible image fusion via detail preserving adversarial learning. Inf. Fusion 2020, 54, 85–98. [Google Scholar] [CrossRef]
- Xu, J.; Shi, X.; Qin, S.; Lu, K.; Wang, H.; Ma, J. LBP-BEGAN: A generative adversarial network architecture for infrared and visible image fusion. Infrared Phys. Technol. 2020, 104, 103144. [Google Scholar] [CrossRef]
- Li, Q.; Lu, L.; Li, Z.; Wu, W.; Liu, Z.; Jeon, G.; Yang, X. Coupled GAN with relativistic discriminators for infrared and visible images fusion. IEEE Sens. J. 2019, 1. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef]
- Sun, Y.; Zuo, W.; Liu, M. Rtfnet: Rgb-thermal fusion network for semantic segmentation of urban scenes. IEEE Robot. Autom. Lett. 2019, 4, 2576–2583. [Google Scholar] [CrossRef]
- Yan, H.; Yu, X.; Zhang, Y.; Zhang, S.; Zhao, X.; Zhang, L. Single image depth estimation with normal guided scale invariant deep convolutional fields. IEEE Trans 2017, 29, 80–92. [Google Scholar] [CrossRef]
- Li, L.; Zhang, S.; Yu, X.; Zhang, L. PMSC: PatchMatch-based superpixel cut for accurate stereo matching. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 679–692. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kessy, A.; Lewin, A.; Strimmer, K. Optimal whitening and decorrelation. Am. Stat. 2018, 72, 309–314. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; Volume 1, pp. 4700–4708. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chan, A.L.; Schnelle, S.R. Fusing concurrent visible and infrared videos for improved tracking performance. Opt. Eng. 2013, 52, 017004. [Google Scholar] [CrossRef]
- Chen, Y.; Blum, R.S. A new automated quality assessment algorithm for image fusion. Image Vis. Comput. 2009, 27, 1421–1432. [Google Scholar] [CrossRef]
- Jin, X.; Jiang, Q.; Yao, S.; Zhou, D.; Nie, R.; Hai, J.; He, K. A survey of infrared and visual image fusion methods. Infrared Phys. Technol. 2017, 85, 478–501. [Google Scholar] [CrossRef]
- Cvejic, N.; Canagarajah, C.N.; Bull, D.R. Image fusion metric based on mutual information and Tsallis entropy. Electron. Lett. 2006, 42, 626–627. [Google Scholar] [CrossRef]
- Chen, Y.; Shin, H. Multispectral image fusion based pedestrian detection using a multilayer fused deconvolutional single-shot detector. JOSA A 2020, 37, 768–779. [Google Scholar] [CrossRef] [PubMed]
- Patil, U.; Mudengudi, U. Image fusion using hierarchical PCA. In Proceedings of the 2011 International Conference on Image Information Processing, Shimla, India, 3–15 November 2011; pp. 1–6. [Google Scholar]
- Yan, X.; Qin, H.; Li, J.; Zhou, H.; Zong, J.G. Infrared and visible image fusion with spectral graph wavelet transform. JOSA A 2015, 32, 1643–1652. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhou, D.; Zhang, X.; Nie, R.; Wang, Q.; Jin, X. Infrared and visible image fusion based on target extraction in the nonsubsampled contourlet transform domain. J. Appl. Remote Sens. 2017, 11, 015011. [Google Scholar] [CrossRef]
- Zhao, J.; Cui, G.; Gong, X.; Zang, Y.; Tao, S.; Wang, D. Fusion of visible and infrared images using global entropy and gradient constrained regularization. Infrared Phys. Technol. 2017, 81, 201–209. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, Y.; Fan, F.; Zhang, Y.; Huang, J. Infrared and visible image fusion via saliency analysis and local edge-preserving multiscale decomposition. JOSA A 2017, 34, 1400–1410. [Google Scholar] [CrossRef]
- Li, H.; Liu, L.; Huang, W.; Yue, C. An improved fusion algorithm for infrared and visible images based on multiscale transform. Infrared Phys. Technol. 2016, 74, 28–37. [Google Scholar] [CrossRef]
- Kong, W.; Wang, B.; Lei, Y. Technique for infrared and visible image fusion based on non-subsampled shearlet transform and spiking cortical model. Infrared Phys. Technol. 2015, 71, 87–98. [Google Scholar] [CrossRef]
- Conneau, A.; Lample, G.; Ranzato, M.; Denoyer, L.; Jégou, H. Word translation without parallel data. arXiv 2017, arXiv:1710.04087. [Google Scholar]
- Pajares, G.; De La Cruz, J.M. A wavelet-based image fusion tutorial. Pattern Recognit. 2004, 37, 1855–1872. [Google Scholar] [CrossRef]
- Kumar, B.S. Image fusion based on pixel significance using cross bilateral filter. Signal Image Video Process. 2015, 9, 1193–1204. [Google Scholar] [CrossRef]
- Xiang, T.; Yan, L.; Gao, R. A fusion algorithm for infrared and visible images based on adaptive dual-channel unit-linking PCNN in NSCT domain. Infrared Phys. Technol. 2015, 69, 53–61. [Google Scholar] [CrossRef]
- Zhan, L.; Zhuang, Y.; Huang, L. Infrared and visible images fusion method based on discrete wavelet transform. J. Comput 2017, 28, 57–71. [Google Scholar] [CrossRef]
- James, A.P.; Dasarathy, B.V. Medical image fusion: A survey of the state of the art. Inf. Fusion 2014, 19, 4–19. [Google Scholar] [CrossRef]
- Zhao, C.; Guo, Y.; Wang, Y. A fast fusion scheme for infrared and visible light images in NSCT domain. Infrared Phys. Technol. 2015, 72, 266–275. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, B.; Zhao, Y.; Liu, H.; Pei, H. The infrared and visible image fusion algorithm based on target separation and sparse representation. Infrared Phys. Technol. 2014, 67, 397–407. [Google Scholar] [CrossRef]
- Piella, G. A general framework for multiresolution image fusion: From pixels to regions. Inf. Fusion 2003, 4, 259–280. [Google Scholar] [CrossRef]
- Ren, K.; Xu, F. Super-resolution images fusion via compressed sensing and low-rank matrix decomposition. Infrared Phys. Technol. 2015, 68, 61–68. [Google Scholar] [CrossRef]
- Han, L.; Shi, L.; Yang, Y.; Song, D. Thermal physical property-based fusion of geostationary meteorological satellite visible and infrared channel images. Sensors 2014, 14, 10187–10202. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Jin, H.; Jiao, L.; Liu, F.; Qi, Y. Fusion of infrared and visual images based on contrast pyramid directional filter banks using clonal selection optimizing. Opt. Eng. 2008, 47, 027002. [Google Scholar] [CrossRef]
- Zhu, P.; Huang, Z.; Lei, H. Fusion of infrared and visible images based on BEMD and NSDFB. Infrared Phys. Technol. 2016, 77, 82–93. [Google Scholar] [CrossRef]
- Pal, A.R.; Singha, A. A comparative analysis of visual and thermal face image fusion based on different wavelet family. In Proceedings of the 2017 International Conference on Innovations in Electronics, Signal Processing and Communication (IESC), Shillong, India, 6–7 April 2017; pp. 213–218. [Google Scholar]
- Krishnamoorthy, S.; Soman, K.P. Implementation and comparative study of image fusion algorithms. Int. J. Comput. Appl. 2010, 9, 25–35. [Google Scholar] [CrossRef]
- Madheswari, K.; Venkateswaran, N. Swarm intelligence based optimisation in thermal image fusion using dual tree discrete wavelet transform. Quant. Infrared Thermogr. J. 2017, 14, 24–43. [Google Scholar] [CrossRef]
- Liu, Z.; Yin, H.; Fang, B.; Chai, Y. A novel fusion scheme for visible and infrared images based on compressive sensing. Opt. Commun. 2015, 335, 168–177. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, M. Image fusion using multiscale edge-preserving decomposition based on weighted least squares filter. IET Image Process. 2014, 8, 183–190. [Google Scholar] [CrossRef]
- Zhang, X.; Li, X.; Feng, Y.; Zhao, H.; Liu, Z. Image fusion with internal generative mechanism. Expert Syst. Appl. 2015, 42, 2382–2391. [Google Scholar] [CrossRef]
- Yang, B.; Li, S. Pixel-level image fusion with simultaneous orthogonal matching pursuit. Inf. Fusion 2012, 13, 10–19. [Google Scholar] [CrossRef]
- Feng, Z.J.; Zhang, X.L.; Yuan, L.Y.; Wang, J.N. Infrared target detection and location for visual surveillance using fusion scheme of visible and infrared images. Math. Probl. Eng. 2013, 2013, 831–842. [Google Scholar] [CrossRef]
- Fu, Z.; Wang, X.; Xu, J.; Zhou, N.; Zhao, Y. Infrared and visible images fusion based on RPCA and NSCT. Infrared Phys. Technol. 2016, 77, 114–123. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Li, H.; Ding, W.; Cao, X.; Liu, C. Image registration and fusion of visible and infrared integrated camera for medium-altitude unmanned aerial vehicle remote sensing. Remote Sens. 2017, 9, 441. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H. A medical image fusion method based on convolutional neural networks. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–7. [Google Scholar]
- Kogan, F.; Fan, A.P.; Gold, G.E. Potential of PET-MRI for imaging of non-oncologic musculoskeletal disease. Quant. Imaging Med. Surg. 2016, 6, 756. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Gao, S.; Cheng, Y.; Zhao, Y. Method of visual and infrared fusion for moving object detection. Opt. Lett 2013, 38, 1981–1983. [Google Scholar] [CrossRef]
- Smith, D.; Singh, S. Approaches to multisensor data fusion in target tracking: A survey. IEEE Trans. Knowl. Data Eng. 2006, 18, 1696–1710. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Chen, H.; Varshney, P.K. A human perception inspired quality metric for image fusion based on regional information. Inf. Fusion 2007, 8, 193–207. [Google Scholar] [CrossRef]
- Roberts, J.W.; van Aardt, J.A.; Ahmed, F.B. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Davis, J.W.; Sharma, V. Background-subtraction using contour-based fusion of thermal and visible imagery. Comput. Vis. Image Underst. 2007, 106, 162–182. [Google Scholar] [CrossRef]
- Toet, A. TNO Image Fusion Dataset; Figshare Data: London, UK, 2014. [Google Scholar]
- Ellmauthaler, A.; Pagliari, C.L.; da Silva, E.A.; Gois, J.N.; Neves, S.R. A visible-light and infrared video database for performance evaluation of video/image fusion methods. Multidimens. Syst. Signal Process. 2019, 30, 119–143. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Xiao, G. VIFB: A Visible and Infrared Image Fusion Benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 104–105. [Google Scholar]
- Brown, M.; Süsstrunk, S. Multi-spectral SIFT for scene category recognition. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 177–184. [Google Scholar]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Lewis, J.J.; O’Callaghan, R.J.; Nikolov, S.G.; Bull, D.R.; Canagarajah, N. Pixel-and region-based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Families of Fusion Methods | Ref. | Innovation |
|---|---|---|
| CNN method of DL | [35] | VGG-19; L1 norm; weighted average strategy; maximum selection strategy |
| [36] | Dense net | |
| [37] | Minimize the total change | |
| [38] | ZCA-zero-phase component analysis; L1-norm; weighted average strategy | |
| [39] | Elastic weight consolidation | |
| [40] | Perceptual loss; use two convolutional layers to extract image features; weight sharing strategy | |
| [41] | Adaptive information preservation strategy | |
| [42] | MLF-CNN; weighting summation strategy | |
| [43] | Mixed loss function (M-SSIM loss; TV loss); adaptive VIF-Net | |
| Siamese network of DL | [44] | Fusion strategy of local similarity; weighted average |
| [45] | Pixel-level image fusion; feature tracking | |
| [46] | Dual Siamese network; weight sharing strategy | |
| [47] | Saliency map; three-level wavelet transform | |
| GAN of DL | [33] | The confrontation between generator and discriminator |
| [48] | Learnable group convolution | |
| [49] | Adversarial generation network with dual discriminators | |
| [50] | Detail loss; target edge loss | |
| [51] | Local binary pattern | |
| [52] | Pre-fused image as the label | |
| Autoencoder of DL | [49] | Automatic coding feature extraction strategy of generator |
| [53] | Combination of autoencoder and dense network | |
| [54] | RGB encoder; infrared encoder; decoder used to restore the resolution of the feature map |
| Ref. | Limitation |
|---|---|
| [57] | It is only suitable for multi-focus image fusion, and only the last layer is used to calculate the result. Much useful information obtained by the middle layer will be lost. When the network depth increases, the information loss will become more serious. |
| [36] | Feature extraction will still lose some information. |
| [37] | In different application fields, the accuracy of the fusion result cannot be guaranteed due to the large difference in resolution and spectrum. |
| [40] | The specific performance of different source images needs to be considered in a specific dataset. |
| [42] | A large number of samples with a complex background bring a large amount of calculation to model training. |
| Ref. | Limitation |
|---|---|
| [45] | The starting point of the article is target tracking. As far as the fusion effect is concerned, the fusion result is slightly blurred. |
| [44] | It cannot be effectively combined with conventional fusion technology and is not suitable for complex data sets. |
| [46] | The thermal infrared network training uses visible images, and you can consider using thermal infrared images for better results. |
| [47] | The CPU is used to train the model, so the computational efficiency of the model is not very prominent. It takes an average of 19 s to process a pair of source images. |
| Ref. | Limitation |
|---|---|
| [33] | Reduce the prominence of infrared thermal targets. |
| [50] | The pixel intensity of some fusion image areas is changed, and the overall brightness is reduced. |
| [48] | Some edges of the fused image are a bit blurry. |
| [51] | Unique fusion results have bright artifacts. |
| [52] | In the early stage of model training, it takes some time to label the pre-fused images. |
| Evaluation Metrics | References | +/− |
|---|---|---|
| Entropy (EN) | [68,69,70,71,72] | + |
| Spatial frequency (SF) | [73,74,75,76,77,78,79] | + |
| Similarity (COSIN) | [77] | + |
| Correlation coefficient (CC) | [59,80,81,82] | + |
| Standard deviation (SD) | [31,83,84,85] | + |
| Structural similarity index measure (SSIM) | [86,87,88] | + |
| Mutual information (MI) | [89,90,91,92] | + |
| Average gradient (AG) | [73,93,94,95] | + |
| Mean squared error (MSE) | [96,97,98] | − |
| Gradient-based fusion performance (QAB/F) | [99,100,101,102,103] | + |
| Peak signal-to-noise ratio (PSNR) | [2,104,105,106,107] | + |
| Visual information fidelity of fusion (VIFF) | [108] | + |
| Chen–Blum metric (QCB) | [66] | + |
| Chen–Varshney metric (QCV) | [109] | − |
| Name | Image/Video Pairs | Image Type | Resolution | Year |
|---|---|---|---|---|
| TNO | 63 image pairs | Multispectral | Various | 2014 |
| VLRVDIF | 24 video pairs | RGB, infrared | 720 × 480 | 2019 |
| OSU color-thermal database | 6 video pairs | RGB, infrared | 320 × 240 | 2005 |
| VIFB | 21 image pairs | RGB, infrared | Various | 2020 |
| INO-video analytics dataset | 223 image pairs | RGB, infrared | Various | 2012 |
| RGB-NIR scene dataset | 477 image pairs | RGB, near-infrared (NIR) | 1024 × 768 | 2011 |
| Methods | SF | EN | CC | COSIN | SD | SSIM | QAB/F |
|---|---|---|---|---|---|---|---|
| Deep Fuse | 6.9603 | 6.7448 | 0.4182 | 0.9706 | 44.0915 | 0.4259 | 0.4396 |
| CVT | 6.9696 | 6.2151 | 0.4023 | 0.9118 | 28.7006 | 0.394 | 0.5065 |
| DTCWT | 6.9266 | 6.6617 | 0.3892 | 0.9549 | 32.6006 | 0.4652 | 0.5359 |
| GFF | 7.0902 | 7.1238 | 0.3711 | 0.8683 | 43.2243 | 0.3763 | 0.6168 |
| GTF | 7.2161 | 7.1464 | 0.3622 | 0.9739 | 44.3197 | 0.3858 | 0.4154 |
| Fusion GAN | 7.4707 | 7.377 | 0.4473 | 0.9715 | 48.5708 | 0.4132 | 0.6237 |
| FLGC-fusion GAN | 8.0068 | 7.5199 | 0.4861 | 0.9801 | 50.6215 | 0.4541 | 0.6941 |
| DDcGAN | 7.9142 | 7.4589 | 0.5558 | 0.9847 | 50.6318 | 0.5093 | 0.6434 |
| Method | TNO |
|---|---|
| CVT | 1.46 |
| DTCWT | 3.32 × 10−1 |
| GFF | 3.18 × 10−1 |
| Deep Fuse | 4.27 × 10−2 |
| GTF | 4.82 |
| Fusion GAN | 4.61 × 10−2 |
| FLGC-fusion GAN | 3.07 × 10−2 |
| DDcGAN | 5.19 × 10−2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Zhang, C.; Xiong, N. Infrared and Visible Image Fusion Techniques Based on Deep Learning: A Review. Electronics 2020, 9, 2162. https://doi.org/10.3390/electronics9122162
Sun C, Zhang C, Xiong N. Infrared and Visible Image Fusion Techniques Based on Deep Learning: A Review. Electronics. 2020; 9(12):2162. https://doi.org/10.3390/electronics9122162
Chicago/Turabian StyleSun, Changqi, Cong Zhang, and Naixue Xiong. 2020. "Infrared and Visible Image Fusion Techniques Based on Deep Learning: A Review" Electronics 9, no. 12: 2162. https://doi.org/10.3390/electronics9122162
APA StyleSun, C., Zhang, C., & Xiong, N. (2020). Infrared and Visible Image Fusion Techniques Based on Deep Learning: A Review. Electronics, 9(12), 2162. https://doi.org/10.3390/electronics9122162