A Systolic Accelerator for Neuromorphic Visual Recognition

 ,
,
Abstract
1. Introduction
2. Background and Preliminary Information
3. SAFA: Systolic Accelerator for HMAX
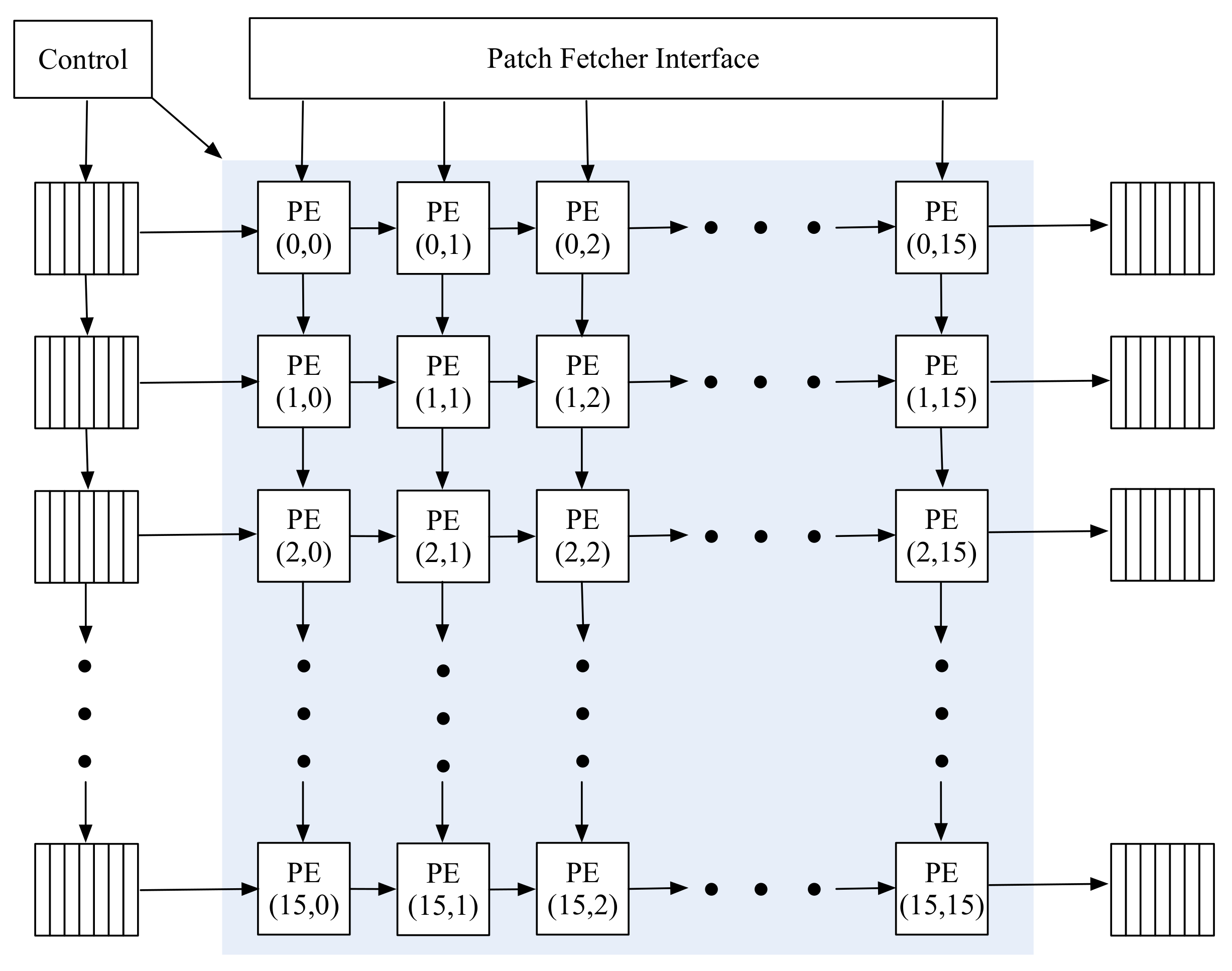
3.1. Structure of the Systolic Array
3.2. Processing Element
3.3. Schematic Dataflow for SAFA
4. Experimental Results and Analysis
4.1. Experiment Setup
4.2. Implementation Details
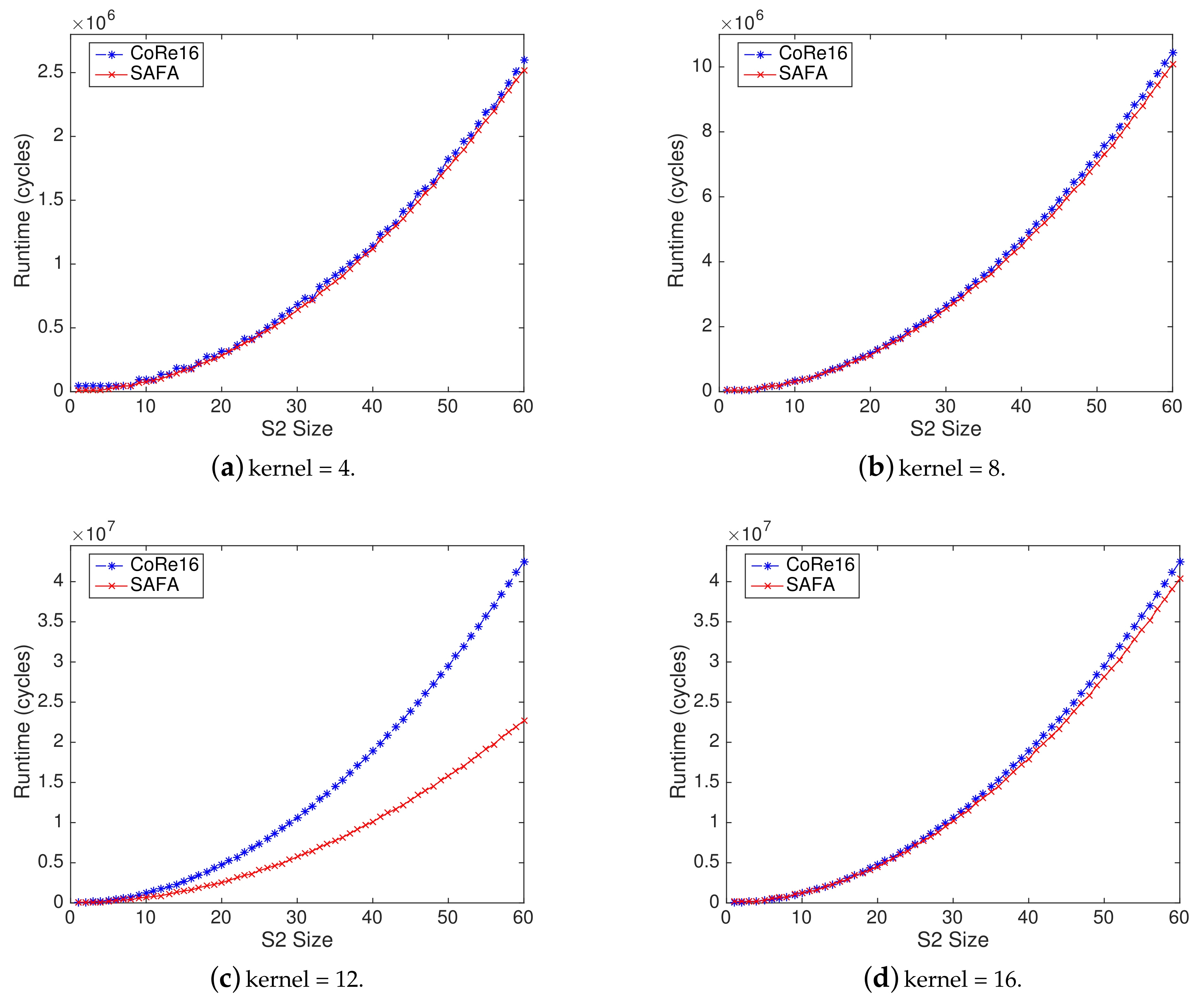
4.3. Comparison of Runtime
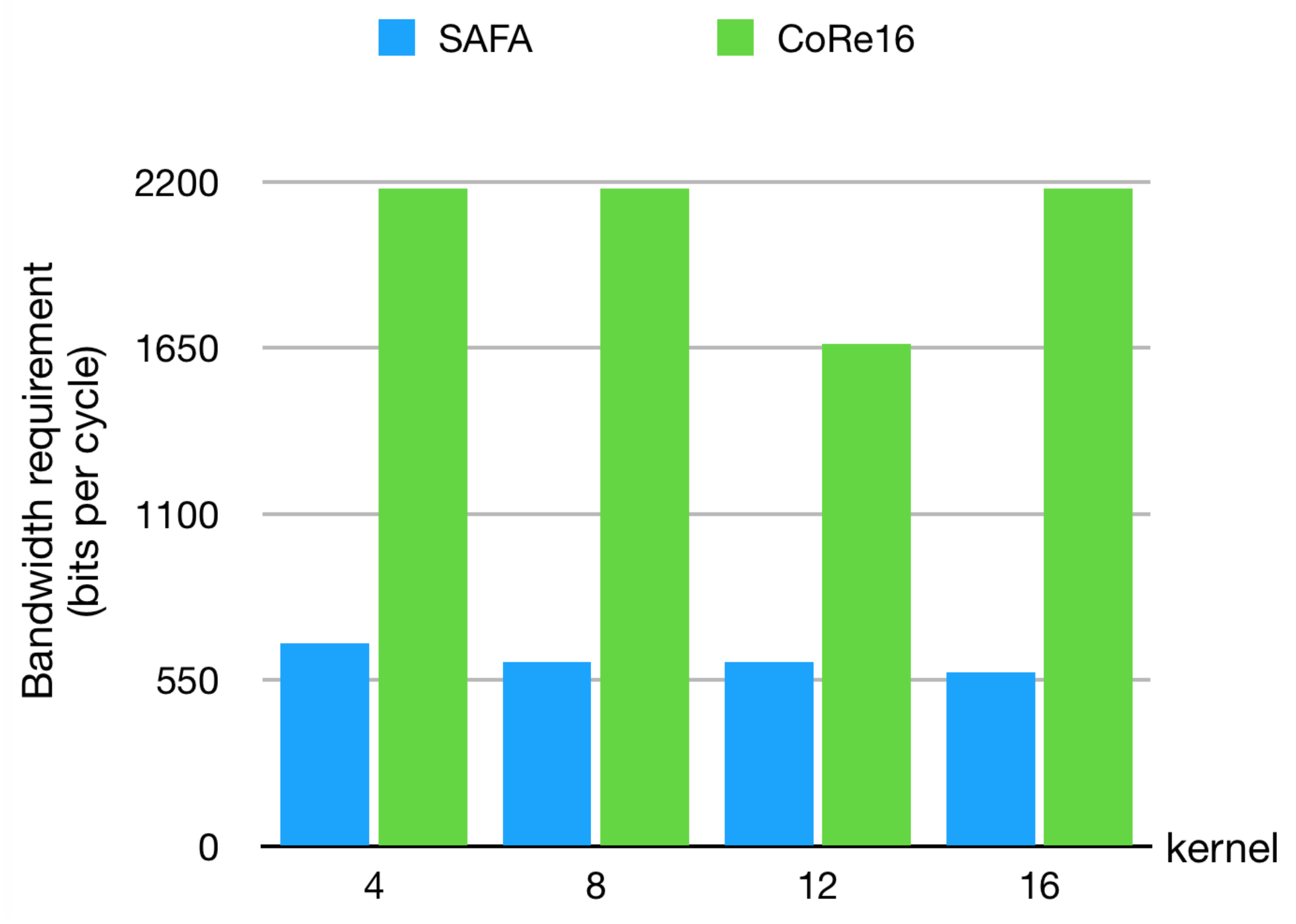
4.4. Comparison of Storage Bandwidth
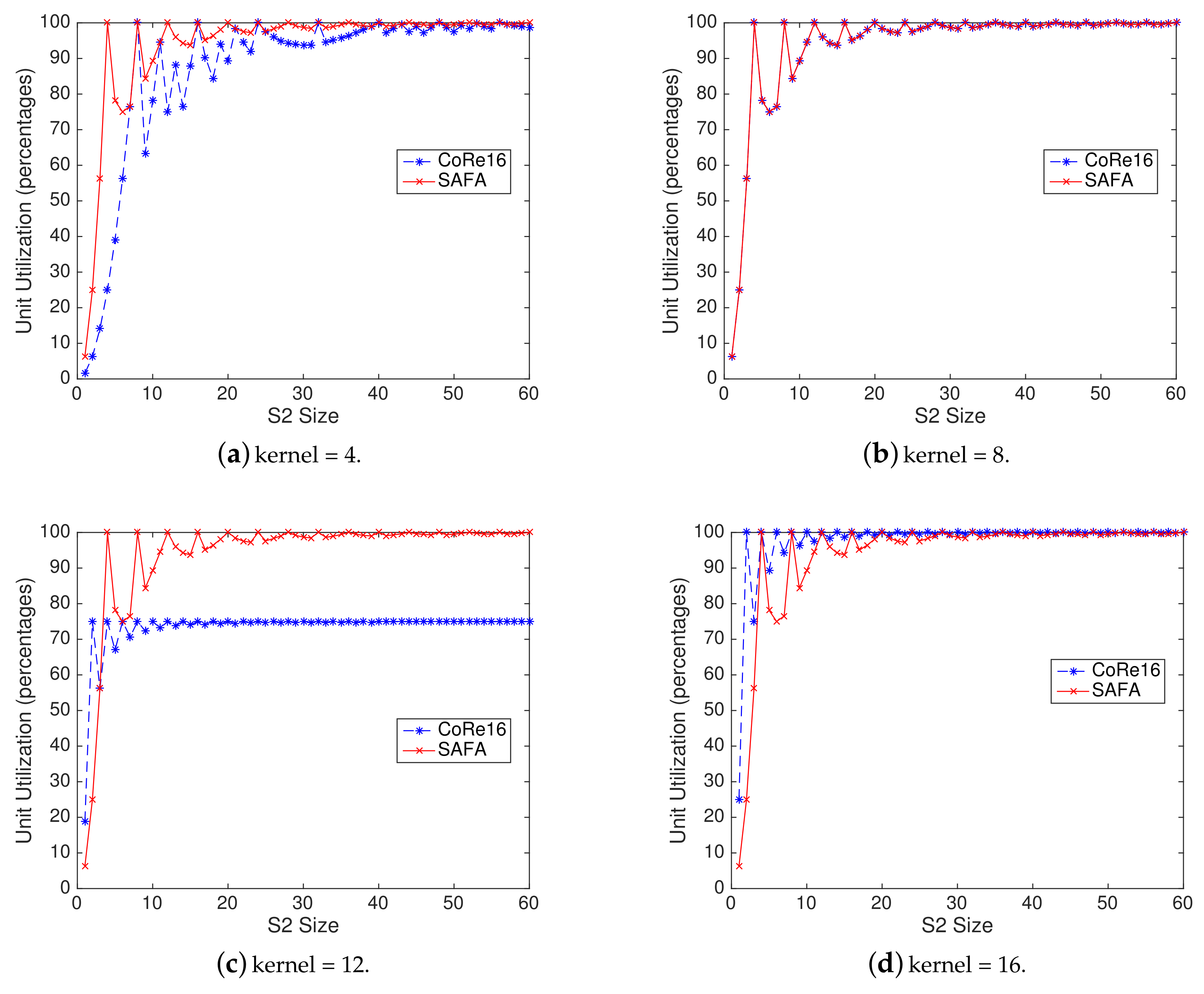
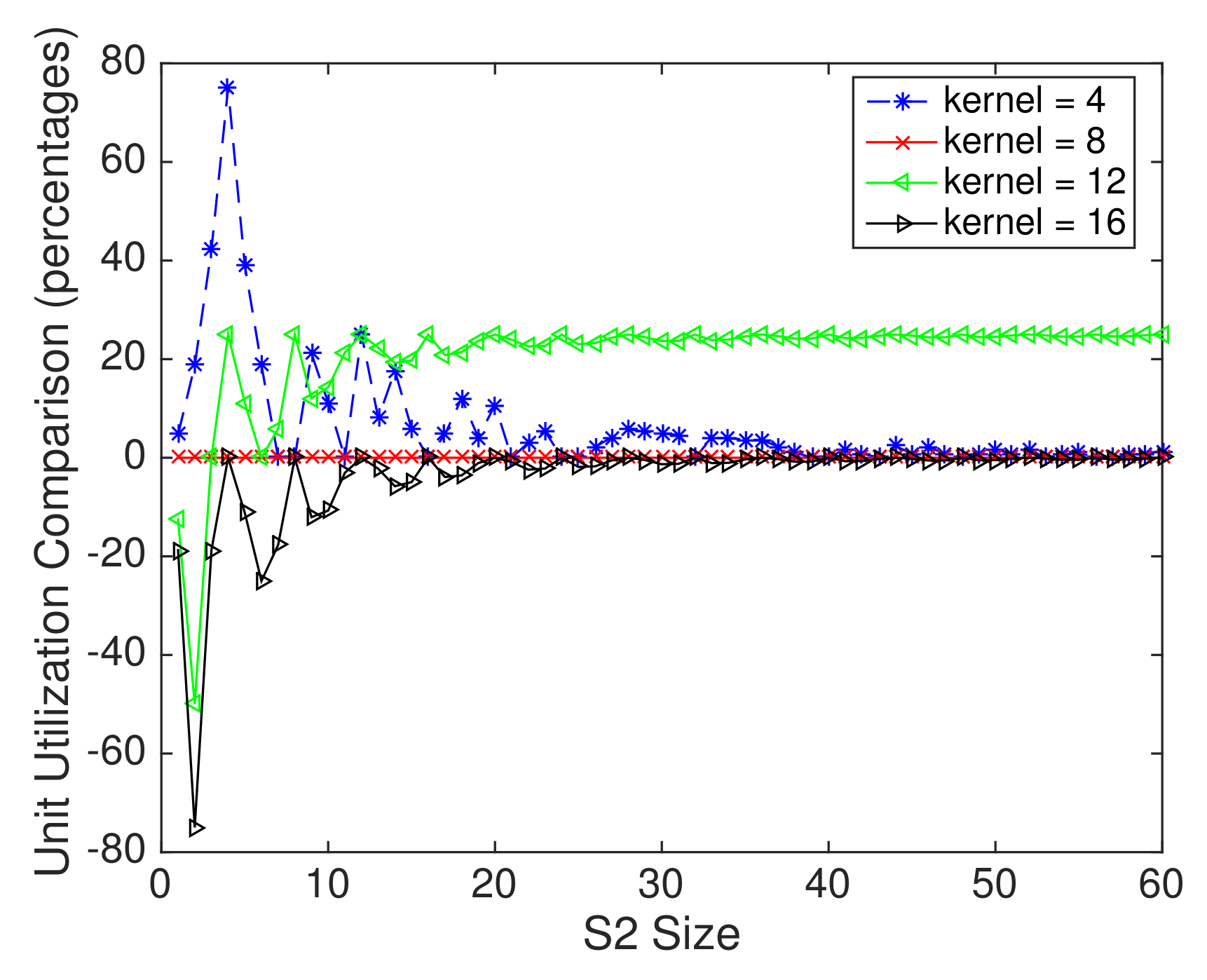
4.5. Comparison of Unit Utilization
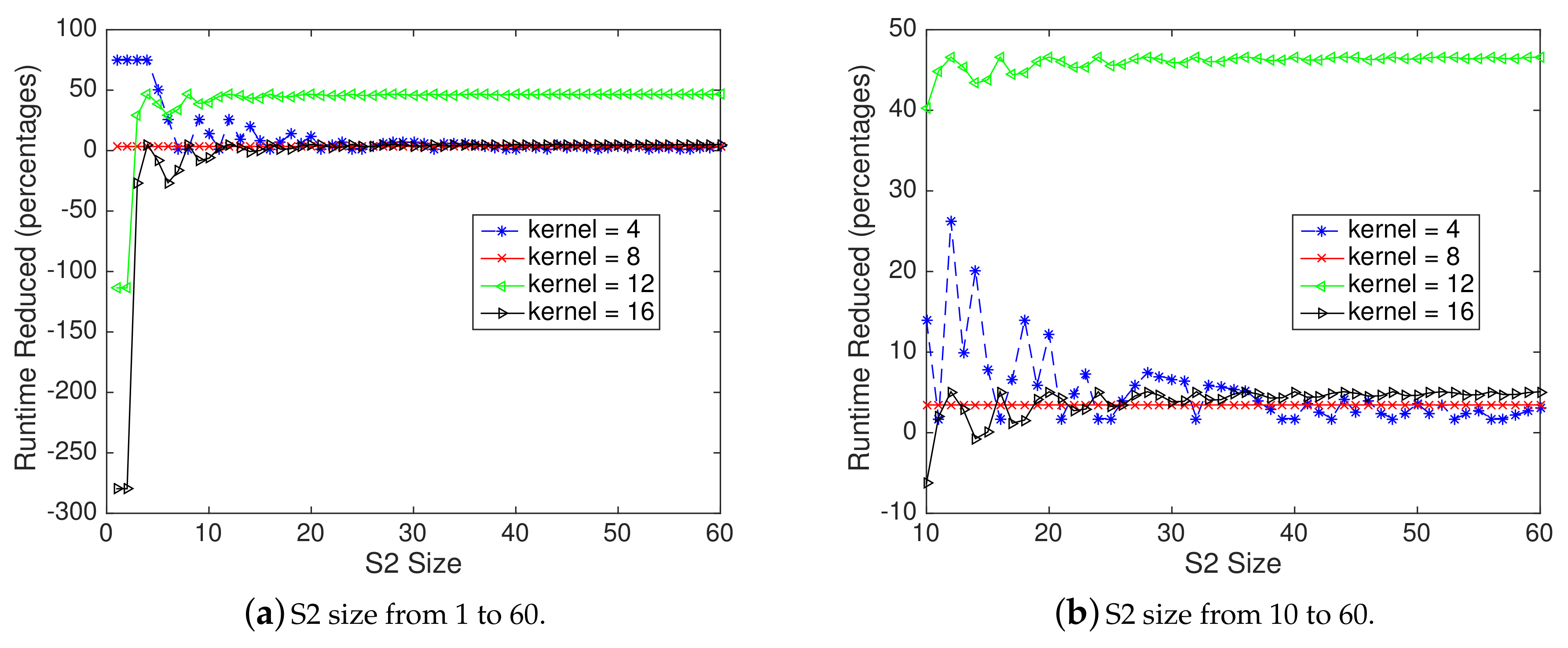
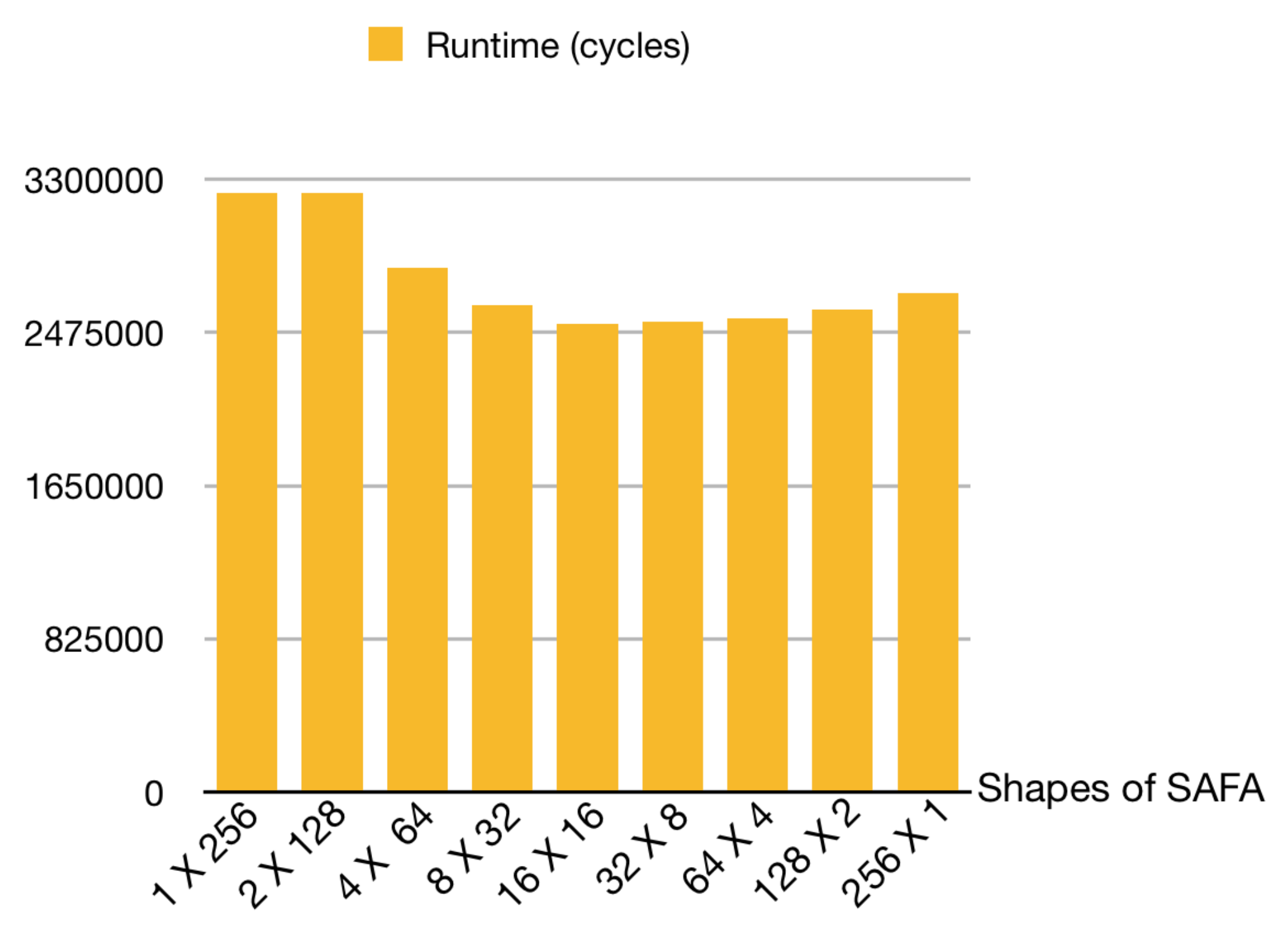
4.6. Sensitivity of Shape Array on Runtime
4.7. Area and Power Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Sanchez, J.; Soltani, N.; Chamarthi, R.; Sawant, A.; Tabkhi, H. A Novel 1D-Convolution Accelerator for Low-Power Real-time CNN processing on the Edge. In Proceedings of the IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 25–27 September 2018; pp. 1–8. [Google Scholar]
- Serre, T.; Oliva, A.; Poggio, T. A feedforward architecture accounts for rapid categorization. Proc. Natl. Acad. Sci. USA 2007, 104, 6424–6429. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Yan, M.; Bohg, J. MeteorNet: Deep learning on dynamic 3D point cloud sequences. In Proceedings of the International Conference on Computer Vision (CVPR), Seoul, Korea, 21 October 2019; pp. 9246–9255. [Google Scholar]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Label propagation for deep semi-supervised learning. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 13 June 2019; pp. 5070–5079. [Google Scholar]
- Maximilian, R.; Tomaso, P. Hierarchical models of object recognition in cortex. Nat. Neurosci. 1999, 2, 1019–1025. [Google Scholar] [CrossRef]
- Serre, T.; Wolf, L.; Bileschi, S.; Riesenhuber, M.; Poggio, T. Robust object recognition with cortex-like mechanisms. Trans. Pattern Anal. Mach. Intell. (TPAMI) 2007, 29, 411–426. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.-Z.; Lu, Y.-F.; Kang, T.-K.; Lim, M.-T. B-HMAX: A fast binary biologically inspired model for object recognition. Neurocomputing 2016, 218, 242–250. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, L. Modeling object recognition in visual cortex using multiple firing k-means and non-negative sparse coding. Signal Process. 2016, 124, 198–209. [Google Scholar] [CrossRef]
- Sufikarimi, H.; Mohammadi, K. Role of the Secondary Visual Cortex in HMAX Model for Object Recognition. Cogn. Syst. Res. 2020, 64, 15–28. [Google Scholar] [CrossRef]
- Cherloo, M.N.; Shiri, M.; Daliri, M.R. An enhanced HMAX model in combination with SIFT algorithm for object recognition. Signal Image Video Process. 2020, 14, 425–433. [Google Scholar] [CrossRef]
- Sabarad, J.; Kestur, S.; Park, M.S.; Dantara, D.; Narayanan, V.; Chen, Y.; Khosla, D. A reconfigurable accelerator for neuromorphic object recognition. In Proceedings of the Asia and South Pacific Design Automation Conference (ASP-DAC), Sydney, Australia, 9 January 2012; pp. 813–818. [Google Scholar]
- Sufikarimi, H.; Mohammadi, K. Speed up biological inspired object recognition, HMAX. In Proceedings of the 2017 3rd Iranian Conference on Intelligent Systems and Signal Processing (ICSPIS), Shahrood, Iran, 6 December 2017; pp. 183–187. [Google Scholar]
- Mutch, J.; Knoblich, U.; Poggio, T. CNS: A GPU-Based Framework for Simulating Cortically-Organized Networks; Massachusetts Institute of Technology: Cambridge, MA, USA, 2010. [Google Scholar]
- Maashri, A.A.; DeBole, M.; Yu, C.L.; Narayanan, V.; Chakrabarti, C. A hardware architecture for accelerating neuromorphic vision algorithms. In Proceedings of the IEEE Workshop on Signal Processing Systems (SIPS), Beirut, Lebanon, 8 October 2011. [Google Scholar]
- Park, M.; Kestur, S.; Sabarad, J.; Narayanan, V.; Irwin, M. An fpga accelerator for cortical object classification. In Proceedings of the Design Automation and Test Conference and Exhibition (DATE), Dresden, Germany, 19 March 2012. [Google Scholar]
- Liu, B.; Chen, X.; Wang, Y.; Han, Y.; Li, J.; Xu, H.; Li, X. Addressing the issue of processing element under-utilization in general-purpose systolic deep learning accelerators. In Proceedings of the Asia and South Pacific Design Automation Conference (ASP-DAC), Tokyo, Japan, 20 January 2019; pp. 733–738. [Google Scholar]
- Samajdar, A.; Zhu, Y.; Whatmough, P.; Mattina, M.; Krishna, T. Scale-sim: Systolic cnn accelerator simulator. arXiv 2018, arXiv:1811.02883. [Google Scholar]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Poggio, T.; Bizzi, E. Generalization in Vision and Motor Control. Nature 2004, 431, 768–774. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Dou, Y.; Jiang, J.; Wang, Q.; Chow, P. An FPGA-based processor for training convolutional neural networks. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, VIC, Australia, 7 December 2017; pp. 207–210. [Google Scholar]
- Riesenhuber, M.; Serre, T.R.; Bileschi, S.; Martin, J.G.; Rule, J. HMAX Tarball. Available online: https://maxlab.neuro.georgetown.edu/hmax.html (accessed on 26 February 2020).
- Erik, L.M. Labeled Faces in the Wild: A Survey. Advances in Face Detection and Facial Image Analysis; Springer International Publishing: Basel, Switzerland, 2016. [Google Scholar]
- Hwang, K.; Jotwani, N. Advanced Computer Architecture; McGraw-Hill Education: New York, NY, USA, 2016. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale Band | C1 Spatial Pooling Grid | Overlap | S1 Filter Size |
|---|---|---|---|
| Band 1 | 4 | ||
| Band 2 | 5 | ||
| Band 3 | 6 | ||
| Band 4 | 7 | ||
| Band 5 | 8 | ||
| Band 6 | 9 | ||
| Band 7 | 10 | ||
| Band 8 | 11 |
| Maashri et al. [14] | Park et al. [15] | CoRe16 [11] | SAFA | |
|---|---|---|---|---|
| Area () | 4.44 | 4.06 | 4.14 | 3.93 |
| Power (mw) | 3715.3 | 3390.1 | 3456.9 | 3320.8 |
| Park et al. [15] | CoRe16 [11] | SAFA | |
|---|---|---|---|
| Area () | 0.0147 | 0.0154 | 0.0141 |
| Power (mw) | 12.6 | 13.1 | 12.2 |
| FPS | 1.74 | 1.69 | 1.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, S.; Wang, L.; Xu, S.; Guo, S.; Yang, Z.; Zhang, J.; Xu, W. A Systolic Accelerator for Neuromorphic Visual Recognition. Electronics 2020, 9, 1690. https://doi.org/10.3390/electronics9101690
Tian S, Wang L, Xu S, Guo S, Yang Z, Zhang J, Xu W. A Systolic Accelerator for Neuromorphic Visual Recognition. Electronics. 2020; 9(10):1690. https://doi.org/10.3390/electronics9101690
Chicago/Turabian StyleTian, Shuo, Lei Wang, Shi Xu, Shasha Guo, Zhijie Yang, Jianfeng Zhang, and Weixia Xu. 2020. "A Systolic Accelerator for Neuromorphic Visual Recognition" Electronics 9, no. 10: 1690. https://doi.org/10.3390/electronics9101690
APA StyleTian, S., Wang, L., Xu, S., Guo, S., Yang, Z., Zhang, J., & Xu, W. (2020). A Systolic Accelerator for Neuromorphic Visual Recognition. Electronics, 9(10), 1690. https://doi.org/10.3390/electronics9101690