Deep architecture generation is a challenging task, since related studies [
1,
2,
4,
20] tend to create search spaces that are immense and feasibly impossible to properly navigate without a huge amount of resources for parallelisation. In this research, we approach the problem differently by proposing novel weight inheritance schemes, a DenseBlock skeleton architecture, as well as an adaptive cosine oriented PSO search mechanism to balance between devising versatile architectures and maintaining optimal training costs. In addition, we devise the skeleton architecture by considering more recent developments in the world of CNN design. Specifically, we employ the concept of residual or skip connections [
21], as well as the concept of dense connectivity [
22], in order to create architectures from a set of parameters with a much wider variety of structural variations. Using our DenseBlock skeleton architecture, we obtain a search process to include a total of
potential architectures, where
K represents the denormalised range of the growth rate (
k), while
D represents the denormalised range of the depth (number of internal layers) of each dense block, and
i represents the number of dense blocks. Such a potentially large search space provides a vastly more difficult task, albeit with the benefit of greater oautonomyn the part of the optimisation process. To significantly reduce computational costs and effectively explore the search space, two weight inheritance strategies, i.e., the BLSK-NS and BLSK-S methods, are proposed for the joint optimisation and training of the CNN architectures. These weight inheritance strategies purely rely on the parameters of the individual layers in the CNN architecture, meaning they can be used with any CNN construction method, rather than being tied to the optimisation process itself. Two ensemble models are subsequently built based on the optimised deep networks with dense connectivity to further enhance performance. We introduce each key proposed strategy comprehensively below.
Model Construction
Similar to the VGG networks, a typical DenseNet CNN model for image classification is constructed as a hierarchical graph of convolutional, batch normalisation, ReLU activation, and average pooling layers, followed by a final fully connected classification layer and a Softmax output layer. However, whilst the VGG models attach the output of a layer only with the next contiguous layer, DenseNets build up a ‘global state’ by connecting the output of a layer with all of the subsequent layers. This global state takes the form of a stack of feature maps, where the output of a layer is simply concatenated onto the stack following its processing of the previous global state. Constructing the network in this way allows the features from earlier in the network to persist for longer in the network hierarchy, rather than being repeatedly reprocessed by the intermediate layers and losing entropy.
Moreover, in the proposed DenseBlock skeleton architecture, as many existing studies [
3,
5,
15], we employ the concept of blocks separated by spatial downsampling layers, in order to reduce the spatial size of the feature maps and increase the receptive field size of the subsequent layers. However, we achieve this by using the DenseNet concept of the ‘growth rate’ (
k), which defines the number of feature maps that each new layer can concatenate onto the global state matrix. The growth rate is also used to determine the maximum size of the global state, as an excessive growth rate can result in drastically reduced performance. In our experiments, we set the maximum size of the global state as
, based on the recommendation of [
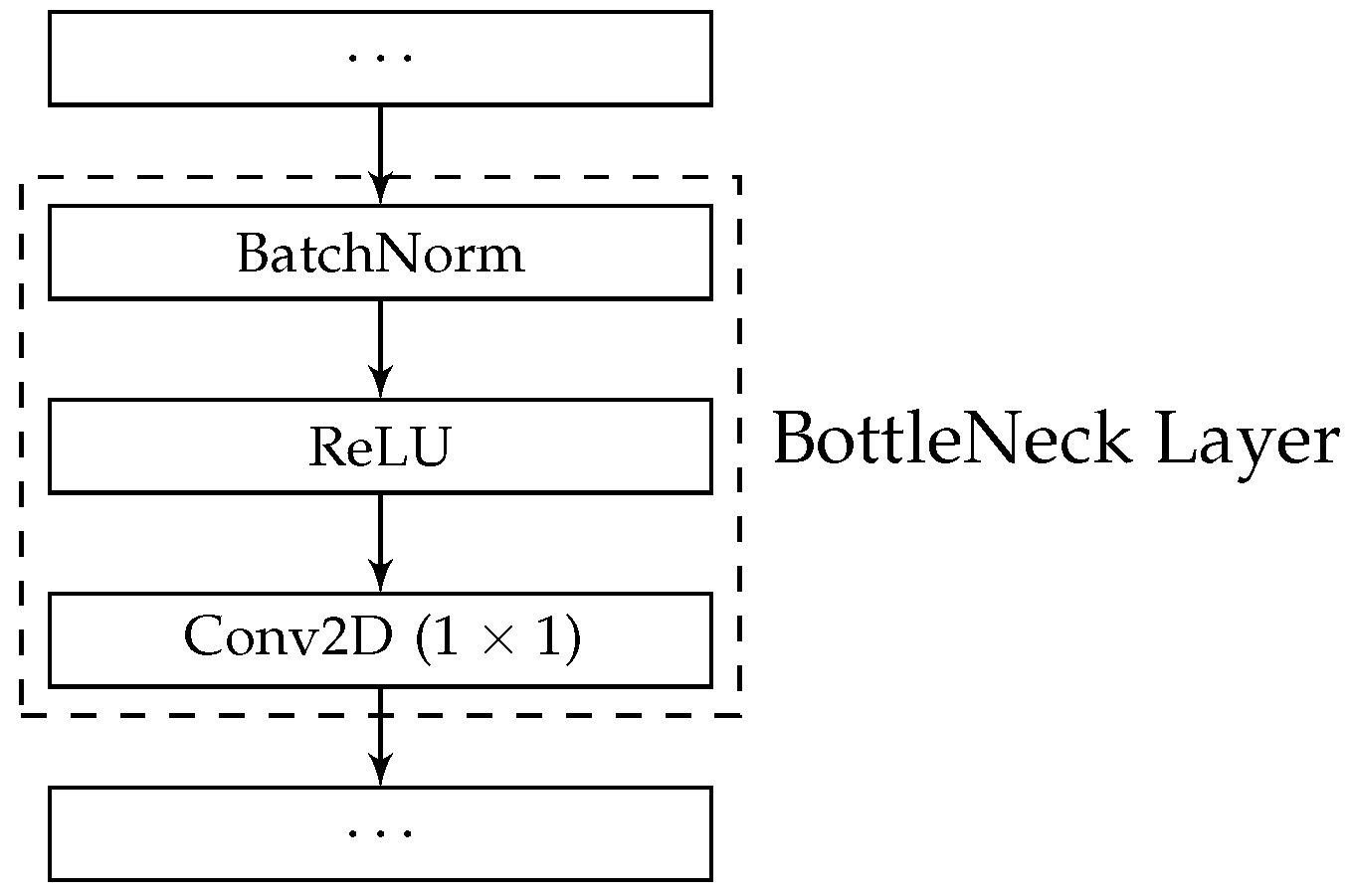
22]. This maximum size is maintained through the use of BottleNeck Layers consisting of a batch normalisation layer, followed by a ReLU activation and a
convolution mapping the number of input features to the maximum global state size. A visualisation of a BottleNeck Layer can be seen in
Figure 1.
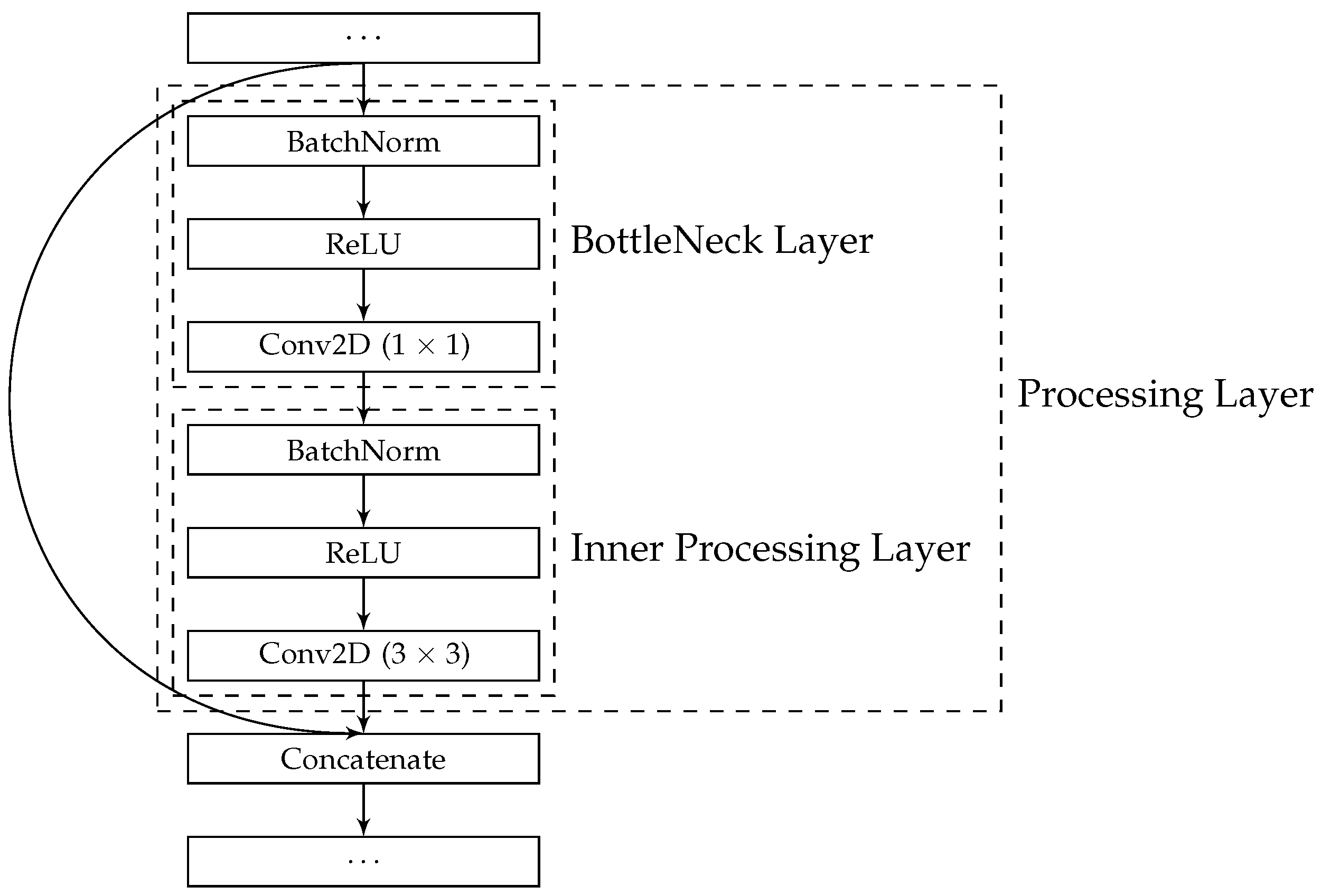
As compared with related studies, including a BottleNeck layer before every convolution creates a fundamental change in structure, resulting in a definition of Processing Layers that are stacked within the blocks of our resulting architectures.
Figure 2 depicts the Processing Layer definition, which consists of a sequence of actual component layers, i.e., batch normalisation, ReLU Activation,
convolution, batch normalisation, ReLU Activation, and finally a
convolution to form the bulk of the processing.
One effect of the number of feature maps produced and processed by the Processing Layers is that the parameter matrices do not grow to enormous sizes. This allows for us to construct much deeper networks by stacking many more Processing Layers in each block, without running out of GPU memory in the process. Due to the dense connections that are inherent in the SODBAE skeleton architecture, we also do not suffer from the vanishing entropy problem commonly seen when drastically increasing the depth of a CNN. Moreover, the optimization process enables each processing layer to always add the identified optimal (e.g.,
k) number of feature maps to the global state. We do not enforce any constraints when adding the number of feature maps that are recommended by the optimization process. The maximum number of feature maps in the global state is maintained by the bottleneck layers, as illustrated in
Figure 1. Each bottleneck layer uses a 1 × 1 convolution to map the number of input features to the maximum size of the global state, after adding each set of new feature maps from each processing layer.
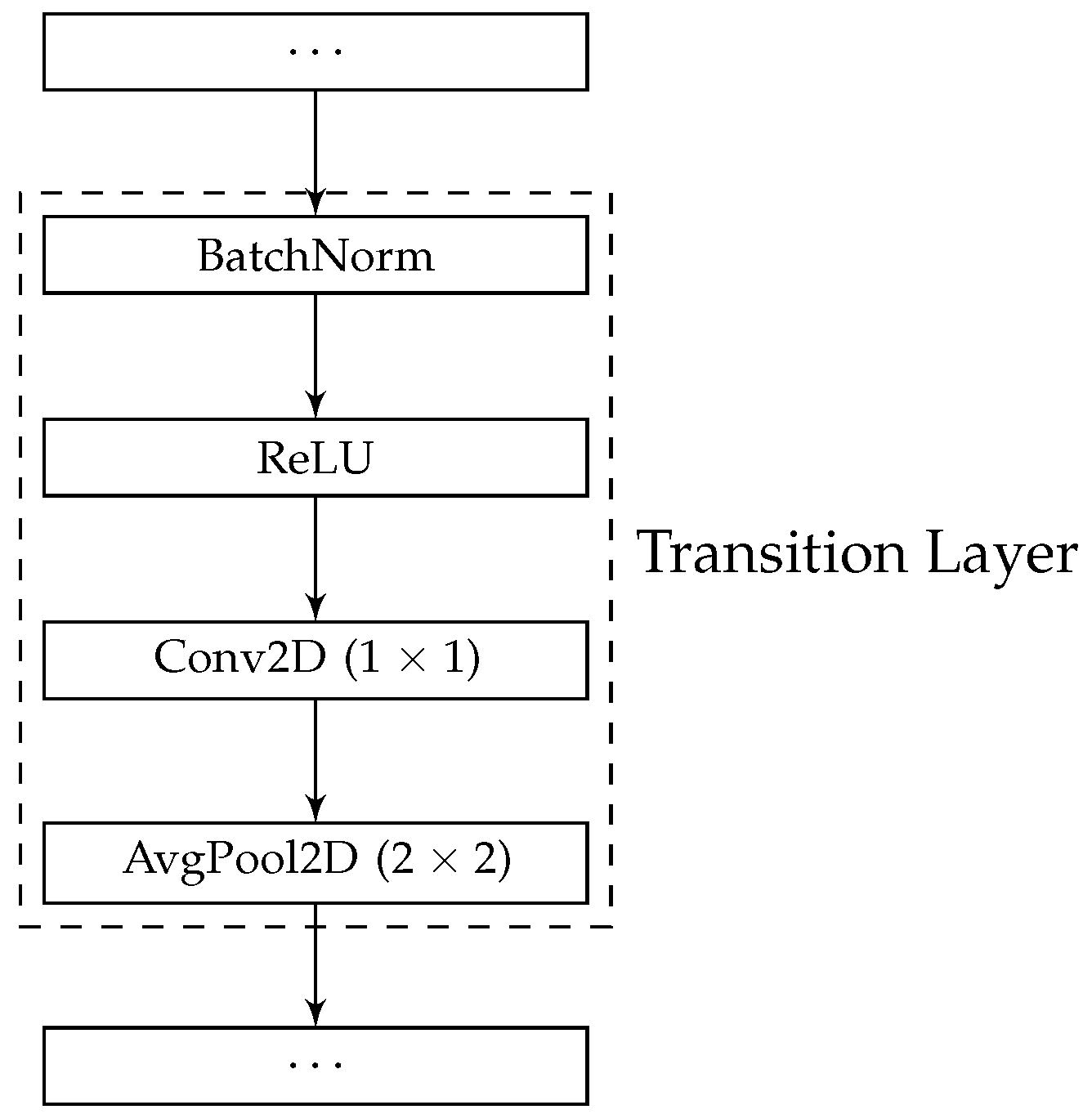
As previously mentioned, in order to periodically reduce the spatial size of the internal feature maps, and increase the receptive field size of later Processing Layers, we implement spatial downsampling between the blocks in the SODBAE skeleton architecture. The spatial downsampling is performed by Transition Layers, rather than simply a single average pooling layer as in many existing studies. Transition Layers, as seen in [
22], consist of a batch normalisation layer, followed by a ReLU activation, a
convolution, and finally an average pooling layer in order to perform the actual spatial downsampling. A visualisation of a Transition Layer can be seen in
Figure 3.
In the proposed model, we construct a SODBAE skeleton architecture by defining a number of design choices as parameters to an objective function, where the objective function can then use the parameters with the skeleton architecture in order to construct a full CNN model. The objective function used by the SODBAE method can be seen in Algorithm 1. For the model initialisation process, the skeleton architecture design choices we choose to optimise include:
The growth rate (k)
The depth (No. of layers) of the first DenseBlock ()
The depth (No. of layers) of the second DenseBlock ()
The depth (No. of layers) of the third DenseBlock ()
The depth (No. of layers) of the fourth DenseBlock ()
| Algorithm 1 The objective function to be optimised. |
- 1:
functionObjectiveFunction(): - 2:
model ← InitModel(position) - 3:
if weight_sharing then - 4:
model.weights ← InheritWeights(model) - 5:
end if - 6:
Train(model) - 7:
error_rate ← Validate(model) - 8:
if weight_sharing then - 9:
StoreWeights(model, error_rate) - 10:
end if - 11:
return (error_rate/100) - 12:
end function
|
We use ranges of
giving
for the growth rate and
giving
for the depth of each dense block, with a total number of blocks of
. This means that each dense block will consist of between 0 and 48 Processing Layers, with each Processing Layer adding between 1 and 48 feature maps to the global state, which will contain a range of 4 to 192 feature maps at a time. Being motivated by [
22], we simply use a single fully connected layer, followed by a Softmax layer to perform the final predictions. As with the earlier reduction in feature maps, this again saves GPU memory, allowing for us to construct deeper models with more convolutional processing.
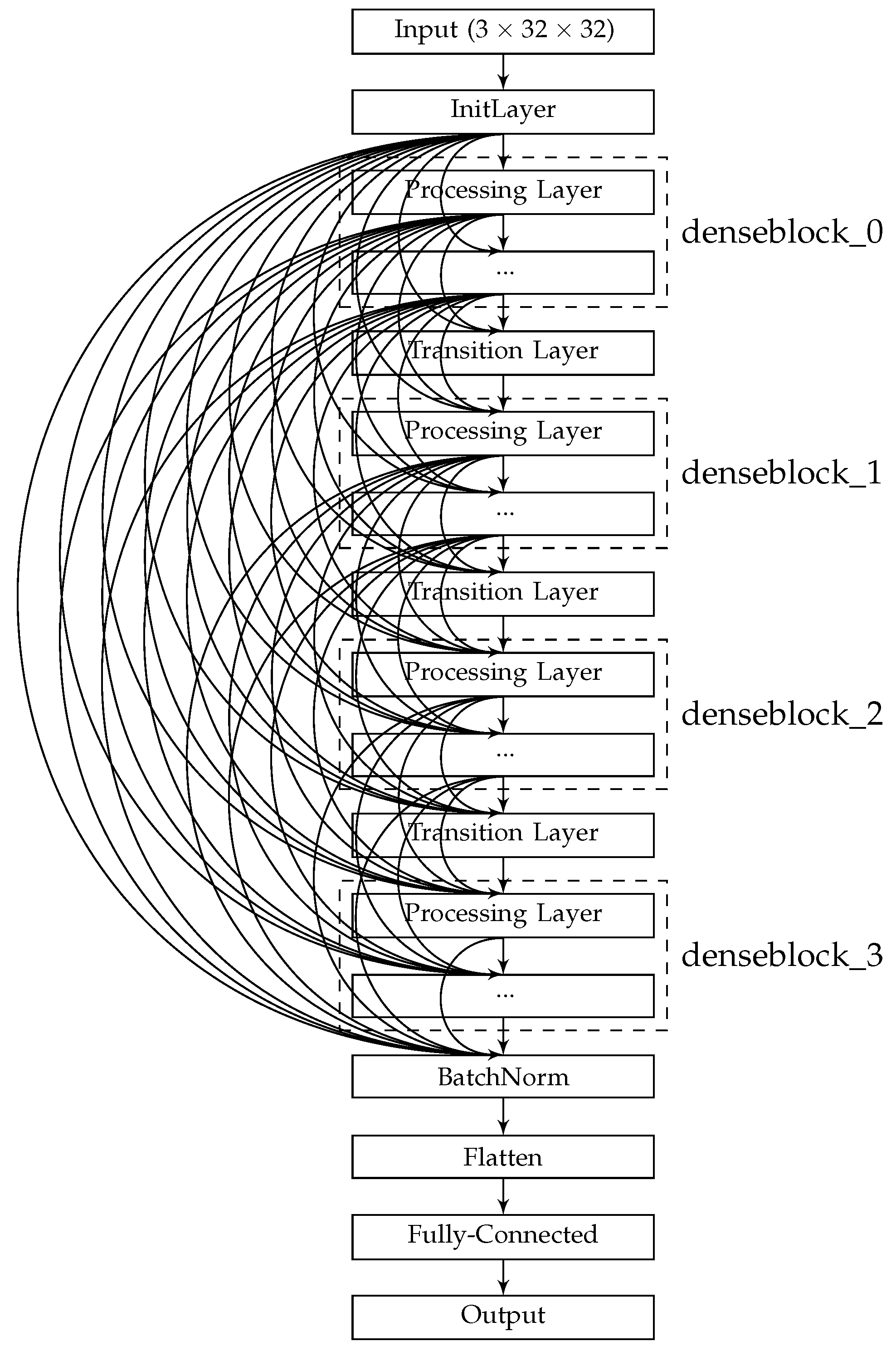
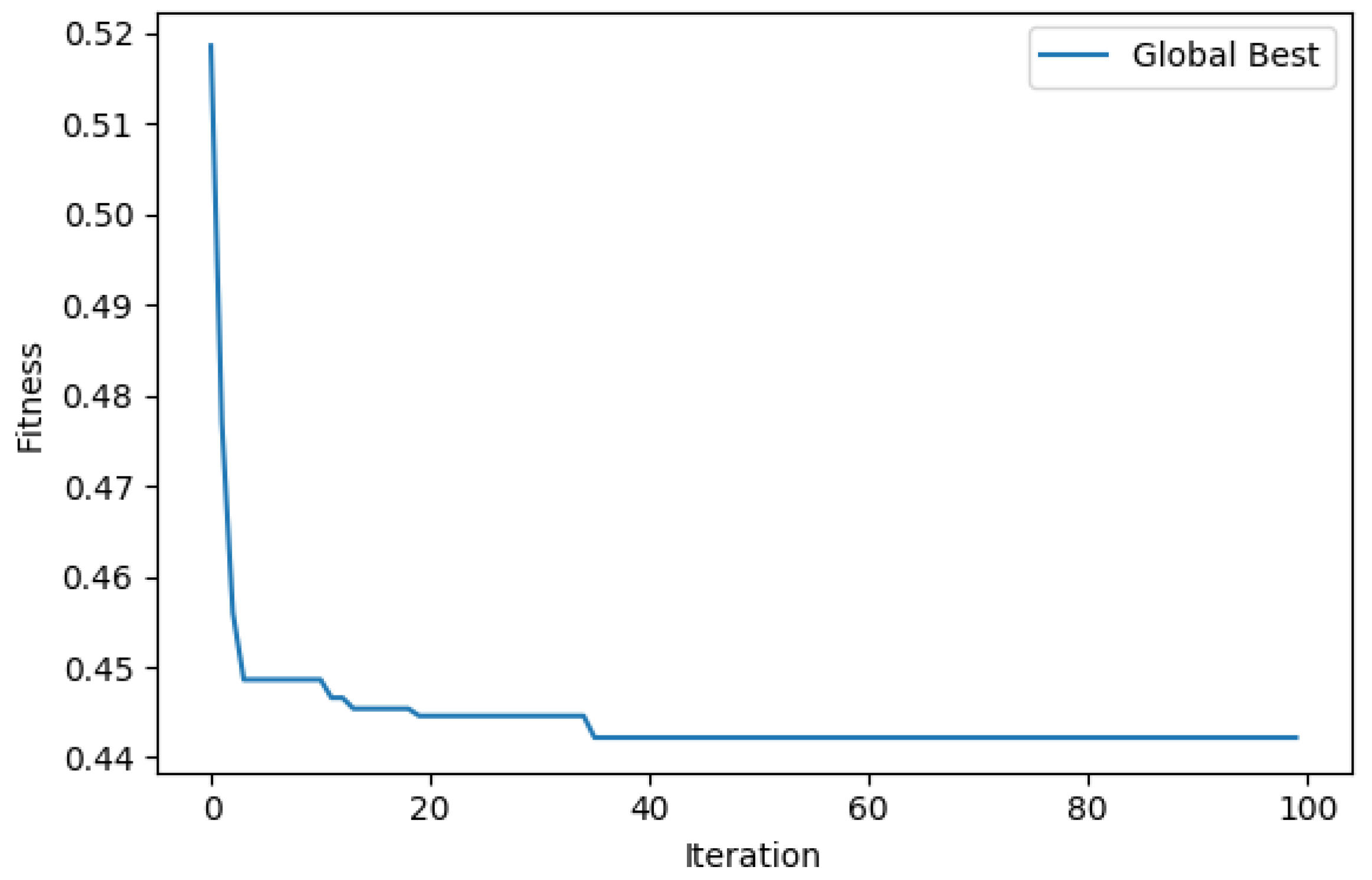
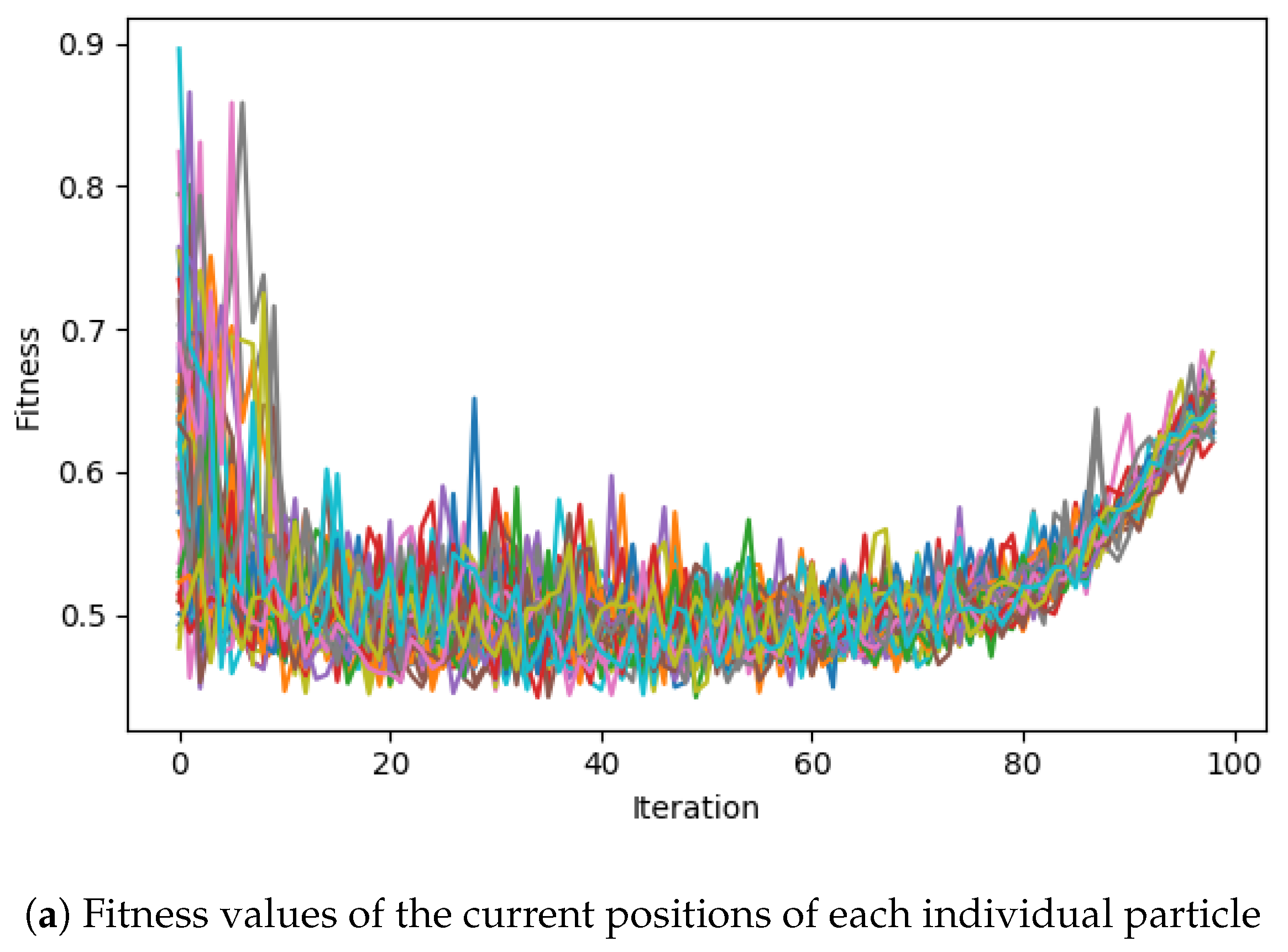
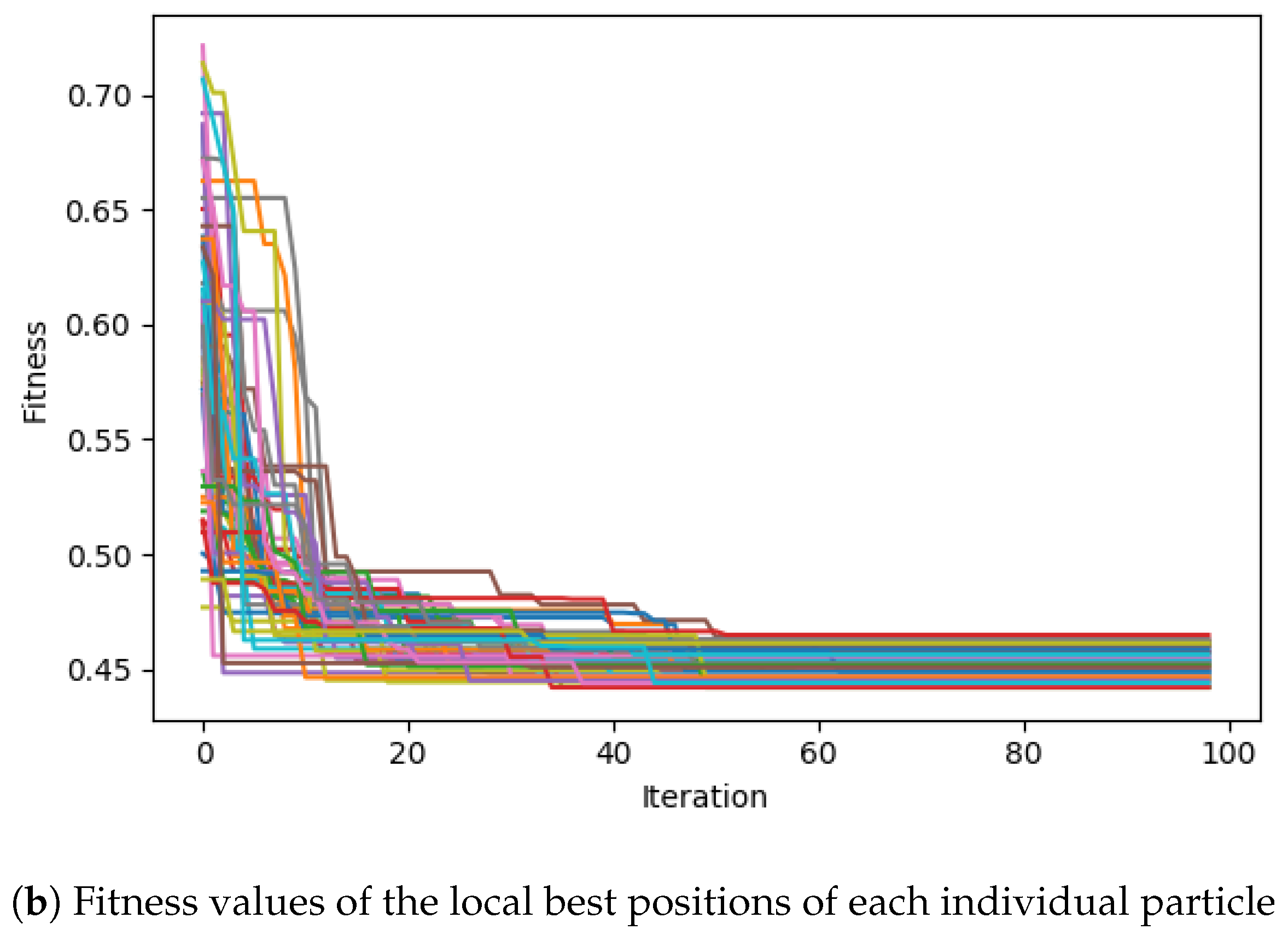
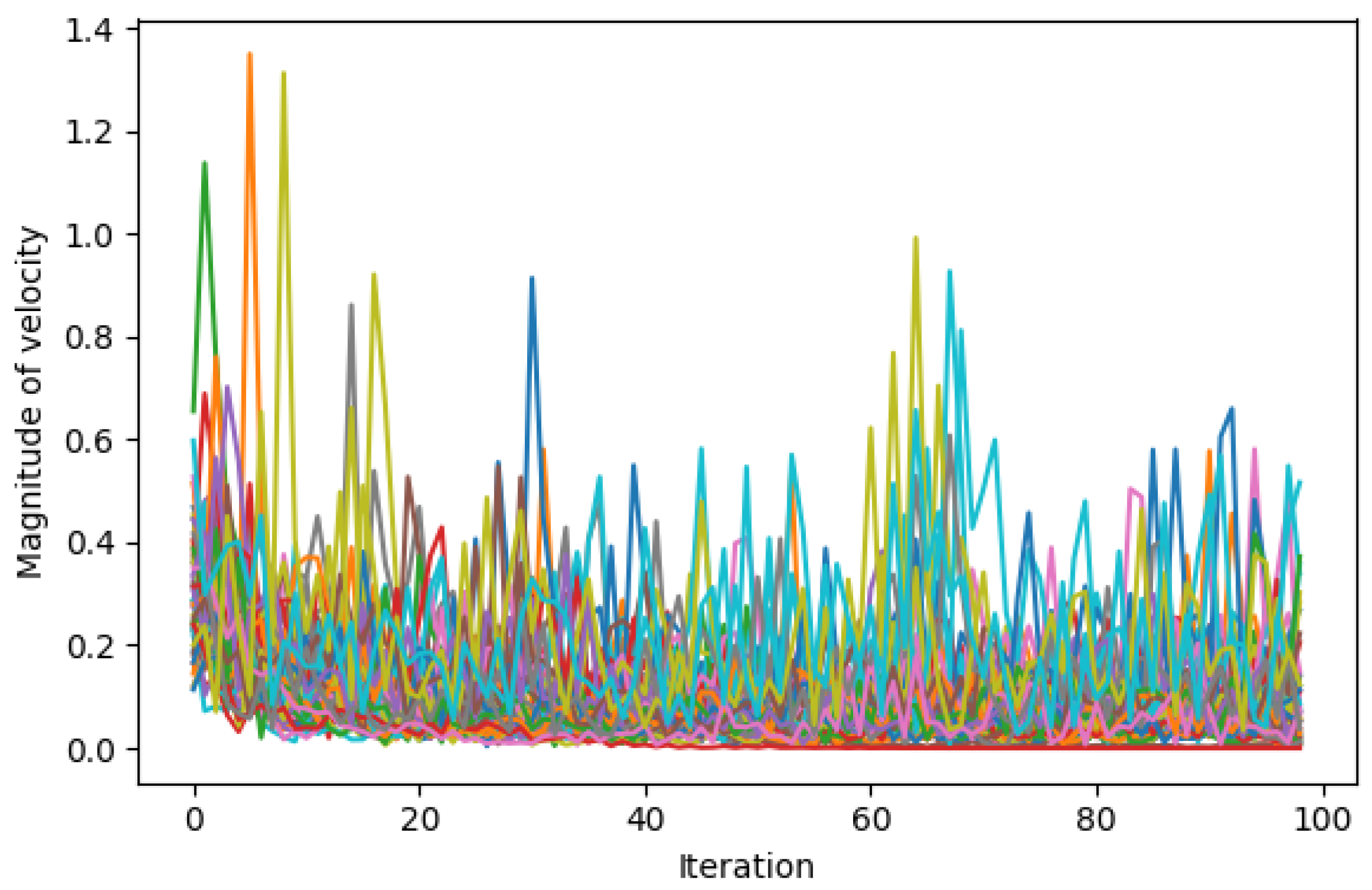
Table 1 shows the parameters of the DenseBlock skeleton architecture to be optimised, leading to the total distinct architecture variants of
. The skeleton architecture of the resulting CNN is visualised in
Figure 4, where the Processing Layer refers to an encompassing SODBAE Processing Layer, as depicted in
Figure 2 and Transition Layer refers to the one, as depicted in
Figure 3. The ellipses in the visualisations represent the repeating layers in the respective blocks, where the dense connections will continue between the repeated layers and all subsequent layers, potentially creating very deep, very densely connected architectures. It is important to note that, whilst the dense connections are shown throughout the network, in actual processing this is represented as a global state that passes linearly through the network, allowing for the spatial size of the feature maps inside to be downsampled by the Transition Layers.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}