Does Deep Learning Work Well for Categorical Datasets with Mainly Nominal Attributes?

Abstract
1. Introduction
1.1. Background
1.2. Types of Data Attributes
1.3. Heterogeneous Datasets
1.4. Deep Learning (DL) Approaches for Datasets with Ordinal Attributes
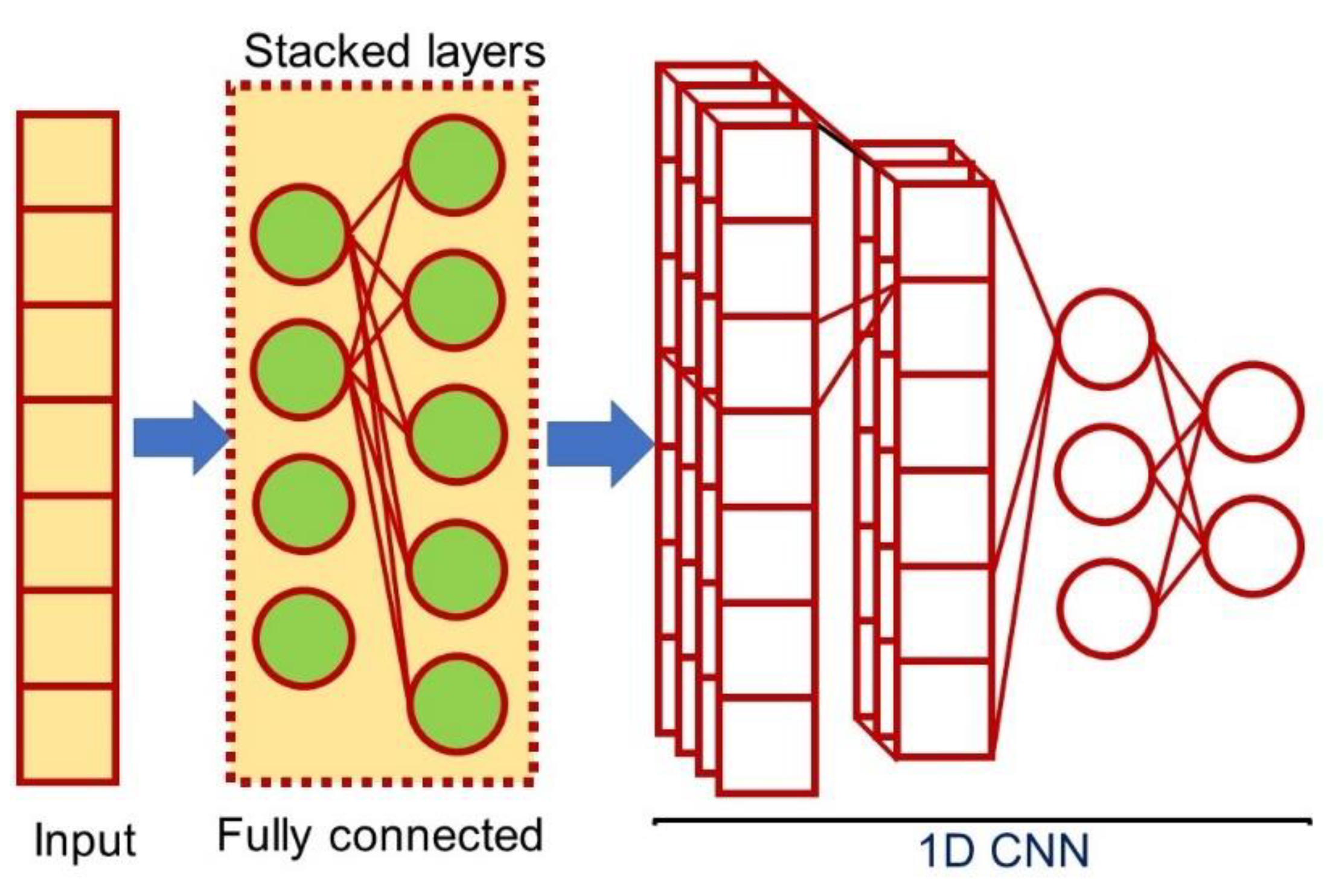
1.5. State-of-the-Art DL Classifiers for Categorical and Mixed Datasets
1.6. Novelty of This Paper
2. Categorical Datasets and Their Recent High Accuracies
2.1. The Wisconsin Breast Cancer Dataset (WBCD) and Classification Accuracies
2.1.1. The Wisconsin Breast Cancer Dataset (WBCD)
2.1.2. Recent High Accuracies by Classifiers for the WBCD
2.2. Credit Scoring Datasets
2.2.1. German (-Categorical) Dataset
2.2.2. Recent High-Accuracy Classifiers for the German Dataset
2.2.3. Australian Dataset
3. Discussion
3.1. Discussion
3.2. A Black-Box ML Approach to Achieve Very High Accuracies for the German (-Numerical) Credit Dataset
3.3. Pitfalls for Handling Nominal Attributes to Design High-performance Classifiers
4. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Notations
| TS ACC | Test accuracy |
| 10CV | 10-fold cross-validation |
Abbreviations
| CNN | Convolutional neural network |
| 1D | One-dimensional |
| FCLF | Fully-connected layer first |
| Re-RX | Recursive-rule eXtraction |
| SVM | Support vector machine |
| DL | Deep learning |
| NN | Neural network |
| DNN | Deep neural network |
| ML | Machine learning |
| BPNN | Backpropagation neural network |
| CV | Cross-validation |
| AUC-ROC | Area under the receiver operating characteristic curve |
| SMOTE | Synthetic minority oversampling technique |
| DBN | Deep belief network |
| PSO | Particle swarm optimization |
| ERENN-MHL | Electric rule extraction from a neural network with a multi-hidden layer for a DNN |
| ABC | Artificial bee colony |
| RF | Random forest |
| ELM | Extreme learning machine |
References
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems 2; Touretzky, D.S., Ed.; MIT Press: Cambridge, MA, USA, 1989; pp. 396–404. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wolpert, D. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Wolpert, D.H. The existence of a prior distinctions between learning algorithms. Neural Comput. 1996, 8, 1391–1420. [Google Scholar] [CrossRef]
- Gŏmez, D.; Rojas, A. An empirical overview of the no free lunch theorem and its effect on real-world machine learning classification. Neural Comput. 2016, 28, 216–228. [Google Scholar] [CrossRef] [PubMed]
- Liang, Q.; Wang, K. Distributed outlier detection in hierarchically structured datasets with mixed attributes. Qual. Technol. Quant. Manag. 2019, 17, 337–353. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J.; Solanas, A. A measure of variance for hierarchical nominal attributes. Inf. Sci. 2008, 178, 4644–4655. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheung, Y.-M.; Tan, K.C. A Unified Entropy-Based Distance Metric for Ordinal-and-Nominal-Attribute Data Clustering. IEEE Trans. Neural Networks Learn. Syst. 2020, 31, 39–52. [Google Scholar] [CrossRef]
- Tripathi, D.; Edla, D.R.; Cheruku, R. Hybrid credit scoring model using neighborhood rough set and multi-layer ensemble classification. J. Intell. Fuzzy Syst. 2018, 34, 1543–1549. [Google Scholar] [CrossRef]
- Hsu, F.-J.; Chen, M.-Y.; Chen, Y.-C. The human-like intelligence with bio-inspired computing approach for credit ratings prediction. Neurocomputing 2018, 279, 11–18. [Google Scholar] [CrossRef]
- Arora, N.; Kaur, P.D. A Bolasso based consistent feature selection enabled random forest classification algorithm: An application to credit risk assessment. Appl. Soft Comput. 2020, 86, 105936. [Google Scholar] [CrossRef]
- Jadhav, S.; He, H.; Jenkins, K. Information gain directed genetic algorithm wrapper feature selection for credit rating. Appl. Soft Comput. 2018, 69, 541–553. [Google Scholar] [CrossRef]
- Shen, F.; Zhao, X.; Li, Z.; Li, K.; Meng, Z. A novel ensemble classification model based on neural networks and a classifier optimisation technique for imbalanced credit risk evaluation. Phys. A: Stat. Mech. Its Appl. 2019, 526, 121073. [Google Scholar] [CrossRef]
- Bequé, A.; Lessmann, S. Extreme learning machines for credit scoring: An empirical evaluation. Expert Syst. Appl. 2017, 86, 42–53. [Google Scholar] [CrossRef]
- Hayashi, Y. Use of a Deep Belief Network for Small High-Level Abstraction Data Sets Using Artificial Intelligence with Rule Extraction. Neural Comput. 2018, 30, 3309–3326. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Setiono, R.; Baesens, B.; Mues, C. Recursive Neural Network Rule Extraction for Data with Mixed Attributes. IEEE Trans. Neural Networks 2008, 19, 299–307. [Google Scholar] [CrossRef]
- Hayashi, Y.; Nakano, S. Use of a recursive-rule extraction algorithm with J48graft to archive highly accurate and concise rule extraction from a large breast cancer dataset. Inform. Med. Unlocked 2015, 1, 9–16. [Google Scholar] [CrossRef]
- Webb, G.I. Decision tree grafting from the all-tests-but-one partition. In Proceedings of the 16th International Joint Conference on Artificial Intelligence; Morgan Kaufmann, San Mateo, CA, USA; 1999; pp. 702–707. [Google Scholar]
- Gűlçehre, C.; Bengio, Y. Knowledge matters: Importance of prior information for optimization. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Abdel-Zaher, A.M.; Eldeib, A.M. Breast cancer classification using deep belief networks. Expert Syst. Appl. 2016, 46, 139–144. [Google Scholar] [CrossRef]
- Liu, K.; Kang, G.; Zhang, N.; Hou, B. Breast Cancer Classification Based on Fully-Connected Layer First Convolutional Neural Networks. IEEE Access 2018, 6, 23722–23732. [Google Scholar] [CrossRef]
- Karthik, S.; Perumal, R.S.; Mouli, P.V.S.S.R.C. Breast Cancer Classification Using Deep Neural Networks. In Knowledge Computing and Its Applications; Anouncia, S.M., Wiil, U.K., Eds.; Springer: New York, NY, USA, 2018; pp. 227–241. [Google Scholar]
- Pławiak, P.; Abdar, M.; Acharya, U.R. Application of new deep genetic cascade ensemble of SVM classifiers to predict the Australian credit scoring. Appl. Soft Comput. 2019, 84, 105740. [Google Scholar] [CrossRef]
- Hayashi, Y.; Takano, N. One-Dimensional Convolutional Neural Networks with Feature Selection for Highly Concise Rule Extraction from Credit Scoring Datasets with Heterogeneous Attributes. Electronics 2020, 9, 1318. [Google Scholar] [CrossRef]
- Salzberg, S.L. On Comparing Classifiers: Pitfalls to Avoid and a Recommended Approach. Data Min. Knowl. Discov. 1997, 1, 317–328. [Google Scholar] [CrossRef]
- Carrington, A.; Fieguth, P.W.; Qazi, H.; Holzinger, A.; Chen, H.; Mayr, F.; Douglas, G.; Manuel, D. A new concordant partial AUC and partial c statistic for imbalanced data in the evaluation of machine learning algorithms. BMC Med Informatics Decis. Mak. 2020, 20, 4–12. [Google Scholar] [CrossRef]
- Manfrin, E.; Mariotto, R.; Remo, A.; Reghellin, D.; Dalfior, D.; Falsirollo, F.; Bonetti, F. Is there still a role for fine-needle aspiration cytology in breast cancer screening? Cancer 2008, 114, 74–82. [Google Scholar] [CrossRef]
- Fogliatto, F.S.; Anzanello, M.J.; Soares, F.; Brust-Renck, P.G. Decision Support for Breast Cancer Detection: Classification Improvement Through Feature Selection. Cancer Control. 2019, 26, 1–8. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Feng, J. Deep forest: Towards an alternative to deep neural networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3553–3559. [Google Scholar]
- Zhou, Z.-H.; Feng, J. Deep forest. Natl. Sci. Rev. 2019, 6, 74–86. [Google Scholar] [CrossRef]
- Onan, A. A fuzzy-rough nearest neighbor classifier combined with consistency-based subset evaluation and instance selection for automated diagnosis of breast cancer. Expert Syst. Appl. 2015, 42, 6844–6852. [Google Scholar] [CrossRef]
- Chen, H.-L.; Yang, B.; Wang, G.; Wang, S.-J.; Liu, J.; Liu, D.-Y. Support Vector Machine Based Diagnostic System for Breast Cancer Using Swarm Intelligence. J. Med Syst. 2012, 36, 2505–2519. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Tiwari, A. Breast cancer diagnosis using Genetically Optimized Neural Network model. Expert Syst. Appl. 2015, 42, 4611–4620. [Google Scholar] [CrossRef]
- Dora, L.; Agrawal, S.; Panda, R.; Abraham, A. Optimal breast cancer classification using Gauss–Newton representation based algorithm. Expert Syst. Appl. 2017, 85, 134–145. [Google Scholar] [CrossRef]
- Duch, W.; Adamczak, R.; Grąbczewski, K.; Jankowski, N. Neural methods of knowledge extraction. Control Cybern. 2000, 29, 997–1017. [Google Scholar]
- Latchoumi, T.P.; Ezhilarasi, T.P.; Balamurugan, K. Bio-inspired weighed quantum particle swarm optimization and smooth support vector machine ensembles for identification of abnormalities in medical data. SN Appl. Sci. 2019, 1, 1137. [Google Scholar] [CrossRef]
- Tripathi, D.; Edla, D.R.; Cheruku, R.; Kuppili, V. A novel hybrid credit scoring model based on ensemble feature selection and multilayer ensemble classification. Comput. Intell. 2019, 35, 371–394. [Google Scholar] [CrossRef]
- Kuppili, V.; Tripathi, D.; Edla, D.R. Credit score classification using spiking extreme learning machine. Comput. Intell. 2020, 36, 402–426. [Google Scholar] [CrossRef]
- Tai, L.Q.; Vietnam, V.B.A.O.; Huyen, G.T.T. Deep Learning Techniques for Credit Scoring. J. Econ. Bus. Manag. 2019, 7, 93–96. [Google Scholar] [CrossRef]
- Hayashi, Y.; Oishi, T. High Accuracy-priority Rule Extraction for Reconciling Accuracy and Interpretability in Credit Scoring. New Gener. Comput. 2018, 36, 393–418. [Google Scholar] [CrossRef]
- Liu, P.J.; McFerran, B.; Haws, K.L. Mindful Matching: Ordinal Versus Nominal Attributes. J. Mark. Res. 2019, 57, 134–155. [Google Scholar] [CrossRef]
- Baesens, B.; Setiono, R.; Mues, C.; Vanthienen, J. Using Neural Network Rule Extraction and Decision Tables for Credit-Risk Evaluation. Manag. Sci. 2003, 49, 312–329. [Google Scholar] [CrossRef]
- Pławiak, P.; Abdar, M.; Pławiak, J.; Makarenkov, V.; Acharya, U.R. DGHNL: A new deep genetic hierarchical network of learners for prediction of credit scoring. Inf. Sci. 2020, 516, 401–418. [Google Scholar] [CrossRef]
- Hayashi, Y. The Right Direction Needed to Develop White-Box Deep Learning in Radiology, Pathology, and Ophthalmology: A Short Review. Front. Robot. AI 2019, 6. [Google Scholar] [CrossRef]


{kind=link}
| Dataset | # Instances | # Total Features | Categorical Nominal | Categorical Ordinal | Numerical |
|---|---|---|---|---|---|
| WBCD | 699 | 9 | 0 | 9 | 0 |
| German | 1000 | 20 | 10 | 3 | 7 |
| Australian | 690 | 14 | 0 | 8 | 6 |
| Method | TS ACC (%) | AUC-ROC | Year |
|---|---|---|---|
| Fuzzy-rough nearest neighbor with instance feature selection [10CV] [33] | 99.71 | 1.000 | 2015 |
| DBN-NN [22] | 99.68 | ---- | 2016 |
| Particle Swarm Optimization (PSO)_SVM [10CV] [34] | 99.30 | 0.993 | 2012 |
| Genetically Optimized Neural Network (GONN) [10CV] [35] | 99.26 | 1.000 | 2015 |
| Gauss-Newton Representation-based Algorithm [10CV] [36] | 99.23 | 0.997 | 2017 |
| C-MLP2LN [10CV] [37] | 99.00 | ---- | 2000 |
| Ensemble of 1D FCLF-CNN [10CV] [23] | 98.71 | ---- | 2018 |
| Deep neural network (DNN) and recursive feature elimination (RFE) [80:20 split] [24] | 98.62 | ---- | 2018 |
| Bio-inspired weighted quantum swarm optimization and SVM ensemble [10CV] [38] | 98.70 | ---- | 2019 |
| Deep Forest [10CV] [31,32] | 95.52 1 | ---- | 2020 |
| Method | TS ACC (%) | AUC-ROC (%) | Year |
|---|---|---|---|
| Neighborhood rough set + multi-layer ensemble classification [10CV] [10] | 86.57 | ---- | 2018 |
| Artificial bee-colony based SVM [10CV] [11] | 84.00 | ---- | 2018 |
| Bolasso based feature selection + random forest [10CV] [12] | 84.00 | 0.713 | 2020 |
| Information Gain Directed Feature Selection algorithm [10CV] [13] | 82.80 | 0.753 | 2018 |
| SMOTE-based ensemble method [10CV] [14] | 78.70 | 0.810 | 2019 |
| Extreme Learning Machine [10CV] [15] | 76.40 | 0.801 | 2017 |
| 1D FCLF-CNN [10CV] [23] | 74.70 2 [25] | 0.697 2 [25] | 2018 |
| Deep Forest [10CV] [31,32] | 71.12 1 | ---- | 2017 |
| Dataset | German | Australian |
|---|---|---|
| Pruning stop rate for 1D FCLF-CNN | 0.13 | 0.20 |
| # of first layer hidden units for 1D FCLF-CNN | 4 | 3 |
| Learning rate for 1D FCLF-CNN | 0.0182 | 0.0106 |
| Momentum factor for 1D FCLF-CNN | 0.1154 | 0.7549 |
| # of filters in each branch in the inception module | 19 | 8 |
| # of channels after concatenation | 57 | 24 |
| Method | TS ACC (%) | AUC-ROC (%) | Year |
|---|---|---|---|
| Deep Genetic Cascade Ensemble of SVM classifier [10CV] [25] | 97.39 | ---- | 2019 |
| Spiking extreme learning machine [10CV] [40] | 95.98 | 0.970 | 2019 |
| Artificial bee colony-based SVM [10CV] [11] | 92.75 | ---- | 2018 |
| Ensemble feature selection + multilayer ensemble classification [100 × 10CV] [39] | 92.69 | ---- | 2019 |
| DNN (sequential neural network, convolution neural network) [10CV] [41] | 87.54 | ---- | 2019 |
| 1D FCLF-CNN [10CV] [23] | 85.80 1 [25] | 0.859 [25] | 2018 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hayashi, Y. Does Deep Learning Work Well for Categorical Datasets with Mainly Nominal Attributes? Electronics 2020, 9, 1966. https://doi.org/10.3390/electronics9111966
Hayashi Y. Does Deep Learning Work Well for Categorical Datasets with Mainly Nominal Attributes? Electronics. 2020; 9(11):1966. https://doi.org/10.3390/electronics9111966
Chicago/Turabian StyleHayashi, Yoichi. 2020. "Does Deep Learning Work Well for Categorical Datasets with Mainly Nominal Attributes?" Electronics 9, no. 11: 1966. https://doi.org/10.3390/electronics9111966
APA StyleHayashi, Y. (2020). Does Deep Learning Work Well for Categorical Datasets with Mainly Nominal Attributes? Electronics, 9(11), 1966. https://doi.org/10.3390/electronics9111966