1. Introduction
The evolution of social networks in the last few decades has aroused the interest of scientists from different and diverse areas, from psychology to computer sciences. Millions of people constantly share all their personal and professional information in several social networks [
1]. Furthermore, social networks have become one of the most used information sources, mainly due to their ability to provide the user with real-time content. Social networks are not only a new way of communication, but also a powerful tool that can be used to gather information related to relevant questions. For instance, which is the favourite political party for the next elections?, what are the most commented on movies in the last year?, which is the best rated restaurant in a certain area?, etc.
Extracting relevant information from social networks is a matter of interest mainly due to the huge amount of potential data available. However, traditional network analysis techniques are becoming obsolete because of the exponential growth of the social networks, in terms of the number of active users.
The analysis of social networks has become one of the most popular and challenging tasks in data science [
2]. One of the most tackled problems in social networks is the analysis of the relevance of the users in a given social network [
3]. The relevance of a user is commonly related to the number of followers or friends that the user has in a certain social network. However, this concept can be extended since a user may be relevant not only if he/she is connected with a large number of users, but also with users that are relevant too. Several metrics have been proposed for analyzing the relevance of a user in a social network, with PageRank emerging as one of the most used [
4]. Furthermore, it is interesting to know in advance which users will be the most relevant ones before they become influential [
5]. Finally, in the field of marketing analysis, there is special interest in generating the profile of a user given a set of tweets written by that user [
6].
Evaluating the relevance of a user has evolved into a more complex problem that consists of detecting specific users (often named influencers) with certain personal attributes that can be personal (credibility or enthusiasm) or related to their social networks (connectivity or centrality). These attributes allow them to influence a large number of users either directly or indirectly [
7].
Another important problem regarding the influence of people in other users is the analysis of sentiments in social networks. It is focused on finding out what people think about a certain topic by analyzing the information they post in social networks. We refer the reader to [
8] to find a complete survey on sentiment analysis techniques.
The previously described problems deal with only individual users. Nevertheless, some problems also exist related to the structure of the network, devoted to finding specific attributes and properties that can help to infer additional information of the whole social network. In this context, community detection emerges as one of the most studied problems.
Most of the social networks present a common feature named community structure [
9]. Networks with this property have the capacity to be divided into groups in such a way that the connections among users in the same group are dense, while connections among users in different groups are sparse. Connections among users can represent different features depending on the social network and the user profile, i.e., from professional relationships to friendships or hobbies in common. Community detection tasks are devoted to finding and analyzing these groups in order to better understand and visualize the structure of network and the relationships among their users.
Performing community detection algorithms over current social networks requires a huge computational effort mainly due to their continuous growth. Furthermore, since these networks are constantly changing (new friendships, mentions to users, viral information, etc.), it is interesting to perform the community detection in the shortest possible computing time, producing real-time information. These features make traditional exact methods not suitable for the current size of social networks, requiring heuristic algorithms in order to accelerate the process without losing quality. Recent works have tackled the community detection problem from a non-exact perspective in order to generate high quality solutions in short computing time [
10]. Several studies are devoted to reducing the computational effort for detecting communities in social networks [
11,
12]. When comparing traditional algorithms over modern large social networks, it can be seen that some of the algorithms require more than 40,000 s for networks with approximately 10,000 nodes, and they are not able to provide a solution after 24 h computing for networks with more than 50,000 nodes.
The growth of social networks complicates their representation and understanding. The communities of a social network usually summarize the whole network but reduce its size and, therefore, makes it easier to analyze. In addition, detecting communities in social networks has several practical applications. Recommendation systems leverage the data of similar users in order to suggest content that can be interesting for them. In order to find similar users in a network, we can simply perform a community detection over the network [
13], improving the results of the recommendation system. Communities in social networks also identify people with similar interests, allowing us to evaluate the popularity of a political party [
14], or even to detect radicalism in social networks [
15].
Although several community detection algorithms exist that have been proposed with the aim of identifying similar users in networks, most of the available algorithms have been designed for optimizing a specific objective function, it being hard to be adapted to a different one (see
Section 3 for a detailed description of the considered algorithms). However, the continuous evolution of this area results in a continuous proposal of new metrics that better evaluates the community structure of a given network. This work presents an efficient and versatile algorithm that can be easily adapted to different optimization metrics. To the best of our knowledge, this is the first algorithm based on classical metaheuristics for detecting communities in social networks. The success of this proposal opens a new research line for modeling social network problems as optimization problems, with the aim of applying metaheuristics for solving them.
The main contributions of this work are itemized as follows:
A new solution representation for the community detection problem is presented.
A new constructive procedure for generating partitions based on the Greedy Randomized Adaptive Search Procedure (GRASP) is introduced.
The local search proposed is able to handle not only the change of community of certain nodes, but also the creation and elimination of communities, increasing the portion of search space explored.
A classical metaheuristic algorithm, GRASP, is adapted to be competitive in social network analysis.
The proposed algorithm is highly scalable, being easily adapted to be executed in distributed systems.
A thorough comparison with the most used methods in community detection is provided, analyzing the advantages and disadvantages of each one of them.
A comparison between two of the most extended metrics is presented, one of them for optimization and the other for evaluation. Furthermore, the evaluation of the metric used for optimization is also performed, with the aim of testing its suitability for the networks considered.
The remainder of the paper is structured as follows:
Section 2 formally defines the problem considered as well as the metrics proposed for the evaluation of solutions;
Section 3 presents a thorough description of the classical algorithms proposed for detecting communities in social networks;
Section 4 presents the new procedure proposed for detecting communities;
Section 5 introduces the computational experiments performed to test the quality of the proposal; and finally
Section 6 draws some conclusions on the research.
2. Problem Statement
A social network is represented as a graph , where the set of vertices V, with , represents the users of the network and the set of edges E, with , represents relations between users belonging to the network. An edge , with can represent different types of relations depending on the social network under consideration. For example, on Twitter, a relation represents that a user follows/is followed by another user, or if there has been some interaction (comment, like, share, etc.) between users, while, on LinkedIn, it represents a professional relationship.
This work is focused on the Community Detection Problem (CDP), which involves grouping users of a social network into communities. A desirable community in a social network is densely connected to the nodes in the same community and sparsely connected (or even unconnected) to nodes in other communities. Therefore, the main objective is to obtain groups or communities of users that are similar and, at the same time, different to the users in other communities with respect to a certain criterion.
A solution for the CDP is represented by a set of decision variables S, with , where indicates that vertex v is assigned to community j in solution S. Therefore, the community for each vertex is represented by the corresponding decision variable . It is worth mentioning that the number of communities is not predefined in advance. Therefore, a solution where all users are assigned to the same community is feasible. Similarly, a solution where each user is assigned to a different community is also valid.
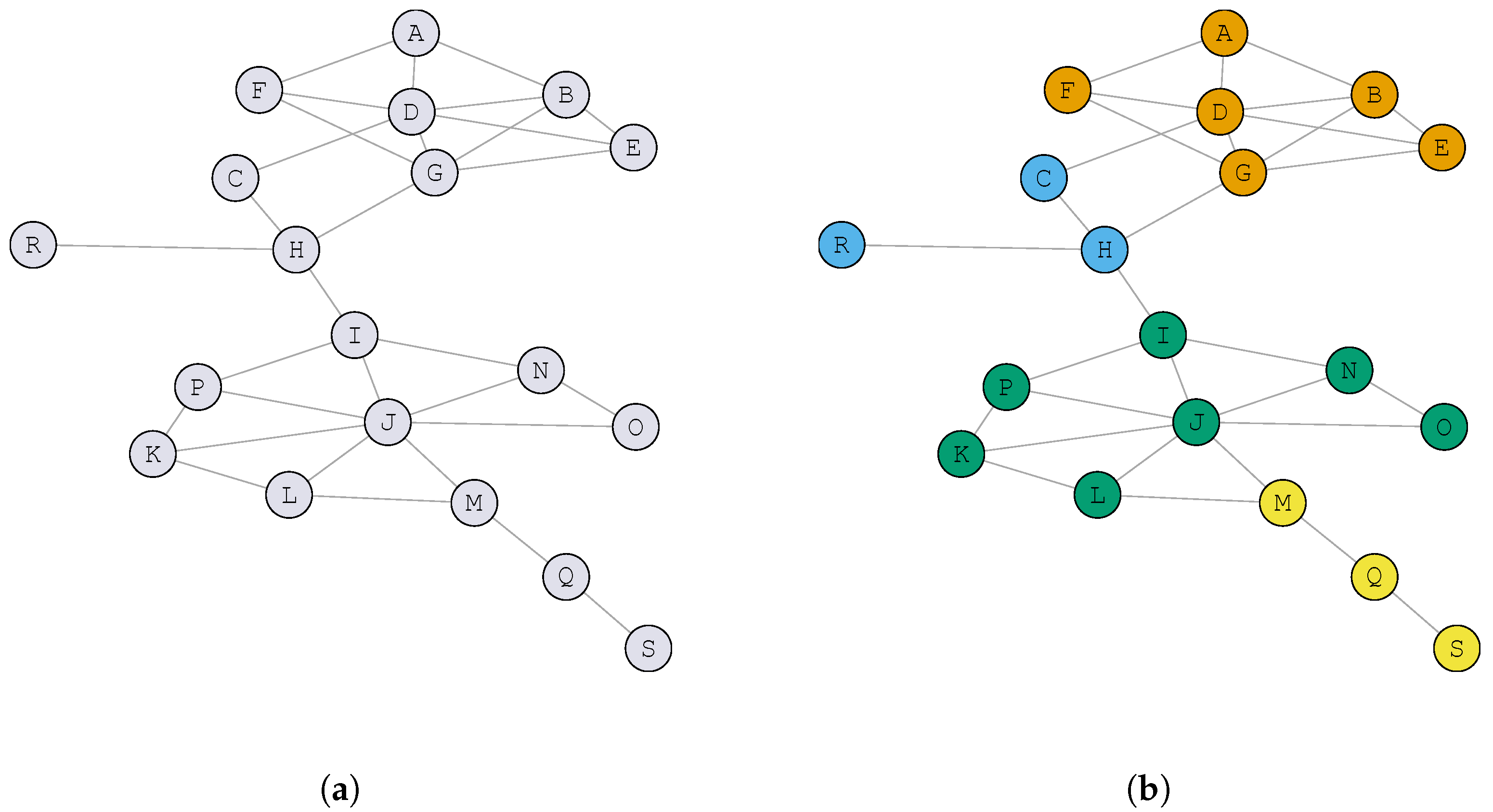
Figure 1a shows an example graph with 19 vertices and 31 edges derived from a social network. In this example, an edge represents a friendship relationship between two users; for instance, users
A and
B are friends, while users
A and
C are not friends, but they have a friend in common, which is vertex
D.
Figure 1b shows a possible solution
S for the community detection problem, where each community is represented with a different color. Notice that, in this example, the number of communities is 4. For the sake of completeness, we report in
Table 1 the community to which each vertex has been assigned. For example, vertex
A belongs to community 1 (
), vertex
C to community 2 (
), and so on).
The CDP then consists in finding a solution
that maximizes a certain objective function value, denoted as
f. In mathematical terms,
where
is the set of all possible solutions for a given social network.
There exists a large variety of quality metrics that can be used as objective functions for finding high quality solutions. Most of the metrics are focused on maximizing the density of intra-community edges (those connecting vertices of the same community) while minimizing inter-community edges (those connecting vertices in different communities).
Notice that the metric considered for optimization is not required from the ground truth since we are dealing with an unsupervised clustering problem [
16]. However, some metrics used for evaluating the quality of an algorithm assume that the optimal partition (ground truth) is known beforehand, considering that an algorithm is better if it minimizes the distance from the generated partition to the optimal one. One example of such a metric is the Omega-Index (see [
10] for further details). In this work, we consider an alternative approach where the optimal partition is not known.
In this research, we evaluate two metrics that have traditionally been used for optimizing the quality of a solution for the CDP: conductance and modularity [
17]. The conductance metric is normalized in the range 0–1, while modularity can take on negative values, ranging from −1/2 to 1. For both metrics, the largest value indicates the value of the optimal partition, while random assignment of users to communities is expected to produce values close to the smallest value. Notice that, in some cases, it is not possible to reach the optimal score due to the internal structure of the network.
The first metric considered in this paper is known as conductance [
18]. Given a network
G, a solution
, and a specific community
k, its conductance,
, is defined as the number of edges that connect vertices of different communities divided by the minimum between the number of edges with, at least, an endpoint in the community and the number of edges without an endpoint in the community. More formally,
Then, the conductance of a complete solution
is evaluated as the average conductance for all the communities in the graph. In mathematical terms,
where
is the number of communities in the incumbent solution
S, i.e.,
.
Let us illustrate the computation of this metric with the example depicted in
Figure 1b. The conductance of community 2 is evaluated as follows:
Similarly, the conductance of the remaining communities (1, 3, and 4) are , , and , respectively. Therefore, .
In order to have a direct comparison with other metrics, it is usually reported the opposite of the conductance evaluated as . In the aforementioned example, this value is then . Then, the objective is to maximize this value to produce high quality solutions.
The second metric is the modularity [
19] that evaluates, for each edge connecting vertices in the same community, the probability of the existence of that edge in a random graph. The modularity of a community
k over a solution
S for a network
G is defined as follows:
where
is the number of communities in the solution,
is the percentage of intra-community edges (with respect to the whole set of edges) in the community
k, and
is the percentage of edges with at least one endpoint in
k. Then, the modularity of the complete solution
S is formally defined as:
Let us illustrate how we can compute this metric for the example depicted in
Figure 1b. Specifically, the modularity of community 2 is evaluated as:
Similarly, the modularity of the remaining communities (1, 3, and 4) are
,
, and
, respectively. Then, the modularity of the complete solution depicted in
Figure 1b is
.
The main disadvantage of modularity metric is its resolution metric. As stated in [
20], optimizing modularity may lead the algorithm to miss substructures of the network, thus ignoring the detection of some sub-communities. This behavior does not depend on a particular network structure, but on the ratio between intra-community relations versus the total number of relations in the network.
The majority of the traditional algorithms for community detection considers this metric as the one to be optimized in order to find high-quality partitions in communities, since it does not fall in trivial solutions (i.e., those with a single community for all the network, or those with a different community for each node of the network), being a robust metric to be considered for optimization.
4. Greedy Randomized Adaptive Search Procedure
Metaheuristics comprehend a set of approximate algorithms designed for solving hard combinatorial optimization problems for which traditional heuristic methods are not effective. These algorithms provide a general framework for creating new hybrid algorithms with concepts derived from artificial intelligence, biological evolution and statistical mechanisms [
27].
Greedy Randomized Adaptive Search Procedure (GRASP) is a metaheuristic originally presented in [
28] and formally defined in [
29]. We refer the reader to [
30] for a recent survey on this methodology. This metaheuristic can be divided into two main phases: solution construction and local improvement.
The first phase iteratively adds elements to an initially empty solution until it becomes feasible. The first element is usually selected at random, acting as a seed for the procedure. The algorithm then constructs a candidate list (CL) with all the elements that must be included in the solution. After that, a Restricted Candidate List (RCL) is created with the most promising elements of the CL according to a predefined greedy function. Then, in each iteration, an element is selected at random from the RCL and added to the solution under construction, updating the CL and RCL in each step until reaching a feasible solution.
The construction phase of the GRASP algorithm presents a random part devoted to increasing the diversity of the solutions generated. In particular, in the previous description, the random part relies on the random selection of the next element from the
RCL. Therefore, most of the obtained solutions are not local optimum and can be improved by means of a local optimizer. The second phase of the GRASP algorithm is intended to find a local optimum of the solution generated, usually applying a local search method, although it can be replaced with a more complex optimizer, like Tabu Search or Variable Neighborhood Search, for instance [
31,
32,
33].
The algorithm presented in this section is able to optimize any of the metrics defined in
Section 1. However, heavily optimizing conductance usually leads to the trivial partition where all the vertices are in the same community. Therefore, the proposed algorithm is focused on optimizing the modularity, which has been traditionally considered as a good optimization metric.
Analyzing the related literature, most of the algorithms are designed for optimizing a specific objective function value. However, the versatility of the proposed algorithm allows it to be easily adapted to optimize either a new or a traditional metric, which converts it into a generic algorithm for finding community structures for any optimization metric.
Furthermore, the algorithm is proposed as a framework for detecting communities. It is easy to replace the constructive method or local search procedure proposed with a different one, or even embed a more complex local optimizer, such as Tabu Search [
34], or Variable Neighborhood Search [
35], among others.
4.1. Constructive Procedure
The constructive procedure designed for the community detection problem, named GRASPAGG follows an agglomerative approach, where each element is initially located in a different community. Then, GRASPAGG iteratively joins two of the most promising communities with the objective of maximizing the modularity. Algorithm 1 shows the pseudocode of the GRASPAGG constructive method.
| Algorithm 1. |
- 1:
- 2:
- 3:
whiledo - 4:
- 5:
- 6:
- 7:
- 8:
- 9:
- 10:
- 11:
if then - 12:
- 13:
- 14:
else - 15:
- 16:
end if - 17:
end while - 18:
returnS
|
The method starts by assigning a different community to each node in the graph G (step 1), creating the CL with every community in the solution S under construction (step 2). In other words, at the beginning of the construction, there will be n nodes assigned to n different communities. Then, the minimum () and maximum () values for the greedy function under evaluation are calculated (steps 4 and 5). We propose as a greedy function the modularity value of each community j. A threshold is evaluated (step 6) to construct the RCL with the most promising candidates in CL (step 7). The next steps select the two communities that will be joined in the current iteration. The first one, , is selected at random from the RCL (step 8). The second community is the one that maximizes the modularity of the resulting solution after joining communities and (step 9). If the method has found an improvement in the modularity after joining both communities, a new iteration is performed, updating the incumbent solution (step 12) and the candidate list (step 13); otherwise, the community is removed from the candidate list since any join involving produces a worse solution. Finally, GRASPAGG stops when it is not possible to join two communities improving the modularity, returning the best solution found.
4.2. Local Optimization
This section presents a local search procedure designed to find a local optimum for every solution constructed in the previous phase. In order to define a local search method, we firstly need to define the neighborhood in which the local optimum will be found. For this problem, we consider all the solutions that can be reached from a given solution
S by removing one node from its current community and inserting it in a different one. Specifically, after performing the move
, the vertex
v will be located at community
j (i.e.,
).The neighborhood
is defined as:
It is worth mentioning that the number of communities is not a priori defined for the problem. Therefore, if v is the last vertex in the community , then community will disappear after performing the corresponding move. In the same line, the method also considers creating a new community for vertex v if it improves the modularity. Thus, after performing the local search method, the number of communities may have varied either increasing or decreasing.
The next step for defining the local search method is the selection of the vertex to be moved to another community. For this purpose, we define a heuristic criteria based on the number of intra-community edges of the vertex under evaluation with respect to the total number of edges in the graph. Specifically, the local search method selects the vertex
v with the smallest ratio
r between number of edges in the same community and the total number of incident edges to
v. More formally,
The local search method traverses all the nodes in the solution following an ascending order with respect to the previously defined criterion. Each node is moved from its current community to the one that maximizes the modularity among all the existing communities in the incumbent solution.
The proposed local search procedure follows a first improvement approach. In particular, given a solution S, this strategy scans its neighborhood in search for the first solution such that . The method stops when no improvement is found after exploring the whole neighborhood.
4.3. Complexity Analysis
The complexity analysis of the proposed algorithm can be split into two different stages: constructive and local improvement. Firstly, the complexity of the constructive procedure is analyzed.
The constructive procedure iterates until the candidate list is empty. One candidate is removed in each iteration, either due to the joining of two communities or because the candidate cannot be joined. Following a straightforward implementation, this method requires traversing all the nodes and all the edges, resulting in a complexity of . However, we cache the degree of each node and its adjacents in efficient data structures when reading the social network (since the degree of a node will not change during the execution). Therefore, we reduce the complexity of generating the candidate list to . The method then iterates until no improvement in the modularity is found when joining two clusters. In the worst case, it requires performing iterations, resulting in a total complexity of . However, we select in each iteration the community with the smallest modularity value, finding improvements in the first iterations. Therefore, the complexity of this stage is , mainly due to the cost of maintaining the communities sorted by modularity. Finally, the complexity of the complete constructive procedure is .
The second stage corresponds to the local search procedure, where each node is considered to be inserted in each community. Therefore, it presents a complexity of
,
k being the number of communities. However, it is worth mentioning that notation
refers to the worst case, and it is possible to optimize the search with the aim of avoiding the worst case. In particular, the local search method evaluates each node
following an ascending order (worst nodes first) with respect to the ratio
defined in
Section 4.2. This ordering is a heuristic that minimizes the number of movements performed before finding an improvement, since it is presumed that nodes with a small ratio value are not located in the best community. Therefore, on average, the algorithm complexity linearly grows with the problem size.
Analyzing the complexity of both stages, the resulting GRASP algorithm presents a global complexity of plus the complexity of the local search, which is linear (in the average case) with respect to the problem size, resulting in a final complexity of per iteration.
5. Computational Results
This section is devoted to analyzing the quality of the proposed algorithm when compared with the most popular community detection algorithms presented in
Section 3. Since most of the algorithms are focused on optimizing the modularity, the evaluation of the quality must be performed over a different metric. In this work, we consider the conductance with the aim of testing the robustness of the methods when including one additional metric. We also consider the modularity value obtained with each algorithm, although it should not be taken into account in the evaluation of the quality of the community detection. However, we consider that it is interesting to analyze how far an algorithm is able to optimize the detection considering the modularity value. The proposed algorithm has been implemented in Java 8 and the experiments have been conducted in an Intel Core 2 Duo E7300 2.66 GHz with 4 GB RAM.
The instances used for the experiment have been extracted from the Twitter SNAP dataset [
36] and from Network repository [
37]. Specifically, we have selected 100 instances with vertices ranging from 50 to 400 that represent the ego-network of several Twitter users (data is anonymized in the dataset, and the ego user is not included in it) and other interactions between users from other networks.
The first experiment is devoted to tuning the parameter of the GRASPAGG procedure. This parameter controls the degree of randomness of the method: on the one hand, = 0 results in a totally random method, while = 1 considers a completely greedy method. Therefore, it is interesting to test values distributed in the range 0–1 to analyze whether the best results for the CDP are obtained with a small or large percentage of randomness/greediness in the construction. In this experiment, we have considered , where RND indicates that a random value of is selected for each construction. This experiment has been conducted over a subset of 20 representative instances in order to avoid overfitting.
Table 3 reports the results obtained with the different values of
. Specifically, two statistics are considered: Avg., the average of the best modularity value obtained for each instance, and #Best, the number of times that an algorithm matches that best solution. Notice that conductance is not included in this preliminary experiment since it is performed for tuning the algorithm, and conductance should be used only for evaluating its quality.
Analyzing the results presented in
Table 3, we can clearly see that
is able to obtain the largest number of best solutions (9 out of 20). However, the quality of the solutions provided when it does not match the best solution is considerably worse than the other
values. If we now analyze the average modularity value and the number of times that the algorithms reach the best solution, we can conclude that a random value for
in each iteration obtains the best results, closely followed by
. Therefore, the final version of the algorithm is configured with
.
Once the best
parameter for the proposed algorithm has been adjusted, it is necessary to compare its performance with the most used community detection algorithms found in the literature. Specifically, we have included in the comparison the algorithms described in
Section 3: Edge Betweenness (EB), Fast-Greedy (FG), Label Propagation (LP), Multi-level (ML), Walktrap(WT), InfoMap (IM) and Louvain (CL).
Table 4 shows the aforementioned comparison.
Firstly, the analysis will be focused on the modularity value. In particular, GRASPAGG is able to obtain a slightly better result than Louvain (0.31331 vs. 0.31181), which is the second best approach. However, regarding the number of best solutions found, we can clearly see the superiority of our proposal, doubling the number of best solutions found with the Louvain method. Then, the next best algorithm is Fast-Greedy, achieving a total of three best solutions found. It is worth mentioning that the remaining algorithms are far from the results with respect to modularity. This can be partially explained since not all the algorithms are focused on optimizing modularity. Therefore, we need to consider an additional metric to have a fair comparison.
The conductance metric should be the one considered for evaluating the performance of each algorithm, since it is an objective metric that has not been used for any of the compared methods. The results show that the trend continues but with more significant differences among methods. Again, the best average conductance value is obtained by GRASPAGG (0.49483), and the second best value is reached with the Louvain method (0.48002). However, the differences between both results are larger, confirming the superiority of our proposal. Additionally, the GRASPAGG method is able to reach 37 out of 100 instances, while Louvain only obtains nine. The third best algorithm is again Fast-Greedy, with a conductance of 0.44062. Notice that, although the conductance of Louvain is better than the one of Fast-Greedy, the latter is able to achieve a larger number of best solutions found (17 vs. 9). The same conclusions can be derived when analyzing Multi-level and Infomap algorithms.
Finally, we have conducted different statistical tests to validate the results reported in
Table 4. In particular, we have performed the Friedman non-parametric statistical test with all the individual values obtained in the previous experiment to confirm whether there exist statistically significant differences among the compared algorithms or not. The Friedman test ranks each algorithm according to the conductance value obtained, giving rank 1 to the best algorithm, 2 to the second one, and so on. The larger the differences in the average, the smaller the
p-value will be. The average ranks values obtained with this test are
GRASPAGG (1.70), CL (2.47), LP (2.73), FG (2.88), ML (3.30), IM (4.12), WT (5.04), and EB (5.74), resulting in a
p-value smaller than 0.00001. Additionally, we have performed the Wilcoxon signed rank test for the best two algorithms (i.e.,
GRASPAGG and CL). The resulting
p-value smaller than 0.00001 confirms that there are statistically significant differences between both algorithms, then supporting the quality of the proposed GRASP method.





{kind=link}
{kind=link}