DSFTL: An Efficient FTL for Flash Memory Based Storage Systems



Abstract
:1. Introduction
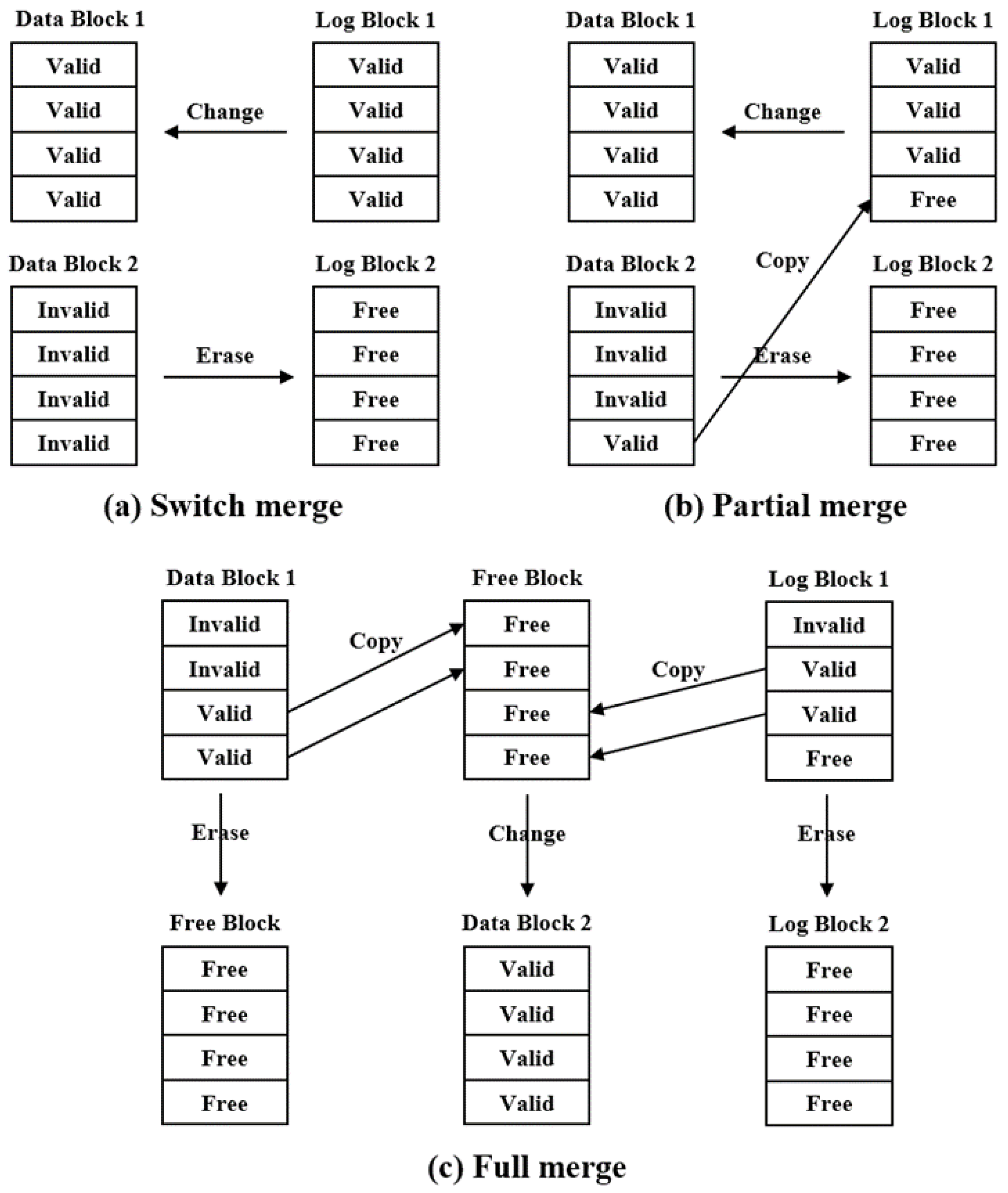
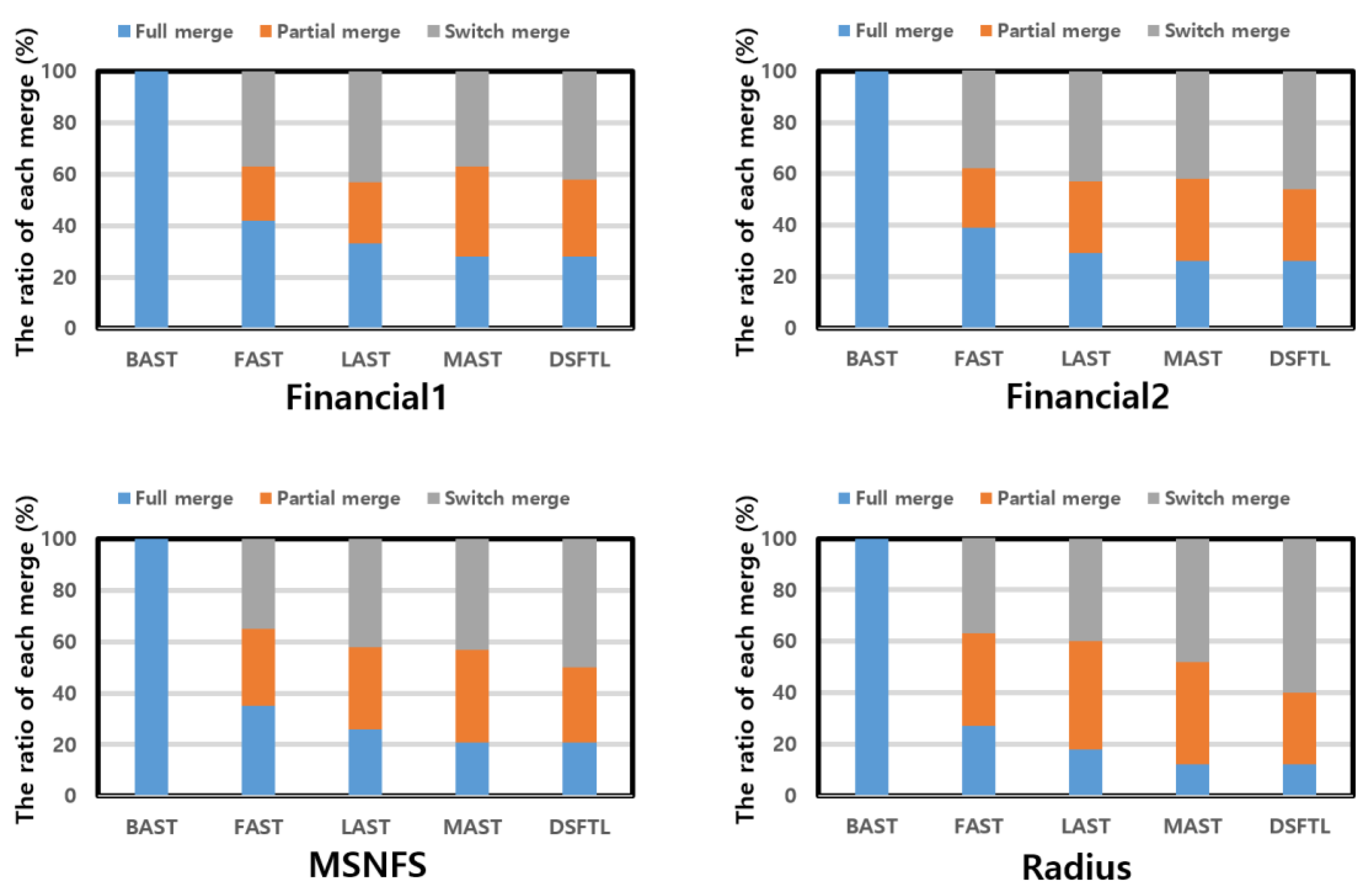
- By our experiments, we check that the operation of switch merge is occurred more often than operation of partial merge by using many SW log blocks.
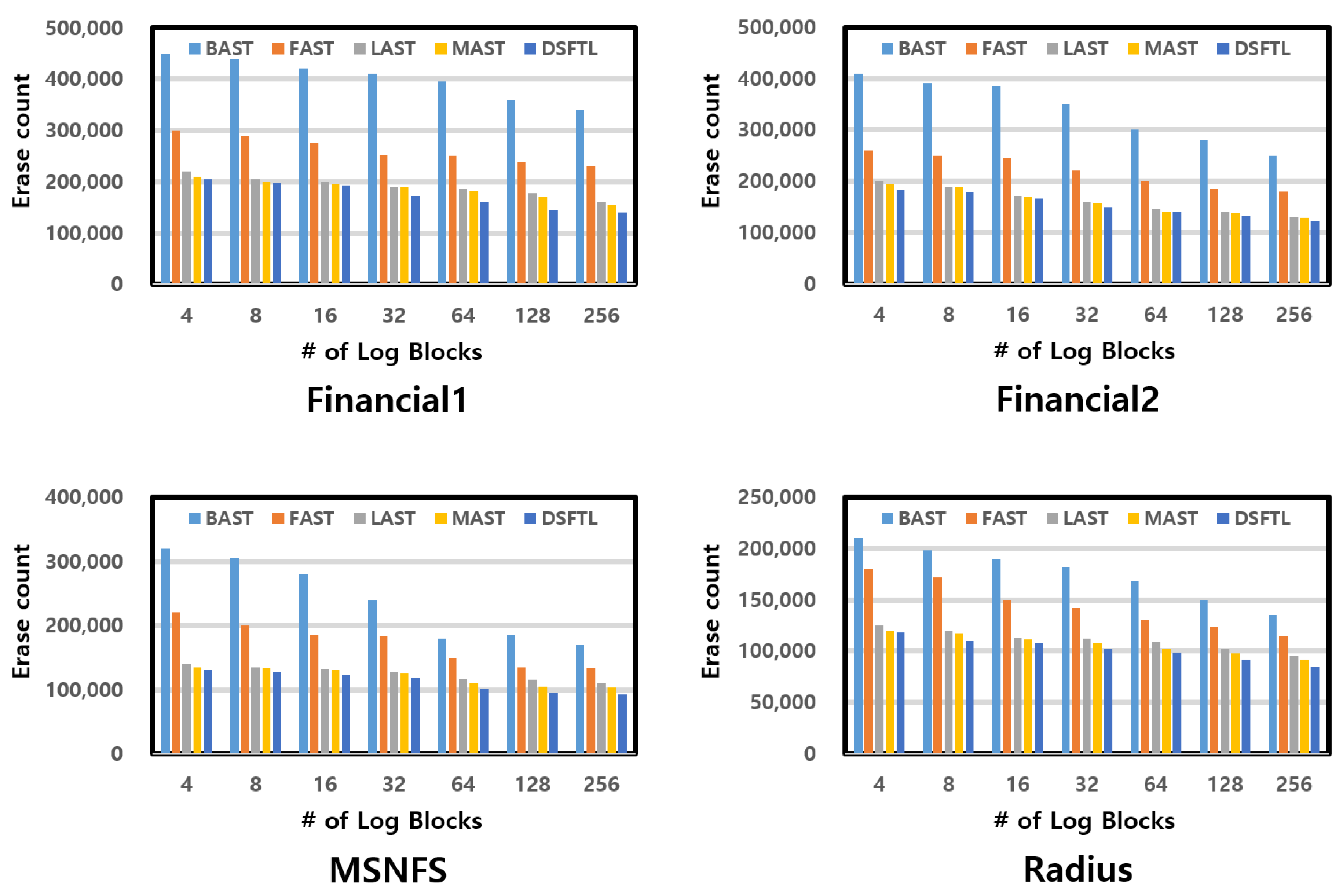
- We show by our experiment that the space availability of the log block is high, and the high-priced operation of full merge is less incurred as the connection of the data block and the log block is managed dynamically.
- Based on our experimental results, the space availability of the data block is high, since the data block, which has many free pages, avoids operations of merge.
- As a result, by using DSFTL, we can decrease the garbage collection overhead in hybrid mapping.
2. Related Work
3. Background
3.1. NAND Flash Memory
3.2. FTL
4. Motivation
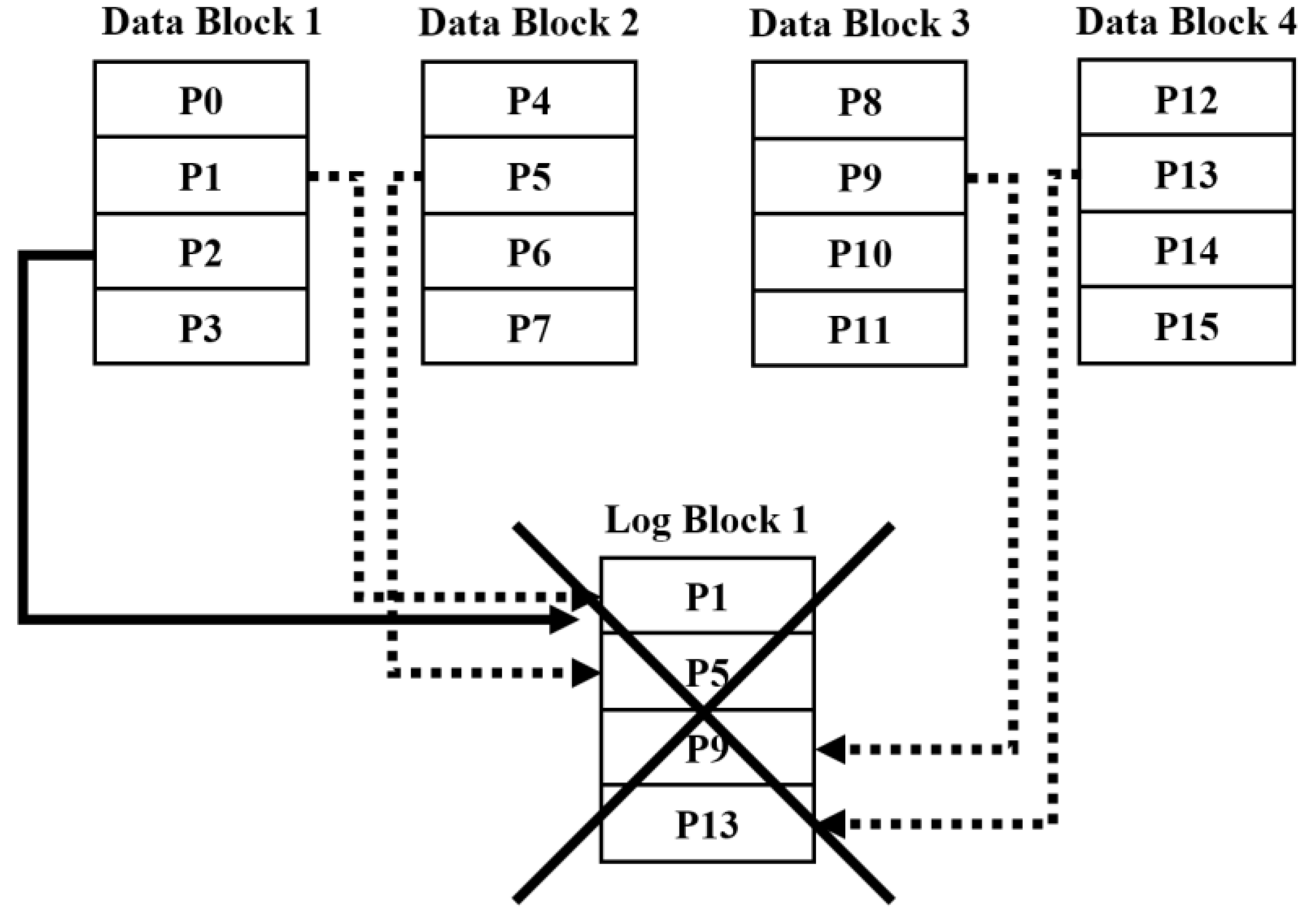
4.1. Operation of Merge
4.2. Availability between a Data Block and a Log Block
4.3. Space Availability of a Data Block
5. System Design
5.1. System Architecture
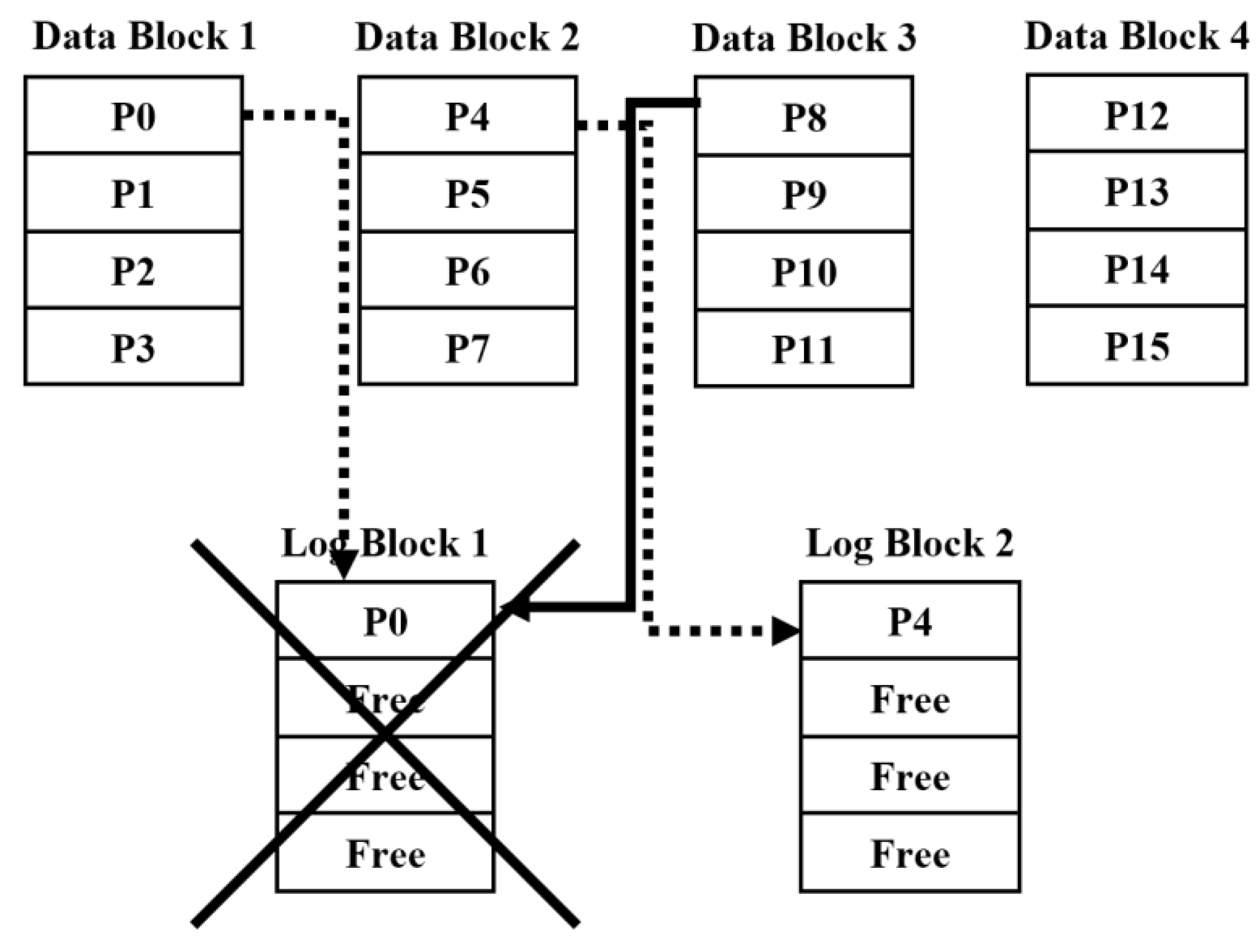
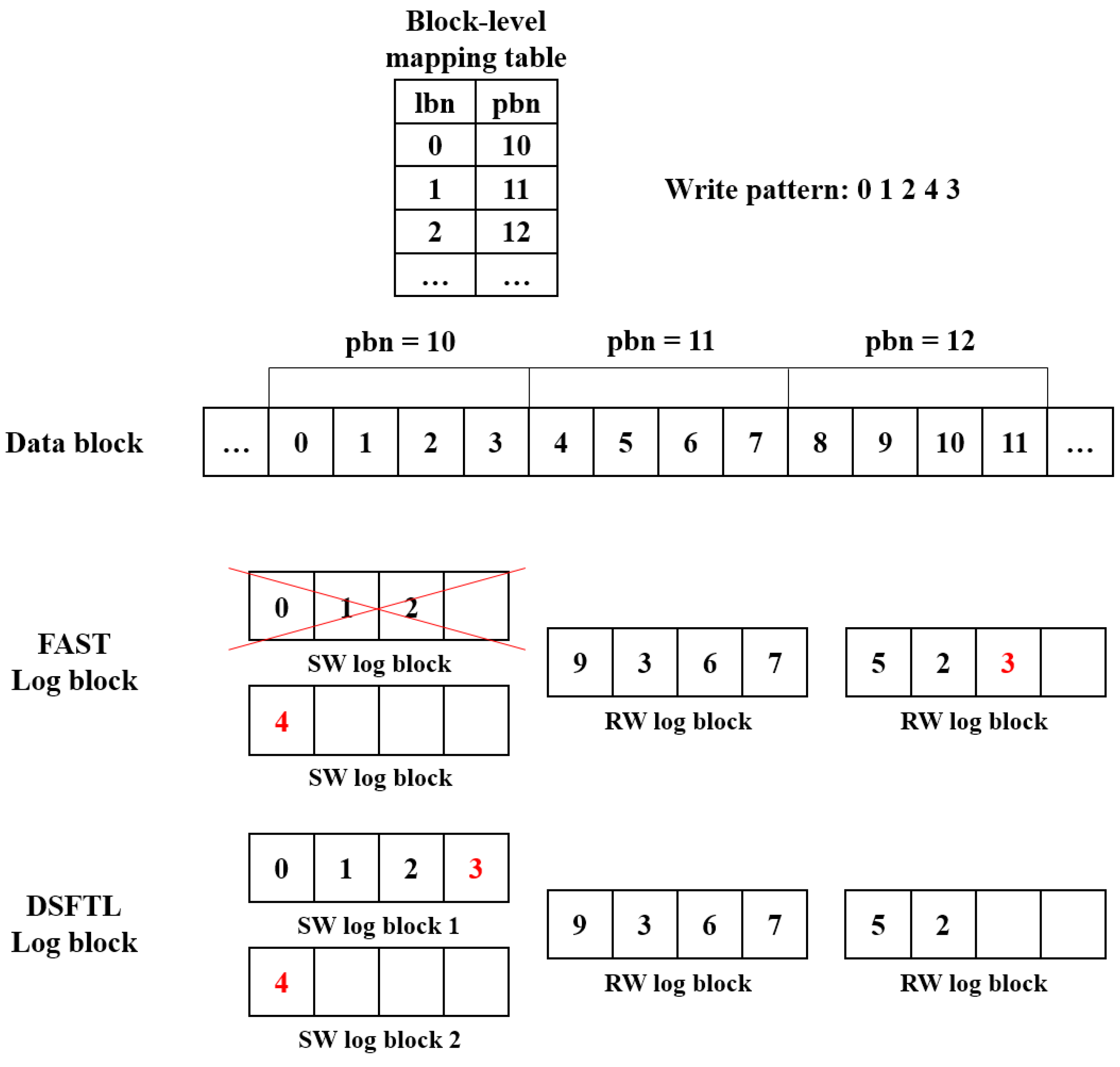
5.2. Increase of a Switch Merge and the Decrease of a Partial Merge
| Algorithm 1: When data with page offset zero is written |
| Input: Data begin 1 if all SW log blocks are not written 2 write data to any SW log block 3 else if some SW log blocks are written 4 do not erase data of these SW log blocks 5 write data to other SW log blocks 6 else /* all SW log blocks are written */ 7 erase data of SW log block which data is less written 8 write data to this SW log block 9 end if |
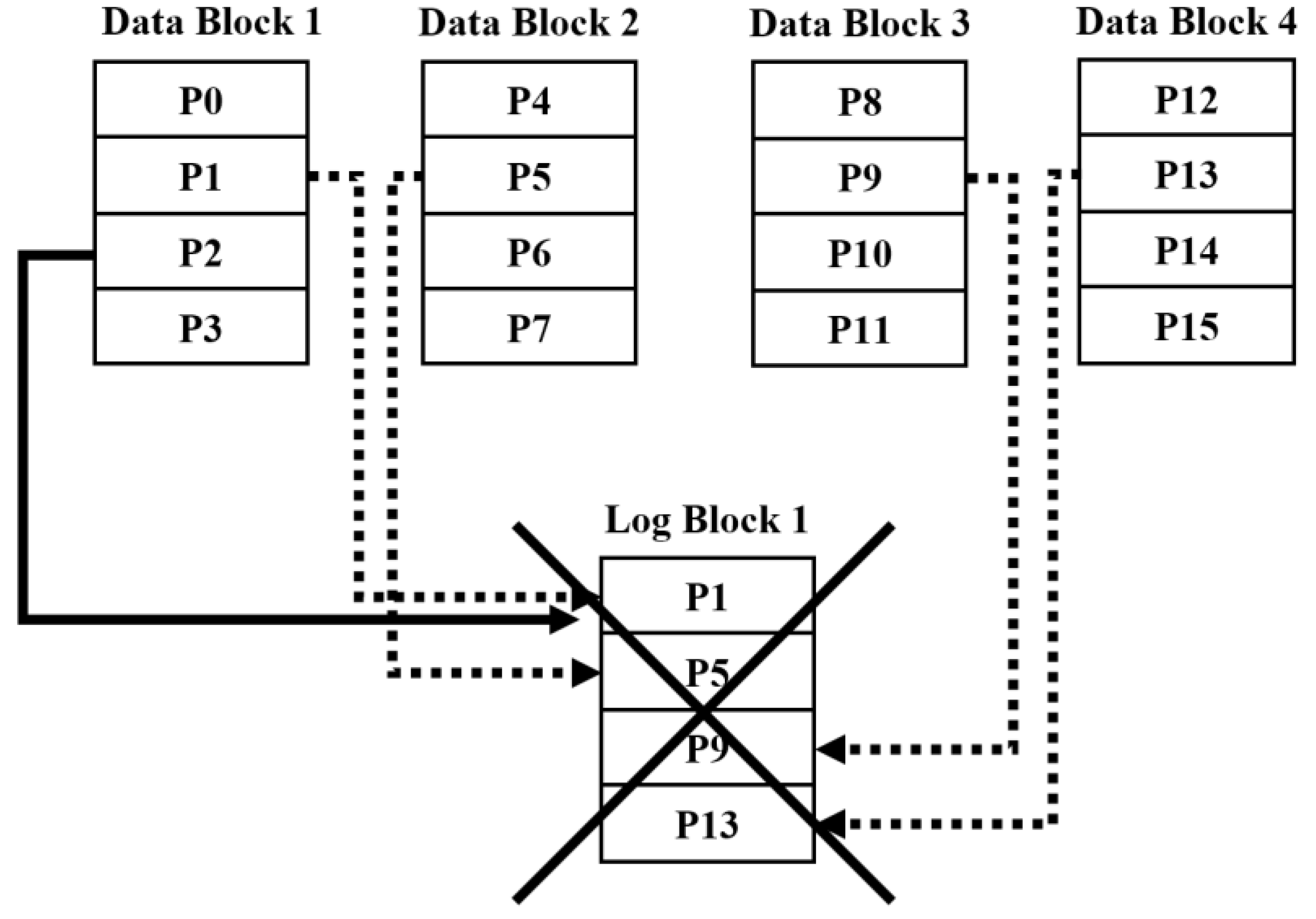
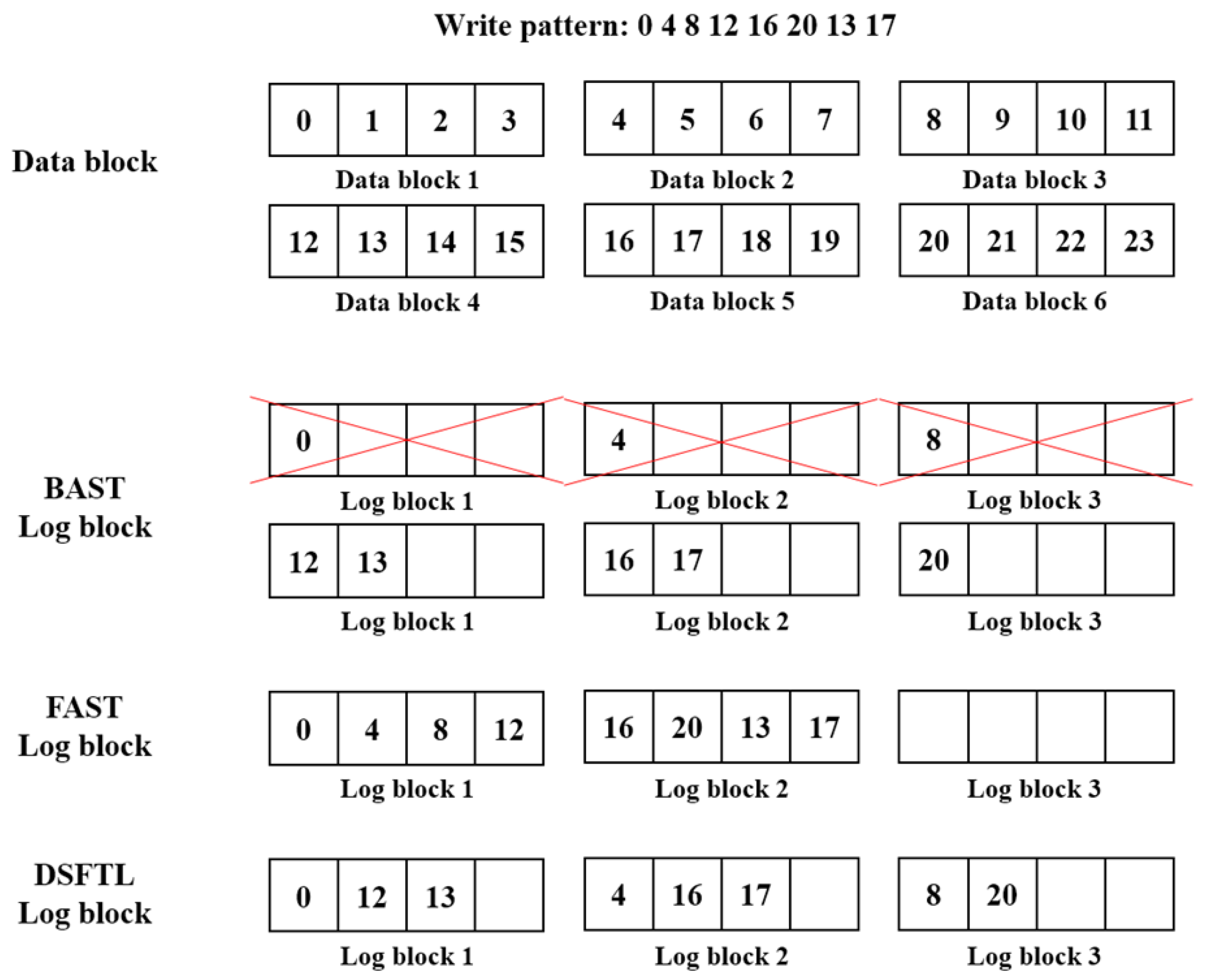
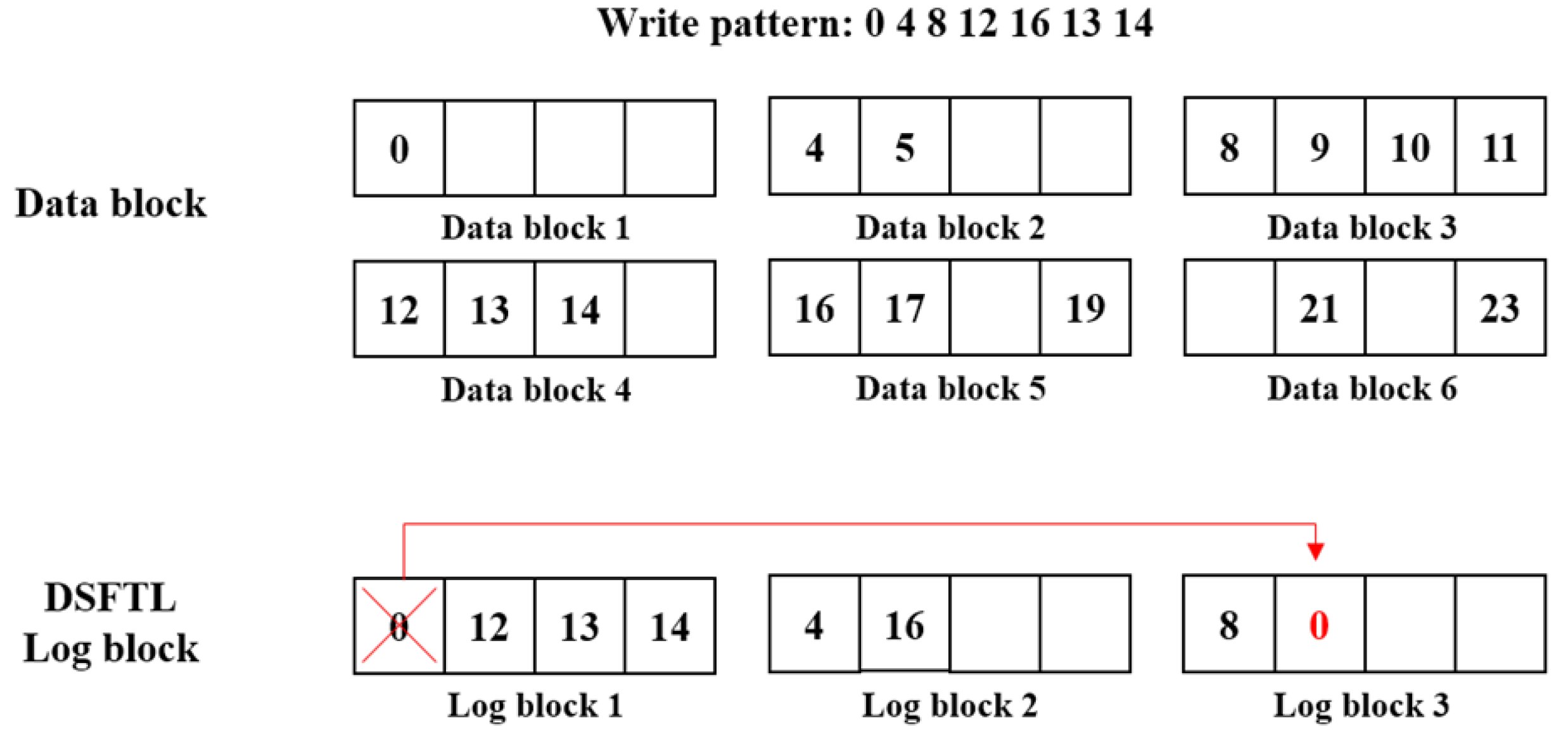
5.3. Adjust Availability Dynamically
| Algorithm 2: When data in a data block is written to a log block |
| Input: Data begin 1 if data is not already written in a log block 2 find a log block which data is less written 3 write data to this log block 4 else /* data is already written in the log block */ 5 write data to only this log block which have already been connected 6 end if |
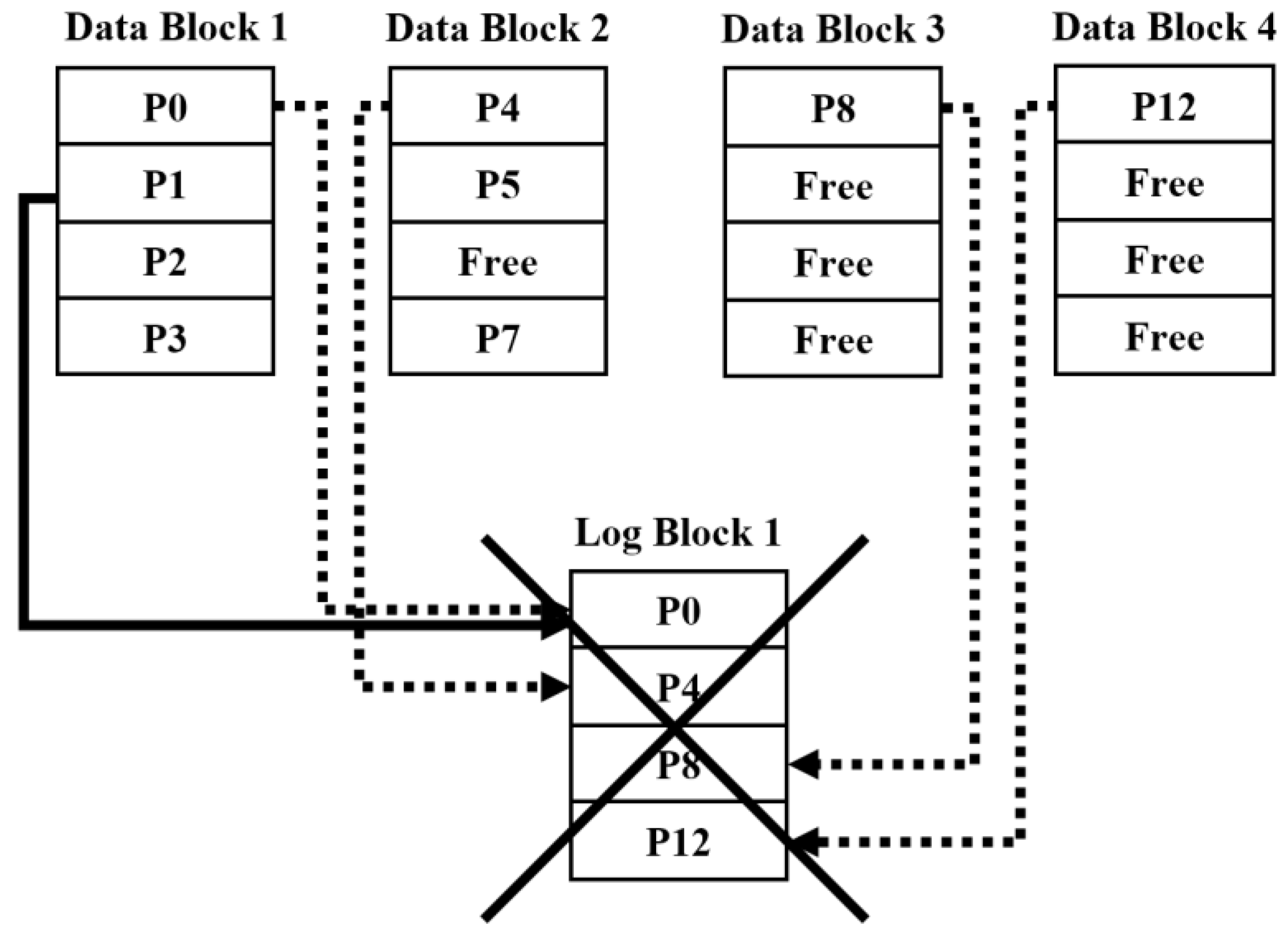
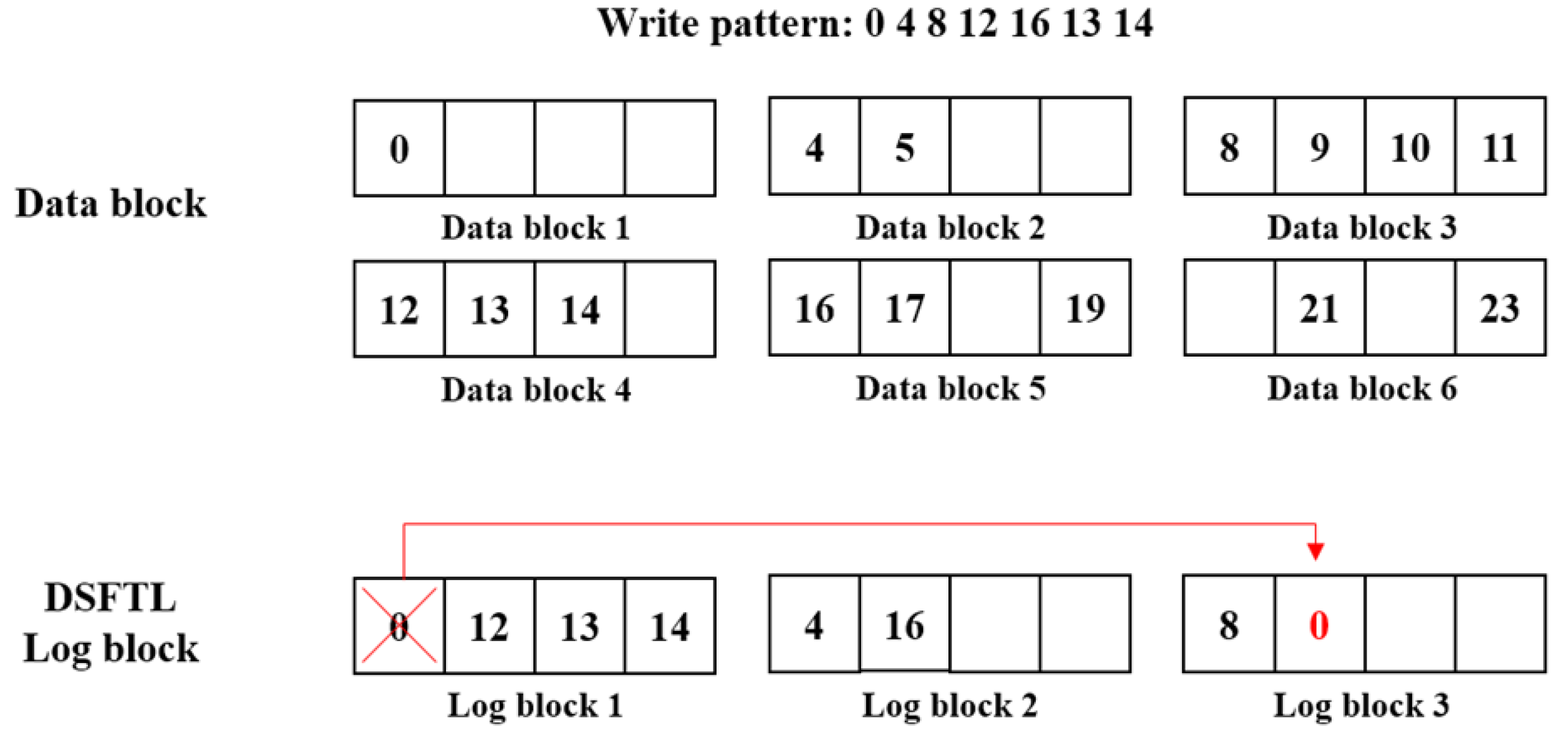
5.4. Increasing Space Availability of a Data Block
| Algorithm 3: When a log block is merged |
| begin 1 if a log block is selected as a victim block 2 find the data block that data is less written in this log block 3 find the log block that availability is the lowest 4 copy data in the victim log block with the found log block 5 invalidate data in the victim log block 6 end if |
6. Evaluation
6.1. Experiment Setup
6.2. Workloads
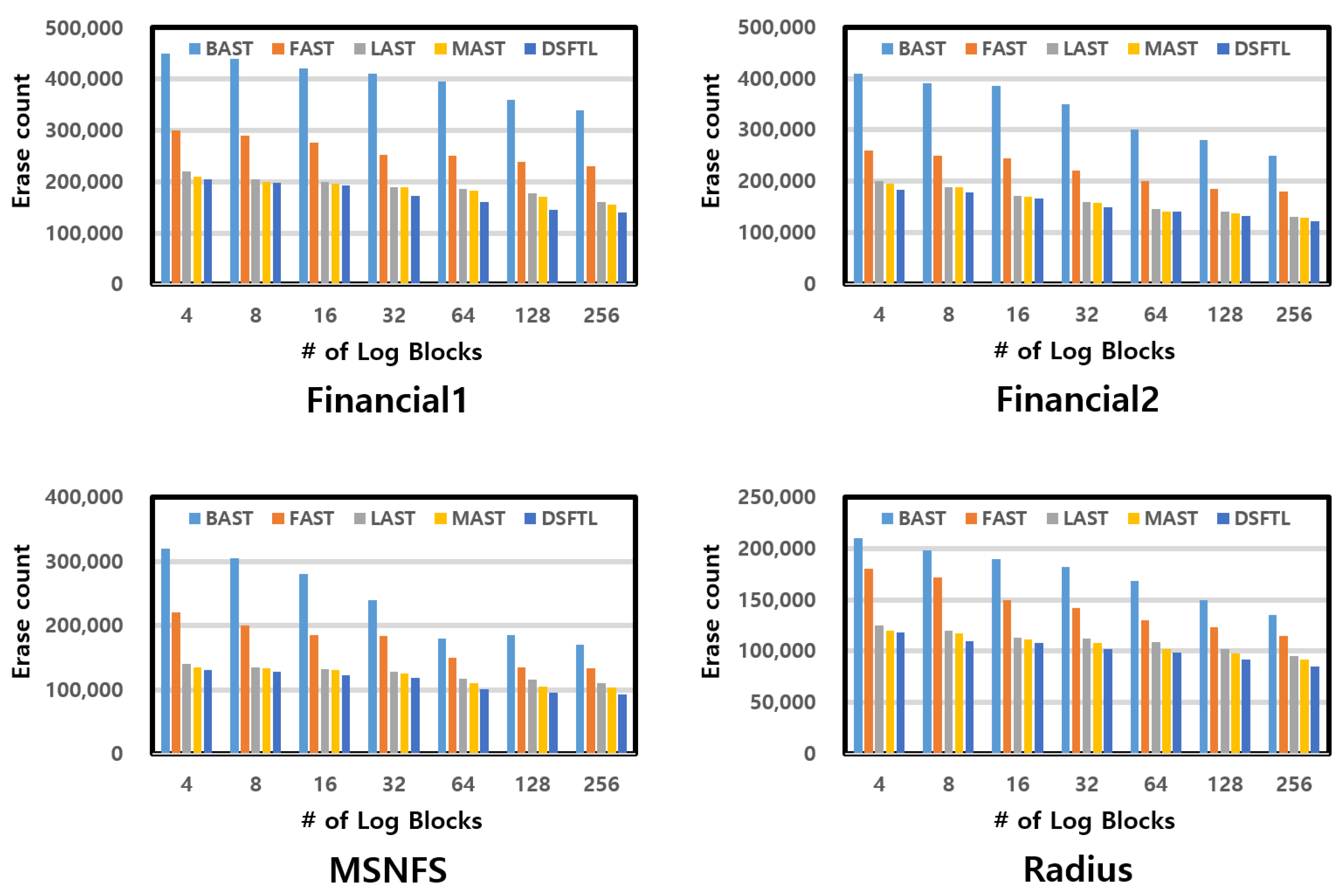
6.3. Experimental Results
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Kinam, K. Symposium on VLSI-TSA Technology; IEEE: Piscataway, NJ, USA, 2008; pp. 5–9. [Google Scholar]
- Gray, J.; Fitzgerald, B. Flash Disk Opportunity for Server-Applications. Available online: http://www.research.microsoft.com/~gray (accessed on 10 January 2020).
- Mativenga, R.; Paik, J.-Y.; Kim, Y.; Lee, J.; Chung, T.-S. RFTL: Improving performance of selective caching-based page-level FTL through replication. Clust. Comput. J. 2019, 22, 25–41. [Google Scholar] [CrossRef]
- Samsung Electronics. Nand Flash Memory & Smartmedia Data Book; Samsung Electronics: Suwon, Korea, 2007. [Google Scholar]
- Amir, B. Flash File System Optimized for Page-mode Flash Technologies. U.S. Patent No. 5,937,425, 10 August 1999. [Google Scholar]
- Chung, T.-S.; Park, D.-J.; Park, S.; Lee, D.-H.; Lee, S.-W.; Song, H.-J. A survey of flash translation layer. J. Syst. Arch. 2009, 55, 332–343. [Google Scholar] [CrossRef]
- Amir, B. Flash File System. U.S. Patent No. 5,404,485, 4 April 1995. [Google Scholar]
- Gupta, A.; Kim, Y.; Urgaonkar, B. DFTL: A flash translation layer employing demand-based selective caching of page-level address mappings. ACM 2009, 44, 229–240. [Google Scholar]
- Kim, J.; Kim, J.M.; Noh, S.H.; Min, S.L.; Cho, Y. A space-efficient flash translation layer for CompactFlash systems. IEEE Trans. Consum. Electron. 2002, 48, 366–375. [Google Scholar]
- Lee, S.-W.; Park, D.J.; Chung, T.S.; Lee, D.H.; Park, S.; Song, H.J. A log buffer-based flash translation layer using fully-associative sector translation. ACM Trans. Embed. Comput. Syst. 2007, 6, 18. [Google Scholar] [CrossRef]
- Kang, J.; Jo, H.; Kim, J.-S.; Lee, J. A superblock-based flash translation layer for NAND flash memory. In Proceedings of the 6th ACM & IEEE International Conference on Embedded Software, Seoul, Korea, 22–25 October 2006. [Google Scholar]
- Cho, H.; Shin, D.; Eom, Y.I. KAST: K-associative sector translation for NAND flash memory in real-time systems. In Proceedings of the 2009 Design, Automation & Test in Europe Conference & Exhibition, Nice, France, 20–24 April 2009. [Google Scholar]
- Forouhar, P.; Safaei, F. DA-FTL: Dynamic associative flash translation layer. In Proceedings of the 2017 19th International Symposium on Computer Architecture and Digital Systems (CADS), Kish Island, Iran, 21–22 December 2017. [Google Scholar]
- Lee, S.; Shin, D.; Kim, Y.-J.; Kim, J. LAST: Locality-aware sector translation for NAND flash memory-based storage systems. ACM SIGOPS Oper. Syst. Rev. 2008, 42, 36–42. [Google Scholar] [CrossRef]
- Kim, J.; Kang, D.H.; Ha, B.; Cho, H.; Eom, Y.I. MAST: Multi-level associated sector translation for NAND flash memory-based storage system. In Computer Science and Its Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 817–822. [Google Scholar]
- Kim, J.K.; Lee, H.G.; Choi, S.; Bahng, K. A PRAM and NAND flash hybrid architecture for high-performance embedded storage subsystems. In Proceedings of the 8th ACM International Conference on Embedded Software, Atlanta, GA, USA, 19–24 October 2008. [Google Scholar]
- Wei, Q.; Zeng, L.; Chen, J.; Chen, C. A popularity-aware buffer management to improve buffer hit ratio and write sequentiality for solid-state drive. IEEE Trans. Magn. 2013, 49, 2786–2793. [Google Scholar] [CrossRef]
- Liu, D.; Wang, T.; Wang, Y.; Qin, Z.; Shao, Z. A block-level flash memory management scheme for reducing write activities in PCM-based embedded systems. In Proceedings of the Conference on Design, Automation and Test in Europe, EDA Consortium, Dresden, Germany, 12–16 March 2012. [Google Scholar]
- Kwon, S.J. Non-volatile translation layer for PCM + NAND in wearable devices. IEEE Trans. Consum. Electron. 2017, 63, 483–489. [Google Scholar] [CrossRef]
- Tal, A. Two Technologies Compared: NOR vs. NAND; M-Systems White Paper: Kfar Saba, Israel, 2003. [Google Scholar]
- Sun, G.; Joo, Y.; Chen, Y.B.; Niu, D.; Xie, Y.; Chen, Y.R.; Li, H. A hybrid solid-state storage architecture for the performance, energy consumption, and lifetime improvement. In Emerging Memory Technologies; Springer: New York, NY, USA, 2014; pp. 51–77. [Google Scholar]
- Moshayedi, M.; Seyed, J.S. SLC-MLC Combination Flash Storage Device. U.S. Patent No. 8,825,941, 2 September 2014. [Google Scholar]
- Harari, E.; Robert, D. Norman, and Sanjay Mehrotra. Flash Eeprom System. U.S. Patent No. 5,602,987, 11 February 1997. [Google Scholar]
- Robinson, K.B.; Elbert, D.K.; Levy, M.A. Block-Erasable Non-Volatile Semiconductor Memory Which Tracks and Stores the Total Number of Write/Erase Cycles for Each Block. U.S. Patent No. 5,544,356, 6 August 1996. [Google Scholar]
- Dayan, N.; Svendsen, M.K.; Bjorling, M.; Bonnet, P.; Bouganim, L. EagleTree: Exploring the design space of SSD-based algorithms. In Proceedings of the VLDB Endowment, Riva del Garda, Italy, 26 August 2013; pp. 1290–1293. [Google Scholar]
- Park, S.-H.; Ha, S.-W.; Bang, K.; Chung, E.-Y. Design and analysis of flash translation layers for multi-channel NAND flash-based storage devices. IEEE Trans. Consum. Electron. 2009, 55, 1392–1400. [Google Scholar] [CrossRef]
- Chang, Y.-H.; Kuo, T.-W. A management strategy for the reliability and performance improvement of MLC-based flash-memory storage systems. IEEE Trans. Comput. 2011, 60, 305–320. [Google Scholar] [CrossRef]
- UMASS Trace Repository. Available online: http://traces.cs.umass.edu/ (accessed on 10 January 2020).
- SNIA IOTTA Repository. Available online: http://iotta.snia.org/ (accessed on 10 January 2020).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value (Fixed)-Varied |
|---|---|
| Page Size (KB) | 8 |
| Pages per Block | 1024 |
| Blocks per Plane | 1024 |
| Plane per Die | 1 |
| Die per Chip | 2 |
| Chip per Channel | 1 |
| Channel number | 6 |
| Erase time | 1500 μs |
| Program time | 800 μs |
| Buffer service time | 1000 ns |
| Traces | Financial 1 | Financial 2 | MSNFS | Radius |
|---|---|---|---|---|
| Read Ratio | 0.41 | 0.23 | 0.85 | 0.09 |
| Write Ratio | 0.59 | 0.87 | 0.15 | 0.91 |
| Ave Read size (KB) | 2.5 | 18.6 | 14.8 | 7.1 |
| Ave Write size (KB) | 3.1 | 21.4 | 10.6 | 8.4 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chae, S.-J.; Mativenga, R.; Paik, J.-Y.; Attique, M.; Chung, T.-S. DSFTL: An Efficient FTL for Flash Memory Based Storage Systems. Electronics 2020, 9, 145. https://doi.org/10.3390/electronics9010145
Chae S-J, Mativenga R, Paik J-Y, Attique M, Chung T-S. DSFTL: An Efficient FTL for Flash Memory Based Storage Systems. Electronics. 2020; 9(1):145. https://doi.org/10.3390/electronics9010145
Chicago/Turabian StyleChae, Suk-Joo, Ronnie Mativenga, Joon-Young Paik, Muhammad Attique, and Tae-Sun Chung. 2020. "DSFTL: An Efficient FTL for Flash Memory Based Storage Systems" Electronics 9, no. 1: 145. https://doi.org/10.3390/electronics9010145
APA StyleChae, S.-J., Mativenga, R., Paik, J.-Y., Attique, M., & Chung, T.-S. (2020). DSFTL: An Efficient FTL for Flash Memory Based Storage Systems. Electronics, 9(1), 145. https://doi.org/10.3390/electronics9010145