
RFID Reader Anticollision Protocols for Dense and Mobile Deployments



Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- distributed and local: Each reader runs the same algorithm with a loose TDMA approach based on its internal clock handling clock-drifts with time margins and relying solely on the information given by neighbors in its vicinity. This allows our proposals to be scalable;
- mobile-ready: the previous criterion grants our proposals the capacity to handle mobile deployments of readers without mitigating their performance;
- efficient: improving the throughput in terms of idle medium accesses while highly reducing the number of collisions compared to the state-of-the-art protocols.
2. Problem Statement
2.1. Dense Environments
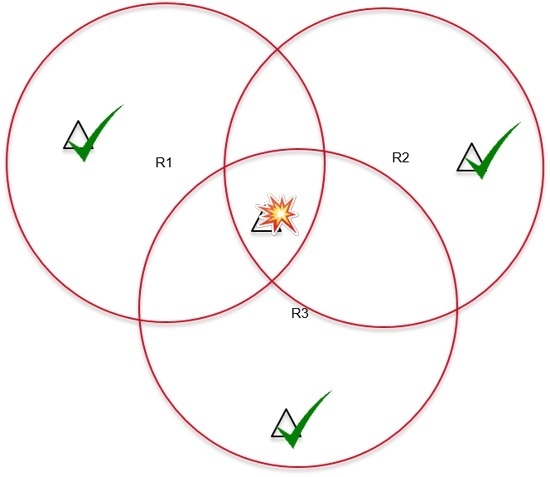
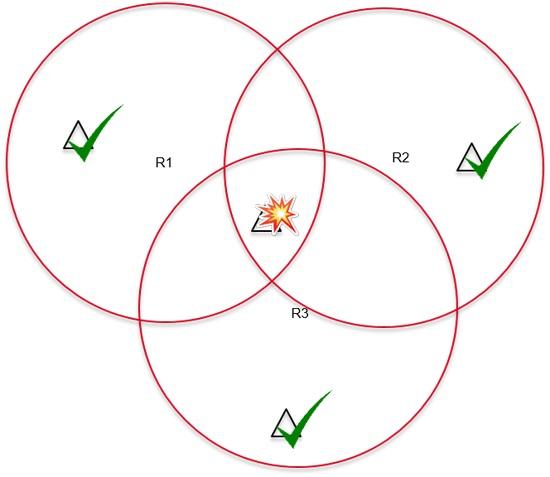
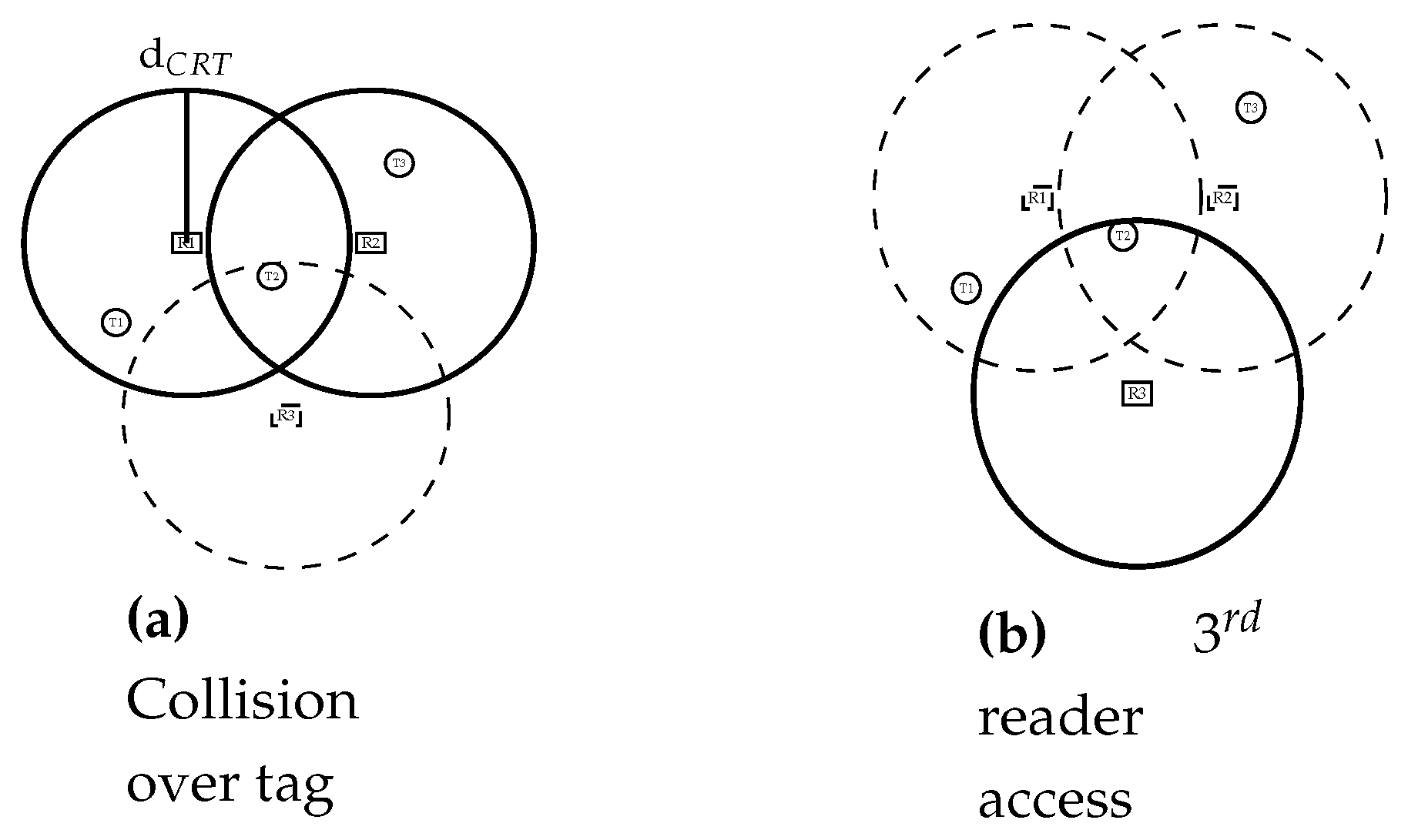
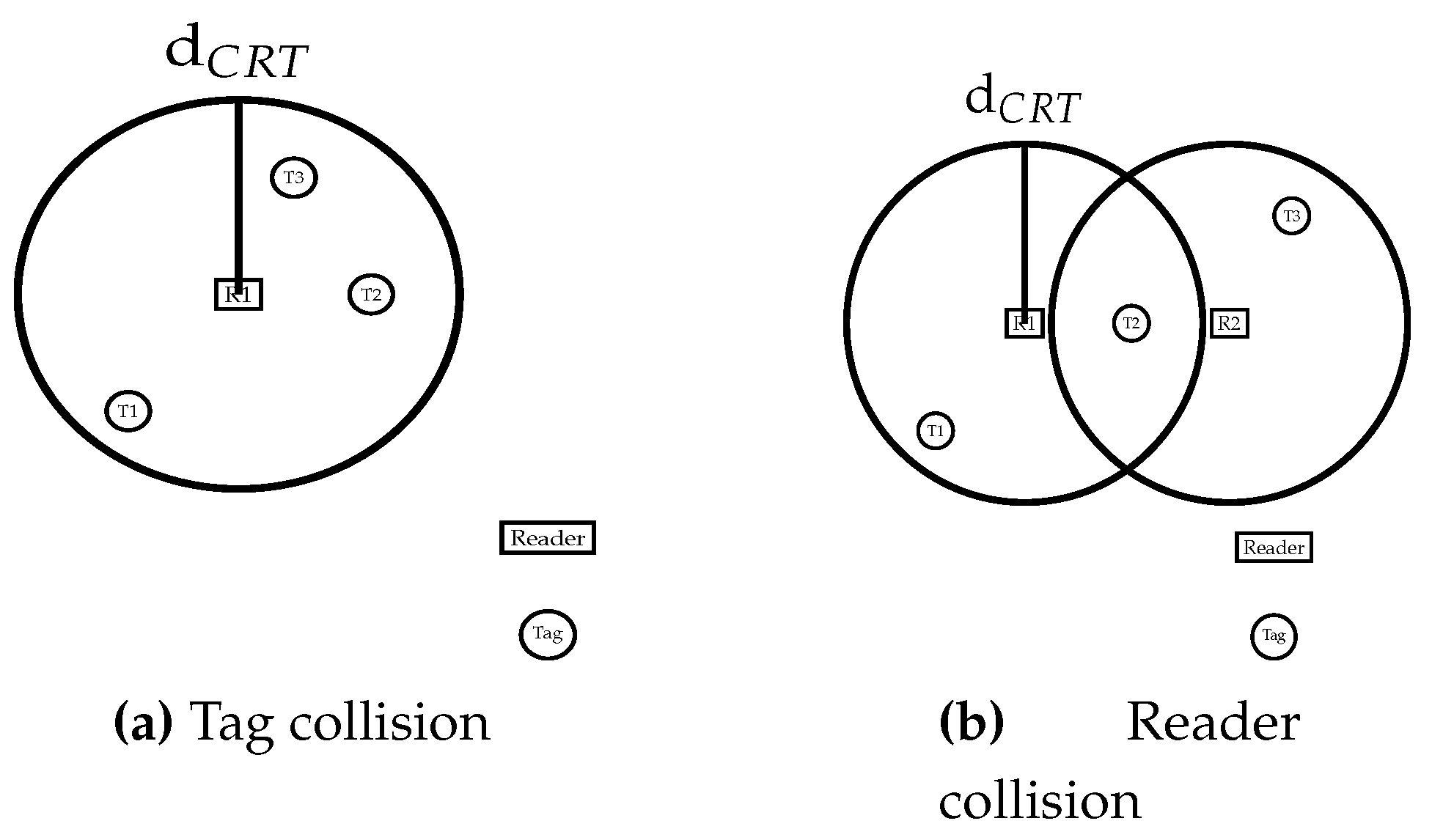
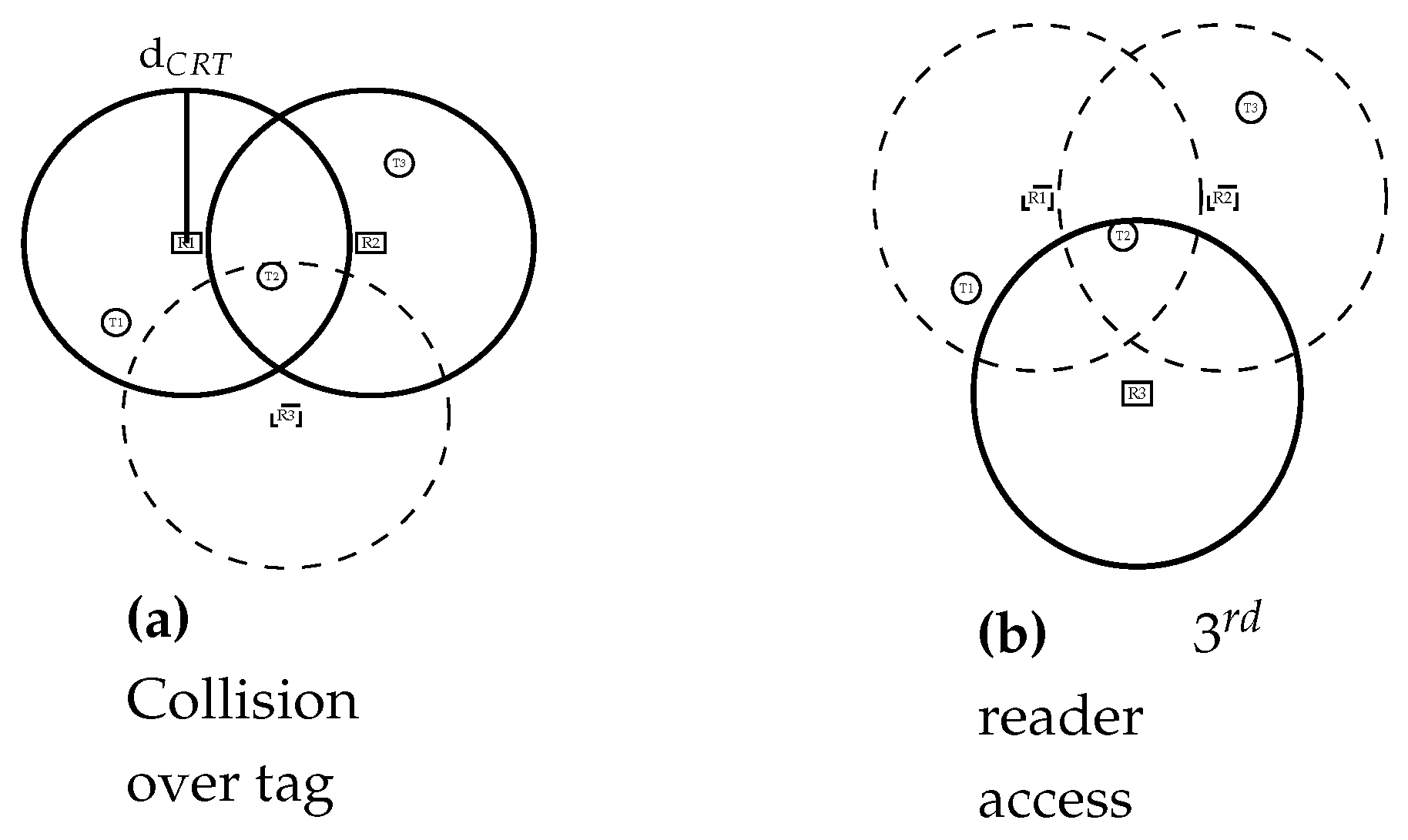
- Tag collision: This happens when a reader covering multiple tags tries to read all of them at the same time. When all tags try to backscatter their response to the reader, their generated signals will collide and none of them will be identified. As featured in Figure 1a, when R1 sends a request to read tags within its reading range, tags T1, T2 and T3 will simultaneously answer, thus R1 will not be able to identify any of the tags. In the case of an application such as a warehouse, where tags are attached to products, this could result in misplaced or untracked goods, highly impacting the productivity. Fortunately, many solutions have been proposed to overcome this issue which is more than likely resolved thanks to ALOHA [7,8,9], tree [10,11,12], and frame-and-tree [13,14,15] based protocols. These solutions are already integrated in readers available on the market.
- Reader collision: This occurs when multiple readers attempt to read a given tag simultaneously. Since tags are passive entities, with no computation or frequency dissociation capabilities, they are unable to differentiate the different requests coming from the different readers, and will just identify the multiple requests as radio noise, which again results in an unread tag. In Figure 1b, an example is shown where both readers R1 and R2 attempt to identify tags in their vicinity. While tags T1 and T3 are successfully read by readers R1 and R2 respectively, T2 which is within the colliding area of the readers fails to be read. To overcome this issue, readers can either operate at different times or ensure a distance of ( is the reading range) between devices [16].
2.2. Mobility
2.3. Centralized vs. Distributed
- Centralized: In this configuration, readers communicate with a top entity (central server) responsible for the scheduling of operations. The central server is able, after gathering all information from the readers topology, to compute the optimal reading scheme, reducing collisions. However, in general, the use of a central server restricts the mobility of readers at the expense of a higher level of computation and latency. Added to that, having readers depending on a superior entity for any operation makes solutions less reactive. Solutions depending on the use of a central server are usually found in TDMA-based schemes.
- Distributed: In this setup, readers directly communicate with each other and locally (in time and space) agree in a peer-to-peer manner on their operation schemes to reduce collisions. Readers are able to exchange with their peers in the extent of their communication range defining their vicinity; this allows solutions based on this paradigm to be scalable and support dynamic changes in topology. Every decision taken by a given reader is dictated by its knowledge of its vicinity at a given time. Distributed solutions are found both in TDMA and CSMA-based algorithms.
2.4. Monochannel vs. Multichannel
2.5. Dedicated Control Channel
3. Related Work
4. Distributed Efficient and Fair Anticollision for RFID Protocol DEFAR
4.1. Overview of DEFAR
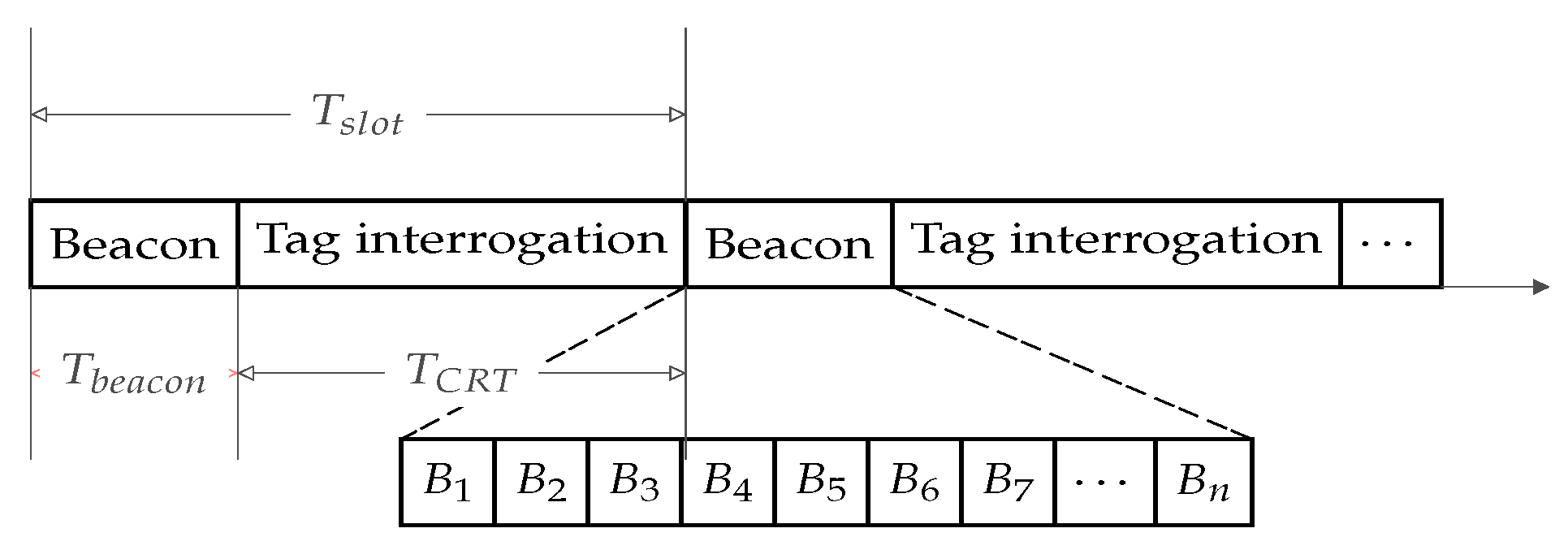
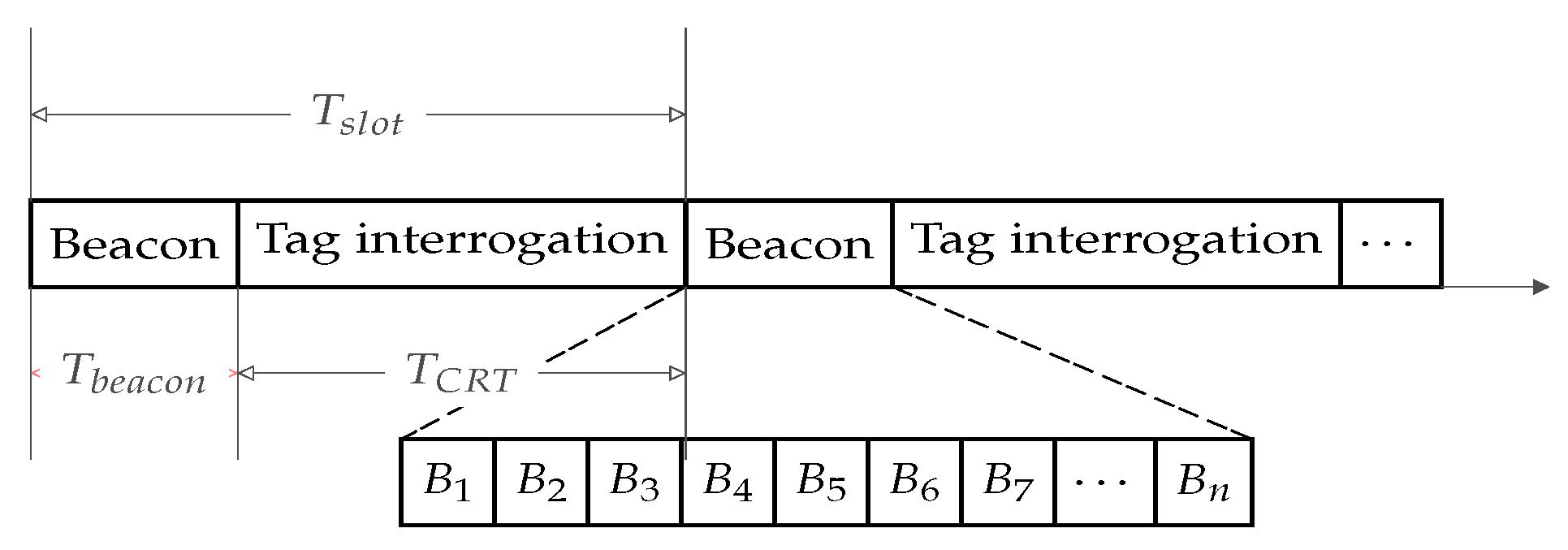
- First, a beaconing phase for each reader to discover its neighbors and ensure it can access the medium. During this phase, each reader observes a random backoff period before sending its beacon. The way we designed the number of backoff slots allows an insubstantial number of potential beacon collisions. A large range of beaconing slots are available (see Figure 3) for readers to randomly chose from and only readers at the current ongoing reading slot are awakened, thus making beacon collisions very unlikely to happen.
- Second is a reading phase for readers to access tags for a defined period of time. Regarding the previous beacons’ exchange between readers and the disabling of colliding readers, no collision is then conceivable when reading tags, since on each slot and frequency, there cannot be more than one reader trying to read tags: the corresponding competition is based on the information gathered during the beaconing phase.
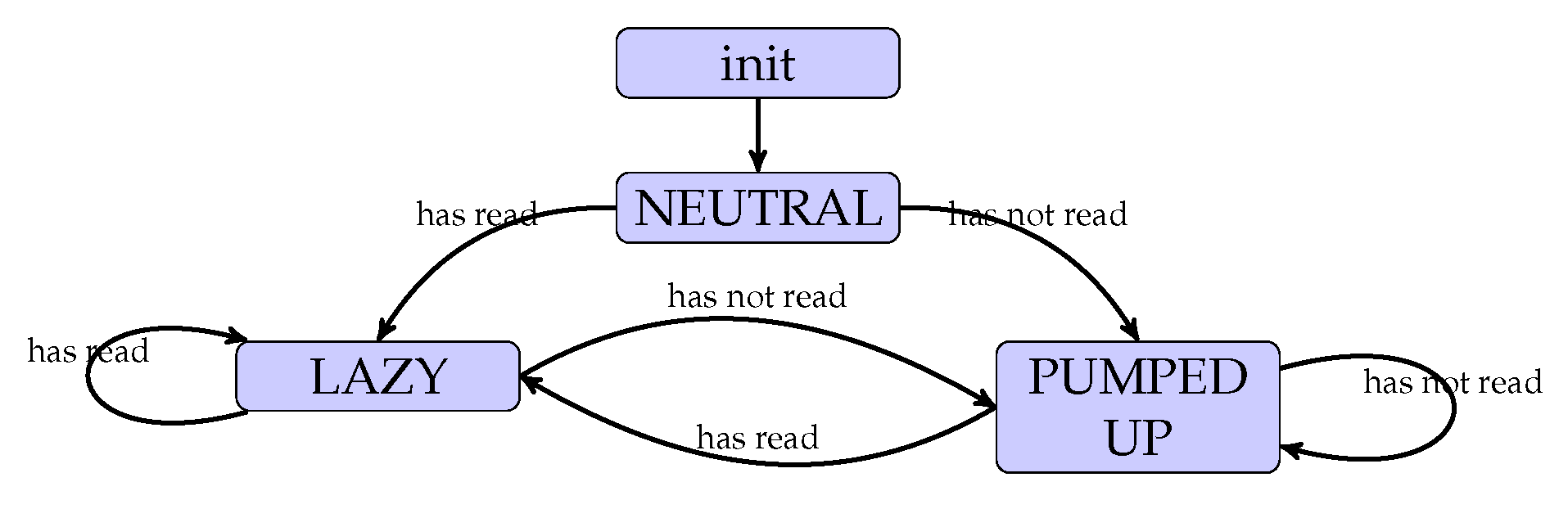
- NEUTRAL is the priority of all readers at start;
- LAZY is the lowest priority, it is given to readers which have successfully read the tags in their range on the previous frame;
- PUMPED UP, the highest priority, is given to readers that have failed to access the medium, thus giving them a higher probability of accessing tags during the following frame.
- Case 1:
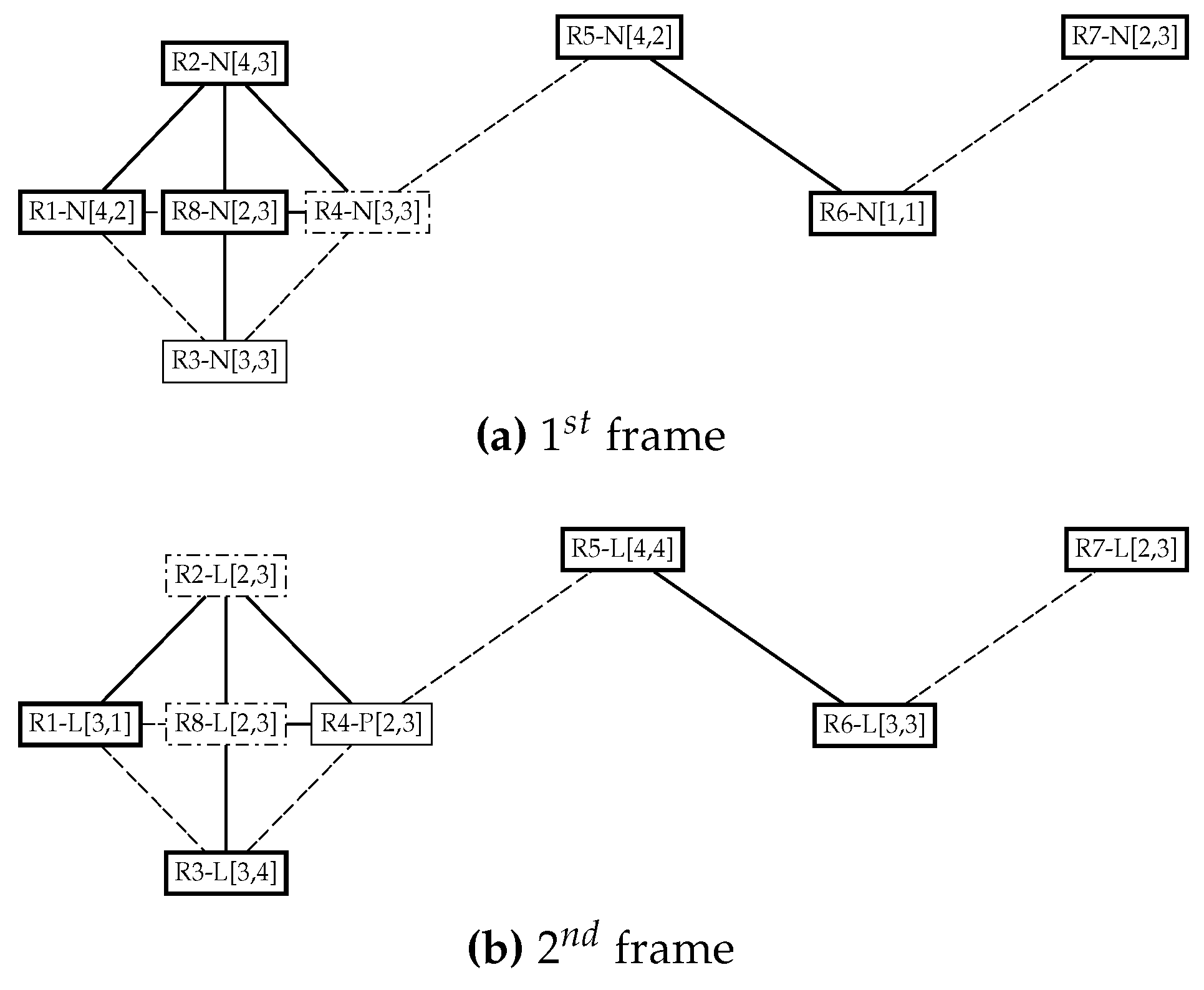
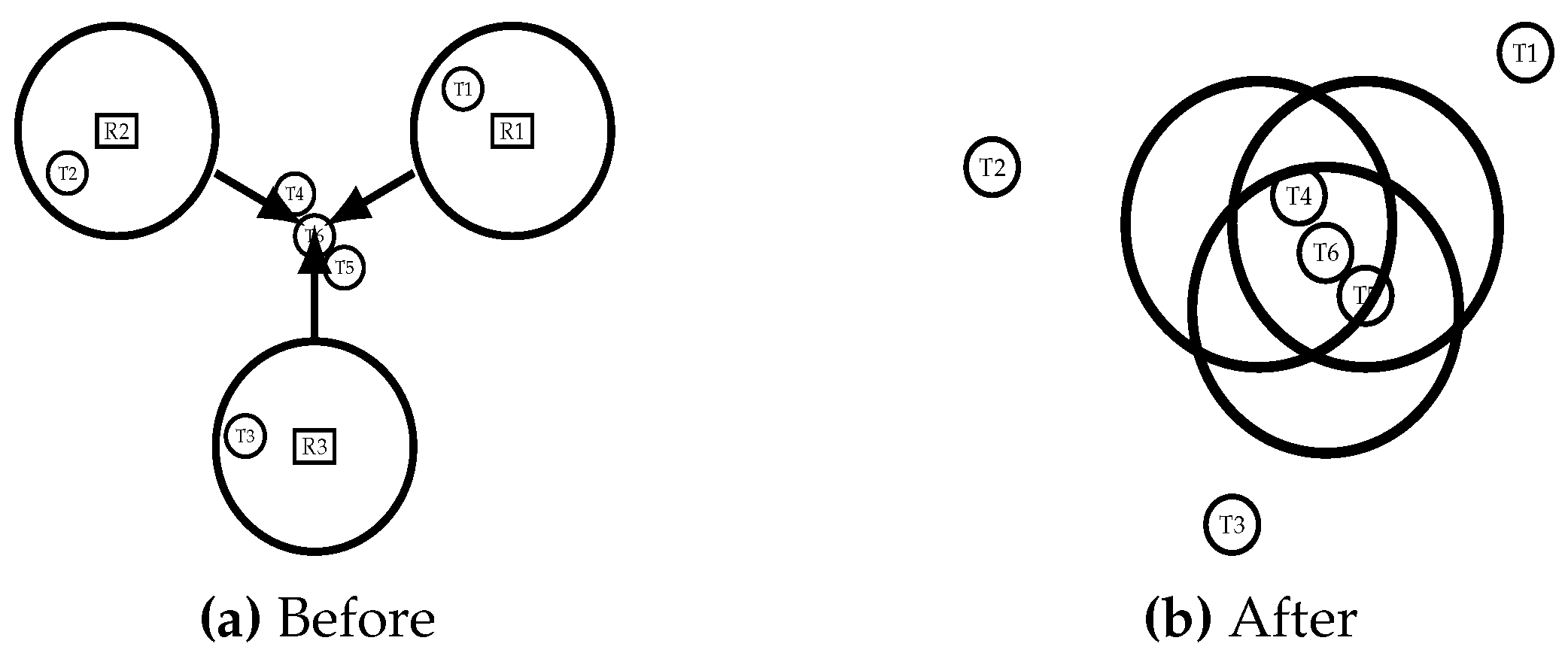
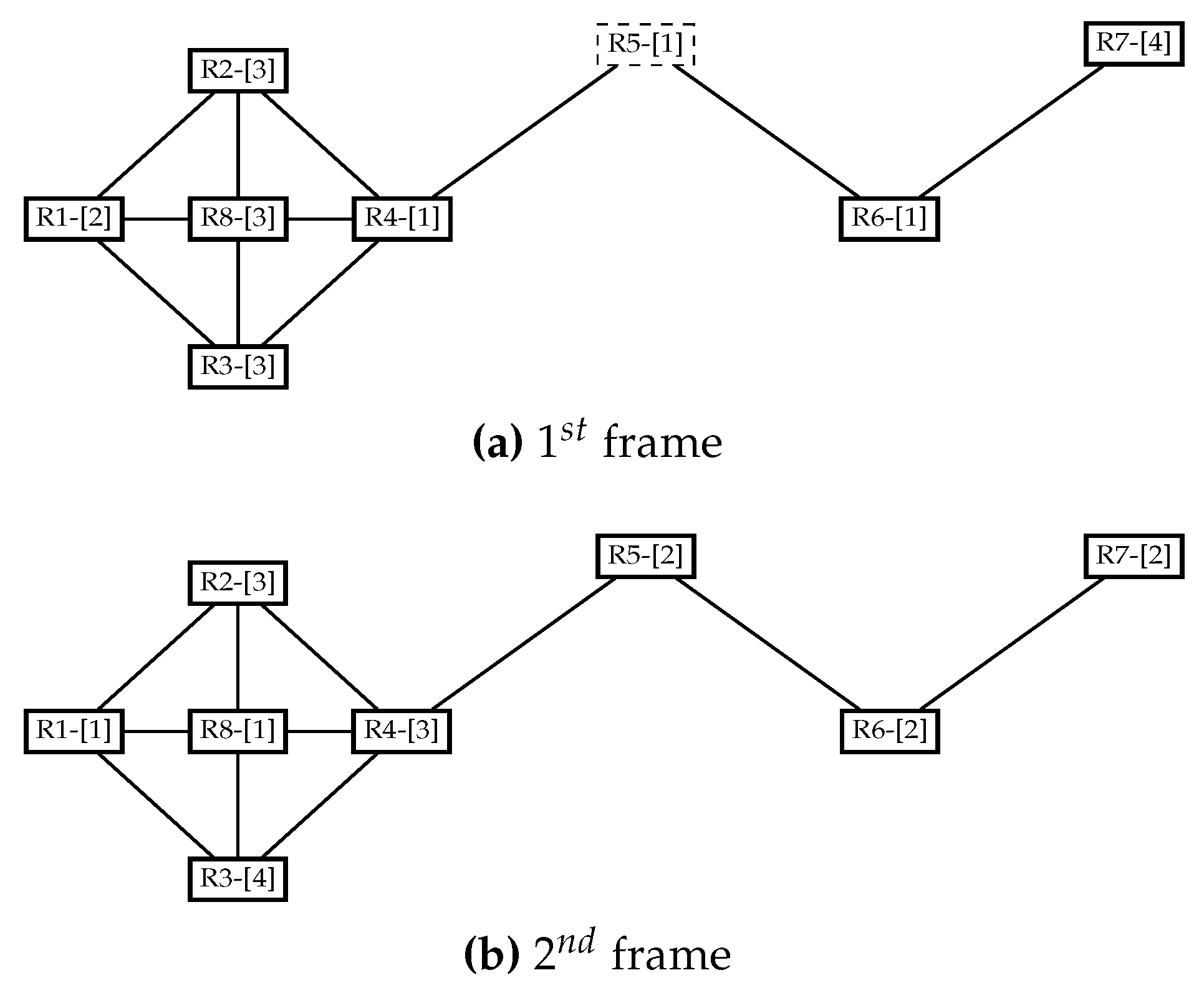
- Ri does not receive any beacon during Tbeacon. Ri is thus the only reader with this corresponding token in its vicinity. It can then access the medium to read tags during TCRT and switches its priority to LAZY (Algorithm 1, lines 5 and 6). In the topology shown in Figure 5a, readers R1, R2, R5, R6, R7 and R8 are in this case, they will not receive any beacon from their neighbors and will proceed to read tags.
- Case 2:
- Ri receives one or more beacon(s) with corresponding tokens during Tbeacon. In Figure 5a, R3 and R4 collide and receive each other’s beacons. Ri thus compares the IDs contained in the received beacons with its own:
- –
- Either ID of Ri is the smallest. Ri then accesses the medium for TCRT and switches to LAZY priority (Algorithm 1, lines 8 and 9). In Figure 5a, R3 wins the contention since it has the lowest ID;
- –
- or ID of Ri is greater than any of the IDs received. Ri leaves the contention and switches its priority to PUMPED UP (Algorithm 1, line 10). It loses the previously chosen token and randomly picks another set of channels and slots for the next frame. In the case of our topology in Figure 5a, R4 loses the contention and lets R3 read.
- Case 1:
- Ri is LAZY:
- -
- no collision: There are no concurring readers in the vicinity of Ri, it sends its beacon but does not receive any beacon from its neighbors. It then accesses the tags for TCRT and remains in LAZY priority (Algorithm 2, lines 5 and 6). Readers R1, R3, R5, R6 and R7 successfully read tags since they do not receive beacons from neighbors in Figure 5b;
- -
- collision: There is at least one concurring reader in the vicinity of reader Ri which receives at least one corresponding beacon from one of its neighbors (Algorithm 2, line 7). In Figure 5b, Readers R2 and R8 are concerned:
- *
- Ri matches the priority levels of the readers that sent their beacons, if any of them is a PUMPED UP one, Ri shuts off and waits for the the next frame with a PUMPED UP priority (Algorithm 2, lines 9 and 10). As such, R2 and R8 receive the PUMPED UP beacon from R4 and get disabled for the current round in Figure 5b;
- *
- if all the readers that have sent beacons are LAZY as well, Ri then matches its ID with the readers that sent their beacons. It resolves the contention with respect to the IDs, as done in the first round (Algorithm 2, lines 12 to 14).
- Case 2:
- Ri is PUMPED UP:
- -
- no collision: there are no concurring readers in the vicinity of Ri, it sends its beacon but does not receive any beacon from its neighboring readers. It then accesses the tags for TCRT and switches its priority to LAZY (Algorithm 2, lines 5 to 7);
- -
- collision: there is at least one concurring reader in the vicinity of reader Ri which receives at least one corresponding beacon from one of its neighbors (Algorithm 2, line 7). In Figure 5b, R4 is concerned:
- *
- Ri compares the priority levels of the readers that have sent their beacons during phase 1, if all of them are LAZY ones, Ri accesses the medium to read tags for TCRT and then switches to LAZY priority (Algorithm 2, lines 18 and 19). Indeed, in Figure 5b, R4 receives LAZY beacons from R2 and R8;
- *
- if any of the readers that have sent a beacon are in a PUMPED UP priority as well, Ri then compares the IDs and resolves the contention with respect to the IDs, as done in the first round (Algorithm 2, lines 21 to 23).
| Algorithm 1 First frame for a reader Ri |
|
| Algorithm 2 Next frames for a reader Ri |
|
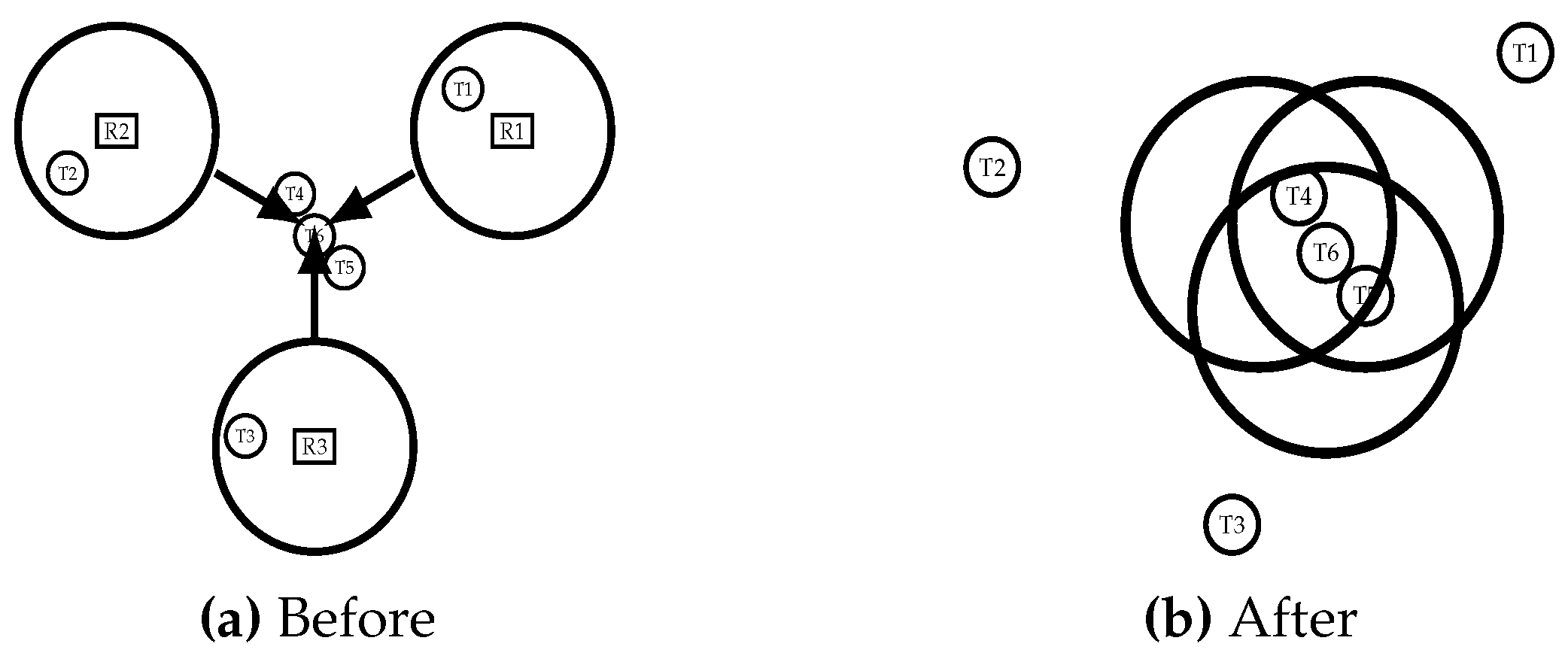
4.2. Mobile-DEFAR
5. Coverage Oriented RFID Anticollision (CORA)
- if M > 0 (Algorithm 3, lines 15 and 16), the reader considers there are too many neighbors on the same slot as its own and gets disabled. The potential size of the colliding area between all the contending readers in its vicinity involved makes it inefficient to read. In the example of Figure 7a, after beacon exchange, reader R5 will not access tags since it collides with both R4 and R6. In Figure 7b, tags covered by R5 will be read since it is now on a different slot;
- if M ≤ 0 (Algorithm 3, lines 17 to 19), the reader accesses the medium even if it might collide with some of its neighbors, considering that the uncovered tags due to collisions will be read by the neighboring readers on different slots within the same frame. As such, in Figure 7a, all readers except R5 access tags. Regarding tags laying between R2, R3 and R8, they will not be read in the current round but in the following round, Figure 7b; the previously unread tags will successfully be read since the three involved readers are on different slots.
| Algorithm 3 CORA algorithm |
|
6. Performance Results
- static deployments: In these runs, both tags and readers deployed remain fixed during the length of the simulation. This scenario was considered to assess the performance of our algorithms in a dense environment;
- dynamic deployments: In these runs, we considered a mix of both static and mobile tags and readers moving around the considered deployments area at various speeds and patterns. Having more dynamic scenarios that remain dense in terms of readers and tags deployments allows the observation of the performance of our algorithms in applications such as the one depicted in Section 1.
6.1. Static Deployments
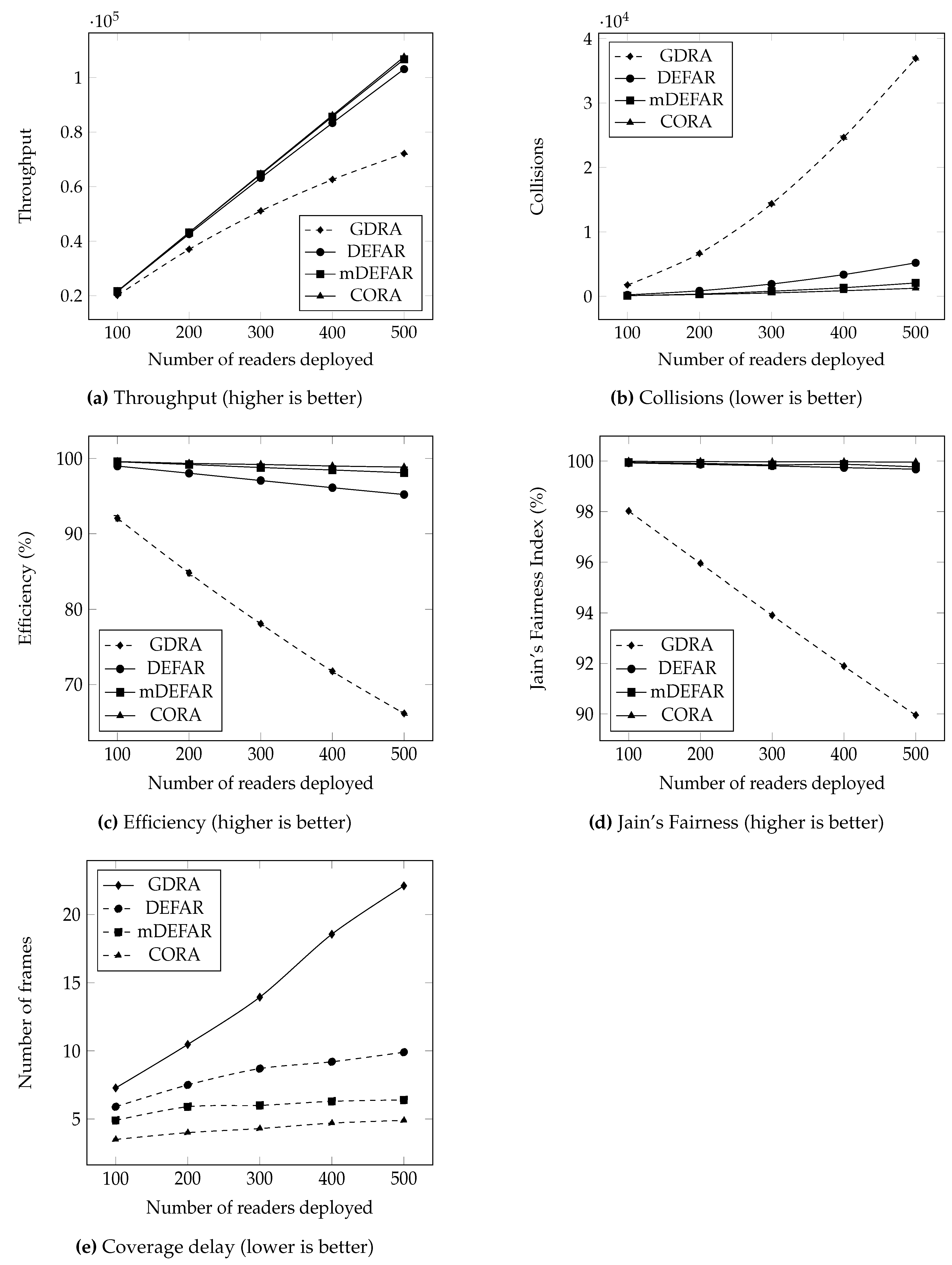
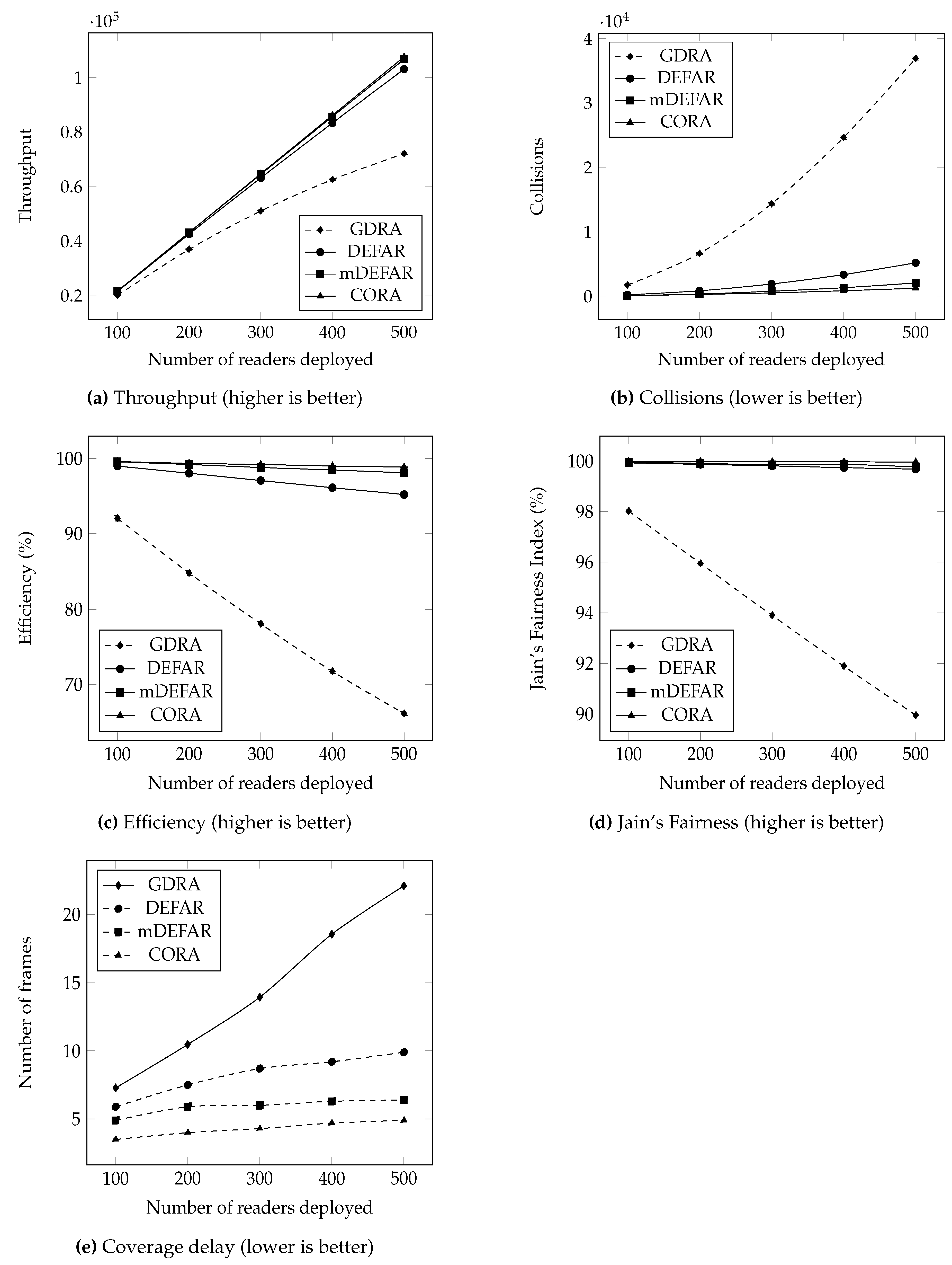
- Throughput: Here defined as the average number of successful query sections (SQS) over simulated time. A successful query section is counted every time a reader successfully goes through the contention process and accesses the medium. The higher the throughput, the better the protocol is considered to be. In Figure 8a, the throughput of our three proposals is compared with GDRA for the different network densities tested. All throughput values increase with the number of readers deployed in the system; this is expected since with more readers we have more potential query sections. We notice that all throughput values are similar in the beginning, around 100 readers deployed then an increasing gap is noticed between our proposals and GDRA. For GDRA, this is explained by the fact that in case of a collisions, all readers in the same vicinity get disabled. While in DEFAR, mDEFAR and CORA there is always at least one reader enabled to identify tags. The three proposals show quite similar values with mDEFAR and CORA operating slightly better since the smaller interference and communication range induce more readers to have a chance at being enabled.
- Collisions: Two types of collisions are identified, channel access collision and reading collision. Channel access collisions happen when multiple readers choose the same beaconing slot or when different readers in the same vicinity fail to choose different slots and/or channels. Reading collisions happen when two or more readers access tags in their intersecting surroundings at the same time (see Figure 1). When the former occurs, we consider an unsuccessful query section happened, and the involved readers got disabled and covered tags were not read. The latter ones are not computed since, according to our proposals and the ones used to compare, they cannot happen because readers in that situation are disabled by the respective algorithms except in the case of the CORA algorithm, but here again they cannot be computed as we willingly let them occur for a better compromise. Figure 8b shows the number of collisions according to the density of readers deployed. GDRA registers more collisions than our proposals due to its contention resolution process. Indeed, while we can have up to for DEFAR or for mDEFAR, only a single reader can be enabled in a reader’s vicinity in GDRA. This leads to more readers being disabled, hence the number of collisions recorded.
- Efficiency: This is the ratio of the SQS over the attempted query sections (AQS), . Attempted query sections are counted every time a reader tries to access the medium and goes through the contention process. This metric allows the combination of both the results in terms of throughput and collisions, in order to identify the best performing algorithm. In Figure 8c, the efficiency for all compared protocols depending on the density is shown. As this result is a combination of the previously introduced, it explains why GDRA has the lowest efficiency (dropping from 92% to 66%) while all our proposals remain above 95%. This proves that our proposals are all well-suited for dense deployments.
- Jain’s Fairness Index: This is the most used equity indicator [37] in the literature. Since simulations were run with static readers randomly deployed, it is interesting to understand how well each reader gets a fair access to the medium to read the tags that it is covering. If the resource is not fairly distributed, it can result in some tags not being identified. This JFI is computed as follows:where xi is the throughput of the i-th reader and n is the cardinal of deployed readers. When all readers get even throughput values, and in the worst case . Figure 8d shows that all tested algorithms perform very well in terms of equity since all of them have values over 90%. However, DEFAR and mDEFAR get better results thanks to the different priority levels introduced which allows failing readers a better chance at succeeding in following rounds.
- Coverage delay: This is the minimal time needed to read at least all tags in range at least once. Since readers are here static and both tags and readers were deployed randomly, not all tags are sure to be in range, so only the ones covered were considered in Figure 8e. It shows that our proposals perform faster than GDRA which is explained by the precedent results. It is, however, interesting to see that the compromise regarding collisions done with CORA allows a faster completion. Regarding the difference between DEFAR and mDEFAR, once again using a single channel allowed the reduction of the interference range. Since less readers are colliding, more are enabled and tags are identified faster.
6.2. Dynamic Deployments
6.2.1. Warehouse
6.2.2. Urban
6.2.3. Results
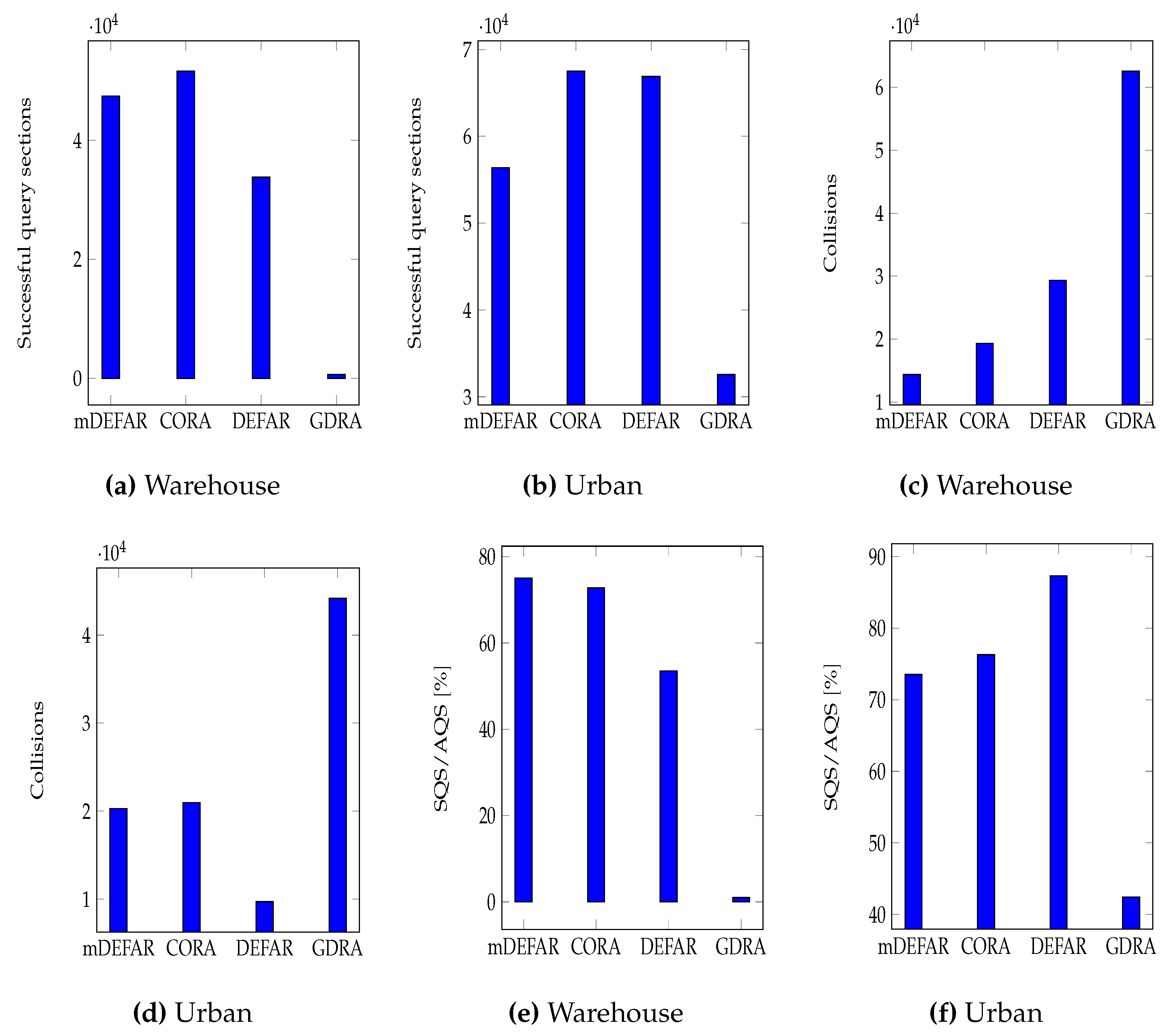
- Throughput: In this case, the throughput can be considered as a gain in tracking capability for security applications, since the higher the throughput, the higher granularity of data regarding products is available. Figure 10a shows the throughput of the different algorithms in the warehouse scenario. We can see that CORA clearly dominates with a higher throughput value. Indeed, in the warehouse where readers are between shelves with tags on the extremity of the reading range, colliding in a tag-free zone is not harmful and CORA takes advantage of this, hence the results. mDEFAR also performs very well thanks to its smaller interference range. GDRA, however, offers poor results due to the high number of colliding readers. In Figure 10b, results are different for mDEFAR and DEFAR. Indeed, in the urban scenario where we have both mobile and static readers, DEFAR performs better since it is able to reach a convergence state between readers located in corners and actively read tags, thus coming close to results obtained with CORA.
- Collisions: A collision in a mobile tag environment could mean that a tag was not identified and in a production chain could lead to a defective product not identified. In Figure 10c,d, GDRA shows the highest number of collisions which was expected from its poor performance in throughput. It is again interesting to see that in Figure 10d, DEFAR has the lowest collision values, which is explained by the convergence state that it is able to reach in this static/dynamic environment. mDEFAR and CORA both offer similar results however.
- Efficiency: From the previous results, in terms of throughput and collisions, the efficiency values can be predicted. As such, in the entirely mobile environment of the warehouse (Figure 10e), GDRA shows remarkably low efficiency (around 1%) compared to our proposals, which proves that it is not suited for mobile environments. mDEFAR, however performs the best despite it having a lower throughput than CORA (see Figure 10a), but the fewer collisions registered makes it slightly more efficient (75% for mDEFAR and 72% for CORA). In the urban scenario (Figure 10f), results are better for GDRA (42%), since the static readers on street corners benefit better from the algorithm, but are still lower than our proposals. DEFAR achieves the best results (87%) while mDEFAR and CORA are still quite similar (respectively 73% and 76%).
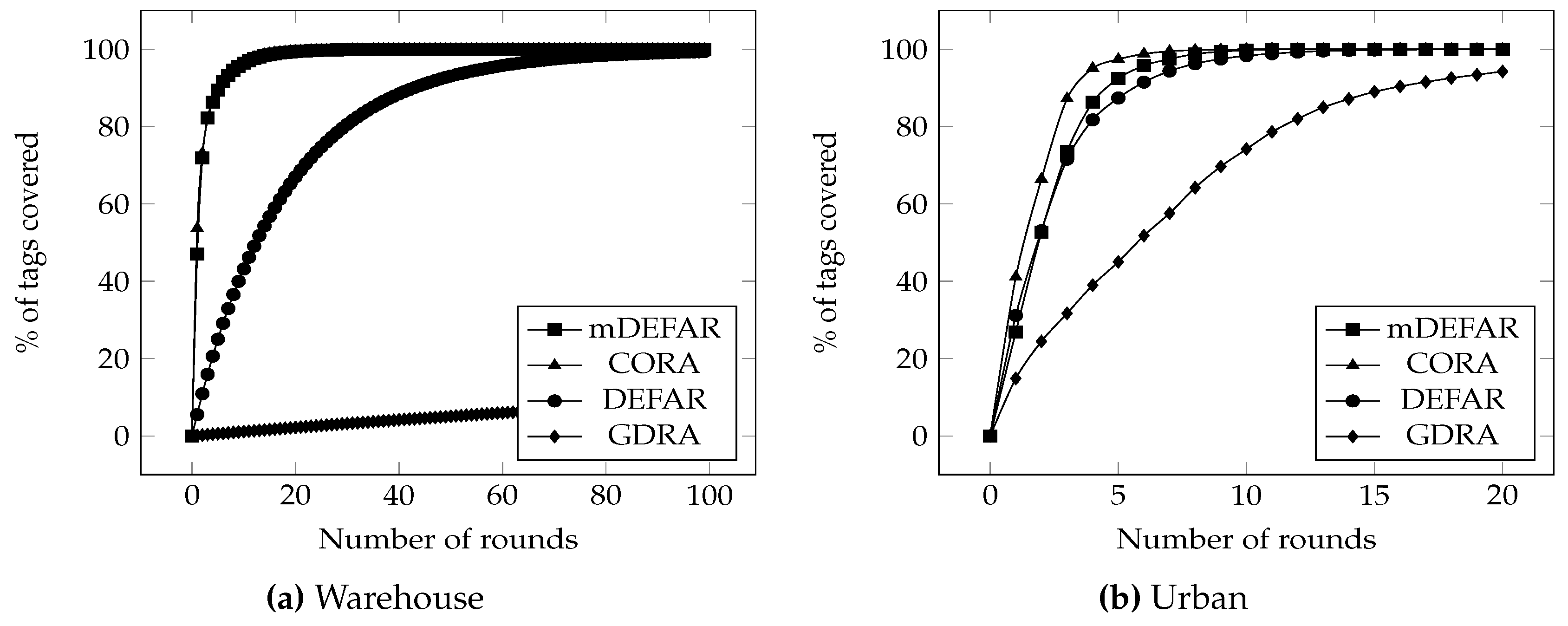
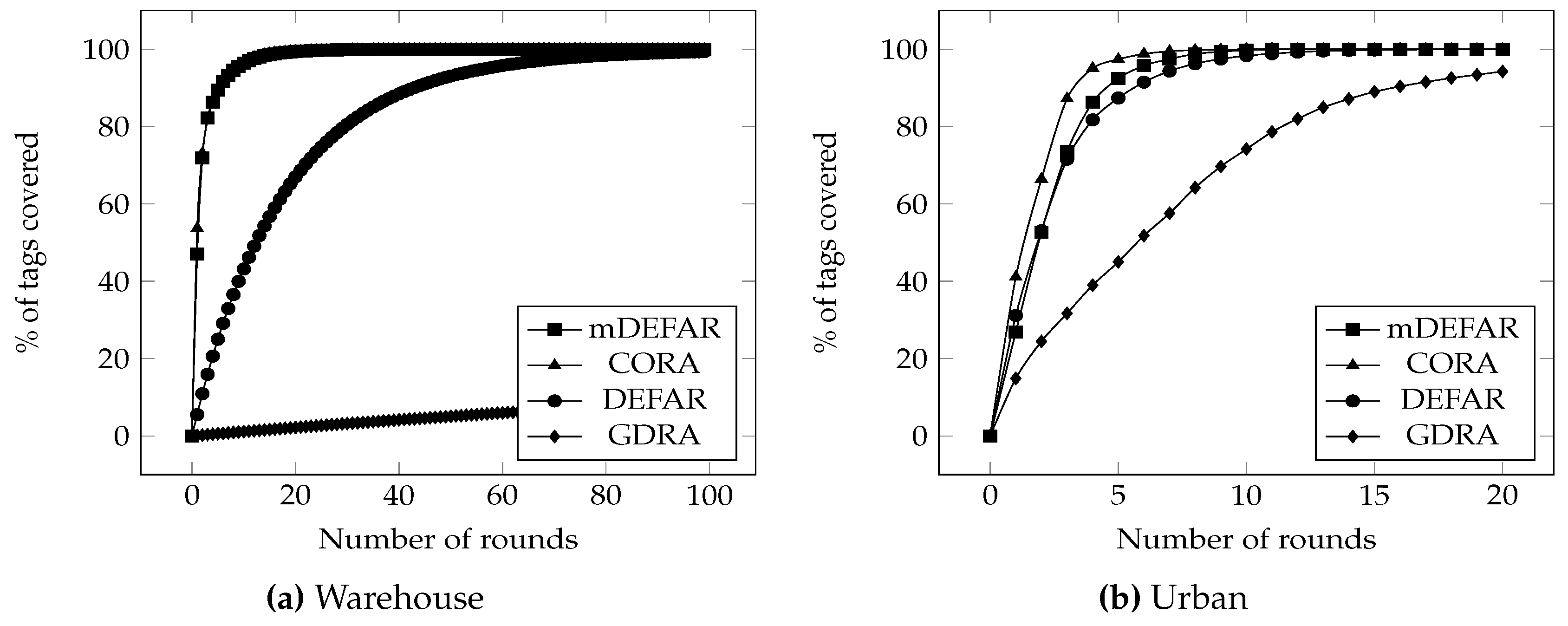
- Coverage delay: In a mobile environment, it can be compelling to get all tags information as fast as possible to know the state of the system at any given moment. Figure 11 shows the percentage of tags covered over time. In the warehouse application (Figure 11a), while mDEFAR and CORA have overlapping plots and achieve almost total coverage after 20 rounds, GDRA struggles to reach 10% coverage over simulation length. DEFAR, however, slowly reaches total coverage after 80 rounds. For the urban application (Figure 11b), results are better for GDRA which reaches 94% coverage after 20 rounds, while our proposals all reach 100%. CORA (12 rounds) achieves total coverage slightly faster than DEFAR (22) and mDEFAR (16). Even though DEFAR had a better efficiency and less collisions, it was still not as fast as CORA since the efficiency boost of DEFAR (see Figure 10d) is offered by the static readers which only cover the tags going through them while the moving readers with CORA bring the gain in coverage delay.
7. Discussion
7.1. Energy Consumption
7.2. Propagation Range Model
8. Conclusions
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| RFID | Radio Frequency IDentification |
| TDMA | Time Division Multiple Access |
| CSMA | Carrier Sense Multiple Access |
| DEFAR | Distributed Efficient Fair Anticollision for RFID |
| mDEFAR | mobile Distributed Efficient Fair Anticollision for RFID |
| CORA | Coverage Oriented RFID Anticollision |
| DCS | Distributed Color Selection |
| VDCS | Variable Distributed Color Selection |
| DCNS | Distributed Color Non-cooperative Selection |
| NFRA | Neighbor-Friendly Reader Anticollision |
| GDRA | Geometric Distribution Reader Anticollision |
| ACoRAS | Adaptive Color-based Reader Anticollision Scheduling |
| LBT | Listen Before Talk |
| HAMAC | High Adaptive Medium Access Control |
| APR | Anticollision Protocol for RFID-enhanced WSN |
| WSN | Wireless Sensor Network |
| SQS | Successful Query Sections |
| AQS | Attempted Query Sections |
| JFI | Jain’s Fairness Index |
References
- Finkenzeller, K. RFID Handbook: Fundamentals and Applications in Contactless Smart Cards and Identification; John Wiley & Sons: Hoboken, NJ, USA, 2003; Chapter 3; pp. 29–61. [Google Scholar]
- Engels, D.; Sarma, S. The Reader Collision Problem. In Proceedings of the 2002 IEEE International Conference on Systems, Man and Cybernetics, Hammamet, Tunisia, 6–9 October 2002.
- Specification, E.S. EPC TM radio-frequency identity protocols class-1 generation-2 UHF RFID protocol for communications at 860 MHz–960 MHz version 1.2.0. EPCglobal, USA, 2007. [Google Scholar]
- Bolic, M.; Simplot-Ryl, D.; Stojmenovic, I. RFID Systems : Research Trends and Challenges; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Benedetti, D.; Maselli, G.; Petrioli, C. Fast identification of mobile RFID tags. In Proceedings of the 2012 IEEE 9th International Conference on Mobile Adhoc and Sensor Systems (MASS), Las Vegas, NV, USA, 8–11 October 2012.
- Mbacke, A.A.; Mitton, N.; Rivano, H. Distributed Efficient & Fair Anticollision for RFID protocol. In Proceedings of the International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), New York, NY, USA, 17–19 October 2016.
- Khandelwal, G.; Lee, K.; Yener, A.; Serbetli, S. ASAP: A MAC protocol for dense and time-constrained RFID systems. EURASIP J. Wirel. Comm. Netw. 2007, 2007, 3. [Google Scholar] [CrossRef]
- Lee, S.R.; Joo, S.D.; Lee, C.W. An enhanced dynamic framed slotted ALOHA algorithm for RFID tag identification. In Proceedings of the International Conference on Mobile and Ubiquitous Systems: Networking and Services, MobiQuitous, San Diego, CA, USA, 17–21 July 2005.
- Simplot-Ryl, D.; Stojmenovic, I.; Micic, A.; Nayak, A. A hybrid randomized protocol for RFID tag identification. Sens. Rev. 2006, 26, 147–154. [Google Scholar] [CrossRef]
- Myung, J.; Lee, W.; Srivastava, J. Adaptive binary splitting for efficient RFID tag anti-collision. IEEE Commun. Lett. 2006, 10, 144–146. [Google Scholar] [CrossRef]
- Khandelwal, G.; Yener, A.; Chen, M. OPT: Optimal protocol tree for efficient tag identification in dense RFID systems. In Proceedings of the IEEE International Conference on Communications ICC ’06, Istanbul, Turkey, 11–15 June 2006.
- Piramuthu, S. Anticollision Algorithm for RFID Tags. In Proceedings of the Conference on Mobile and Pervasive Computer, CoMPC, New Delhi, India, 7–8 August 2008.
- Park, J.; Chung, M.Y.; Lee, T.J. Identification of RFID tags in framed-slotted ALOHA with robust estimation and binary selection. IEEE Commun. Lett. 2007, 11, 452–454. [Google Scholar] [CrossRef]
- Eom, J.B.; Lee, T.J.; Rietman, R.; Yener, A. An efficient framed-slotted ALOHA algorithm with pilot frame and binary selection for anti-collision of RFID tags. IEEE Commun. Lett. 2008, 12, 861–863. [Google Scholar] [CrossRef]
- Bolic, M.; Latteux, M.; Simplot-Ryl, D. Framed aloha based anti-collision protocol for RFID tags. In Proceedings of the of ACM Workshop on Convergence of RFID and Wireless Sensor Networks and their Applications, SenseID, Sidney, Australia, 6–9 November 2007.
- Yu, J.; Lee, W. GENTLE: Reducing reader collision in mobile RFID networks. In Proceedings of the 4th International Conference on Mobile Ad-Hoc and Sensor Networks, Wuhan, China, 10–12 December 2008.
- Electromagnetic compatibility and Radio spectrum Matters ERM Radio Frequency Identification Equipment operating in the band 865 MHz to 868 MHz with power levels up to 2 W Part 2: Harmonized EN covering the essential requirements of article 3.2 of the R and TTE Directive. ETSI EN 302 208-2, July 2011.
- Waldrop, J.; Engels, D.W.; Sarma, S.E. Colorwave: An anticollision algorithm for the reader collision problem. In Proceedings of the IEEE International Conference on Communications, 2003. ICC ’03, Anchorage, AK, USA, 11–15 May 2003.
- Birari, S.; Iyer, S. PULSE : A MAC Protocol for RFID Networks. In Proceedings of the IEEE/IFIP International Conference on Embedded and Ubiquitous Computing, Nagasaki, Japan, 6–9 December 2005.
- Hwang, K.I.; Kim, K.; Eom, D.S. DiCA: Distributed Tag Access with Collision-Avoidance Among Mobile RFID Readers. In Proceedings of the International Conference on Computational Science and Engineering, 2009. CSE ’09, Vancouver, BC, Canada, 29–31 August 2006.
- Hamouda, E.; Mitton, N.; Simplot-Ryl, D. Reader Anti-Collision in Dense RFID Networks With Mobile Tags. In Proceedings of the 2011 IEEE International Conference on RFID-Technologies and Applications (RFID-TA), Shunde, China, 21–23 September 2011.
- Eom, J.B.; Yim, S.B.; Lee, T.J. An efficient reader anticollision algorithm in dense RFID networks with mobile RFID readers. IEEE Trans. Ind. Electron. 2009, 56, 2326–2336. [Google Scholar]
- Xia, M.; Yu, Q.; Li, Z. Relative density based anti-collision algorithm in RFID networks with dense readers. In Proceedings of the IEEE Region 10 Conference TENCON, Macau, China, 1–4 November 2015.
- Eom, J.; Lee, T.J. RFID Reader Anti-collision Algorithm Using a Server and Mobile Readers Based on Conflict-Free Multiple Access. In Proceedings of the IEEE International Performance, Computing and Communications Conference, IPCCC 2008, Austin, TX, USA, 7–9 December 2008.
- Bueno-Delgado, M.V.; Ferrero, R.; Gandino, F.; Pavon-Marino, P.; Rebaudengo, M. A geometric distribution reader anti-collision protocol for RFID dense reader environments. IEEE Trans. Autom. Sci. Eng. 2013, 10, 296–306. [Google Scholar] [CrossRef]
- Ferrero, R.; Gandino, F.; Montrucchio, B.; Rebaudengo, M. Fair anti-collision protocol in dense RFID networks. In Proceedings of the 3rd International EURASIP Workshop on RFID Technology (EURASIP-RFID), Cartagena, Spain, 6–7 September 2010.
- Ferrero, R.; Gandino, F.; Montrucchio, B.; Rebaudengo, M. A fair and high throughput reader-to-reader anticollision protocol in dense RFID networks. IEEE Trans. Ind. Inform. 2012, 8, 697–706. [Google Scholar] [CrossRef]
- Amadou, I.; Mitton, N. HAMAC: High Adaptive MAC Protocol for Dense RFID reader-to-reader Networks. In Proceedings of the International Conference on Ad Hoc Networks (AdHocNets), San Remo, Italy, 1–2 September 2015.
- Golsorkhtabaramiri, M.; Hosseinzadeh, M.; Reshadi, M.; Rahmani, A.M. A Reader Anti-collision Protocol for RFID-Enhanced Wireless Sensor Networks. Wirel. Pers. Commun. 2015, 81, 893–905. [Google Scholar] [CrossRef]
- Waldrop, J.; Engles, D.W.; Sarma, S.E. Colorwave: A MAC for RFID reader networks. In Proceedings of the IEEE International Conference on Wireless Communications and Networking, 2003. WCNC ’03, New Orleans, LA, USA, 16–20 March 2003.
- Gandino, F.; Ferrero, R.; Montrucchio, B.; Rebaudengo, M. DCNS: An adaptable high throughput RFID reader-to-reader anticollision protocol. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 893–905. [Google Scholar] [CrossRef]
- Jamieson, K.; Balakrishnan, H.; Tay, Y. Sift: A MAC protocol for event-driven wireless sensor networks. In Proceedings of the EWSN ’06 International Conference on Embedded Wireless Systems and Networks, Zurich, Switzerland, 13–15 February 2006.
- Amadou, I.; Mbacké, A.A.; Mitton, N. How to improve CSMA-based MAC protocol for dense RFID reader-to-reader Networks? In Proceedings of the ADHOC-NOW 2014, 13th International Conference, Benidorm, Spain, 22–27 June 2014.
- Leong, K.S.; Ng, M.L.; Grasso, A.R.; Cole, P.H. Synchronization of RFID readers for dense RFID reader environments. In Proceedings of the SAINT Workshops 2006, International Symposium on Applications and the Internet Workshops, Phoenix, AZ, USA, 23–27 January 2006.
- Hamida, E.B. WSNet—An event-driven simulator for large-scale wireless sensor networks. 2007. Available online: http://wsnet.gforge.inria.fr/ (accessed on 25 November 2016).
- Gandino, F.; Ferrero, R.; Montrucchio, B.; Rebaudengo, M. Evaluation Criteria for Reader-to-Reader Anti-collision Protocols; Technical Report; Politecnico di Torino: Turin, Italy, 2012. [Google Scholar]
- Jain, R.; Durresi, A.; Babic, G. Throughput Fairness Index: An Explanation; Technical Report; Department of CIS, The Ohio State University: Columbus, OH, USA, February 1999. [Google Scholar]


© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mbacke, A.A.; Mitton, N.; Rivano, H. RFID Reader Anticollision Protocols for Dense and Mobile Deployments. Electronics 2016, 5, 84. https://doi.org/10.3390/electronics5040084
Mbacke AA, Mitton N, Rivano H. RFID Reader Anticollision Protocols for Dense and Mobile Deployments. Electronics. 2016; 5(4):84. https://doi.org/10.3390/electronics5040084
Chicago/Turabian StyleMbacke, Abdoul Aziz, Nathalie Mitton, and Herve Rivano. 2016. "RFID Reader Anticollision Protocols for Dense and Mobile Deployments" Electronics 5, no. 4: 84. https://doi.org/10.3390/electronics5040084
APA StyleMbacke, A. A., Mitton, N., & Rivano, H. (2016). RFID Reader Anticollision Protocols for Dense and Mobile Deployments. Electronics, 5(4), 84. https://doi.org/10.3390/electronics5040084