Audio-Based Aircraft Detection System for Safe RPAS BVLOS Operations

 , , and
, , and
Abstract
1. Introduction
1.1. Motivation
1.2. Related Work
2. Materials and Methods
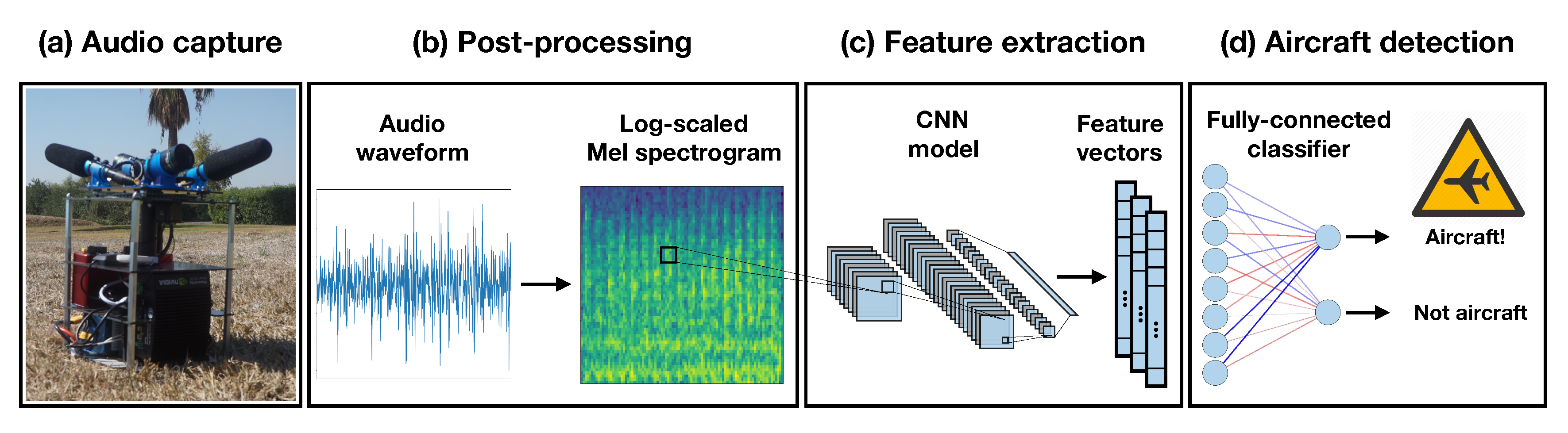
2.1. Aircraft Detection System
2.2. Dataset: Small Aircraft Sounds
2.3. Models: Fine-Tuning Sound Event Detection Models
2.3.1. Audio Post-Processing: From Sound to Images
2.3.2. Feature Extraction Using Pre-Trained CNN Models
2.3.3. Aircraft Sound Classification
3. Results and Discussion
3.1. Performance Metrics
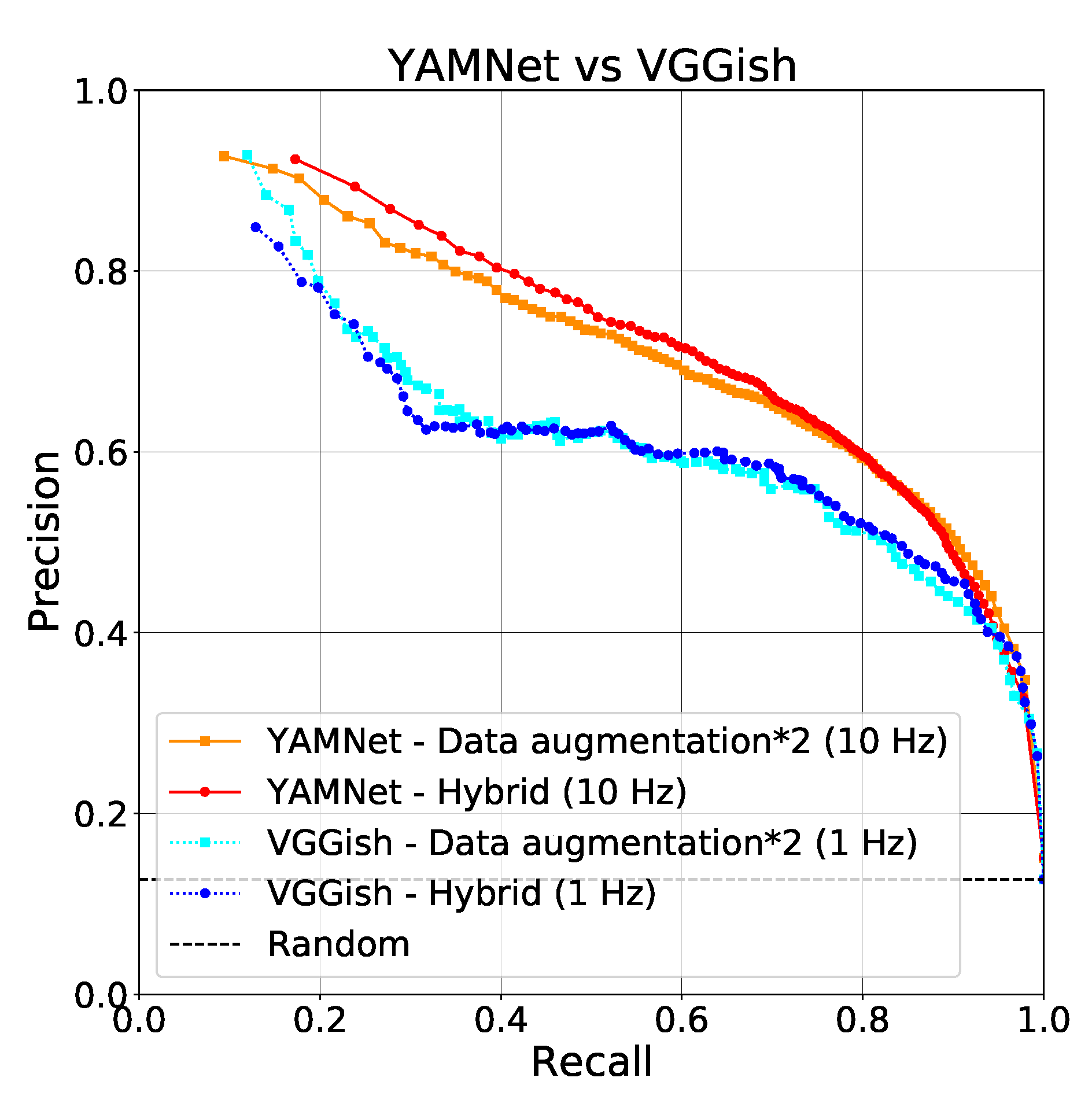
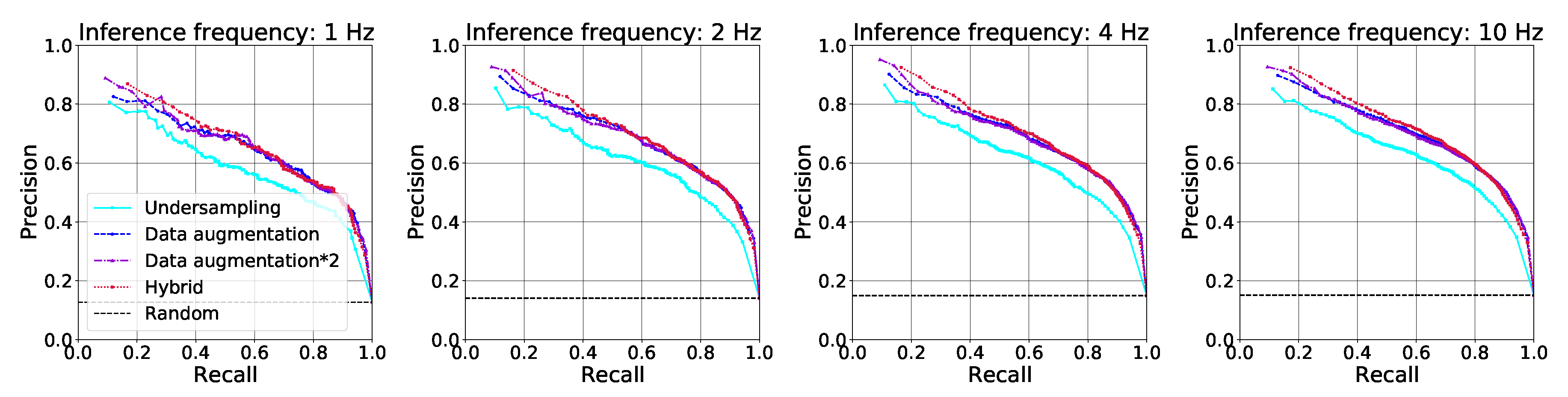
3.2. Dataset and Inference Frequency Comparison
3.3. Computational Performance Assessment
4. Conclusions
Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ADS-B | Automatic Dependent Surveillance-Broadcast |
| ATLAS | Air Traffic Laboratory for Advanced Unmanned Systems |
| BVLOS | Beyond Visual Line of Sight |
| CNN | Convolutional Neural Network |
| DCASE | Detection and Classification of Acoustic Scenes and Events |
| FN | False Negatives |
| FP | False Positives |
| FPR | False Positive Rate |
| P–R | Precision–Recall |
| PRE | Precision |
| RNN | Recurrent Neural Network |
| RPAS | Remotely Piloted Aircraft Systems |
| SED | Sound Event Detection |
| STFT | Short-Time Fourier Transform |
| TN | True Negatives |
| TP | True Positives |
| TPR | True Positive Rate |
| VLL | Very Low Level |
Appendix A. Nvidia Jetson TX2 Configuration and Implementation
- GPU: 256-core Nvidia Pascal architecture (Nvidia, Santa Clara, CA, USA)
- CPU: Dual-Core Nvidia Denver 1.5 64-Bit and Quad-Core ARM Cortex-A57 MPCore processor (Nvidia, Santa Clara, CA, USA)
- RAM: 8 GB 128-bit LPDDR4 58.3 GB/s
- Storage: 32 GB eMMC 5.1
References
- SESARS. European Drones Outlook Study. 2016. Available online: https://www.sesarju.eu/sites/default/files/documents/reports/European_Drones_Outlook_Study_2016.pdf (accessed on 4 September 2020).
- EASA. AMC & GM to Part-UAS. 2019. Available online: https://www.easa.europa.eu/sites/default/files/dfu/AMC%20%26%20GM%20to%20Part-UAS%20%E2%80%94%20Issue%201.pdf (accessed on 7 September 2020).
- Alarcón, V.; García, M.; Alarcón, F.; Viguria, A.; Martínez, A.; Janisch, D.; Acevedo, J.; Maza, I.; Ollero, A. Procedures for the Integration of Drones into the Airspace Based on U-Space Services. Aerospace 2020, 7, 128. [Google Scholar] [CrossRef]
- Murphy, J.R.; Williams-Hayes, P.S.; Kim, S.K.; Bridges, W.; Marston, M. Flight test overview for UAS integration in the NAS project. In Proceedings of the AIAA Atmospheric Flight Mechanics Conference, San Diego, CA, USA, 4–8 January 2016; p. 1756. [Google Scholar]
- Kim, Y.; Jo, J.Y.; Lee, S. ADS-B vulnerabilities and a security solution with a timestamp. IEEE Aerosp. Electron. Syst. Mag. 2017, 32, 52–61. [Google Scholar] [CrossRef]
- Otsuyama, T.; Honda, J.; Shiomi, K.; Minorikawa, G.; Hamanaka, Y. Performance evaluation of passive secondary surveillance radar for small aircraft surveillance. In Proceedings of the 2015 European Radar Conference (EuRAD), Paris, France, 9–11 September 2015; pp. 505–508. [Google Scholar]
- Terneux, E.A.E. Design of an Algorithm for Aircraft Detection and Tracking with a Multi-coordinate VAUDEO System. Ph.D. Thesis, Blekinge Institute of Technology, Karlskrona, Sweden, 2014. [Google Scholar]
- Church, P.; Grebe, C.; Matheson, J.; Owens, B. Aerial and surface security applications using lidar. In Laser Radar Technology and Applications XXIII; Turner, M.D., Kamerman, G.W., Eds.; International Society for Optics and Photonics (SPIE): Bellingham, WA, USA, 2018; Volume 10636, pp. 27–38. [Google Scholar] [CrossRef]
- Petridis, S.; Geyer, C.; Singh, S. Learning to Detect Aircraft at Low Resolutions. In Computer Vision Systems; Gasteratos, A., Vincze, M., Tsotsos, J.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 474–483. [Google Scholar]
- Paweł, R.; Tomasz, R.; Grzegorz, J.; Damian, K.; Piotr, S.; Andrzej, P. Simulation studies of a vision intruder detection system. Aircr. Eng. Aerosp. Technol. 2020, 92, 621–631. [Google Scholar] [CrossRef]
- Xia, X.; Togneri, R.; Sohel, F.; Zhao, Y.; Huang, D. A Survey: Neural Network-Based Deep Learning for Acoustic Event Detection. Circuits Syst. Signal Process. 2019, 38, 3433–3453. [Google Scholar] [CrossRef]
- Abeßer, J. A review of deep learning based methods for acoustic scene classification. Appl. Sci. 2020, 10, 2020. [Google Scholar] [CrossRef]
- DCASE2020 Challenge Results Published—DCASE. 2020. Available online: http://dcase.community/articles/dcase2020-challenge-results-published (accessed on 5 September 2020).
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN Architectures for Large-Scale Audio Classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hayashi, T.; Watanabe, S.; Toda, T.; Hori, T.; Le Roux, J.; Takeda, K. Duration-Controlled LSTM for Polyphonic Sound Event Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2059–2070. [Google Scholar] [CrossRef]
- Adavanne, S.; Pertilä, P.; Virtanen, T. Sound event detection using spatial features and convolutional recurrent neural network. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 771–775. [Google Scholar]
- Miyazaki, K.; Komatsu, T.; Hayashi, T.; Watanabe, S.; Toda, T.; Takeda, K. Weakly-Supervised Sound Event Detection with Self-Attention. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 66–70. [Google Scholar]
- Mnasri, Z.; Rovetta, S.; Masulli, F. Audio surveillance of roads using deep learning and autoencoder-based sample weight initialization. In Proceedings of the 2020 IEEE 20th Mediterranean Electrotechnical Conference ( MELECON), Palermo, Italy, 16–18 June 2020; pp. 99–103. [Google Scholar]
- Guo, X.; Su, R.; Hu, C.; Ye, X.; Wu, H.; Nakamura, K. A single feature for human activity recognition using two-dimensional acoustic array. Appl. Phys. Lett. 2019, 114, 214101. [Google Scholar] [CrossRef]
- Suero, M.; Gassen, C.P.; Mitic, D.; Xiong, N.; Leon, M. A Deep Neural Network Model for Music Genre Recognition. In Advances in Natural Computation, Fuzzy Systems and Knowledge Discovery; Liu, Y., Wang, L., Zhao, L., Yu, Z., Eds.; Springer: Basel, Switzerland, 2020; pp. 377–384. [Google Scholar]
- LeNail, A. NN-SVG: Publication-Ready Neural Network Architecture Schematics. J. Open Source Softw. 2019, 4, 747. [Google Scholar] [CrossRef]
- Salamon, J.; Jacoby, C.; Bello, J.P. A Dataset and Taxonomy for Urban Sound Research. In Proceedings of the 22nd ACM International Conference on Multimedia, New York, NY, USA, 3 November 2014; pp. 1041–1044. [Google Scholar] [CrossRef]
- Mesaros, A.; Heittola, T.; Virtanen, T. A multi-device dataset for urban acoustic scene classification. arXiv 2018, arXiv:1807.09840. [Google Scholar]
- Cartwright, M.; Mendez, A.; Cramer, J.; Lostanlen, V.; Dove, G.; Wu, H.H.; Salamon, J.; Nov, O.; Bello, J. SONYC Urban Sound Tagging (SONYC-UST): A Multilabel Dataset from an Urban Acoustic Sensor Network. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), New York, NY, USA, 1 October 2019; pp. 35–39. [Google Scholar] [CrossRef]
- Turpault, N.; Serizel, R.; Parag Shah, A.; Salamon, J. Sound event detection in domestic environments with weakly labeled data and soundscape synthesis. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019, New York, NY, USA, 25–26 October 2019. [Google Scholar] [CrossRef]
- Koizumi, Y.; Saito, S.; Uematsu, H.; Harada, N.; Imoto, K. ToyADMOS: A Dataset of Miniature-machine Operating Sounds for Anomalous Sound Detection. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019; pp. 308–312. [Google Scholar]
- Purohit, H.; Tanabe, R.; Ichige, T.; Endo, T.; Nikaido, Y.; Suefusa, K.; Kawaguchi, Y. MIMII Dataset: Sound Dataset for Malfunctioning Industrial Machine Investigation and Inspection. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019; pp. 209–213. [Google Scholar]
- Chen, H.; Xie, W.; Vedaldi, A.; Zisserman, A. Vggsound: A Large-Scale Audio-Visual Dataset. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 721–725. [Google Scholar]
- Trowitzsch, I.; Taghia, J.; Kashef, Y.; Obermayer, K. The NIGENS General Sound Events Database; Technical Report; Technische Universität Berlin: Berlin, Germany, 2019. [Google Scholar]
- Piczak, K.J. ESC: Dataset for Environmental Sound Classification. In Proceedings of the 23rd ACM International Conference on Multimedia, New York, NY, USA, 1 October 2015; pp. 1015–1018. [Google Scholar] [CrossRef]
- Partners In Rhyme. Free Airplane Sound Effects. Available online: https://www.freesoundeffects.com/free-sounds/airplane-10004/ (accessed on 9 June 2020).
- Music Technology Research Group (MTG), UPF. Freesound. Available online: https://freesound.org/search/?q=airplane (accessed on 9 June 2020).
- SoundBible. Airplane Sounds. Available online: http://soundbible.com/suggest.php?q=airplane&x=0&y=0 (accessed on 9 June 2020).
- FADA. ATLAS—Air Traffic Laboratory for Advanced unmanned Systems. Available online: http://atlascenter.aero/en/ (accessed on 9 June 2020).
- Rosen, S.; Howell, P. Signals and Systems for Speech and Hearing, 2nd ed.; OCLC: 706853128; lEmerald: Bingley, UK, 2011. [Google Scholar]
- More, S.R. Aircraft Noise Characteristics and Metrics. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 2011. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Google. YAMNet. 2019. Available online: https://github.com/tensorflow/models/tree/master/research/audioset/yamnet (accessed on 9 June 2020).
- Google. VGGish. 2019. Available online: https://github.com/tensorflow/models/tree/master/research/audioset/vggish (accessed on 9 June 2020).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:cs.CV/1704.04861. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision–Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning (ICML ’06), New York, NY, USA, 1 June 2006; pp. 233–240. [Google Scholar]
- Kiskin, I.; Zilli, D.; Li, Y.; Sinka, M.; Willis, K.; Roberts, S. Bioacoustic detection with wavelet-conditioned convolutional neural networks. Neural Comput. Appl. 2020, 32, 915–927. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Aircraft Sample Size | Not Aircraft Sample Size |
|---|---|---|
| Small Aircraft | 21,398 | 244,750 |
| Undersampling | 21,398 | 40,247 |
| Data augmentation | 215,746 | 244,750 |
| Data augmentation*2 | 427,916 | 446,765 |
| Hybrid | 135,910 | 154,759 |
| Augmentation | Time Stretch, % | Resampling, % | Volume Change, % | Random Noise, % |
|---|---|---|---|---|
| Value range | 75–150 | 90–110 | 65–120 | ±1 |
| Inference Frequency | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | Datasets | 1 Hz | 2 Hz | 4 Hz | 10 Hz | ||||
| , % | , % | , % | , % | , % | , % | , % | , % | ||
| YAMNet | Undersampling | 66.44 | 8.92 | 66.20 | 8.64 | 65.67 | 8.73 | 65.83 | 8.35 |
| Data augmentation | 71.26 | 7.17 | 70.18 | 6.98 | 69.37 | 6.88 | 69.86 | 6.64 | |
| Data augmentation*2 | 68.05 | 6.27 | 67.49 | 6.25 | 67.08 | 6.34 | 67.45 | 6.11 | |
| Hybrid | 74.48 | 8.65 | 74.74 | 8.25 | 74.54 | 8.07 | 74.90 | 7.77 | |
| VGGish | Undersampling | 62.76 | 6.84 | 62.69 | 7.00 | 61.61 | 7.31 | 62.00 | 7.61 |
| Data augmentation | 56.78 | 5.60 | 56.26 | 5.66 | 56.91 | 5.95 | 57.06 | 6.20 | |
| Data augmentation*2 | 53.56 | 5.03 | 54.04 | 5.14 | 54.79 | 5.26 | 54.34 | 5.73 | |
| Hybrid | 63.91 | 6.24 | 63.74 | 6.35 | 63.32 | 6.36 | 62.81 | 6.68 | |
| Models | Inference Frequency | |||
|---|---|---|---|---|
| 1 Hz | 2 Hz | 4 Hz | 10 Hz | |
| YAMNet | 0.140 ± 0.022 | 0.144 ± 0.026 | 0.138 ± 0.026 | 0.154 ± 0.018 |
| VGGish | 1.637 ± 0.073 | 1.632 ± 0.052 | 1.618 ± 0.061 | 1.637 ± 0.086 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mariscal-Harana, J.; Alarcón, V.; González, F.; Calvente, J.J.; Pérez-Grau, F.J.; Viguria, A.; Ollero, A. Audio-Based Aircraft Detection System for Safe RPAS BVLOS Operations. Electronics 2020, 9, 2076. https://doi.org/10.3390/electronics9122076
Mariscal-Harana J, Alarcón V, González F, Calvente JJ, Pérez-Grau FJ, Viguria A, Ollero A. Audio-Based Aircraft Detection System for Safe RPAS BVLOS Operations. Electronics. 2020; 9(12):2076. https://doi.org/10.3390/electronics9122076
Chicago/Turabian StyleMariscal-Harana, Jorge, Víctor Alarcón, Fidel González, Juan José Calvente, Francisco Javier Pérez-Grau, Antidio Viguria, and Aníbal Ollero. 2020. "Audio-Based Aircraft Detection System for Safe RPAS BVLOS Operations" Electronics 9, no. 12: 2076. https://doi.org/10.3390/electronics9122076
APA StyleMariscal-Harana, J., Alarcón, V., González, F., Calvente, J. J., Pérez-Grau, F. J., Viguria, A., & Ollero, A. (2020). Audio-Based Aircraft Detection System for Safe RPAS BVLOS Operations. Electronics, 9(12), 2076. https://doi.org/10.3390/electronics9122076