Spatiotemporal Feature Learning Based Hour-Ahead Load Forecasting for Energy Internet

Abstract
1. Introduction
2. Proposed Solution
2.1. Model Input Data
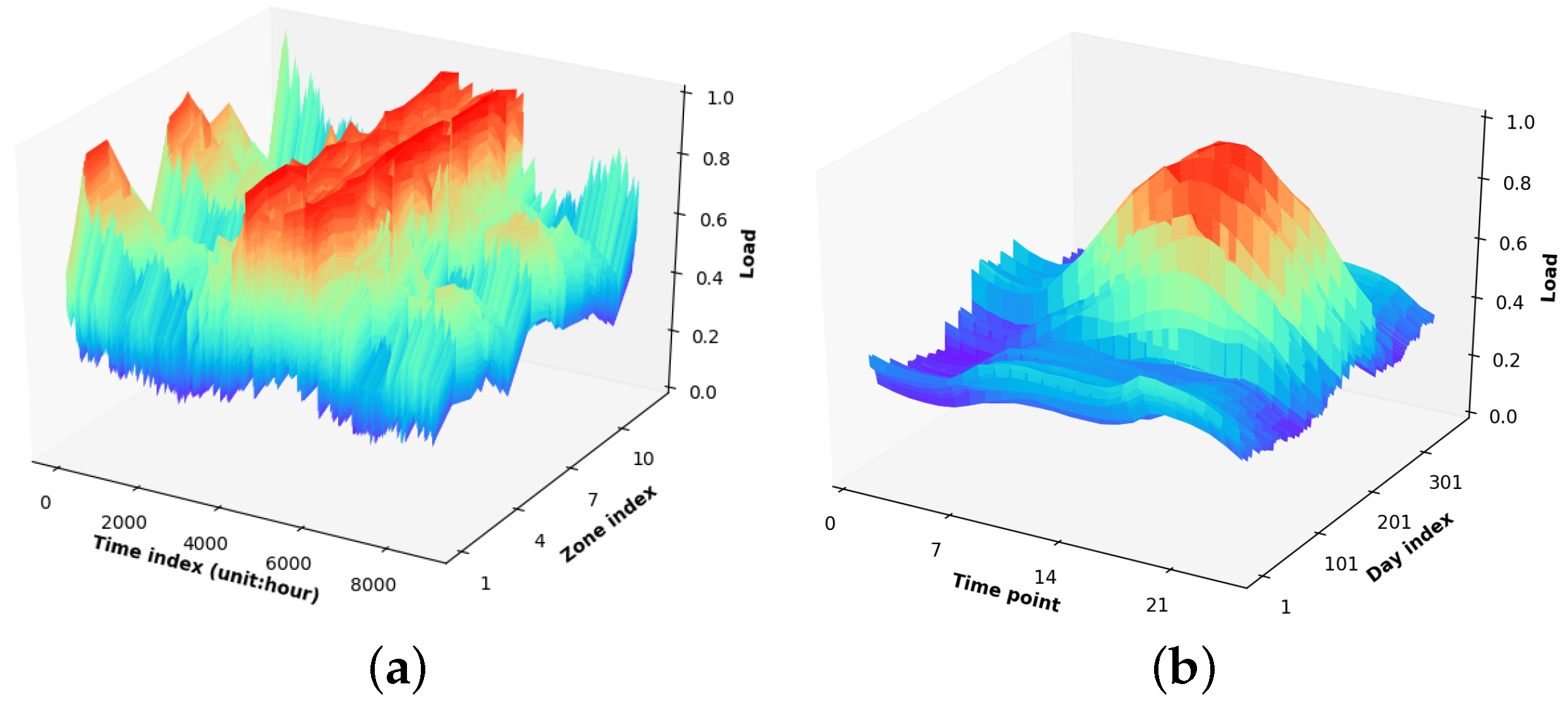
2.1.1. Historical Load Tensor
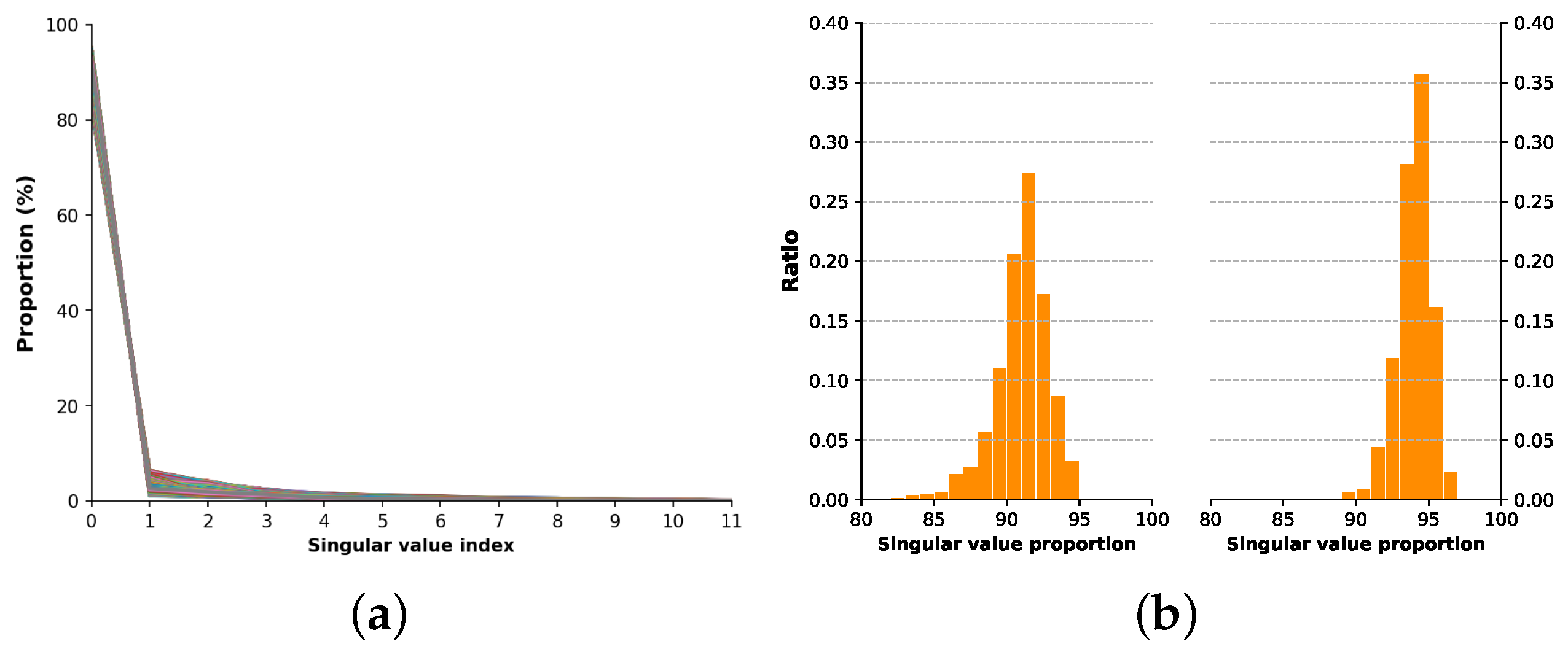
2.1.2. Load Tensor Decomposition
| Algorithm 1 Distributed augmented Lagrange multipliers algorithm. |
|
2.1.3. Load Gradient
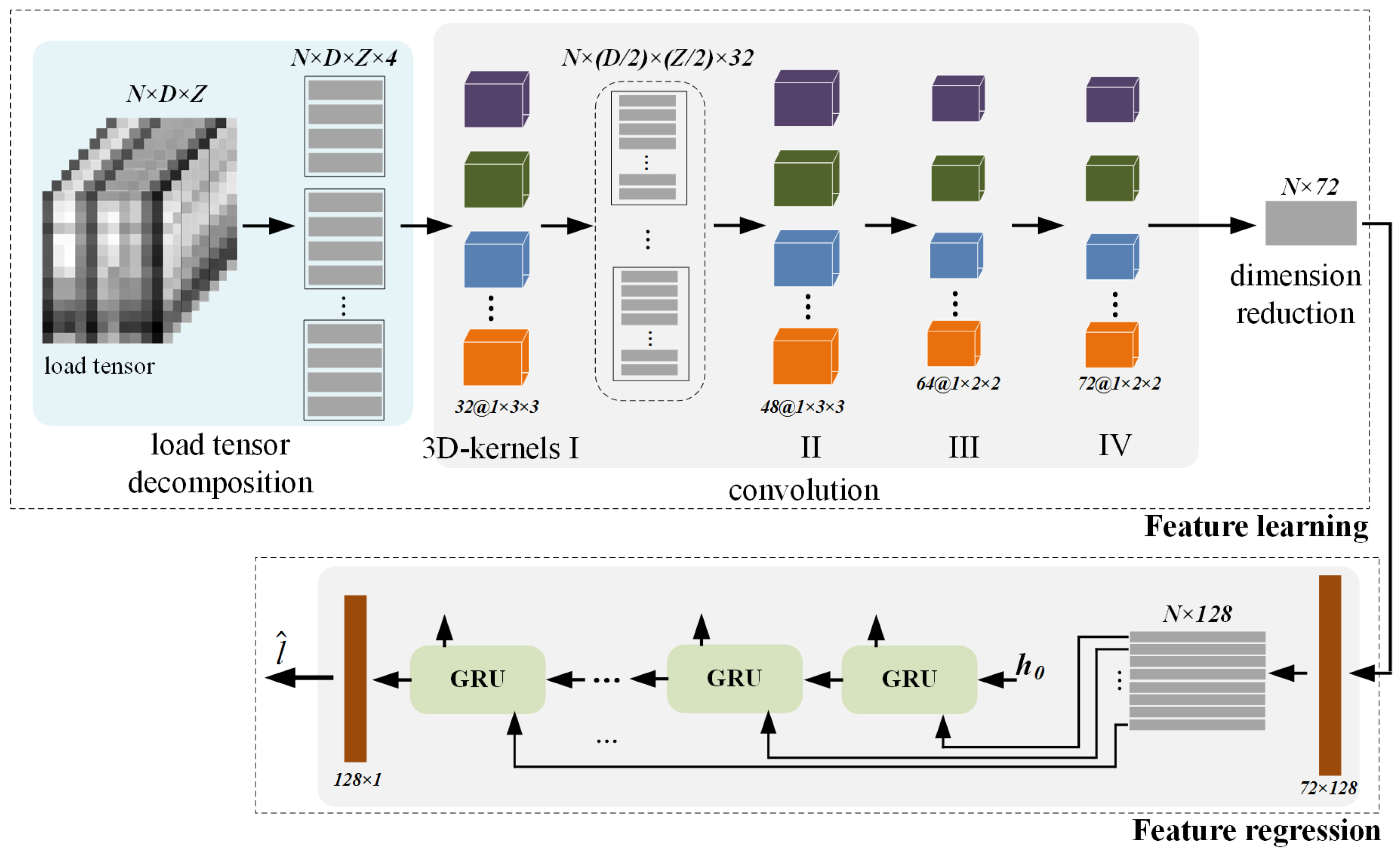
2.2. 3D CNN-GRU
2.2.1. Learning Module
2.2.2. Regression Module
2.2.3. Training
3. Experiments and Analysis
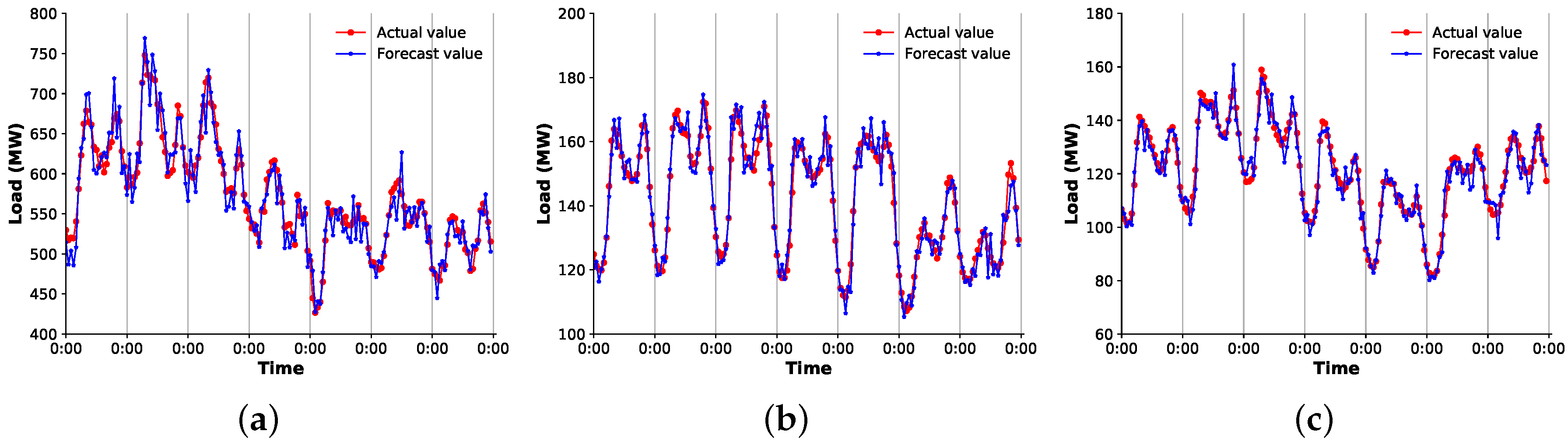
3.1. Data Description
3.2. Comparison Methods
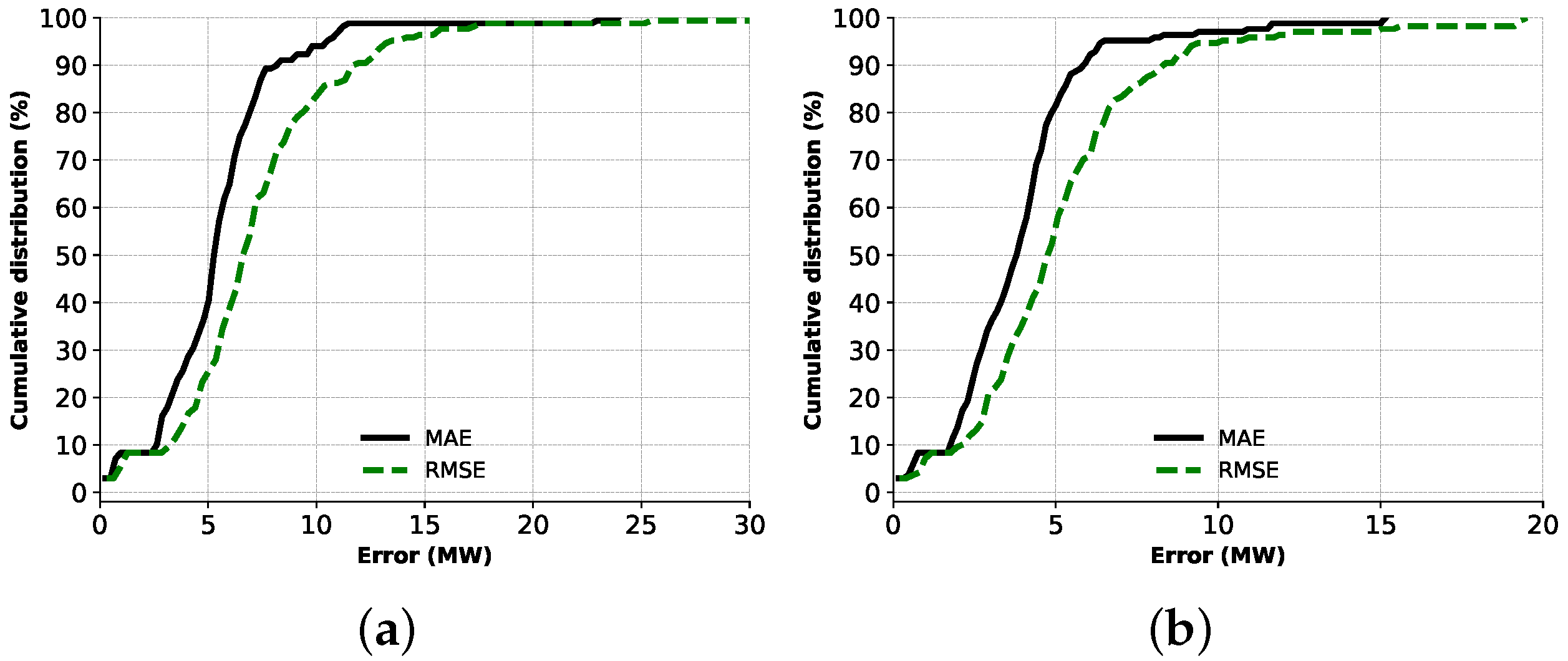
3.3. Performance Evaluation
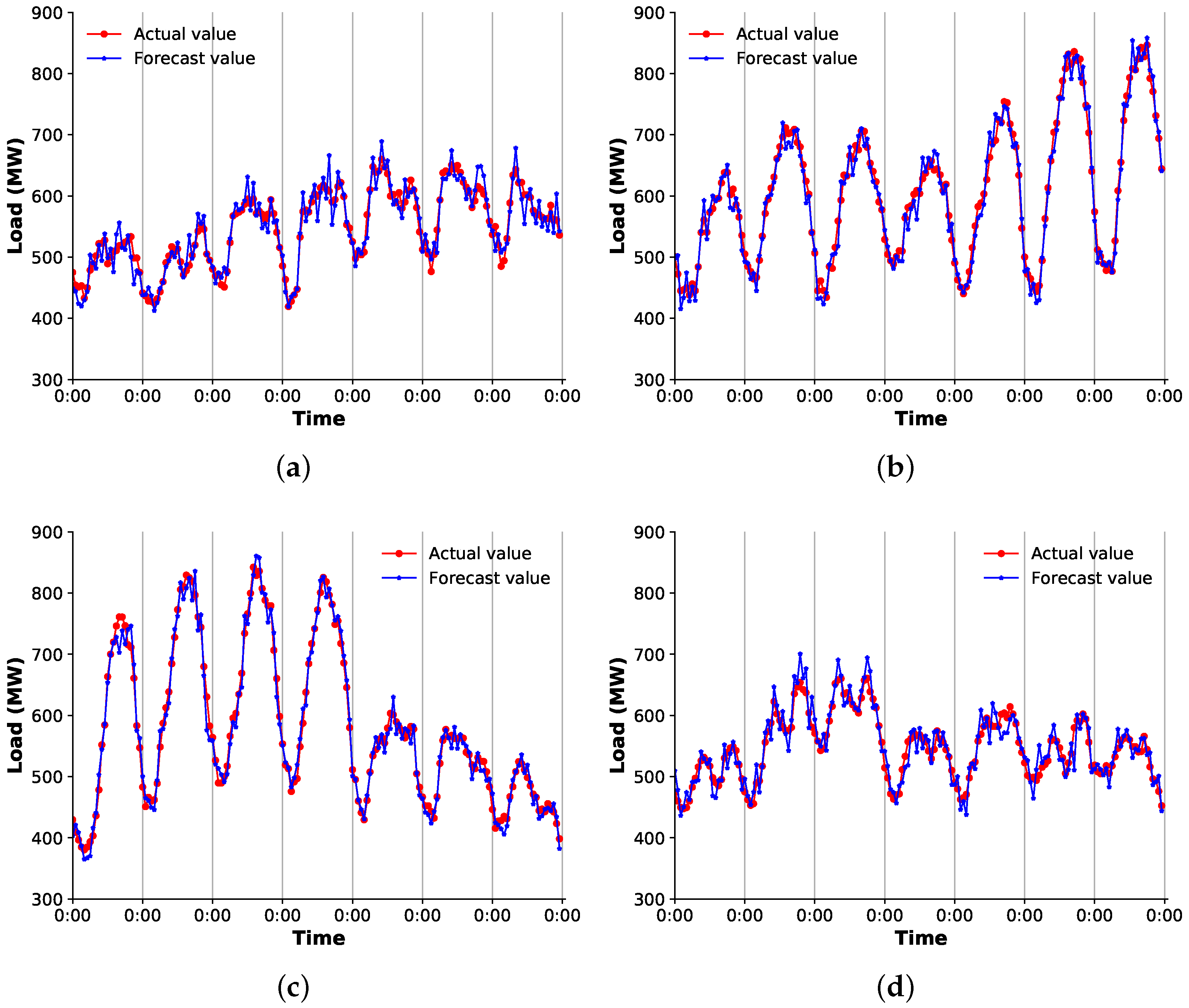
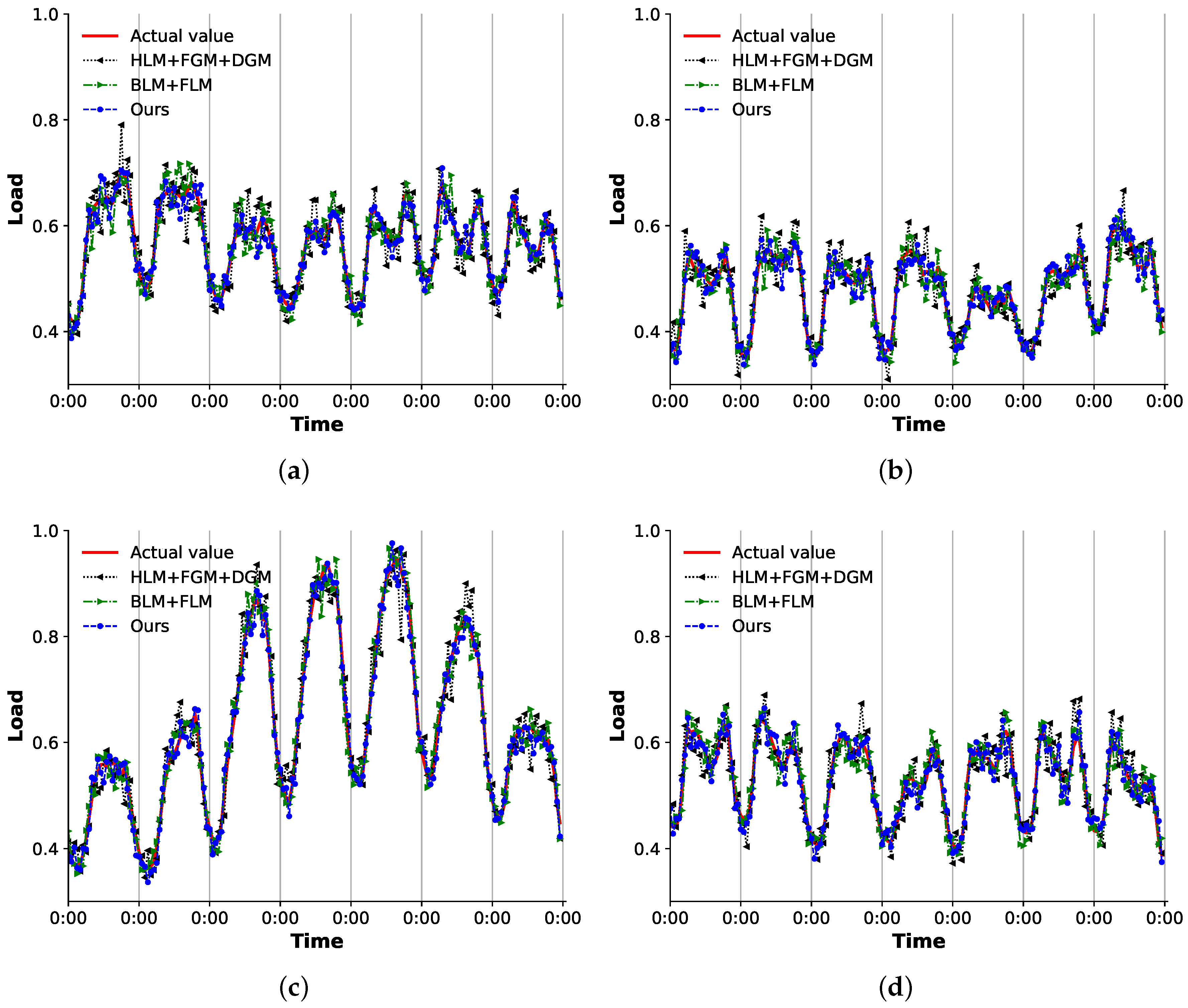
3.4. Performance Comparison
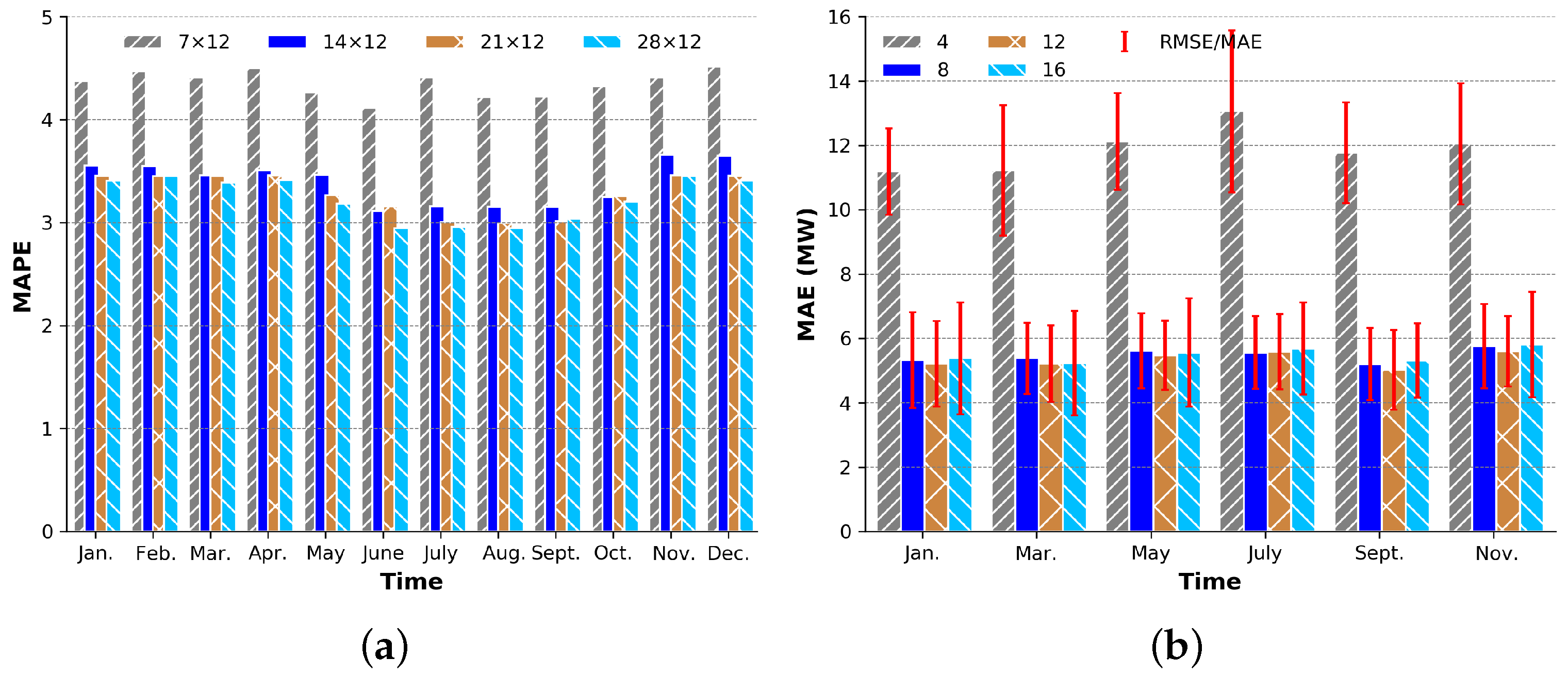
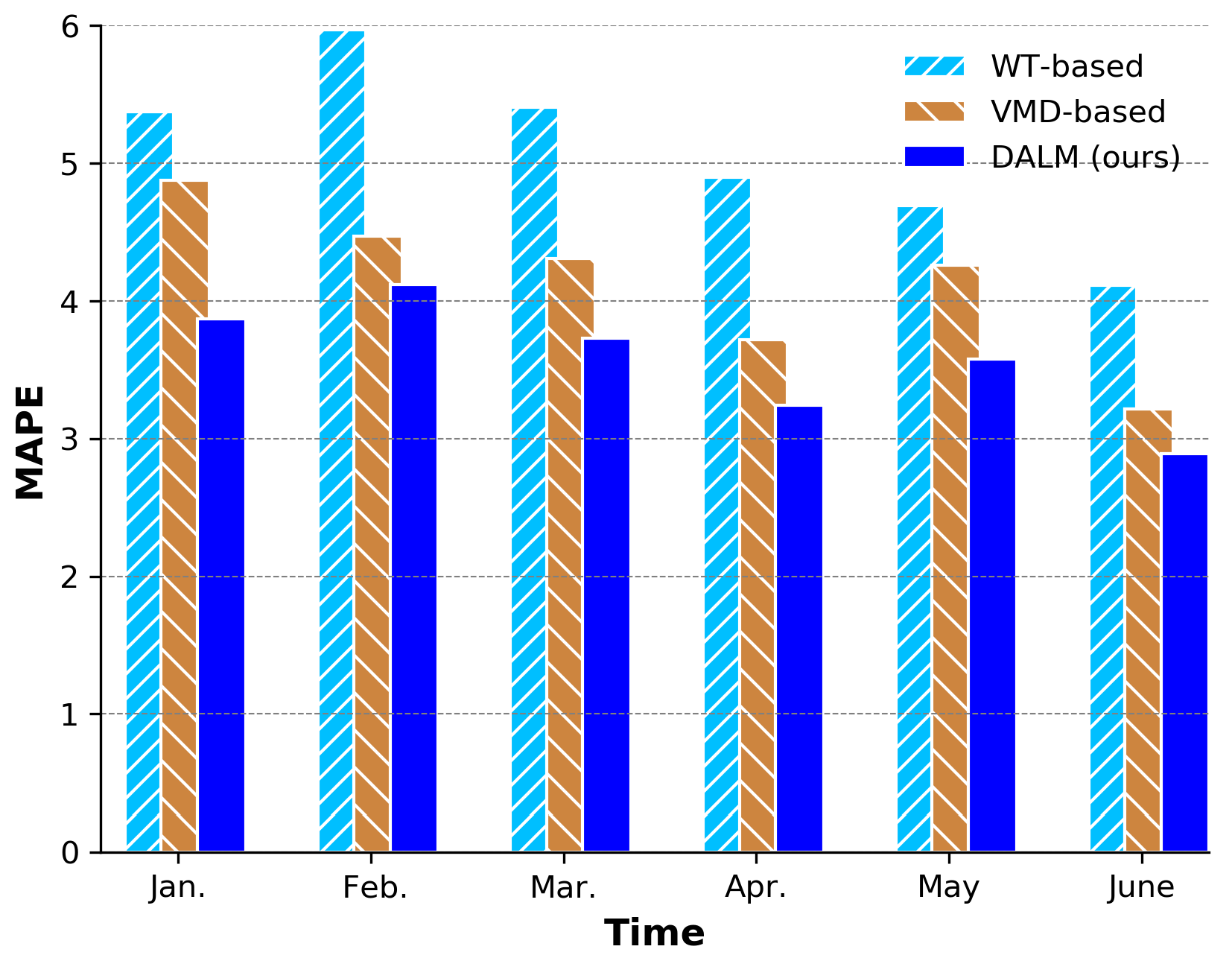
3.4.1. Data Preprocessing Algorithm
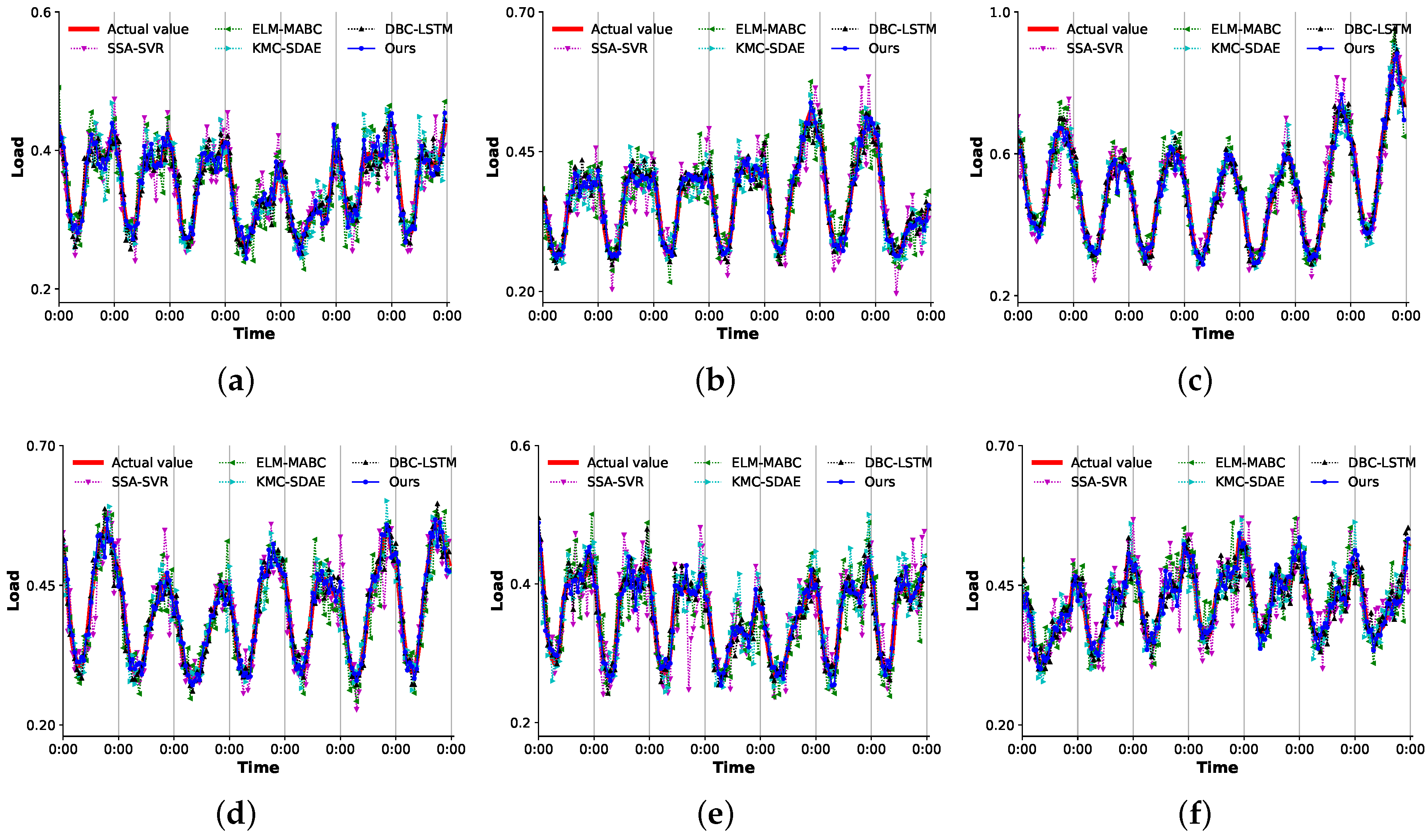
3.4.2. Comparison of the Overall Scheme
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huang, A.Q.; Crow, M.L.; Heydt, G.T.; Zheng, J.P.; Dale, S.J. The future renewable electric energy delivery and management (FREEDM) system: The energy Internet. Proc. IEEE 2011, 99, 133–148. [Google Scholar] [CrossRef]
- Wang, K.; Yu, J.; Yu, Y.; Qian, Y.; Zeng, D.; Guo, S.; Xiang, Y.; Wu, J. A survey on energy Internet: Architecture approach and emerging technologies. IEEE Syst. J. 2018, 12, 2403–2416. [Google Scholar] [CrossRef]
- Tsoukalas, L.; Gao, R. From smart grids to an energy internet: Assumptions, architectures and requirements. In Proceedings of the 3rd International Conference on Electric Utility Deregulation and Restructuring and Power Technologies, Nanjing, China, 6–9 April 2008; pp. 94–98. [Google Scholar]
- Sun, Q.; Zhang, Y.; He, H.; Ma, D.; Zhang, H. A novel energy function based stability evaluation and nonlinear control approach for energy internet. IEEE Trans. Smart Grid 2017, 8, 1195–1210. [Google Scholar] [CrossRef]
- Hippert, H.S.; Pedreira, C.E.; Souza, R.C. Neural networks for short-term load forecasting: A review and evaluation. IEEE Trans. Power Syst. 2001, 16, 44–55. [Google Scholar] [CrossRef]
- Reis, A.J.R.; da Silva, A.P.A. Feature extraction via multiresolution analysis for short-term load forecasting. IEEE Trans. Power Syst. 2005, 20, 189–198. [Google Scholar]
- Ceperic, E.; Ceperic, V.; Baric, A. A strategy for short-term load forecasting by support vector regression machines. IEEE Trans. Power Syst. 2013, 28, 4356–4364. [Google Scholar] [CrossRef]
- Lin, Y.; Luo, H.; Wang, D.; Guo, H.; Zhu, K. An ensemble model based on machine learning methods and data preprocessing for short-term electric load forecasting. Energies 2017, 10, 1186. [Google Scholar] [CrossRef]
- Jiang, H.; Zhang, Y.; Muljadi, E. Zhang, J.J.; Gao, D.W. A short-term and high-resolution distribution system load forecasting approach using support vector regression with hybrid parameters optimization. IEEE Trans. Smart Grid 2018, 9, 3341–3350. [Google Scholar] [CrossRef]
- Metaxiotis, K.; Kagiannas, A.; Askounis, D.; Psarras, J. Artificial intelligence in short term electric load forecasting: A state-of-the-art survey for the researcher. Energy Convers. Manag. 2003, 44, 1525–1534. [Google Scholar] [CrossRef]
- Cerne, G.; Dovzan, D.; Skrjanc, I. Short-term load forecasting by separating daily profile and using a single fuzzy model across the entire domain. IEEE Trans. Ind. Electron. 2018, 65, 7406–7415. [Google Scholar] [CrossRef]
- Ko, C.N.; Lee, C.M. Short-term load forecasting using svr (support vector regression) based radial basis function neural network with dual extended kalman filter. Energy 2013, 49, 413–422. [Google Scholar] [CrossRef]
- Li, S.; Wang, P.; Goel, L. Short-term load forecasting by wavelet transform and evolutionary extreme learning machine. Electr. Power Syst. Res. 2015, 122, 96–103. [Google Scholar] [CrossRef]
- Fan, G.-F.; Peng, L.-L.; Hong, W.-C. Short term load forecasting based on phase space reconstruction algorithm and bi-square kernel regression model. Appl. Energy 2018, 224, 13–33. [Google Scholar] [CrossRef]
- Fan, G.-F.; Guo, Y.-H.; Zheng, J.-M.; Hong, W.-C. Application of the weighted k-nearest neighbor algorithm for short-term load forecasting. Energies 2019, 12, 916. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Khafaf, N.A.; Jalili, M.; Sokolowski, P. Application of deep learning long short-term memory in energy demand forecasting. arXiv 2019, arXiv:1903.1194. [Google Scholar]
- Din, G.M.U.; Marnerides, A.K. Short term power load forecasting using deep neural networks. In Proceedings of the International Conference on Computing, Networking and Communications, Santa Clara, CA, USA, 26–29 January 2017; pp. 1–5. [Google Scholar]
- Li, L.; Ota, K.; Dong, M. Everything is image: CNN based short-term electrical load forecasting for smart grid. In Proceedings of the IEEE CS ISPAN-FCST-ISCC 2017, Exeter, UK, 21–23 June 2017; pp. 344–351. [Google Scholar]
- Shi, H.; Xu, M.; Li, R. Deep learning for household load forecasting—a novel pooling deep RNN. IEEE Trans. Smart Grid 2018, 9, 271–5280. [Google Scholar] [CrossRef]
- Marino, D.L.; Amarasinghe, K.; Manic, M. Building energy load forecasting using deep neural networks. In Proceedings of the 42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 1–6. [Google Scholar]
- Kong, W.; Dong, Z.-Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on lstm recurrent neural network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Hosein, S.; Hosein, P. Load forecasting using deep neural networks. In Proceedings of the IEEE PES ISGT 2017, Washington, DC, USA, 23–26 April 2017; pp. 1–5. [Google Scholar]
- Ouyang, T.; He, Y.; Li, H.; Sun, Z.; Baek, S. Modeling and forecasting short-term power load with copula model and deep belief network. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 127–136. [Google Scholar] [CrossRef]
- Farfar, K.E.; Khadir, M.T. A two-stage short-term load forecasting approach using temperature daily profiles estimation. Neural Comput. Appl. 2019, 31, 3909–3919. [Google Scholar] [CrossRef]
- Chen, K.; Chen, K.; Wang, Q.; He, Z.; Hu, J.; He, J. Short-term load forecasting with deep residual networks. IEEE Trans. Smart Grid 2019, 10, 3943–3952. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the 32nd ICML, Lille, France, 6–11 July 2015; pp. 1–9. [Google Scholar]
- TensorFlow. Available online: https://tensorflow.google.cn (accessed on 17 November 2018).
- Xu, J.; Yue, M.; Katramatos, D.; Yoo, S. Spatial-temporal load forecasting using AMI data. In Proceedings of the IEEE SmartGridComm: Data Management and Grid Analytics and Dynamic Pricing, Sydney, NSW, Australia, 6–9 November 2016; pp. 1–7. [Google Scholar]
- Tascikaraoglu, A.; Sanandaj, B.M. Short-term residential electric load forecasting: A compressive spatio-temporal approach. Energy Build. 2016, 111, 380–392. [Google Scholar] [CrossRef]
- Wang, Y.; Lu, X.; Xu, Y.; Shi, D.; Wang, Z. Submodular load clustering with robust principal component analysis. arXiv 2019, arXiv:1902.07376. [Google Scholar]
- Carreno, E.M.; Rocha, R.M.; Padilha-Feltrin, A. A cellular automaton approach to spatial electric load forecasting. IEEE Trans. Power Syst. 2011, 26, 532–540. [Google Scholar] [CrossRef]
- PJM Data Miner 2. Hourly Load. Available online: Http://dataminer2.pjm.com/feed/hrl_load_metered/definition (accessed on 12 August 2019).
- PJM Interregional Map. Transmission Zones. Available online: https://www.pjm.com/markets-and-operations/interregional-map.aspx (accessed on 25 June 2018).
- Wright, J.; Ganesh, A.; Rao, S.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low rank matrices. In Proceedings of the 23rd NIPS, Vancouver, BC, Canada, 7–10 December 2009; pp. 1–9. [Google Scholar]
- Cai, J.-F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Weather Underground. Historical Weather. Available online: https://www.wunderground.com/history (accessed on 3 October 2019).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filter Bank | I | II | II | IV | V | |
|---|---|---|---|---|---|---|
| HLM Size | ||||||
| 32@ | 48@ | 64@ | 72@ | - | ||
| 32@ | 48@ | 64@ | 72@ | - | ||
| 32@ | 48@ | 64@ | 64@ | 72@ | ||
| 32@ | 48@ | 64@ | 64@ | 72@ | ||
| MAE/RMSE | GRU | 1 Layer (128) | 1 Layer (256) | 1 Layer (512) | 2 Layer (128) | 3 Layer (128) |
|---|---|---|---|---|---|---|
| CNN | ||||||
| Figure 3, mean pooling | 4.32/6.26 | - | - | - | - | |
| Figure 3, max pooling | 5.51/7.72 | 5.00/7.93 | - | - | - | |
| , no pooling | 3.88/5.05 | 3.82/5.10 | 3.88/5.17 | - | - | |
| Figure 3, no pooling | 3.84/4.80 | 3.79/4.96 | 3.91/5.20 | 3.82/5.12 | 4.12/6.07 | |
| Model | SSA-SVR | ELM-MABC | KMC-SDAE | DBC-LSTM | Ours | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Time | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| January | 7.33 | 16.22 | 6.44 | 11.16 | 5.76 | 10.67 | 3.04 | 5.47 | 2.10 | 3.05 | |
| February | 10.42 | 24.32 | 7.52 | 13.52 | 4.74 | 8.99 | 2.33 | 3.99 | 2.26 | 2.79 | |
| March | 8.09 | 17.86 | 5.00 | 9.04 | 5.39 | 10.10 | 2.71 | 4.33 | 2.21 | 3.09 | |
| April | 7.21 | 15.36 | 5.35 | 9.47 | 6.82 | 11.50 | 1.95 | 3.26 | 2.01 | 2.81 | |
| May | 6.21 | 13.59 | 5.98 | 9.12 | 4.02 | 7.04 | 2.62 | 4.04 | 1.90 | 2.62 | |
| June | 8.91 | 16.79 | 6.03 | 10.27 | 3.78 | 6.61 | 2.86 | 3.29 | 2.15 | 2.52 | |
| July | 8.10 | 17.58 | 5.33 | 8.46 | 3.60 | 5.53 | 1.99 | 3.03 | 2.02 | 2.23 | |
| August | 7.22 | 12.29 | 4.01 | 6.61 | 4.44 | 6.71 | 1.84 | 2.72 | 1.85 | 2.11 | |
| September | 7.01 | 15.51 | 5.42 | 9.18 | 4.66 | 7.77 | 2.66 | 4.31 | 1.95 | 2.49 | |
| October | 8.02 | 17.81 | 6.07 | 10.86 | 7.03 | 10.61 | 2.44 | 3.46 | 2.55 | 3.61 | |
| November | 8.00 | 18.39 | 6.92 | 13.06 | 6.76 | 12.33 | 2.59 | 4.64 | 2.34 | 2.84 | |
| December | 9.09 | 20.56 | 7.10 | 13.11 | 6.03 | 10.98 | 2.93 | 4.79 | 2.38 | 2.89 | |
| Mean | 7.97 | 17.19 | 5.93 | 10.32 | 5.25 | 9.07 | 2.51 | 3.95 | 2.14 | 2.76 | |
| MAPE | Model | SSA-SVR | ELM-MABC | KMC-SDAE | DBC-LSTM | Ours |
|---|---|---|---|---|---|---|
| Time | ||||||
| January | 10.10 | 9.13 | 10.17 | 4.26 | 3.95 | |
| February | 12.09 | 11.09 | 8.09 | 4.53 | 4.05 | |
| March | 11.11 | 9.11 | 10.11 | 4.10 | 3.85 | |
| April | 9.90 | 10.9 | 9.90 | 3.91 | 3.62 | |
| May | 9.80 | 8.80 | 7.80 | 4.00 | 3.11 | |
| June | 10.70 | 7.24 | 8.66 | 3.93 | 2.97 | |
| Mean | 10.61 | 9.38 | 9.12 | 4.12 | 3.59 | |
| M/R | Model | January | February | March | April | May | June | Mean |
|---|---|---|---|---|---|---|---|---|
| Time | ||||||||
| NCST-LF | 7.76/12.65 | 8.14/13.10 | 7.99/12.96 | 6.73/10.50 | 7.04/11.22 | 6.27/8.29 | 7.32/11.45 | |
| knmV-AR | 7.06/10.15 | 6.60/9.44 | 6.72/9.98 | 7.17/10.72 | 6.26/9.16 | 5.93/8.46 | 6.63/9.65 | |
| Ours | 2.66/3.41 | 2.73/3.43 | 2.65/3.50 | 2.30/2.92 | 2.19/2.77 | 2.03/2.53 | 2.42/3.11 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, L.; Zhang, L.; Wang, X. Spatiotemporal Feature Learning Based Hour-Ahead Load Forecasting for Energy Internet. Electronics 2020, 9, 196. https://doi.org/10.3390/electronics9010196
Du L, Zhang L, Wang X. Spatiotemporal Feature Learning Based Hour-Ahead Load Forecasting for Energy Internet. Electronics. 2020; 9(1):196. https://doi.org/10.3390/electronics9010196
Chicago/Turabian StyleDu, Liufeng, Linghua Zhang, and Xu Wang. 2020. "Spatiotemporal Feature Learning Based Hour-Ahead Load Forecasting for Energy Internet" Electronics 9, no. 1: 196. https://doi.org/10.3390/electronics9010196
APA StyleDu, L., Zhang, L., & Wang, X. (2020). Spatiotemporal Feature Learning Based Hour-Ahead Load Forecasting for Energy Internet. Electronics, 9(1), 196. https://doi.org/10.3390/electronics9010196