A Key-Policy Searchable Attribute-Based Encryption Scheme for Efficient Keyword Search and Fine-Grained Access Control over Encrypted Data


Abstract
:1. Introduction
1.1. Motivation
1.2. Related Works
1.2.1. Searchable Encryption
1.2.2. Attribute Based Encryption
1.2.3. Searchable Attribute-Based Encryption
1.3. Contributions
- (1)
- We propose KPSABES, a key-policy searchable attribute-based encryption scheme. KPSABES enables efficient keyword based search and flexible and fine-grained access control over encrypted data by leveraging the searchable encryption and the key-policy attribute-based encryption.
- (2)
- We analyzed the performance complexity for our proposed algorithms in KPSABES and the similar scheme KP-ABKS in [49]. In addition, we provide the thorough security proofs for our proposed scheme.
- (3)
- We implemented our proposed KPSABES and the similar work KP-ABKS in [49], and made the thorough performance comparisons between these two schemes through extensive experiments. The results demonstrate that KPSABES is superior in many aspects to PK-ABKS.
2. Background Knowledge
2.1. Bilinear Map
- (1)
- Computability: For all , there exists an efficient polynomial time algorithm to compute .
- (2)
- Bilinearity: For all and , holds.
- (3)
- Non-degeneracy: , where g is a generator of .
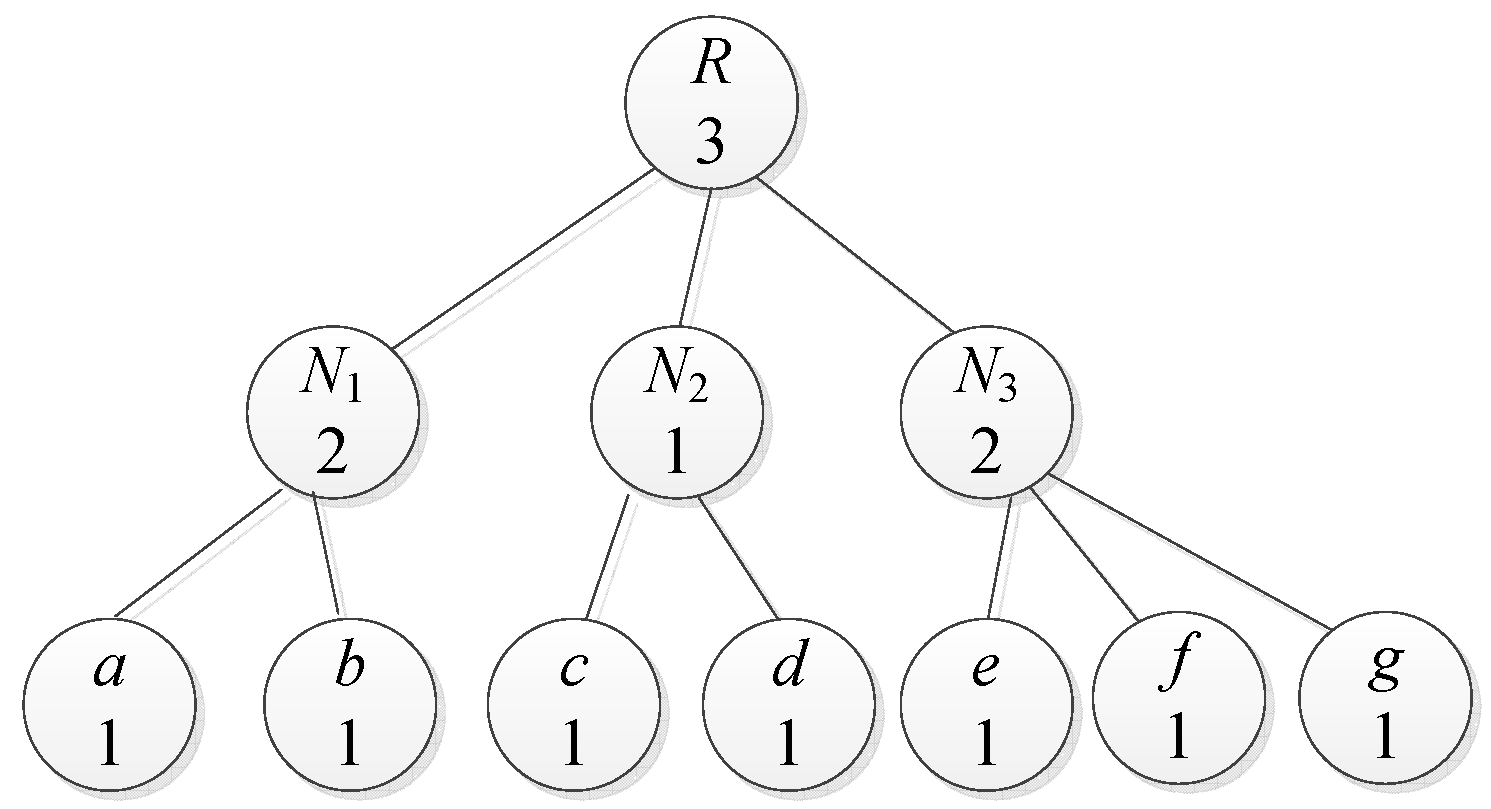
2.2. Access Tree
- (1)
- : The parent of node x.
- (2)
- : The ordering number of node x with respect to its parent node . For example, if x is the first child (from left to right) of node , then , and so forth.
- (3)
- : The attribute associated with the leaf node x in an attribute-based encryption system.
2.3. Complexity Assumption
- (1)
- Decisional Diffie–Hellman (DDH) assumption. Let g be a generator of group with order p; choose three elements at random uniformly. The DDH assumption is that no probabilistic polynomial-time adversary can distinguish the tuple from the tuple with a non-negligible advantage.
- (2)
- Decisional Bilinear Diffie–Hellman (DBDH) assumption. Let and be two multiplicative groups of order p, where g is a generator of and e denotes a bilinear map; choose four elements at random uniformly. DBDH assumption is that no probabilistic polynomial-time adversary can distinguish the tuple from the tuple with a non-negligible advantage.
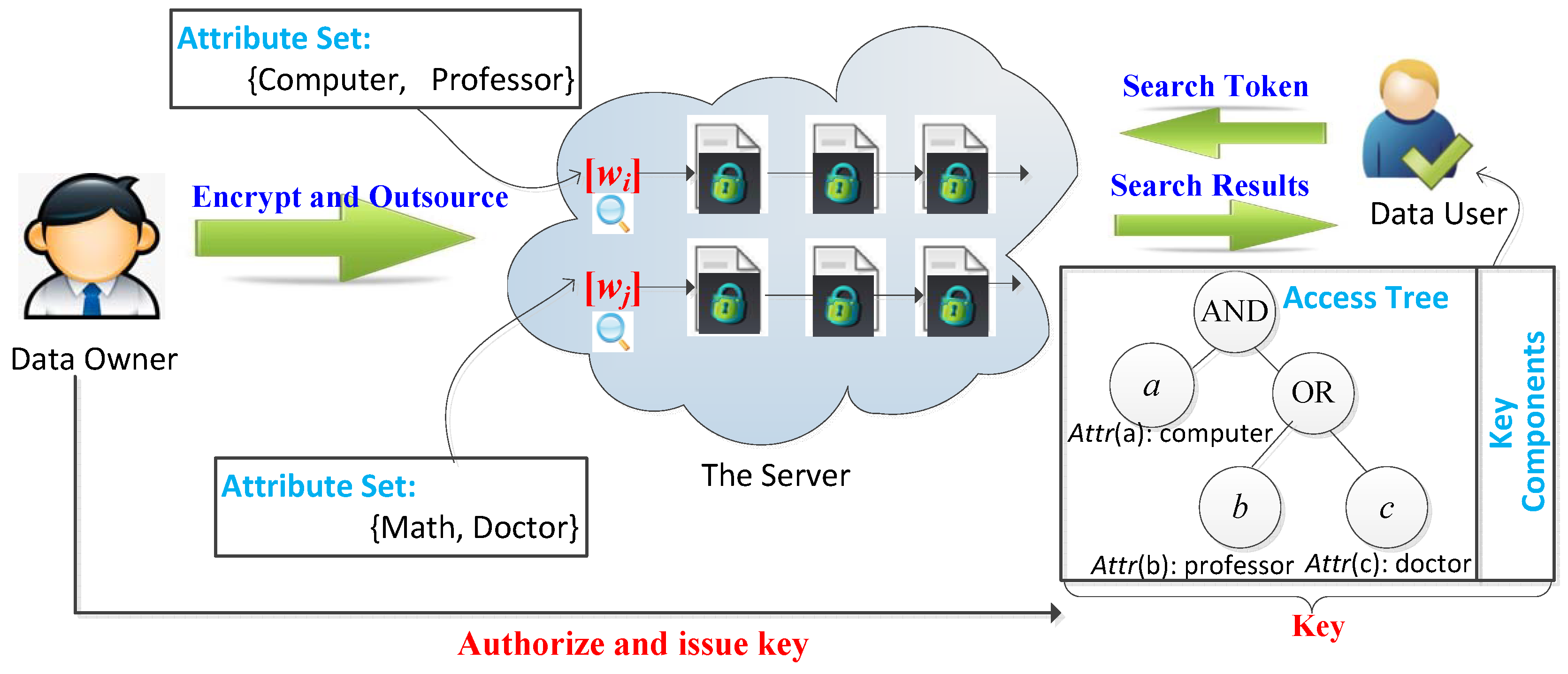
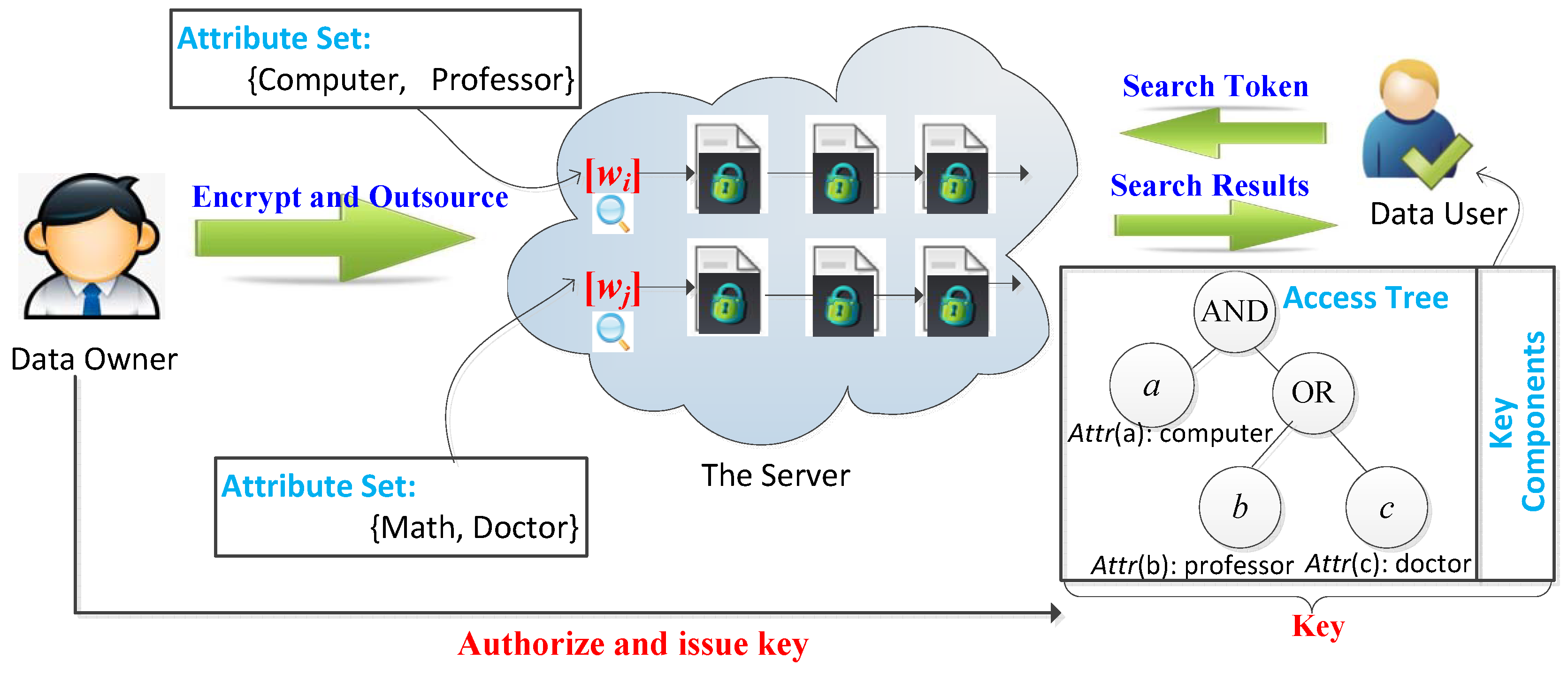
3. System Model and Security Model
3.1. System Model
3.2. Security Model
4. Definition and Construction of KPSABES
4.1. Definition
- Setup. The data owner runs setup algorithm to output system public parameter PK and the master private key MK, where is a security parameter as the input of this algorithm.
- Keygen(. The data owner runs keygen algorithm to generate the private key for a data user u, where PK and MK are the system public parameter and the master private, respectively, and is an access tree which defines u’s search permission.
- Enc(. The data owner runs enc algorithm to encrypt an index keyword w and outputs w’s ciphertext , where PK is the system public parameter, w is an index keyword, and is a set of attributes which defines w’s access permission.
- Searchtoken(. The data user u runs searchtoken algorithm to encrypt a query keyword and outputs ’s search token , where PK is the public parameter, is the data user u’s private key, and denotes any query keyword.
- Search(. The server runs search algorithm to perform matching between the encrypted index keyword and the search token with the help of the system public parameter PK. The algorithm outputs 1 if the data user u has access to the index keyword w and w is identical to , simultaneously; otherwise, it outputs 0.
4.2. Construction
4.2.1. Setup
4.2.2. Keygen
4.2.3. Enc
4.2.4. Searchtoken
4.2.5. Search
5. Performance Analysis
6. Security Proof
- PolySat. PolySat takes as input an access tree rooted at x such that , the attribute set , a secret value , and determines the polynomials for each node of . Specifically, it first generates a polynomial of degree for the root node x such that and randomly sets other points to completely generate . Then, for each child node of x, it calls PolySat, where .
- PolyUnsat. PolyUnsat takes as input an access tree rooted at x such that , the attribute set , a group element , , and determines the polynomials for each node of . Specifically, it first generates a polynomial of degree for the root node x and makes . means that no more than children of node x are satisfied. Let SC denote a set of child nodes of x that are satisfied by , we have . For each node , it randomly chooses a value and sets and randomly chooses other points to completely define . Then, the procedure continues to run PolySat if , where is known to the simulator; otherwise, the PolyUnsat is run, where is known to the simulator.
- If , chooses a random value and sets , , and .
- If , let , chooses a random value and sets the key components corresponding to the node x as follows.If we let , the above keys are legitimate, because
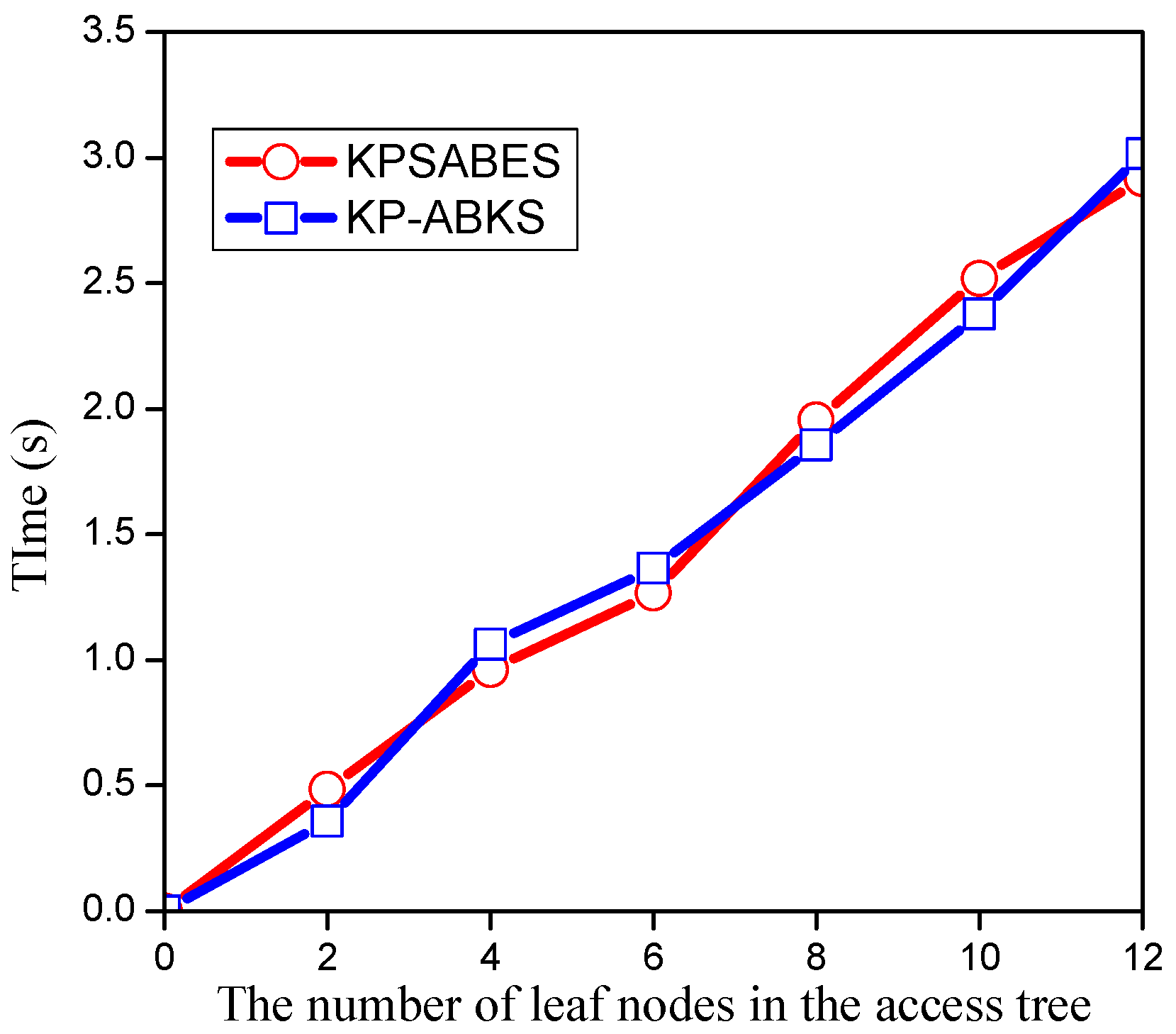
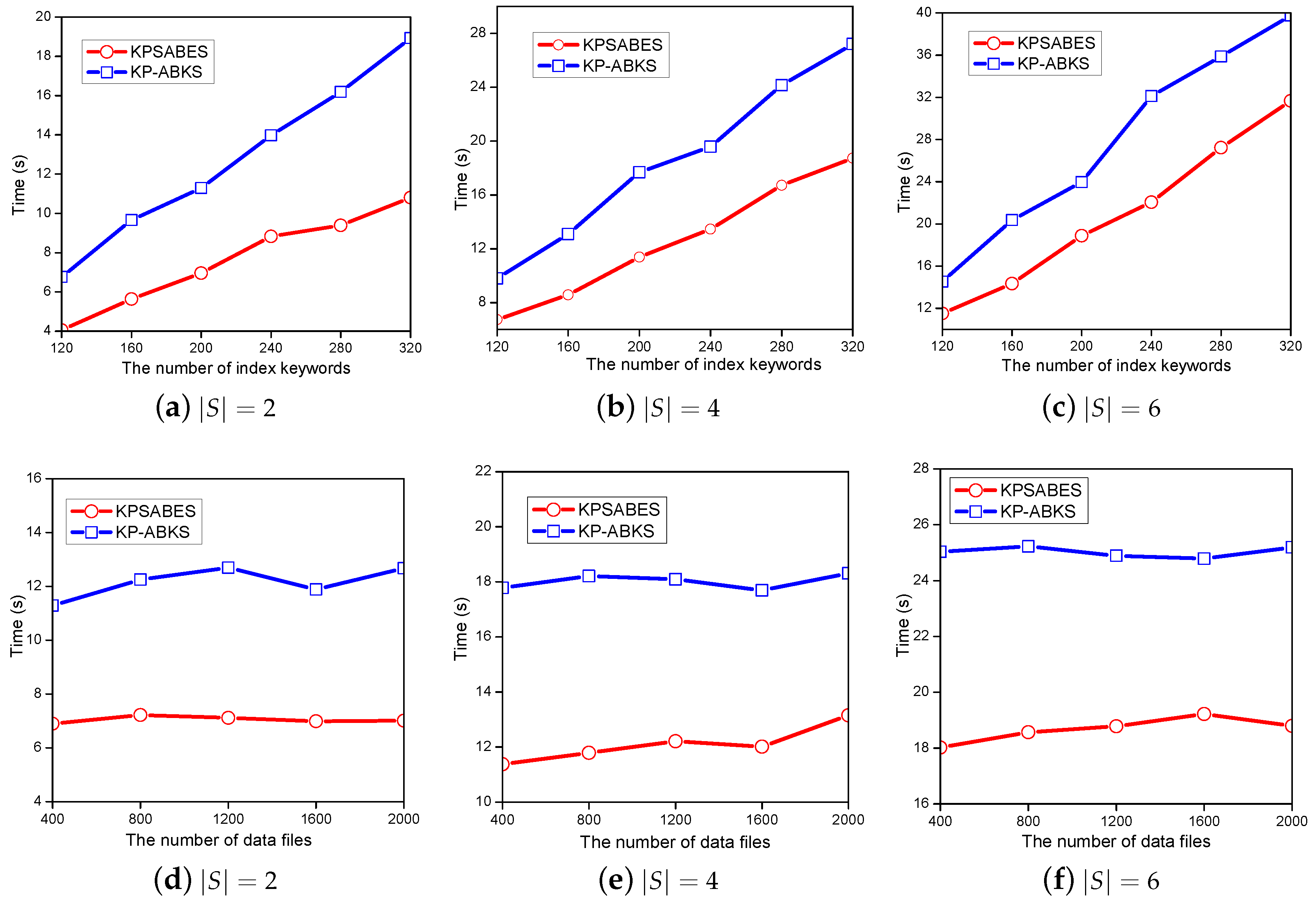
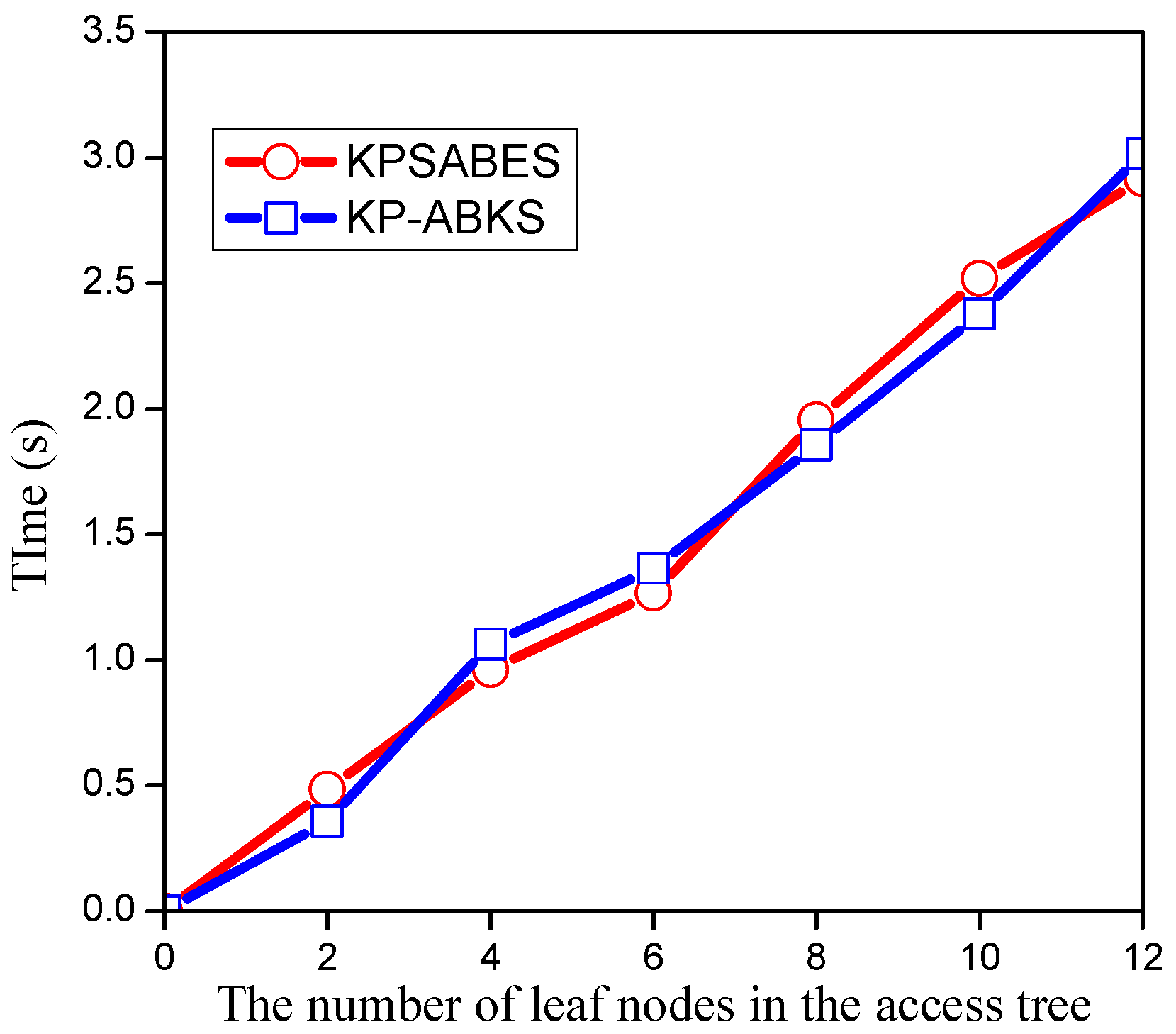
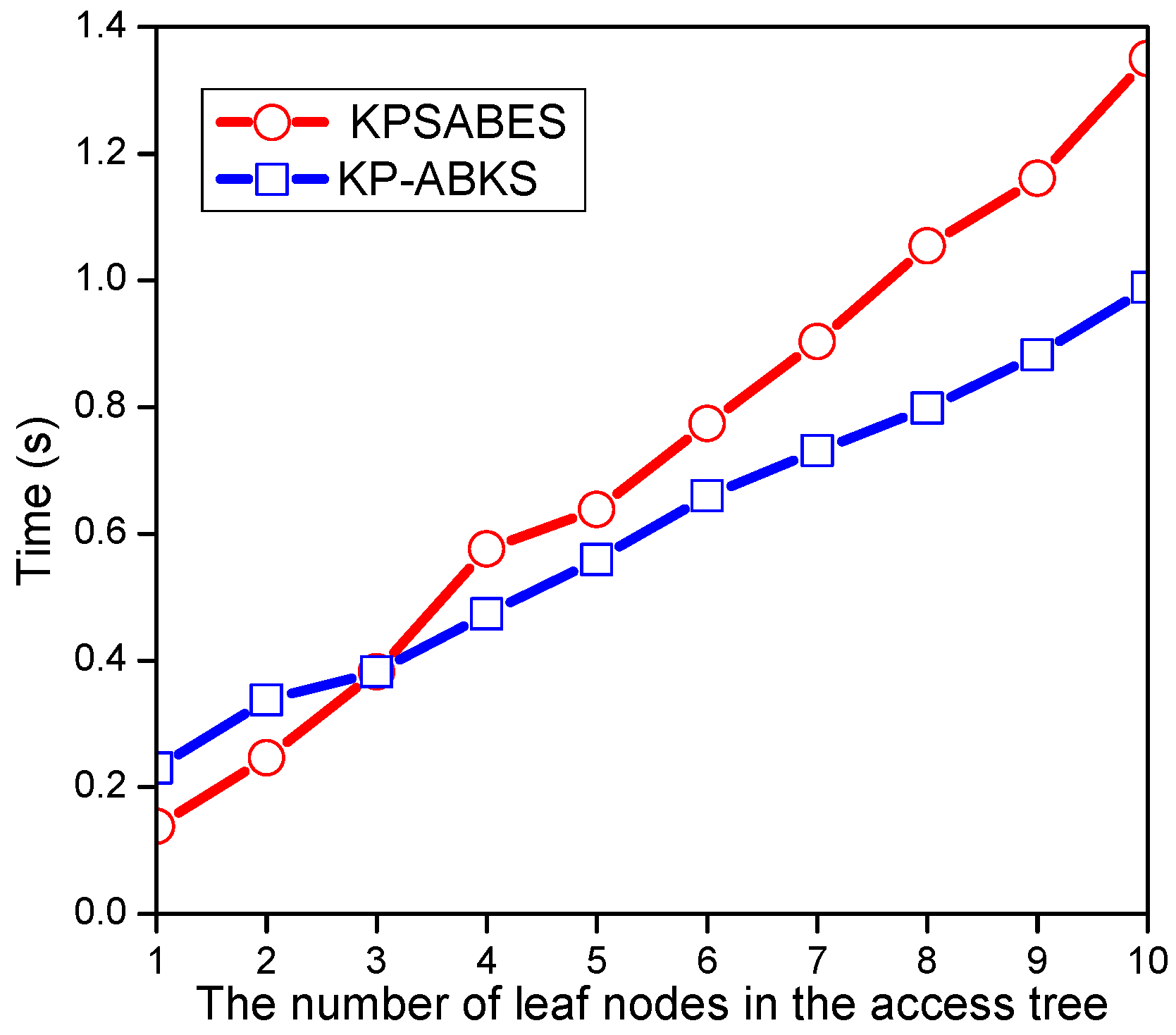
7. Experimental Evaluation
7.1. Evaluation of Setup Algorithm
7.2. Evaluation of Keygen Algorithm
7.3. Evaluation of Enc Algorithm
7.4. Evaluation of Searchtoken Algorithm
7.5. Evaluation of Search Algorithm
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ren, K.; Wang, C.; Wang, Q. Security Challenges for the Public Cloud. IEEE Internet Comput. 2012, 16, 69–73. [Google Scholar] [CrossRef]
- Kamara, S.; Lauter, K. Cryptographic cloud storage. In Financial Cryptography and Data Security; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Peng, Y.; Zhao, W.; Xie, F.; Dai, Z.; Gao, Y.; Chen, D. Secure cloud storage based on cryptographic techniques. J. China Univ. Posts Telecommun. 2012, 19, 182–189. [Google Scholar] [CrossRef]
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-based encryption for fine-grained access control of encryption data. In Proceedings of the 13th ACM Conference on Computer and Communications Security, CCS 2006, Alexandria, VA, USA, 30 October–3 November 2006; pp. 89–98. [Google Scholar]
- Song, D.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the IEEE Symposiumon Security and Privacy, Berkeley, CA, USA, 14–17 May 2000; Volume 8, pp. 44–55. [Google Scholar]
- Curtmola, R.; Garay, J.; Kamara, S.; Ostrovsky, R. Searchable symmetric encryption: Improved deinitions and efficient constructions. In Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006; Volume 19, pp. 79–88. [Google Scholar]
- Kamara, S.; Papamanthou, C.; Roeder, T. Dynamic searchable symmetric encryption. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 965–976. [Google Scholar]
- Stefanov, E.; Papamanthou, C.; Shi, E. Practical Dynamic Searchable Encryption with Small Leakage. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Kim, K.S.; Kim, M.; Lee, D.; Park, J.H.; Kim, W.H. Forward Secure Dynamic Searchable Symmetric Encryption with Efficient Updates. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1449–1463. [Google Scholar]
- Bost, R.; Minaud, B.; Ohrimenko, O. Forward and Backward Private Searchable Encryption from Constrained Cryptographic Primitives. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1465–1482. [Google Scholar]
- Kurosawa, K.; Ohtaki, Y. UC-Secure Searchable Symmetric Encryption. In Financial Cryptography and Data Security; Springer: Berlin/Heidelberg, Germany, 2012; pp. 285–298. [Google Scholar]
- Yin, H.; Qin, Z.; Zhang, J.; Ou, L.; Li, K. Achieving secure, universal, and fine-grained query results verification for secure search scheme over encrypted cloud data. IEEE Trans. Cloud Comput. 2017. [Google Scholar] [CrossRef]
- Zhang, Y.; Deng, R.H.; Shu, J.; Yang, K.; Zheng, D. TKSE: Trustworthy Keyword Search over Encrypted Data with Two-side Verifiability via Blockchain. IEEE Access 2018, 6, 31077–31087. [Google Scholar] [CrossRef]
- Hu, S.; Cai, C.; Wang, Q.; Luo, X.; Ren, K. Searching an Encrypted Cloud Meets Blockchain: A Decentralized, Reliable and Fair Realization. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 792–800. [Google Scholar]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-preserving multi-keyword ranked search over encrypted cloud data. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 222–233. [Google Scholar] [CrossRef]
- Sun, W.; Wang, B.; Cao, N.; Li, M.; Lou, W.; Hou, Y.T. Verifiable privacy-preserving multi-keyword text search in the cloud supporting similarity-based ranking. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 3025–3035. [Google Scholar] [CrossRef]
- Wang, B.; Yu, S.; Luo, W.; Hou, Y. Privacy-Preserving Multi-Keyword Fuzzy Search over Encrypted Data in the Cloud. In Proceedings of the IEEE INFOCOM—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 2112–2120. [Google Scholar]
- Xia, Z.; Wang, X.; Sun, X.; Wang, Q. A secure and dynamic multi-keyword ranked search scheme over encrypted cloud data. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 340–352. [Google Scholar] [CrossRef]
- Li, H.; Yang, Y.; Luan, T.; Liang, X.; Zhou, L.; Shen, X. Enabling Fine-grained Multi-keyword Search Supporting Classified Sub-dictionaries over Encrypted Cloud Data. IEEE Trans. Dependable Secure Comput. 2016, 13, 312–325. [Google Scholar] [CrossRef]
- Fu, Z.; Ren, K.; Shu, J.; Sun, X.; Huang, F. Enabling Personalized Search over Encrypted Outsourced Data with Efficiency Improvement. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2546–2559. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Q.; Shu, J.; Wang, G. PRMS: A Personalized Mobile Search over Encrypted Outsourced Data. IEEE Access 2018, 6, 31541–31552. [Google Scholar] [CrossRef]
- Boneh, D.; Crescenzo, G.D.; Ostrovsky, R.; Persiano, G. Public-key encryption with keyword search. In Advances in Cryptology—EUROCRYPT 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 506–522. [Google Scholar]
- Golle, P.; Staddon, J.; Waters, B. Secure conjunctive keyword search over encrypted data. In Applied Cryptography and Network Security; Springer: Berlin/Heidelberg, Germany, 2004; pp. 31–45. [Google Scholar]
- Ballard, L.; Kamara, S.; Monrose, F. Achieving efficient conjunctive keyword searches over encrypted data. In Information and Communications Security; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Boneh, D.; Waters, B. Conjunctive, subset, and range queries on encrypted data. In Theory of Cryptography; Springer: Berlin/Heidelberg, Germany, 2007; pp. 535–554. [Google Scholar]
- Yin, H.; Qin, Z.; Zhang, J.; Li, W.; Ou, L.; Hu, Y.; Li, K. Secure Conjunctive Multi-keyword Search for Multiple Data Owners in Cloud Computing. In Proceedings of the 2016 IEEE 22nd International Conference on Parallel and Distributed Systems (ICPADS), Wuhan, China, 13–16 December 2016; pp. 761–768. [Google Scholar]
- Sahai, A.; Waters, B. Fuzzy Identity-Based Encryption. In Advances in Cryptology—EUROCRYPT 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 457–473. [Google Scholar]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-policy attribute-based encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Cheung, L.; Newport, C. Provably Secure Ciphertext Policy ABE. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 29 October–2 November 2007; pp. 456–465. [Google Scholar]
- Waters, B. Ciphertext-policy attribute-based encryption: An expressive, efficient, and provably secure realization. In Public Key Cryptography; Springer: Berlin/Heidelberg, Germany, 2011; pp. 53–70. [Google Scholar]
- Lewko, A.B.; Waters, B. Decentralizing attribute-based encryption. In Advances in Cryptology—EUROCRYPT 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 547–567. [Google Scholar]
- Ostrovsky, R.; Sahai, A.; Waters, B. Attribute-based encryption with non-monotonic access structures. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 29 October–2 November 2007; pp. 195–203. [Google Scholar]
- Chase, M. Multi-authority attribute based encryption. In Theory of Cryptography; Springer: Berlin/Heidelberg, Germany, 2007; pp. 515–534. [Google Scholar]
- Chase, M.; Chow, S.S.M. Improving privacy and security in multi-authority attribute-based encryption. In Proceedings of the 16th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 9–13 November 2009; pp. 121–130. [Google Scholar]
- Kapadia, A.; Tsang, P.P.; Smith, S.W. Attribute-based publishing with hidden credentials and hidden policies. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2007, San Diego, CA, USA, 28 February–2 March 2007; pp. 179–192. [Google Scholar]
- Nishide, T.; Yoneyama, K.; Ohta, K. ABE with partially hidden encryptor-specified access structure. In Applied Cryptography and Network Security; Springer: Berlin/Heidelberg, Germany, 2008; pp. 111–129. [Google Scholar]
- Zhang, Y.; Zheng, D.; Deng, R.H. Security and Privacy in Smart Health: Efficient Policy-Hiding Attribute-Based Access Control. IEEE Internet Things J. 2018, 5, 2130–2145. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X.; Li, J.; Wong, D.S.; Li, H.; You, I. Ensuring attribute privacy protection and fast decryption for outsourced data security in mobile cloud computing. Inf. Sci. 2017, 379, 42–61. [Google Scholar] [CrossRef]
- Sun, W.; Yu, S.; Lou, W.; Hou, Y.T.; Li, H. Protecting your right: Attribute-based keyword search with fine-grained owner-enforced search authorization in the cloud. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 226–234. [Google Scholar]
- Wang, H.; Dong, X.; Cao, Z. Multi-value-Independent Ciphertext-Policy Attribute Based Encryption with Fast Keyword Search. IEEE Trans. Serv. Comput 2017. [Google Scholar] [CrossRef]
- Wang, C.; Li, W.; Li, Y.; Xu, X. A Ciphertext-Policy Attribute-Based Encryption Scheme Supporting Keyword Search Function. In Cyberspace Safety and Security; Springer: Cham, Switzerland, 2013; pp. 377–386. [Google Scholar]
- Liang, K.; Susilo, W. Searchable Attribute-Based Mechanism With Efficient Data Sharing for Secure Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1981–1992. [Google Scholar] [CrossRef]
- Cui, H.; Wan, Z.; Deng, R.; Wang, G.; Li, Y. Efficient and Expressive Keyword Search Over Encrypted Data in Cloud. IEEE Trans. Dependable Secure Comput. 2018, 15, 409–422. [Google Scholar] [CrossRef]
- Wang, S.; Ye, J.; Zhang, Y. Searchable attribute-based encryption scheme with attribute revocation in cloud storage. PLoS ONE 2018, 12, e0183459. [Google Scholar] [CrossRef] [PubMed]
- Yin, H.; Zhang, J.; Xiong, Y.; Ou, L.; Li, F.; Liao, S.; Li, K. CP-ABSE: A Ciphertext-Policy Attribute-Based Searchable Encryption Scheme. IEEE Access 2019, 7, 5682–5694. [Google Scholar] [CrossRef]
- Lai, J.; Zhou, X.; Deng, R.H.; Chen, K. Expressive search on encrypted data. In Proceedings of the ACM Sigsac Symposium on Information, Computer and Communications Security, Hangzhou, China, 8–10 May 2013; pp. 243–252. [Google Scholar]
- Lv, Z.; Hong, C.; Zhang, M.; Feng, D. Expressive and Secure Searchable Encryption in the Public Key Setting. In Proceedings of the International Information Security Conference, Hong Kong, China, 12–14 October 2014; pp. 364–376. [Google Scholar]
- Peng, T.; Qin, L.; Hu, B.; Liu, J.; Zhu, J. Dynamic Keyword Search With Hierarchical Attributes in Cloud Computing. IEEE Access 2018, 6, 68948–68960. [Google Scholar] [CrossRef]
- Zheng, Q.; Xu, S.; Ateniese, G. Vabks: Verifiable attribute-based keyword search over outsourced encrypted data. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 522–530. [Google Scholar]
- Yin, H.; Qin, Z.; Ou, L.; Li, K. A query privacy-enhanced and secure search scheme over encrypted data in cloud computing. J. Comput. Syst. Sci. 2017, 90, 14–27. [Google Scholar] [CrossRef]
- JPBC. Available online: http://gas.dia.unisa.it/projects/jpbc/index.html (accessed on 10 October 2018).
- RFC: Request for Comments Database. Available online: http://www.ietf.org/rfc.html (accessed on 10 October 2018).
- Hermetic Word Frequency Counter. Available online: http://www.hermetic.ch/wfc/wfc.htm (accessed on 10 October 2018).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| P | Time cost of a pairing computation. |
| Time cost of an exponentiation in group . | |
| Time cost of an exponentiation in group . | |
| Time cost of choosing a random element from . | |
| H | Time cost of hashing a bit-string to an element of . |
| The cardinality if x is a set; the bit-length if x is an element. | |
| L | Leaf-node set of the access tree in the data user’s private key. |
| Attribute set of encrypting an index keyword. | |
| S | Least interior node set satisfying an access structure (include the root). |
| U | Universe set of attributes. |
| Algorithm | KPSABES | KP-ABKS [49] |
|---|---|---|
| Setup | ||
| Keygen | ||
| Enc | ||
| Searchtoken | ||
| Search |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, H.; Xiong, Y.; Zhang, J.; Ou, L.; Liao, S.; Qin, Z. A Key-Policy Searchable Attribute-Based Encryption Scheme for Efficient Keyword Search and Fine-Grained Access Control over Encrypted Data. Electronics 2019, 8, 265. https://doi.org/10.3390/electronics8030265
Yin H, Xiong Y, Zhang J, Ou L, Liao S, Qin Z. A Key-Policy Searchable Attribute-Based Encryption Scheme for Efficient Keyword Search and Fine-Grained Access Control over Encrypted Data. Electronics. 2019; 8(3):265. https://doi.org/10.3390/electronics8030265
Chicago/Turabian StyleYin, Hui, Yinqiao Xiong, Jixin Zhang, Lu Ou, Shaolin Liao, and Zheng Qin. 2019. "A Key-Policy Searchable Attribute-Based Encryption Scheme for Efficient Keyword Search and Fine-Grained Access Control over Encrypted Data" Electronics 8, no. 3: 265. https://doi.org/10.3390/electronics8030265
APA StyleYin, H., Xiong, Y., Zhang, J., Ou, L., Liao, S., & Qin, Z. (2019). A Key-Policy Searchable Attribute-Based Encryption Scheme for Efficient Keyword Search and Fine-Grained Access Control over Encrypted Data. Electronics, 8(3), 265. https://doi.org/10.3390/electronics8030265