Deep Learning of Appearance Affinity for Multi-Object Tracking and Re-Identification: A Comparative View




Abstract
1. Introduction
- Implementation of a neural model to measure the Appearance Affinity between observations for addressing both, the MOT, and the Re-Id problem.
- Study of the differences in data constraints derived from the specifications of each task, MOT, and Re-Id.
- Formulation and implementation of mini-batch learning algorithms to train a base network (concretely with a VGG architecture) under the Siamese and the Triplet model.
- Comparative analysis of the effects of imposing the Double-Margin-Contrastive Loss and the Triplet Loss constrains over the MOT and the Re-Id data.
2. Appearance Affinity Learning
2.1. Base Neural Network
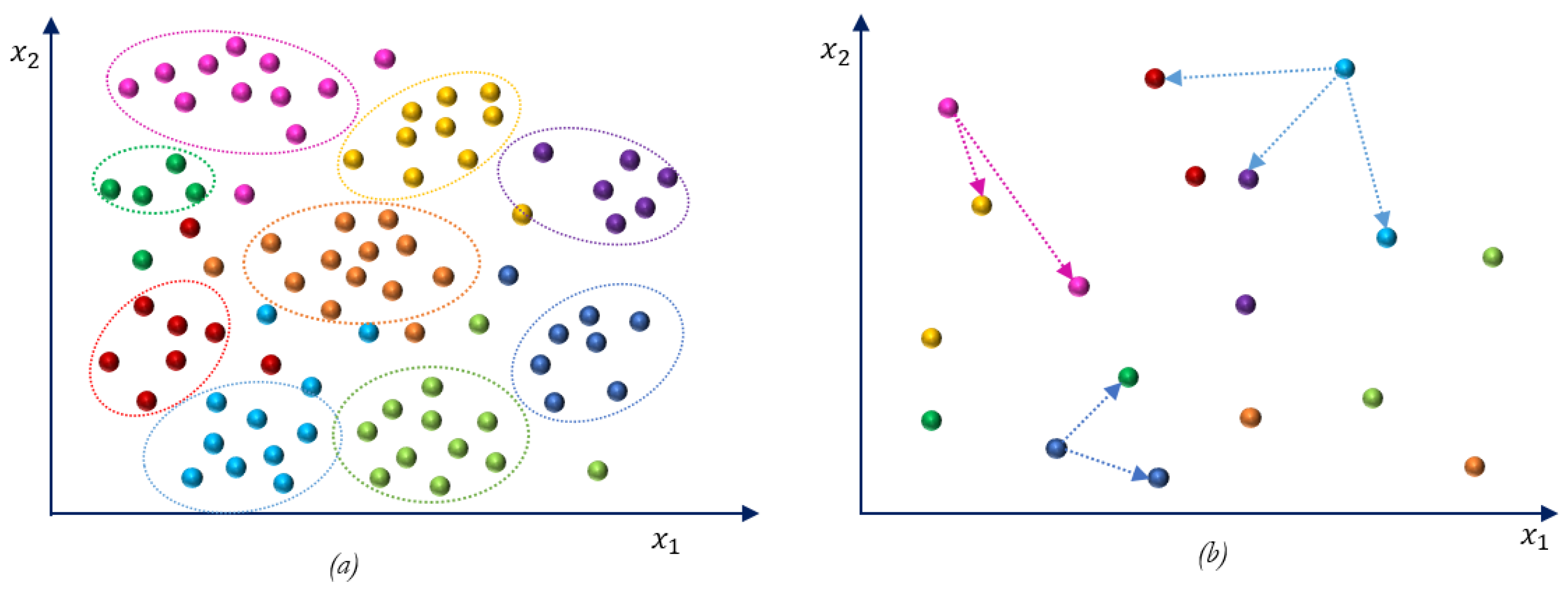
2.2. Analysis of Multi-Object Tracking and Re-Identification Challenges: Differences on Data
- Camera view. In an MOT system, the identification of a certain individual is performed through a video sequence that is captured from a certain camera. Therefore, the compared observations of the query person are captured from the same monitoring point. On contrary, by definition, Person Re-identification is the recognition of an individual across images that are captured from different and non-overlapping camera views. This results in extended periods of occlusion and large changes of viewpoint and illumination across different fields of view.
- Number of samples of each individual. In a Single-Shot Re-Identification system, identity recognition is performed from only two images of every individual, one per camera view. However, in a tracking sequence, there are so many samples of a person as frames where the person appears.
- Intra-class variations. In the Re-Id frame, intra-class variations are caused by the significant and unknown cross-view feature distortion between two different capturing points. The differences between the camera characteristics and point of view of two different monitoring points cause large changes in perspective, illumination, background, pose, scale, and resolution. This results in dramatically different appearances and consequently different representations of the same person. In MOT sequences, every detection of an individual is captured from the same device, so the intra-class variation is smaller. However, the data can also present certain appearance variations due to temporal occlusions, the presence of fast-moving people or the use of moving camera platforms, which vary the pose, illumination, and background between observations.
- Inter-class ambiguity. Inter-class ambiguities are produced by the existence of different individuals with almost identical shape and wearing similar clothes and hairstyles. These ambiguities are more accused in Re-Id data, where the representation of a person is compared with that across view variations, so it can be more similar to the representation of another person than himself/herself.
- Local features alignment. The variations of viewpoints and poses cause misalignment in the compared human shapes. These misalignments are caused by occlusions and moving cameras in MOT domain, and by the different location of the camera views in Re-Id domain, where the variations are more pronounced.
- Binary classification balance. The number of samples of a query individual is very reduced, specifically when compared with the huge amount of potentially available detections of different people. The Single-Shot Re-Identification task is especially affected by the unbalanced nature of its underlying data (two samples per person). In an MOT system, the number of samples of a certain individual is equal to the number of frames where the query person has appeared, which is reduced when new individuals enter in the field of view of the surveillance camera.
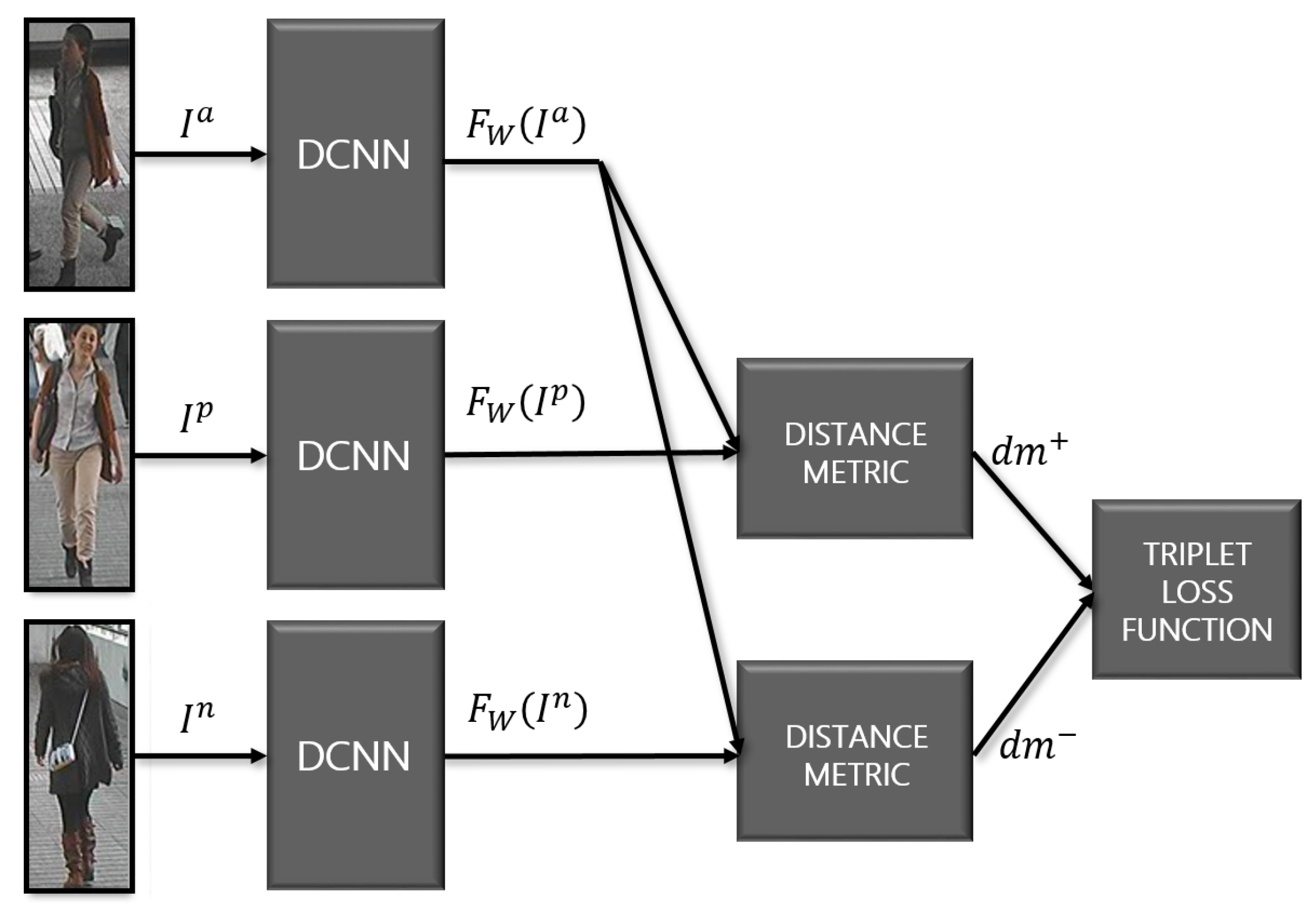
2.3. Double-Margin-Contrastive Loss vs. Triplet Loss
2.4. Learning Algorithm Implementation
| Algorithm 1 Pair-based Mini-Batch Gradient Descent Learning Algorithm. |
| Require: Batches of pairs, . Ensure: The network parameters .
|
| Algorithm 2 Triplet-based Mini-Batch Gradient Descent Learning Algorithm [67]. |
| Require: Batches of triplets, . Ensure: The network parameters .
|
3. Results
3.1. Datasets Protocol
- The MOT17 dataset belongs to the MOTchallenge (MOTChallenge is a Multiple Object Tracking Benchmark which provides a unified framework to standardise the evaluation of MOT methods. This is published under https://motchallenge.net/) and includes fourteen variate real-world surveillance sequences, meant to train and test Multi-Person Tracking algorithms, which were released in 2017. This benchmark contains challenging video sequences captured from static and moving cameras in unconstrained environments. The MOT17 dataset contains the same set of sequences as MOT16 [68], but with an extended more accurate ground truth. Seven of the sequences are accompanied by its corresponding ground-truth files and have been used to extract person images, to obtain samples of the identities appearing in those sequences.
- PRID2011 (PRID2011 dataset is publicly available under https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/prid11/) [69] is a Single-Shot Re-Id dataset that was captured from two different, static surveillance cameras, placed outdoors. This is composed of two sets of images, where all the images from one set, A, were captured from the same camera view, and all the samples from the other set, B, were acquired from a second camera view different from the first one. Set A contains 385 individuals and set B, 749. 200 of the captured individuals are rendered in both sets. In addition, 100 of them have been used to train the model. The test set has been formed by following the procedure described in [69], i.e., the images of set A for the 100 remaining individuals with representation in both sets have been used as the probe set. The gallery set has been formed by 649 images belonging to set B (all images of set B except the 100 corresponding to the training individuals).
- VIPeR (VIPeR dataset is publicly available under https://vision.soe.ucsc.edu/node/178) [63] is a Single-Shot Re-Id dataset where the images were captured from arbitrary viewpoints under varying illumination conditions, even inside the same set, but maintaining the assumption that the representation of a person in set A was captured from a different camera view than that from which its representation in the set B was captured. This dataset presents 632 pedestrians, each one with representation in both sets. For evaluation, the procedure described in [63] has been followed. The pairs have been randomly grouped into two sets of 316 pairs to train and test the model. Therefore, the gallery set is formed by 316 images from set A, and the probe set by their matching images from set B.
3.2. Evaluation Methodology: Metrics
- Evaluation of binary classification capacity. A ROC (Relative Operating Characteristic) [72] curve has been used to visualize the capacity of the learnt models to properly classify the pairs samples of the test set. This curve renders the diagnostic ability of a binary classifier as its discrimination threshold, , is varied. defines the value until which the classifier output is considered as the prediction of a positive pair, and from which it is considered as a negative pair. The ROC curve plots the True Positive Rate (), also called Sensitivity or Recall, against the False Positive Rate (), also known as the fall-out rate. The and metrics are defined by Equations (17) and (18), respectively, where is the number of true positives, is the number of true negatives, is the number of false positives, and is the number of false negatives.Other metrics widely used to measure the performance of binary classifiers are Positive Predictive Value, (also called Precision), score, and Accuracy, A, defined by Equations (19)–(21), respectively. score provides a trade-off between precision and recall. The accuracy value, which is the proportion of well-classified pairs is not an appropriate metric for the case of having skewed classes In the case of identifying a person when he/she is compared with many people images, the ratio of positive samples to negative ones is very low. However, to provide a fair evaluation through the accuracy metric, the test set has been formed by the same number of positive as negatives pairs, presenting a completely balanced proportion of samples from each class.
- Evaluation of the Re-Id ranking capacity. The test set is formed by two groups of images, the set of probe images and the galley. The capacity of the model to rank the gallery images according to their affinity with a query probe image has been evaluated through the Cumulative Matching Characteristic (CMC) curve [73].To obtain the CMC curve, a query probe image is coupled with all the images from the gallery and the distance metrics, , between them are computed. The obtained distance metrics, , are ranked, and this process is repeated for each one of the probe images. The rank value, i.e., the position of the correct match in the rank, is calculated for each probe image and, subsequently, the percentage in which each rank appears. Then, the CMC curve renders the expectation of finding the correct match within the top r matches, for different values of r, called ranks. The computed percentages are cumulative.All the gallery images must be ranked in order of decreasing appearance affinity w.r.t. the probe image and the correct match must occupy the first position on the ranking. This is an extremely arduous task, since, even under the human criteria, the probe image can be visually more similar to gallery images from different people than to the corresponding one because of the inter-class ambiguities and the intra-class variations. Moreover, the person rendered in one probe image must be recognized among multiple gallery images. For instance, in PRID dataset, a probe individual must be found among 649 images. For that reason, CMC curves are not comparable to ROC curves, since the first ones represent the ranking capacity of a method instead of its classification capacity.
- Evaluation of the learning evolution. The evolution of every training process is evaluated by analyzing their learning curves, which is the representation of the loss function value throughout the learning process. This allows for checking the model convergence. The convergence of the Mini-Batch Gradient Descent cannot be guaranteed by an arithmetical method, but experimentally observing the progression of the learning curve of the training process. The Mini-Batch learning algorithm performs frequent parameters updates with a high variance that cause the objective function to fluctuate heavily, resulting in a learning curve with oscillations. Despite the oscillations, the convergence of the learning algorithms is proved by the decreasing tendency of their learning curves that eventually are stabilized around a certain value.
3.3. Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CMC | Cumulative Matching Characteristic |
| DCNN | Deep Convolutional Neural Network |
| ELF | Ensemble of Localized Features |
| FPR | False Positive Rate |
| GFI | Global Feature Importance |
| ISS | Intelligent Surveillance System |
| LDA | Linear Discriminant Analysis |
| LDML | Logistic Discriminant Metric Learning |
| MOT | Multi-Object Tracking |
| MTMCT | Multi Target Multi Camera Tracking |
| PPV | Positive Predictive Value |
| PRDC | Probabilistic Relative Distance Comparison |
| PRID2011 | Person Re-IDentification 2011 |
| PSFI | Prototype-Sensitive Feature Importance |
| RankSVM | Ranking Support Vector Machines |
| Re-Id | Person Re-Identification |
| ROC | Relative Operating Characteristic |
| TCA | Transfer Component Analysis |
| TFLDA | Transference to Fisher Linear Discriminant Analysis |
| TPR | True Positive Rate |
| VGG | Visual Geometry Group |
| VIPeR | Viewpoint Invariant Pedestrian Recognition |
References
- Research, G.V. Perimeter Security Market Size, Share & Trends Analysis Report by System (Alarms & Notification, Video Surveillance), by Service, by End Use (Government, Transportation), in addition, and Segment Forecasts, 2019–2025; Market Research Report, Report ID: GVR-2-68038-042-2; 2019; p. 243. Available online: https://www.researchandmarkets.com/reports/4452096/perimeter-security-market-size-share-and-trends (accessed on 20 October 2020).
- Sulman, N.; Sanocki, T.; Goldgof, D.; Kasturi, R. How effective is human video surveillance performance? In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–3. [Google Scholar]
- Qian, H.; Wu, X.; Xu, Y. Intelligent Surveillance Systems; Springer Science & Business Media: New York, NY, USA, 2011. [Google Scholar]
- Ibrahim, S. A comprehensive review on intelligent surveillance systems. Commun. Sci. Technol. 2016, 1. [Google Scholar] [CrossRef]
- Fookes, C.; Denman, S.; Lakemond, R.; Ryan, D.; Sridharan, S.; Piccardi, M. Semi-supervised intelligent surveillance system for secure environments. In Proceedings of the 2010 IEEE International Symposium on Industrial Electronics, Bari, Italy, 4–7 July 2010; pp. 2815–2820. [Google Scholar]
- Valera, M.; Velastin, S.A. Intelligent distributed surveillance systems: A review. IEEE Proc. Vision Image Signal Process. 2005, 152, 192–204. [Google Scholar] [CrossRef]
- Velastin, S.; Khoudour, L.; Lo, B.; Sun, J.; Vicencio-Silva, M. PRISMATICA: A Multi-Sensor Surveillance System for Public Transport Networks. In Proceedings of the 12th IEE International Conference on Road Transport Information & Control—RTIC 2004, London, UK, 20–22 April 2004. [Google Scholar]
- Siebel, N.T.; Maybank, S. The advisor visual surveillance system. In Proceedings of the ECCV 2004 Workshop Applications of Computer Vision (ACV), Prague, Czech Republic, 11–14 May 2004. [Google Scholar]
- Collins, R.T.; Lipton, A.J.; Fujiyoshi, H.; Kanade, T. Algorithms for cooperative multisensor surveillance. Proc. IEEE 2001, 89, 1456–1477. [Google Scholar] [CrossRef]
- Choi, W. Near-online multi-target tracking with aggregated local flow descriptor. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3029–3037. [Google Scholar]
- Possegger, H.; Mauthner, T.; Roth, P.M.; Bischof, H. Occlusion geodesics for online multi-object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–25 June 2014; pp. 1306–1313. [Google Scholar]
- Kuo, C.H.; Nevatia, R. How does person identity recognition help multi-person tracking? In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 1217–1224. [Google Scholar]
- Shu, G.; Dehghan, A.; Oreifej, O.; Hand, E.; Shah, M. Part-based multiple-person tracking with partial occlusion handling. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1815–1821. [Google Scholar]
- Zhang, L.; Li, Y.; Nevatia, R. Global data association for multi-object tracking using network flows. In Proceedings of the Computer Vision and Pattern Recognition, CVPR 2008, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Milan, A.; Roth, S.; Schindler, K. Continuous energy minimization for multitarget tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 58–72. [Google Scholar] [CrossRef] [PubMed]
- Oron, S.; Bar-Hille, A.; Avidan, S. Extended lucas-kanade tracking. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 142–156. [Google Scholar]
- Dicle, C.; Camps, O.I.; Sznaier, M. The way they move: Tracking multiple targets with similar appearance. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 8–12 April 2013; pp. 2304–2311. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning social etiquette: Human trajectory understanding in crowded scenes. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 549–565. [Google Scholar]
- Kratz, L.; Nishino, K. Tracking pedestrians using local spatio-temporal motion patterns in extremely crowded scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 987–1002. [Google Scholar] [CrossRef]
- Ristani, E.; Tomasi, C. Tracking multiple people online and in real time. In Asian Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 444–459. [Google Scholar]
- Butt, A.A.; Collins, R.T. Multi-target tracking by lagrangian relaxation to min-cost network flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1846–1853. [Google Scholar]
- Chen, X.; An, L.; Bhanu, B. Multitarget tracking in nonoverlapping cameras using a reference set. IEEE Sens. J. 2015, 15, 2692–2704. [Google Scholar] [CrossRef]
- Le, N.; Heili, A.; Odobez, J.M. Long-term time-sensitive costs for crf-based tracking by detection. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 43–51. [Google Scholar]
- Tang, S.; Andres, B.; Andriluka, M.; Schiele, B. Multi-person tracking by multicut and deep matching. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 100–111. [Google Scholar]
- Zhang, S.; Staudt, E.; Faltemier, T.; Roy-Chowdhury, A.K. A camera network tracking (CamNeT) dataset and performance baseline. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 365–372. [Google Scholar]
- Zhang, S.; Zhu, Y.; Roy-Chowdhury, A. Tracking multiple interacting targets in a camera network. Comput. Vis. Image Underst. 2015, 134, 64–73. [Google Scholar] [CrossRef]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 749–765. [Google Scholar]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by tracking: Siamese CNN for robust target association. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 33–40. [Google Scholar]
- Zhai, M.; Chen, L.; Mori, G.; Roshtkhari, M.J. Deep learning of appearance models for online object tracking. In European Conference on Computer Vision; Springer: New York, NY, USA, 2018; pp. 681–686. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Robust online multiobject tracking with data association and track management. IEEE Trans. Image Process. 2014, 23, 2820–2833. [Google Scholar]
- Yang, M.; Jia, Y. Temporal dynamic appearance modeling for online multi-person tracking. Comput. Vis. Image Underst. 2016, 153, 16–28. [Google Scholar] [CrossRef]
- Shitrit, H.B.; Berclaz, J.; Fleuret, F.; Fua, P. Tracking multiple people under global appearance constraints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 137–144. [Google Scholar]
- Han, M.; Xu, W.; Tao, H.; Gong, Y. An algorithm for multiple object trajectory tracking. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Matsukawa, T.; Okabe, T.; Suzuki, E.; Sato, Y. Hierarchical gaussian descriptor for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1363–1372. [Google Scholar]
- Yang, Y.; Yang, J.; Yan, J.; Liao, S.; Yi, D.; Li, S.Z. Salient color names for person re-identification. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 536–551. [Google Scholar]
- Zhao, R.; Ouyang, W.; Wang, X. Learning mid-level filters for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 144–151. [Google Scholar]
- Lisanti, G.; Masi, I.; Bagdanov, A.D.; Del Bimbo, A. Person re-identification by iterative re-weighted sparse ranking. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1629–1642. [Google Scholar] [CrossRef]
- Ma, L.; Yang, X.; Tao, D. Person re-identification over camera networks using multi-task distance metric learning. IEEE Trans. Image Process. 2014, 23, 3656–3670. [Google Scholar] [PubMed]
- Xiong, F.; Gou, M.; Camps, O.; Sznaier, M. Person re-identification using kernel-based metric learning methods. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 1–16. [Google Scholar]
- Zhang, Y.; Li, B.; Lu, H.; Irie, A.; Ruan, X. Sample-specific svm learning for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 30 2016; pp. 1278–1287. [Google Scholar]
- Liu, H.; Feng, J.; Qi, M.; Jiang, J.; Yan, S. End-to-end comparative attention networks for person re-identification. IEEE Trans. Image Process. 2017, 26, 3492–3506. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Deep metric learning for person re-identification. In Proceedings of the IEEE Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 34–39. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification Using a “ Siamese” Time Delay Neural Network. In Advances in Neural Information Processing Systems; 1994; pp. 737–744. Available online: https://papers.nips.cc/paper/769-signature-verification-using-a-siamese-time-delay-neural-network.pdf (accessed on 20 October 2020).
- Ahmed, E.; Jones, M.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3908–3916. [Google Scholar]
- Ustinova, E.; Ganin, Y.; Lempitsky, V. Multi-region bilinear convolutional neural networks for person re-identification. In Proceedings of the Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated siamese convolutional neural network architecture for human re-identification. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 791–808. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 1735–1742. [Google Scholar]
- G’omez-Silva, M.J.; Armingol, J.M.; de la Escalera, A. Deep Part Features Learning by a Normalised Double-Margin-Based Contrastive Loss Function for Person Re-Identification. In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2017) (6: VISAPP), Porto, Portugal, 27 February–1 March 2017; pp. 277–285. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Zhuang, B.; Lin, G.; Shen, C.; Reid, I. Fast training of triplet-based deep binary embedding networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5955–5964. [Google Scholar]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning fine-grained image similarity with deep ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar]
- Ding, S.; Lin, L.; Wang, G.; Chao, H. Deep feature learning with relative distance comparison for person re-identification. Pattern Recognit. 2015, 48, 2993–3003. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification With Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; 2012; pp. 1097–1105. Available online: https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf (accessed on 20 October 2020).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Wang, P.; Bai, X. Regional parallel structure based CNN for thermal infrared face identification. Integr. Comput. Aided Eng. 2018, 25, 247–260. [Google Scholar] [CrossRef]
- Hirzer, M.; Roth, P.M.; Bischof, H. Person re-identification by efficient impostor-based metric learning. In Proceedings of the Advanced Video and Signal-Based Surveillance (AVSS), Beijing, China, 18–21 September 2012; pp. 203–208. [Google Scholar]
- Gray, D.; Tao, H. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In European Conference on Computer Vision; Springer: New York, NY, USA, 2008; pp. 262–275. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Cogn. Model. 1988, 5, 1. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. Available online: http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf (accessed on 20 October 2020).
- Gómez-Silva, M.J.; Izquierdo, E.; Escalera, A.d.l.; Armingol, J.M. Transferring learning from multi-person tracking to person re-identification. Integr. Comput. Aided Eng. 2019, 26, 329–344. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Hirzer, M.; Beleznai, C.; Roth, P.M.; Bischof, H. Person re-identification by descriptive and discriminative classification. In Scandinavian Conference on Image Analysis; Springer: New York, NY, USA, 2011; pp. 91–102. [Google Scholar]
- Gómez-Silva, M.J.; Armingol, J.M.; de la Escalera, A. Balancing people re-identification data for deep parts similarity learning. J. Imaging Sci. Technol. 2019, 63, 20401-1. [Google Scholar] [CrossRef]
- Gómez-Silva, M.J.; Armingol, J.M.; de la Escalera, A. Triplet Permutation Method for Deep Learning of Single-Shot Person Re-Identification. In Proceedings of the 9th International Conference on Imaging for Crime Detection and Prevention (ICDP-2019), London, UK, 16–18 December 2019. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Moon, H.; Phillips, P.J. Computational and performance aspects of PCA-based face-recognition algorithms. Perception 2001, 30, 303–321. [Google Scholar] [CrossRef]
- Liu, C.; Gong, S.; Loy, C.C.; Lin, X. Evaluating feature importance for re-identification. In Person Re-Identification; Springer: New York, NY, USA, 2014; pp. 203–228. [Google Scholar]
- Zheng, W.S.; Gong, S.; Xiang, T. Reidentification by relative distance comparison. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 653–668. [Google Scholar] [CrossRef]
- Prosser, B.; Zheng, W.S.; Gong, S.; Xiang, T.; Mary, Q. Person Re-Identification by Support Vector Ranking. BMVC 2010, 2, 6. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Loy, C.C.; Xiang, T.; Gong, S. Time-delayed correlation analysis for multi-camera activity understanding. Int. J. Comput. Vis. 2010, 90, 106–129. [Google Scholar] [CrossRef]
- Hirzer, M.; Roth, P.; Köstinger, M.; Bischof, H. Relaxed pairwise learned metric for person re-identification. In Computer Vision–ECCV 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 780–793. [Google Scholar]
- Guillaumin, M.; Verbeek, J.; Schmid, C. Is that you? Metric learning approaches for face identification. In Proceedings of the Computer Vision, 2009 IEEE 12th International Conference on IEEE, Kyoto, Japan, 29 September–2 October 2009; pp. 498–505. [Google Scholar]
- Si, S.; Tao, D.; Geng, B. Bregman divergence-based regularization for transfer subspace learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 929. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input Size | Output Size | Kernel |
|---|---|---|---|
| Conv-1-1 | 128 × 64 × 3 | 128 × 64 × 64 | 3 × 3 × 3 |
| Pool-1 | 128 × 64 × 64 | 64 × 32 × 64 | 2 × 2 × 64, 2 |
| Conv-2-1 | 64 × 32 × 64 | 64 × 32 × 128 | 3 × 3 × 64 |
| Pool-2 | 64 × 32 × 128 | 32 × 16 × 128 | 2 × 2 × 128, 2 |
| Conv-3-1 | 32 × 16 × 128 | 32 × 16 × 256 | 3 × 3 × 128 |
| Conv-3-2 | 32 × 16 × 256 | 32 × 16 × 256 | 3 × 3 × 256 |
| Pool-3 | 32 × 16 × 256 | 16 × 8 × 256 | 2 × 2 × 256, 2 |
| Conv-4-1 | 16 × 8 × 256 | 16 × 8 × 512 | 3 × 3 × 256 |
| Conv-4-2 | 16 × 8 × 512 | 16 × 8 × 512 | 3 × 3 × 512 |
| Pool-4 | 16 × 8 × 512 | 8 × 4 × 512 | 2 × 2 × 512, 2 |
| Conv-5-1 | 8 × 4 × 512 | 8 × 4 × 512 | 3 × 3 × 512 |
| Conv-5-2 | 8 × 4 × 512 | 8 × 4 × 512 | 3 × 3 × 512 |
| Pool-5 | 8 × 4 × 512 | 4 × 2 × 512 | 2 × 2 × 512, 2 |
| FC-6 | 4 × 2 × 512 | 1 × 1 × 4096 | 4096 |
| FC-7 | 1 × 1 × 4096 | 1 × 1 × 4096 | 4096 |
| FC-8 | 1 × 1 × 4096 | 1 × 1 × 1000 | 1000 |
| Experiments | Description | ||
|---|---|---|---|
| Data Source | Loss Function | Other Settings | |
| Exp.MOT.Contrast | MOT domain | Double-Margin-Contrastive loss, , Equation (1) | VGG11 architecture. Euclidean distance metric. Adagrad optimizer. L2 regularization, . |
| Exp.MOT.Triplet | Triplet loss, , Equation (5) | ||
| Exp.ReId.Contrast | Re-Id domain | Double-Margin-Contrastive loss, , Equation (1) | |
| Exp.ReId.Triplet | Triplet loss, , Equation (5) | ||
| [%] | [%] | [%] | [%] | A [%] | |||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | - | - | ||||
| 5758 | 223 | ||||||||
| 3614 | 559 | ||||||||
| 2498 | 1057 | ||||||||
| 1702 | 1623 | ||||||||
| 1106 | 2220 | ||||||||
| 667 | 2760 | ||||||||
| 378 | 3229 | ||||||||
| 238 | 3711 | ||||||||
| 149 | 4226 | ||||||||
| 99 | 4738 | ||||||||
| 59 | 5352 | ||||||||
| 32 | 6100 | ||||||||
| 16 | 6850 | ||||||||
| 5 | 7813 | ||||||||
| 0 | 8787 | ||||||||
| 9868 | 0 | ||||||||
| 8498 | 0 | ||||||||
| 7509 | 0 | ||||||||
| 6047 | 0 | ||||||||
| 0 | 0 |
| [%] | [%] | [%] | [%] | A [%] | |||||
|---|---|---|---|---|---|---|---|---|---|
| 20000 | 20000 | 0 | 0 | 0 | 0 | - | - | ||
| 3 | 5273 | ||||||||
| 10 | 8401 | ||||||||
| 9516 | 16 | ||||||||
| 7879 | 30 | ||||||||
| 6542 | 64 | ||||||||
| 5428 | 122 | ||||||||
| 4540 | 235 | ||||||||
| 3849 | 400 | ||||||||
| 3370 | 559 | ||||||||
| 2968 | 736 | ||||||||
| 2646 | 970 | ||||||||
| 2340 | 1215 | ||||||||
| 2082 | 1501 | ||||||||
| 1861 | 1834 | ||||||||
| 1612 | 2273 | ||||||||
| 1387 | 2907 | ||||||||
| 1166 | 3656 | ||||||||
| 863 | 4644 | ||||||||
| 430 | 6249 | ||||||||
| 0 | 0 |
| Dataset | PRID2011 | VIPeR | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rank | 1 | 5 | 10 | 20 | 50 | 100 | 1 | 5 | 10 | 20 | 50 | 100 |
| Exp.ReId.Contrast | 0 | 4 | 9 | 13 | 19 | 27 | 4 | 13 | 17 | 26 | 42 | 60 |
| Exp.ReId.Triplet | 4 | 14 | 20 | 77 | 11 | 35 | 54 | 69 | 90 | 96 | ||
| Method | Rank | |||||
|---|---|---|---|---|---|---|
| 1 | 5 | 10 | 20 | 50 | 100 | |
| Proposed Method | ||||||
| PSFI+PRDC [74] | 3 | 9 | 16 | 24 | 39 | - |
| PRDC [75] | 3 | 10 | 15 | 23 | 38 | - |
| PSFI+RankSVM [74] | 4 | 9 | 13 | 20 | 32 | - |
| RankSVM [76] | 4 | 9 | 13 | 19 | 32 | - |
| LDA [77] | 4 | - | 14 | 21 | 35 | 48 |
| GFI [78] | 4 | - | 10 | 17 | 32 | - |
| Euclidean [79] | 3 | - | 10 | 14 | 28 | 45 |
| LDML [80] | 2 | - | 6 | 11 | 19 | 32 |
| PSFI [74] | 1 | 2 | 4 | 7 | 14 | - |
| Method | Rank | |||||
|---|---|---|---|---|---|---|
| 1 | 5 | 10 | 20 | 50 | 100 | |
| Proposed Method | 11 | 35 | 69 | 96 | ||
| PRDC [75] | 16 | 38 | 54 | 70 | 87 | 97 |
| PSFI+PRDC [74] | 16 | 38 | 51 | 66 | - | - |
| PSFI+RankSVM [74] | 16 | 38 | 51 | 66 | - | - |
| RankSVM [76] | 15 | 37 | 50 | 65 | - | - |
| ELF [63] | 12 | 31 | 41 | 58 | - | - |
| PSFI [74] | 10 | 22 | 31 | 43 | - | - |
| GFI [78] | 9 | - | 27 | 34 | - | - |
| LDA [77] | 7 | - | 25 | 37 | 61 | 79 |
| Euclidean [79] | 7 | - | 24 | 34 | 55 | 73 |
| LDML [80] | 6 | - | 24 | 35 | 54 | 72 |
| TFLDA [81] | 6 | 17 | 26 | 40 | - | - |
| TCA [82] | 5 | 11 | 16 | 25 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gómez-Silva, M.J.; de la Escalera, A.; Armingol, J.M. Deep Learning of Appearance Affinity for Multi-Object Tracking and Re-Identification: A Comparative View. Electronics 2020, 9, 1757. https://doi.org/10.3390/electronics9111757
Gómez-Silva MJ, de la Escalera A, Armingol JM. Deep Learning of Appearance Affinity for Multi-Object Tracking and Re-Identification: A Comparative View. Electronics. 2020; 9(11):1757. https://doi.org/10.3390/electronics9111757
Chicago/Turabian StyleGómez-Silva, María J., Arturo de la Escalera, and José M. Armingol. 2020. "Deep Learning of Appearance Affinity for Multi-Object Tracking and Re-Identification: A Comparative View" Electronics 9, no. 11: 1757. https://doi.org/10.3390/electronics9111757
APA StyleGómez-Silva, M. J., de la Escalera, A., & Armingol, J. M. (2020). Deep Learning of Appearance Affinity for Multi-Object Tracking and Re-Identification: A Comparative View. Electronics, 9(11), 1757. https://doi.org/10.3390/electronics9111757