Memristive Spiking Neural Networks Trained with Unsupervised STDP


Abstract
1. Introduction
- No leakage currents. Neurons in the proposed MSNN are integrate-and-fire. Their integrated voltages are reset only at the beginning of next processing duration.
- No firing rates and no refractory periods. All neurons can generate at most one spike during a processing duration, and the spike is reduced to step signals for simplicity (this constraint reduces the complexity of CMOS neurons).
- No lateral inhibition. The proposed MSNN is purely feedforward and has no lateral inhibitory neurons (the architecture complexity is undoubtedly reduced when no inhibitory neuron is required).
- No adaptive threshold voltages. All neurons of the proposed MSNN have the same fixed threshold voltage for classification (the complexity of supplying a fixed threshold voltage is evidently lower than supplying various threshold voltages).
- We propose a hardware-friendly MSNN architecture, which decreases the hardware complexity by adding several constraints.
- We present an unsupervised STDP learning method for the architecture.
- The architecture with the learning method is validated by the MNIST dataset and achieves a classification accuracy that outperforms other time-based unsupervised SNNs.
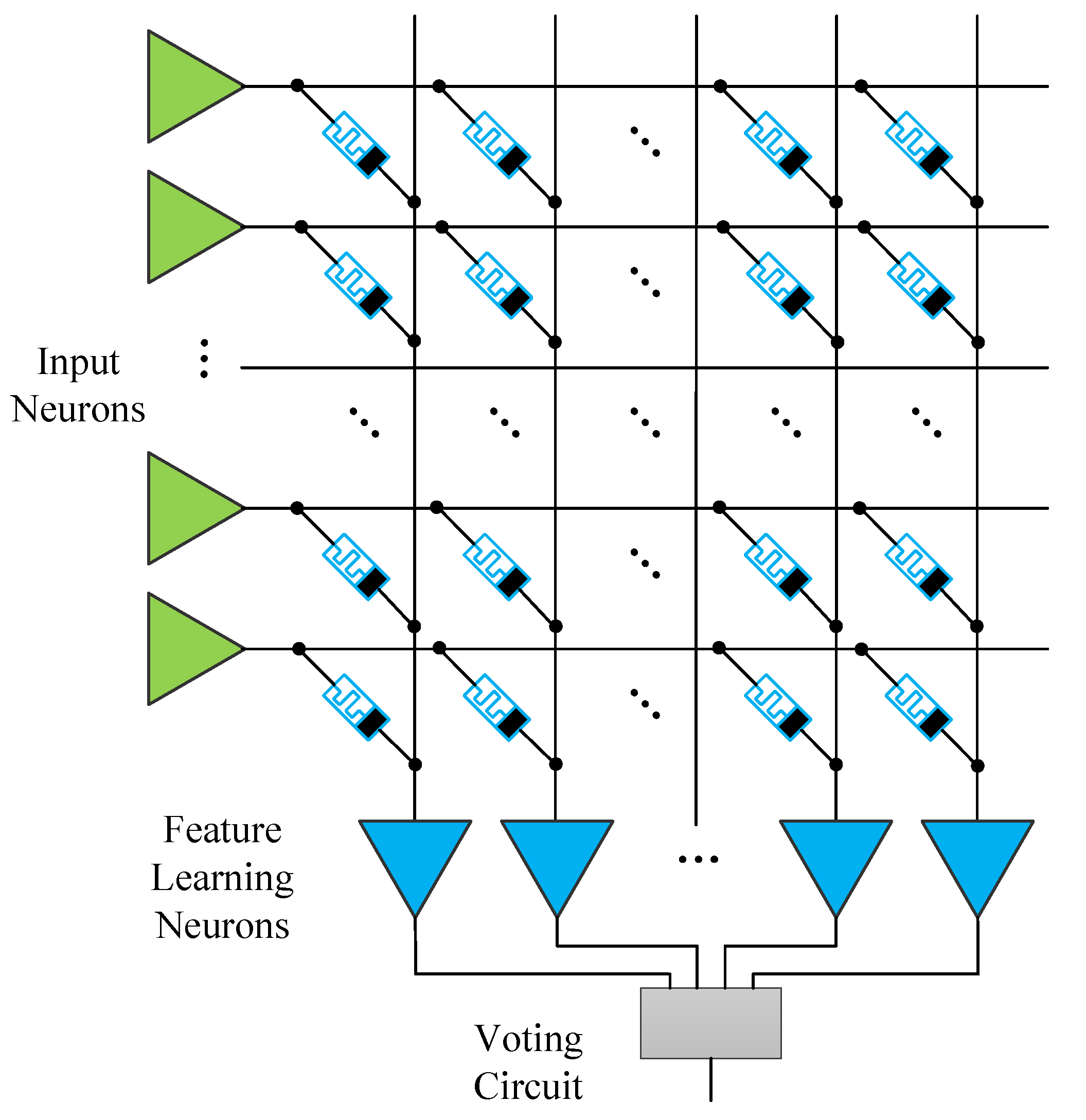
2. Architecture
2.1. Input Layer
2.2. Synapse
2.3. Feature Learning Layer
2.4. Voting Circuit
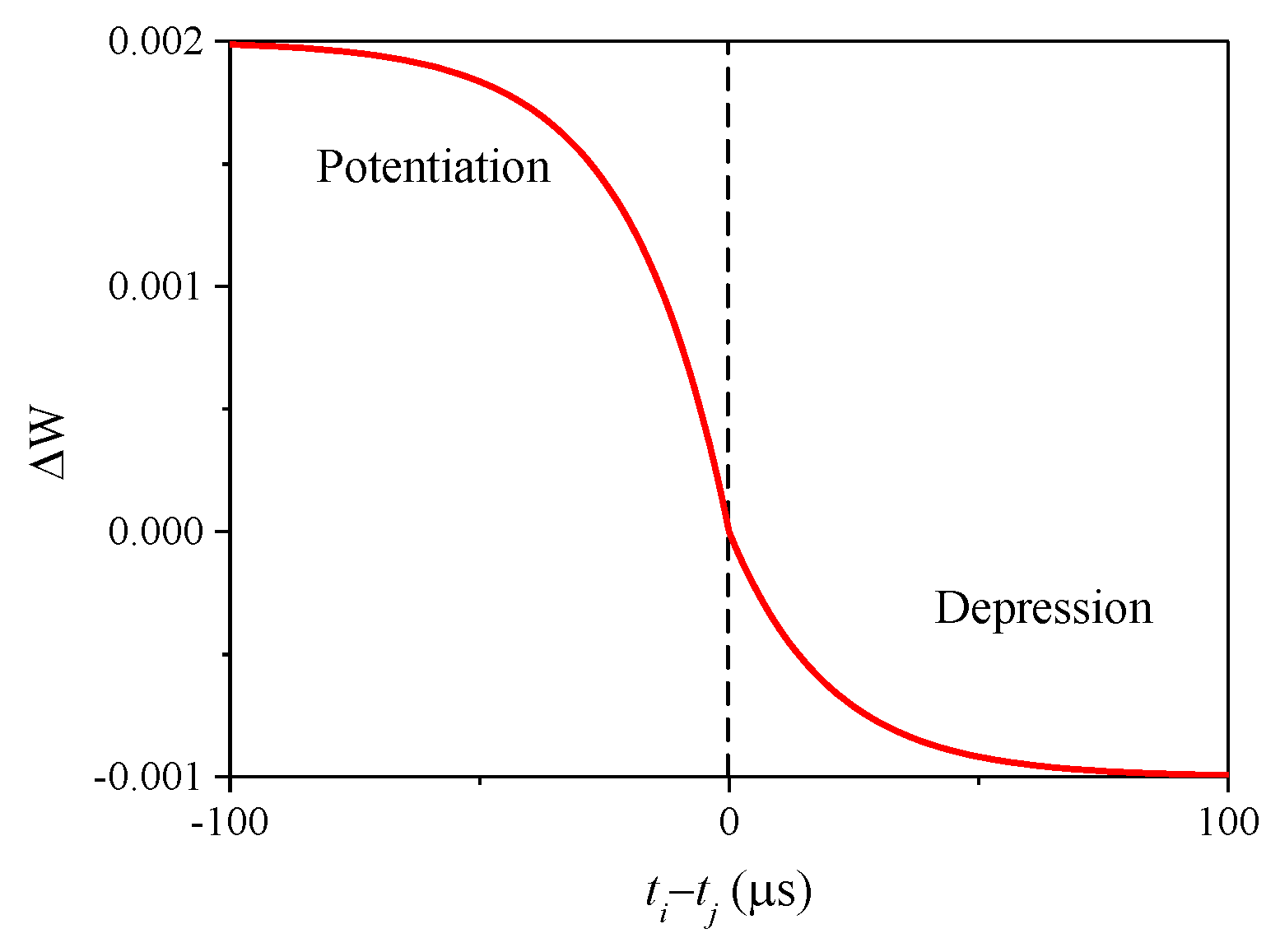
3. Learning Method
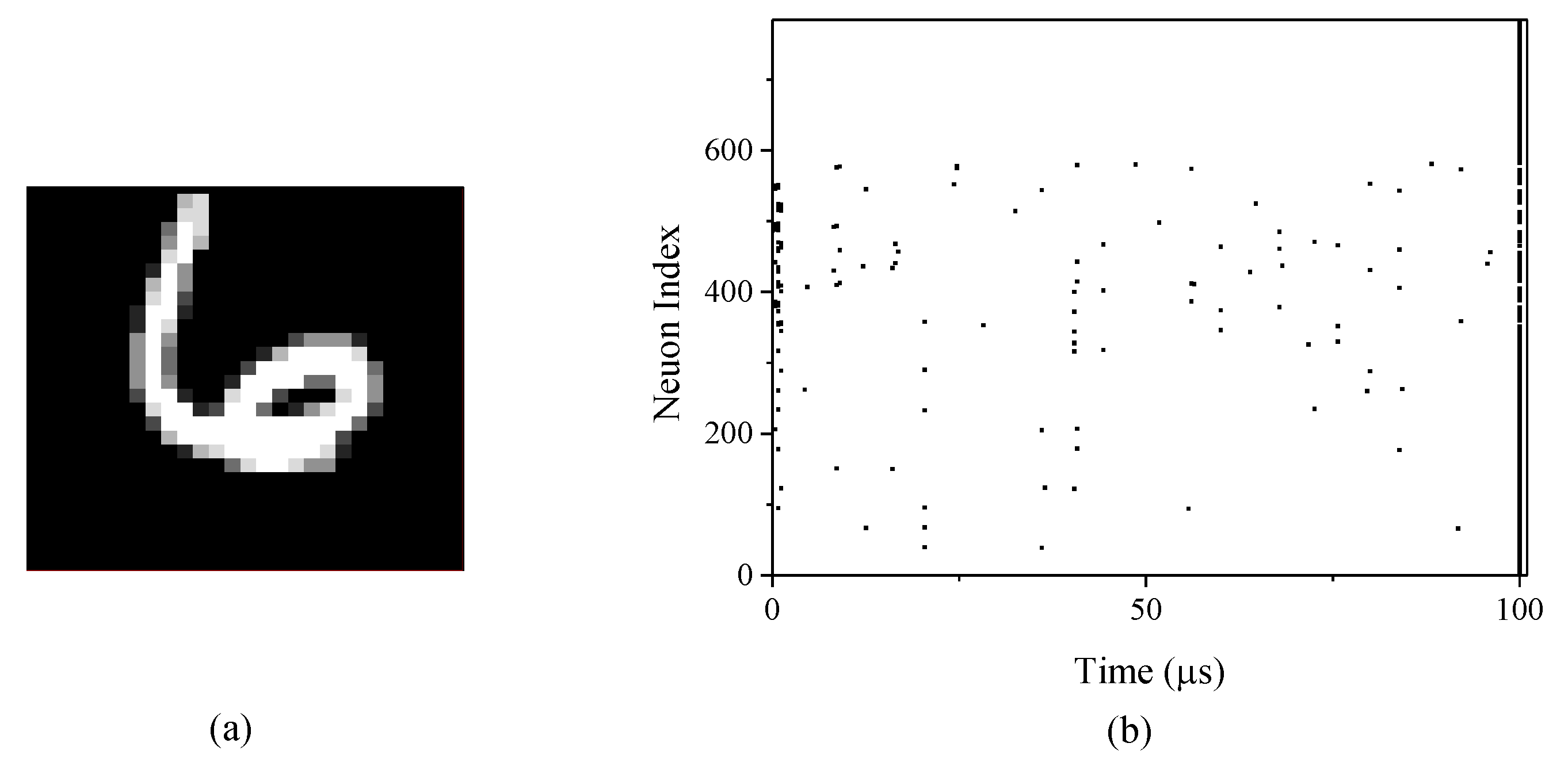
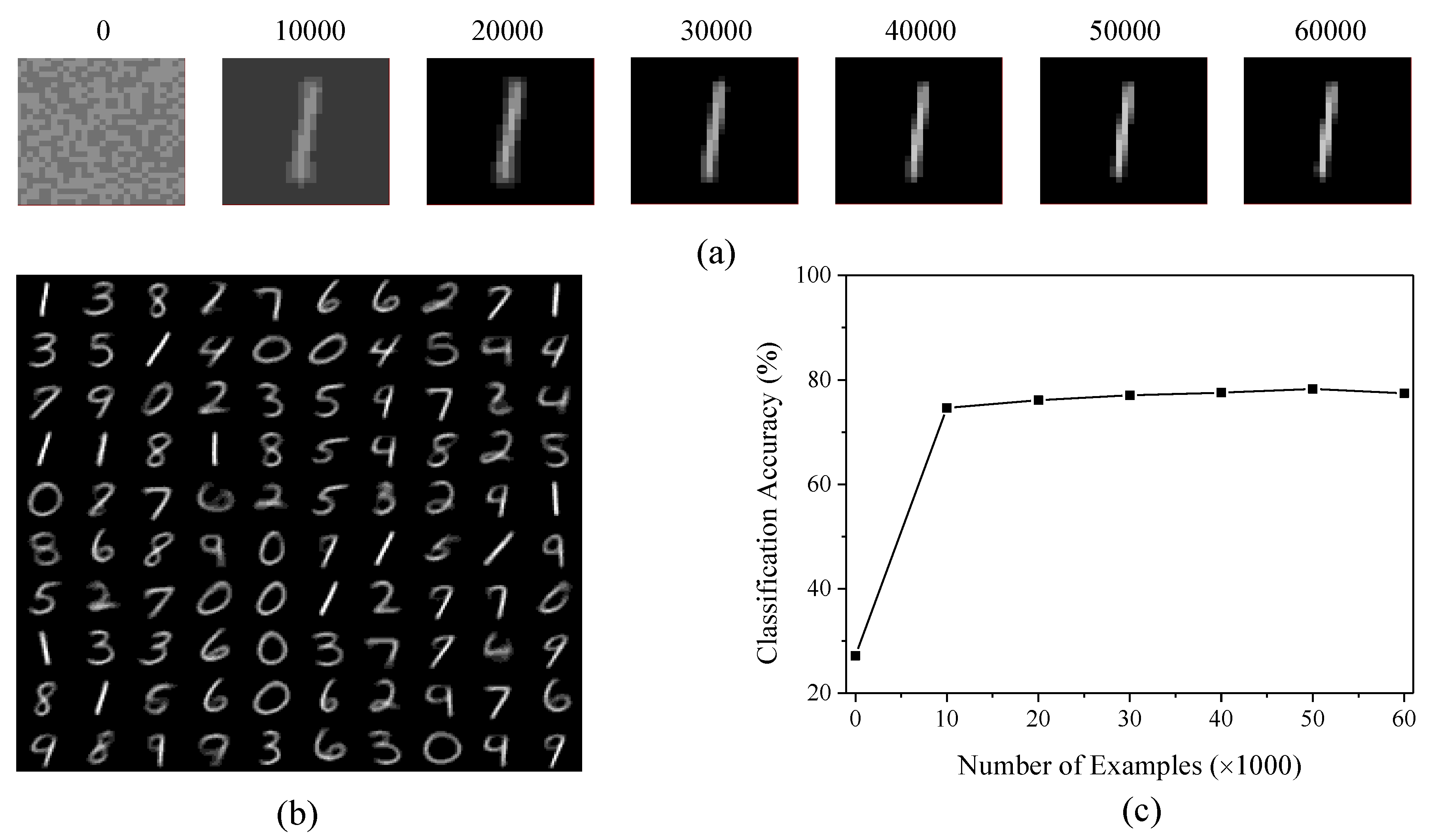
4. Results
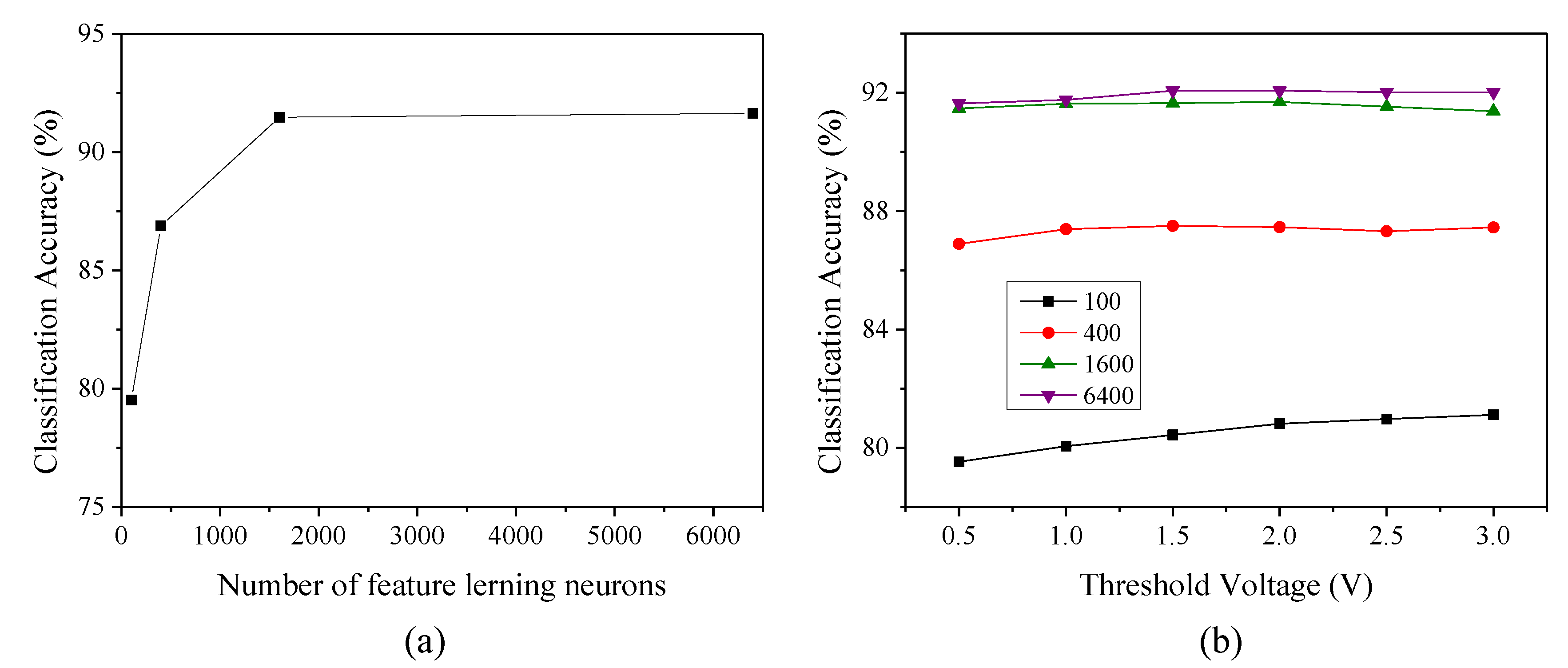
4.1. Feature Learning
4.2. Impact of the Threshold Voltage for Testing
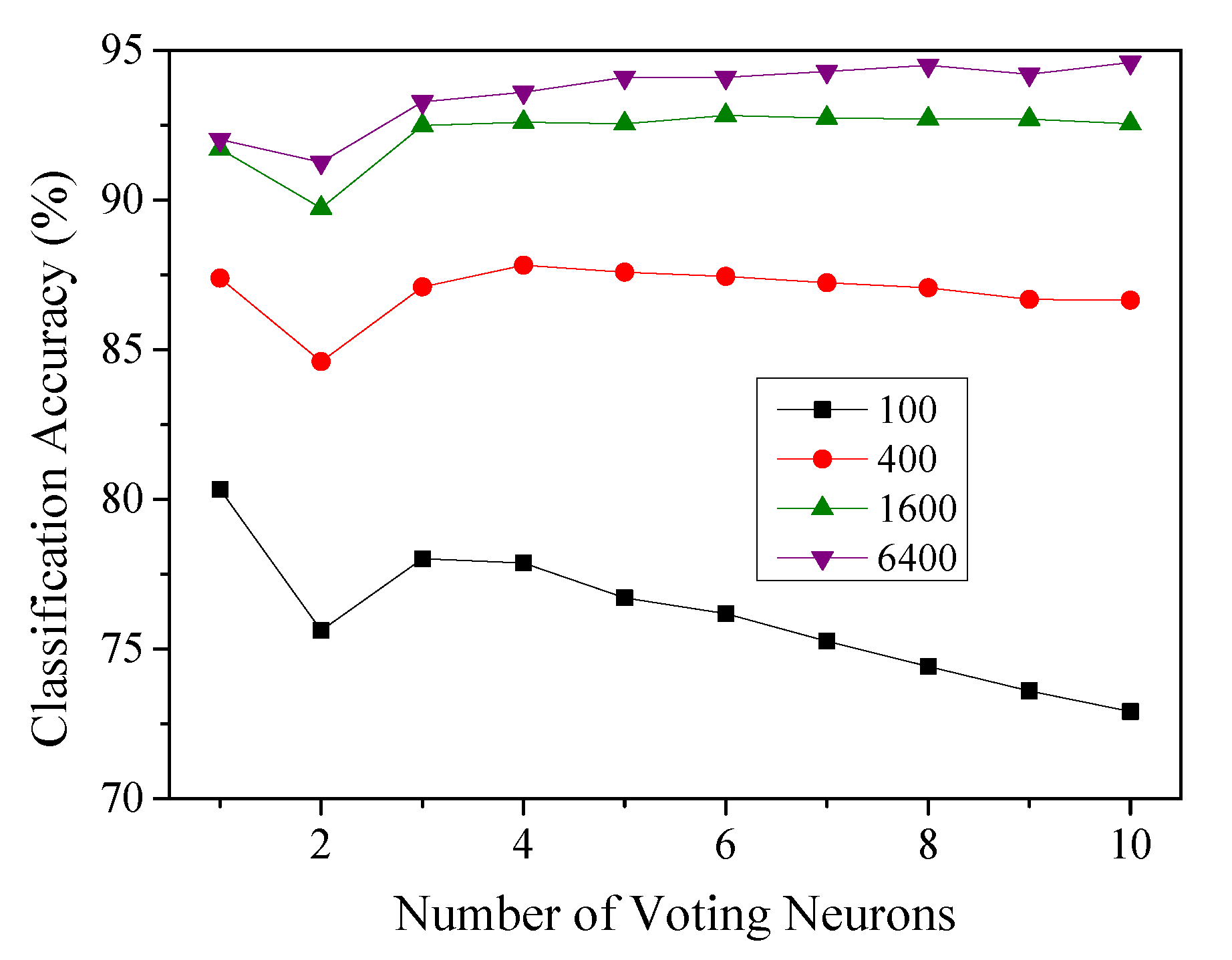
4.3. Impact of the Number of Voting Neurons
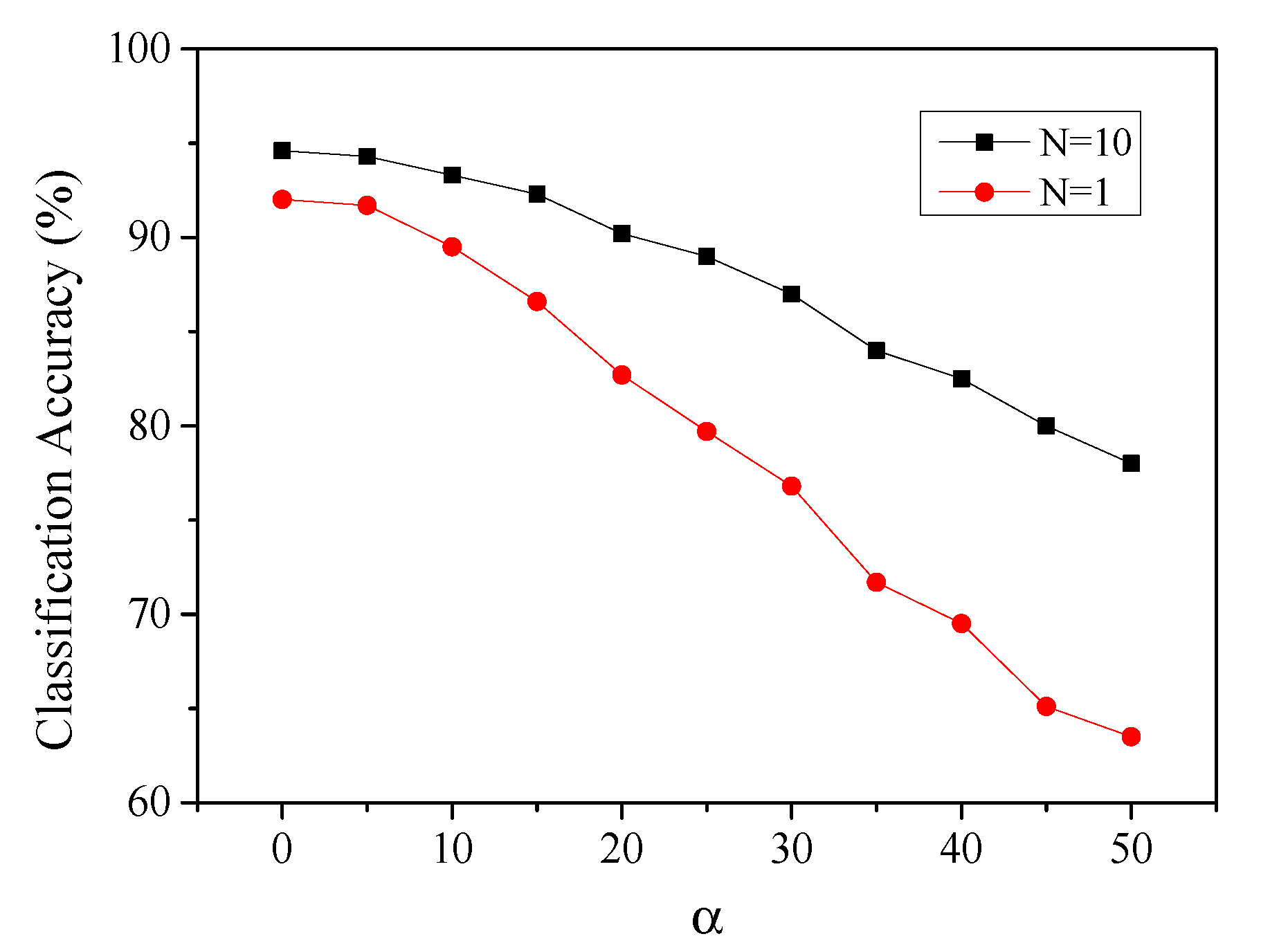
4.4. Impact of Variations of Synaptic Weights
4.5. Comparison
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ambrogio, S.; Narayanan, P.; Tsai, H.; Shelby, R.M.; Boybat, I.; Di Nolfo, C.; Sidler, S.; Giordano, M.; Bodini, M.; Farinha, N.C.P.; et al. Equivalent-accuracy accelerated neural-network training using analogue memory. Nature 2018, 558, 60–67. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Belkin, D.; Li, Y.; Yan, P.; Hu, M.; Ge, N.; Jiang, H.; Montgomery, E.; Lin, P.; Wang, Z.; et al. Efficient and self-adaptive in-situ learning in multilayer memristor neural networks. Nat. Commun. 2018, 9, 7–14. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Yang, X.J.; Wu, J.J.; Zhu, X.; Fang, X.D.; Huang, D. A memristor-based architecture combining memory and image processing. Sci. China Inf. Sci. 2014, 57, 52111. [Google Scholar] [CrossRef]
- Borghetti, J.; Snider, G.S.; Kuekes, P.J.; Yang, J.J.; Stewart, D.R.; Williams, R.S. Memristive switches enable stateful logic operations via material implication. Nature 2010, 464, 873–876. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Yang, X.; Wu, C.; Xiao, N.; Wu, J.; Yi, X. Performing stateful logic on memristor memory. IEEE Trans. Circuits Syst. II Express Briefs 2013, 60, 682–686. [Google Scholar] [CrossRef]
- Vato, A.; Bonzano, L.; Chiappalone, M.; Cicero, S.; Morabito, F.; Novellino, A.; Stillo, G. Spike manager: A new tool for spontaneous and evoked neuronal networks activity characterization. Neurocomputing 2004, 58–60, 1153–1161. [Google Scholar] [CrossRef]
- Payvand, M.; Nair, M.V.; Muller, L.K.; Indiveri, G. A neuromorphic systems approach to in-memory computing with non-ideal memristive devices: From mitigation to exploitation. Faraday Discuss. 2018. [Google Scholar] [CrossRef]
- Hu, M.; Graves, C.E.; Li, C.; Li, Y.; Ge, N.; Montgomery, E.; Davila, N.; Jiang, H.; Williams, R.S.; Yang, J.J.; et al. Memristor-Based Analog Computation and Neural Network Classification with a Dot Product Engine. Adv. Mater. 2018, 30, 1705934. [Google Scholar] [CrossRef]
- Querlioz, D.; Bichler, O.; Dollfus, P.; Gamrat, C.; Querlioz, D.; Bichler, O.; Dollfus, P.; Gamrat, C.; Querlioz, D.; Bichler, O.; et al. Immunity to Device Variations in a Spiking Neural Network with Memristive Nanodevices. IEEE Trans. Nanotechnol. 2013, 12, 288–295. [Google Scholar] [CrossRef]
- Wang, J.J.; Hu, S.G.; Zhan, X.T.; Yu, Q.; Liu, Z.; Chen, T.P.; Yin, Y.; Hosaka, S.; Liu, Y. Handwritten-Digit Recognition by Hybrid Convolutional Neural Network based on HfO2 Memristive Spiking-Neuron. Sci. Rep. 2018, 8, 12546. [Google Scholar] [CrossRef]
- Wang, Z.; Joshi, S.; Savel, S.; Song, W.; Midya, R.; Li, Y.; Rao, M.; Yan, P.; Asapu, S.; Zhuo, Y.; et al. Fully memristive neural networks for pattern classification with unsupervised learning. Nat. Electron. 2018, 1, 137–145. [Google Scholar] [CrossRef]
- Kheradpisheh, S.R.; Ganjtabesh, M.; Thorpe, S.J.; Masquelier, T. STDP-based spiking deep convolutional neural networks for object recognition. Neural Netw. 2018, 99, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Bohte, S.M.; Kok, J.N.; La Poutré, H. Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 2002, 48, 17–37. [Google Scholar] [CrossRef]
- Lee, J.H.; Delbruck, T.; Pfeiffer, M. Training deep spiking neural networks using backpropagation. Front. Neurosci. 2016, 10, 508. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Chen, Y.; Khosla, D. Spiking Deep Convolutional Neural Networks for Energy-Efficient Object Recognition. Int. J. Comput. Vis. 2015, 113, 54–66. [Google Scholar] [CrossRef]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Cohen, G.K.; Orchard, G.; Leng, S.H.; Tapson, J.; Benosman, R.B.; van Schaik, A. Skimming digits: Neuromorphic classification of spike-encoded images. Front. Neurosci. 2016, 10, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Diehl, P.U.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [PubMed]
- Thiele, J.C.; Bichler, O.; Dupret, A. Event-Based, Timescale Invariant Unsupervised Online Deep Learning with STDP. Front. Comput. Neurosci. 2018, 12, 46. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Zeng, Y.; Zhao, D.; Shi, M. A Plasticity-centric Approach to Train the Non-differential Spiking Neural Networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI 2018), New Orleans, LA, USA, 2–7 February 2018; pp. 620–627. [Google Scholar]
- Delorme, A.; Thorpe, S.J. Face identification using one spike per neuron: Resistance to image degradation. Neural Netw. 2001, 14, 795–803. [Google Scholar] [CrossRef]
- Liu, D.; Yue, S. Event-Driven Continuous STDP Learning with Deep Structure for Visual Pattern Recognition. IEEE Trans. Cybern. 2018. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Hu, M.; Li, Y.; Jiang, H.; Ge, N.; Montgomery, E.; Zhang, J.; Song, W.; Dávila, N.; Graves, C.E.; et al. Analogue signal and image processing with large memristor crossbars. Nat. Electron. 2017, 1, 52–59. [Google Scholar] [CrossRef]
- Al-Shedivat, M.; Naous, R.; Cauwenberghs, G.; Salama, K.N. Memristors empower spiking neurons with stochasticity. IEEE J. Emerg. Sel. Top. Circuits Syst. 2015, 5, 242–253. [Google Scholar] [CrossRef]
- Kwon, M.; Park, J.; Baek, M.; Hwang, S.; Park, B. Spiking Neural Networks with Unsupervised Learning Based on STDP Using Resistive Synaptic Devices and Analog CMOS Neuron Circuit. J. Nanosci. Nanotechnol. 2016, 18, 6588–6592. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Saxena, V.; Zhu, K.; Balagopal, S. A CMOS Spiking Neuron for Brain-Inspired Neural Networks with Resistive Synapses and in Situ Learning. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 1088–1092. [Google Scholar] [CrossRef]
- Ferré, P.; Mamalet, F.; Thorpe, S.J. Unsupervised Feature Learning With Winner-Takes-All Based STDP. Front. Comput. Neurosci. 2018, 12, 24. [Google Scholar] [CrossRef] [PubMed]
- Zhou, E.; Fang, L.; Liu, R.; Tang, Z. An improved memristor model for brain-inspired computing. Chin. Phys. B 2017, 26, 118502. [Google Scholar] [CrossRef]
- Lee, C.; Srinivasan, G.; Panda, P.; Roy, K. Deep Spiking Convolutional Neural Network Trained with Unsupervised Spike Timing Dependent Plasticity. IEEE Trans. Cogn. Dev. Syst. 2018. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Voltage of Step Signals for learning () | 1 V |
| Threshold Voltage of Neurons for Learning () | 0.5 V |
| Integration Capcitance (C) | 1 nF |
| Processing Duration (p) | 100 s |
| 20 s | |
| / | 0.002/−0.001 |
| Architecture | (Un)-Supervised | Learning Method | Encoding Scheme | Lateral Inhibition | Adaptive Threshold Voltage | Accuracy |
|---|---|---|---|---|---|---|
| our work | Unsupervised | STDP | Time-based | No | No | 94.6% |
| Two-layer MSNN [9] | Unsupervised | STDP | Rate-based | Yes | Yes | 93.5% |
| SCNN [12] | Both | STDP + SVM | Time-based | Yes | No | 98.4% |
| Two-layer SNN [18] | Unsupervised | STDP | Rate-based | Yes | Yes | 95% |
| SCNN [19] | Unsupervised | STDP | Rate-based | Yes | Yes | 96.58% |
| Multilayer SNN [20] | Both | STDP | Rate-based | No | No | 98.52% |
| SCNN [22] | Supervised | STDP | Time-based | Yes | Yes | 93% |
| SCNN [29] | Unsupervised | STDP | Rate-based | Yes | Yes | 91.1% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, E.; Fang, L.; Yang, B. Memristive Spiking Neural Networks Trained with Unsupervised STDP. Electronics 2018, 7, 396. https://doi.org/10.3390/electronics7120396
Zhou E, Fang L, Yang B. Memristive Spiking Neural Networks Trained with Unsupervised STDP. Electronics. 2018; 7(12):396. https://doi.org/10.3390/electronics7120396
Chicago/Turabian StyleZhou, Errui, Liang Fang, and Binbin Yang. 2018. "Memristive Spiking Neural Networks Trained with Unsupervised STDP" Electronics 7, no. 12: 396. https://doi.org/10.3390/electronics7120396
APA StyleZhou, E., Fang, L., & Yang, B. (2018). Memristive Spiking Neural Networks Trained with Unsupervised STDP. Electronics, 7(12), 396. https://doi.org/10.3390/electronics7120396