1. Introduction
Over the last two decades, localization systems have become a subject of great interest due to the need to provide services to users according to their locations. In fact, more and more applications are being developed every day involving user location awareness [
1]. Therefore, precise positioning remains a crucial requirement, which is not properly covered in many localization-based systems, such as applications for monitoring people with disabilities or robotic systems.
Thus, precise indoor localization is still a critical missing component, which has gained an increasing interest in a wide range of location-based applications, such as robotics, tracking disabled people, etc.
In outdoor environments, the Global Positioning System (GPS) is the most popular navigation system based on satellites. However, GPS-driven navigation does not work well where there is no line-of-sight with GPS satellites, as happens in inside buildings [
2,
3]. Furthermore, a 3D localization cannot be determined with GPS; only longitude and latitude information are available. Therefore, systems capable of sensing location in indoor environments have to be designed to provide services that fulfill the aforementioned requirements. In the literature, many indoor localization-based solutions using other signals, such as Wi-Fi [
4], Bluetooth [
5], ZigBee [
6], RFID [
7], or ultrasound [
8], have been proposed. Among all of them, Wi-Fi networks have had great attention paid to them, mainly because of their low cost, mature standardization state, and wide deployment.
On the other hand, indoor localization systems based on fingerprints have become a promising approach thanks to their ability to determine user position by means of received signal patterns, such as a collection of RSS values obtained from different access points, in which case there is no need for additional hardware to gather RSS values [
9]. Most research works based on fingerprinting methods use machine learning algorithms to learn the relationships among positions and RSS values.
Much work has been published about indoor localization using Wi-Fi infrastructure and fingerprinting, with the aim of reducing system complexity and improving accuracy. In [
10], Principal Components (PC) were obtained by processing RSS measurements for the purpose of simplifying and reducing the radio map data handling. Compared to traditional approaches, their method reduced mean error by 33.75%, and complexity was decreased by 40%. The authors in [
11] proposed the use of a method of data analysis based on Kernel Principal Component Analysis (KPCA) to remove radio map data redundancy, combined with an algorithm for classifying and grouping reference points on the basis of the Affinity Propagation Clustering (APC) method. Then, they employed Maximum Likelihood (ML) estimation for positioning, obtaining a location accuracy by a margin of 3 m in up to 94% of the cases, having an improvement of 38% compared to the use of ML-based estimation alone.
In [
12], they employed relative RSS values and a K-Nearest Neighbor (KNN) algorithm based on Spearman distance to enhance the accurateness of localization under conditions of multipath signal attenuation and environmental changes. Their results showed deviations of up to 2.7 m for 80% of the evaluated samples when having a shadow fading factor of 5 dB. In [
13], the authors proposed a technique based on relative neighbor RSS values for radio map building and a Markov chain prediction model for localization. They obtained a stable accuracy in conditions of environmental changes and device heterogeneity, with results of a 1.5-m average error. The authors in [
14] analyzed the effects of beacon nodes’ placement on the obtained results by several clustering methods employed to reduce positioning time. By evaluating the positioning time and the positioning error as performance metrics, they proposed an optimum beacon node layout scheme, which ensured coverage visibility within the location area, thus improving the accuracy in all tested clustering methods.
In [
15], a crowdsourcing localization system was proposed, in which each user could contribute to the construction of the radio map. To mitigate the variation of RSS values due to the use of different devices, a linear regression algorithm combined with a graph-based learning method was applied, to correlate RSS values at nearby locations. According to their results, localization accuracy was improved with an average error of 1.98 m. In [
16], the authors proposed a hybrid system combining Wi-Fi with Bluetooth Low Energy to determine user localization, with coarse and fine accuracy, respectively. They employed the KNN algorithm to determine user positions, with accuracy up to 1.47 m and accuracy up to 1.81 m for 90% of the time.
A major weakness of fingerprinting techniques based on RSS is that accuracy is easily affected by the spatial and temporal variation due to the multipath effect. Thus, Channel State Information (CSI) has recently attracted research efforts in indoor localization because CSI is a fine-grained value from the PHY layer, which describes the amplitude and phase on each subcarrier of the OFDM systems, yielding sub-meter-level accuracy [
17]. For instance, the authors in [
18] used network features obtained from the amplitude and phase information of individual subcarriers and a visibility graph method to determine the location using machine learning algorithms. In [
19], the authors used a deep network with four hidden layers to explore the features of wireless channel data and obtain the optimal weights as fingerprints. Although the average error of CSI-based systems is less than RSS-based systems, the former requires more computation time in the training phase to analyze fine-grained features.
Substantial progress has been accomplished in the development of solutions for localization in indoor environments, with the achievement of highly-precise systems. However, a major drawback of those systems is that they have both high demands on computation time and energy consumption. In many situations, elapsed time to build the system and energy constraints are the most important parameters that restrict the fast deployment of localization-based services where an acceptable accuracy can be allowed, and no high accuracy is required. Temporary environments, such as emergency situations due to natural catastrophes, could be candidates to implement localization systems with these restrictions. In addition, the computational complexity of indoor localization systems must be kept in mind when developing for portable devices, in which restrictions usually apply not only in computation capacity but also in energy consumption.
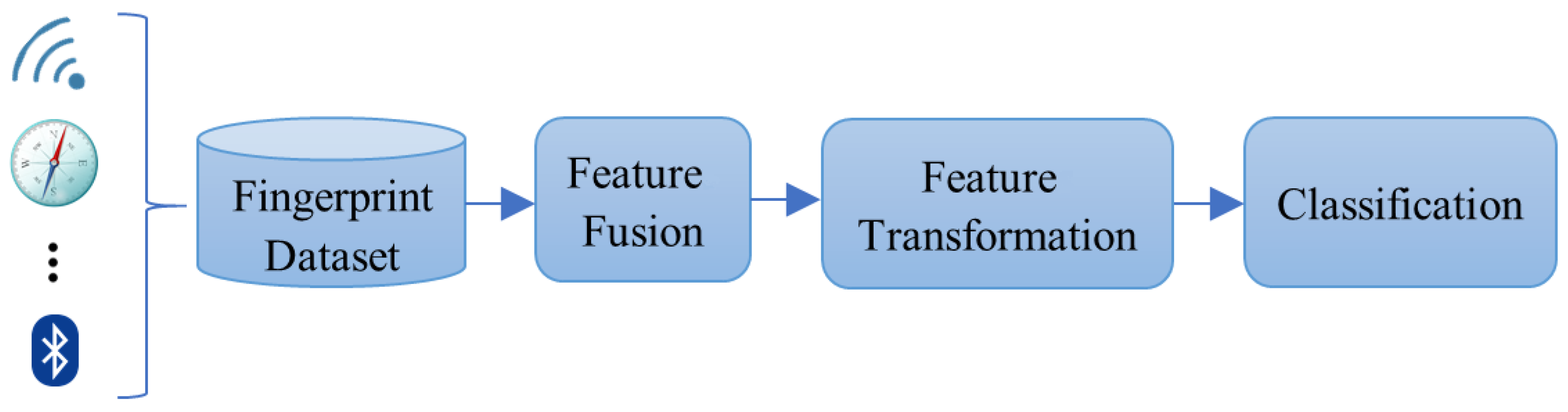
Thus, in this manuscript, a methodology for fast building of an indoor localization system is proposed. Unlike other approaches, few training samples are required to build the dataset, resulting in the system cost of gathering data being cut. This is due to the combination of feature fusion and feature transformation, allowing one to retain valuable information. In addition, both feature fusion and feature transformation are computationally light. Hence, the amount of features can be reduced, with the consequent reduction in the computational load required to estimate the location. Such dimensionality reduction can be a useful technique for processing high-dimensional datasets, such as in high-density Wi-Fi environments, while still retaining as much of the variance in the dataset as possible. Thus, the performance of the classifier can be further enhanced when the discarded information is redundant noise [
10]. Three different datasets were used to validate the proposed methodology. Two of them are public datasets based mainly on RSS from different Wi-Fi access points (from the University of Mannheim and the University of Yuan Ze), and the third is an RSS dataset built using a simulation tool where the direct component and multipath reflections of the optical signal from LED lamps are included.
The paper is organized as follows:
Section 2 describes the phases of the proposed methodology.
Section 3 explains the datasets used for validating the methodology. Next, in
Section 4, the experimental results are discussed, and the performance and robustness of our methodology are analyzed. Finally, in
Section 5, the conclusions are presented.
4. Experimental Results and Discussion
In this section, the performance results of the proposed methodology in the three aforementioned datasets are described and discussed. Experiments were focused on comparing accuracy, error distance, and computation time using several machine learning algorithms based on classification. Furthermore, the robustness of the methodology was evaluated using different training dataset sizes. The accuracy was computed as the number of instances correctly classified divided by the total number of instances used for testing, Equation (
3). The expected distance from the misclassified instance (estimated location) and the real position were used as the error measure in our system. This error was obtained by calculating the Euclidean distance between these points, and the arithmetic mean was computed from the results of the experiments.
In order to validate the experimental results and to ensure statistical independence, all experiments were repeated 100 times, averaging the results, and 10-fold cross-validation was used. The methodology was implemented using the Weka API [
32]. All experiments were carried out on an Intel Core i7 3.4 GHz/32 GB RAM non-dedicated Windows machine.
4.1. Feature Transformation
In order to transform the data fusion into principal components, PCA algorithm was used in conjunction with a Ranker search. Dimensionality reduction was accomplished by choosing enough eigenvectors to account for 95% of the variance in the original data.
Table 2 shows the features transformation. As can be observed, for the Yuan Ze and VLC datasets, the number of features was considerably reduced, and therefore, the number of computations carried out for the classifiers was also greatly reduced. However, most of the features of the Mannheim dataset were considered outstanding, and for that reason, the number of principal components was almost equal to the number of features. This may be due to the fact that all access points have been strategically placed in the environment, and therefore, all of them provide relevant information.
4.2. Setting of Classifiers
In order to find the best setting of each classifier several experiments were carried out varying the key parameter of classifiers with the three datasets. Both fusion and transformation of features were applied to the dataset before being used as input to the classifier.
For the KNN algorithm, experiments were implemented to find the optimal k parameter, varying from k = 1 to k = 5. For the AdaBoost algorithm, confidenceFactor, c, was varied from 0.20 to 0.40 in steps of 0.05. Lastly, for the SVM algorithm, the C-SVC and nu-SVC implementations were used, and three kinds of kernels were used to find the best accuracy: linear, polynomial, and Radial Basis Function (RBF). For both polynomial and RBF kernels, the gamma parameter was varied from –.
Table 3 and
Table 4 show accuracy results obtained with different values of the key parameter for KNN and AdaBoost, respectively.
Table 5 shows the best accuracy for each kernel using SVM as the classifier. The gamma value for the best accuracy is specified in brackets.
As can be observed, for the KNN algorithm, the best results were obtained with k = 1 for all datasets. For the AdaBoost algorithm, a confidenceFactor of 0.25 yielded the best accuracy with the Mannheim and Yuan Ze dataset, and for the VLC dataset, the best accuracy was obtained when the confidenceFactor was set to 0.4. However, regardless of the value of the confidenceFactor, all settings had similar accuracy. Lastly, for the SVM algorithm, the best results were reached using the C-SVC machine and the polynomial kernel for all datasets. Furthermore, this classifier provided the best accuracy results, except for the Mannheim dataset, although they were similar to the results obtained when KNN was used. The rest of the experiments described in this manuscript were implemented using the key parameter value that yielded the best accuracy.
4.3. Evaluation of the Methodology
Table 6 shows the performance results obtained from the proposed methodology taking into account the accuracy, error distance, and the elapsed training time by the classifier to build the model.
Table 7 shows the performance results when the dataset was directly used as input to the classifier, that is without data fusion and transformation of features. As can be seen, with regard to the accuracy and error distance, similar results were yielded in both experiments. Even so, in most of the experiments for the Yuan Ze and VLC datasets, the results obtained using the proposed methodology were slightly worse because of the fact that features transformation removed some useful information. For the Mannheim dataset, principal components removed redundant information, and hence, the proposed methodology improved the accuracy by about 15% using the KNN algorithm.
With regard to the elapsed time to build the model, it can be appreciated that this time was considerably less when the proposed methodology was used. For the Yuan Ze and VLC datasets, the computation time to train the classifier was less. Even so, for VLC dataset, the time reduction was about 50% for all classifiers. This was due to the fact that the number of features was considerably reduced in both datasets when the transformation into principal components was carried out (see
Table 2), and hence, the number of computations was greatly reduced. The same applies to the Yuan Ze dataset. However, for the Mannheim datasets, the number of principal components was almost equal to the number of original features, and therefore, the number of computations was similar. Thus, the elapsed time to build the model was similar in both experiments.
On the other hand, regardless of the dataset, the KNN algorithm was the classifier that yielded the best results, both in accuracy and computation time.
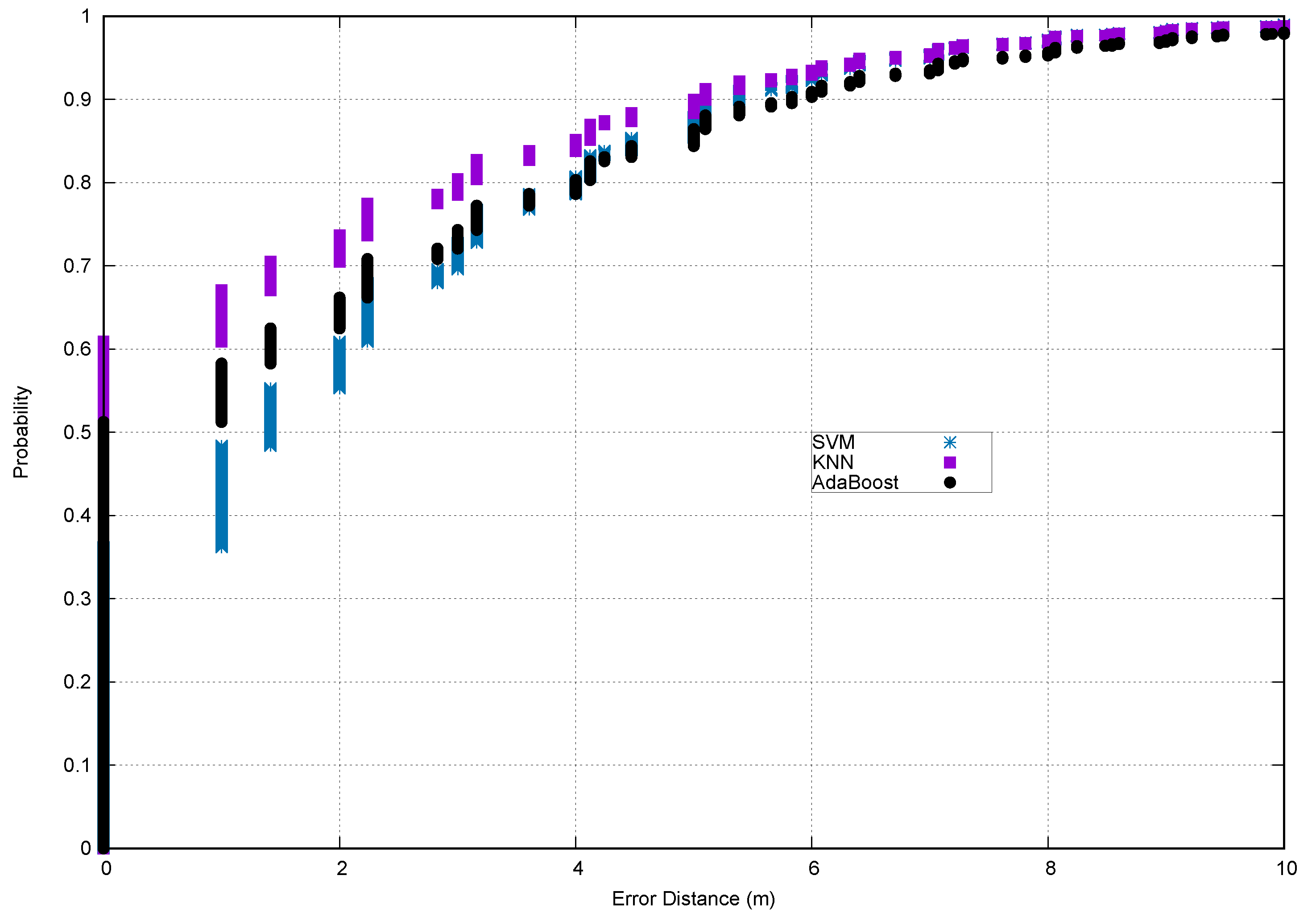
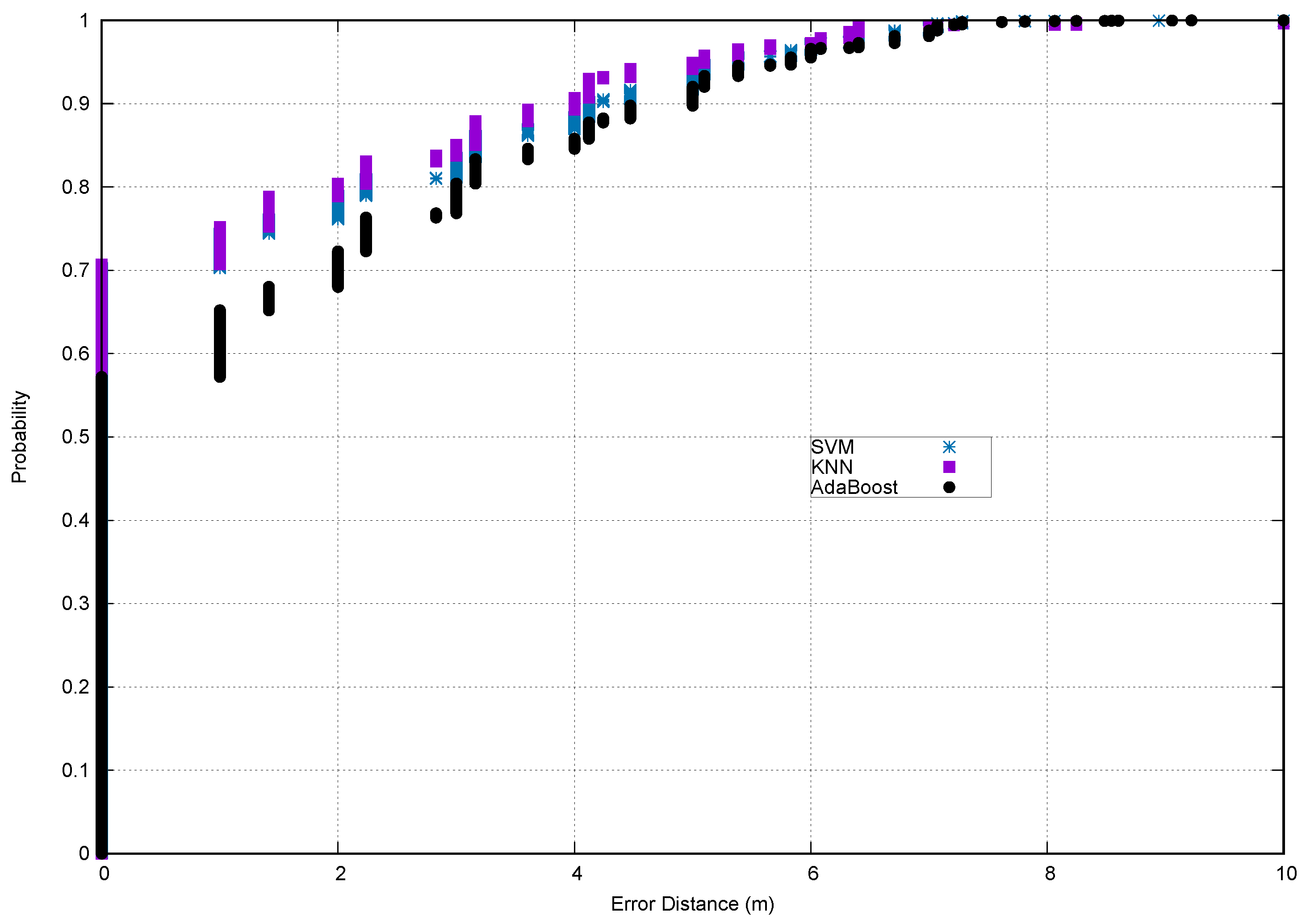
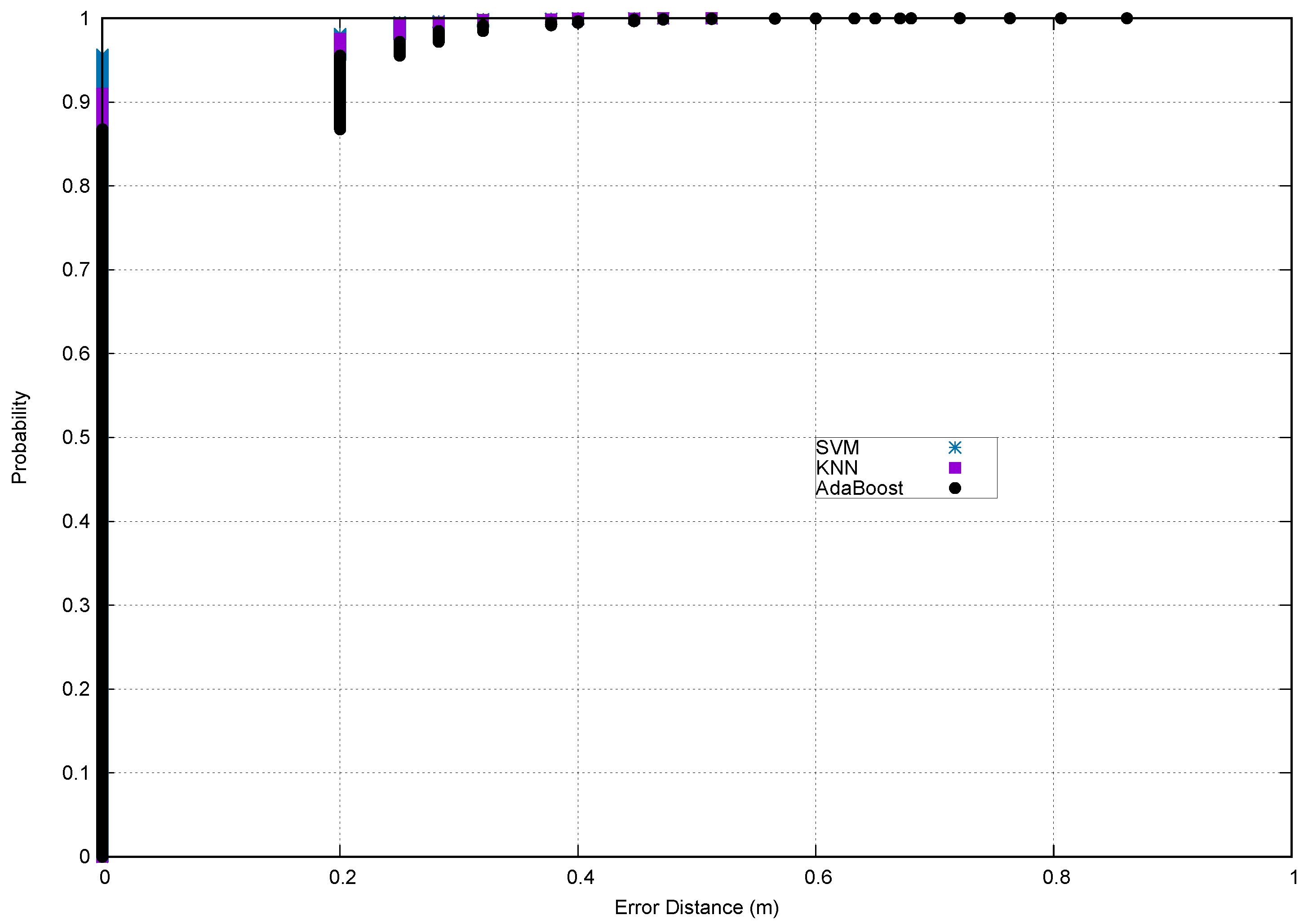
Lastly,
Figure 5,
Figure 6 and
Figure 7 show the Cumulative Distribution Function (CDF) using the proposed methodology. As can be seen, for the Mannheim dataset, the error was about 2 m with a 75% probability using KNN as the classifier, and furthermore, it was about 5 m with a 90% probability using any classifier. Something similar occurred for the Yuan Ze dataset: the error was about 2 m with a 80% probability using KNN as the classifier, and the error was about 4 m with a 90% probability using any classifier. For both datasets, at the 90th percentile and above, the accuracy was comparable in all classifiers. For the VLC dataset, most of the test instances were correctly classified, and most of the misclassified instances were about 20 cm for all classifiers, that is the error was about 20 cm with a 95% probability. Therefore, the experimental results demonstrated that the proposed methodology yielded an acceptable accuracy, with a reduction of computation time.
4.4. Methodology Robustness
In order to validate the robustness of the proposed methodology, the efficiency of this approach was tested by varying the training dataset size from 20–80%. All experiments were performed using the fastest classifier, that is the classifier implemented by the KNN algorithm.
Table 8 shows the experimental results obtained by varying the training size. As can be seen, the system accuracy increased when the training size did, yielding good results with a low number of training samples. Thus, for the Yuan Ze dataset, the accuracy only decreased about 7% when the size of the training dataset was 20% of the total. For the Mannheim and VLC datasets, the methodology can be considered equally robust using 60% of the training samples, with only about a 5% accuracy reduction. For other training sizes, this approach decreased in effectiveness. Furthermore, precision, recall, and F-measure measurements also followed a similar behavior related to the accuracy. Thus, the measurements increased with the training size, keeping the values close to 0.76 when using only a 40% training size for the Yuan Ze and VLC datasets. This shows that the methodology was effective for the fast building of an indoor localization system, for which the reduction in the size of the training set and the reduction of the data dimensionality offered a time savings; although, it may reduce the performance in terms of error distance.
Finally,
Table 9 shows a comparative analysis with other state-of-the-art indoor localization methods. As can be seen, the results obtained in this work were similar to other research works, being able to achieve a low error distance, and our even research outperformed some recent works.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}