Decision-Making System for Lane Change Using Deep Reinforcement Learning in Connected and Automated Driving

Abstract
:1. Introduction
- A model that combines deep reinforcement learning with vehicular communication is proposed. We show how to utilize information from a remote vehicle as well as the host vehicle in deep reinforcement learning.
- We handle different state information update periods for the host and remote vehicles. Generally, the state information of the remote vehicle is updated every 100 ms via vehicle communication, whereas the state information of the host vehicle is updated faster. This paper shows the results of agent learning considering these different update periods.
- We handle continuous action space for steering wheel and accelerator to improve the feasibility of the lane change problem. Furthermore, in order that our end-to-end method covers collision-free action, reward function takes the collision reward directly into account.
- We introduce a physically and visually realistic simulator Airsim [23]. Our main focus is to avoid collision between vehicles and realistic longitudinal and lateral control. We have experimented in the simulation environment that can handle both controls.
2. Decision-Making System for Lane Change
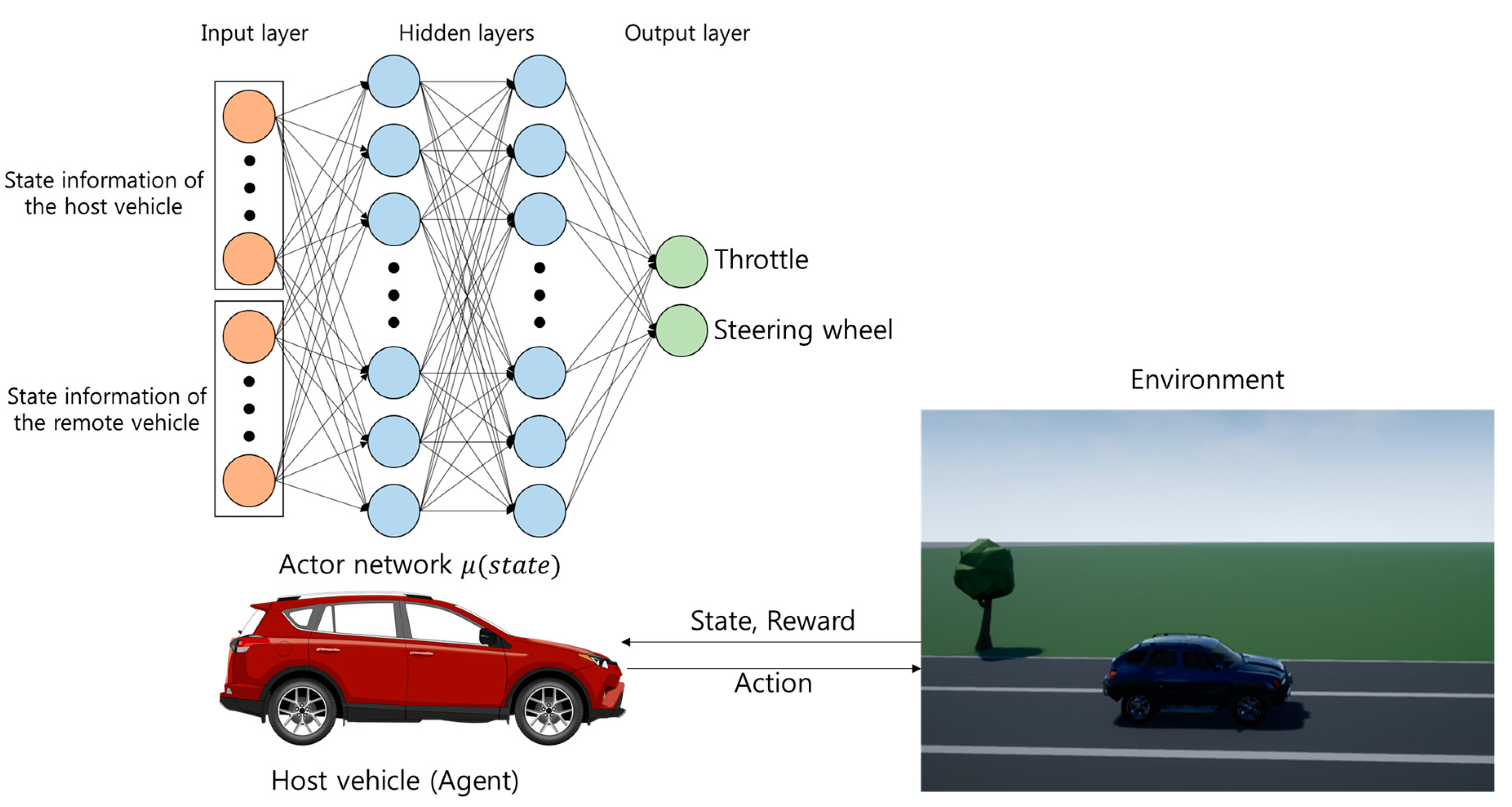
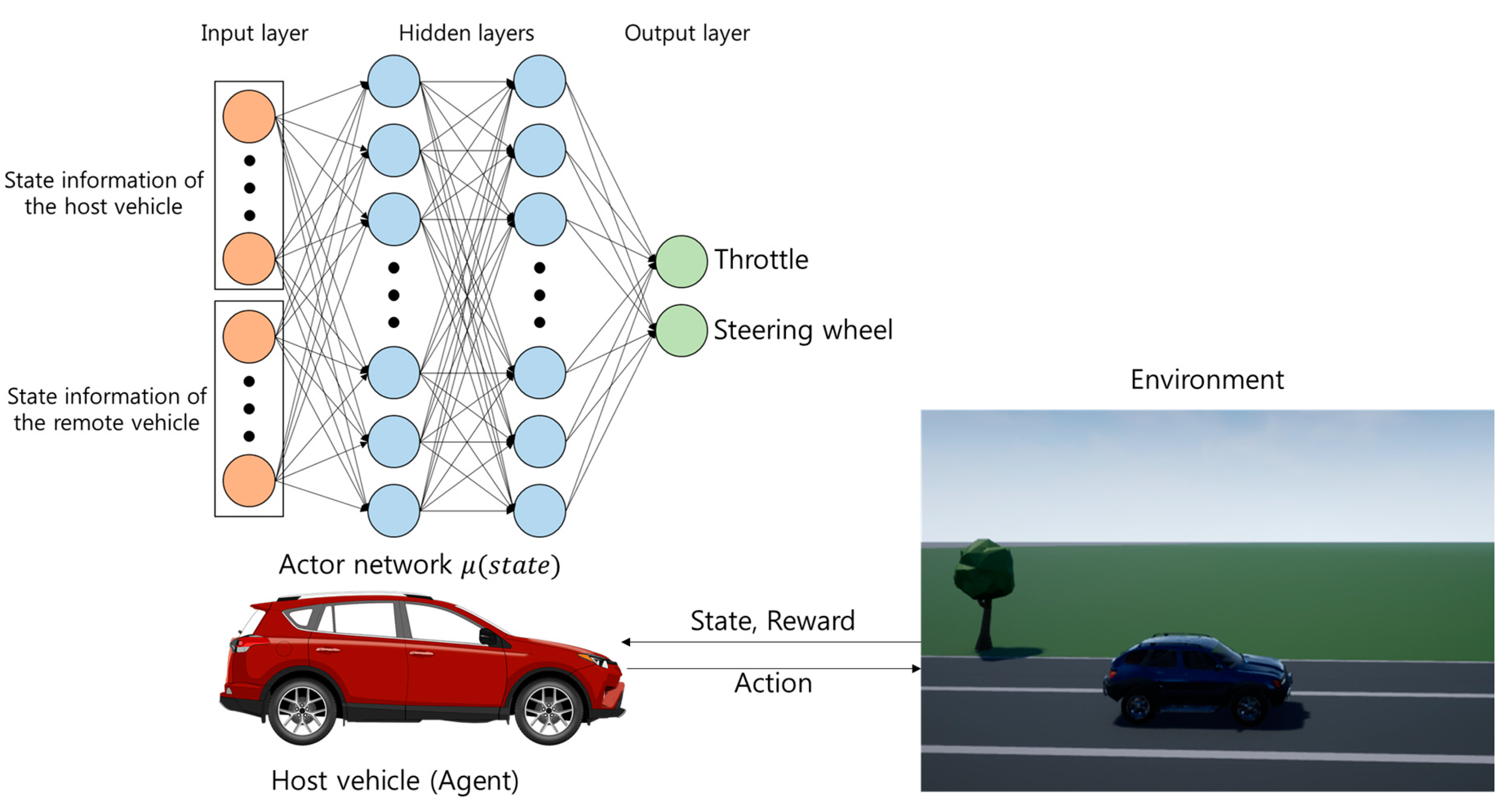
2.1. System Architecture
2.2. Markov Decision Process
2.2.1. States
- represents the x coordinate of the host vehicle.
- represents the y coordinate of the host vehicle.
- represents the speed of the host vehicle.
- represents the heading of the host vehicle.
- shows the x coordinate of the remote vehicle.
- shows the y coordinate of the remote vehicle.
- represents the speed of the remote vehicle.
- represents the heading of the remote vehicle.
2.2.2. Actions and Policy
- represents the throttle of the host vehicle.
- represents the steering wheel of the host vehicle.
2.2.3. Transition Dynamics
2.2.4. Rewards
- Collision with the remote vehicle and deviation from the road
- Final time step
- Completion of the lane change
- Failure to complete the lane change
- Etc.
- Driving in the next lane
- Driving in the initial lane
- Remainder
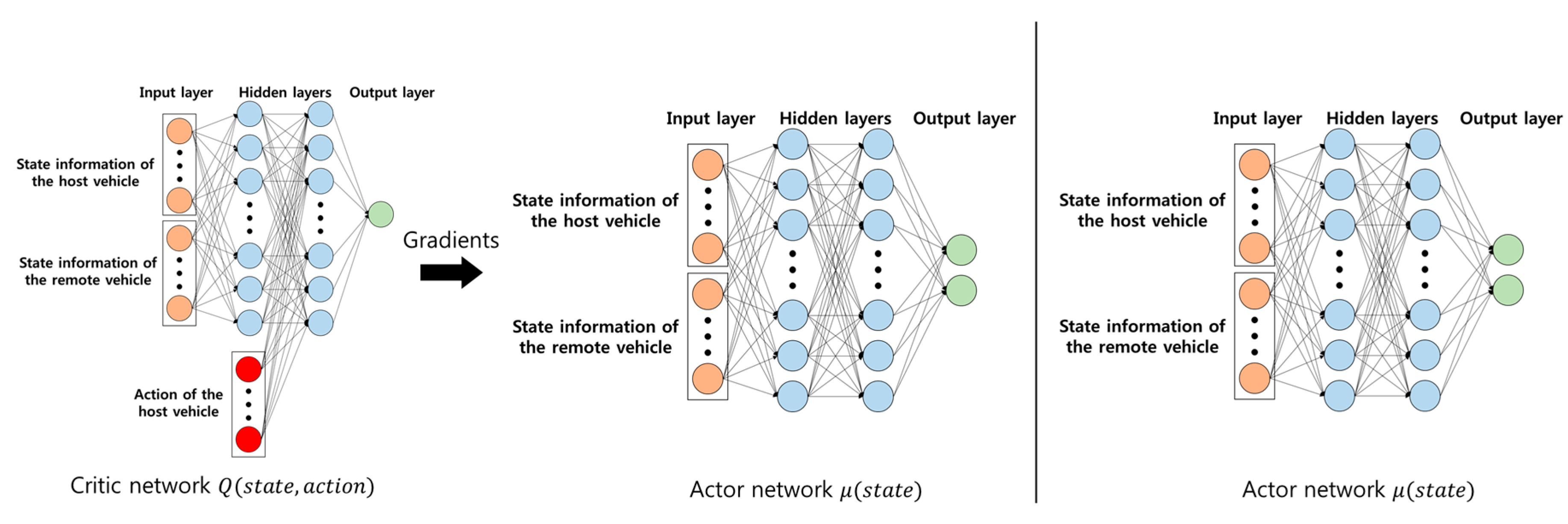
2.2.5. Deep Reinforcement Learning
2.3. Training Scenario and Algorithm
| Algorithm 1. Modification to Deep Deterministic Policy Gradient (DDPG) Training Algorithm. |
| Randomly initialize critic network and actor network Initialize target networks and replay buffer for episode = 1 to E do Receive initial state from sensors in the host vehicle for step = 0 to S-1 do if step % 10 == 0 then Receive state of the remote vehicle from the vehicular communication device end if Select action according to the current policy and exploration noise using normal distribution Simulation pause off Execute action and observe reward and observe new state Simulation pause on Store transition in replay memory Sample a random minibatch of N transitions from replay memory Update critic by minimizing the loss Update the actor policy using the sampled policy gradient Update the target networks end for end for |
3. Experiments
3.1. Simulation Setup and Data Collection
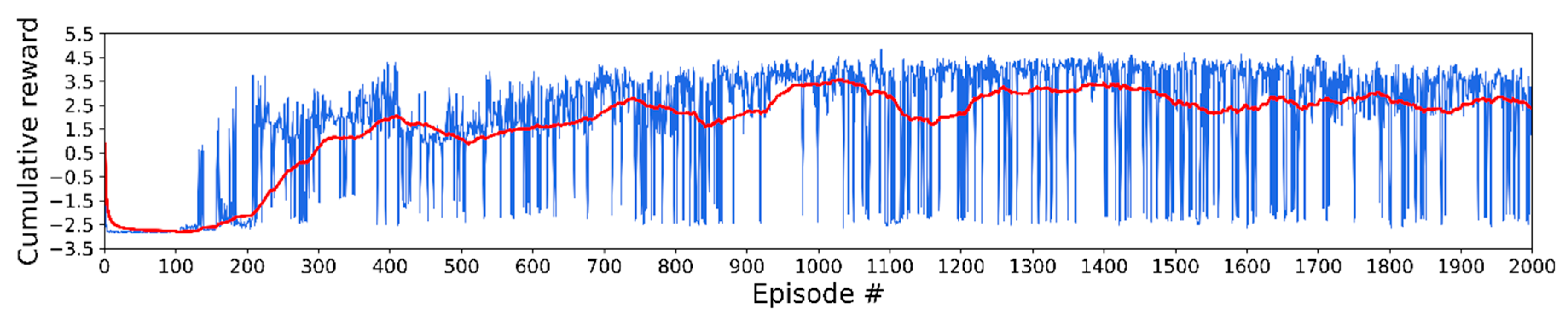
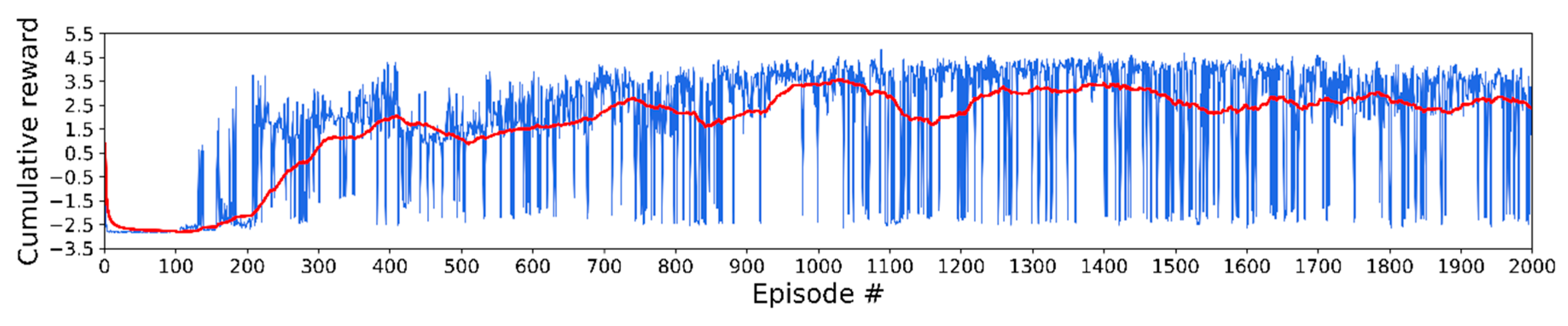
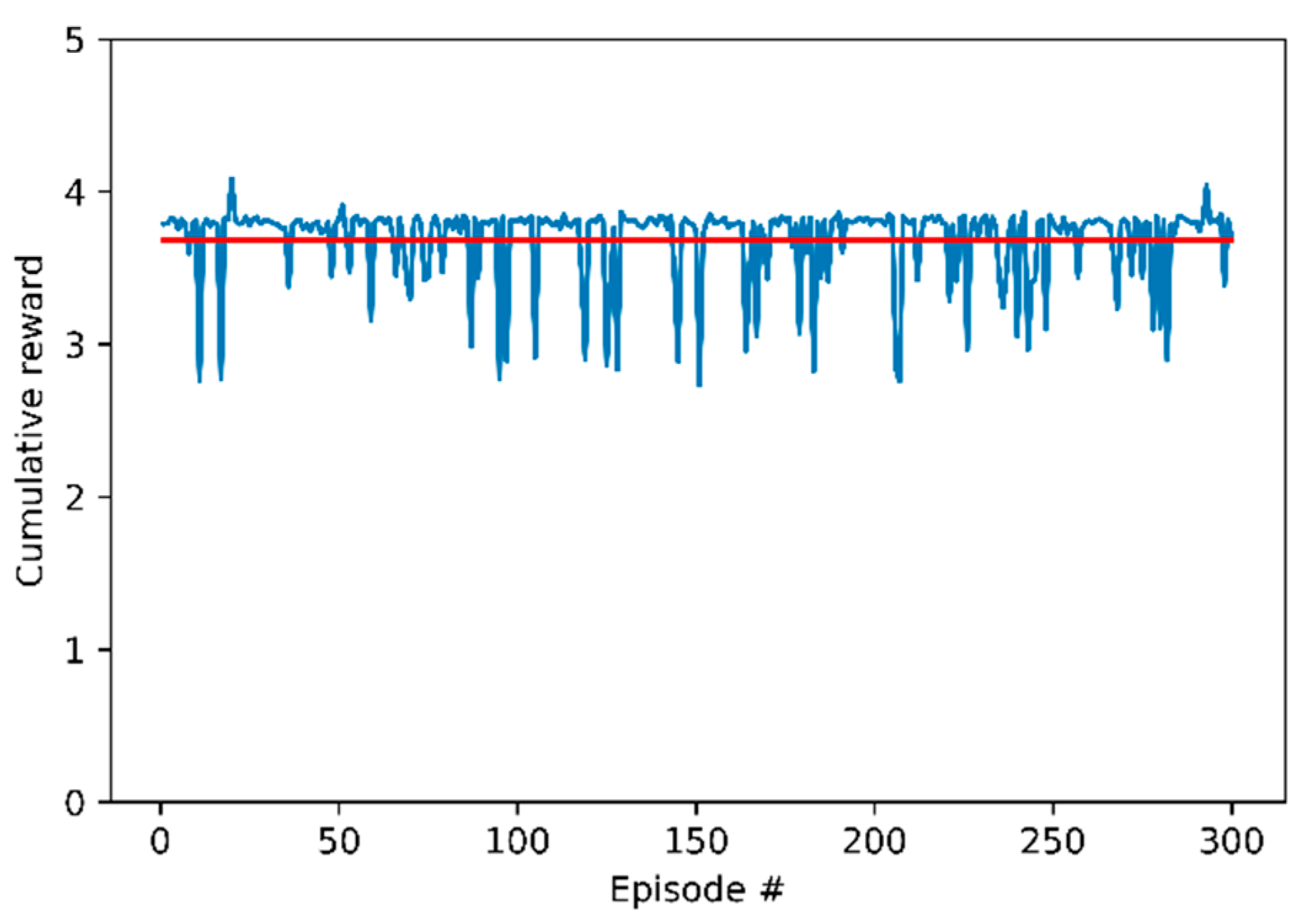
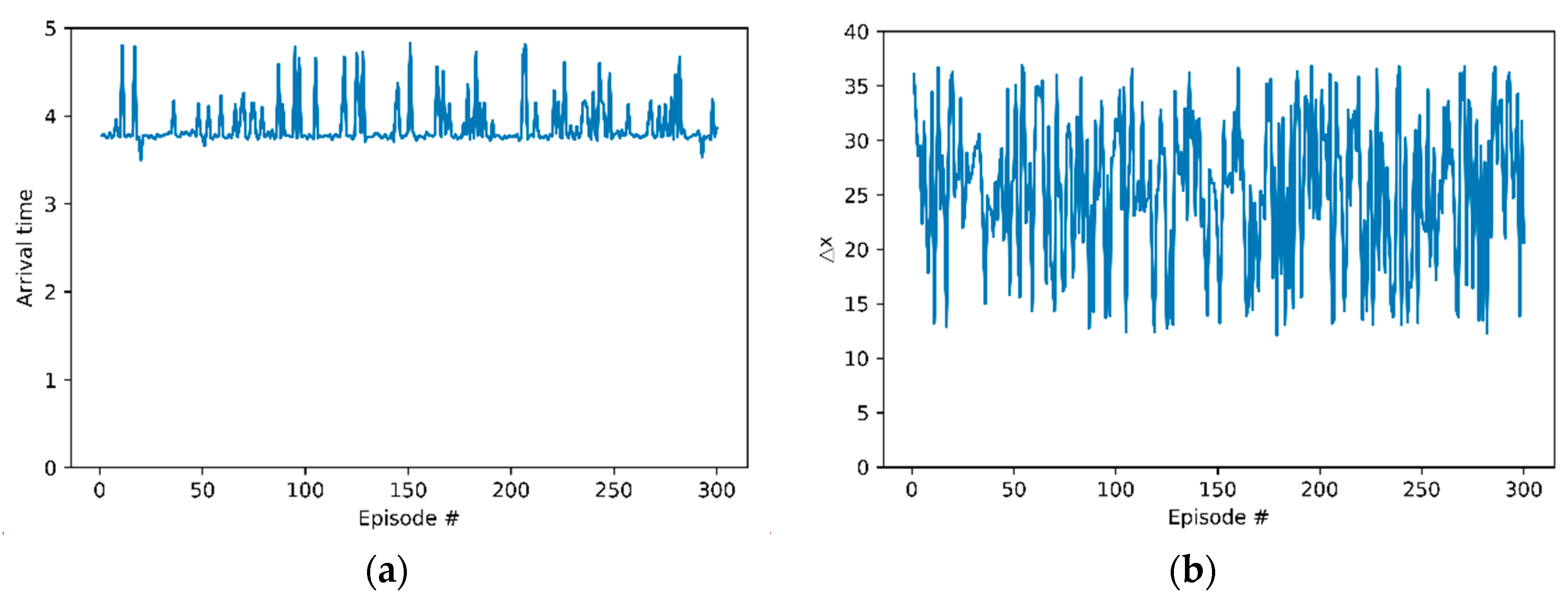
3.2. Training Details and Results
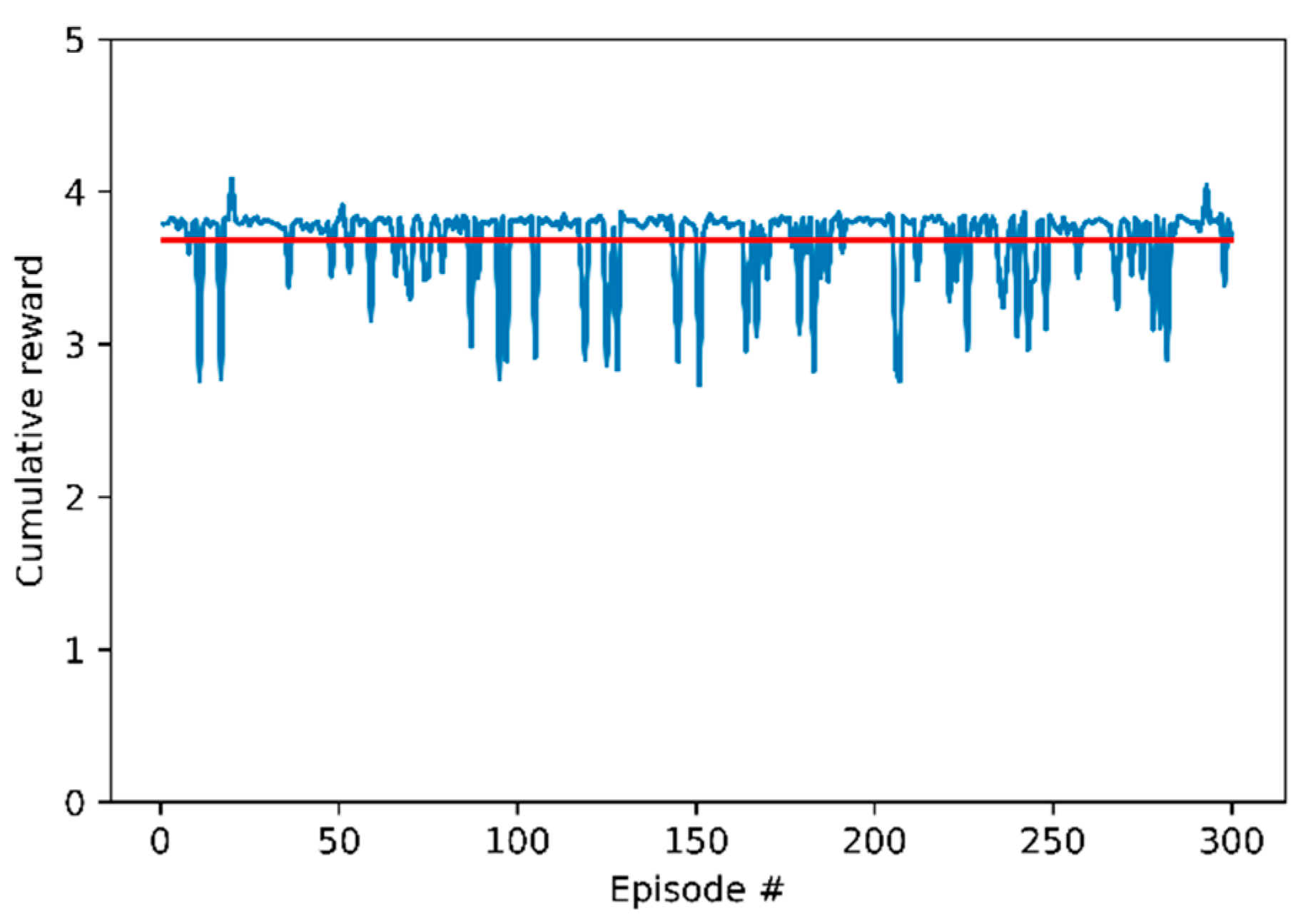
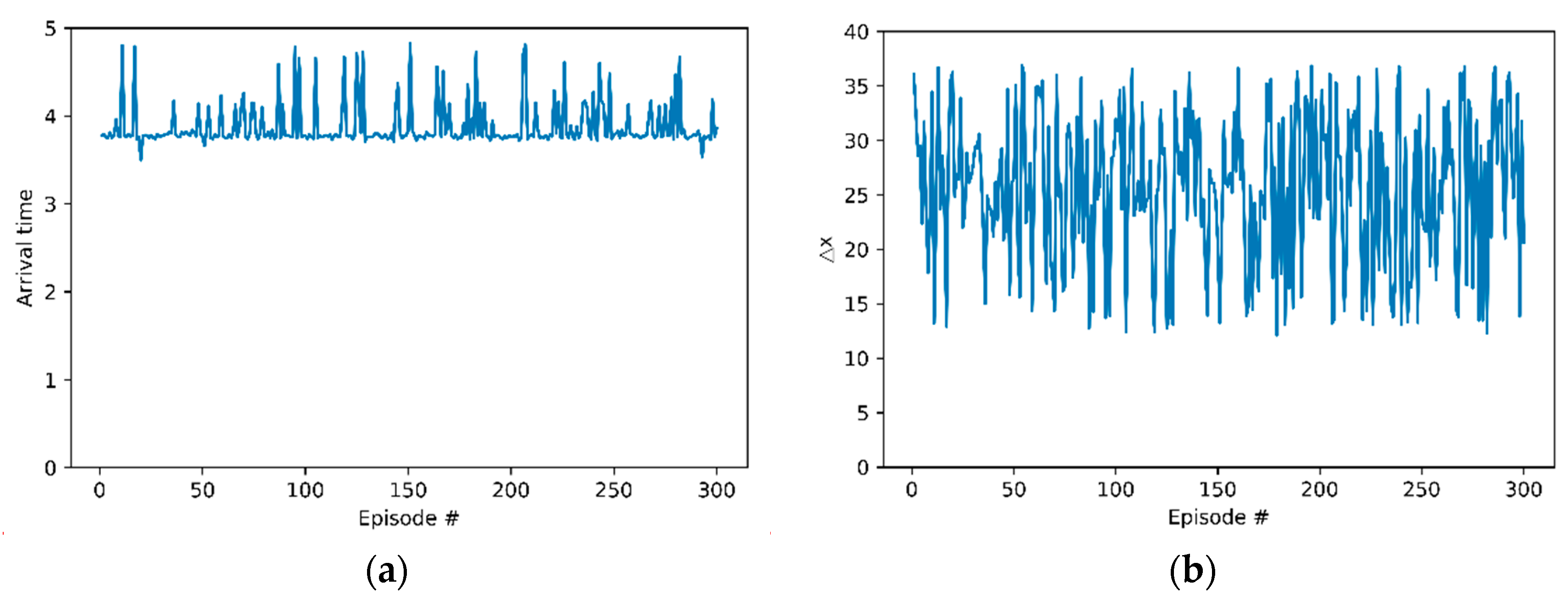
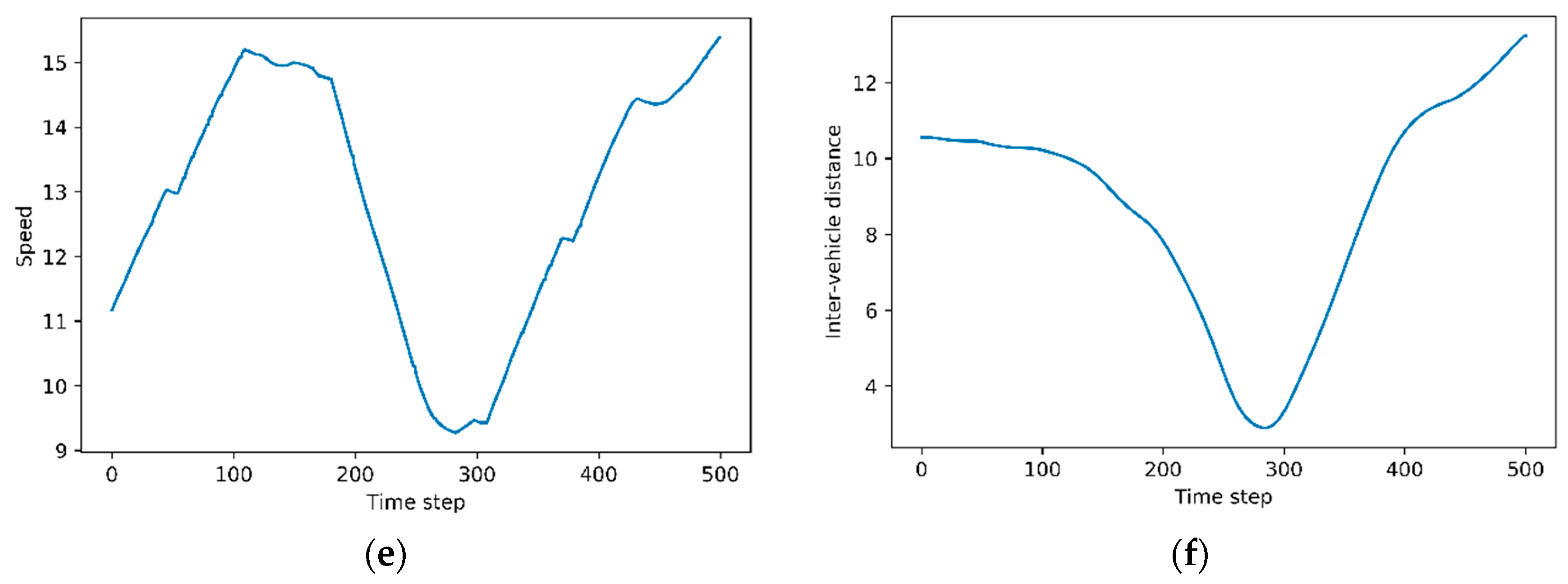
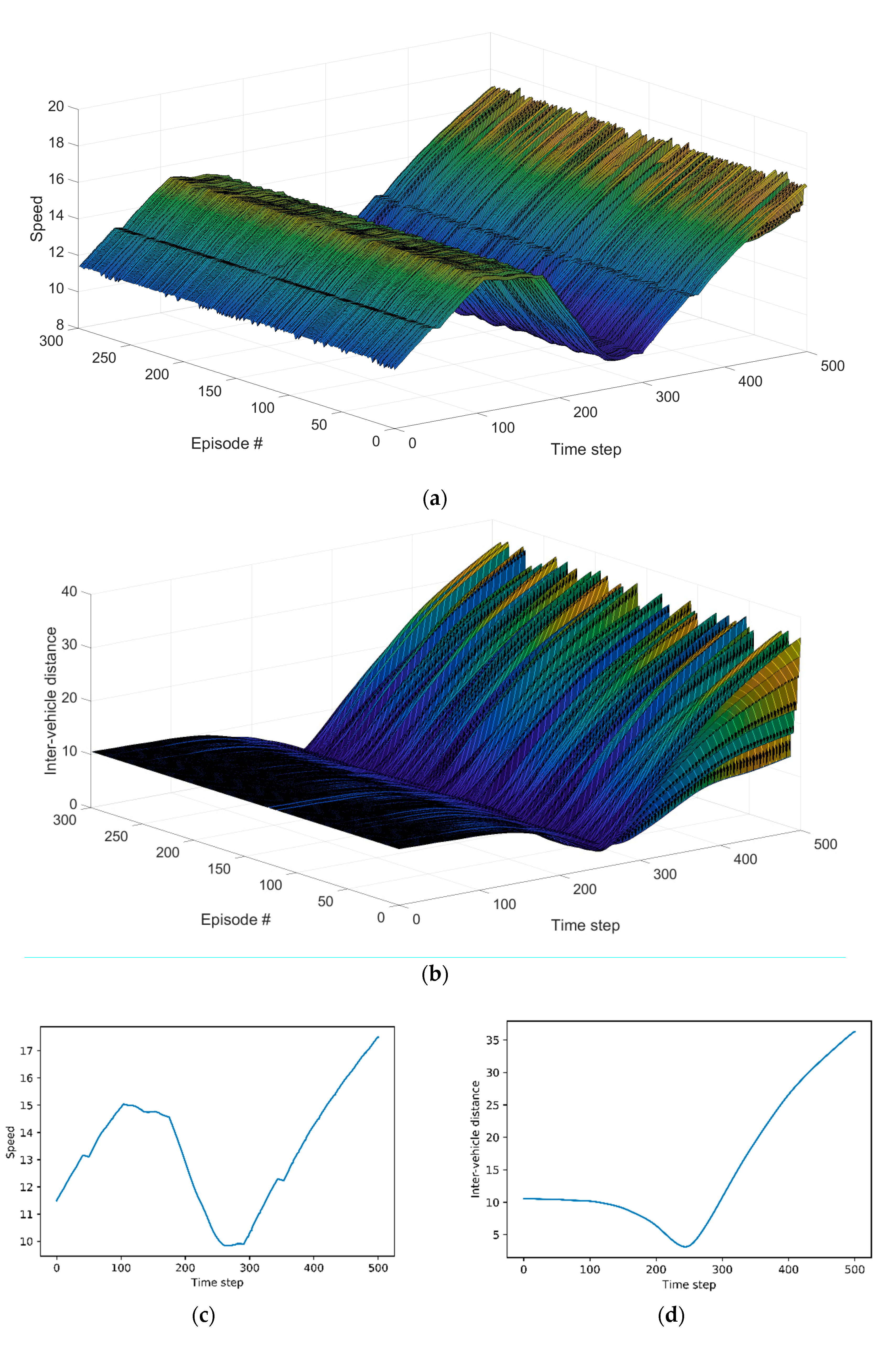
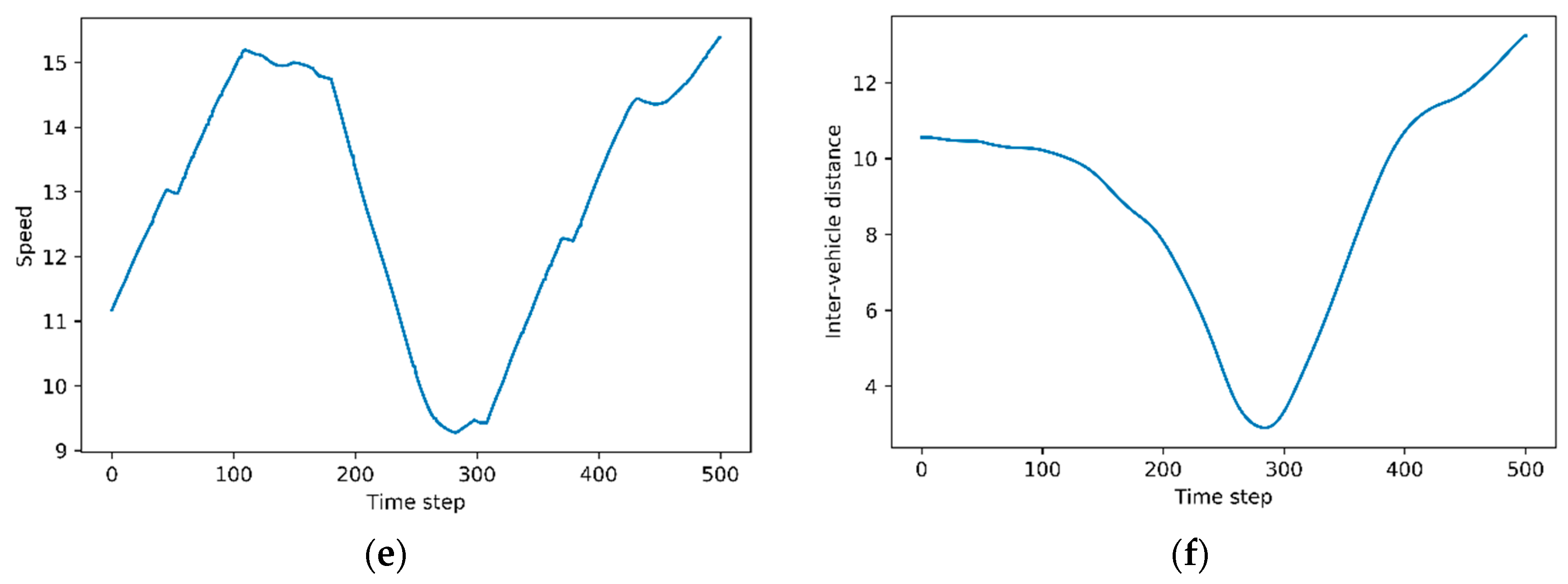
3.3. Evaluation Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nilsson, J.; Silvlin, J.; Brannstrom, M.; Coelingh, E.; Fredriksson, J. If, when, and how to perform lane change maneuvers on highways. IEEE Intell. Transp. Syst. 2016, 8, 68–78. [Google Scholar] [CrossRef]
- Cesari, G.; Schildbach, G.; Carvalho, A.; Borrelli, F. Scenario model predictive control for lane change assistance and autonomous driving on highways. IEEE Intell. Transp. Syst. 2017, 9, 23–35. [Google Scholar] [CrossRef]
- Al-Sultan, S.; Al-Doori, M.M.; Al-Bayatti, A.H.; Zedan, H. A comprehensive survey on vehicular ad hoc network. J. Netw. Comput. Appl. 2014, 37, 380–392. [Google Scholar] [CrossRef]
- Ali, G.M.N.; Noor-A-Rahim, M.; Rahman, M.A.; Samantha, S.K.; Chong, P.H.J.; Guan, Y.L. Efficient real-time coding-assisted heterogeneous data access in vehicular networks. IEEE Internet Things J. 2018, 5, 3499–3512. [Google Scholar] [CrossRef]
- Nguyen, H.; Liu, Z.; Jamaludin, D.; Guan, Y. A Semi-Empirical Performance Study of Two-Hop DSRC Message Relaying at Road Intersections. Information 2018, 9, 147. [Google Scholar] [CrossRef]
- Martin-Vega, F.J.; Soret, B.; Aguayo-Torres, M.C.; Kovacs, I.Z.; Gomez, G. Geolocation-based access for vehicular communications: Analysis and optimization via stochastic geometry. IEEE Trans. Veh. Technol. 2017, 67, 3069–3084. [Google Scholar] [CrossRef]
- He, J.; Tang, Z.; Fan, Z.; Zhang, J. Enhanced collision avoidance for distributed LTE vehicle to vehicle broadcast communications. IEEE Commun. Lett. 2018, 22, 630–633. [Google Scholar] [CrossRef]
- Hobert, L.; Festag, A.; Llatser, I.; Altomare, L.; Visintainer, F.; Kovacs, A. Enhancements of V2X communication in support of cooperative autonomous driving. IEEE Commun. Mag. 2015, 53, 64–70. [Google Scholar] [CrossRef]
- Bevly, D.; Cao, X.; Gordon, M.; Ozbilgin, G.; Kari, D.; Nelson, B.; Woodruff, J.; Barth, M.; Murray, C.; Kurt, A. Lane change and merge maneuvers for connected and automated vehicles: A survey. IEEE Trans. Intell. Veh. 2016, 1, 105–120. [Google Scholar] [CrossRef]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and decision-making for autonomous vehicles. Annu. Rev. Control Rob. Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A brief survey of deep reinforcement learning. arXiv 2017, arXiv:1708.05866. [Google Scholar] [CrossRef]
- Wolf, P.; Hubschneider, C.; Weber, M.; Bauer, A.; Härtl, J.; Dürr, F.; Zöllner, J.M. Learning How to Drive in a Real World Simulation with Deep Q-Networks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 244–250. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-Driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Wang, P.; Chan, C.-Y. Formulation of Deep Reinforcement Learning Architecture Toward Autonomous Driving for On-Ramp Merge. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Wang, P.; Chan, C.Y.; de La Fortelle, A. A reinforcement learning based approach for automated lane change maneuvers. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, Suzhou, China, 26 June–1 July 2018; pp. 1379–1384. [Google Scholar]
- Hoel, C.-J.; Wolff, K.; Laine, L. Automated Speed and Lane Change Decision Making using Deep Reinforcement Learning. arXiv 2018, arXiv:1803.10056. [Google Scholar]
- Kaushik, M.; Prasad, V.; Krishna, K.M.; Ravindran, B. Overtaking Maneuvers in Simulated Highway Driving using Deep Reinforcement Learning. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1885–1890. [Google Scholar]
- Mukadam, M.; Cosgun, A.; Nakhaei, A.; Fujimura, K. Tactical decision making for lane changing with deep reinforcement learning. In Proceedings of the NIPS Workshop on Machine Learning for Intelligent Transportation Systems, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Mirchevska, B.; Pek, C.; Werling, M.; Althoff, M.; Boedecker, J. High-level decision making for safe and reasonable autonomous lane changing using reinforcement learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2156–2162. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. Airsim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Proceedings of the 11th Conference on Field and Service Robotics, Zürich, Switzerland, 13–15 September 2017; pp. 621–635. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Lin, L.-J. Reinforcement Learning for Robots Using Neural Networks; Carnegie-Mellon University: Pittsburgh, PA, USA, 1993. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Training episodes, E | 2000 |
| Width of lanes | 3.4 m |
| Max time step, S | 500 |
| Weight corresponding to next lane, | 0.01 |
| Weight corresponding to initial lane, | 0.001 |
| Weight corresponding to speed, | 0.0002 |
| Initial velocity, | 11.11 m/s |
| Initial distance, | 10 m |
| Reply memory size | 1,000,000 |
| Minibatch size, N | 256 |
| Mean of normal distribution for exploration noise | 0 |
| Standard deviation for exploration noise | 1 |
| Minimum target speed, | 16.67 m/s |
| Maximum target speed, | 22.22 m/s |
| Maximum acceleration | 4.9 |
| Learning rate for actor | 0.001 |
| Learning rate for critic | 0.001 |
| Hidden units of actor network | 64, 64 |
| Hidden units of critic network | 64, 66 |
| Tau for deep deterministic policy gradient (DDPG) algorithm | 0.06 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, H.; Jung, J.-i. Decision-Making System for Lane Change Using Deep Reinforcement Learning in Connected and Automated Driving. Electronics 2019, 8, 543. https://doi.org/10.3390/electronics8050543
An H, Jung J-i. Decision-Making System for Lane Change Using Deep Reinforcement Learning in Connected and Automated Driving. Electronics. 2019; 8(5):543. https://doi.org/10.3390/electronics8050543
Chicago/Turabian StyleAn, HongIl, and Jae-il Jung. 2019. "Decision-Making System for Lane Change Using Deep Reinforcement Learning in Connected and Automated Driving" Electronics 8, no. 5: 543. https://doi.org/10.3390/electronics8050543
APA StyleAn, H., & Jung, J.-i. (2019). Decision-Making System for Lane Change Using Deep Reinforcement Learning in Connected and Automated Driving. Electronics, 8(5), 543. https://doi.org/10.3390/electronics8050543