Fusion of 2D CNN and 3D DenseNet for Dynamic Gesture Recognition


Abstract
1. Introduction
2. Methodology
2.1. The Framework of the Proposed Method
2.2. The Proposed 3D DenseNet Model for Gesture Recognition
2.3. The 2D Motion Representation CNN Model
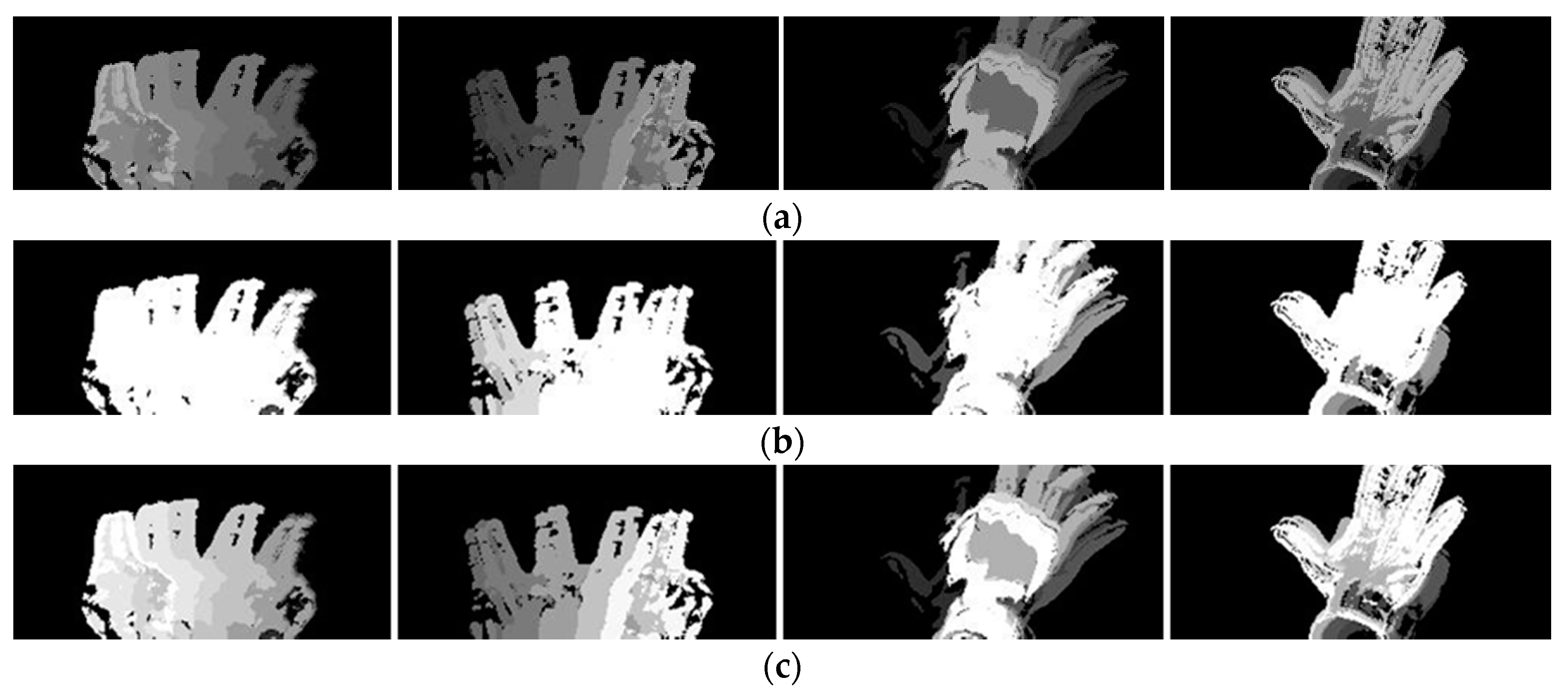
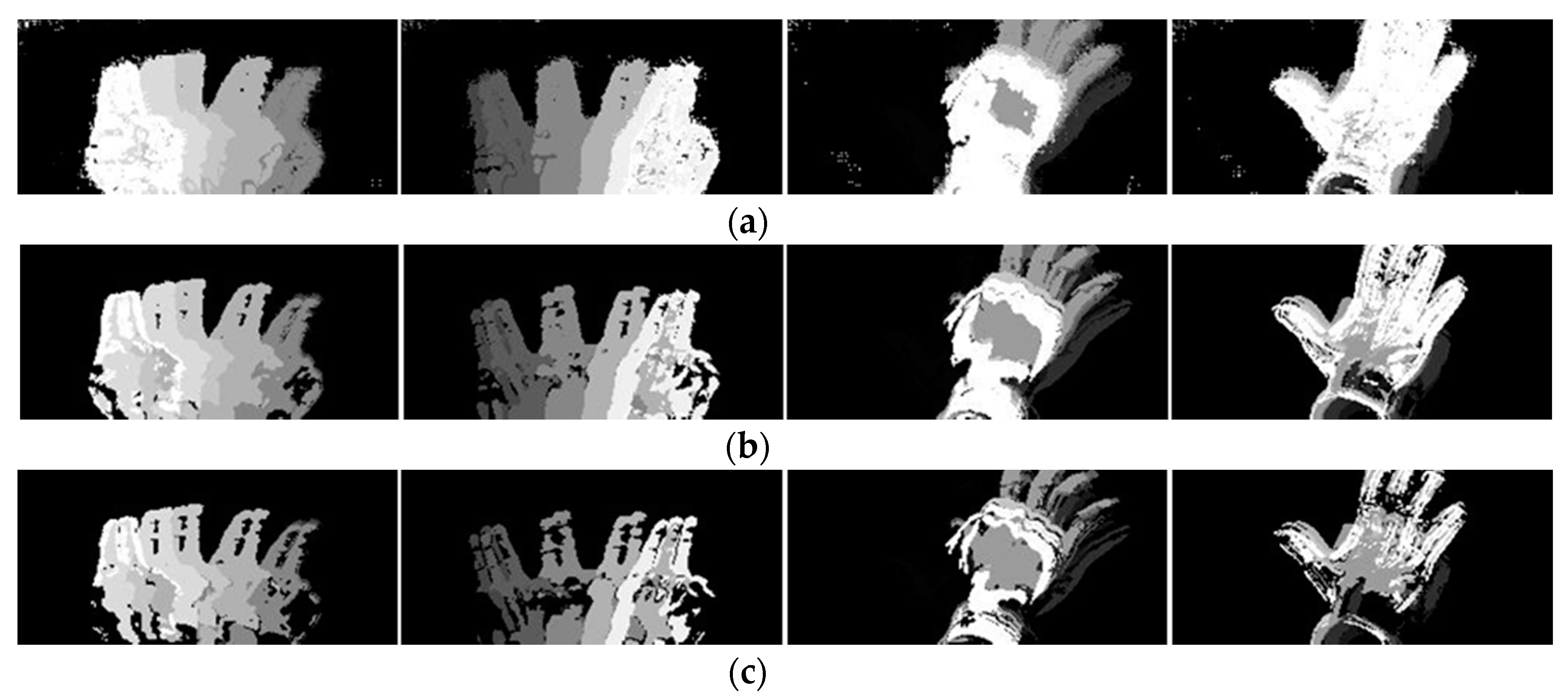
2.3.1. Motion Representation Based on MHI
2.3.2. Pseudo-Coloring for MHI
2.3.3. 2D CNN Based on VGGNet
2.4. Fusion Scheme
3. Experiment
3.1. Dataset
3.2. Experimental Setup
3.3. Performance Evaluation of the Proposed Method
3.4. Comparison with Other Methods
3.5. Performance Evaluation on the Depth Dataset
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. Part C. Appl. Rev. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Han, F.; Reily, B.; Hoff, W.; Zhang, H. Space-time representation of people based on 3D skeletal data: A review. Comput. Vis. Image Underst. 2017, 158, 85–105. [Google Scholar] [CrossRef]
- Maghoumi, M.; LaViola, J.J., Jr. DeepGRU: Deep gesture recognition utility. In Proceedings of the 14th International Symposium on Visual Computing (ISVC 2019), Lake Tahoe, NV, USA, 7–9 October 2019; pp. 16–31. [Google Scholar]
- Paraskevopoulos, G.; Spyrou, E.; Sgouropoulos, D.; Giannakopoulos, T.; Mylonas, P. Real-time arm gesture recognition using 3D skeleton joint data. Algorithm 2019, 12, 108. [Google Scholar] [CrossRef]
- Nguyen, X.; Brun, L.; Lézoray, O.; Bougleux, S. Skeleton-based hand gesture recognition by learning SPD matrices with neural networks. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Konecny, J.; Hagara, M. One-shot-learning gesture recognition using HOG-HOF features. J. Mach. Learn. Res. 2014, 15, 2513–2532. [Google Scholar]
- Danafar, S.; Gheissari, N. Action recognition for surveillance applications using optic flow and SVM. In Proceedings of the 8th Asian Conference on Computer Vision, Tokyo, Japan, 18–22 November 2007; pp. 457–466. [Google Scholar]
- Wan, J.; Guo, G.; Li, S. Explore efficient local features from RGB-D data for one-shot learning gesture recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1626–1639. [Google Scholar] [CrossRef]
- Kane, L.; Khanna, P. Depth matrix and adaptive Bayes classifier based dynamic hand gesture recognition. Pattern Recognit. Lett. 2019, 120, 24–30. [Google Scholar] [CrossRef]
- Park, H.; Kim, E.; Jang, S.; Park, S.; Park, M.; Kim, H. HMM-based gesture recognition for robot control. In Proceedings of the Second Iberian Conference on Pattern Recognition and Image Analysis, Estoril, Portugal, 7–9 June 2005; pp. 607–614. [Google Scholar]
- Ma, L.; Zhang, J.; Wang, J. Modified CRF algorithm for dynamic hand gesture recognition. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 July 2014; pp. 4763–4767. [Google Scholar]
- Zhang, E.; Zhang, Y.; Duan, J. Color inverse halftoning method with the correlation of multi-color components based on extreme learning machine. Appl. Sci. 2019, 9, 841. [Google Scholar] [CrossRef]
- Song, J.; Kim, W.; Park, K. Finger-vein recognition based on deep DenseNet using composite image. IEEE Access 2019, 7, 66845–66863. [Google Scholar] [CrossRef]
- Kang, X.; Zhang, E. A universal defect detection approach for various types of fabrics based on the Elo-rating algorithm of the integral image. Text. Res. J. 2019, 89, 4766–4793. [Google Scholar] [CrossRef]
- Wang, H.; Shen, Y.; Wang, S.; Xiao, T.; Deng, L.; Wang, X.; Zhao, X. Ensemble of 3D densely connected convolutional network for diagnosis of mild cognitive impairment and alzheimer’s disease. Neurocomputing 2019, 333, 145–156. [Google Scholar] [CrossRef]
- Chung, H.; Chung, Y.; Tsai, W. An efficient hand gesture recognition system based on deep CNN. In Proceedings of the IEEE International Conference on Industrial Technology, Melbourne, VIC, Australia, 13–15 February 2019; pp. 853–858. [Google Scholar]
- Cheng, W.; Sun, Y.; Li, G.; Jiang, G.; Liu, H. Jointly network: A network based on CNN and RBM for gesture recognition. Neural Comput. Appl. 2019, 31, 309–323. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J. Dynamic hand gesture recognition based on 3D convolutional neural network Models. In Proceedings of the 2019 IEEE 16th International Conferences on Networking, Sensing and Control, Banff, AB, Canada, 9–11 May 2019; pp. 224–229. [Google Scholar]
- Li, Y.; Miao, Q.; Tian, K.; Fan, Y.; Xu, X.; Ma, Z.; Song, L. Large-scale gesture recognition with a fusion of RGB-D data based on optical flow and the C3D model. Pattern Recognit. Lett. 2019, 119, 187–194. [Google Scholar] [CrossRef]
- Elboushaki, A.; Hannane, R.; Afdel, K.; Koutti, L. MultiD-CNN: A multi-dimensional feature learning approach based on deep convolutional networks for gesture recognition in RGB-D image sequences. Expert Syst. Appl. 2020, 139, 112829. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 2015 International Conference on Learning Representations(ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M. Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2368–2377. [Google Scholar] [CrossRef]
- Abidi, B.R.; Zheng, Y.; Gribok, A.V.; Abidi, M.A. Improving weapon detection in single energy x-ray images through pseudo coloring. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2006, 36, 784–796. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP 2015), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Molchanov, P.; Gupta, S.; Kim, K.; Kautz, J. Hand gesture recognition with 3D convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2015), Boston, MA, USA, 7–12 June 2015; pp. 1–7. [Google Scholar]
- Wang, T.; Chen, Y.; Zhang, M.; Chen, J.; Snoussi, H. Internal transfer learning for improving performance in human action recognition for small datasets. IEEE Access 2017, 5, 17627–17633. [Google Scholar] [CrossRef]
- Li, J.; Yang, M.; Liu, Y.; Wang, Y.; Zheng, Q.; Wang, D. Dynamic hand gesture recognition using multi-direction 3D convolutional neural networks. Eng. Lett. 2019, 27, 490–500. [Google Scholar]
- Jiang, S.; Chen, Y. Hand gesture recognition by using 3DCNN and LSTM with adam optimizer. Lect. Notes Comput. Sci. 2018, 10735, 743–753. [Google Scholar]
- Wu, X.; Zhang, J.; Xu, X. Hand gesture recognition algorithm based on faster R-CNN. J. Comput. Aided Des. Comput. Graph. 2018, 30, 468–476. [Google Scholar] [CrossRef]
- Bulbul, M.; Jiang, Y.; Ma, J. DMMs based multiple features fusion for human action recognition. Int. J. Multimed. Data Eng. Manag. 2015, 6, 23–39. [Google Scholar] [CrossRef]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.-P.; Guerry, J.; Le Saux, B.; Filliat, D. SHREC’17 track: 3D hand gesture recognition using a depth and skeletal dataset. In Proceedings of the 10th Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017; pp. 33–38. [Google Scholar]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.-P. Skeleton-based dynamic hand gesture recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1206–1214. [Google Scholar]
- Ohe-Bar, E.; Trivedi, M. Joint angles similarities and HOG2 for action recognition. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 465–470. [Google Scholar]
- Oreifej, O.; Liu, Z. HON4D: Histogram of oriented 4D normal for activity recognition from depth sequences. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3-D human action recognition by shape analysis of motion trajectories on riemannian manifold. IEEE Trans. Cybern. 2015, 45, 1340–1352. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure of Network | Input (D × H × W) | D20-3D-DenseNet Model = 12) | D40-3D-DenseNet Model | Output |
|---|---|---|---|---|
| 3D Convolution Layer | 16 × 112 × 112 | (stride: 1 × 2 × 2) | 16 × 56 × 56 | |
| 3D Pooling | 16 × 28 × 28 | (stride: 1 × 2 × 2) | 16 × 28 × 28 | |
| Dense Block 1 | 16 × 28 × 28 | 6 | 16 × 28 × 28 | |
| Transition Layer 1 | 16 × 28 × 28 | 16 × 28 × 28 | ||
| 16 × 28 × 28 | 8 × 14 × 14 | |||
| Dense Block 2 | 8 × 14 × 14 | 8 × 14 × 14 | ||
| Transition Layer 2 | 8 × 14 × 14 | 8 × 14 × 14 | ||
| 8 × 14 × 14 | 4 × 7 × 7 | |||
| Dense Block 3 | 4 × 7 × 7 | 4 × 7 × 7 | ||
| Classification Layer | 4 × 7 × 7 | 1 × 1 × 1 | ||
| Full Connection Layer with N nodes | ||||
| Softmax Classifier | ||||
| Cases | Without Data Augmentation and Pseudo-Coloring | Only Data Augmentation | With Data Augmentation and Pseudo-Coloring |
|---|---|---|---|
| Accuracy (%) | 72.00 | 75.21 | 82.23 |
| Methods | Description | Accuracy (%) |
|---|---|---|
| Reference [24] | 64.5 | |
| Reference [27] | 3D CNN (LRN) | 74.0 |
| 3D CNN (LRN + HRN) | 77.5 | |
| Reference [28] | C3D | 81.0 |
| ITL-C3D | 84.3 | |
| ITL-pC3D | 96.1 | |
| Reference [29] | md3D CNN | 63.4 |
| Reference [30] | 3D CNN | 82.0 |
| LSTM + 3DCNN | 94.5% | |
| Reference [31] | Faster R-CNN | 84.7 |
| Proposed method | 2D motion Representation CNN | 79.1 |
| D40-3D-DenseNet | 87.4 | |
| Fusion at feature level | 87.8 | |
| Fusion at decision level | 89.1 |
| Methods | Data Modality | Accuracy (%) |
|---|---|---|
| Reference [26] | RGB + Depth | 79.1 |
| Reference [32] | RGB + Depth | 88.4 |
| 2D motion representation CNN Model | RGB | 81.6 |
| D40-3D-DenseNet model | RGB | 86.4 |
| Fusion at feature level | RGB | 87.7 |
| Fusion at decision level | RGB | 89.5 |
| Methods | Guerry et al. [33] | De Smedt et al. [34] | Ohn-Bar et al. [35] | Oreifej et al. [36] | Devanne et al. [37] | Maghoumi et al. [3] | Proposed Method |
|---|---|---|---|---|---|---|---|
| 14 gestures (%) | 82.90 | 88.24 | 83.85 | 78.53 | 79.61 | 94.50 | 81.70 |
| 28 gestures (%) | 71.90 | 81.90 | 76.53 | 74.03 | 62.00 | 91.40 | 74.41 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, E.; Xue, B.; Cao, F.; Duan, J.; Lin, G.; Lei, Y. Fusion of 2D CNN and 3D DenseNet for Dynamic Gesture Recognition. Electronics 2019, 8, 1511. https://doi.org/10.3390/electronics8121511
Zhang E, Xue B, Cao F, Duan J, Lin G, Lei Y. Fusion of 2D CNN and 3D DenseNet for Dynamic Gesture Recognition. Electronics. 2019; 8(12):1511. https://doi.org/10.3390/electronics8121511
Chicago/Turabian StyleZhang, Erhu, Botao Xue, Fangzhou Cao, Jinghong Duan, Guangfeng Lin, and Yifei Lei. 2019. "Fusion of 2D CNN and 3D DenseNet for Dynamic Gesture Recognition" Electronics 8, no. 12: 1511. https://doi.org/10.3390/electronics8121511
APA StyleZhang, E., Xue, B., Cao, F., Duan, J., Lin, G., & Lei, Y. (2019). Fusion of 2D CNN and 3D DenseNet for Dynamic Gesture Recognition. Electronics, 8(12), 1511. https://doi.org/10.3390/electronics8121511