Brain-Inspired Self-Organization with Cellular Neuromorphic Computing for Multimodal Unsupervised Learning




Abstract
1. Introduction
2. Multimodal Learning: State of the Art
2.1. Brain-Inspired Approaches: Reentry and Convergence Divergence Zone (CDZ)
2.2. Models and Applications
2.2.1. Sensori-Motor Mapping
2.2.2. Multi-Sensory Classification
2.2.3. Summary
3. Proposed Model: Reentrant Self-Organizing Map (ReSOM)
3.1. Unimodal Post-Labeled Unsupervised Learning with Self-Organizing Maps (SOMs)
3.1.1. SOM Learning
| Algorithm 1: SOM unimodal learning |
|
3.1.2. SOM Labeling
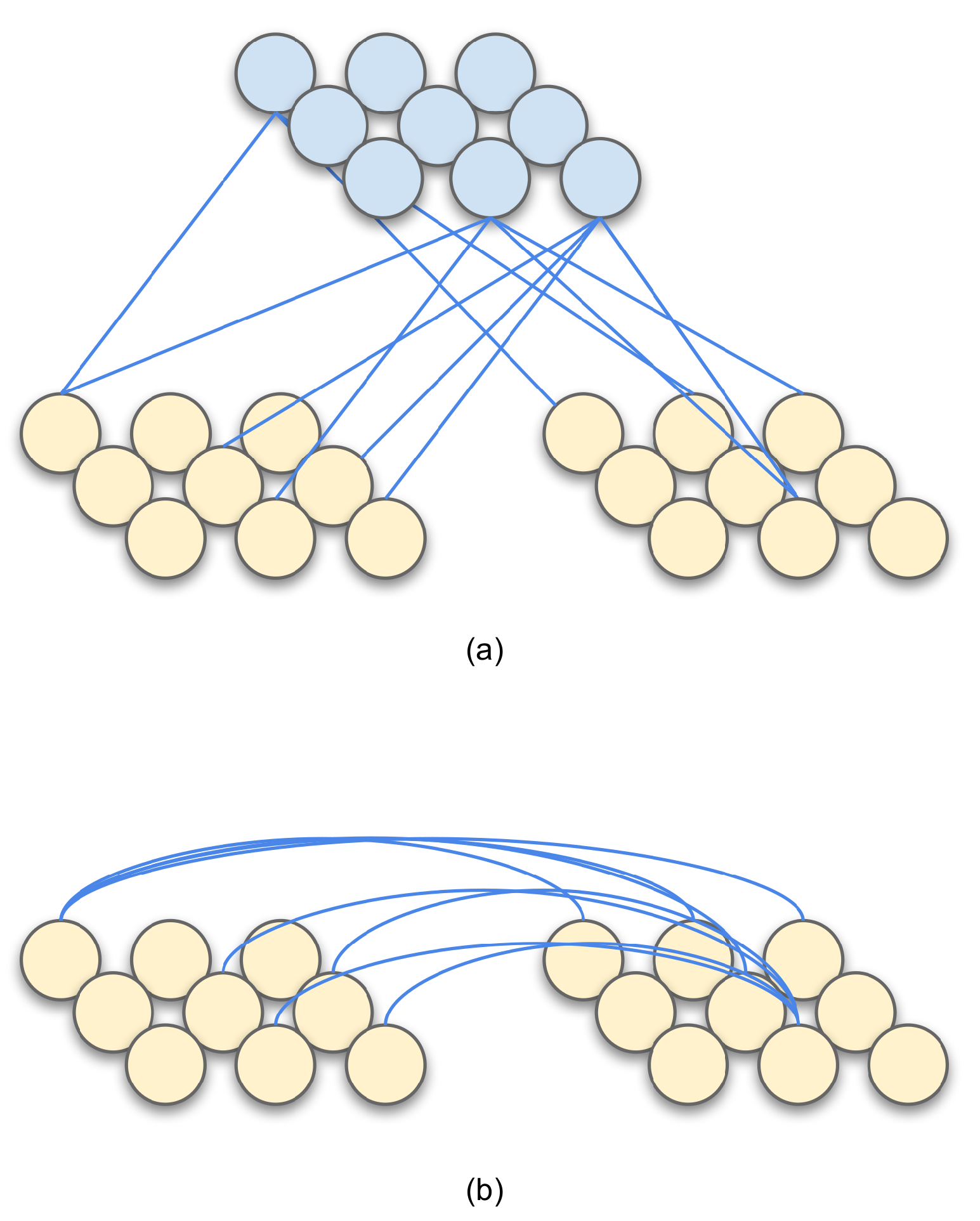
3.2. ReSOM Multimodal Association: Sprouting, Hebbian-Like Learning and Pruning
| Algorithm 2: ReSOM multimodal association learning |
|
3.3. ReSOM Divergence for Labeling
| Algorithm 3: ReSOM divergence for labeling |
|
3.4. ReSOM Convergence for Classification
- First, there is an independent activity computation (Equation (13)): each neuron of the two SOMs computes its activity based on the afferent activity from the input.
- Third and finally, there is a global competition amongst all neurons (line 19 in Algorithm 4): they all compete to elect a winner, that is, a global BMU with respect to the two SOMs.
| Algorithm 4: ReSOM convergence for classification |
|
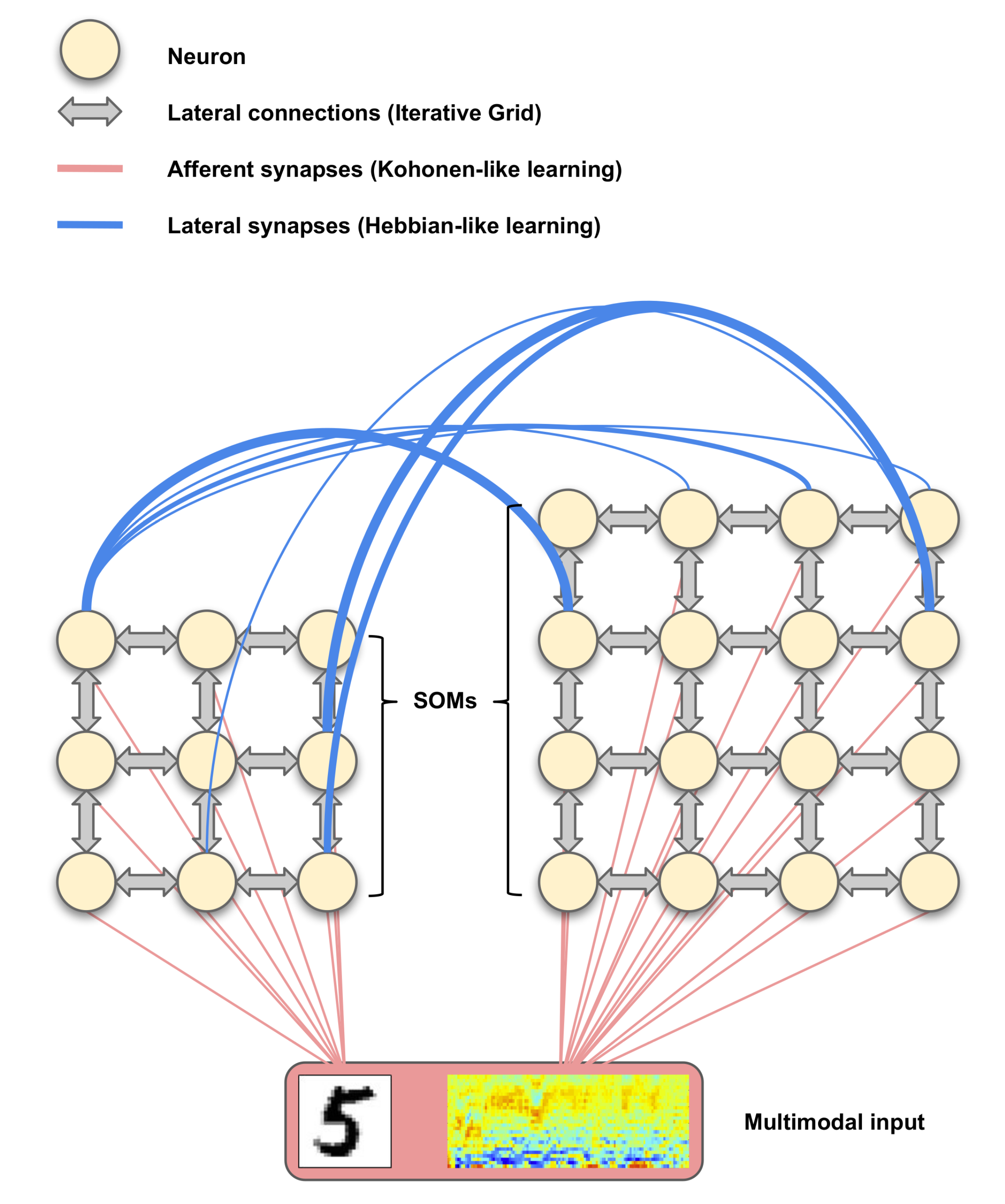
4. Cellular Neuromorphic Architecture
4.1. The Iterative Grid (IG) Substrata
4.2. Iterative Grid for SOM Model
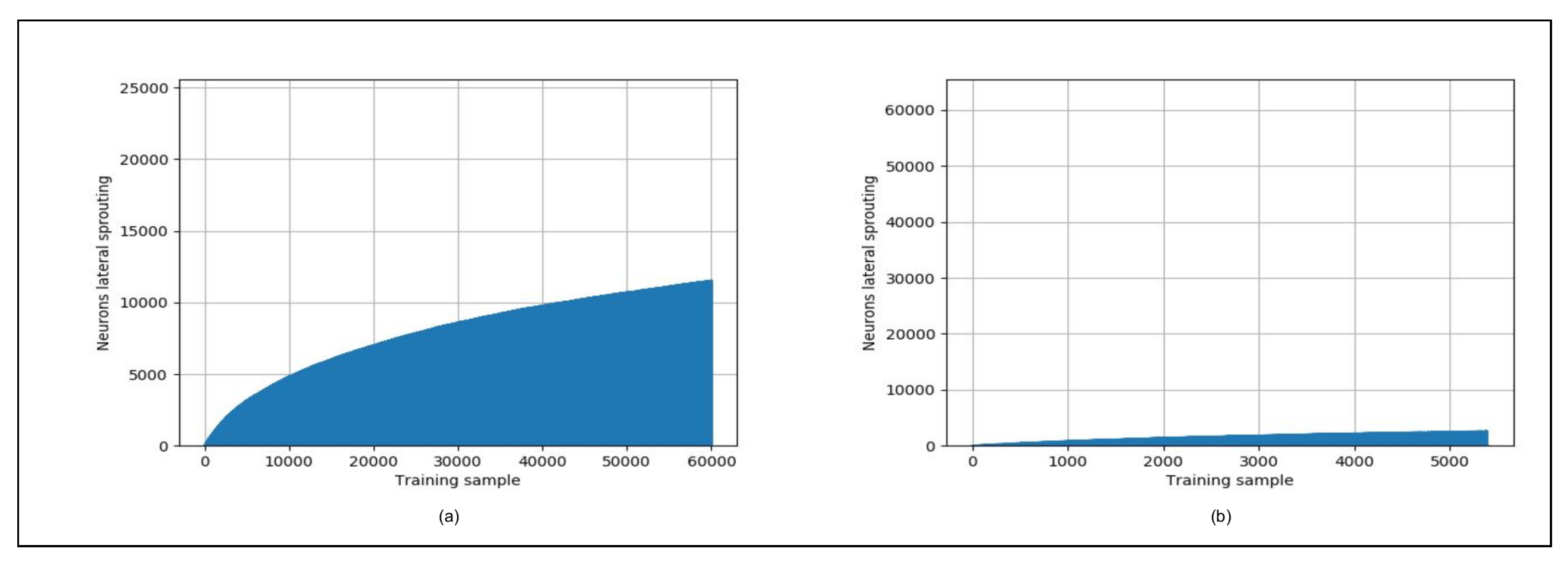
4.3. Hardware Support for the Iterative Grid
- Waves complexity: The “smallest of 5” and “neighborhood” waves in Reference [81] have been coupled into one wave called the “winner wave”, as the iterative grid is based on time to distance transformation to find the Manhattan distance between the BMU and each neuron. We have therefore a gain of about in the time complexity of the SOM training.
- Sequential vs. combinatory architecture: The processes of calculating the neuron distances to the input vector, searching for the BMU and updating the weight vectors are performed in a single clock cycle. This assumption goes against the iterative computing paradigm in the SOM grid to propagate the neurons information. Hence, the hardware implementation in Reference [81] is almost fully combinatory. It explains why the maximum operating frequency is low and decreases when increasing the number of neurons, thus being not scalable in terms of both hardware resources and latency.
4.4. Hardware Support for Multimodal Association
5. Experiments and Results
5.1. Databases
5.1.1. Written/Spoken Digits Database
5.1.2. DVS/EMG Hand Gestures Database
5.2. SOM Unimodal Classification
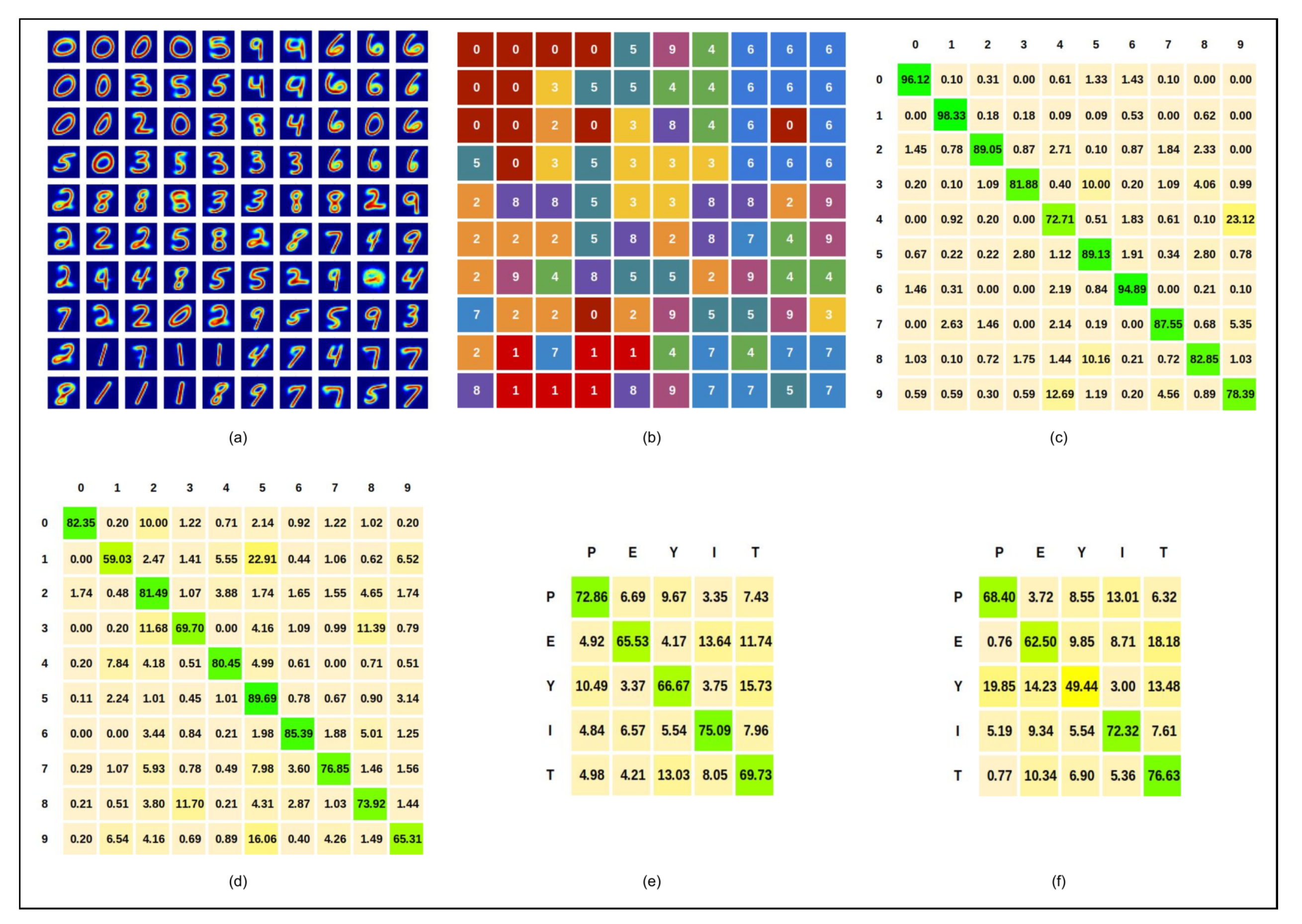
5.2.1. Written Digits
5.2.2. Spoken Digits
5.2.3. DVS Hand Gestures
5.2.4. EMG Hand Gestures
5.3. ReSOM Multimodal Classification
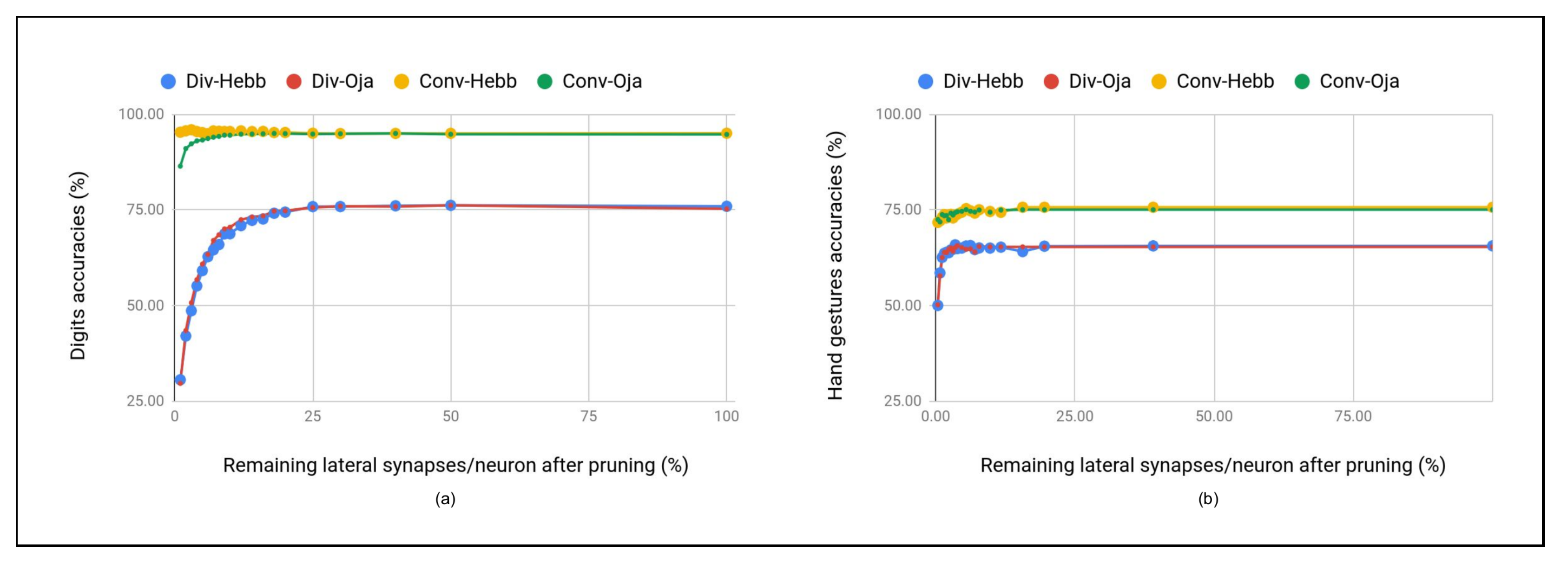
5.3.1. ReSOM Divergence Results
5.3.2. ReSOM Convergence Results
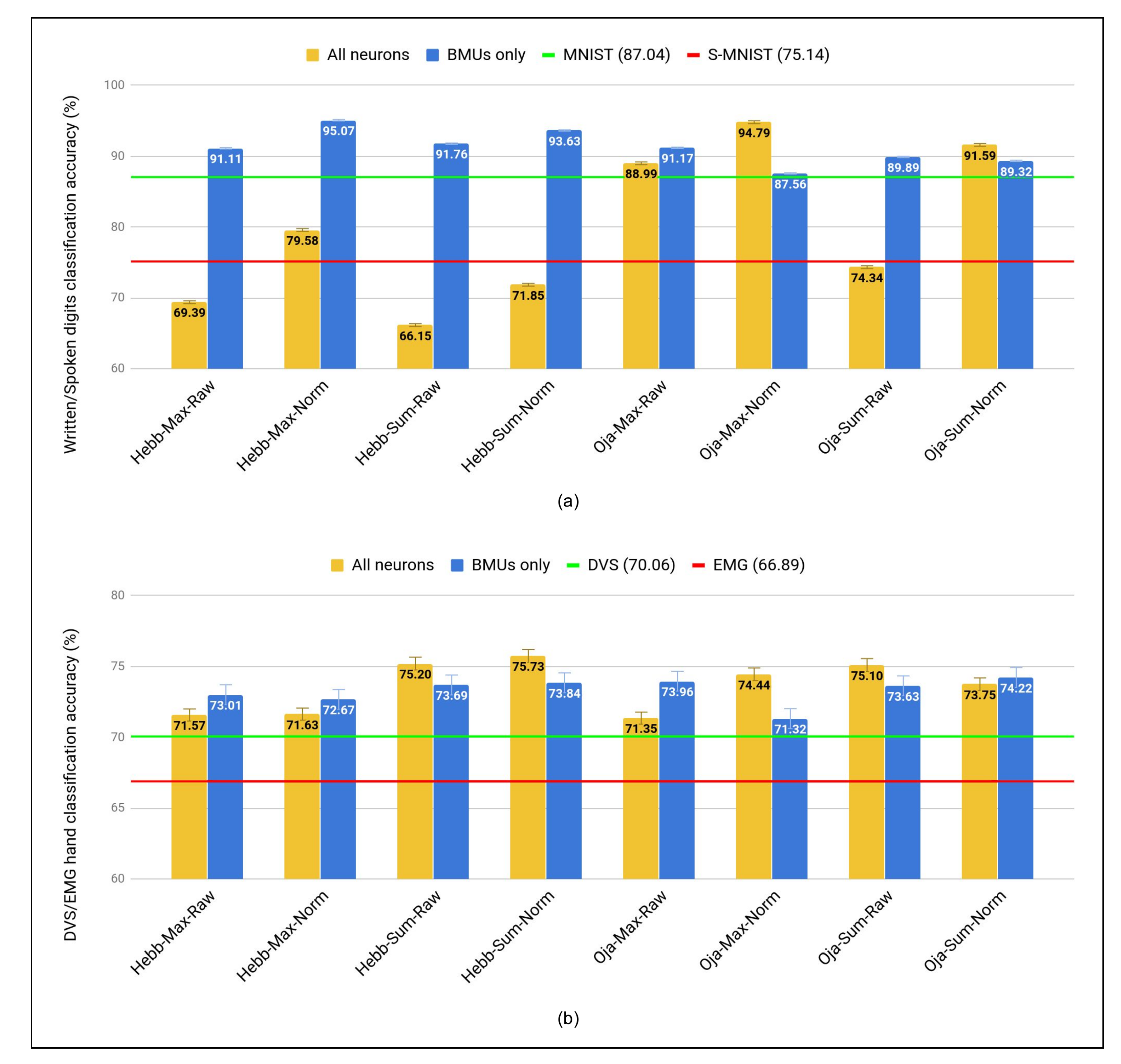
5.4. Comparative Study
5.4.1. SOMs vs. SNNs Approaches for Unsupervised Learning
- The cross-modal connections are formed randomly and initialized with random weights. The multimodal STDP learning is therefore limited to connections that have been randomly decided, which induces an important variation in the network performance.
- The cross-modal connections are not bi-directional, thus breaking with the biological foundations of reentry and CDZ. Half the connections carry spikes from image to audio neurons and the other half carry spikes from audio to image neurons, otherwise making the system unstable.
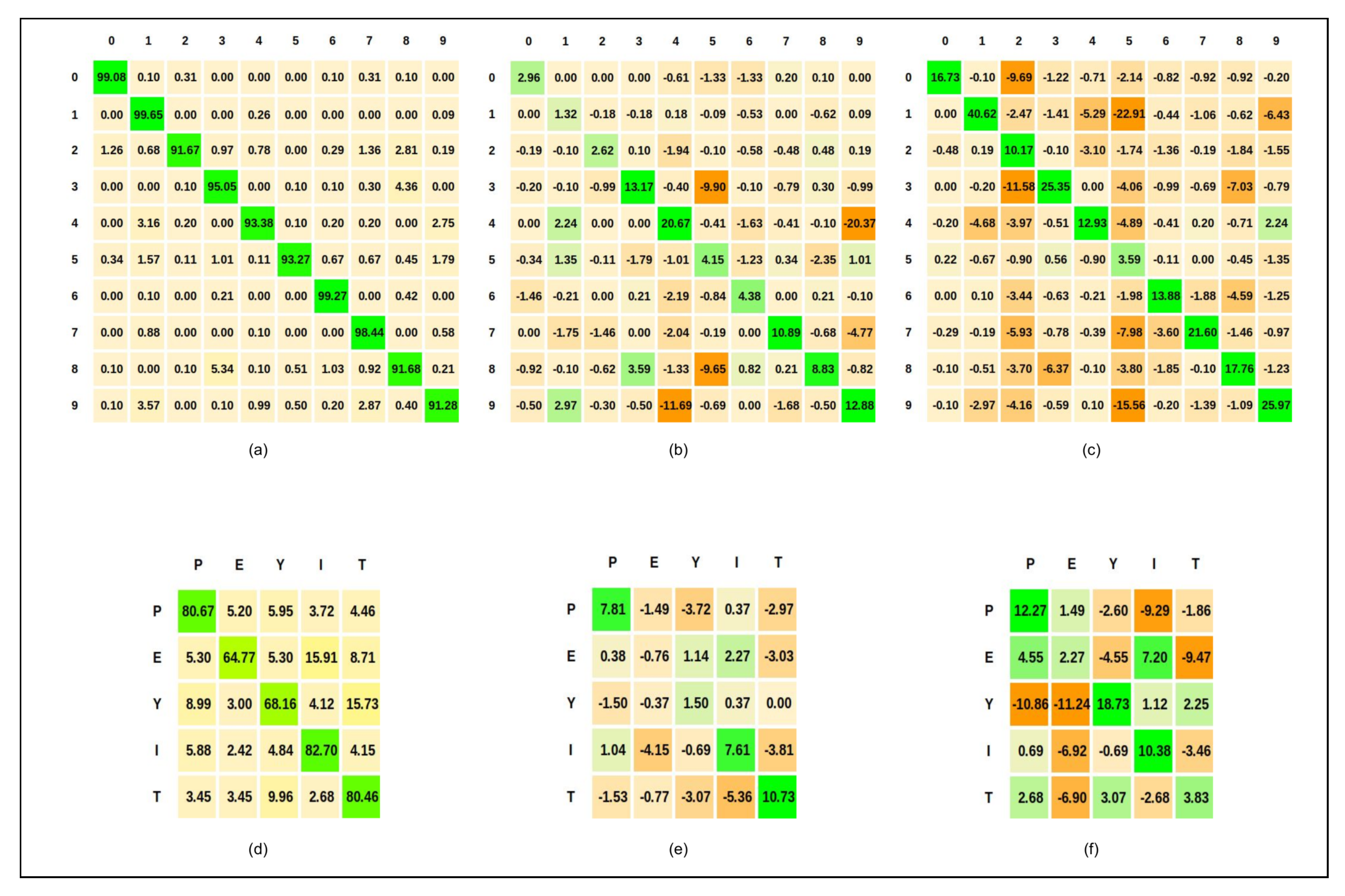
- The accuracy goes down beyond connections. When the number of random cross-modal connections is increased, the neurons that have learned different label gets connected. We do not observe such a behavior in the ReSOM, as shown in Figure 6.
- The SNN computation is distributed, but requires an all-to-all connectivity amongst neurons. This full connectivity goes against the scalability of the network as discussed in Section 4.
- The decision of the multimodal network is computed by observing the spiking activity in both ensembles, thus requiring a central unit.
5.4.2. SOM Early Data Fusion
5.4.3. SOMs Coupled to Supervised Fusion
6. Discussion
6.1. A Universal Multimodal Association Model?
6.2. SOMA: Toward Hardware Plasticity
7. Conclusions and Further Works
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sternberg, R.J. Handbook of Intelligence; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar] [CrossRef]
- Smith, L.; Gasser, M. The Development of Embodied Cognition: Six Lessons from Babies. Artif. Life 2005, 11, 13–29. [Google Scholar] [CrossRef]
- Droniou, A.; Ivaldi, S.; Sigaud, O. Deep unsupervised network for multimodal perception, representation and classification. Robot. Auton. Syst. 2015, 71, 83–98. [Google Scholar] [CrossRef]
- Edelman, G.M. Neural Darwinism: The Theory of Neuronal Group Selection; Basic Books: New York, NY, USA, 1987. [Google Scholar]
- Edelman, G.M.; Gally, J.A. Degeneracy and complexity in biological systems. Proc. Natl. Acad. Sci. USA 2001, 98, 13763–13768. [Google Scholar] [CrossRef] [PubMed]
- Lahat, D.; Adali, T.; Jutten, C. Multimodal Data Fusion: An Overview of Methods, Challenges, and Prospects. Proc. IEEE 2015, 103, 1449–1477. [Google Scholar] [CrossRef]
- Shivappa, S.T.; Trivedi, M.M.; Rao, B.D. Audiovisual Information Fusion in Human–Computer Interfaces and Intelligent Environments: A Survey. Proc. IEEE 2010, 98, 1692–1715. [Google Scholar] [CrossRef]
- Rivet, B.; Wang, W.; Naqvi, S.M.; Chambers, J.A. Audiovisual Speech Source Separation: An overview of key methodologies. IEEE Signal Process. Mag. 2014, 31, 125–134. [Google Scholar] [CrossRef]
- Pitti, A.; Blanchard, A.; Cardinaux, M.; Gaussier, P. Gain-field modulation mechanism in multimodal networks for spatial perception. In Proceedings of the 2012 12th IEEE-RAS International Conference on Humanoid Robots (Humanoids 2012), Osaka, Japan, 29 November–1 December 2012; pp. 297–302. [Google Scholar] [CrossRef]
- Fiack, L.; Cuperlier, N.; Miramond, B. Embedded and Real-Time Architecture for Bio-Inspired Vision-Based Robot Navigation. J. Real-Time Image Process. 2015, 10, 699–722. [Google Scholar] [CrossRef]
- Braun, S.; Neil, D.; Anumula, J.; Ceolini, E.; Liu, S. Attention-driven Multi-sensor Selection. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Zhao, D.; Zeng, Y. Dynamic Fusion of Convolutional Features based on Spatial and Temporal Attention for Visual Tracking. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Tan, A.H.; Subagdja, B.; Wang, D.; Meng, L. Self-organizing neural networks for universal learning and multimodal memory encoding. Neural Netw. 2019. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Z.; Du, J. Deep Fusion: An Attention Guided Factorized Bilinear Pooling for Audio-video Emotion Recognition. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Turk, M. Multimodal interaction: A review. Pattern Recognit. Lett. 2014, 36, 189–195. [Google Scholar] [CrossRef]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; van Kasteren, T.; Liao, W.; Bellens, R.; Pizurica, A.; Gautama, S.; et al. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7. [Google Scholar] [CrossRef]
- Hoeks, C.; Barentsz, J.; Hambrock, T.; Yakar, D.; Somford, D.; Heijmink, S.; Scheenen, T.; Vos, P.; Huisman, H.; van Oort, I.; et al. Prostate Cancer: Multiparametric MR Imaging for Detection, Localization, and Staging. Radiology 2011, 261, 46–66. [Google Scholar] [CrossRef] [PubMed]
- Horwitz, B.; Poeppel, D. How can EEG/MEG and fMRI/PET data be combined? Hum. Brain Mapp. 2002, 17, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Edelman, G.M. Group selection and phasic reentrant signaling: A theory of higher brain function. In Proceedings of the 4th Intensive Study Program of the Neurosciences Research Program, Boston, MA, USA, 1982. [Google Scholar]
- Damasio, A.R. Time-locked multiregional retroactivation: A systems-level proposal for the neural substrates of recall and recognition. Cognition 1989, 33, 25–62. [Google Scholar] [CrossRef]
- Rodriguez, L.; Khacef, L.; Miramond, B. A distributed cellular approach of large scale SOM models for hardware implementation. In Proceedings of the IEEE International Conference on Image Processing, Applications and Systems (IPAS), Sophia Antipolis, France, 12–14 December 2018. [Google Scholar]
- Escobar-Juárez, E.; Schillaci, G.; Hermosillo-Valadez, J.; Lara-Guzmán, B. A Self-Organized Internal Models Architecture for Coding Sensory–Motor Schemes. Front. Robot. AI 2016, 3, 22. [Google Scholar] [CrossRef]
- Varela, F.J.; Thompson, E.T.; Rosch, E. The Embodied Mind: Cognitive Science and Human Experience; new edition; The MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Meyer, K.; Damasio, A. Convergence and divergence in a neural architecture for recognition and memory. Trends Neurosci. 2009, 32, 376–382. [Google Scholar] [CrossRef] [PubMed]
- Man, K.; Damasio, A.; Meyer, K.; Kaplan, J.T. Convergent and invariant object representations for sight, sound, and touch. Hum. Brain Mapp. 2015, 36, 3629–3640. [Google Scholar] [CrossRef]
- Kiefer, M.; Sim, E.J.; Herrnberger, B.; Grothe, J.; Hoenig, K. The Sound of Concepts: Four Markers for a Link between Auditory and Conceptual Brain Systems. J. Neurosci. Off. J. Soc. Neurosci. 2008, 28, 12224–12230. [Google Scholar] [CrossRef]
- González, J.; Barrós-Loscertales, A.; Pulvermüller, F.; Meseguer, V.; Sanjuán, A.; Belloch, V.; Avila, C. Reading cinnamon activates olfactory brain regions. NeuroImage 2006, 32, 906–912. [Google Scholar] [CrossRef]
- Sathian, K.; Zangaladze, A. Feeling with the mind’s eye: Contribution of visual cortex to tactile perception. Behav. Brain Res. 2002, 135, 127–132. [Google Scholar] [CrossRef]
- Calvert, G.A. Crossmodal Processing in the Human Brain: Insights from Functional Neuroimaging Studies. Cereb. Cortex 2001, 11, 1110–1123. [Google Scholar] [CrossRef]
- Kriegstein, K.; Giraud, A.L. Implicit Multisensory Associations Influence Voice Recognition. PLoS Biol. 2006, 4, e326. [Google Scholar] [CrossRef]
- Edelman, G.M. Neural Darwinism: Selection and reentrant signaling in higher brain function. Neuron 1993, 10, 115–125. [Google Scholar] [CrossRef]
- Edelman, G.; Gally, J. Reentry: A Key Mechanism for Integration of Brain Function. Front. Integr. Neurosci. 2013, 7, 63. [Google Scholar] [CrossRef] [PubMed]
- Singer, W. The formation of cooperative cell assemblies in the visual cortex. J. Exp. Biol. 1990, 153, 177–197. [Google Scholar]
- Shatz, C.J. How are specific connections formed between thalamus and cortex? Curr. Opin. Neurobiol. 1992, 2, 78–82. [Google Scholar] [CrossRef]
- Douglas, R.J.; Martin, K.A. Neuronal Circuits of the Neocortex. Annu. Rev. Neurosci. 2004, 27, 419–451. [Google Scholar] [CrossRef]
- Rutishauser, U.; Douglas, R.J. State-Dependent Computation Using Coupled Recurrent Networks. Neural Comput. 2009, 21, 478–509. [Google Scholar] [CrossRef]
- Damasio, A.R.; Damasio, H. Cortical Systems for Retrieval of Concrete Knowledge: The Convergence Zone Framework. In Large-Scale Neuronal Theories of the Brain; Koch, C., Davis, J., Eds.; MIT Press: Cambridge, MA, USA, 1994; pp. 61–74. [Google Scholar]
- Lallee, S.; Dominey, P.F. Multi-modal convergence maps: From body schema and self-representation to mental imagery. Adapt. Behav. 2013, 21, 274–285. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Wolpert, D.; Kawato, M. Multiple paired forward and inverse models for motor control. Neural Netw. 1998, 11, 1317–1329. [Google Scholar] [CrossRef]
- Hebb, D.O. The Organization of Behavior: A Neuropsychological Theory; Wiley: New York, NY, USA, 1949. [Google Scholar]
- Zahra, O.; Navarro-Alarcon, D. A Self-organizing Network with Varying Density Structure for Characterizing Sensorimotor Transformations in Robotic Systems. In Annual Conference Towards Autonomous Robotic Systems; Althoefer, K., Konstantinova, J., Zhang, K., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 167–178. [Google Scholar]
- Oja, E. Simplified neuron model as a principal component analyzer. J. Math. Biol. 1982, 15, 267–273. [Google Scholar] [CrossRef] [PubMed]
- Parisi, G.I.; Tani, J.; Weber, C.; Wermter, S. Emergence of multimodal action representations from neural network self-organization. Cogn. Syst. Res. 2017, 43, 208–221. [Google Scholar] [CrossRef]
- Marsland, S.; Shapiro, J.; Nehmzow, U. A Self-organising Network That Grows when Required. Neural Netw. 2002, 15, 1041–1058. [Google Scholar] [CrossRef]
- Jayaratne, M.; Alahakoon, D.; Silva, D.D.; Yu, X. Bio-Inspired Multisensory Fusion for Autonomous Robots. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3090–3095. [Google Scholar]
- Alahakoon, D.; Halgamuge, S.K.; Srinivasan, B. Dynamic self-organizing maps with controlled growth for knowledge discovery. IEEE Trans. Neural Netw. 2000, 11, 601–614. [Google Scholar] [CrossRef]
- Rathi, N.; Roy, K. STDP-Based Unsupervised Multimodal Learning With Cross-Modal Processing in Spiking Neural Network. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 1–11. [Google Scholar] [CrossRef]
- Diehl, P.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef]
- Cholet, S.; Paugam-Moisy, H.; Regis, S. Bidirectional Associative Memory for Multimodal Fusion: A Depression Evaluation Case Study. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Azcarraga, A.; Giacometti, A. A prototype-based incremental network model for classification tasks. In Proceedings of the Fourth International Conference on Neural Networks and their Applications, Nimes, France, 4–8 November 1991; pp. 121–134. [Google Scholar]
- Khacef, L.; Miramond, B.; Barrientos, D.; Upegui, A. Self-organizing neurons: Toward brain-inspired unsupervised learning. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Gu, L.; Li, H. Memory or Time: Performance Evaluation for Iterative Operation on Hadoop and Spark. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications 2013 IEEE International Conference on Embedded and Ubiquitous Computing, Zhangjiajie, China, 13–15 November 2013; pp. 721–727. [Google Scholar] [CrossRef]
- Barth, D.S.; Goldberg, N.; Brett, B.; Di, S. The spatiotemporal organization of auditory, visual, and auditory-visual evoked potentials in rat cortex. Brain Res. 1995, 678, 177–190. [Google Scholar] [CrossRef]
- Allman, B.L.; Keniston, L.P.; Meredith, M.A. Not Just for Bimodal Neurons Anymore: The Contribution of Unimodal Neurons to Cortical Multisensory Processing. Brain Topogr. 2009, 21, 157–167. [Google Scholar] [CrossRef]
- Lefort, M.; Boniface, Y.; Girau, B. SOMMA: Cortically Inspired Paradigms for Multimodal Processing. In Proceedings of the International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Calvert, G.; Spence, C.; Stein, B. The Handbook of Multisensory Processing; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Bizley, J.K.; King, A.J. Visual–auditory spatial processing in auditory cortical neurons. Brain Res. 2008, 1242, 24–36. [Google Scholar] [CrossRef]
- Cappe, C.; Rouiller, E.M.; Barone, P. Multisensory anatomical pathways. Hear. Res. 2009, 258, 28–36. [Google Scholar] [CrossRef]
- Schroeder, C.; Foxe, J. Multisensory contributions to low-level, ‘unisensory’ processing. Curr. Opin. Neurobiol. 2005, 15, 454–458. [Google Scholar] [CrossRef] [PubMed]
- Dehner, L.R.; Keniston, L.P.; Clemo, H.R.; Meredith, M.A. Cross-modal Circuitry Between Auditory and Somatosensory Areas of the Cat Anterior Ectosylvian Sulcal Cortex: A ‘New’ Inhibitory Form of Multisensory Convergence. Cereb. Cortex 2004, 14, 387–403. [Google Scholar] [CrossRef] [PubMed]
- Fiebelkorn, I.C.; Foxe, J.J.; Molholm, S. Dual mechanisms for the cross-sensory spread of attention: How much do learned associations matter? Cereb. Cortex 2010, 20, 109–120. [Google Scholar] [CrossRef] [PubMed]
- Chum, L.; Subramanian, A.; Balasubramanian, V.N.; Jawahar, C.V. Beyond Supervised Learning: A Computer Vision Perspective. J. Indian Inst. Sci. 2019, 99, 177–199. [Google Scholar] [CrossRef]
- Kohonen, T.; Schroeder, M.R.; Huang, T.S. (Eds.) Self-Organizing Maps, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Kohonen, T.; Oja, E.; Simula, O.; Visa, A.; Kangas, J. Engineering applications of the self-organizing map. Proc. IEEE 1996, 84, 1358–1384. [Google Scholar] [CrossRef]
- Silva, D.D.; Ranasinghe, W.K.B.; Bandaragoda, T.R.; Adikari, A.; Mills, N.; Iddamalgoda, L.; Alahakoon, D.; Lawrentschuk, N.L.; Persad, R.; Osipov, E.; et al. Machine learning to support social media empowered patients in cancer care and cancer treatment decisions. PLoS ONE 2018, 13, e0205855. [Google Scholar] [CrossRef]
- Nallaperuma, D.; Silva, D.D.; Alahakoon, D.; Yu, X. Intelligent Detection of Driver Behavior Changes for Effective Coordination Between Autonomous and Human Driven Vehicles. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3120–3125. [Google Scholar]
- Kromes, R.; Russo, A.; Miramond, B.; Verdier, F. Energy consumption minimization on LoRaWAN sensor network by using an Artificial Neural Network based application. In Proceedings of the 2019 IEEE Sensors Applications Symposium (SAS), Sophia Antipolis, France, 11–13 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C. MNIST Handwritten Digit Database. 1998. Available online: http://yann.lecun.com/exdb/mnist/.
- Fauth, M.; Tetzlaff, C. Opposing Effects of Neuronal Activity on Structural Plasticity. Front. Neuroanat. 2016, 10, 75. [Google Scholar] [CrossRef]
- Goodhill, G.J.; Barrow, H.G. The Role of Weight Normalization in Competitive Learning. Neural Comput. 1994, 6, 255–269. [Google Scholar] [CrossRef]
- Fyfe, C. A Neural Network for PCA and Beyond. Neural Process. Lett. 1997, 6, 33–41. [Google Scholar] [CrossRef]
- Asano, M.; Imai, M.; Kita, S.; Kitajo, K.; Okada, H.; Thierry, G. Sound symbolism scaffolds language development in preverbal infants. Cortex 2015, 63, 196–205. [Google Scholar] [CrossRef]
- Kemeny, J.G. Theory of Self-Reproducing Automata. John von Neumann. Edited by Arthur W. Burks. University of Illinois Press, Urbana, 1966. 408 pp., illus. 10. Science 1967, 157, 180. [Google Scholar] [CrossRef]
- Wolfram, S. Universality and complexity in cellular automata. Phys. D Nonlinear Phenom. 1984, 10, 1–35. [Google Scholar] [CrossRef]
- Halbach, M.; Hoffmann, R. Implementing cellular automata in FPGA logic. In Proceedings of the 18th International Parallel and Distributed Processing Symposium, Santa Fe, NM, USA, 26–30 April 2004; p. 258. [Google Scholar] [CrossRef]
- Kyparissas, N.; Dollas, A. An FPGA-Based Architecture to Simulate Cellular Automata with Large Neighborhoods in Real Time. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 95–99. [Google Scholar] [CrossRef]
- Walsh, D.; Dudek, P. A compact FPGA implementation of a bit-serial SIMD cellular processor array. In Proceedings of the 2012 13th International Workshop on Cellular Nanoscale Networks and their Applications, Turin, Italy, 29–31 August 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Schuman, C.D.; Potok, T.E.; Patton, R.M.; Birdwell, J.D.; Dean, M.E.; Rose, G.S.; Plank, J.S. A Survey of Neuromorphic Computing and Neural Networks in Hardware. arXiv 2017, arXiv:1705.06963. [Google Scholar]
- Blazewicz, J.; Ecker, K.; Plateau, B.; Trystram, D. Handbook on Parallel and Distributed Processing; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar] [CrossRef]
- de Abreu de Sousa, M.A.; Del-Moral-Hernandez, E. An FPGA distributed implementation model for embedded SOM with on-line learning. In Proceedings of the 2017 International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar] [CrossRef]
- Fiack, L.; Rodriguez, L.; Miramond, B. Hardware design of a neural processing unit for bio-inspired computing. In Proceedings of the 2015 IEEE 13th International New Circuits and Systems Conference (NEWCAS), Grenoble, France, 7–10 June 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Rodriguez, L.; Fiack, L.; Miramond, B. A neural model for hardware plasticity in artificial vision systems. In Proceedings of the Conference on Design and Architectures for Signal and Image Processing, Cagliari, Italy, 8–10 October 2013. [Google Scholar]
- Vannel, F.; Barrientos, D.; Schmidt, J.; Abegg, C.; Buhlmann, D.; Upegui, A. SCALP: Self-configurable 3-D Cellular Adaptive Platform. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1307–1312. [Google Scholar] [CrossRef]
- Kheradpisheh, S.R.; Ganjtabesh, M.; Thorpe, S.J.; Masquelier, T. STDP-based spiking deep convolutional neural networks for object recognition. Neural Netw. 2018, 99, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Khacef, L.; Rodriguez, L.; Miramond, B. Written and spoken digits database for multimodal learning. 2019. [Google Scholar] [CrossRef]
- Ceolini, E.; Taverni, G.; Payvand, M.; Donati, E. EMG and Video Dataset for Sensor Fusion Based Hand Gestures Recognition; European Commission: Brussels, Belgium, 2019. [Google Scholar] [CrossRef]
- Ceolini, E.; Taverni, G.; Khacef, L.; Payvand, M.; Donati, E. Sensor fusion using EMG and vision for hand gesture classification in mobile applications. In Proceedings of the 2019 IEEE Biomedical Circuits and Systems Conference (BioCAS), Nara, Japan, 17–19 October 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Ceolini, E.; Frenkel, C.; Shrestha, S.B.; Taverni, G.; Khacef, L.; Payvand, M.; Donati, E. Hand-Gesture Recognition Based on EMG and Event-Based Camera Sensor Fusion: A Benchmark in Neuromorphic Computing. Front. Neurosci. 2020, 14, 637. [Google Scholar] [CrossRef]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 X 128 120db 30mw asynchronous vision sensor that responds to relative intensity change. In Proceedings of the 2006 IEEE International Solid State Circuits Conference-Digest of Technical Papers, San Francisco, CA, USA, 6–9 February 2006; pp. 2060–2069. [Google Scholar]
- Ceolini, E.; Taverni, G.; Khacef, L.; Payvand, M.; Donati, E. Live Demostration: Sensor fusion using EMG and vision for hand gesture classification in mobile applications. In Proceedings of the 2019 IEEE Biomedical Circuits and Systems Conference (BioCAS), Nara, Japan, 17–19 October 2019; p. 1. [Google Scholar] [CrossRef]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Barbancho, J. Non-sequential automatic classification of anuran sounds for the estimation of climate-change indicators. Expert Syst. Appl. 2018, 95, 248–260. [Google Scholar] [CrossRef]
- Darabkh, K.A.; Haddad, L.; Sweidan, S.; Hawa, M.; Saifan, R.R.; Alnabelsi, S.H. An efficient speech recognition system for arm-disabled students based on isolated words. Comp. Applic. Eng. Educ. 2018, 26, 285–301. [Google Scholar] [CrossRef]
- Pan, Z.; Li, H.; Wu, J.; Chua, Y. An Event-Based Cochlear Filter Temporal Encoding Scheme for Speech Signals. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Mermelstein, P. Distance measures for speech recognition, psychological and instrumental. In Pattern Recognition and Artificial Intelligence; Chen, R., Ed.; Academic Press: New York, NY, USA, 1976; pp. 374–388. [Google Scholar]
- Chapaneri, S. Spoken Digits Recognition using Weighted MFCC and Improved Features for Dynamic Time Warping. Int. J. Comput. Appl. 2012, 40, 6–12. [Google Scholar] [CrossRef]
- Sainath, T.; Parada, C. Convolutional Neural Networks for Small-Footprint Keyword Spotting. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Khacef, L.; Rodriguez, L.; Miramond, B. Improving Self-Organizing Maps with Unsupervised Feature Extraction. In Proceedings of the 2020 International Conference on Neural Information Processing (ICONIP), Bangkok, Thailand, 18–22 November 2020. [Google Scholar]
- Falez, P.; Tirilly, P.; Bilasco, I.M.; Devienne, P.; Boulet, P. Unsupervised visual feature learning with spike-timing-dependent plasticity: How far are we from traditional feature learning approaches? Pattern Recognit. 2019, 93, 418–429. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Phinyomark, A.; N Khushaba, R.; Scheme, E. Feature Extraction and Selection for Myoelectric Control Based on Wearable EMG Sensors. Sensors 2018, 18, 1615. [Google Scholar] [CrossRef] [PubMed]
- Liberman, M.; Amsler, R.; Church, K.; Fox, E.; Hafner, C.; Klavans, J.; Marcus, M.; Mercer, B.; Pedersen, J.; Roossin, P.; et al. TI 46-Word LDC93S9 Database. 1991. Available online: https://catalog.ldc.upenn.edu/LDC93S9.
- Khacef, L.; Abderrahmane, N.; Miramond, B. Confronting machine-learning with neuroscience for neuromorphic architectures design. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- O’Connor, P.; Neil, D.; Liu, S.C.; Delbruck, T.; Pfeiffer, M. Real-time classification and sensor fusion with a spiking deep belief network. Front. Neurosci. 2013, 7, 178. [Google Scholar] [CrossRef]
- Hazan, H.; Saunders, D.; Sanghavi, D.T.; Siegelmann, H.; Kozma, R. Unsupervised Learning with Self-Organizing Spiking Neural Networks. In Proceedings of the 2018 International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Baltrusaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Chen, L.; Shen, Y.; Chen, G. Activity recognition exploiting classifier level fusion of acceleration and physiological signals. In Proceedings of the UbiComp 2014-Adjunct Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 63–66. [Google Scholar] [CrossRef]
- Peng, L.; Chen, L.; Wu, X.; Guo, H.; Chen, G. Hierarchical complex activity representation and recognition using topic model and classifier level fusion. IEEE Trans. Biomed. Eng. 2016, 64, 1369–1379. [Google Scholar] [CrossRef] [PubMed]
- Biagetti, G.; Crippa, P.; Falaschetti, L. Classifier Level Fusion of Accelerometer and sEMG Signals for Automatic Fitness Activity Diarization. Sensors 2018, 18, 2850. [Google Scholar] [CrossRef]
- Castanedo, F. A Review of Data Fusion Techniques. Sci. World J. 2013, 2013, 704504. [Google Scholar] [CrossRef]
- Ursino, M.; Cuppini, C.; Magosso, E. Neurocomputational approaches to modelling multisensory integration in the brain: A review. Neural Netw. Off. J. Int. Neural Netw. Soc. 2014, 60, 141–165. [Google Scholar] [CrossRef]
- Vavrecka, M.; Farkas, I. A Multimodal Connectionist Architecture for Unsupervised Grounding of Spatial Language. Cogn. Comput. 2013, 6, 101–112. [Google Scholar] [CrossRef]
- Morse, A.F.; Benitez, V.L.; Belpaeme, T.; Cangelosi, A.; Smith, L.B. Posture Affects How Robots and Infants Map Words to Objects. PLoS ONE 2015, 10, e0116012. [Google Scholar] [CrossRef]
- de Andrade, D.C.; Leo, S.; Viana, M.L.D.S.; Bernkopf, C. A neural attention model for speech command recognition. arXiv 2018, arXiv:1808.08929. [Google Scholar]
- Khacef, L.; Girau, B.; Rougier, N.P.; Upegui, A.; Miramond, B. Neuromorphic hardware as a self-organizing computing system. In Proceedings of the IJCNN 2018 Neuromorphic Hardware in Practice and Use Workshop, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Heylighen, F.; Gershenson, C. The Meaning of Self-Organization in Computing. IEEE Intell. Syst. 2003, 18, 72–75. [Google Scholar] [CrossRef]
- Khacef, L.; Rodriguez, L.; Miramond, B. Brain-inspired self-organization with cellular neuromorphic computing for multimodal unsupervised learning. arXiv 2020, arXiv:2004.05488. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Work | Paradigm | Learning | Computing |
|---|---|---|---|---|
| Sensori-motor mapping | Lallee et al. [38] (2013) | CDZ | Unsupervised | Centralized |
| Droniou et al. [3] (2015) | CDZ | Unsupervised | Centralized | |
| Escobar-Juarez et al. [22] (2016) | CDZ | Unsupervised | Centralized | |
| Zahra et al. [42] (2019) | Reentry | Unsupervised | Centralized | |
| Multi-sensory classification | Parisi et al. [44] (2017) | Reentry | Semi-supervised | Centralized |
| Jayaratne et al. [46] (2018) | Reentry | Semi-supervised | Distributed (data level) | |
| Rathi et al. [48] (2018) | Reentry | Unsupervised | Centralized ** | |
| Cholet et al. [50] (2019) | Reentry * | Supervised | Centralized | |
| Khacef et al. [this work] (2020) | Reentry | Unsupervised | Distributed (system level) |
| Database | Digits | Hand Gestures | |||
|---|---|---|---|---|---|
| MNIST | S-MNIST | DVS | EMG | ||
| SOMs | Dimensions | 784 | 507 | 972 | 192 |
| Neurons | 100 | 256 | 256 | 256 | |
| Labeled data (%) | 1 | 10 | 10 | 10 | |
| Accuracy (%) | 87.04 | 75.14 | 70.06 | 66.89 | |
| ReSOM Divergence | Labeled data (%) | 1 | 0 | 10 | 0 |
| Gain (%) | / | +0.76 | / | -1.33 | |
| Accuracy (%) | / | 75.90 | / | 65.56 | |
| ReSOM Convergence | Gain (%) | +8.03 | +19.17 | +5.67 | +10.17 |
| Accuracy (%) | 95.07 | 75.73 | |||
| Learning | ReSOM Convergence Method and Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Update Algorithm | Neurons Activities | Digits | Hand Gestures | |||
| All Neurons | BMUs Only | All Neurons | BMUs Only | |||
| Hebb | Max | Raw | 69.39 | 91.11 | 71.57 | 73.01 |
| Norm | 79.58 | 95.07 | 71.63 | 72.67 | ||
| Sum | Raw | 66.15 | 91.76 | 75.20 | 73.69 | |
| Norm | 71.85 | 93.63 | 75.73 | 73.84 | ||
| Oja | Max | Raw | 88.99 | 91.17 | 71.35 | 73.96 |
| Norm | 94.79 | 87.56 | 74.44 | 71.32 | ||
| Sum | Raw | 74.34 | 89.89 | 75.10 | 73.63 | |
| Norm | 91.59 | 89.32 | 73.75 | 74.22 | ||
| ANN | Model | Neurons | Labels (%) * | Modality | Dataset | Accuracy (%) |
|---|---|---|---|---|---|---|
| SNN | Diehl et al. [49] (2015) | 400 | 100 | Unimodal | MNIST | 88.74 |
| Hazan et al. [106] (2018) | 400 | 100 | Unimodal | MNIST | 92.56 | |
| Rathi et al. [48] (2018) | 400 | 100 | Unimodal | MNIST | 86.00 | |
| Rathi et al. [48] (2018) | 400 | 100 | Multimodal | MNIST + TI46 | 89.00 | |
| SOM | Khacef et al. [this work] (2020) | 356 | 1 | Multimodal | MNIST + SMNIST | 95.07 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khacef, L.; Rodriguez, L.; Miramond, B. Brain-Inspired Self-Organization with Cellular Neuromorphic Computing for Multimodal Unsupervised Learning. Electronics 2020, 9, 1605. https://doi.org/10.3390/electronics9101605
Khacef L, Rodriguez L, Miramond B. Brain-Inspired Self-Organization with Cellular Neuromorphic Computing for Multimodal Unsupervised Learning. Electronics. 2020; 9(10):1605. https://doi.org/10.3390/electronics9101605
Chicago/Turabian StyleKhacef, Lyes, Laurent Rodriguez, and Benoît Miramond. 2020. "Brain-Inspired Self-Organization with Cellular Neuromorphic Computing for Multimodal Unsupervised Learning" Electronics 9, no. 10: 1605. https://doi.org/10.3390/electronics9101605
APA StyleKhacef, L., Rodriguez, L., & Miramond, B. (2020). Brain-Inspired Self-Organization with Cellular Neuromorphic Computing for Multimodal Unsupervised Learning. Electronics, 9(10), 1605. https://doi.org/10.3390/electronics9101605