Q-Selector-Based Prefetching Method for DRAM/NVM Hybrid Main Memory System



Abstract
1. Introduction
- We propose QSBP, a dynamic prefetcher selection method for DRAM/PCM hybrid main memory systems based on an online reinforcement learning method.
- We measure the entire performance and hit ratio of DRAM caches of various DRAM/PCM hybrid main memory models including QSBP. The result of the evaluation shows that our QSBP model is far better than the traditional hybrid main memory system without any management methods and a state-of-the-art prefetcher based model.
2. Background and Related Works
2.1. Phase Change Memory
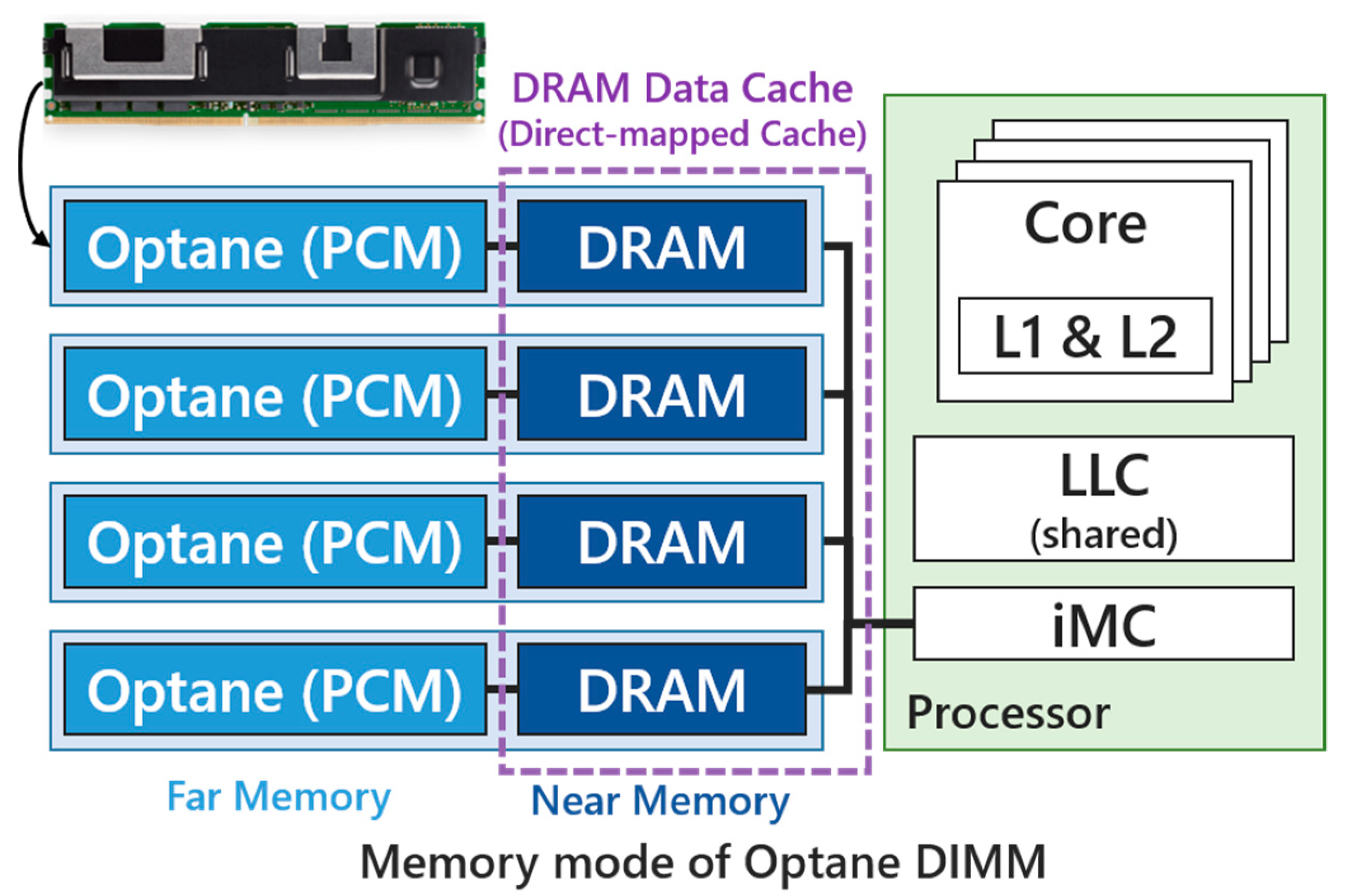
2.2. DRAM/PCM Hybrid Memory Systems
3. Methodology: Q-Selector-Based Prefetching Method for Hybrid Main Memory System
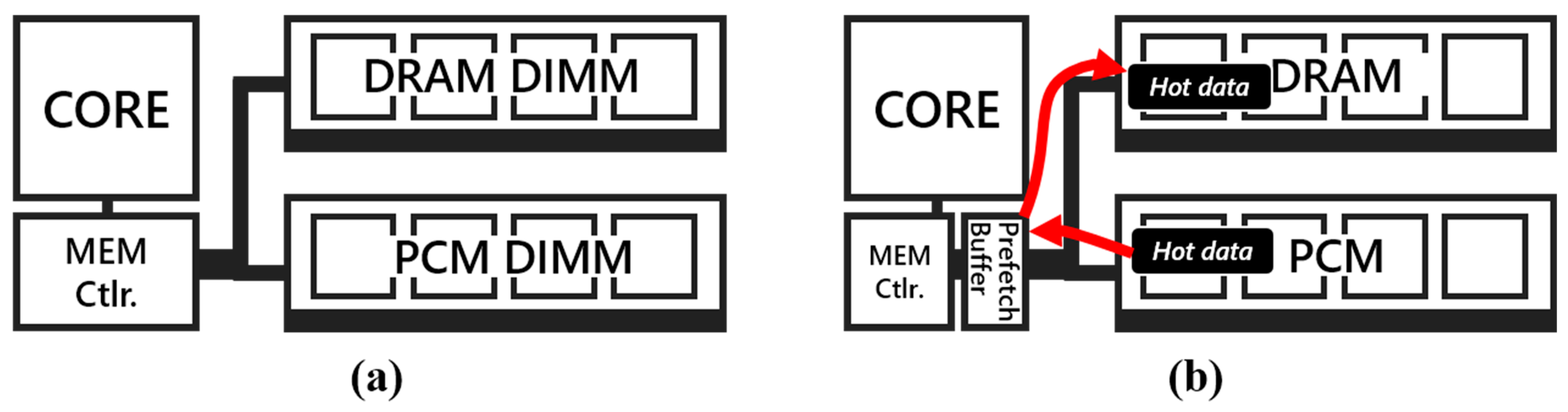
3.1. Motivations: DRAM/PCM Hybrid Main Memory System
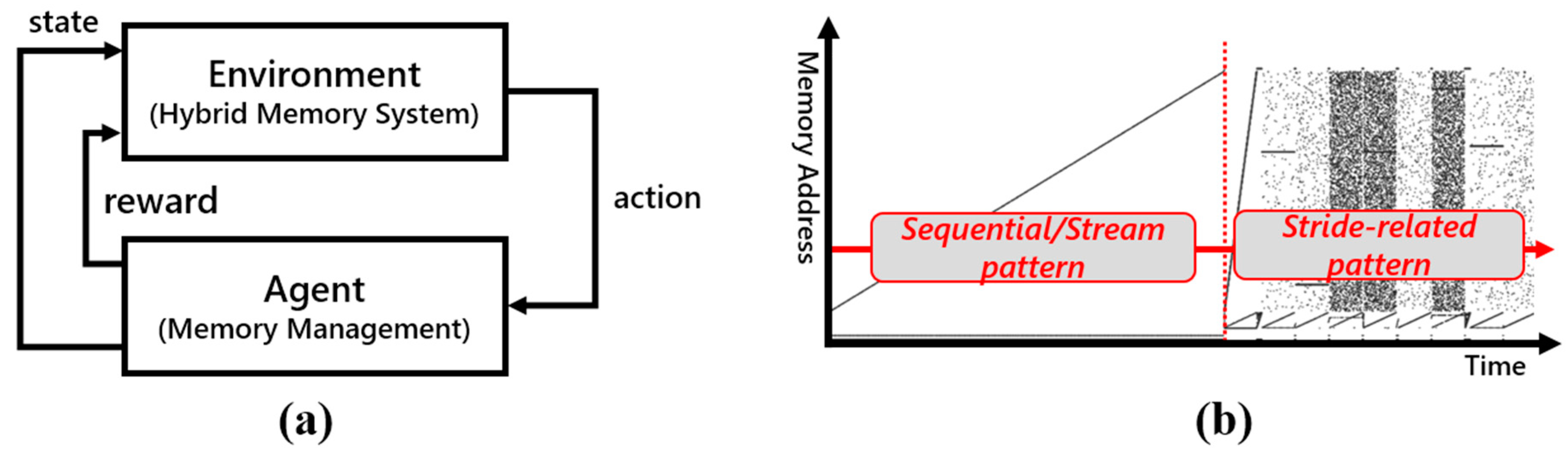
3.2. Reinforcement Learning
- Environment: certain physical environment where the agent operates and interacts,
- State: a set of states of environment and agent,
- Actions: a set of actions of the agent,
- Reward: feedback (rewards or gains after actions by the agent) from the environment,
- Policy: a way to map agent’s state to actions,
- Value: future reward (delayed reward) after agent’s action at a certain state.
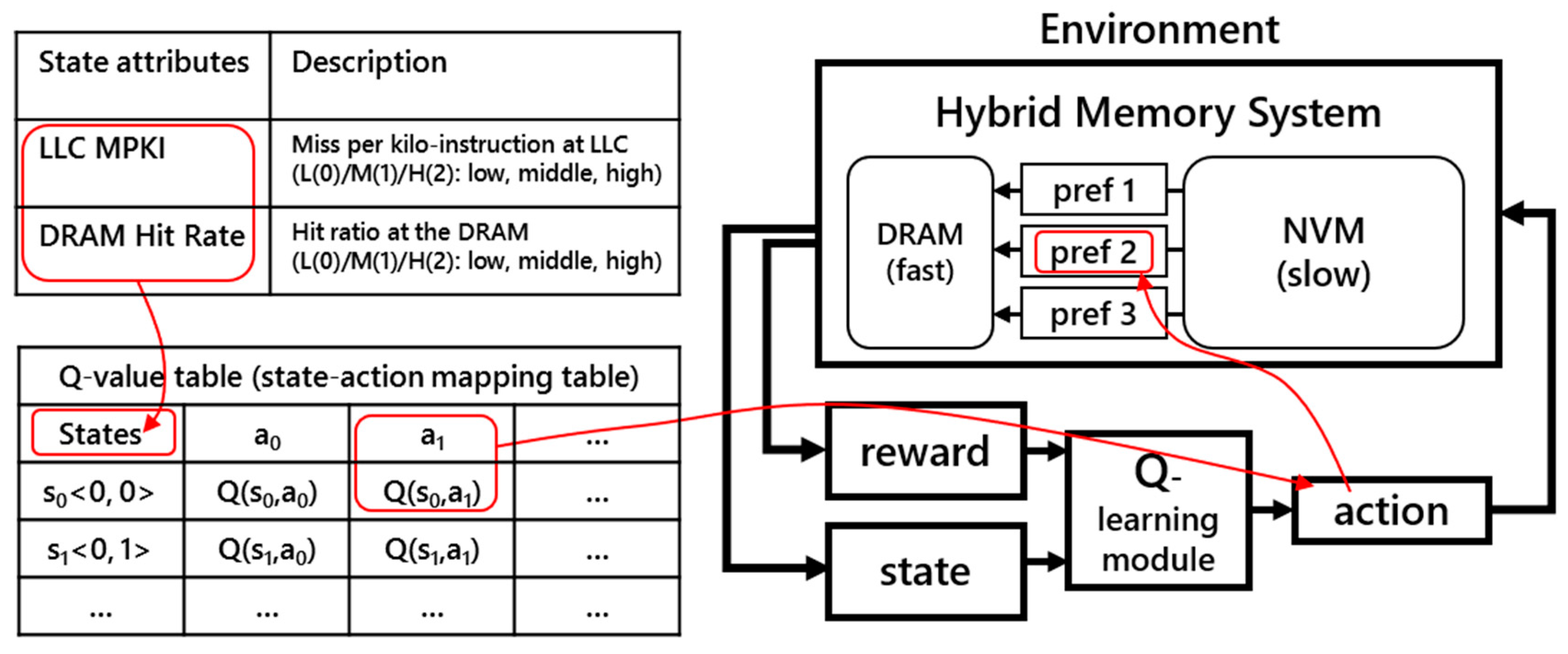
3.3. Design of Q-Selector-Based Prefetching Method
4. Experiments
5. Evaluation
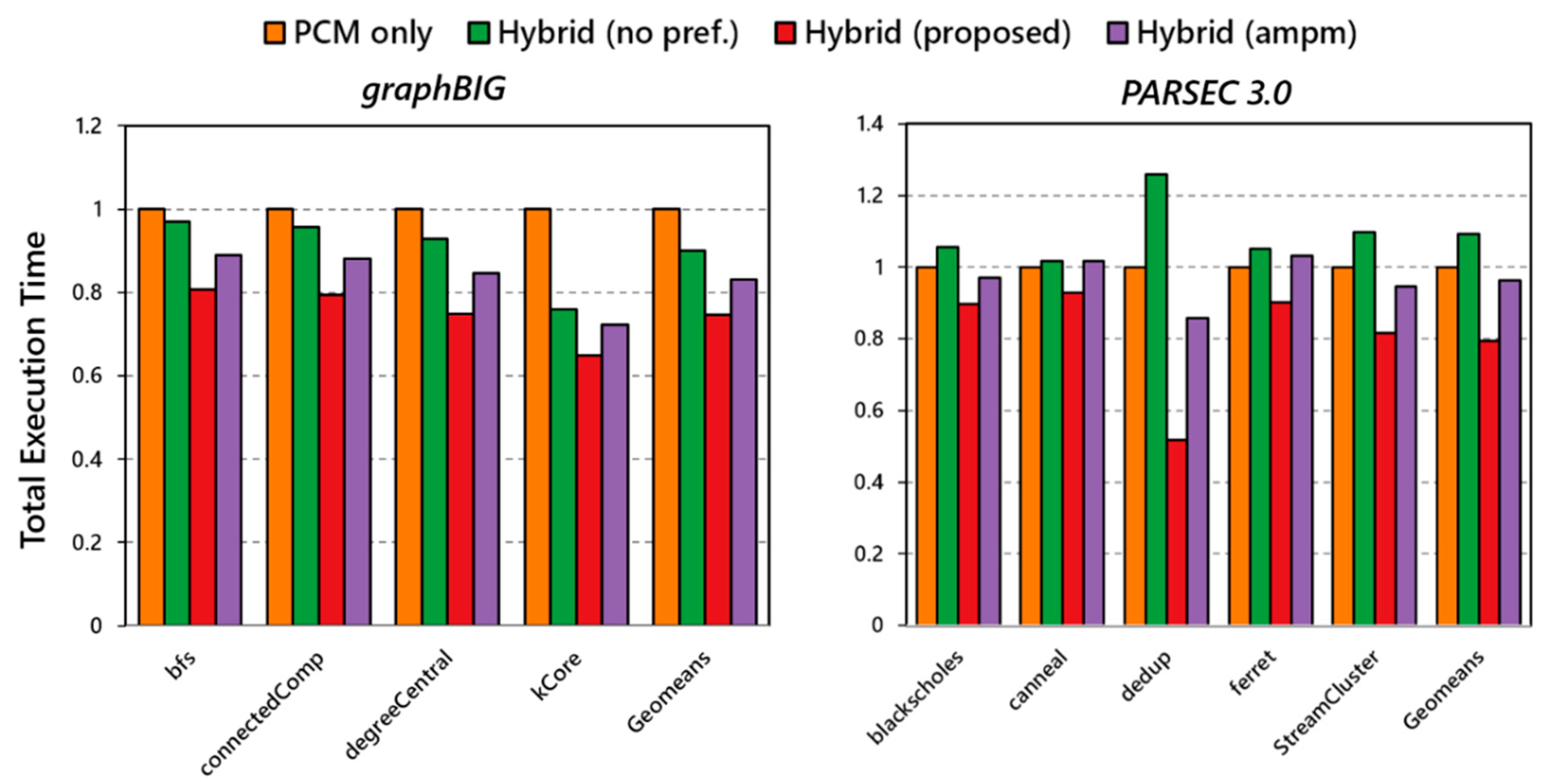
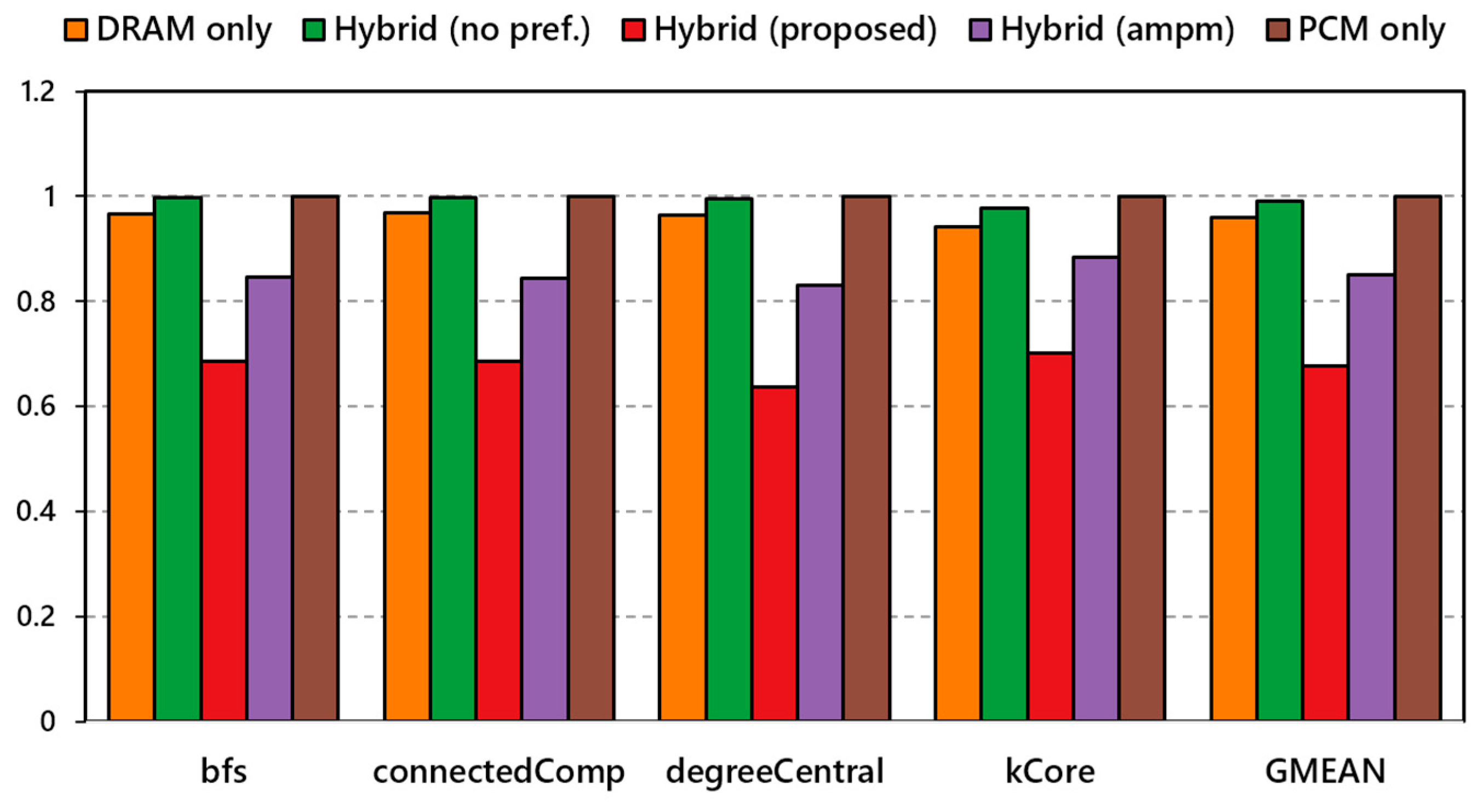
- DRAM only: a baseline configuration based on conventional DDR4-DRAM main memory,
- PCM only: a baseline configuration based on DDR4-PCM main memory without DRAM devices,
- DRAM/PCM hybrid memory system: a hybrid main memory-based system based on DRAM/NVM devices without any prefetchers or management policies,
- DRAM/PCM hybrid memory system with AMPM [14] prefetcher: a hybrid memory system with AMPM prefetcher,
- QSBP (proposed): our proposed hybrid memory system based on Q-Selector based prefetcher.
5.1. Performance
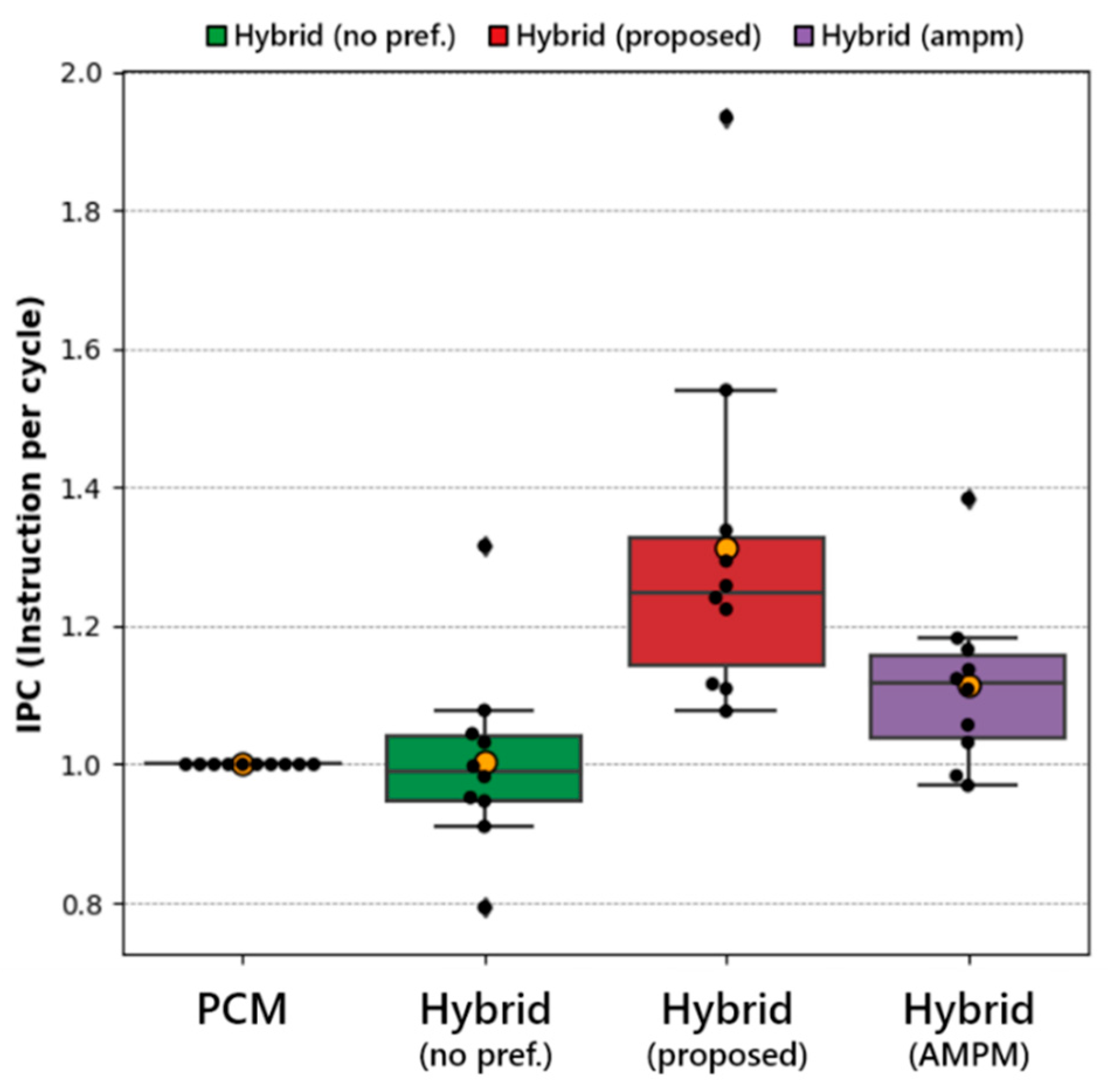
5.2. Relative IPC
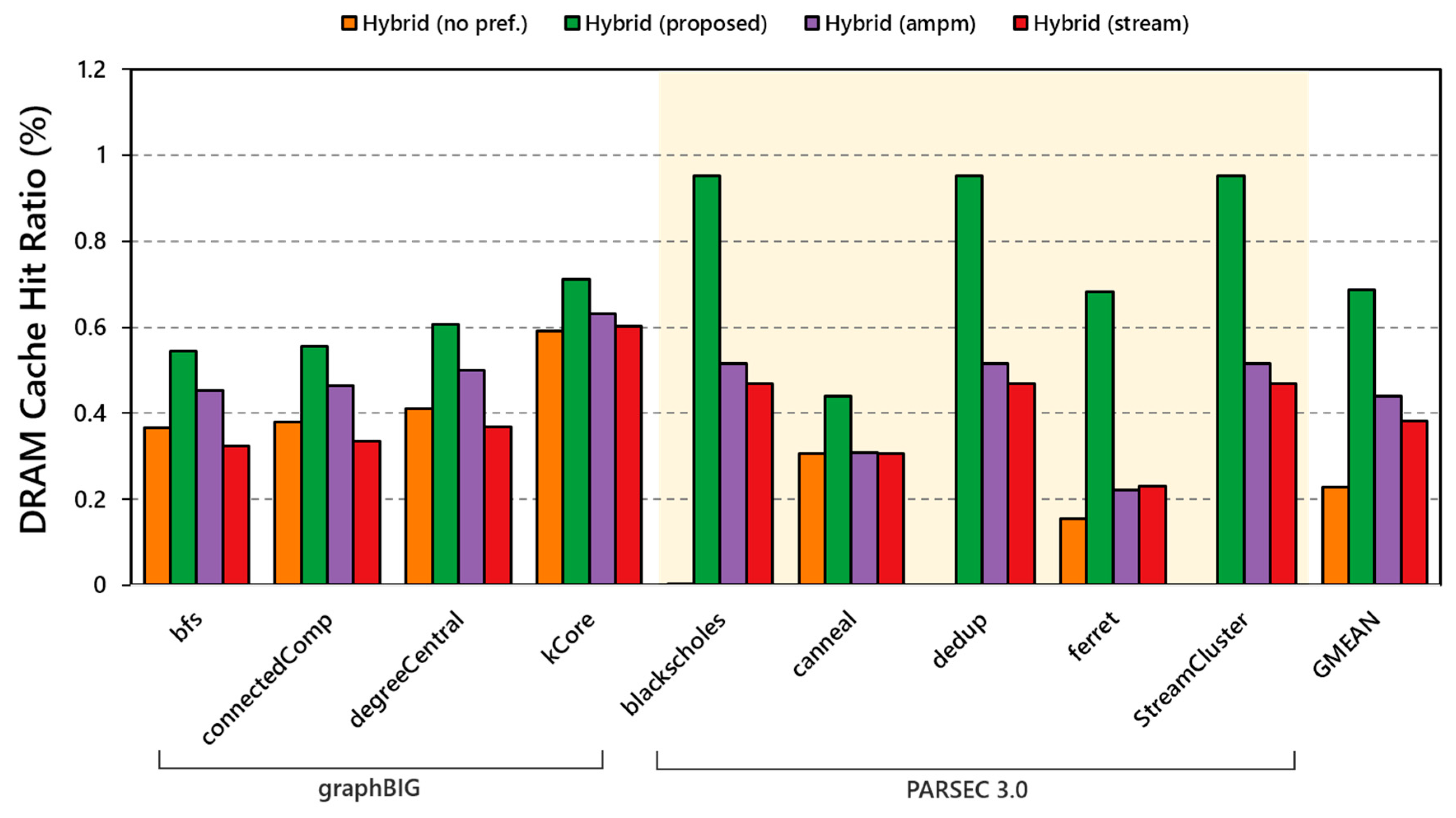
5.3. Hit Ratio of DRAM-Cache
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| NVM | Non-Volatile Memory |
| PCM | Phase Change Memory |
| DRAM | Dynamic Random-Access Memory |
| LLC | Last-Level Cache |
| QSBP | Q-Selector Based Prefetcher |
| FCFS | First-Come-First Serve |
| SSD | Solid-State Drive (Disk) |
| MPKI | Miss Per Kilo Instruction |
| IPC | Instructions Per Cycle |
| RL | Reinforcement Learning |
References
- Qureshi, M.K.; Srinivasan, V.; Rivers, J.A. Scalable high performance main memory system using phase-change memory technology. ACM Sigarch Comput. Arch. News 2009, 37, 24–33. [Google Scholar] [CrossRef]
- Sim, J.; Alameldeen, A.R.; Chishti, Z.; Wilkerson, C.; Kim, H. Transparent Hardware Management of Stacked DRAM as Part of Memory. In Proceedings of the 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; pp. 13–24. [Google Scholar]
- Qureshi, M.K.; Franceschini, M.M.; Lastras-Montano, L.A. Improving read performance of Phase Change Memories via Write Cancellation and Write Pausing. In Proceedings of the HPCA—16 2010 The Sixteenth International Symposium on High-Performance Computer Architecture, Bangalore, India, 9–14 January 2010; pp. 1–11. [Google Scholar]
- Ustiugov, D.; Daglis, A.; Picorel, J.; Sutherland, M.; Bugnion, E.; Falsafi, B.; Pnevmatikatos, D. Design guidelines for high-performance SCM hierarchies. In Proceedings of the International Symposium on Memory Systems, Alexandria, VA, USA, 1–4 October 2018; Association for Computing Machinery (ACM): New York, NY, USA, 2018; pp. 3–16. [Google Scholar]
- Zhang, W.; Mazzarello, R.; Wuttig, M.; Ma, E. Designing crystallization in phase-change materials for universal memory and neuro-inspired computing. Nat. Rev. Mater. 2019, 4, 150–168. [Google Scholar] [CrossRef]
- PMDK Library. Available online: https://github.com/pmem/pmdk/ (accessed on 10 December 2020).
- Boukhobza, J.; Rubini, S.; Chen, R.; Shao, Z. Emerging NVM: A Survey on Architectural Integration and Research Challenges. ACM Trans. Des. Autom. Electron. Syst. 2018, 23, Article 14. [Google Scholar] [CrossRef]
- Wang, J.; Panda, R.; John, L.K. Prefetching for cloud workloads: An analysis based on address patterns. In Proceedings of the 2017 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Santa Rosa, CA, USA, 24–25 April 2017; pp. 163–172. [Google Scholar]
- Islam, M.; Banerjee, S.; Meswani, M.; Kavi, K. Prefetching as a Potentially Effective Technique for Hybrid Memory Optimization. In Proceedings of the Second International Symposium on Memory Systems, Washington, DC, USA, 3–6 October 2016; Association for Computing Machinery (ACM): New York, NY, USA, 2016; pp. 220–231. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning, 1st ed.; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction. IEEE Trans. Neural Netw. 1998, 9, 1054. [Google Scholar] [CrossRef]
- Ipek, E.; Mutlu, O.; Martínez, J.F.; Caruana, R. Self-Optimizing Memory Controllers: A Reinforcement Learning Approach. Int. Sym. Comput. Arch. 2008, 36, 39–50. [Google Scholar] [CrossRef]
- Kang, W.; Shin, D.; Yoo, S. Reinforcement Learning-Assisted Garbage Collection to Mitigate Long-Tail Latency in SSD. ACM Trans. Embed. Comput. Syst. 2017, 16, 1–20. [Google Scholar] [CrossRef]
- Ishii, Y.; Inaba, M.; Hiraki, K. Access map pattern matching for high performance data cache prefetch. J. Instruct. Level Parallelism 2011, 13, 1–24. [Google Scholar]
- Kim, Y.; Yang, W.; Mutlu, O. Ramulator: A Fast and Extensible DRAM Simulator. IEEE Comput. Arch. Lett. 2016, 15, 45–49. [Google Scholar] [CrossRef]
- Champsim. Available online: https://github.com/ChampSim/ChampSim (accessed on 10 December 2020).
- Luk, C.K.; Cohn, R.; Muth, R.; Patil, H.; Klauser, A.; Lowney, G.; Hazelwood, K. Pin: Building customized program analysis tools with dynamic instrumentation. Acm Sigplan Not. 2005, 40, 190–200. [Google Scholar] [CrossRef]
- Lee, B.C.; Ipek, E.; Mutlu, O.; Burger, D. Architecting phase change memory as a scalable dram alternative. ACM Sigarch Comput. Arch. News 2009, 37, 2–13. [Google Scholar] [CrossRef]
- Yoon, H.; Meza, J.; Ausavarungnirun, R.; Harding, R.A.; Mutlu, O. Row buffer locality aware caching policies for hybrid memories. In Proceedings of the 2012 IEEE 30th International Conference on Computer Design (ICCD), Montreal, QC, Canada, 30 September–3 October 2012; pp. 337–344. [Google Scholar]
- Bienia, C.; Kai, L. Benchmarking Modern Multiprocessors; Princeton University: Princeton, NJ, USA, 2011. [Google Scholar]
- Nai, L.; Xia, Y.; Tanase, I.G.; Kim, H.; Lin, C.Y. GraphBIG: Understanding graph computing in the context of industrial solutions. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Austin, TX, USA, 15–20 November 2015; pp. 1–12. [Google Scholar]
- Henning, J.L. SPEC CPU2006 benchmark descriptions. ACM Sigarch Comput. Arch. News 2006, 34, 1–17. [Google Scholar] [CrossRef]
- Panda, R.; Song, S.; Dean, J.; John, L.K. Wait of a Decade: Did SPEC CPU 2017 Broaden the Performance Horizon? In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 271–282. [Google Scholar]
- Farshin, A.; Roozbeh, A.; Maguire, G.Q.; Kostić, D. Make the Most out of Last Level Cache in Intel Processors. In Proceedings of the Fourteenth EuroSys Conference (EuroSys ’19), Dresden, Germany, 25–28 March 2019; Association for Computing Machinery (ACM): New York, NY, USA, 2019; p. 8. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NAND Flash | PCM | ReRAM | STT-MRAM | |
|---|---|---|---|---|
| Read Latency | 15–35 us | 20–60 ns | ~10 ns | 2–35 ns |
| Write Latency | 200–500 us | 20–150 ns | ~50 ns | 3–50 ns |
| Dynamic Energy (R/W) | Low | Medium/High | Low/High | Low/High |
| Write Endurance | 104–105 | 108–109 | 108–1011 | 1012–1015 |
| Maturity | Mature | Mature (Intel Optane) | Test Chips | Test Chips |
| Inputs: requestt, statet-1 (St-1), statet (St), actiont-1 (At-1) Output: actiont (At) Learning parameters: α(0.9), γ(0.8) if LLCmiss then At = maxQ(St-1, {A0, A1, …, Ai}) rt = reward(DRAM-Cache Miss Ratio) Q(St-1, At-1) = (1 − α) · Q(St-1, At-1) + α · {rt + γ · maxQ(St, At)} end if |
| Processor | 1 core, 4GHz, 4-wide issue |
| Caches | L1-I and L1-D caches: 32 KiB, 8-ways, 64B/line, LRU replacement L2 Unified cache: 256 KiB, 4-ways, 64B/line, LRU replacement Shared L3 (Last-level cache): 8 MiB, 16-way, 64B/line, LRU replacement |
| Memory Controller | Memory Scheduler: FCFS scheduling Unified management for DRAM/NVM hybrid configuration |
| DRAM | Access Latency: 100 ns Energy Consumption: array {read, write} = {1.17, 0.39} pJ/bit |
| NVM | Cell Device: Phase Change Memory Access Latency: 300 ns (3 times slower than DRAM) Energy Consumption: array {read, write} = {2.47, 16.83} pJ/bit (NOTE: DRAM/PCM size is scaled down to balance in terms of cost) |
| Benchmark Suite Name | Benchmark Name | Description |
|---|---|---|
| PARSEC 3.0 [20] | blackscholes | financial analysis application for calculating prices of options |
| canneal | chip optimization tool based on simulated annealing method | |
| dedup | data-center application which compresses storage images | |
| ferret | similarity search application based on feature-rich data | |
| streamcluster | data mining application to solve online clustering problem | |
| graphBIG [21] | bfs | (graph traversal) breadth-first search kernel |
| connected component | finding connected subgraphs using BFS traversal | |
| degree centrality | counting the number of connections linked to vertices | |
| k-core | finding the minimum value of connection for all vertices | |
| Graph Data sets | Real world graph data including: Watson Gene Graph, CA RoadNet (California Road Network) |
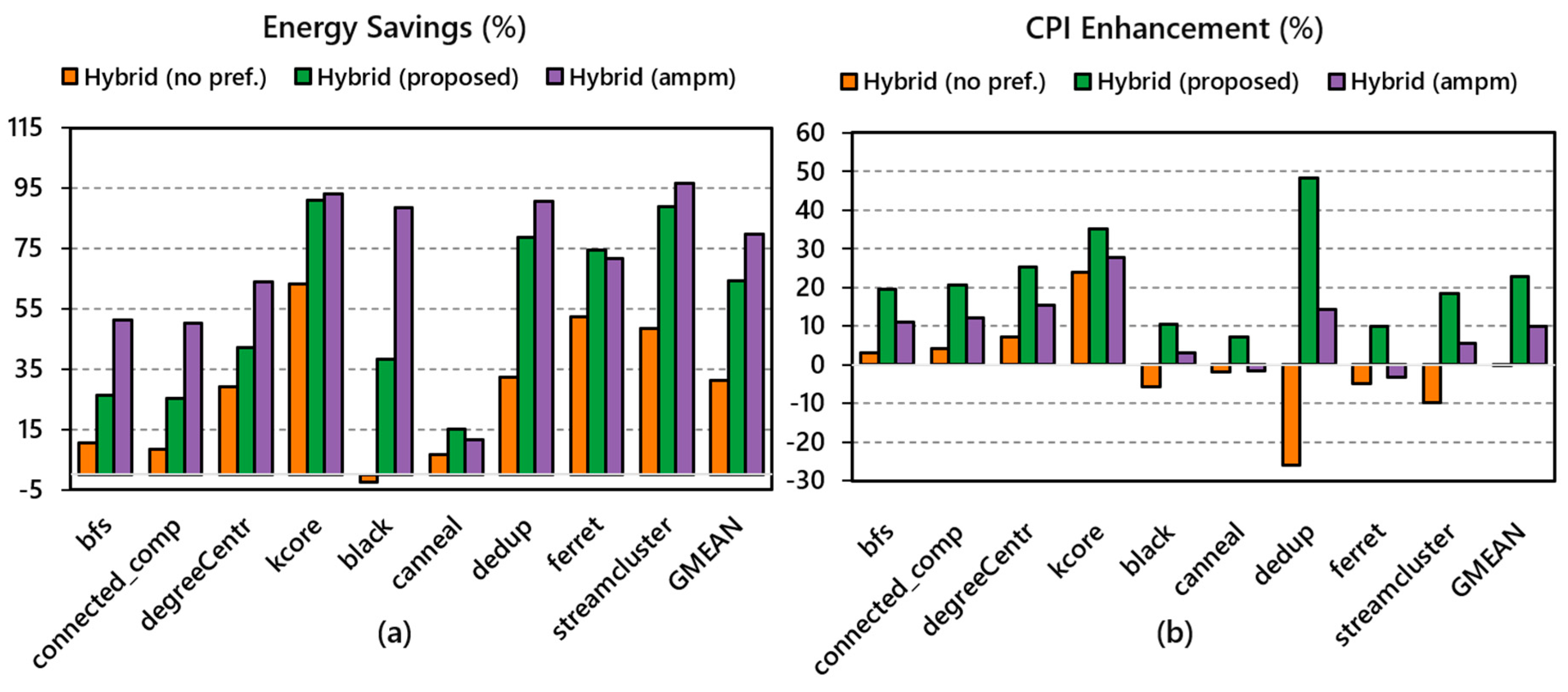
| Energy Savings (%) | CPI Increase (%) | |||||
|---|---|---|---|---|---|---|
| Benchmark | Hybrid (no pref.) | Hybrid (ampm) | Hybrid (QSBP) | Hybrid (no pref.) | Hybrid (ampm) | Hybrid (QSBP) |
| bfs | 10.49% | 51.13% | 26.38% | 3.09% | 11.00% | 19.38% |
| connectedComp | 8.56% | 50.34% | 25.46% | 4.24% | 12.02% | 20.50% |
| degreeCentr | 29.27% | 64.01% | 42.27% | 7.23% | 15.40% | 25.25% |
| kCore | 63.27% | 93.01% | 90.96% | 23.98% | 27.73% | 35.07% |
| blackscholes | −2.32% | 88.60% | 38.22% | −5.59% | 3.06% | 10.40% |
| canneal | 6.66% | 11.49% | 14.98% | −1.80% | −1.66% | 7.12% |
| dedup | 32.14% | 90.70% | 78.72% | −26.02% | 14.22% | 48.32% |
| ferret | 52.50% | 71.57% | 74.53% | −5.03% | −3.14% | 9.84% |
| streamcluster | 48.46% | 96.59% | 88.88% | −9.86% | 5.39% | 18.30% |
| GMEAN | 31.38% | 79.82% | 64.45% | −0.25% | 9.81% | 22.70% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-G.; Kim, S.-D.; Yoon, S.-K. Q-Selector-Based Prefetching Method for DRAM/NVM Hybrid Main Memory System. Electronics 2020, 9, 2158. https://doi.org/10.3390/electronics9122158
Kim J-G, Kim S-D, Yoon S-K. Q-Selector-Based Prefetching Method for DRAM/NVM Hybrid Main Memory System. Electronics. 2020; 9(12):2158. https://doi.org/10.3390/electronics9122158
Chicago/Turabian StyleKim, Jeong-Geun, Shin-Dug Kim, and Su-Kyung Yoon. 2020. "Q-Selector-Based Prefetching Method for DRAM/NVM Hybrid Main Memory System" Electronics 9, no. 12: 2158. https://doi.org/10.3390/electronics9122158
APA StyleKim, J.-G., Kim, S.-D., & Yoon, S.-K. (2020). Q-Selector-Based Prefetching Method for DRAM/NVM Hybrid Main Memory System. Electronics, 9(12), 2158. https://doi.org/10.3390/electronics9122158