Illumination-Insensitive Skin Depth Estimation from a Light-Field Camera Based on CGANs toward Haptic Palpation


Abstract
1. Introduction
2. Related Work
2.1. Illumination Normalization
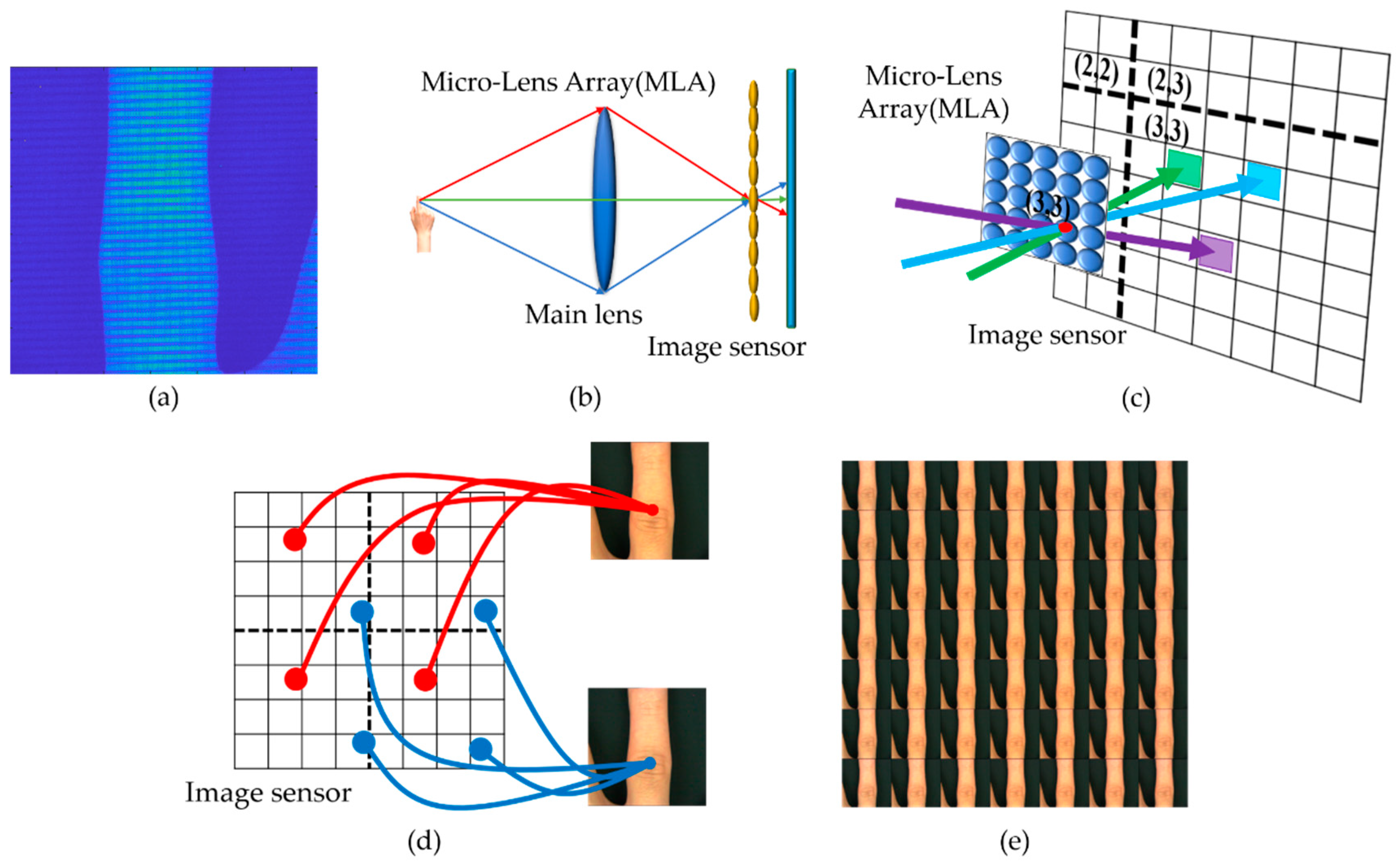
2.2. Depth Estimation from Light-Field Images
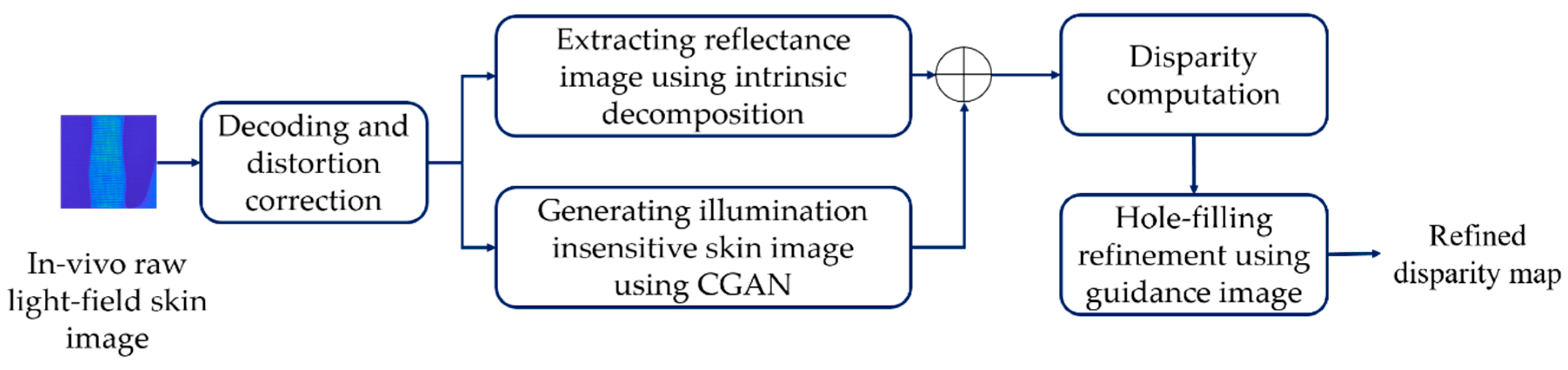
3. Materials and Methods
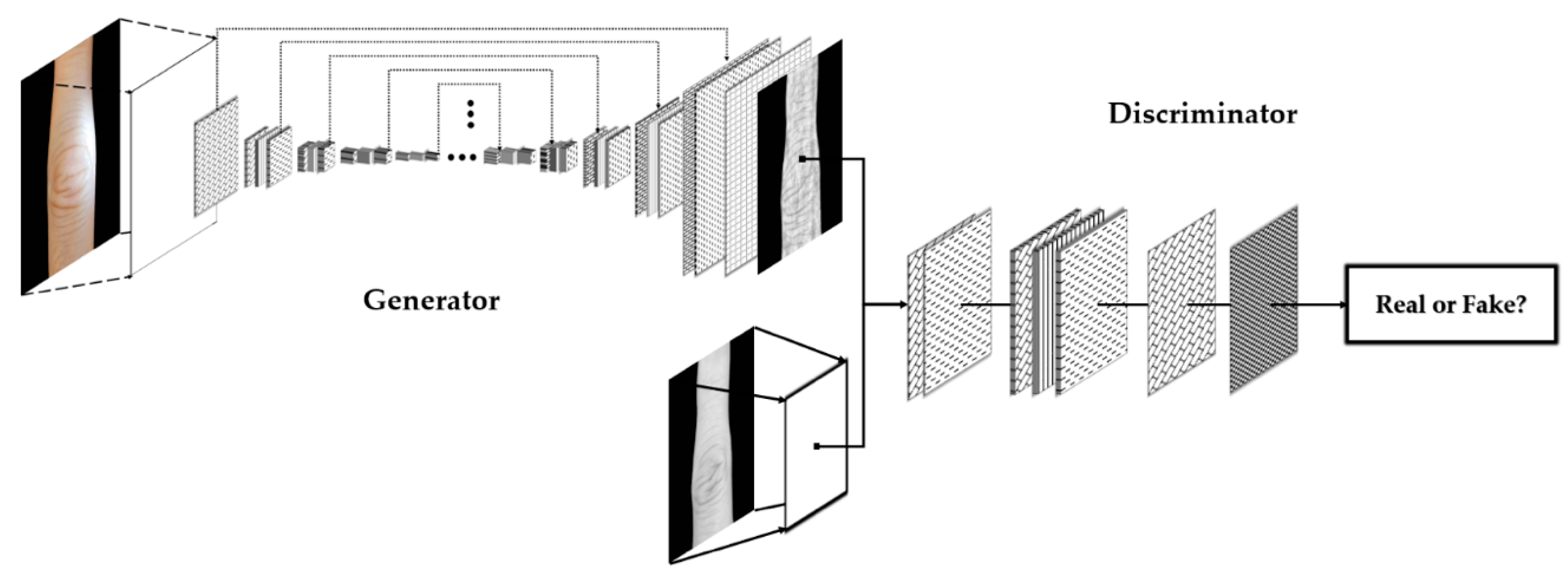
3.1. Conditional Generative Adversarial Network (CGAN)-Based Illumination Insensitive and Texture Enhancemed Image Generation
3.1.1. Generative Adversarial Networks (GANs)
3.1.2. Conditional Generative Adversarial Networks (CGANs)
3.2. Intrinsic Image Decomposition
3.3. Decoding and Distortion Correction of Lytro Images
3.4. Disparity Estimation and Refinement
3.4.1. Initial Depth Estimation
3.4.2. Disparity Refinement
4. Results
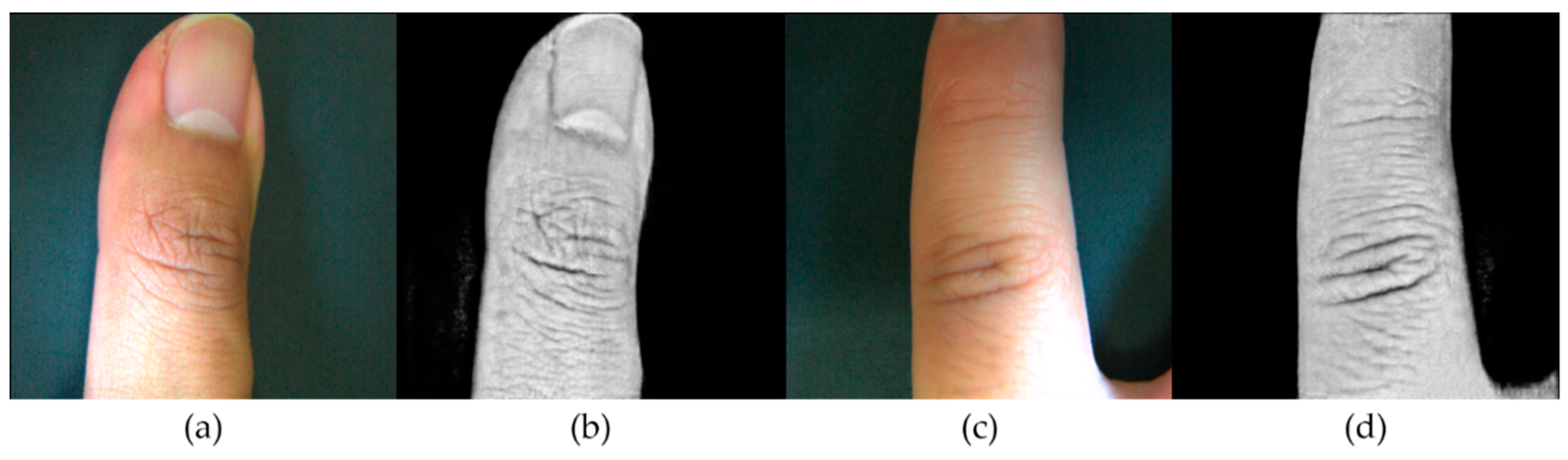
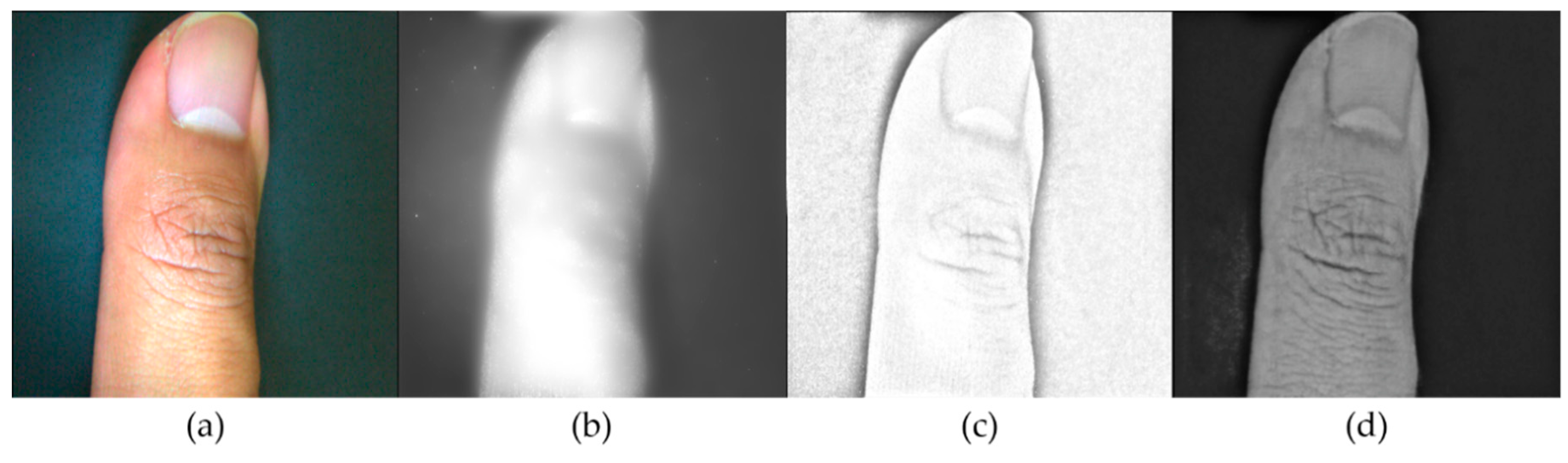
4.1. CGAN-Based Illumination Insensitive Image Generation
4.2. Disparity Map Estimation Using Light-Field Images under Natural Illumination
4.3. Disparity Map Estimation Using Light-Field Images under Controlled Illumination
5. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Ring, J.; Eberlein-König, B.; Schäfer, T.; Huss-Marp, J.; Darsow, U.; Möhrenschlager, M.; Behrendt, H. Skin surface pH, stratum corneum hydration, trans-epidermal water loss and skin roughness related to atopic eczema and skin dryness in a population of primary school children: Clinical report. Acta Dermatol.-Venerol. 2000, 80, 188–191. [Google Scholar]
- Fadzil, M.A.; Prakasa, E.; Fitriyah, H.; Nugroho, H.; Affandi, A.M.; Hussein, S.H. Validation on 3D surface roughness algorithm for measuring roughness of psoriasis lesion. Biol. Biomed. Sci. 2010, 7, 205–2010. [Google Scholar]
- Lagarde, J.; Rouvrais, C.; Black, D. Topography and anisotropy of the skin surface with ageing. Skin Res. Technol. 2005, 11, 110–119. [Google Scholar] [CrossRef] [PubMed]
- Masaki, H. Role of antioxidants in the skin: Anti-aging effects. J. Dermatol. Sci. 2010, 58, 85–90. [Google Scholar] [CrossRef] [PubMed]
- Fujimura, T.; Haketa, K.; Hotta, M.; Kitahara, T. Global and systematic demonstration for the practical usage of a direct in vivo measurement system to evaluate wrinkles. Int. J. Cosmet. Sci. 2007, 29, 423–436. [Google Scholar] [CrossRef] [PubMed]
- Schrader, K.; Bielfeldt, S. Comparative studies of skin roughness measurements by image analysis and several in vivo skin testing methods. J. Soc. Cosmet. Chem. 1991, 42, 385–391. [Google Scholar]
- Levy, J.L.; Servant, J.J.; Jouve, E. Botulinum toxin A: A 9-month clinical and 3D in vivo profilometric crow’s feet wrinkle formation study. J. Cosmet. Laser Ther. 2004, 6, 16–20. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.; Nam, G.W.; Kim, S.; Lee, H.; Moon, S.; Chang, I. Influence of polyol and oil concentration in cosmetic products on skin moisturization and skin surface roughness. Skin Res. Technol. 2007, 13, 417–424. [Google Scholar] [CrossRef] [PubMed]
- Kim, K. Roughness based perceptual analysis towards digital skin imaging system with haptic feedback. Skin Res. Technol. 2016, 22, 334–340. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Lee, S. Perception-based 3D tactile rendering from a single image for human skin examinations by dynamic touch. Skin Res. Technol. 2015, 21, 164–174. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.; Kim, M.; Lee, O.; Kim, K. Roughness preserving filter design to remove spatial noise from stereoscopic skin images for stable haptic rendering. Skin Res. Technol. 2017, 23, 407–415. [Google Scholar] [CrossRef] [PubMed]
- Kim, K. Image-based haptic roughness estimation and rendering for haptic palpation from in vivo skin image. Med. Biol. Eng. Comput. 2018, 56, 413–420. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.; Kim, M.; Kim, K. 3D skin surface reconstruction from a single image by merging global curvature and local texture using the guided filtering for 3D haptic palpation. Skin Res. Technol. 2018, 24, 672–685. [Google Scholar] [CrossRef] [PubMed]
- Lee, O.; Lee, K.; Oh, C.; Kim, K.; Kim, M. Prototype tactile feedback system for examination by skin touch. Skin Res. Technol. 2014, 20, 307–314. [Google Scholar] [CrossRef] [PubMed]
- Kim, K. Haptic augmented skin surface generation toward telepalpation from a mobile skin image. Skin Res. Technol. 2018, 24, 203–212. [Google Scholar] [CrossRef] [PubMed]
- Lee, O.; Lee, G.; Oh, J.; Kim, M.; Oh, C. An optimized in vivo multiple-baseline stereo imaging system for skin wrinkles. Opt. Commun. 2010, 283, 4840–4845. [Google Scholar] [CrossRef]
- Tepole, A.B.; Gart, M.; Purnell, C.A.; Gosain, A.K.; Kuhl, E. Multi-view stereo analysis reveals anisotropy of prestrain, deformation, and growth in living skin. Biomech. Model. Mechanobiol. 2015, 14, 1007–1019. [Google Scholar] [CrossRef] [PubMed]
- Jeon, H.-G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.-W.; So Kweon, I. Accurate depth map estimation from a lenslet light field camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1547–1555. [Google Scholar]
- Jeon, H.-G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.W.; Kweon, I.S. Depth from a Light Field Image with Learning-based Matching Costs. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Park, I.K.; Lee, K.M. Robust light field depth estimation using occlusion-noise aware data costs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 10, 2484–2497. [Google Scholar]
- Tao, M.W.; Hadap, S.; Malik, J.; Ramamoorthi, R. Depth from combining defocus and correspondence using light-field cameras. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 673–680. [Google Scholar]
- Tao, M.W.; Srinivasan, P.P.; Hadap, S.; Rusinkiewicz, S.; Malik, J.; Ramamoorthi, R. Shape estimation from shading, defocus, and correspondence using light-field angular coherence. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 546–560. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.-C.; Efros, A.A.; Ramamoorthi, R. Occlusion-aware depth estimation using light-field cameras. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3487–3495. [Google Scholar]
- Yu, Z.; Guo, X.; Lin, H.; Lumsdaine, A.; Yu, J. Line assisted light field triangulation and stereo matching. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2792–2799. [Google Scholar]
- Heber, S.; Pock, T. Shape from light field meets robust PCA. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 751–767. [Google Scholar]
- Zhang, S.; Sheng, H.; Li, C.; Zhang, J.; Xiong, Z. Robust depth estimation for light field via spinning parallelogram operator. Comput. Vis. Image Underst. 2016, 145, 148–159. [Google Scholar] [CrossRef]
- Wanner, S.; Goldluecke, B. Globally consistent depth labeling of 4D light fields. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 41–48. [Google Scholar]
- Wanner, S.; Straehle, C.; Goldluecke, B. Globally consistent multi-label assignment on the ray space of 4d light fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1011–1018. [Google Scholar]
- Kim, C.; Zimmer, H.; Pritch, Y.; Sorkine-Hornung, A.; Gross, M.H. Scene reconstruction from high spatio-angular resolution light fields. ACM Trans. Graph. 2013, 32. [Google Scholar] [CrossRef]
- Tosic, I.; Berkner, K. Light field scale-depth space transform for dense depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 435–442. [Google Scholar]
- Heber, S.; Pock, T. Convolutional networks for shape from light field. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3746–3754. [Google Scholar]
- Heber, S.; Yu, W.; Pock, T. U-shaped Networks for Shape from Light Field. In Proceedings of the British Machine Vision Conference 2016, York, UK, 19–22 September 2016; p. 5. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.-P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2782–2790. [Google Scholar]
- Chen, W.; Er, M.J.; Wu, S. Illumination compensation and normalization for robust face recognition using discrete cosine transform in logarithm domain. IEEE Trans. Syst. Man Cybern. Part B 2006, 36, 458–466. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Smith, K.; Li, Y.; Piccinini, F.; Csucs, G.; Balazs, C.; Bevilacqua, A.; Horvath, P. CIDRE: An illumination-correction method for optical microscopy. Nat. Methods 2015, 12, 404. [Google Scholar] [CrossRef] [PubMed]
- Kakadiaris, I.A.; Toderici, G.; Evangelopoulos, G.; Passalis, G.; Chu, D.; Zhao, X.; Shah, S.K.; Theoharis, T. 3D-2D face recognition with pose and illumination normalization. Comput. Vis. Image Underst. 2017, 154, 137–151. [Google Scholar] [CrossRef]
- Tu, X.; Gao, J.; Xie, M.; Qi, J.; Ma, Z. Illumination normalization based on correction of large-scale components for face recognition. Neurocomputing 2017, 266, 465–476. [Google Scholar] [CrossRef]
- Thomas, M.M.; Forbes, A.G. Deep Illumination: Approximating Dynamic Global Illumination with Generative Adversarial Network. arXiv, 2017; arXiv:1710.09834. [Google Scholar]
- Funke, I.; Bodenstedt, S.; Riediger, C.; Weitz, J.; Speidel, S. Generative adversarial networks for specular highlight removal in endoscopic images. In Proceedings of the Medical Imaging 2018: Image-Guided Procedures, Robotic Interventions, and Modeling, Houston, Texas, USA, 10–15 February 2018; p. 1057604. [Google Scholar]
- Memariani, A.; Kakadiaris, I.A. SoLiD: Segmentation of Clostridioides Difficile Cells in the Presence of Inhomogeneous Illumination Using a Deep Adversarial Network. In Proceedings of the 2018 International Workshop on Machine Learning in Medical Imaging, Granada, Spain, 16 September 2018; pp. 285–293. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. arXiv, 2017; arXiv:1611.07004. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv, 2014; arXiv:1411.1784. [Google Scholar]
- Land, E.H.; McCann, J.J. Lightness and retinex theory. Josa 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Sabater, N.; Drazic, V.; Seifi, M.; Sandri, G.; Pérez, P. Light-Field Demultiplexing and Disparity Estimation. 2014. Available online: https://hal.archives-ouvertes.fr/hal-00925652 (accessed on 18 October 2018).
- Dansereau, D.G.; Pizarro, O.; Williams, S.B. Decoding, calibration and rectification for lenselet-based plenoptic cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1027–1034. [Google Scholar]
- Tang, H.; Kutulakos, K.N. What does an aberrated photo tell us about the lens and the scene? In Proceedings of the 2013 IEEE International Conference on Computational Photography (ICCP), Cambridge, MA, USA, 19–21 April 2013; pp. 1–10. [Google Scholar]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Rhemann, C.; Hosni, A.; Bleyer, M.; Rother, C.; Gelautz, M. Fast cost-volume filtering for visual correspondence and beyond. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3017–3024. [Google Scholar]
- Kolmogorov, V.; Zabih, R. Multi-camera scene reconstruction via graph cuts. In Proceedings of the 2002 European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; pp. 82–96. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In Proceedings of the 2010 European Conference on computer Vision, Crete, Greece, 5–11 September 2010; pp. 1–14. [Google Scholar]
- Bradley, D.; Roth, G. Adaptive thresholding using the integral image. J. Graph. Tools 2007, 12, 13–21. [Google Scholar] [CrossRef]
- Wanner, S.; Meister, S.; Goldluecke, B. Datasets and benchmarks for densely sampled 4d light fields. In Proceedings of the Vision, Modeling & Visualization, Lugano, Switzerland, 11 September–13 October 2013; pp. 225–226. [Google Scholar]
- Shen, C.-T.; Hwang, W.-L. Color image enhancement using retinex with robust envelope. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 3141–3144. [Google Scholar]
- Zuiderveld, K. Contrast limited adaptive histogram equalization. In Graphics Gems; Academic Press Professional, Inc.: San Diego, CA, USA, 1994; pp. 474–485. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | TT [36] | CIDRE [37] | Shen [55] | Zuiderveld [56] | Our method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM | PSNR | MSE | SSIM | PSNR | MSE | SSIM | PSNR | MSE | SSIM | PSNR | MSE | SSIM | PSNR | MSE | |
| 1 | 0.74 | 17.39 | 1184.7 | 0.83 | 20.63 | 562.5 | 0.82 | 11.10 | 5052.1 | 0.84 | 11.42 | 4690.1 | 0.85 | 21.03 | 512.4 |
| 2 | 0.76 | 17.92 | 1049.5 | 0.77 | 19.21 | 780.5 | 0.85 | 13.10 | 3183.6 | 0.85 | 13.95 | 2616.5 | 0.82 | 24.34 | 239.2 |
| 3 | 0.73 | 17.68 | 1108.8 | 0.76 | 18.71 | 875.7 | 0.85 | 15.06 | 2030.0 | 0.84 | 16.08 | 1605.1 | 0.84 | 23.05 | 321.8 |
| 4 | 0.75 | 17.69 | 1106.4 | 0.78 | 18.79 | 859.9 | 0.88 | 14.92 | 2095.7 | 0.85 | 15.04 | 2035.2 | 0.86 | 23.91 | 265.1 |
| 5 | 0.73 | 15.24 | 1943.9 | 0.75 | 13.66 | 2800.8 | 0.84 | 17.43 | 1173.8 | 0.82 | 17.54 | 1146.7 | 0.77 | 20.77 | 544.3 |
| 6 | 0.74 | 15.52 | 1824.8 | 0.79 | 14.71 | 2198.0 | 0.86 | 19.21 | 779.5 | 0.86 | 18.41 | 937.9 | 0.81 | 22.14 | 397.4 |
| 7 | 0.79 | 17.21 | 1237.2 | 0.85 | 16.56 | 1435.3 | 0.92 | 19.79 | 682.8 | 0.91 | 17.13 | 1259.1 | 0.87 | 20.78 | 543.2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ko, M.; Kim, D.; Kim, M.; Kim, K. Illumination-Insensitive Skin Depth Estimation from a Light-Field Camera Based on CGANs toward Haptic Palpation. Electronics 2018, 7, 336. https://doi.org/10.3390/electronics7110336
Ko M, Kim D, Kim M, Kim K. Illumination-Insensitive Skin Depth Estimation from a Light-Field Camera Based on CGANs toward Haptic Palpation. Electronics. 2018; 7(11):336. https://doi.org/10.3390/electronics7110336
Chicago/Turabian StyleKo, Myeongseob, Donghyun Kim, Mingi Kim, and Kwangtaek Kim. 2018. "Illumination-Insensitive Skin Depth Estimation from a Light-Field Camera Based on CGANs toward Haptic Palpation" Electronics 7, no. 11: 336. https://doi.org/10.3390/electronics7110336
APA StyleKo, M., Kim, D., Kim, M., & Kim, K. (2018). Illumination-Insensitive Skin Depth Estimation from a Light-Field Camera Based on CGANs toward Haptic Palpation. Electronics, 7(11), 336. https://doi.org/10.3390/electronics7110336