Proposal of an Adaptive Fault Tolerance Mechanism to Tolerate Intermittent Faults in RAM

 ,
,  ,
,  , and
, and
Abstract
1. Introduction
2. Related Work
- The detection and correction of intermittent faults, which are an important issue in systems where reparation is difficult (like space ships) or in critical systems (like car or airplane driving systems).
- The ability to modify online the operation of the system when error conditions vary.
- Write-back [44]. If faults are corrected in a read operation, the correct data are written back at the end of the read operation. In this way, faults due to environmental causes can be corrected.
- Scrubbing. This consists of reading, correcting and rewriting back the information stored in the memory [45]. It should not be confused with the memory refresh performed in DRAM memories. A refresh consists of merely reading to a buffer the physical information stored and writing it back. Instead, in a scrubbing, the information is read, and the ECC used is applied to correct (if possible) existing errors; then, the corrected data together with the recalculated ECC are written back.
3. Design of an Adaptive Fault Tolerance Mechanism
3.1. Methodology
- The size of internal memory was augmented in order to store data bits together with their corresponding code bits. Considering that the ECCs used have redundancy of r bits, the 512 × 32 original RAM was changed to a 512 × (32 + r) RAM.
- Consequently, the data bus length also grows in r bits.
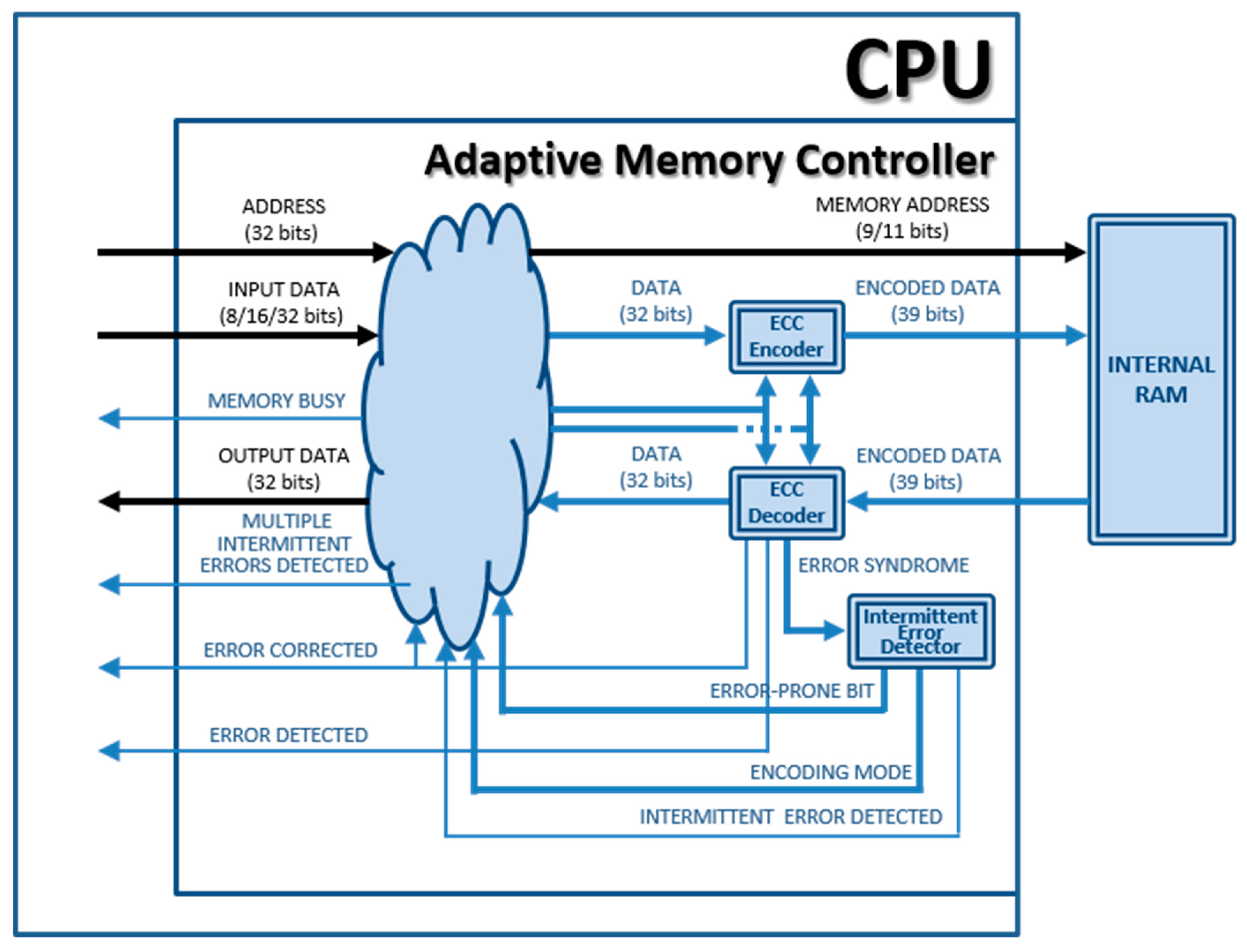
- The “Memory Controller” module that we have renamed as “Adaptive Memory Controller” in the adaptive version. The mission of this component in the original (non-fault-tolerant) Plasma core is to manage the access to the internal RAM from the CPU. In the adaptive version, the memory controller will also:
- support the ECCs implemented,
- detect changes in the error condition, and
- manage the adaption process.
- Adding r code bits to data from the CPU (to be written in memory), or encoding operation;
- Removing the r code bits from data read from memory (to be sent to the CPU). In addition, in case of existing errors, data should be corrected (if errors are covered by the active ECC). This operation is called decoding.
- During a write operation (see Figure 3d), the “ECC Encoder” calculates a code from the input data (adding a delay tenc), and both are stored together in the memory.
- In a read operation, the encoded data are obtained from the RAM. The “ECC Decoder” uses the data part of the memory word read to calculate the corresponding code, and then, the calculated code and the stored code are compared, generating a syndrome vector. This syndrome vector will mark if an erroneous bit(s) is(are) present or not and if error(s) can be corrected or detected. If there are no errors (see Figure 3c, where tdec represents all the delay introduced by the decoder: syndrome generation and data correction), read data can be buffered and delivered to the control unit. If error(s) can be corrected, the output data will be corrected by the decoder and then buffered and delivered; also, the corrected data are re-encoded and written-back in the memory (see Figure 3e). In this case, the memory controller stops the processor during the write-back cycle by setting the “MEMORY BUSY” signal (see Figure 2).
- Both “ECC Encoder” and “ECC Decoder” modules must implement the encoders and decoders of at least two different ECCs.When errors are detected, but cannot be corrected, the “ECC Decoder” module issues the “Error Detected” signal to warn the control unit. This signal is set under distinct circumstances, depending on the error correction and detection capabilities of the ECC used.
- The system starts operating with the simplest ECC (let us name it ECC1).
- An error monitor module monitors the occurrence of errors. As the memory degrades, either because the number of upsets increments or because errors in the same location repeatedly appear (manifesting the appearance of an intermittent fault), the error monitor module should be able to detect the new error condition, and it may be necessary to change from current ECC (let us name ECCi) to another ECC (ECCj, j ≠ i) able to cope with the new error condition.
- If there are no more ECCs available after detecting a new error condition, the “Adaptive Memory Controller” should issue some warning or error signal to the control unit (e.g., see “MULTIPLE INTERMITTENT ERRORS DETECTED” in Figure 2).
- Error conditions are not supposed to improve, but only to get worse. That is, if fault multiplicity increases, it will not decrease back again. Similarly, once a bit has been labeled as “error-prone” (i.e., an intermittent fault has been detected in that bit), it will never be unlabeled. If anything, a second (or more) bit could also be labeled as “error-prone”.
- The microprocessor is stopped (by setting the aforementioned “MEMORY BUSY” signal), and the “ECC Encoder” module is changed to the corresponding to the new ECC to be used;
- The whole RAM is scrubbed by reading all memory addresses sequentially using the old “ECC Decoder” to get the data and re-encoding them with the new “ECC Encoder”. This operation is similar to the faulty read shown in Figure 3e, and hence it takes two clock cycles per memory address;
- The “ECC Decoder” is changed to the corresponding to the new ECC to be used;
- The microprocessor is resumed (unsetting “MEMORY BUSY”), continuing its operation from the same point.
3.2. Case Example: Intermittent Fault Detection
3.3. Other Cases
4. Assessment of the Adaptive Fault Tolerance Mechanism
4.1. Fault Injection Parameters
- Fault injection technique. We have used simulator commands, a VHDL simulation-based fault injection technique [59]. This technique allows changing, at simulation time, the value or the timing of the signals and variables of a VHDL model.
- Injection targets. Faults have been injected in the internal RAM of the Plasma microprocessor, running the Bubblesort sorting algorithm. This algorithm sorts 10 integer values. The size of the algorithm is 72 memory words (out of 512 of the whole memory) for the code segment, plus 30 words for the data segment. Therefore, only 102 memory addresses out of 512 (a 20%) are actually accessed by the workload.Bubblesort algorithm is an adequate workload to check the performance of the AFT mechanism proposed because it accesses multiple times memory addresses (belonging to both code and data segments). This allows to inject faults in the same memory location at different operation times (simulating intermittent faults) and analyze if they are corrected or detected by the AFT mechanism. On the other hand, the duration of this workload makes the duration of the injection campaign to be reasonable.We have considered running other workloads, but we have discarded them because either they do not access the data segment enough times to allow detecting intermittent faults in it, or their simulation times are unfeasible.
- Number of faults injected. Each injection experiment consists of a number of model simulations where a set of faults is injected in each simulation.We have studied a suitable number of injections per experiment. In tuning experiments, we have injected experiments with 1000 and 10,000 injections. The results differ by less than 1%. Hence, we have opted for injecting 1000 faults per experiment.
- Fault models. As commented in the Introduction, besides transient faults, intermittent faults are a major challenge in modern computer design, as detecting and tolerating them is not an easy task. Thus, we have injected these two types of faults.Consequent to the injection target (i.e., RAM cells), the fault models injected are bit-flip for transient faults and intermittent stuck-at and intermittent bit-flip for intermittent faults [22]. For short, we will refer to them as BF, ISA and IBF hereinafter.Regarding intermittent fault models, ISA and IBF differ in their behavior after fault deactivation; in ISA faults, the effect of fault disappears, and the target recovers the previous value; in IBF faults, however, the erroneous value persists in time until it is overwritten.
- Fault timing. As the bit-flip just consists of inverting the logic value of the affected cell, the duration of transient faults does not make sense.The timing of intermittent faults depends on some variable aspects like manufacturing process, environment, wearout process, etc. In this way, three burst parameters must be taken into account to model intermittent faults [60]:
- Burst length (LBurst). It represents the number of times that the fault is activated in the burst.
- Activity time (tA). It indicates the duration of each fault activation. In IBF faults, the activity time does not make sense. In ISA faults, we have defined three ranges: [0.1T, T], [T, 10T] and [10T, 100T], where T is the clock cycle.
- Inactivity time (tI). It is the separation between two consecutive activations. Due to their different behavior, we have defined different settings for this parameter. In IBF faults, we have the average access time (i.e., the average separation between accesses, obtained from the workload analysis, see Section 4), which is different for each memory address. Instead, in ISA faults, we have defined three ranges: [0.1T, T], [T, 10T] and [10T, 100T].
The reason to use the average access time in IBF faults is to reduce the probability that two (or more) consecutive activations may occur between two consecutive accesses. If an even number of fault activations occurred prior to memory access, they would cancel in pairs, reducing the effect of the intermittent fault. - Fault multiplicity. Transient faults may affect multiple locations due to technology scaling [5]. These multiple locations can be adjacent (i.e., neighbor cells in registers and memory, neighbor wires in a bus, etc.) or non-adjacent (i.e., random). Thus, we have injected both single and multiple faults in both random and adjacent bits (in the same memory word). In addition, multiple transient faults can occur when a single transient fault coincides with a previously uncorrected error [41], no matter what its origin is. We have also injected this type of multiple faults, particularly an intermittent fault followed by single and multiple transient faults.
- Measurements. The data measured are:
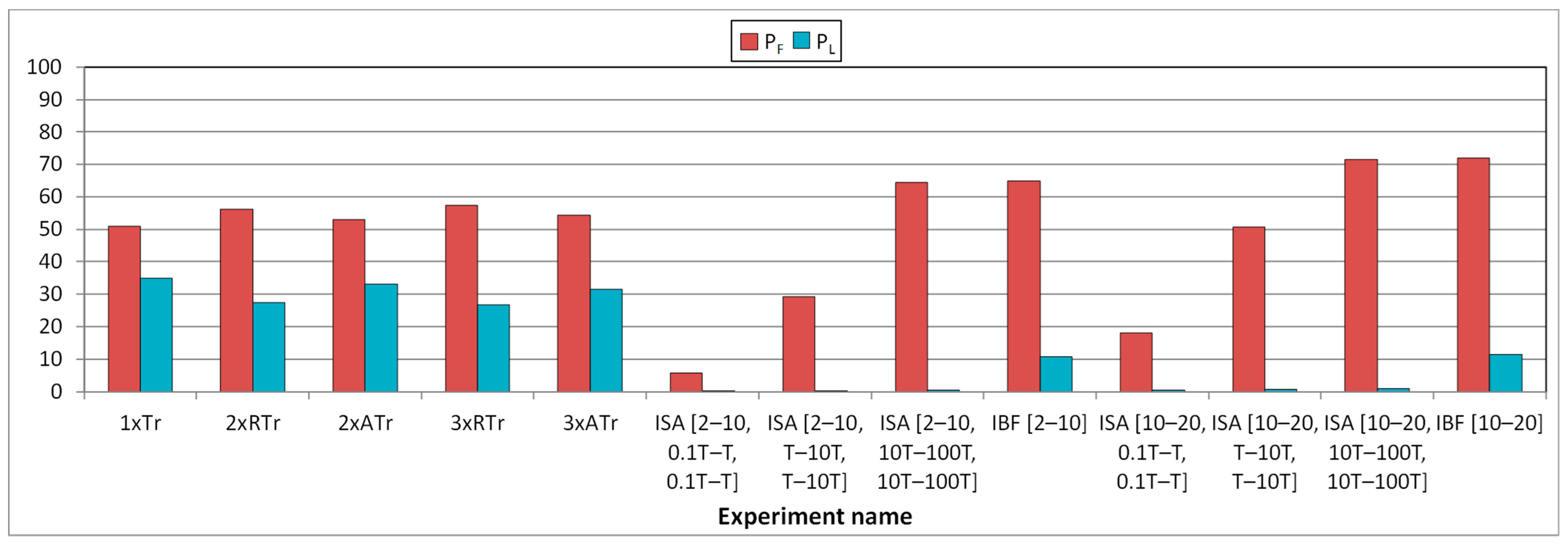
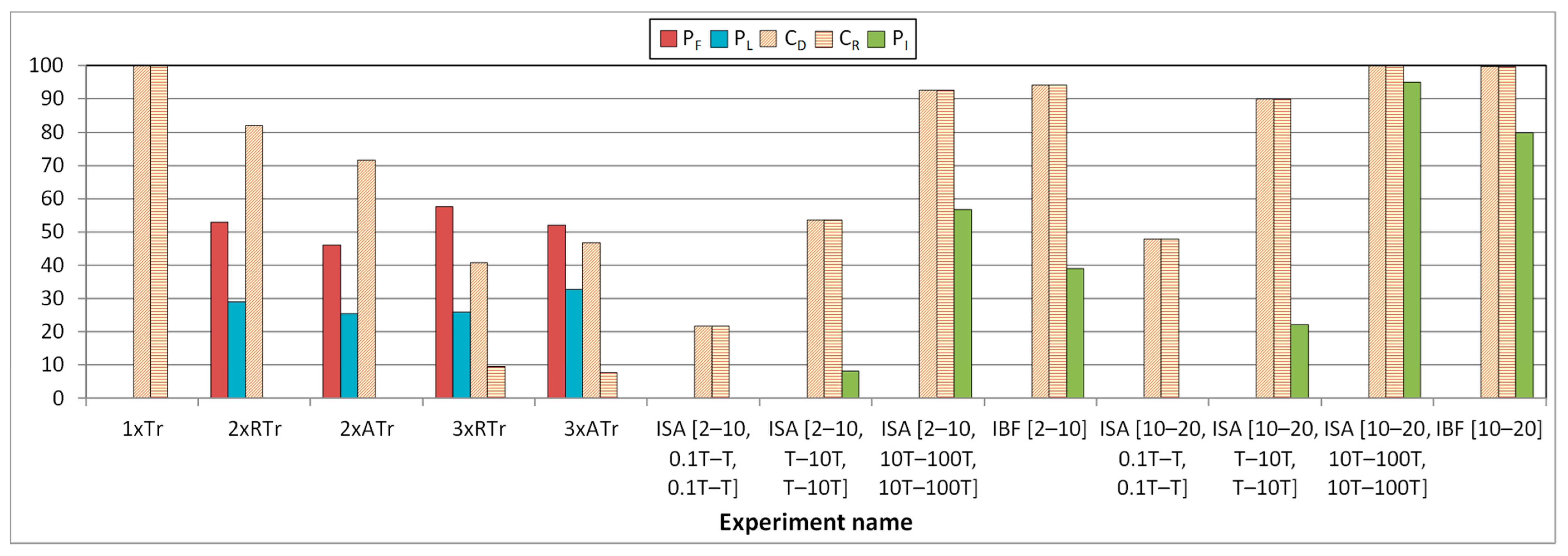
- The percentage of failures, PF:where NF is the number of failures, and Ninj is the number of injections (i.e., simulations).
- The percentage of latent errors, PL:where NL is the number of latent errors.
- The detection coverage, CD:where ND is the number of errors detected.
- The recovery coverage, CR:where NR is the number of errors corrected.
- The percentage of intermittent errors detected, PI:where NI is the number of intermittent errors detected.
4.2. Injection Experiments
- Single transient faults;
- Double and triple random (in the same memory word) transient faults;
- Double and triple adjacent (in the same memory word) transient faults;
- Single intermittent faults;
- Single intermittent faults combined with single and multiple transient faults in the same memory word. These experiments simulate the occurrence of a transient fault in the same memory word after an intermittent error has been detected, the system has been reconfigured with a new ECC, and the memory has been scrubbed. The objective of these experiments is to check the behavior of the system after the reconfiguration.
4.3. Injection Campaign
- The set of injection targets are limited in each experiment to those memory addresses that are accessed by the workload, and only if they are accessed (at least) as many times as the maximum number of fault activations of the fault to be injected. That is to say, a memory address that is accessed 15 times during the workload execution will be selected as the target when injecting intermittent faults with a burst length in the range [2, 10], but not in the range [10, 20].
- Faults are injected in each target in a time window where the addresses are accessed. We know these time windows from the workload analysis (see Section 4).
- The injected fault modified a memory address but did not cause any failure.
- The fault was injected after the last access to that address, or the address was never accessed.
4.4. Outcomes
- Single transient faults (labeled as 1xTr);
- Double random transient faults (2xRTr);
- Double adjacent transient faults (2xATr);
- Triple random transient faults (3xRTr);
- Triple adjacent transient faults (3xATr);
- Single intermittent faults. From all the experiments carried out (varying the fault model, Lburst, tA and tI), we have selected a subset:
- o
- Intermittent stuck-at (ISA) fault model, with Lburst in the range [2, 10], tA in the range [0.1T, T], and tI in the range [0.1T, T], where T is the clock cycle of the system (labeled as ISA [2–10, 0.1T–T, 0.1T–T] in the graph).
- o
- ISA fault model, with Lburst in the range [2, 10], tA in the range [T, 10T], and tI in the range [T, 10T] (ISA [2–10, T–10T, T–10T]).
- o
- ISA fault model, with Lburst in the range [2, 10], tA in the range [10T, 100T], and tI in the range [10T, 100T] (ISA [2–10, 10T–100T, 10T–100T]).
- o
- Intermittent bit-flip (IBF) fault model, with Lburst in the range [2, 10] (IBF [2–10]).
- o
- ISA fault model, with Lburst in the range [10, 20], tA in the range [0.1T, T], and tI in the range [0.1T, T] (ISA [10–20, 0.1T–T, 0.1T–T]).
- o
- ISA fault model, with Lburst in the range [10, 20], tA in the range [T, 10T], and tI in the range [T, 10T] (ISA [10–20, T–10T, T–10T]).
- o
- ISA fault model, with Lburst in the range [10, 20], tA in the range [10T, 100T], and tI in the range [10T, 100T] (ISA [10–20, 10T–100T, 10T–100T]).
- o
- Intermittent bit-flip (IBF) fault model, with Lburst in the range [10, 20] (IBF [2–10]).
- When injecting ISA faults with tA in the range [0.1T, T], it is very unlikely to access a memory address affected by a fault. Moreover, this probability reduces for smaller numbers of fault activations. This implies that most fault activations do not affect the system. However, this probability grows as tA does, causing more failures than transient faults.
- Something different occurs to IBF faults: if a fault activation does not affect the system, the next activation will cancel the effect of the previous one, thus reducing its damage.
- Single faults (labeled in the X-axis as 1xTr ×);
- Double random faults (2xRTr);
- Double pseudorandom faults (2xPsRTr);
- Double adjacent faults (2xATr);
- Double pseudo-adjacent faults (2xPsATr);
- Triple random faults (3xRTr);
- Triple adjacent faults (3xATr);
- Triple pseudo-adjacent faults (3xPsATr).
4.5. Analysis of System Overhead
- Switching the “ECC Encoder” (one clock cycle, as explained in Section 3.2), which corresponds to step 1 of the reconfiguration algorithm, is described in Section 3.1;
- Scrubbing the memory (two clock cycles per memory address; in total, 2 × W clock cycles), which corresponds to step 2;
- Switching the “ECC Decoder” and the “Error Manager” (one clock cycle) of step 3.
4.6. Comparison with Other Proposals
- The type of memory to which is applied.
- How is the adaption management implemented (hardware vs. software)?
- The adaption trigger.
- The list of alternative ECCs.
- Do the alternative ECCs have the same redundancy?
- Does the system physically reconfigure? That is to say, is the system reprogrammed/reconfigured, or are all the ECCs physically implemented in the system as spares?
- A 2-bit BCH could be used as the initial ECC.
- It should swap to another (UEC) ECC able to support at least one intermittent error plus multiple (adjacent or random) additional errors.
5. Conclusion and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- International Technology Roadmap for Semiconductors (ITRS). 2013. Available online: http://www.itrs2.net/2013-itrs.html (accessed on 2 October 2020).
- Jen, S.L.; Lu, J.C.; Wang, K. A review of reliability research on nanotechnology. IEEE Trans. Reliab. 2007, 56, 401–410. [Google Scholar] [CrossRef]
- Ibe, E.; Taniguchi, H.; Yahagi, Y.; Shimbo, K.; Toba, T. Impact of scaling on neutron-induced soft error in SRAMs from a 250 nm to a 22 nm design rule. IEEE Trans. Electron Devices 2010, 57, 1527–1538. [Google Scholar] [CrossRef]
- Boussif, A.; Ghazel, M.; Basilio, J.C. Intermittent fault diagnosability of discrete event systems: And overview of automaton-based approaches. Discret. Event Dyn. Syst. 2020. [Google Scholar] [CrossRef]
- Constantinescu, C. Trends and challenges in VLSI circuit reliability. IEEE Micro 2003, 23, 14–19. [Google Scholar] [CrossRef]
- Constantinescu, C. Impact of Intermittent Faults on Nanocomputing Devices. In Proceedings of the Workshop on Dependable and Secure Nanocomputing (WDSN 2007), Edinburgh, UK, 28 June 2007; pp. 238–241. [Google Scholar]
- De Kleer, J. Diagnosing Multiple Persistent and Intermittent Faults. In Proceedings of the 21st International Joint Conference on Artificial Intelligence (IJCAI-09), Pasadena, CA, USA, 11–17 July 2009; pp. 733–738. [Google Scholar]
- Bondavalli, A.; Chiaradonna, S.; Di Giandomenico, F.; Grandoni, F. Threshold-Based Mechanisms to Discriminate Transient from Intermittent Faults. IEEE Trans. Comput. 2000, 49, 230–245. [Google Scholar] [CrossRef]
- Contant, O.; Lafortune, S.; Teneketzis, D. Diagnosis of Intermittent Faults. Discret. Event Dyn. Syst.-Theory Appl. 2004, 14, 171–202. [Google Scholar] [CrossRef]
- Sorensen, B.A.; Kelly, G.; Sajecki, A.; Sorensen, P.W. An Analyzer for Detecting Intermittent Faults in Electronic Devices. In Proceedings of the 1994 IEEE Systems Readiness Technology Conference (AUTOTESTCON’94), Anaheim, CA, USA, 20–22 September 1994; pp. 417–421. [Google Scholar] [CrossRef]
- Gracia-Moran, J.; Gil-Tomas, D.; Saiz-Adalid, L.J.; Baraza, J.C.; Gil-Vicente, P.J. Experimental validation of a fault tolerant microcomputer system against intermittent faults. In Proceedings of the 2010 IEEE/IFIP International Conference on Dependable Systems and Networks (DSN 2010), Chicago, IL, USA, 28 June–1 July 2010; pp. 413–418. [Google Scholar] [CrossRef]
- Fujiwara, E. Code Design for Dependable Systems; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar] [CrossRef]
- Hamming, R.W. Error detecting and error correcting codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Saiz-Adalid, L.J.; Gil-Vicente, P.J.; Ruiz, J.C.; Gil-Tomás, D.; Baraza, J.C.; Gracia-Morán, J. Flexible Unequal Error Control Codes with Selectable Error Detection and Correction Levels, Proceedings of the 2013 Computer Safety, Reliability, and Security Conference (SAFECOMP 2013), Toulouse, France, 14–27 September 2013; Bitsch, F., Guiochet, J., Kaâniche, M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8153, pp. 178–189. [Google Scholar] [CrossRef]
- Frei, R.; McWilliam, R.; Derrick, B.; Purvis, A.; Tiwari, A.; Di Marzo Serugendo, G. Self-healing and self-repairing technologies. Int. J. Adv. Manuf. Technol. 2013, 69, 1033–1061. [Google Scholar] [CrossRef]
- Maiz, J.; Hareland, S.; Zhang, K.; Armstrong, P. Characterization of multi-bit soft error events in advanced SRAMs. In Proceedings of the 2003 IEEE International Electron Devices Meeting (IEDM 2003), Washington, DC, USA, 8–10 December 2003; pp. 21.4.1–21.4.4. [Google Scholar] [CrossRef]
- Schroeder, B.; Pinheiro, E.; Weber, W.-D. DRAM errors in the wild: A large-scale field study. Commun. ACM 2011, 54, 100–107. [Google Scholar] [CrossRef]
- McCartney, M. SRAM Reliability Improvement Using ECC and Circuit Techniques. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, December 2014. [Google Scholar]
- Mofrad, A.B.; Ebrahimi, M.; Oborily, F.; Tahooriy, M.B.; Dutt, N. Protecting caches against Multi-Bit Errors using embedded erasure coding. In Proceedings of the 2015 20th IEEE European Test Symposium (ETS 2015), Cluj-Napoca, Romania, 25–29 May 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Kim, J.; Sullivan, M.; Lym, S.; Erez, M. All-inclusive ECC: Thorough end-to-end protection for reliable computer memory. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 622–633. [Google Scholar] [CrossRef]
- Hwang, A.A.; Stefanovici, I.; Schroeder, B. Cosmic rays don’t strike twice: Understanding the nature of DRAM errors and the implications for system design. ACM SIGPLAN Not. 2012, 47, 111–122. [Google Scholar] [CrossRef]
- Gil-Tomás, D.; Gracia-Morán, J.; Baraza-Calvo, J.C.; Saiz-Adalid, L.J.; Gil-Vicente, P.J. Studying the effects of intermittent faults on a microcontroller. Microelectron. Reliab. 2012, 52, 2837–2846. [Google Scholar] [CrossRef]
- Cai, Y.; Yalcin, G.; Mutlu, O.; Haratsch, E.F.; Cristal, A.; Unsal, O.S.; Mai, K. Error analysis and retention-aware error management for NAND flash memory. Intel Technol. J. 2013, 17, 140–164. [Google Scholar]
- Siewiorek, D.P.; Swarz, R.S. Reliable Computer Systems: Design and Evaluation, 2nd ed.; Digital Press: Burlington, MA, USA, 1992. [Google Scholar]
- Plasma CPU Model. Available online: https://opencores.org/projects/plasma (accessed on 2 October 2020).
- Arlat, J.; Aguera, M.; Amat, L.; Crouzet, Y.; Fabre, J.C.; Laprie, J.C.; Martins, E.; Powell, D. Fault Injection for Dependability Validation: A Methodology and Some Applications. IEEE Trans. Softw. Eng. 1990, 16, 166–182. [Google Scholar] [CrossRef]
- Gil-Tomás, D.; Gracia-Morán, J.; Baraza-Calvo, J.C.; Saiz-Adalid, L.J.; Gil-Vicente, P.J. Analyzing the Impact of Intermittent Faults on Microprocessors Applying Fault Injection. IEEE Des. Test Comput. 2012, 29, 66–73. [Google Scholar] [CrossRef]
- Rashid, L.; Pattabiraman, K.; Gopalakrishnan, S. Modeling the Propagation of Intermittent Hardware Faults in Programs. In Proceedings of the 16th IEEE Pacific Rim International Symposium on Dependable Computing (PRDC 2010), Tokyo, Japan, 13–15 December 2010; pp. 19–26. [Google Scholar] [CrossRef]
- Amiri, M.; Manzoor Siddiqui, F.; Kelly, C.; Woods, R.; Rafferty, K.; ·Bardak, B. FPGA-Based Soft-Core Processors for Image Processing Applications. J. Signal Process. Syst. 2017, 87, 139–156. [Google Scholar] [CrossRef]
- Hailesellasie, M.; Rafay Hasan, S.; Ait Mohamed, O. MulMapper: Towards an Automated FPGA-Based CNN Processor Generator Based on a Dynamic Design Space Exploration. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS 2019), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Mittal, S. A survey of FPGA-based accelerators for convolutional neural networks. Neural Comput. Appl. 2020, 32, 1109–1139. [Google Scholar] [CrossRef]
- Intel Completes Acquisition of Altera. Available online: https://newsroom.intel.com/news-releases/intel-completes-acquisition-of-altera/#gs.mi6uju (accessed on 27 November 2020).
- AMD to Acquire Xilinx, Creating the Industry’s High Performance Computing Leader. Available online: https://www.amd.com/en/press-releases/2020-10-27-amd-to-acquire-xilinx-creating-the-industry-s-high-performance-computing (accessed on 27 November 2020).
- Kim, K.H.; Lawrence, T.F. Adaptive Fault Tolerance: Issues and Approaches. In Proceedings of the Second IEEE Workshop on Future Trends of Distributed Computing Systems (FTDCS 1990), Cairo, Egypt, 30 September–2 October 1990; pp. 38–46. [Google Scholar] [CrossRef]
- González, O.; Shrikumar, H.; Stankovic, J.A.; Ramamritham, K. Adaptive Fault Tolerance and Graceful Degradation under Dynamic Hard Real-time Scheduling. In Proceedings of the 18th IEEE Real-Time Systems Symposium (RTSS’97), San Francisco, CA, USA, 3–5 December 1997; pp. 79–89. [Google Scholar] [CrossRef]
- Marin, O.; Sens, P.; Briot, J.P.; Guessoum, Z. Towards Adaptive Fault Tolerance for Multi-Agent Systems. In Proceedings of the 4th European Seminar on Advanced Distributed Systems (ERSADS ’2001), Bertinoro, Italy, 14–18 May 2001; pp. 195–201. [Google Scholar]
- Wells, P.M.; Chakraborty, K.; Sohi, G.S. Adapting to Intermittent Faults in Multicore Systems. ACM SIGOPS Oper. Syst. Rev. 2008, 42, 255–264. [Google Scholar] [CrossRef]
- Nithyadharshini, P.S.; Pounambal, M.; Nagaraju, D.; Saritha, V. An adaptive fault tolerance mechanism in grid computing. ARPN J. Eng. Appl. Sci. 2018, 13, 2543–2548. [Google Scholar]
- Tamilvizhi, T.; Parvathavarthini, B. A novel method for adaptive fault tolerance during load balancing in cloud computing. Clust. Comput. 2019, 22, 10425–10438. [Google Scholar] [CrossRef]
- Jacobs, A.; George, A.D.; Cieslewski, G. Reconfigurable Fault-Tolerance: A Framework for Environmentally Adaptive Fault Mitigation in Space. In Proceedings of the 2009 19th International Conference on Field Programmable Logic and Applications (FPL), Prague, Czech Republic, 31 August–2 September 2009; pp. 199–204. [Google Scholar] [CrossRef]
- Shin, D.; Park, J.; Paul, S.; Park, J.; Bhunia, S. Adaptive ECC for tailored protection of nanoscale memory. IEEE Des. Test 2017, 34, 84–93. [Google Scholar] [CrossRef]
- Silva, F.; Muniz, A.; Silveira, J.; Marcon, C. CLC-A: An adaptive implementation of the Column Line Code (CLC) ECC. In Proceedings of the 33rd Symposium on Integrated Circuits and Systems Design (SBCCI 2020), Campinas, Brazil, 24–28 August 2020. [Google Scholar] [CrossRef]
- Mukherjee, S.S.; Emer, J.; Fossum, T.; Reinhardt, S.K. Cache scrubbing in microprocessors: Myth or necessity? In Proceedings of the 10th IEEE Pacific Rim International Symposium on Dependable Computing (PRDC 2004), Papeete, Tahiti, French Polynesia, 3–5 March 2004; pp. 37–42. [Google Scholar] [CrossRef]
- DeBrosse, J.K.; Hunter, H.C.; Kilmer, C.A.; Kim, K.-h.; Maule, W.E.; Yaari, R. Adaptive Error Correction in a Memory System. U.S. Patent US 2016/0036466 A1, 15 November 2016. [Google Scholar]
- Saleh, A.M.; Serrano, J.J.; Patel, J.H. Reliability of Scrubbing Recovery-Techniques for Memory Systems. IEEE Trans. Reliab. 1990, 39, 114–122. [Google Scholar] [CrossRef]
- Supermicro. X9SRA User’s Manual (Rev. 1.1). Available online: https://www.manualshelf.com/manual/supermicro/x9sra/user-s-manual-1-1.html (accessed on 3 October 2020).
- Chishti, Z.; Alameldeen, A.R.; Wilkerson, C.; Wu, W.; Lu, S.-L. Improving cache lifetime reliability at ultra-low voltages. In Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO-42), New York, NY, USA, 12–16 December 2009; pp. 89–99. [Google Scholar] [CrossRef]
- Datta, R.; Touba, N.A. Designing a fast and adaptive error correction scheme for increasing the lifetime of phase change memories. In Proceedings of the 2011 29th IEEE VLSI Test Symposium (VTS 2011), Dana Point, CA, USA, 1–5 May 2011; pp. 134–139. [Google Scholar] [CrossRef]
- Kim, J.-k.; Lim, J.-b.; Cho, W.-c.; Shin, K.-S.; Kim, H.; Lee, H.-J. Adaptive memory controller for high-performance multi-channel memory. J. Semicond. Technol. Sci. 2016, 16, 808–816. [Google Scholar] [CrossRef]
- Yuan, L.; Liu, H.; Jia, P.; Yang, Y. Reliability-based ECC system for adaptive protection of NAND flash memories. In Proceedings of the 2015 Fifth International Conference on Communication Systems and Network Technologies (CSNT 2015), Gwalior, India, 4–6 April 2015; pp. 897–902. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, F.; Lu, Z.; He, X.; Huang, P.; Xie, C. SCORE: A novel scheme to efficiently cache overlong ECCs in NAND flash memory. ACM Trans. Archit. Code Optim. 2018, 15, 60. [Google Scholar] [CrossRef]
- Lu, S.-K.; Li, H.-P.; Miyase, K. Adaptive ECC techniques for reliability and yield enhancement of Phase Change Memory. In Proceedings of the 2018 IEEE 24th International Symposium on On-Line Testing and Robust System Design (IOLTS 2018), Platja d’Aro, Spain, 2–4 July 2018; pp. 226–227. [Google Scholar] [CrossRef]
- Chen, J.; Andjelkovic, M.; Simevski, A.; Li, Y.; Skoncej, P.; Krstic, M. Design of SRAM-based low-cost SEU monitor for self-adaptive multiprocessing systems. In Proceedings of the 2019 22nd Euromicro Conference on Digital System Design (DSD 2019), Kallithea, Greece, 28–30 August 2019; pp. 514–521. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, L.; Chakrabarty, K. LSTM-based analysis of temporally- and spatially-correlated signatures for intermittent fault detection. In Proceedings of the 2020 IEEE 38th VLSI Test Symposium (VTS 2020), San Diego, CA, USA, 5–8 April 2020. [Google Scholar] [CrossRef]
- Ebrahimi, H.; Kerkhoff, H.G. Intermittent resistance fault detection at board level. In Proceedings of the 2018 IEEE 21st International Symposium on Design and Diagnostics of Electronic Circuits & Systems (DDECS 2018), Budapest, Hungary, 25–27 April 2018; pp. 135–140. [Google Scholar] [CrossRef]
- Ebrahimi, H.; Kerkhoff, H.G. A new monitor insertion algorithm for intermittent fault detection. In Proceedings of the 2020 IEEE European Test Symposium (ETS 2020), Tallinn, Estonia, 25–29 May 2020. [Google Scholar] [CrossRef]
- Hsiao, M.Y. A class of optimal minimum odd-weigth-column SEC-DED codes. IBM J. Res. Dev. 1970, 14, 395–401. [Google Scholar] [CrossRef]
- Gracia-Morán, J.; Saiz-Adalid, L.J.; Gil-Vicente, P.J.; Gil-Tomás, D.; Baraza-Calvo, J.C. Adaptive Mechanism to Tolerate Intermittent Faults. In Proceedings of the Fast Abstracts of the 11th European Dependable Computing Conference (EDCC 2015), Paris, France, 7–11 September 2015. [Google Scholar]
- Benso, A.; Prinetto, P. (Eds.) Fault Injection Techniques and Tools for VLSI Reliability Evaluation; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2003. [Google Scholar] [CrossRef]
- Gracia, J.; Saiz, L.J.; Baraza, J.C.; Gil, D.; Gil, P.J. Analysis of the influence of intermittent faults in a microcontroller. In Proceedings of the 2008 IEEE Workshop on Design and Diagnostics of Electronic Circuits and Systems (DDECS 2008), Bratislava, Slovakia, 16–18 April 2008; pp. 80–85. [Google Scholar] [CrossRef]
- Xilinx. ZC702 Evaluation Board for the Zynq-7000 XC7Z020 SoC. Available online: https://www.xilinx.com/support/documentation/boards_and_kits/zc702_zvik/ug850-zc702-eval-bd.pdf (accessed on 3 October 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Full Model | Mem_Ctrl | RAM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hardware | Max. Speed | Power Consumption (W) | Hardware | Hardware | |||||||
| LUTs | FFs | fmax (MHz) | Tmin (ns) | Dynamic | Static | Total | LUTs | FFs | LUTs | FFs | |
| Plasma | 1834 | 448 | 100 | 10 | 0.009 | 0106 | 0.115 | 189 | 103 | 281 | 0 |
| Plasma_SECDED | 2040 | 380 | 83.33 | 12 | 0.005 | 0103 | 0.108 | 344 | 35 | 341 | 0 |
| Plasma_ADAPTIVE (static) | 10,652 | 586 | 58.82 | 17 | 0.006 | 0103 | 0.109 | 8985 | 241 | 341 | 0 |
| Full Model | Mem_Ctrl | RAM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hardware | Max. Speed | Power Consumption (W) | Hardware | Hardware | |||||||
| LUTs | FFs | fmax (MHz) | Tmin (ns) | Dynamic | Static | Total | LUTs | FFs | LUTs | FFs | |
| Plasma | 1852 | 478 | 100 | 10 | 1.600 | 0.145 | 1.745 | 189 | 103 | 281 | 0 |
| Plasma_SECDED | 2054 | 410 | 100 | 10 | 1.573 | 0.140 | 1.713 | 344 | 35 | 341 | 0 |
| Plasma_ADAPTIVE (static) | 10,180 | 616 | 66.67 | 15 | 1.573 | 0.141 | 1.714 | 8985 | 241 | 341 | 0 |
| Plasma_ADAPTIVE (dynamic) | 2770 | 617 | 83.33 | 12 | 1.574 | 0.141 | 1.715 | - | - | 341 | 0 |
| Work | Description | Memory Type | Management Implementation | Trigger | Alternative ECCs | Same Redundancy? | Physical Reconfiguration? |
|---|---|---|---|---|---|---|---|
| [41] | Adaptive ECC for cache | SRAM | Hardware | Voltage scaling | 1-, 2-, 4-bit BCH | No | No |
| [42] | CLC with two decoding modes | Undefined | Hardware | Decoding error | CLC-S, CLC-E | Yes | No |
| [47] | Adaptive error correction scheme for cache | SRAM | Software | Voltage variation | SEC-DED, OLSC (varying data/code ratio) | No | Yes |
| [48] | Adaptive error correction scheme for PCM | PCM | Software | Number of failed cells | OLSC (varying data/code ratio) | No | Yes |
| [50] | Adaptive ECC for NAND flash | NAND-flash | Hardware | Bit error rate | Hamming, 2-, 4-bit BCH | No | No |
| Static | Static version of Plasma_ADAPTIVE | RAM | Hardware | Intermittent error | SEC-DED, EPB3932 | Yes | No |
| Dynamic | Dynamic version of Plasma_ADAPTIVE | RAM | Hardware | Intermittent error | SEC-DED, EPB3932 | Yes | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baraza-Calvo, J.-C.; Gracia-Morán, J.; Saiz-Adalid, L.-J.; Gil-Tomás, D.; Gil-Vicente, P.-J. Proposal of an Adaptive Fault Tolerance Mechanism to Tolerate Intermittent Faults in RAM. Electronics 2020, 9, 2074. https://doi.org/10.3390/electronics9122074
Baraza-Calvo J-C, Gracia-Morán J, Saiz-Adalid L-J, Gil-Tomás D, Gil-Vicente P-J. Proposal of an Adaptive Fault Tolerance Mechanism to Tolerate Intermittent Faults in RAM. Electronics. 2020; 9(12):2074. https://doi.org/10.3390/electronics9122074
Chicago/Turabian StyleBaraza-Calvo, J.-Carlos, Joaquín Gracia-Morán, Luis-J. Saiz-Adalid, Daniel Gil-Tomás, and Pedro-J. Gil-Vicente. 2020. "Proposal of an Adaptive Fault Tolerance Mechanism to Tolerate Intermittent Faults in RAM" Electronics 9, no. 12: 2074. https://doi.org/10.3390/electronics9122074
APA StyleBaraza-Calvo, J.-C., Gracia-Morán, J., Saiz-Adalid, L.-J., Gil-Tomás, D., & Gil-Vicente, P.-J. (2020). Proposal of an Adaptive Fault Tolerance Mechanism to Tolerate Intermittent Faults in RAM. Electronics, 9(12), 2074. https://doi.org/10.3390/electronics9122074